
基于联邦学习的交通标志识别
2022-10-24 08:12:32李佳灏毕国耀
电脑知识与技术 2022年26期
李佳灏,毕国耀
(广东工业大学,广东广州 510006)
1 概述
随着社会发展水平的不断提升,交通运输技术和通信技术两者凭借着高速的信息物质交流方式得以在近年来得到高速发展,大大提高了人们的生活质量水平,但另一方面,由于运输车辆的膨胀式增加,导致多地交通事故频发,给人们的生活带来了一定的安全问题,由于互联网的高速发展以及人们的网络安全知识相对并未有较大提升,网络安全问题也给人们的隐私安全问题带来了困扰。为了解决这些问题,人们也在不断探索着相关方面的内容。为了避免驾驶员驾驶过程中因为疏忽导致的交通安全问题,企业在车辆方面进行了一系列的改进,如美国汽车工程学会通过分级的形式对自动驾驶提出了从Level 0到Level 5的等级划分[1],其中驾驶辅助等级表示驾驶员和车辆系统共同操作驾驶过程,减轻驾驶员的部分驾驶工作,目前在多个领域已有落地方案,如红外线探测、超声波探测、计算机视觉探测等[2],通过对外部环境的提前判断,及时给予驾驶员正确的提示,能够大大减少交通事故的发生。然而,随着大数据的发展,数据集的需求性也随之提升,因此数据集的隐私安全问题越来越成为不可忽视的一环,为了避免人们的隐私信息数据的泄露,谷歌提出了一种称为联邦学习的神经网络模型训练模式,其目的是在不共享各自隐私数据的前提下,通过共同构建一个神经网络总模型,聚合各节点的权重更新,也能达到利用多边数据协同训练模型的效果。
本文根据以上所述的驾驶辅助和联邦学习模型,提出一种基于联邦学习的交通标志识别方法,利用联邦学习中多设备协同训练的方式训练预测模型,在不泄露驾驶员的驾驶数据隐私的前提下,利用车辆计算设备的算力资源为预测模型提供本地训练,辅助驾驶员辨识交通标志,提高驾驶安全性。实验以GTSRB数据集作为训练用数据集,以AlexNet作为基础模型,以联邦学习模式更新共享模型,实验结果证明相较传统模型训练方式有更好的可行性。
2 相关工作
2.1 联邦学习
联邦学习是一种多方协同训练模型的训练模式[3],能通过多客户节点不相互透露隐私数据的前提下,只通过向服务节点提供模型更新参数,以达到更新整体预测模型的目的。在这种训练模式下,驾驶系统先下载网络模型至本地后,使用本地的视频数据进行训练,再把训练更新的模型权重参数上传至服务节点。服务节点在接收到各地上传的模型权重参数后,把所有权重参数聚合,再对预测模型进行优化,由于数据的提取和分析都在驾驶系统客户端,解决了数据孤岛以及安全隐私的问题。
2.2 交通标志分类
由于交通行业的发展,针对驾驶识别的相关研究也在不断深入,常见的检测方法都是基于图像传感器作为输入,再基于不同的识别方法进行细致的判断,如颜色、形状、多特征融合、深度学习等[4]。而深度学习方法相比其他方法,在解决光照变化、局部遮挡等问题带来的影响方面具有更为突出的优势,因此基于深度学习的交通标志识别在未来将会有更多的展望与发挥。
3 基于联邦学习的交通标志识别
3.1 交通标志识别系统模型
本文以模拟实际驾驶场景出发,构建出一种辅助驾驶员判断交通标志含义的识别分类系统,为了保护驾驶员的数据安全和隐私内容,同时实现多边数据训练提高检测精度,该系统由多个客户端和一个服务端组成,其中客户端指在驾驶车辆安装的边缘计算设备,用于完成对驾驶数据采集、训练、存储等任务,而服务端则是一个具有算力的云服务器,用于接收各客户端发送来的迭代数据等任务,以聚合多边信息提升总模型精度。整体大致的过程为:服务端先对总模型进行初始化和分发至客户端,客户端接收到对应的模型数据后,基于该模型进行本地数据的训练任务,再将模型参数上传回服务端,各客户端之间的训练任务相互独立,不会相互传输数据,服务端接收到所有客户端的模型参数后,把所有参数进行聚合更新,得到一个新的总模型,由于总模型聚合了所有客户端的权重更新信息,具有一定的识别分类能力,不断循环如上步骤,从而达到所需的模型预测精度。在传输方面,由于在整个过程中并不涉及客户端本地数据集的传输通信操作,所以能保障用户的信息安全和个人隐私,在训练方面,联邦学习算法通过加权平均更新模型参数,相比传统的训练迭代方式,能在相对较少的通信次数下完成更快的模型参数收敛[5]。联邦学习流程结构如图1所示。
3.2 联邦学习实现过程
本文使用迭代平均聚合方式来构建联邦学习模型[6],具体流程可用数学模型表示,设通讯训练轮次t,t∈{1,2,3,…},当前总模型参数权重wt,基于各客户端本地数据的模型参数权重wt+1i,共有n个客户端,i代表其中一个客户端,m代表每一轮随机选择的用户数量。服务端在每轮中随机选择m个客户端作为本轮聚合对象,并向这些客户端发送当前总模型wt,m的值可通过当前模型权重参数量进行调整以提高通信效率。当被选择的客户端收到了当前模型后,通过本地训练网络得到新的模型权重其与原模型的权重参数差就是后续上传回服务端的数据,客户端i在t轮中训练后得到的权重更新值为:

因此可以把系统模型更新函数定义为:
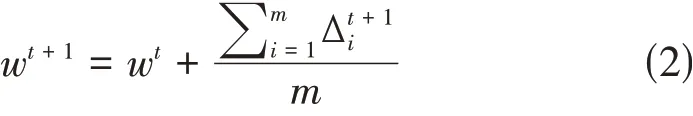
本文应用方案采用的是横向联邦学习方案[7],其关联在于用户特征与用户本身维度,即通过用户的维度来切分数据集的场景,可用于共同训练来自不同用户但有相同特征空间的神经网络模型。当存在两个不同的用户x、y,数据集的特征空间为S,标签空间为L,用户的样本空间为I,则可将其定义为:
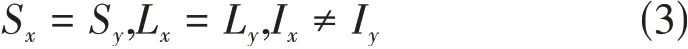
4 实验结果与分析
4.1 数据集和评估指标
本文采用GTSRB交通信号数据集进行训练,该数据集分为训练数据集和测试数据集两部分,其中训练数据集包含43种交通标志类型及其对应标签作为模型训练,测试数据集中随机包含以上43种交通类型数据及其对应标签,数据集图片示例如图2所示。

图2 GTSRB数据集图片示例
4.2 实验内容
本文提出的基于联邦学习的交通标志识别辅助系统架构,以独立分布形式随机抽样数据平均分配到各个客户端中,实验环境硬件配置采用AMD Ryzen7 CPU、GTX3060GPU、16G内存,软件配置为Python3.9、PyTorch1.8。
实验内容为搭建40个客户端和1个服务端,将数据集随机平均分配至全部客户端后,让客户端对持有的数据集图片调整成固定尺寸后进行本地模型训练,具体训练细节如下:总训练通信轮次为50次,客户端训练模型的批量大小为64,客户端训练更新的学习率为0.001,每次训练中客户端本地数据集训练次数为5。
本文使用的网络模型使用迁移学习的方式[8],以AlexNet预训练模型为基础,将模型结构分成特征提取层和分类层,特征提取层用于提取数据中的固有属性;分类层用于预测离散值,输出网络最终的判断结果。本文保留了预训练模型的特征提取层,并接入可用于该数据集的网络结构作为分类层。
4.3 实验结果
经过以上设置参数得出的实验数据结果如图3、图4所示,分别为测试数据集的准确率精度及其训练数据集的损失值指标,在经过50次通信迭代后,总模型精度达到了99.26%,损失值降到了0.0024,可见总模型在经过整体训练后达到了较高的准确率精度,损失值下降也相对稳定。
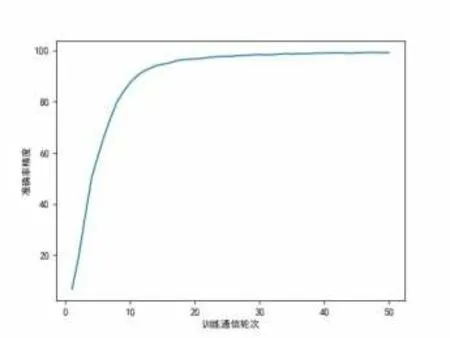
图3 准确率精度
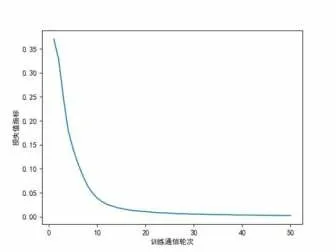
图4 损失值指标
图5、图6为在同样环境下,若干个客户端对本地数据集迭代训练50次的实验结果,绿色虚线、红色破折线、蓝色实线分别代表客户端数量为1、5、20个的情况下的实验结果,最终总模型的测试准确率分别达到了90.76%、97.69%、99.26%。损失值分别稳定在0.0522、0.0077、0.0028,相比联邦学习系统下的迭代过程,单个客户端的训练精度(即不使用联邦学习模式的场景),得到的模型测试准确率偏低,总体过程中的损失值下降过程出现较为明显震荡,而在使用了联邦学习模式下的模型精度有了较为明显的提升,并且随着客户端数量的增多,模型精度也会逐渐提高,损失值下降更快,且不容易出现震荡,整体模型稳定性有所提高。
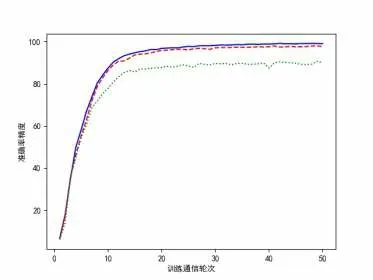
图5 准确率精度对比

图6 损失值指标对比
5 结论
本文基于联邦学习框架,针对智能辅助驾驶中的目标检测分类这一方向展开研究,构建出一种可部署于驾驶车辆和云服务器的交通标志识别系统,对比了联邦学习模式和单客户端之间的模型训练效果,通过客户端对数据参数化,服务端对模型聚合化,实现了在不泄露驾驶员隐私数据的前提下,也能达到训练总模型的效果,从而加快识别系统的训练速度和精度,充分发挥了用户本地资源的有效性,泛化驾驶辅助系统的感知判断能力。
猜你喜欢
东方少年·布老虎画刊(2023年12期)2024-01-01 08:51:05
汽车实用技术(2022年9期)2022-05-20 06:04:02
家庭影院技术(2020年10期)2020-12-14 07:54:16
家庭影院技术(2019年7期)2019-08-27 02:42:06
东华大学学报(自然科学版)(2018年1期)2018-06-29 03:35:18
消费导刊(2018年8期)2018-05-25 13:19:48
网络安全和信息化(2017年9期)2017-11-07 06:30:48
小天使·一年级语数英综合(2016年8期)2016-05-14 19:43:16
小天使·一年级语数英综合(2014年7期)2014-06-26 14:37:53
俄罗斯问题研究(2013年1期)2013-03-11 15:43:59
