
基于机器学习的二次采油高耗水层识别方法研究
2022-10-21 11:29沈旭东刘慧卿张郁哲许宏亮马良宇尚雄涛
钻采工艺 2022年4期
沈旭东, 刘慧卿, 张郁哲, 许宏亮, 范 欣, 马良宇, 尚雄涛
1油气资源与探测国家重点实验室·中国石油大学(北京) 2中国石化华北油气分公司采气一厂 3中国石油集团长城钻探工程有限公司 4中国石油辽河油田安全环保技术监督中心 5中海石油(中国)有限公司天津分公司 6中国石油长庆油田分公司采油二厂
0 引言
我国油田多为陆相沉积,层间非均质性严重,长期的注水开发加剧了层间、层内矛盾进而导致部分层位注入量大、注入强度高、注入水低效循环。高耗水层的形成极大程度降低了油田的开发效益,增加了油田的开发成本。因此,高耗水层的准确识别与评价对于后续实施治理措施,挖潜剩余油以及提高油田开发效益都具有重要意义[1]。
目前,国内外学者主要通过单井压力测试[2- 8]、测井解释[9- 11]等方式进行高耗水层的识别与评价研究,忽略了注采井间的相互作用。部分学者鉴于上述不足,采用模糊数学法[12- 15]综合处理多种动、静态因素指标,取得了较为理想的结果,但指标权重选取的经验性较强,存在主观性。针对上述问题,本文基于胜利油田Z1区块的实际情况建立了数值模型,选取特征值和评价指标对层状油藏储层耗水能力进行定量表征,并建立了高耗水层的识别与评价流程。新方法从含水率及导数曲线出发,综合考虑了注采井和地层的动静态参数,提高了评价结果的客观性,同时也避免了传统试井解释等方法需进行关井测试的局限,保证了生产的持续进行。此外,通过随机森林算法,可有效降低传统图版拟合法在拟合过程中所造成的误差,提高拟合精度进而提高评价结果的准确性。该方法可有效进行层状油藏高耗水层的识别与评价从而为高耗水层的治理与生产制度的优化提供理论支持。
1 数值模型的建立与参数处理
1.1 数值模型的建立
高耗水层的形成主要受地质、流体、开发三方面因素的共同影响[16- 19],综合分析胜利油田Z1区块动、静态资料,选取9类影响因素,并结合该区块的基本参数,建立多层数值模型进行研究,Z1区块基本参数及数值模型参数见表1。
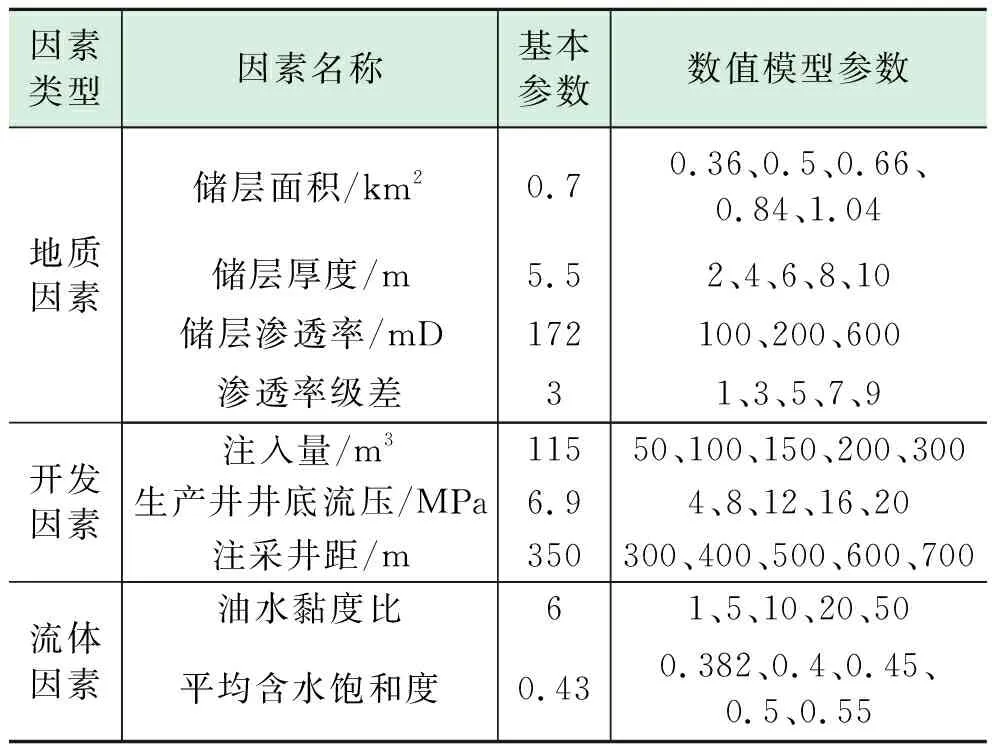
表1 Z1区块基本参数及数值模型参数
1.2 参数的处理及影响因素分析
基于Z1区块的基本参数建立层状油藏层间非均质数值模型,绘制含水率、含水率导数随PV数的变化曲线,结果如图 1所示。含水率导数可通过式(1)进行计算:

图1 五层模型含水率及导数曲线
(1)
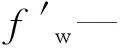
通过图1可知:层状油藏注水开发过程中含水率曲线呈现多段上升特征,相应地,导数曲线具有多峰特征且峰值个数与油藏储层数一致。峰值的出现反映了注入水前缘到达生产井井底而导致含水率快速上升的现象。由于含水率导数峰值出现时的PV数具有明显的渗流力学意义,可有效反映注入水在不同层位的流动特征。基于Z1区块的基本参数,建立双层油藏数值模型,选取含水率导数峰值所对应的PV数作为特征值,结合表1依次设置模型参数进行影响因素敏感性分析,确定不同因素对特征值的影响程度,结果表明:储层面积、注采井距、油水黏度比、储层平均含水饱和度对油藏和储层的含水率导数曲线形态及特征值大小均具有显著影响,选取油水黏度比、储层平均含水饱和度作为示例,结果如图2所示。

注:μr—油水黏度比,无因次;Swi—储层平均含水饱和度,无因次;C1—双层数值模型顶部储层;C2—双层数值模型底部储层。图2 不同模型参数下储层含水率导数曲线
2 基于机器学习算法的特征值预测
由于注采井距与井网控制面积、储层面积间存在固定的倍数关系,因此引入相对井控面积Ar进行整合,计算公式见式(2):
(2)
式中:Ar—相对井控面积,无因次;
A井—井网控制面积,km2;
A—储层面积,km2;
d—注采井距,km。
根据Z1区块的基本参数,依次改变储层面积并设置相对井控面积(取值为0.02~0.5,间隔区间为0.02),结合式(2)计算对应的注采井距。在此基础上,改变储层平均含水饱和度(取值为0.382、0.45、0.5、0.55)、油水黏度比(取值为1、2.5、5、10、15),共建立500组数值模型进行模拟,统计不同相对井控面积、储层平均含水饱和度、油水黏度比情况下特征值的变化情况,结果如图3所示。
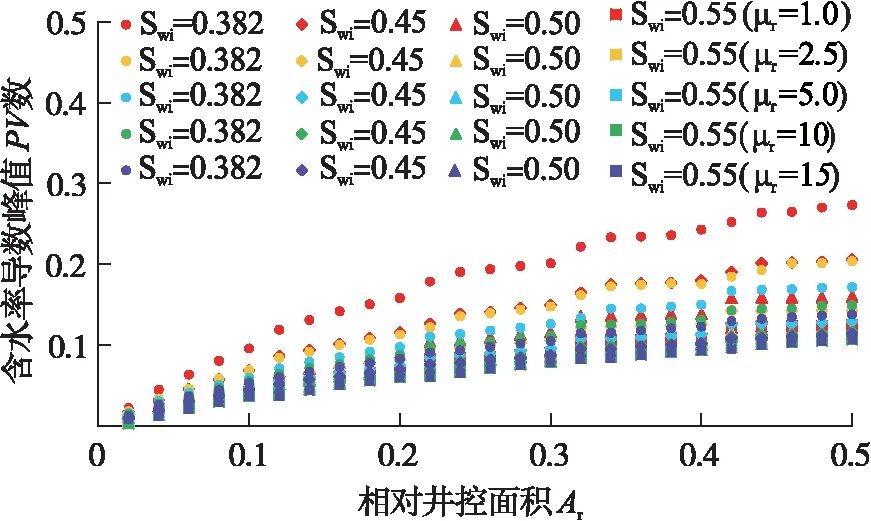
图3 相对井控面积与含水率导数峰值PV数散点图
由于含水率导数峰值出现的无因次时间受相对井控面积、储层初始含水饱和度、油水黏度比的共同影响,通过数值模拟绘制图版工作量巨大,且在数值读取过程中易产生较大误差。采用机器学习的方法可对不同情况下的特征值进行有效预测从而极大地减少计算工作量,同时减少目标点位于图版曲线之间进行插值时产生的误差,进而对油藏高耗水层的发育情况进行更加准确的表征。机器学习算法中线性回归、神经网络算法一般用于处理海量数据,随机森林是常用的小样本机器学习方法,在解决小样本、非线性及高维模式识别中表现出许多特有的优势。针对图3中的数据,采用随机森林法建立含水率导数峰值无因次时间预测模型。选取475组作为训练样本,25组作为验证样本进行研究。
基于475组训练样本,构建800棵随机决策树形成随机森林,采用10折交叉验证法验证模型的预测精度,在训练前随机重置了原始数据的顺序,选择均方误差作为评判标准时,训练精度为99.48%,采用相关系数作为评判标准时,训练精度为99.01%,训练集的结果如图4(a)所示。基于训练完成的模型,将25组验证集数据代入模型进行验证分析,验证结果如图4(b)所示。可以看出:采用随机森林算法预测平均准确率为98.23%,该算法对于小样本集数据有着较高的适应性,该算法可对特征值进行准确预测。
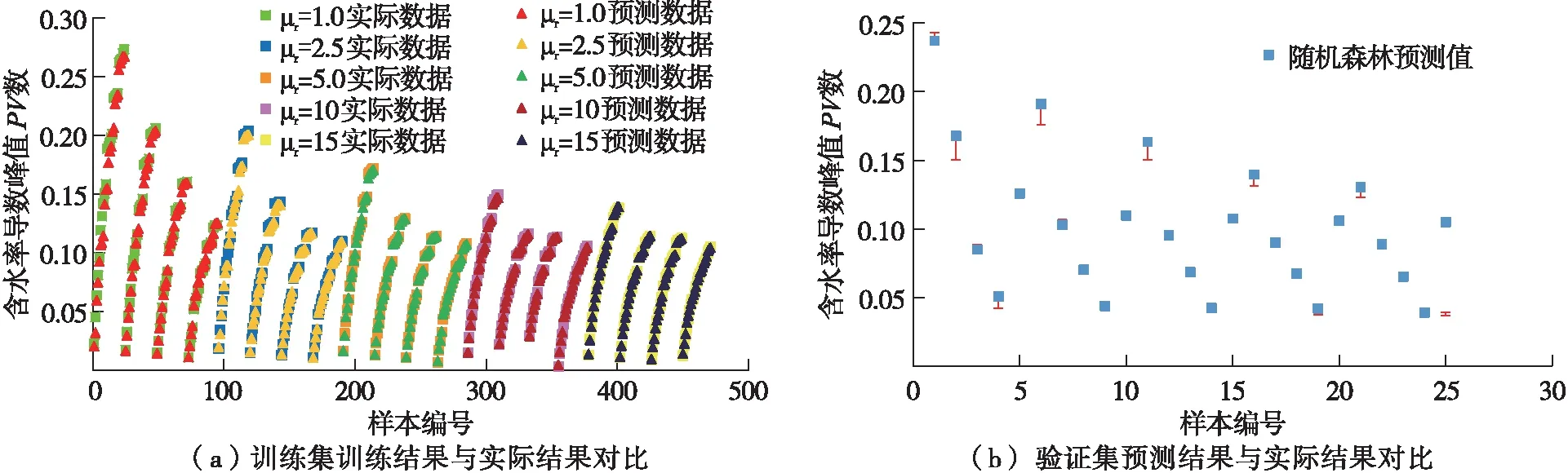
图4 基于随机森林算法的训练集与验证集分析结果对比图
3 高耗水层识别与评价流程的建立
3.1 高耗水层评价指标的建立
由于高耗水层具有注入强度大、注入量大的双重特征,引入储层耗水能力评价因子Fi、相对耗水能力评价因子Fri对层状油藏储层耗水能力进行评价,计算公式见式(3)~式(4)。
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)

基于上述评价指标并结合胜利油田Z1区块的基本情况制定了该区块高耗水层分级标准,如表2所示。

表2 高耗水层分级标准
3.2 高耗水层识别与评价流程的建立
基于随机森林特征值预测算法、高耗水层识别与评价指标,建立高耗水层识别与评价流程,流程如下:
(1)收集目标区块地质、流体、井网及生产动态资料。
(2)基于目标区块的地质、流体、生产动态参数建立机理模型,根据模拟结果建立特征值训练集,编制特征值预测程序。
(3)根据各层生产动态资料计算采收率,在此基础上计算各储层平均含水饱和度,结合井网面积以及注采井距计算各注采井对的井控面积与相对井控面积(式2)。
(4)基于井网特征参数与油藏地质资料计算油藏孔隙体积,绘制注采井对含水率导数曲线,记录含水率导数峰值出现时所对应的实际时间和累计注入量。
(5)根据各储层的平均含水饱和度、相对井控面积,通过特征值预测程序计算注入水在各储层到达生产井井底时的累计注入量,结合含水率导数曲线各峰值出现的实际时间计算不同见水次序下储层的注入速率,并以注采井对注入速率为约束条件选取误差最小的组合进行储层匹配。
(6)根据各储层的注入速率计算注入能力差异系数(式5)并绘制洛伦兹曲线,计算储层注入能力差异系数与完全均质线的包络面积V,当包络面积大于0.3时需针对储层高耗水层的发育情况进行进一步识别。
(7)计算耗水能力评价因子(式3)与相对耗水能力评价因子(式4),根据表 2的评价标准完成高耗水层的识别与评价。
根据上述流程绘制层状油藏高耗水层识别与评价流程图,如图5所示。
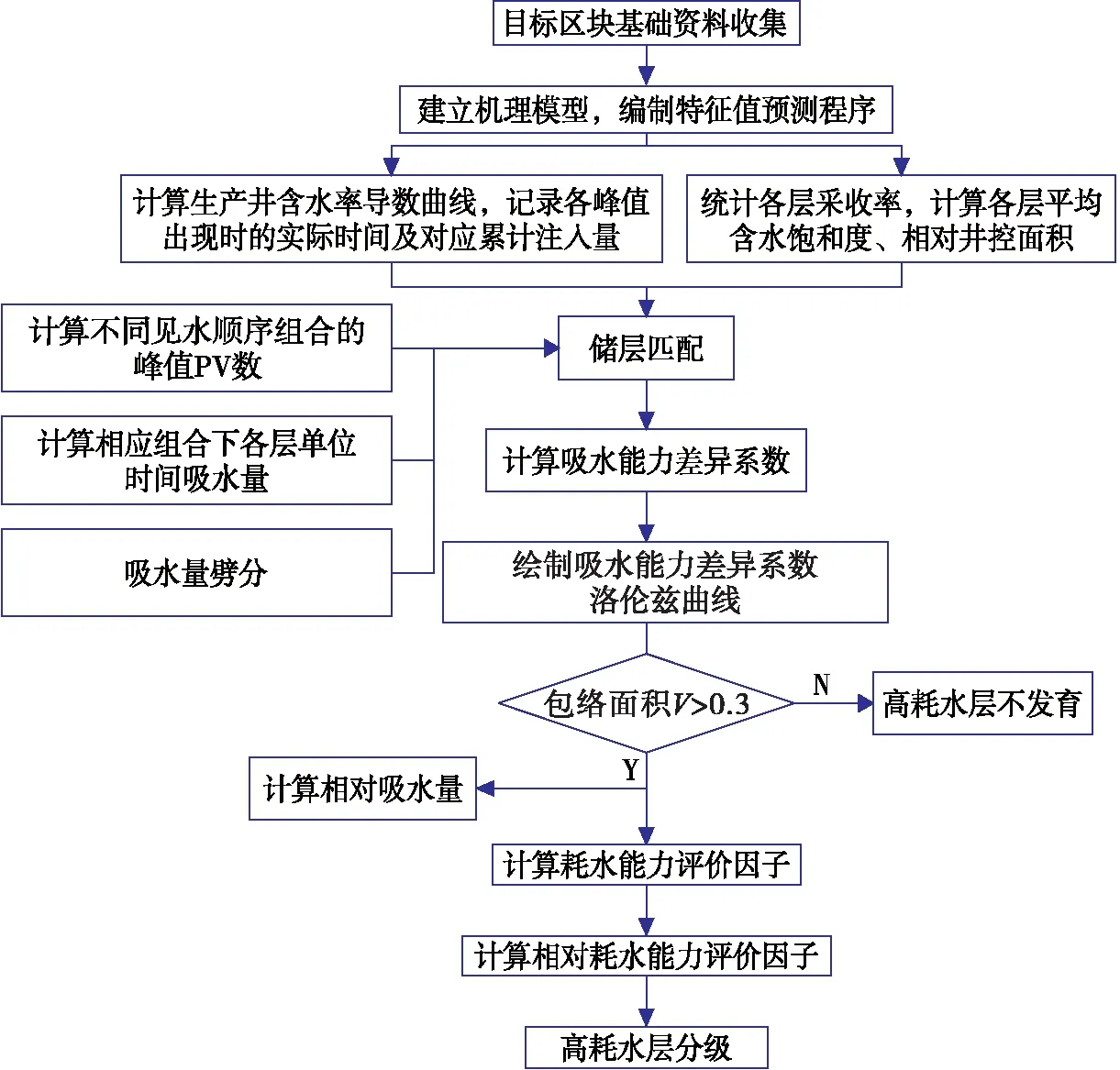
图5 高耗水层识别与评价流程图
4 高耗水层识别与评价实例
选取胜利油田Z1区块Z1- 3井组进行研究,其中Z1- 3与Z1P5、Z1P6、Z1P7构成注采井对,Z1P5、Z1P6、Z1P7均合采两套砂体。根据Z1- 3注入数据分别绘制Z1P5、Z1P6、Z1P7含水率及导数曲线,结果如图 6所示。可以看出,该井组生产井含水率导数曲线均具有明显的多峰特征,记录各生产井峰值对应的PV数并计算高耗水层识别与评价指标,结果如表3所示。

图6 Z1- 3井组生产井动态曲线

表3 Z1- 3井组高耗水层识别与评价指标计算结果及识别结果统计表
由表3结果表明:在Z1- 3井组中,Z1- 3与Z1P5、Z1P6井间发育强高耗水层,该结果与现场认识一致,所建立的高耗水层识别与评价方法可靠。
5 结论
(1)层状油藏含水率导数曲线具有多峰特征,峰值个数与油藏储层个数一致;峰值出现时所对应的PV数主要受储层面积、储层平均含水饱和度、流体黏度比、注采井距影响。
(2)当流体黏度比、储层平均含水饱和度一定时,特征值与相对井控面积呈现良好的线性相关关系。
(3)根据不同黏度比、储层平均含水饱和度条件下相对井控面积—特征值之间的关系建立了基于随机森林算法的特征值预测方法,该方法可有效对
不同初始地质、流体、开发条件下的特征值进行准确预测。
(4)通过高耗水层的典型特征和特征值预测方法建立了层状油藏高耗水层识别与评价流程,将该流程应用于胜利油田Z1区块取得了较为理想的效果。该流程可有效解决层状油藏高耗水层的识别与评价问题,并为后续高耗水层的治理技术的选择提供参考。
猜你喜欢
中学生理科应试(2021年11期)2021-12-09
小资CHIC!ELEGANCE(2021年25期)2021-07-29
新疆地质(2021年1期)2021-04-12
科学导报·学术(2019年1期)2019-09-10
环球市场(2019年6期)2019-09-10
智富时代(2019年5期)2019-07-05
智富时代(2019年5期)2019-07-05
课程教育研究·新教师教学(2016年18期)2017-04-12
少儿科学周刊·儿童版(2015年7期)2015-11-24
科技经济市场(2014年11期)2014-12-30
