
Self-supervised human semantic parsing for video-based person re-identification
2022-10-24 01:50WeiWuandJiaweiLiu
中国科学技术大学学报 2022年9期
Wei Wu,and Jiawei Liu
School of Information Science and Technology,University of Science and Technology of China,Hefei 230027,China
Abstract: Video-based person re-identification is an important research topic in computer vision that entails associating a pedestrian’s identity with non-overlapping cameras.It suffers from severe temporal appearance misalignment and visual ambiguity problems.We propose a novel self-supervised human semantic parsing approach (SS-HSP) for video-based person re-identification in this work.It employs self-supervised learning to adaptively segment the human body at pixel-level by estimating motion information of each body part between consecutive frames and explores complementary temporal relations for pursuing reinforced appearance and motion representations.Specifically,a semantic segmentation network within SS-HSP is designed,which exploits self-supervised learning by constructing a pretext task of predicting future frames.The network learns precise human semantic parsing together with the motion field of each body part between consecutive frames,which permits the reconstruction of future frames with the aid of several customized loss functions.Local aligned features of body parts are obtained according to the estimated human parsing.Moreover,an aggregation network is proposed to explore the correlation information across video frames for refining the appearance and motion representations.Extensive experiments on two video datasets have demonstrated the effectiveness of the proposed approach.
Keywords: person re-identification;self-supervised learning;semantic parsing
1 Introduction
Person re-identification (Re-ID) is the task of associating individuals across non-overlapping camera views.It has drawn increasing attention in recent years,as it plays a significant role in various practical applications,such as intelligent surveillance,activity analysis,smart retail,etc.[1-4]The surge of deep learning techniques has been reflected in the task of person Re-ID,achieving exciting progresses on many benchmark datasets.Nevertheless,it remains challenging in real scenario,due to cluttered background,partial occlusion,heavy illumination changes,viewpoint variations,etc.[5-7]
Person Re-ID is often approached with either image or video data for representation[8].Most existing approaches recognize pedestrians in static image setting,mainly focusing on learning image-level discriminative representations.In parallel with the impressive progress of image-based person Re-ID,video-based person Re-ID has recently attracted significant attention.Compared to an image with limited appearance information,a video sequence captures abundant visual details in a long time,presenting appearance under diverse posture and viewpoint variations.Hence,a video provides crucial knowledge to alleviate visual ambiguity.Besides,it also contains rich motion patterns of pedestrians,e.g.,walking style and moving direction[9,10],contributing to identifying pedestrians apart from appearance.The key to video-based person re-identification is effectively excavating appearance and motion information from video sequences.Fig.1 illustrates some sample video sequences on the two datasets,i.e.,MARS[11]and iLIDS-VID[12].
To leverage appearance information,some preliminary methods learned frame-level appearance features by considering the whole frames and then aggregating them through pooling operation or recurrent neural network[13].The ubiquitous presence of temporal appearance misalignment problem caused by partial occlusions,inaccurate detection or human pose variations,etc.,leads to severe performance degradation for these preliminary methods.Recent works attempted to address the misalignment issue:including fixed partition based methods which directly partition video frames into rigid horizontal stripes[14,15],and attention based methods which discover distinctive body parts by using diverse spatial attentions and crucial frames by using temporal attentions[16,17].However,they are rough with much background noise in their located partial regions,thus can not accurately extract features from body parts.Instead of utilizing these self-learned styles,some other methods exploit augmented information,including object segmentation[18]or pose estimation[19,20],to achieve part alignment at pixel level.Nevertheless,they depend on the accuracy of the pre-trained semantic segmentation or pose estimation models by additional datasets with annotations and are thus susceptible to dataset discrepancy.

Fig.1.Example video sequences in the MARS and iLIDS-VID person re-identification datasets.
Compared to appearance representation,motion patterns own strong robustness to the variations in illumination and viewpoint,which provide complementary cues for alleviating visual ambiguity and realizing precise matching.To leverage motion information from video sequences,most existing approaches either employ 3D convolution or resort to hand-crafted optical flow in an offline way[21,22].The 3D convolution operation is limited by high computational complexity and the unsatisfied ability for video analysis[23].However,pre-computed optical flow is independent of video-based person reidentification,which may not be optimal for this task.
Apart from the methods mentioned above,some gaitbased[24]and true motion-based[25]person Re-ID methods are also proposed to leverage motion information from video sequences.The method in Ref.[24] introduces gait recognition as an auxiliary task to drive person Re-ID models to learn more effective representations by leveraging personal unique and cloth-independent gait information.However,the learned gait feature is heavily dependent on the pre-extracted input silhouettes and pre-trained GaitSet (a set-based gait recognition model),which is thus susceptible to dataset discrepancy,deteriorating its ability.Moreover,the method in Ref.[25]formulates a FIne moTion encoDing (FITD) model based on dynamic cues,which characters motion patterns by the trajectory-aligned descriptors in a three-level body-action pyramid.However,it can’t obtain robust motion features by only using a fixed partition strategy to capture trajectory-aligned descriptors,due to the widespread misalignment issue.
In this work,we propose a novel self-supervised human semantic parsing approach (SS-HSP) for video-based person Re-ID.It is the first work for video-based person Re-ID exploring self-supervised learning to precisely locate human body parts at pixel-level by estimating the motion of each body part between consecutive frames without any manual annotation.By constructing a pretext task of predicting future frames,SSHSP learns segmentation maps of body parts and the corresponding motion field and explores temporal relations across video frames to generate reinforced appearance and motion representations.As illustrated in Fig.2,SS-HSP consists of a backbone network for extracting low-level visual representation,a semantic segmentation network for predicting future frames,and an aggregation network for Re-ID.The semantic segmentation network composes a segmentation module and a prediction module.The former is in charge of extracting the segmentation maps of body parts and the optical flows corresponding to these body parts.The latter is in charge of predicting the next frame by employing the current frame and the output of the segmentation module.Several customized loss functions optimize the semantic segmentation network.After obtaining the segmentation maps and optical flows,the aggregation network extracts frame-level appearance and motion features.It explores the complementary relation information across video frames via a temporal relation block to generate discriminative video-level representations.We conduct extensive experiments to evaluate SS-HSP on two challenging datasets and report superior performance over state-ofthe-art methods.
Although human semantic parsing has been explored in person Re-ID[5,26],these works are deigned for image-based person Re-ID without considering video human semantic parsing and temporal motion information.Thus they can not be directly applied to video-based person Re-ID.Moreover,they heavily rely on the performance of the pre-trained human parsing models by auxiliary datasets.They do not efficiently handle large-scale video datasets due to iteratively cluster the pixels of all training samples’ feature maps simultaneously.
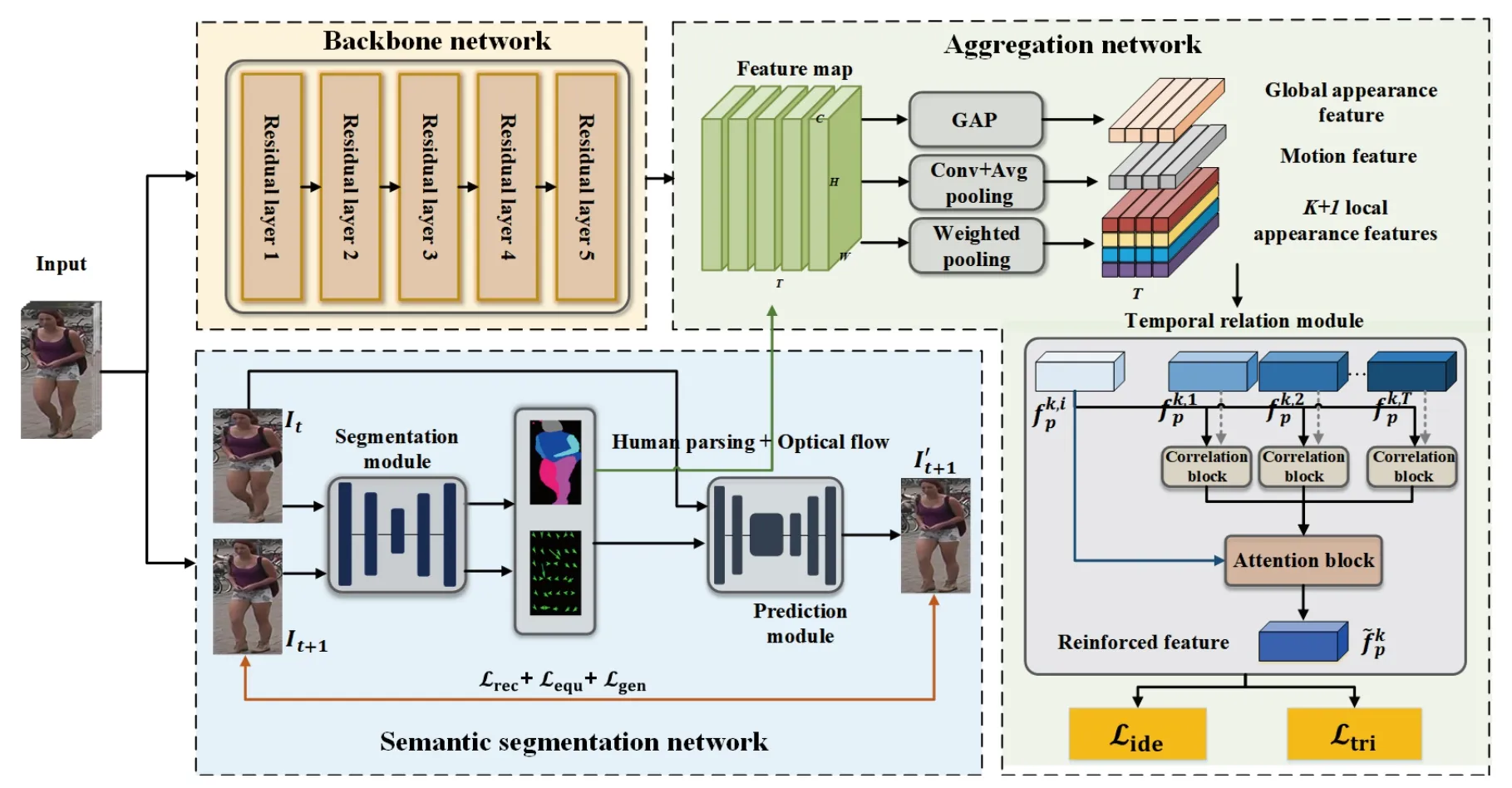
Fig.2.The overall architecture of the proposed SS-HSP.It consists of a backbone network,a semantic segmentation network as well as an aggregation network.
The main contribution of this work is three-fold:(ⅰ) We propose a novel self-supervised human semantic parsing approach (SS-HSP) for video-based person Re-ID.(ⅱ) We design a semantic segmentation network for precisely locating human body parts and estimating each body part’s motion information between consecutive frames.(ⅲ) We develop an aggregation network to explore the complementary relation information among video frames for learning reinforced appearance and motion representations.
2 Related work
Existing person re-identification approaches can be summarized into image-based person Re-ID and video-based person Re-ID.We briefly review the two categories of related works in this section.
2.1 Image-based person Re-ID
Conventional approaches for image-based person Re-ID mainly focus on designing hand-crafted descriptors[27,28]or learning appropriate distance metric[27,29].Recently,deep learning based methods have been widely proposed for learning distinctive features[17,30].For example,Zhou et al.[30]proposed a local-refining based deep neural network for person Re-ID,which contained a main branch network and a pose branch network to fuse pose and attribute information in a consistent way.Zhang et al.[31]proposed a Relation-Aware Global Attention (RGA) module,which captured the global structural information for better attention learning.Jin et al.[32]designed a semantics aligning network (SAN) for learning semantics-aligned feature representations from images under the joint supervision of re-identification and semanticsaligned texture generation.
2.2 Video-based person Re-ID
Early approaches for video-based person Re-ID concentrated on hand-crafted video-level descriptors or distance metric learning[12,33].Recent works mostly utilized deep learning techniques to extract discriminative representations from videos.Some methods[13]were proposed to formulate videobased Re-ID as an extension of image-based Re-ID simply.They extracted appearance features from each frame by various deep learning models,and aggregated frame-level features across time by pooling operation or RNN.For example,McLaughlin et al.[13]proposed a Siamese network,which captured pedestrian features and then employed a recurrent layer and a temporal pooling layer to abstract video-level features.For learning effective appearance features against the misalignment issue,rigid stripe partition[14]and attention mechanism[1]have been widely applied to plenty of person Re-ID methods.For example,Li et al.[16]proposed a spatio-temporal attention model automatically discovering a diverse set of distinctive body parts and extracting useful information from all frames against occlusions and misalignments.Moreover,a few works[18,19]utilized the augmented information to enhance feature representation.For example,Jones et al.[19]proposed a pose-guided alignment network which mimicked the topdown attention of the human visual cortex.On the other hand,for learning motion representation,some existing methods introduce 3D convolution[34]or pre-computed optical flow[35].For example,Liu et al.[21]proposed a Dense 3D-Convolutional Network (D3DNet) to jointly learn spatio-temporal and appearance representation from videos by 3D convolution.
3 Method
In this section,we first present the overall architecture of SSHSP and then introduce each component of SS-HSP in the following subsections.
3.1 Architecture overview
For video person Re-ID,we aim at learning effective and discriminative appearance and motion representations from videos.The overall architecture of SS-HSP is illustrated in-Fig.2.It consists of a backbone network,a semantic segmentation network and an aggregation network.Supposing a video sequence is denoted aswhereTis the sequence length.The backbone network takes each frame as an input to extract the initial feature mapswhere C,H,andWdenote the channel,height,and width of the feature maps,respectively.The backbone network is built on the Res-Net-50 model[36],which contains five residual layers,each of them is composed of several convolution layers,batch normalization (BN) layers,rectified linear units (ReLU) layers,and max-pooling layers.The semantic segmentation network consists of a segmentation module and a prediction module.The network learns the segmentation maps of human body parts and the corresponding optical flows among consecutive frames by constructing a pretext task of predicting future frames.The estimated segmentation maps and motion information together with the feature mapX,are fed into the aggregation network to generate reinforced clip-level appearance and motion features.These features are finally taken into a classifier and optimized by two Re-ID loss functions.
3.2 Semantic segmentation network
The misalignment and visual ambiguity issues are ubiquitous in person Re-ID,which deteriorate the ability of the extracted representation and compromise the performance.Considering that the annotation of human body parts is unavailable,we introduce a self-supervised learning strategy inspired by the work[37]to design a semantic segmentation network for adaptively locating body parts of pedestrians and extracting the corresponding motion information across consecutive frames.As shown in Fig.3,the network consists of a segmentation module and a prediction module.The semantic segmentation network employs the current frame with the motion information of body parts between consecutive frames to predict the next frame.
The segmentation module takes a pair of framesItandIt+1sampled from a video as input and generates the segmentation maps and motion field of body parts between the two consecutive frames.Concretely,the module is based on UNet architecture[38],which consists of four 3×3 convolution layers followed by BN layer,ReLU layer,and average pooling layer,and four 3×3 up-sampling convolution layers followed by BN layer and ReLU layer.The resolution of the input frames isH′×W′,and the outputs of the modules are two(6K+1)-channel tensorsSt,The tensorStcomposes one (K+1)- channel tensor,oneK-channel tensor,and one 4K-channel tensor.TheK-channel and 4K-channel tensors are used to calculate the motion field between the two consecutive frames.The remaining (K+1)-channel tensors are applied with a channel-wise softmax operation to generate the segmentation mapsMt,of body parts (K+1 denotesKbody parts of a pedestrian with additional background).
Moreover,we employ optical flows to represent the motion field between the two consecutive frames,which maps each position of pixels inIt+1to its corresponding position inIt.Note that the module does not use external optical flow estimators to calculate the motion between the two frames.Instead,it models the temporal motion of the pixels within each body part by an affine transformation.Therefore,the backward optical flow G between the two consecutive frames can be approximately by combining the affine transformation of each body part.Letdenotes the locations in the segmentation map associated tokth body part for frameI.Following the previous work[37],the optical flow for
t+1kth body part is computed as follows:



Fig.3.Detailed structure of the semantic segmentation network.
The prediction module takes the current frameItand the estimated optical flow field as input.It then warps the feature ofItaccording to the estimated optical flow field between the two frames for predicting the next frameThe module is based on the encoder-decoder architecture[39],which contains two down-sampling layers,a deformation layer[40],five residual layers and two up-sampling layers.The deformation layer is employed to warp the feature ofItwith the optical flow field,which is defined as follows:

wherevsdenotes the extracted feature map ofItafter two down-sampling layers,fw(·,·) denotes the back-warping function.Orefers to the background visibility map,which indicates the pixels of the background inIt+1are occluded by the foreground body parts inIt.The background visibility map suppresses the occluded regions’ information and provides an important regularization to enforce superior foreground/background region segmentation.Finally,the transformed feature mapis fed to subsequent layers of this module for rendering the next frameThe whole semantic segmentation network is trained by several losses,including reconstruction loss,equivariance loss,and geometric concentration loss.
3.3 Aggregation network
The aggregation network is designed with a temporal relation block to employ temporal relation among video frames and generate reinforced clip-level appearance and motion features.The network receives the initial feature mapXfrom the backbone network,the estimated segmentation map,and the optical flow field from the semantic segmentation network.The initial feature mapXis fed to a global average pooling(GAP) layer and a fully connected (FC) layer to produce the global appearance featuresMoreover,the feature mapXand theKsegmentation maps {M1,M2,...,MK} of body parts are applied with a weighed pooling layer and a FC layer to generate the (K+1) local appearance featuresThe last local appearance featureis associated with the overall foreground regionof video frames.The motion information ofare fed into a 1×1 convolution layer,an average pooling layer,and an FC layer to obtain the motion features
In order to effectively explore the complementary relation information across video frames and enhance the frame-level appearance and motion features,we develop a temporal relation block to refine the frame-level features by their relation with features of the other frames and aggregate them into robust clip-level features.Specifically,the frame-level features are firstly fed into a correlation block,which produces the informative and compact relation features.The formulation of this block is defined as follows:

whereftdenotes the local appearance feature,the global appearance feature,or the motion feature oftth video frame.φ,φ,h1,h2are the embedding functions implemented by a full connected layer with a BN layer and a ReLU layer.The relation featureaggregates the global relation information of all other frame-level features.Afterwards,the generated relation features go through an attention block to infer the temporal attention score for each video frame and form the reinforced clip-level appearance and motion features by weighted sum operation.It is formulated as follows:

whereatis a temporal attention value,Wis parameter matrix anddenotes the reinforced appearance or motion clip-level features.After the temporal relation block,the generated reinforced global and local appearance featuresare supervised by identification loss.Meanwhile,the reinforced appearance and motion featuresare concatenated,and then supervised by triplet loss.In the testing stage,the final video representation of pedestrians is formed by concatenating these features.
3.4 Loss function and optimization
We adopt reconstruction loss,equivariance loss and geometric concentration loss to optimize the semantic segmentation network.The reconstruction loss is based on the perceptual loss[39],which assesses the reconstruction quality between the predicted next frame and the ground-true next frame.The formulation of this loss is defined as follows:

where φi(·) denotes thei-th channel feature extracted from a pre-trained and fixed VGG-19 model[37].This loss calculates on three resolutions of 256×128,128×64,and 64×32 forThe equivariance loss encourages the learned segmentation maps and the optical flow field to be robust against the appearance variation and consistent with geometric transformation.It is formulated as follows:

whereDKLdenotes the Kullback-Leibler divergence distance,are the estimated segmentation map,the affine and shift parameters from the transformed framerefers to spatial transformation by thin plate splines,andTcrefers to appearance perturbation by color transforms.The geometric concentration loss enforces all the pixels that belong to a body part and are spatially close to the center of this body part[41].The formulation of this loss is defined as follows:

Identification loss and triplet loss are the widely-used losses for person Re-ID[42].Thus,we adopt triplet loss with hard mining strategy Ltri[43]and identification loss with label smoothing regularization Lide[44]to optimize the aggregation network.Thus,the total loss for this network is sum of the two losses (λ4Lide+λ5Ltri).The whole training process of SSHSP contains two stages.In the first stage,the semantic segmentation network is trained until convergence for the task of predicting future frames.In the second stage,the backbone network is followed by the aggregation network,and the pretrained segmentation module is optimized until convergence for person re-identification.
Although our semantic segmentation network is inspired by the method mentioned in Ref.[37] (hereinafter,the previous method),there are significant differences between SS-HSP and the previous method.(ⅰ) The previous method was proposed for image animation tasks that use a representation consisting of a set of learned key points along with their local affine transformations to encode the motion information.Thus,It cannot directly locate body parts of pedestrians and learn the corresponding motion information,which are the main purpose of video person Re-ID.(ⅱ) The previous method requires at least 2 frames to predict key-point neighborhoods,even during the inference,which makes its predictions highly dependent on the other frame in a pair.In contrast,SS-HSP encodes more semantically meaningful body parts by making independent frame-based predictions,thus can adaptively locate body parts of pedestrians for a single image during the inference.(ⅲ) Different from the previous method using reconstruction loss and equivariance loss,SS-HSP employs reconstruction loss,reinforced equivariance loss,and geometric concentration loss to impel the semantic segmentation network and to estimate more accurate segmentation map of body parts and learn more effective motion feature.
4 Experiments
In this section,we conduct several experiments on two widelyused video datasets to evaluate the effectiveness of SS-HSP.These experiments consist of comparative analysis with stateof-the-art methods and ablation studies.
4.1 Experimental settings
Datasets.MARS dataset[11]is one of the largest video-based person Re-ID dataset,consisting of 1261 identities and a total of 20715 video sequences.Each identity contains 13.2 video sequences on average,and the length of each video sequence varies from 2 to 920 frames,with an average number of 59.5.Following the work[11],we fixedly divide this dataset into 625 identities for training and remain 636 identities for testing.iLIDS-VID dataset[12]is another video person Re-ID dataset.It contains 300 identities from 600 video sequences.Each identity captured from two cameras has a pair of video sequences.Each video sequence contains variable lengths ranging from 23 to 192 video frames,with an average number of 73.Following the work[12],this dataset is randomly divided into 150 identities for training and 150 identities for testing.
Evaluation metrics.Cumulative matching characteristic(CMC) is widely used to quantitatively evaluate the performance of person Re-ID algorithms.The rank-krecognition rate in the CMC curve indicates the probability that an approach retrieves the ground-truth identity in the top-kposition.Another evaluation metric is the mean average precision (MAP),which evaluates the algorithms in a multi-shot setting.
Implementation details.The implementation of SS-HSP is based on the PyTorch framework with four Titan RTX GPUs.We randomly selectT=8 frames from a variablelength video sequence as the input clip.Each min-batch contains 16 pedestrians and 4 input clips for each pedestrian.All video frames are resized to the dimension of 3×256×128,which are then normalized with 1.0/256.The input frames are enlarged by data augmentation including random horizontal flipping and random erasing probability of 0.3.The parameters ofH′×W′are set to 64×32,andKis set to 6.The dimensions ofare 256.The hyper-parameters of λ1,λ2,...,λ5are set to 1.We adopt the Adam optimizer with the initial learning rate (lr) of 3e-4,the weight decay of 5e-4,and the Nesterov momentum of 0.9.In the first stage,the semantic segmentation network is trained for 120 epochs,which takes about 10 h.lris decreased by 0.1 after every 40 epochs.In the second stage,the whole model is optimized for 400 epochs,which takes about 12 h.lris decreased by 0.1 after every 150 epochs.
4.2 Comparison to state-of-the-arts
MARS:In Table 1,14 state-of-the-art methods of person Re-ID are compared with SS-HSP.The first two approaches belong to image-based person Re-ID,and the remaining approaches belong to video-based person Re-ID.From the results,SS-HSP achieves superior performance in terms of both Rank-1 accuracy and mAP over most of the state-of-the-art methods,especially for image-based Re-ID algorithms.The Rank-1 accuracy and mAP of SS-HSP reach 91.0% and 85.9%,respectively.Compared with the 2nd best method DenseIL,SS-HSP improves Rank-1 accuracy by 0.2%.Considering the high performance,the improvement of SS-HSP is appreciable.The comparison indicates the effectiveness of SSHSP for learning reinforced appearance and motion representations from video sequences against temporal appearance misalignment and visual ambiguity problems.
iLIDS-VID:In Table 2,12 state-of-the-art methods of person Re-ID are compared with the proposed SS-HSP.SS-HSP surpasses all the existing methods from Rank-1 to Rank-20 by a large margin,except for the method DenseIL.Especially on Rank-1 accuracy,it boosts the compared method AP3D by 1.6%.Moreover,compared with the 2nd best method DenseIL,SS-HSP improves Rank-5 accuracy by 0.4%.Thecomparison shows the effectiveness of the proposed SS-HSP on relatively small video datasets.Note that Snippet and AP3D utilize the optical flow or 3D convolution kernels to learn motion features,VRSTC,AGRL,and RGSAT attempt to learn appearance feature for handling temporal appearance misalignment problem.These methods are all inferior to SSHSP,which indicates SS-HSP is able to learn reinforced and discriminative appearance and motion features for person Re-ID.

Table 1.Performance comparison to the state-of-the-art methods on MARS dataset.

Table 2.Performance comparison to the state-of-the-art methods on iLIDS-VID dataset.
4.3 Ablation studies
Effectiveness of components.Table 3 summarizes the experimental results of the ablation studies for SS-HSP on MARS dataset.Basel,Basel+Part,Basel+Part+Motion,Basel+Part+Motion+TRB denote using SS-HSP to extract the global appearance feature with temporal averaging pooling (TAP),the global and local appearance features with TAP,the appearance and motion features with TAP,the reinforced appearance and motion features with the temporal relation block,respectively.Compared with Basel,Basel+Part boosts Rank-1 accuracy and mAP by 2.2% and 3.7%,respectively.The comparison shows that the semantic segmentation network can precisely learn the segmentation maps of body parts and guide SS-HSP to learn aligned part representations.By utilizing the motion representation,Basel+Part+Motion achieves obvious performance improvement over Basel+Part.The improvement indicates the semantic segmentation network can effectively extract optical flows,which contain abundant complementary information for appearance features.Moreover,by adding the temporal relation block,the best per-formance is obtained.The boosting demonstrates that this block effectively explores the complementary correlation information among video frames to refine the representations.

Table 3.Evaluation of the effectiveness of each component within SS-HSP on MARS dataset.
Different components of the loss function.The results in Table 4 show the influence of different components of the loss function.SS-HSP w/o Ltri,SS-HSP w/o Lide,SS-HSP w/o Lequ,and SS-HSP w/o Lgeodenote SS-HSP is trained without triplet loss,identification loss,equivariance loss,and geometric concentration loss,respectively.By comparing SSHSP w/o Ltriwith SS-HSP w/o Lide,we can observe that triplet loss can enforce the model to learn more effective representation.Moreover,both of SS-HSP w/o Ltriand SS-HSP w/o Lideare inferior to SS-HSP,indicating that jointly employing triplet loss and identification loss contributes to superior feature representation.Besides,the comparison results of SS-HSP w/o Lequ,SS-HSP w/o Lgeo,and SS-HSP show that equivariance loss and geometric concentration loss can impel the semantic segmentation network to learn more accurate human semantic parsing and effective motion representation towards better feature alignment and representation.

Table 4.Evaluation of the effectiveness of each component of the loss function on MARS dataset.
Number of body parts.In Fig.4a,we investigate the influence of different numbers of body parts on SS-HSP and find the most suitableK.From the results,we can see that the performance of SS-HSP is robust to different values ofK.As the number of body parts increases,the performance of SSHSP improves.SS-HSP obtains the best results with the setting of 6 body parts,and the performance drops whenKincreases from 6 to 8.We further visualize two examples of the estimated segmentation maps of 6 body parts in Fig.5,which validates that SS-HSP can precisely locate human body parts and extract aligned local appearance features.
Sequence with different lengths.In Fig.4b,we investigate the influence of sequence length.We selectTframes from a video sequence as the input clip.From the results,we can see that SS-HSP is robust to the variations inT.When the sequence lengthTincreases,the model captures wider range of temporal complementary information and obtains better reidentification performance.The longer sequences bring more computation complexity.Considering the limited computation resources,We setT=8 for SS-HSP in the experiments.
Retrieval results.Fig.6 shows the retrieval results of three pedestrians by SS-HSP on the MARS dataset.We can observe that Rank-1 retrieval results by SS-HSP are all matching.This indicates CTL effectively alleviates the problem of misalignment and occlusion,viewpoint variation,etc.and realizes precise re-identification.

Fig.4.Parameter analysis of (a) the number of body parts K and (b) the sequence length T on the MARS dataset.

Fig.5.Visualization results of the estimated segmentation maps of two video sequences.

Fig.6.Example of retrieval results by SS-HSP on MARS dataset.Correct matches are highlighted red.
5 Conclusions
In this work,we propose a novel self-supervised human semantic parsing approach (SS-HSP) for video-based person reidentification.It explores self-supervised learning to precisely locate body parts of pedestrians at pixel-level by estimating the corresponding optical flows between consecutive frames and utilizes the temporal relation information across video frames to learn reinforced appearance and motion representations.The semantic segmentation network builds a pretext task of predicting future frames in a self-supervised learning manner and learns the segmentation maps of body parts and the optical flow field from video sequences.The aggregation network refines the frame-level features by their relation to features of the other frames for accurate matching.Extensive experiments on the two challenging benchmarks have shown that the proposed SS-HSP achieves superior performance over a wide range of state-of-the-art methods.
Acknowledgements
This work was supported by the National Natural Science Foundation of China (62106245),the Fundamental Research Funds for the Central Universities (WK2100000021),and China Postdoctoral Science Foundation Funded Project(2020M671898).
Conflict of interest
The authors declare that they have no conflict of interest.
Biographies
Wei Wureceived her B.E.degree in Electronic Information Engineering from the University of Science and Technology of China (USTC) in 2020,and is pursing a Ph.D.degree in the School of Cyber Science and Technology at USTC.Her research interests mainly include computer vision and multimedia.
Jiawei Liureceived his B.E.degree from Hefei University of Technology in 2013 and received his Ph.D.degree from the University of Science and Technology of China (USTC) in 2019.He is currently an associate research fellow in the School of Information Science and Technology at USTC.His research interests mainly include computer vision and multimedia.

- 中国科学技术大学学报的其它文章
- IITZ-01 activates NLRP3 inflammasome by inducing mitochondrial damage
- Sphingosine-1-phosphate induces Ca2+ mobilization via TRPC6 channels in SH-SY5Y cells and hippocampal neurons
- Comprehensive bioinformatic analysis of key genes and signaling pathways in glioma
- Evolutionary game analysis of promoting the development of green logistics under government regulation
- The surrounding vehicles behavior prediction for intelligent vehicles based on Att-BiLSTM