
考虑多配送中心的多目标动态车辆路径优化
2022-10-24 04:57江雨燕王付宇
南阳理工学院学报 2022年4期
江雨燕,尹 莉,王付宇
(安徽工业大学管理科学与工程学院 安徽 马鞍山 243002)
0 引言
Dantzing和Ramser在1959年提出车辆路径问题[1](Vehicle Routing Problem,VRP)。在实际物流配送过程中可能出现原客户点的需求增多、减少以及交通堵塞等情况,需要配送车辆根据这些动态变化调整配送路线,这种问题就叫做动态车辆路径问题,与之对应的静态车辆路径问题是指在配送过程中客户所处位置、客户的需求量等都是不会发生变化的。显然,研究前者具有更深的实际意义。
动态车辆路径优化问题一直是众多学者研究的热点[2-4]。曹炳汝等[5]在车辆路径优化问题中,考虑需求变化及多种车型等因素,并建立两阶段车辆配送路径规划模型。李阳等[6]针对客户点不断更新的动态需求车辆路径问题,提出基于延迟服务的周期性客户点实时重置策略,建立周期性优化模型。范双南等[7]针对车辆配送过程中出现的配送路线不合理、客户需求发生变化等问题,建立动态车辆路径优化模型。Hu C等[8]在硬时间窗车辆路径问题中,考虑了动态变化的客户需求和行驶时间,建立一个基于新的路径相关不确定性集的鲁棒优化模型。然而,已有文献在动态车辆路径优化问题的模型上很少有加入多配送中心这一因素。由于目前大中型城市的物流配送系统中普遍存在多个配送中心,因此在动态车辆路径优化问题中加入多个配送中心更具有研究意义。
快速非支配排序遗传算法(NSGA-II)的应用十分广泛,但其具有种群多样性不足、容易陷入局部最优的缺点。针对其不足,许多学者提出一系列改进措施[9-11]。李燕等[12]为了提高NSGA-II算法的收敛性和搜索范围,提出一种改进的NSGA-II算法。吴暖等[13]在NSGA-II算法中引入非劣解进行局部搜索,提高了算法的搜索效率。
基于已有研究,本文以运输成本最小化、碳排放成本最小化和客户满意度最大化为目标,建立考虑多配送中心的多目标动态车辆路径优化模型,并针对动态变化采用两阶段求解策略;为求解该模型,设计一种改进的自适应非支配排序遗传算法,最后通过实验对其进行验证与分析。
1 考虑多配送中心的多目标动态车辆路径优化模型构建
1.1问题描述
考虑多配送中心的多目标动态车辆路径优化问题可以描述为:存在多个配送中心,每个配送中心都配有相应的车辆,为了按时按量完成配送服务,在不超过配送车辆最大载货量的条件下,以车辆运输成本最小化、碳排放成本最小化以及客户满意度最大化为目标,根据配送途中可能出现的信息变化动态调整配送路线。
问题假设:(1)只能用一辆任一配送中心的车辆为客户完成配送;(2)已知配送中心坐标和客户需求点的坐标、需求量和时间窗;(3)配送中心的车辆数量足够多且车型统一;(4)车辆从配送中心驶出,配送完成后选择返回到距离较近的配送中心;(5)车辆的行驶速度全程保持不变;(6)当车载货物配送完或即将配送完,无法为下一客户配送货物时,每个车辆都可以在途经的多个配送中心进行补充货物,继续为下一客户完成配送。
1.2 数学模型
1.2.1 第一阶段初始配送模型
目标函数除了运输成本z1(固定成本和运输距离产生的成本)最小以外,还有碳排放成本z2最小和客户满意度F最大。用Q表示车辆最大载货量,用X表示车辆载货量,用ρ*表示车辆满载时单位距离燃料消耗量,用ρ0表示车辆空载时单位距离燃料消耗量,则
(1)
若车辆从客户i运送xij单位的货物到客户j,则产生的碳排放成本为
e(xij)=c0e0ρ(xij)dij
(2)
其中:dij含义为客户i到客户j的距离;c0含义为单位碳排放费用;e0含义为二氧化碳排放系数;ρ(xij)含义为单位距离燃料消耗量。
式(4)表示客户i的满意度函数,F表示将所有客户满意度的平均值定义为平均客户满意度,如式(3)所示
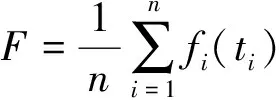
(3)
其中
(4)
ei、li分别表示客户i满意的最早配送时间和最晚配送时间,e′i、l′i分别表示客户i可以接受的最早配送时间和最晚配送时间(其中e′i≤ei≤li≤l′i) 。
符号说明:
(1)集合
M=[1,2,…,Kh]为配送车辆的集合,每个配送中心具备Kh(h=1,2,…H)辆配送车;N=[1,2,…,n]为需要服务的客户数的集合,有n个客户;H=[n+1,n+2,…,n+H]为配送中心数量的集合,有H个配送中心。
(2)参数
Qk为配送车辆的容量,k∈{1,2,…Kh},h∈{n+1,n+2,…n+H};dij为客户i与客户j之间的欧式距离,其中dij=dji,i,j∈(1,2,…n,n+1,n+2,…n+H),dij=∞时,其含义为禁止从配送中心到配送中心或客户i与客户j之间的交通发生中断;ck为第k辆车的单位运输成本,比如燃料成本、司机雇佣工资等,k∈{1,2,…Kh},h∈{n+1,n+2,…n+H};Gk为第k辆车的固定成本,k∈{1,2,…Kh},h∈{n+1,n+2,…n+H};ti为客户i得到服务的时间。
(3)变量
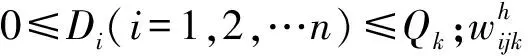
第一阶段初始配送模型为
(5)
(6)
(7)
st.
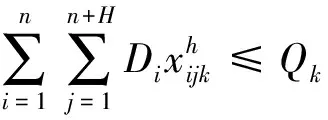
(8)
(9)
(10)
(11)

(12)
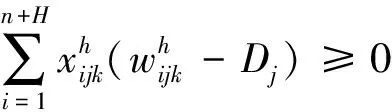
(13)
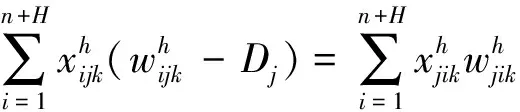
(14)
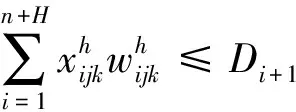
(15)
约束式(8)表示配送车辆的承载能力;约束式(9)表示配送中心具有的车辆总数应不小于该配送中心派出的车辆数;(10)和约束式(11)表示任一客户只被一辆车访问;约束式(12)表示从配送中心出发的车辆载货量为车辆的容量,它是约束式(13)、约束式(14)及约束式(15)的前提条件;约束式(13)表示车辆的运输量不低于任一客户的需求量;约束式(14)表示车辆通过客户点j后,其运输量发生变化的关系式;约束式(15)表示车辆进入配送中心补货的条件,即现有运输量无法满足下一客户的需求时。
1.2.2 第二阶段实时优化模型
在第一阶段初始配送阶段中,配送车辆为部分客户完成了配送服务,且处于客户点位置,因此,第二阶段将无法进行直接调度。在动态事件发生后,第二阶段需要及时更新道路交通情况、客户所在位置及需求量、配送时间窗、车辆状态等信息。本文将车辆所在的客户点设为虚拟配送中心,第一阶段未完成配送的客户与第二阶段新增客户的总数量记为S,若Rh表示第一阶段派出的车辆数,Qhz(h=1,2,…H,z=1,2,…Rh)表示派出车辆的剩余载货量,则用Rh表示虚拟配送中心数量,虚拟配送中心编号为S+H+1,S+H+2,…S+H+Rh,原配送中心编号为S+1,S+2,…S+H,新派车辆Th(k=Rh+1,Rh+2,…Rh+Th)辆。第二阶段实时优化模型为


(16)
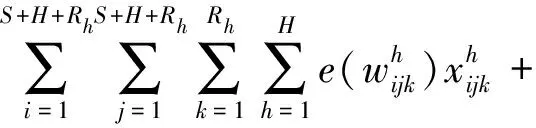
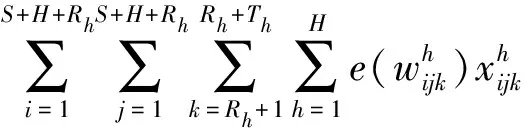
(17)
(18)
st.

(19)
(20)
(21)
(22)
h∈{S+1,S+2,…,S+H+Rh}
k∈{1,2,…Rh,Rh+1,Rh+2,…Rh+Th}
(23)
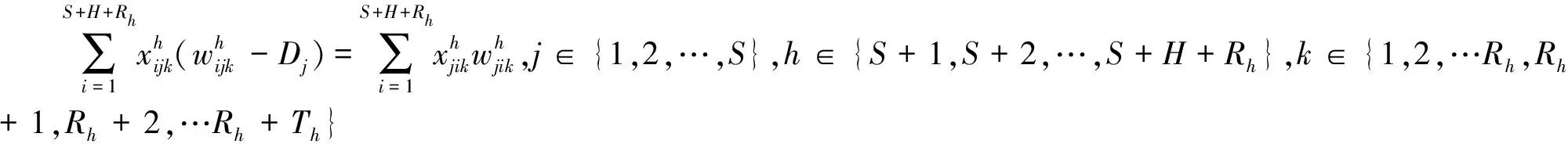
(24)
h∈{S+1,S+2,…,S+H+Rh}
k∈{1,2,…Rh,Rh+1,Rh+2,…Rh+Th}
(25)
式(16)包括3部分:第一部分是第一阶段派出的车辆对第一阶段未完成配送的客户和第二阶段新增加的客户消耗的运输成本;第二部分是第二阶段新派出车辆产生的运输成本;第三部分是第二阶段新派出车辆的固定成本。式(17)包括两部分:第一部分是第一阶段派出车辆对第一阶段未完成配送的客户和第二阶段新增客户产生的碳排放成本;第二部分是第二阶段新派出车辆产生的碳排放成本;式(18)表示的是第一阶段未完成配送的客户和第二阶段新客户的平均客户满意度。约束式(19)表示配送车辆容量的限制;约束式(20)和(21)含义为每个客户只有一辆车为其配送;约束式(22)表示从配送中心新派出车辆的运输量为车辆的容量,它是约束式(23)、约束式(24)及约束式(25)的初始条件;约束式(23)表示配送任一客户之前,车辆的运输量不低于这个客户的需求量;约束式(24)表示配送车辆经过客户点j后运输量发生改变的关系式;约束式(25)表示车辆进入配送中心补货的条件,即下一客户的需求大于车辆的载货量。
2 改进的自适应非支配排序遗传算法设计
2.1 问题的求解策略
对于前文建立的考虑多配送中心的多目标动态车辆路径优化模型,采用两阶段求解策略对其求解,如图1所示。
2.2 改进的自适应非支配排序遗传算法
本文设计改进的自适应非支配排序遗传算法(IANSGA-II)对模型求解。在初始配送阶段,配送方案采用IANSGA-II算法求得;由于配送过程中可能出现原有客户需求变化、新增客户点以及交通中断等情况,在一定程度上会影响初始方案,故采用动态添加和优化策略,对所有已规划子路径中尚未服务的客户和新增客户进行整合,重新进行线路优化。算法流程如图 2 所示。
算法改进方式:
(1)自适应交叉和变异操作:交叉操作采用正态分布交叉算子( normal distribution crossover,NDX)[14]。变异操作是采用交换变异,即互换不同基因位上的数值,互换后产生新的个体。为了使算法搜索能力更强,设计一种自适应的交叉概率和变异概率。如果种群个体的适应度值相差较大,则增加交叉概率。如果种群个体的适应度值都是良好的,则在成熟状态下减少交叉和变异概率。交叉和变异概率的取值如公式(26)和(27)所示。
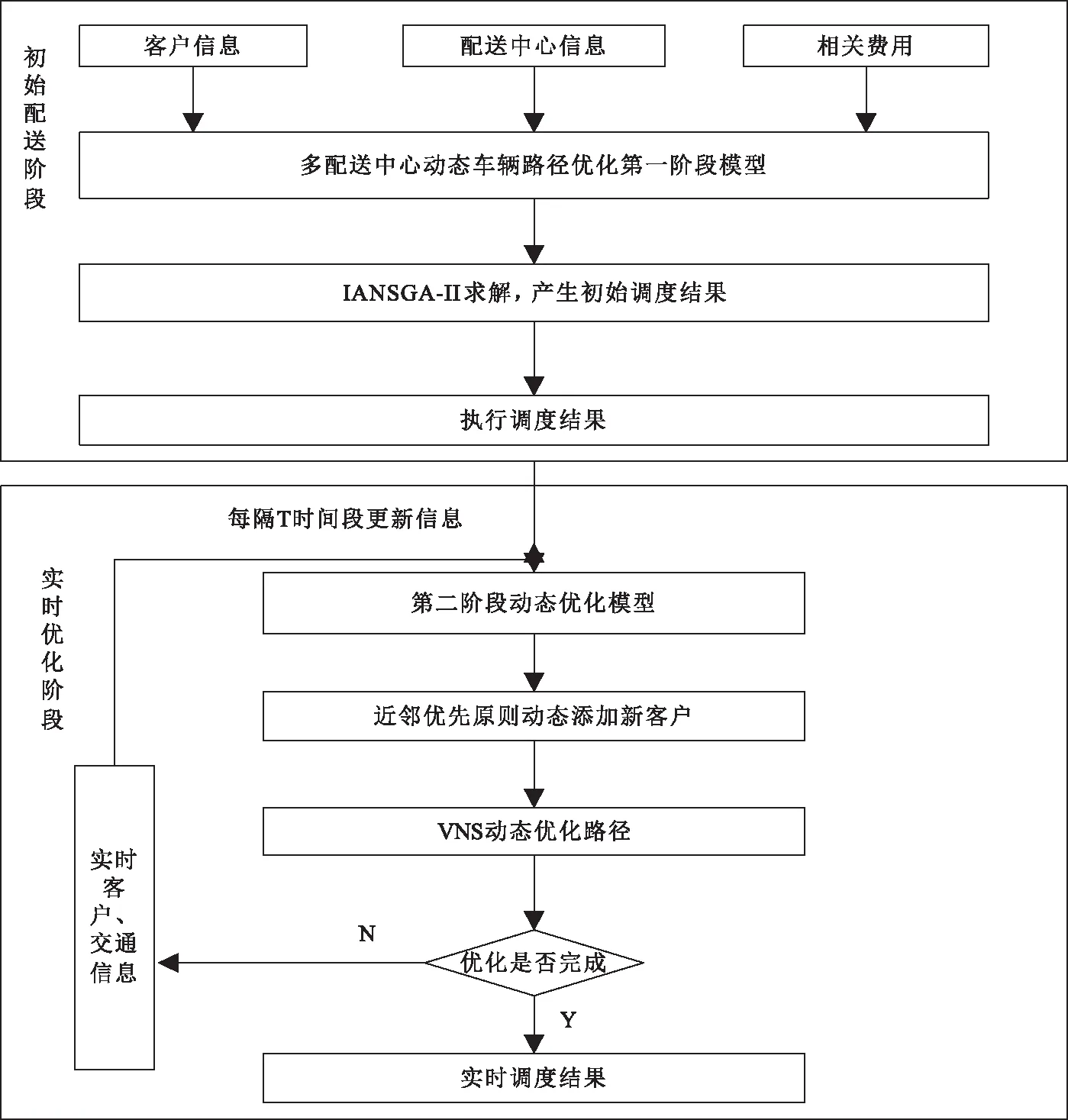
图1 两阶段求解策略流程图
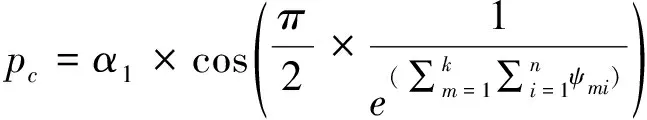
(26)
(27)

(28)
(2)选择算子 :为了维持种群多样性,选择操作采用平均距离聚类的选择算子[15]。设种群P的规模大小为n,小种群中个体数量记为ξ,第i个目标函数的最大值和最小值分别记为fj,max和fj,min,则其第j个目标函数的平均距离为
(29)
若个体j与i在同一个小种群内,则个体j应满足
fi,min≤fj≤fi,max
(30)
fi,min=((f1+f1,avg),(f2+f2,avg),…,(fλ+fλ,avg))
(31)
fi,max=((f1+f1,avg),(f2+f2,avg),…,(fλ+fλ,avg))
(32)
fi,max和fi,min的含义分别为i小种群中全部个体目标函数的最大值和最小值,λ为目标函数的个数。

图2 IANSGA-II算法流程图
(3)动态添加和优化策略:在动态添加策略中,按照近邻优先原则,将新客户添加到距离新客户最近的路线中。若新客户的需求大于车辆容量,则将新客户加入新的服务队列中,并派出其他车辆来处理,最后形成一条额外的路线。对于加入新客户的初始路线,需要对其进行重新优化。每条新路线包括两条子路线,一条是己经完成服务且不需要改变的路线,另外一条路径则需要采用变邻域搜索算法(VNS)进行优化。本文采用Lei H等[14]设计的3种邻域结构进行局部搜索,分别是Inter Route Insertion Inter Route Swap和Inter Route 2-Opt。
3 实验设计及分析
3.1 实验设计
为了验证模型及IANSGA-II算法的有效性,本文以某物流企业为例,该企业具有4个配送中心,每个配送中心各自拥有10辆同质且载重量为5的配送车。在配送开始前,该企业接收到来自所在城市不同位置的30个客户的配送订单。4个配送中心以及30个客户的信息如表1所示,其中配送中心的编号为1至4。根据对物流公司实际运输费用的调研和文献[7],模型中的相关参数值如表2所示。
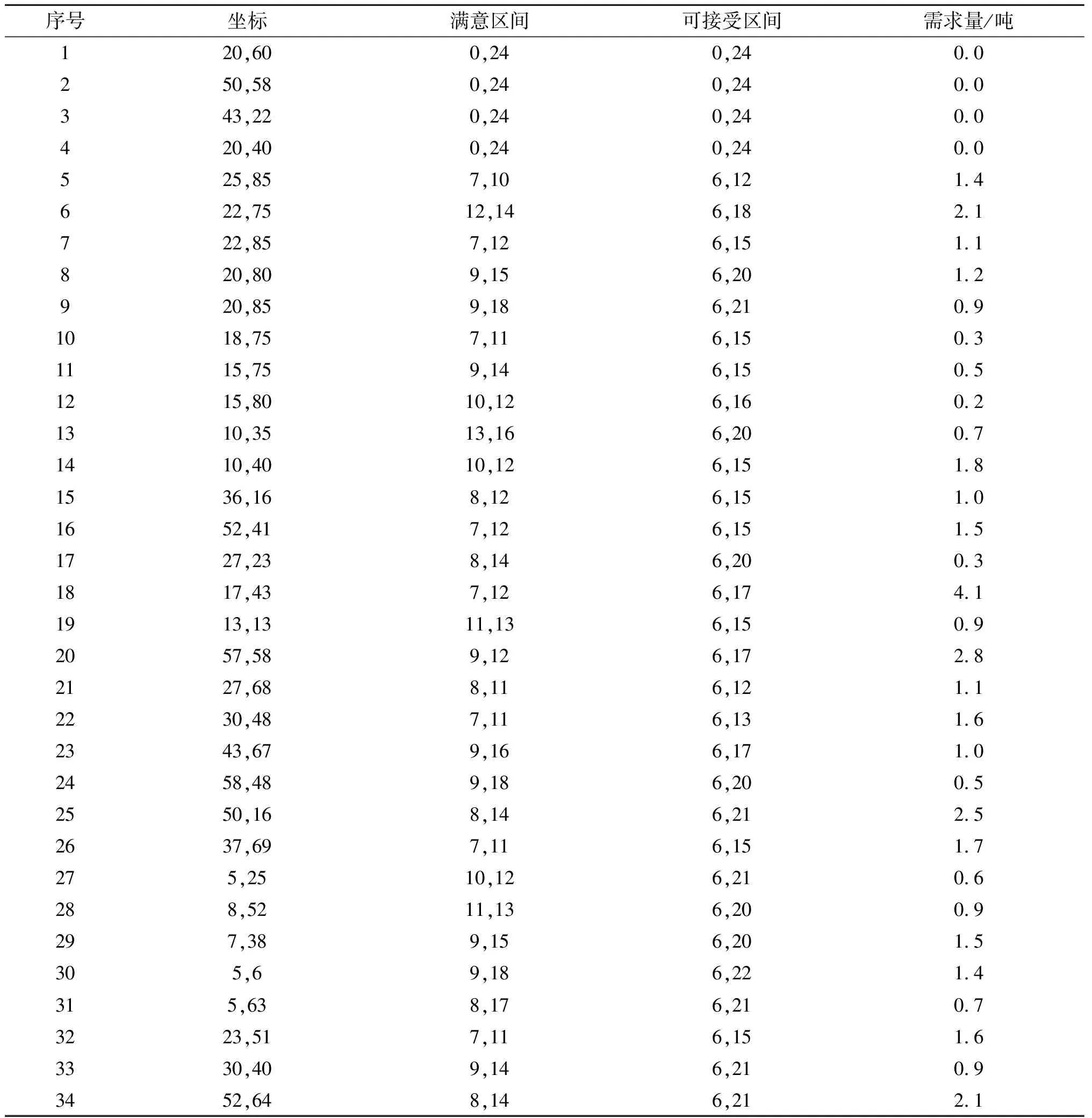
表1 初始客户及配送中心信息

表2 模型相关参数信息
3.2 实验求解与结果分析
程序使用Matlab R2016b编写,并在Intel(R) Core(TM) i5-7200U CPU 2.50 GHz的DELL 笔记本电脑(4核,8 GB内存) 上运行。本文用前文实验算例进行算法分析。在初始配送阶段采用INSGA-II算法,种群大小为100,最大迭代次数为100,独立运行50次,得到Pareto解集如图3所示。分别选取3个目标最优时的初始配送路线,如表3所列。
在t等于10时刻,发生如下的动态事件:客户需求点3和7分别增加需求0.4 t和0.2 t;客户需
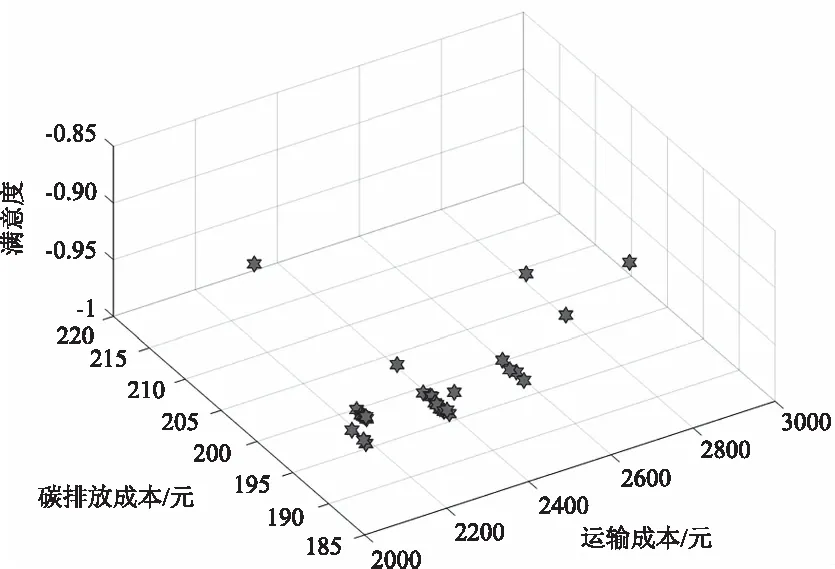
图3 初始配送Pareto最优解集
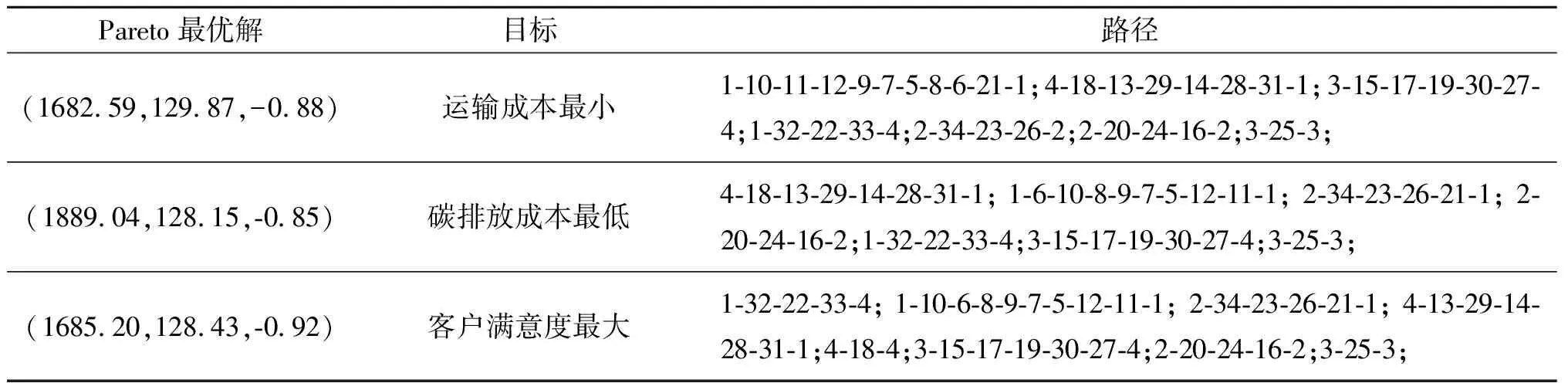
表3 初始配送路线
求点9和14分别减少需求0.2 t和0.3 t;客户需求点8和17的满意区间和可接受区间分别发生更改;客户需求点28和31之间的道路交通发生中断;同时有5个新客户提出配送请求,其客户信息如表4所示。实时优化阶段得到的Pareto解集如图4所示,最优路线如表5所示。
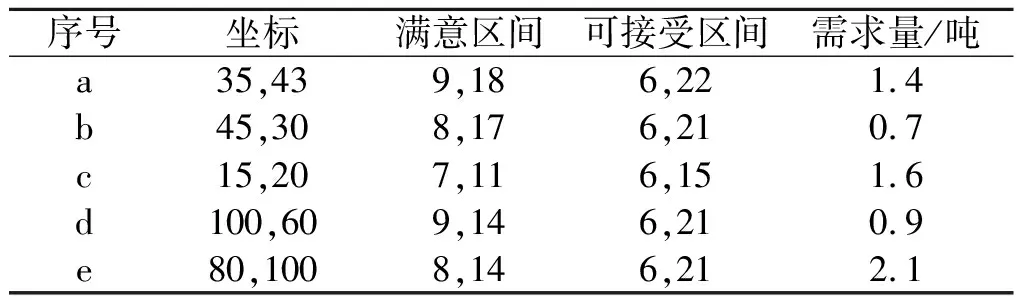
表4 客户变化信息
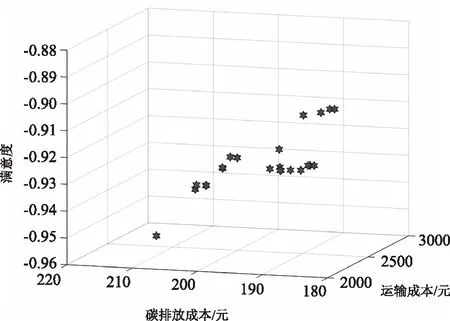
图4 实时优化 Pareto最优解集

表5 实时优化路线
为了验证本文提出的IANSGA-II算法的有效性,在初始配送阶段将NSGA-II算法、IANSGA-II算法、MOPSO算法在不同迭代次数下的评价解集分布性的超体积指标(HV,Hypervolume)[16]以及运行时间进行比较。实验中将3种算法在不同迭代次数下独立运行50次,计算指标的平均值,如表6和表7所示。
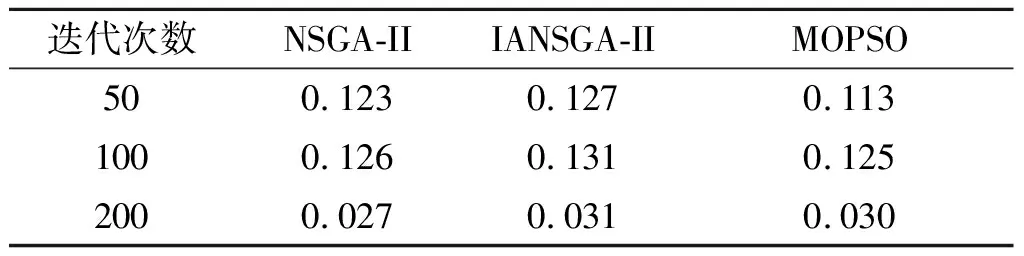
表6 超体积指标HV对比
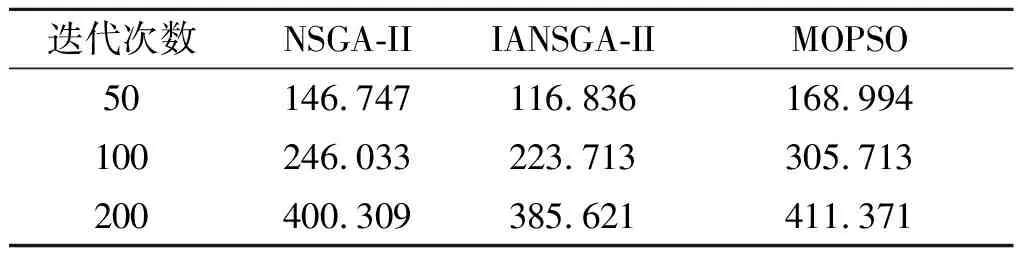
表7 算法运行时间对比(单位:s)
从表6可以看出, IANSGA-II的HV基本高于NSGA-II和MOPSO,表明IANSGA-II得到的Pareto解集可以较好地收敛到理想的Pareto前沿,并且具有更好的解集多样性,说明本文引入的平均距离聚类的选择算子能够较好地保证种群的多样性。此外,从表7可以看出,IANSGA-II在不同迭代次数下,运行时间均明显比NSGA-II和MOPSO较短,也进一步说明本文引入的自适应交叉和变异概率可以较好地加快种群寻优速度以及算法的全局搜索能力。
4 结语
本文针对动态车辆路径优化问题,结合多配送中心及多种动态因素,构建了以运输成本最小化、碳排放成本最小化以及客户满意度最大化为目标的优化模型,该模型更贴近物流配送活动的实际以及满足生态文明建设和生态环境综合治理的内在需求;针对该模型,提出了两阶段求解策略,并提出了改进的自适应NSGA-II算法;通过实验验证,表明该算法能够有效求解多配送中心动态车辆路径优化模型,并且算法性能更优。
未来研究中将考虑不同车型、车辆行驶速度等因素的影响,使问题更贴近实际配送的场景,并改进出更加有效的求解算法。
猜你喜欢
今日农业(2022年15期)2022-09-20
卫星应用(2022年7期)2022-09-05
卫星应用(2022年3期)2022-05-23
卫星应用(2022年1期)2022-03-09
环球慈善(2019年6期)2019-09-25
中学生物学(2018年8期)2018-03-01
小学阅读指南·低年级版(2017年1期)2017-03-13
人生十六七(2015年6期)2015-02-28
计算机辅助工程(2012年5期)2012-11-21
中学生物学(2008年6期)2008-08-29
