
社交媒体类企业数据资产评估探究
——以新浪微博为例
2022-10-21 02:22袁林昊刘春学徐雪莲白彧颖
中国资产评估 2022年6期
■ 袁林昊 刘春学 徐雪莲 白彧颖
(云南财经大学城市与环境学院,云南昆明 650221)
数据通过简便的方法在短时间内获得了快速增长,2013年全球大数据的储量仅为4.3ZB,到了2019年其储量就已经达到了40ZB以上。数据已经成为继土地、劳动、资本、技术、知识以及管理之后的新生产要素。数据资产被充分利用时可以创造大量的利润,但并非所有的数据都能成为数据资产。数据资源能否成为数据资产需要结合其属性进行界定,对于数据资产的界定、性质、特征和价值创造等方面,不同的机构和学者有不同的观点。企业在对能够带来经济利益的集合数据进行整理、清洗、分析和可视化分析之后,数字信息就成为了数据资产,并对数据资产如何计量的问题进行了探讨(李永红和张淑雯,2018)。针对数据资产的不同特点,论证了多种数据资产评估方法,诸如期权模型与传统的评估方法结合、市场法、多期超额收益法等(刘琦等,2016;李虹和鲍金见,2020;陈芳和余谦,2021)。然而截止到目前,对数据资产的界定与价值评估仍就处于起步阶段,对于数据资产的评估方法国际上也没有统一的方法体系。
对于社交媒体类企业而言,用户资源是数据资产价值的核心来源,但传统评估方法及其局限性难以合理评估并全面均衡数据资产价值。因此,本文运用DEVA模型并合理引入用户活跃度、市场占有率、用户变动率等进行修正评估企业价值,最后通过AHP层次分析法剥离数据资产比例,为企业的数据资产价值评估提供参考。
一、社交媒体类数据资产价值分析
对于社交媒体类企业而言,其数据资产价值体现在数据的变现,可以概括为企业内部收益增加和外界合作实现价值变现互赢,这与其用户行为有紧密的联系。
对于企业内部而言,营销收入和产品的变现是数据资产的主要来源。社交媒体类企业通过对收集到的用户数据信息进行分析从而了解到用户的偏好及行为模式,并根据这些信息对产品进行调整以更好的契合市场需求并增加营销收入。同时,用户的信息可以通过支付平台、电商平台和游戏平台等服务进行高效利用和数据互通以实现相关业务的增值。
对于企业外部而言,数据资产主要来源于数据的跨界共享变现。不同的企业之间的数据资产通过网络进行共享,从而实现互利共赢,但我国法律目前对相关用户的隐私保护规定,导致我国数据资产交易的相关案例较少。
(一)数据资产价值特点
非实体性。数据资产具有无形资产的某些特征,与有形资产相比,不存在实体形态,具有非实体性。
业务附着性。社交媒体类企业在日常经营中需要处理冗杂的用户数据,这些附着的数据资源在加工之后形成数据资产。
再生性。数据资产具有非消耗性,在经过一段时间之后仍有使用价值,这是其与实物资产的主要区别。在用户产生数据后,这些数据资源不会被消耗掉,并且还会产生更多的数据资源并通过不断积累以达到最大值。需求越大,这类数据的价值就越大。
体量大。社交媒体用户不管是点击链接还是发布动态,都伴随着大量数据的产生。用户自身的复杂性和用户结构的多层次性都随着数据规模的增加从而丰富了数据资产的多样性。
除此之外,数据资产目前还具有权属不明晰以及价值易变难以衡量等特性,但是未来在建立起完整的数据资产评估体系之后,这些问题亦能迎刃而解。
(二)数据资产的价值影响因素
数据规模质量。少量数据通常情况下难以加以利用,只有对大量的数据进行分析才有价值规律可循。大量的用户能产生高规模的数据量,数据规模越大,数据的质量也会更有真实性和参考价值。
数据的关联程度。由于孤立的数据不能与其他数据产生网络连接,根据梅特卡夫的观点其也就没有价值节点,不能给企业带来价值。因此,社交媒体类企业应该加强不同部门和不同业务之间的关联性,使数据之间保持强的关联度,数据资产的价值也就越大。
数据的更新频率和时效性。数据的频率更新越快,其蕴含的信息也就越丰富。其一般表现为用户的活跃程度,如用户的在线时长、上网频率、浏览爱好等,活跃程度越高,其价值也越高。而时效性的影响主要体现在有限的时间之内对企业的投资决策能够有效,比如随着用户人群和时间流动的不断更替,对过去时点的数据分析可能并不适用于当前的信息决策。
处理数据的能力。无论是数据的获取还是数据开发及应用都依赖于企业庞大的数据储存和分析处理系统。更先进的信息处理分析能力和更快的处理周期不但能够减少成本,还直接影响数据资产的准确利用。
二、数据资产评估模型修正
一般认为,数据资产是指由特定主体合法拥有或者控制,能持续发挥作用并且能带来直接或者间接经济利益的数据资源。
早些时候,成本法和市场法因其在成本核算和交易案例方面的困难,一般不用于数据资产评估。收益法中的超额收益法、增量收益法、有无对比法和许可费节省法等模型都较适用于评估数据资产,特别是多期超额收益法被广泛应用于数据资产价值评估。
(一)梅特卡夫定律与传统DEVA模型
梅特卡夫定律一般用于互联网企业价值评估。该定律认为节点间的网络连接可以创造价值,即网络的价值是可以通过节点数计算所得到,其与网络中的用户数量的平方呈正相关关系。
DEVA估值模型以梅特卡夫定律为基础,广泛应用于互联网企业的估值。其数学模型如下:
V=M×C2
式中M为单位用户初始投资成本,C为单位时间用户创造价值。
DEVA模型侧重于用户的创造价值和初始投资成本,这就避免了因为会计和财务报表问题导致的估值问题,且初创企业的历史数据和可参考的指标不足,现金流不稳定的问题也能够解决。
(二)DEVA模型的修正
1.DEVA模型的修正思路
考虑到活跃用户的占比以及在大数据时代下社交媒体类企业的用户规模以及增长率导致的简单函数关系不再使用的问题,为了反映社交媒体类企业的真实价值,需要对DEVA模型进行一定的修正。
DEVA传统模型在考虑企业价值影响因素时仅从用户角度进行考虑,未能全面考虑影响企业价值的核心因素。只有活跃用户数能给企业带来价值,而非活跃用户不会带来任何收益。由于边际贡献递减,新用户在达到一定规模之后带给网络的价值在下降,因此也需要用新函数对其表达式进行改进。而黏度系数能反映用户对于该公司产品的忠诚程度,活跃用户数目的变动则会对企业价值产生影响。对于一家互联网类型的社交媒体类企业而言,由于马太效应的存在,用户会选择规模更大、流行程度更高的产品,因此行业龙头往往会获得更多的用户,因此市场占有率也是需要调整的因素。上述修正的思路在对DEVA模型修正时应当被考虑到。
2.对公式(用户价值与企业价值关系)的修正
由前文提到的,需要对式中的平方关系进行修正。原理来源于齐普夫提出的词频分布定律,将互联网企业的n个用户按照其贡献进行排序,第一名为1,第二名为第一名的1/2也就是1/2,第三名为第一名的1/3也就是1/3,那么以此类推,第n名为第一名的1/n也就是1/n,那么对他们的贡献求和,也就是对于发散级数1/n的求和,当n很大时,参考欧拉公式:其中γ是欧拉常数,γ≈0.5772,近似看作由于对于网络里的每一个用户都贡献了ln(n),那么其他n-1个用户都能够贡献ln(n),因此n个用户的组合对企业的价值之和可写为故DEVA公式调整为:
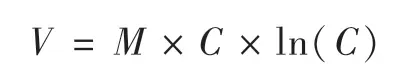
3.对活跃用户数的修正
前文中提到,只有活跃用户才能对企业的价值产生影响。因此这里引入月活跃用户数(MAU)和单用户贡献价值(ARPU)两个指标。
关于活跃用户,腾讯微信对活跃用户的定义是:至少一次通过微信发出一条或以上信息,或在微信进行其他主动操作(如登录游戏中心或更新朋友圈)的用户账号。新浪微博对于活跃用户的定义是在一个月之内多端口登录过新浪微博客户端。活跃用户数的指标有年平均活跃用户数(YAU)、月平均用户数(MAU)和日平均用户数(DAU)。国内互联网行业的相关报告中用的最多的指标是MAU,因为MAU相较于DAU更加稳定,不会因为某一两天的特殊事件而剧烈波动,且MAU相较于YAU数据更容易获取,因此本文使用MAU指标。
对于单用户贡献价值的确定,选用互联网行业的常用指标ARPU。ARPU是指单个用户在单位时间内为企业创造的单位平均价值,其是单用户对企业收入贡献的指标。
由上,通过对DEVA估值模型中的所有目标用户的价值进行修正之后,将C替换为MAU×ARPU,就得到了单位时间内用户创造的平均价值,即此模型的计算公式变为:

4.对黏度系数K修正
正常组小鼠肺组织肺泡结构完整、肺泡腔内无异物、肺泡隔薄、支气管正常、无出血点、无炎症细胞浸润。气管注射LPS 6 h后,可见小鼠肺组织肺泡结构紊乱、大量肺泡塌陷、肺泡腔内可见着染成红色的富含蛋白的水肿液、肺泡隔增厚、可见气道上皮细胞脱落、大量血管充血和出血点。给予TPPU预处理(1 mg/kg)组可见上述肺内病理改变显著减轻(图1),提示TPPU可减轻LPS诱导的小鼠ALI的肺内病理改变。
传统的DEVA模型没有体现出用户的黏性,用户黏性是用户对于品牌产品的忠诚依赖程度。黏度系数越大,代表每日的使用频次在增加,对于平台的依赖程度也在不断攀升,再消费的可能性也就更高。因此引入黏度系数K调整后的公式为:
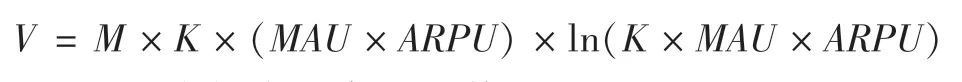
5.对市场占有率L的修正
随着互联网电商企业竞争进入白热化阶段,互联网企业的明显特点是由于马太效应的影响头部占有更大的市场份额,行业的资源会更多的向行业龙头倾斜,企业价值也就更大,即强者更强,弱者更弱。因此这里引入市场占有规模率L。调整后的公式为:
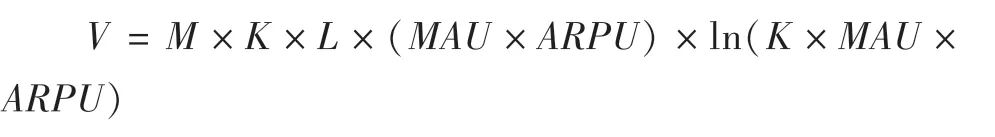
6.对用户变动率i的修正
本次调整还考虑了企业市场份额的未来趋势。由于同行业间的竞争较为激烈,若企业市场份额能够在未来将有大幅度提升,用户数目的增加会对企业价值将会有正向影响,特别是以用户为核心的社交媒体类企业,不能仅仅局限于当时时点的用户数,应当考虑在未来变动的情况下的影响。因此引入用户的变动率i,调整后的公式为:

(三)层次分析法
层次分析法(AHP:Analytic Hierarchy Process )可以定量地表达和处理人的主观判断,并形成相对客观的判断标准,将整体的价值分解成若干个影响因素,通过两两比较各要素的权重并将影响因素中与数字资产价值相关的因素相加,得到数据资产价值的参与率。具体步骤为:

表1 模型参数说明
第二,根据层次和元素之间的关系,构造由某一元素与相邻下一层次有联系的所有元素的比较判断矩阵。

表2 比较判断矩阵
判断矩阵元素按一定比例标度两两比较得到,标度含义见表3。

表3 层次分析法的重要性标度
以上判断是一种对经验和对问题认识程度的主观反映。
第三,根据得到的判断矩阵,运用数学运算得出各因素的权重ωi。
第四,进行一致性检验。有时候会出现自相矛盾的比较结果,这是由于计算之中反复进行因素与因素间的两两重要性比较。因此为了避免不合逻辑的情况,通过特征值法计算出权重后,需要对判断矩阵进行一致性检验,通过计算的CI及CR值,判断结果能否直接使用。

表4 判断矩阵随机一致性指标RI
其中CI为一致性指标,RI为随机一致性指标,CR是一致性比率。
根据公式,计算出总排序一致性比率CR,若CR<0.1,则说明矩阵通过了一次性检验,如果CR>0.1,就需检查原因,调整A后再重新计算,直到通过一致性检验。最终,若判断矩阵通过了一次性检验,则取前面的结果ωi,得到各个因素的权重数值。
三、案例介绍
微博股份有限公司(简称“新浪微博”或者“微博”)为新浪集团控股有限公司控股的子公司,是一家专门提供微型博客服务的企业。用户可以通过网页、WAP页面、手机客户端发布消息或上传图片。2014年其在纳斯达克(NASDAQ)上市,是首家上市的中文社交媒体企业。
(一)新浪微博盈利模式
1.广告及营销收入。新浪微博的广告收入主要由活跃客户、中小企业投放的广告收入以及关联方阿里巴巴的广告收入两大部分组成。由图1可以看出,新浪微博的广告收入均在85%之上。

图1 新浪微博收入构成(亿美元)
2.电商业务。阿里巴巴作为新浪微博的第二大股东,一直和新浪微博有着密切的战略合作关系。通过业务的结合,用户可以在新浪微博上访问淘宝商户界面,淘宝的卖家店铺花钱在新浪微博的热搜榜上做广告宣传,这为双方带来了大量的访问量,同时也获取了大批量优质的广告主资源,实现了价值的变现。
3.其它收入。游戏相关收入,游戏玩家购买的虚拟货币。通过API通道的开放,新浪微博与包括游戏开发商在内的平台合作伙伴签定有收入分享协议。VIP会员费,包括每月签订和每年签订的会员费,为会员提供某些特权,享受增值服务。数据授权服务,由于他人向平台获取数据而收取的费用。
从上述的盈利模式来看,新浪微博的业务核心都离不开其海量的注册用户,用户便是新浪微博最核心的数据。
(二)新浪微博数据资产
社交流量具有量大、时长以及黏性高的特点,由于市场具有马太效应,一旦壁垒形成,新进入者会难以撬动行业龙头的地位。前文提到活跃用户的价值影响企业价值,因此以活跃用户为出发点深入探究,分析界定新浪微博的数据资产。
1.活跃用户信息。用户在注册账号第一次登陆时会被要求填写相应的信息进行实名制注册,或者通过已经实名制注册的第三方平台等进行登陆。其中活跃用户的信息,例如年龄,职业,地区,爱好等都被新浪微博进行划分,新浪微博会以此建立对应的标签来对用户进行推送,用户信息便是此推送的基础。
2.用户行为痕迹。新浪微博的用户的浏览、互动、消费行为会被记录到后台的数据库从而决定了这背后账户的价值。同时,新浪微博的热搜榜会根据点击量给对应的热点内容和新闻进行排名评定。广告商投放的广告也会出现在热搜榜之中,他们会选择具有更高活跃度和号召力的账号进行宣传,关注该类账号的用户一般都有相似的爱好,这也提高广告的投放效果。
3.用户社交关系。与其他的即时通讯软件不同,新浪微博的最大优势就是建立了自由的社交网络。新浪微博的用户关系是基于其爱好所划分,只需单方面关注对方之后就能进行互动,互动群体有可能具有相同的消费水平和倾向,能对特定的人群产生消费影响。另外,线上运营和社交关系的背书也为营销降低成本和快速生效提供了有力保障,新浪微博的这一天然优势使得品牌方更喜欢在新浪微博上做推广。
新浪微博存在着“用户流量→数据资产→利用→公司收益→企业价值”的价值转化逻辑,但需要注意企业价值并非只由数据资产构成。有着丰富数据资产的新浪微博,用户数据在其中发挥着至关重要的作用,因此选取新浪微博作为本次评估的案例。
(三)评估过程
本次评估对象是新浪微博的数据资产价值,评估范围是新浪微博资产中涉及所有社交网络用户的价值,评估基准日为2020年12月31日,基本假设为:(1)公开市场假设;(2)持续经营假设;(3)交易假设,基本方法为基于梅特卡夫定律的调整后的DEVA模型与层次分析法。
由于梅特卡夫定律以及DEVA模型适用于以用户作为核心价值的互联网企业价值的评估,因此该方法适用于新浪微博企业价值评估。
1.DEVA模型参数确定
(1)月活跃用户数(MAU)。MAU为月活跃用户数,即使用唯一新浪微博账号登录并访问的新浪微博用户。由于本次评估基准日为2020年12月31日,因此选择2020年12月的MAU作为指标计算,以求评估值更准确, 2020年12月的MAU为5.21亿。
(2)单位用户投资成本(M)。单位用户投资成本等于企业初始投资成本与平均月活跃用户数的比值。这里将新浪微博在2014年4月刚上市时的融资总额作为新浪微博的初始投资成本,根据新浪微博发布的招股说明书和wind终端数据查询,得到首次融资额为2.86亿美元。MAU5.21亿人,评估基准日实时汇率为1∶6.5265,因此新浪微博的单用户初始投资成本M为3.58元/人。
(3)用户黏度(K)。目前采用的用户黏性系数主要有两种计算方法K=DAU/MAU:一种计算方法为,另一种为K=MAU/平台平均活跃用户。由于新浪微博公布了12月的平均DAU与12月的MAU,因此选取第一个方法,K取2.25/5.21=43.19%
(4)单位用户贡献值(ARPU)。ARPU的计算方法为营业收入/平均活跃用户,平均月活跃用户数目取期初月活跃用户与期末月活跃用户的平均值,期初月活跃用户取2019年12月的MAU,期末月活跃用户取2020年12月的MAU来源于新浪微博的财务报表,新浪微博12月份的ARPU约为21.25元。
(5)市场占有率(L)。如前文提到的,随着互联网的不断发展,马太效应更加突出。基于这种特点,头部企业会获得更高的估值,而新型的企业则很难抢夺资源,难以生存下去。本文选择评估的对象新浪微博是我国社交媒体行业的龙头企业之一,与腾讯的微信、QQ这类即时强社交型的通讯软件不同,轻社交型的新浪微博本身就是国内微型博客领域的行业龙头。同为社交媒体类的公司,腾讯与新浪微博两种类型对应的市场以及受众人群并没有必然的抢占与冲突关系,因此可以将新浪微博的市场占有率看作100%。
(6)用户变动率(i)。由图2可以看出,新浪微博的月活跃人数增长率逐渐下跌,通过计算得到2020年12月的MAU变化率为0.97%,因此本次取i=0.97%。
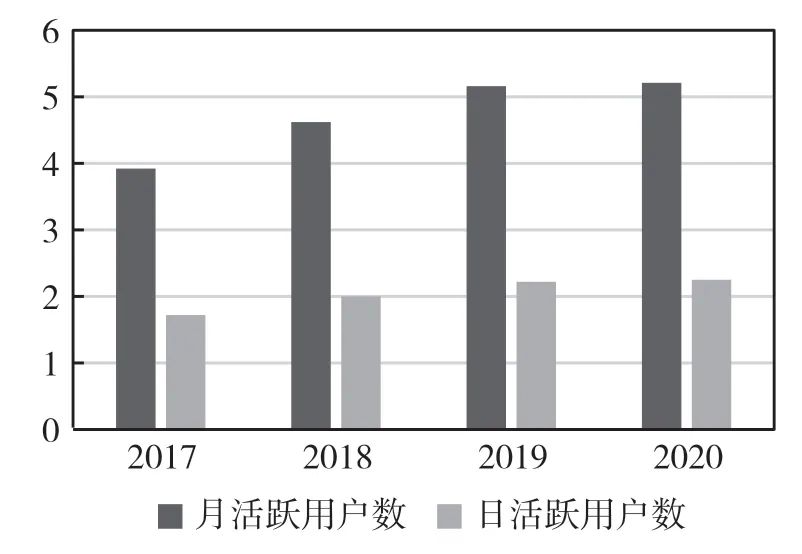
图2 新浪微博近年月活跃用户数(亿人)和变化率(%)
将上述指标代入调整后的DEVA模型式中,得:

通过修正调整后的梅特卡夫DEVA模型,得到新浪微博在2020年12月31日的价值为670.12亿人民币。评估基准日新浪微博(WO.O)的市值为605亿人民币(按实时汇率折算),与本次的估值相差57.03亿,误差为0.76%,存在一定差距,这是因为:①虽然国内目前的微型博客领域只有新浪微博一家,但是之前市场上还有腾讯微博(腾讯已于2020年下半年宣布关闭该业务)以及一些国外公司的产品,它们同样会占有一部分市场规模,但是新浪微博作为龙头企业,市场占有率接近100%,但是本文在计算时取值为100%;②新浪微博2020年的营收由于疫情有所下降,投资者看衰,其股价受到一定的波动也比较正常,且在2021年上半年其股价已经回暖。③在评估过程中,数据获取仅通过互联网公开数据以及企业年报,会存在一定的不准确性。因此本次评估取670.12亿人民币作为新浪微博在2020年12月31日的企业价值。
2.基于AHP层次分析法的用户数据资产分割
根据分析,由于数据资产也是企业拥有或者控制但不可确指的无形资产,且能够以协同作用的方式为企业带来预期的超额收益,因此本次评估构建以无形资产价值为目标层,且影响无形资产价值的因素主要包括收入增加、成本减少、技术创新优势、品牌市场竞争力;对这四个因素能够产生影响的因素有本文讨论的数据资产,还有人力资本、专利技术无形资产、客户网络与生态系统、战略投资与管理,即五个方案层。
利用yaahp软件建立递阶层次结构,如图3。

图3 层次分析结构
其中第一层为目标层,第二层为准则层,第三层为方案层。
根据上部分对贡献因素的分析,通过问卷的模式,邀请了十二位资产评估专家、学院教授对各要素进行了打分,对数据进行整理后处理得到比较判别矩阵。
(1)首先定义准则层对组合无形资产价值的比较判别矩阵
经过打分和数据处理后,得到比较判别矩阵A(表5),通过计算得出矩阵对应的四个特征值为4.038;0.003;-0.021;-0.021。一致性检验:CR=0.014<0.1,检验通过。

表5 比较判别矩阵A
(2)确定方案层相关元素对四个准则层的贡献
对收入增加的影响定义为判断矩阵B1(表6),经过打分和数据处理后,得到比较判别矩阵B1(表6),通过计算得出矩阵对应的五个特征值为5.156;-0.016;-0.016;-0.062;-0.062。一致性检验:CR=0.035<0.1,检验通过。

表6 比较判别矩阵B1
对于成本减少的影响定义为判断矩阵B2,经过打分和数据处理后,得到比较判别矩阵B2(表7),通过计算得出矩阵对应的五个特征值为5.275;-0.035;-0.035;-0.102;-0.102。一致性检验:CR=0.061<0.1,检验通过。

表7 比较判别矩阵B2
对于技术创新的影响定义为矩阵B3,经过打分和数据处理后,得到比较判别矩阵B3(表8),通过计算得出矩阵对应的五个特征值为5.309;-0.012;-0.012;-0.020;-0.266。一致性检验:CR=0.069<0.1,检验通过。

表8 比较判别矩阵B3
对品牌市场竞争力的影响定义为矩阵B4,经过打分和数据处理后,得到比较判别矩阵B4(表9),通过计算得出矩阵对应的五个特征值为5.207;0.038;0.038;-0.142;-0.142。一致性检验:CR=0.046<0.1,检验通过。
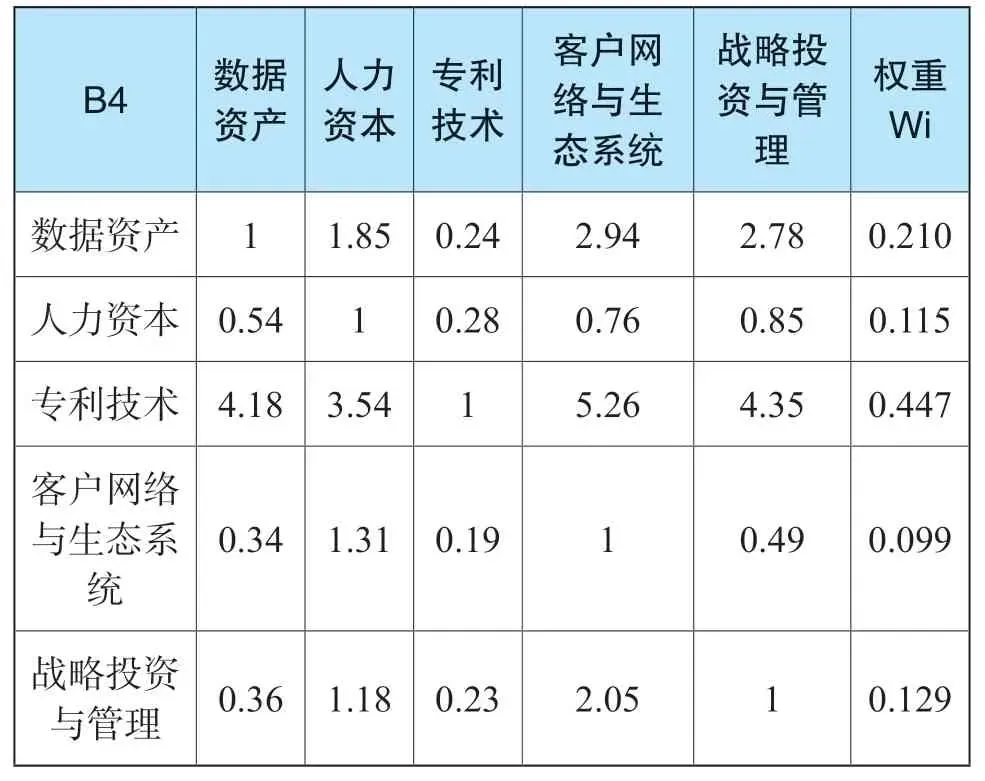
表9 比较判别矩阵B4
整理得表10如下:

表10 无形资产价值贡献率的结果汇总
3.评估结果分析
查看新浪微博2020年资产负债表公布的总资产为6 335 117万美元,即63.35亿美元,其中的有形资产(包括机器及厂房设备)占0.61亿美元,约为资产总值的0.96%。
通过参考有形资产对于企业整体价值贡献比例,可以得到企业无形资产组合价值,再计算出数据资产的结果如下:
数据资产的价值=(评估出的企业价值-有形资产账面价值)×数据资产对无形资产组合的贡献率,前文计算出的新浪微博在评估基准日的企业整体价值为670.12亿元,即新浪微博的在评估基准日的数据资产的价值为
新浪微博113.82亿元的数据资产价值对应单用户价值约为21.85元,约合3.35美元。2018年同为国内社交媒体类企业的陌陌收购探探时,探探的单用户数据源价值为7美元,新浪微博的单用户数据源价值仅为3.35美元,但是考虑到新浪微博基于用户构建的应用模式和商业模式有所不同以及微型博客类社交用户群体的消费水平差异,3.35美元的单用户价值具有一定的合理性。由此可以看出,新浪微博的数据资产确实存在着巨大的价值,这对于企业经营运作具有战略性的意义,数据资产作为企业的无形资产中的重要的一环,运用DEVA模型与层次分析法集合得到的113.82亿元的数据资产的估值结果具有一定的参考价值。
四、结论
1.随着数字经济的规模的不断增大,数据资产价值评估需求不断增加。本文以新浪微博为例,应用DEVA模型,通过AHP层次分析法剥离出社交媒体类企业的数据资产价值。从评估来看,以用户的价值为中心来评估数据资产具有可行性。
2.采用以用户为核心的改进DEVA模型,除了考虑了常见的参数外,还可以调整市场占有率以及用户变化率参数,使其更能契合社交媒体类的企业特质,能更能较好地评估其企业的整体价值,结果更为准确。
3.由于社交媒体类行业的商业模式、变现路径存在差异,其拥有的数据资产各有所不同,本文采用层次分析法构建新浪微博的无形资产组合为目标层,以影响组合无形资产的因素确立了四个准则性,以此准则层确立了五个方案层,降低了由于指标比较次数过多而造成的打分不一致的风险,以此预测数据资产的最终评估价值更具有可靠性。
猜你喜欢
读者(2021年20期)2021-09-25
海峡姐妹(2019年8期)2019-09-03
Coco薇(2017年11期)2018-01-03
读与写·教育教学版(2017年10期)2017-11-10
阅读时代(2017年3期)2017-03-11
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
环球时报(2009-09-29)2009-09-29
证券导刊(2009年23期)2009-09-02
