
一种多任务面部特征点与头部姿态检测方法*
2022-10-20 01:09毅王旭彬王伟
电子器件 2022年3期
韩 毅王旭彬王伟*
(1.华中科技大学机械科学与工程学院,湖北 武汉 430000;2.安阳工学院计算机科学与信息工程学院,河南 安阳 455000)
面部特征点检测与头部姿态估计是计算机视觉与深度学习中较为常见的研究任务,但无论是使用计算机视觉方法还是深度学习方法,目前的许多检测方法都以单一检测任务为目的进行,没有充分利用两个任务间的关联特性以将两个任务高效地结合起来。而使用多任务学习(Multi Task Learning,MTL)可充分利用隐含在多个相关训练任务中的特定信息,相比于单任务学习(Single Task Learning,STL),多任务学习可以获得适用不同任务的特征,共享不同任务之间的内在联系以及复杂的非线性映射关系,且有效地增加用于训练模型的样本大小。
目前多数使用级联卷积神经网络进行面部特征点检测的方法效果较好,如文献[1]使用三层级联卷积神经网络进行人脸关键点检测,将多个网络的输出融合在一起进行估计,其深层的卷积网络结构可于初始化阶段就在整个面部区域提取全局高级特征,级联网络的设计为其提供了较高的可靠性;文献[3]基于级联网络和残差特征,使用一种结合残差特征的沙漏网络结构进行面部特征点检测,组合了不同的优化准则,实验得出二级级联结构的特征点定位精度与四级栈式结构相当。
对于头部姿态估计的方法,可使用计算机视觉方法,如文献[6]提出了一种分层的图形模型,通过利用帧上的现有姿势信息从实际视频中概率估计连续的头部姿势角度;也可使用点云来进行估计,如文献[10]提出一种以点云数据为输入的HPENet,采用多层感知器和最大池化层实现点云的特征提取,提取的特征通过全连接层输出预测的头部姿态;或是基于面部特征点对头部姿态进行估计,如文献[7]将图像中人脸五官特征点使用修正牛顿法与模型对齐以确定人脸姿态,文献[8]使用人眼和鼻孔的位置信息,将眼睛、鼻子定位结果与正脸头部姿态中的眼睛、鼻子进行对比,从而对不同的头部姿态进行粗估计;或者使用卷积神经网路,如文献[9]通过训练一个多损失的卷积神经网络,使用RGB 图像结合分类和回归损失的方法来预测欧拉角。
在人脸识别方面,使用多任务卷积神经网络的方法相较于同类型的单任务方法有着更优秀的效果,如文献[5]提出了一个高效的深度级联的多任务网络框架,它利用了检测和对齐之间的内在联系来提高整体网络的性能,通过三个阶段深度卷积网络预测人脸位置以及面部特征点位置,使得特征点的定位更加准确。
文中首先设计了相关性实验以挑选出与头部姿态变化相关性较强的面部特征点,进而设计了一种基于多任务学习的卷积神经网络(Multi-task Learning Convolutional Neural Network,MTL-CNN),将特定面部特征点检测和头部姿态估计这两个相关性较强的任务联合,充分利用两者之间的内在联系,建立两任务间复杂的映射关系,共享核心卷积神经网络提取到的特征,后使用不同的分类器同时进行预测,精心设计的损失函数去差异化策略解决了尺度差异,有效提高了两任务的检测精度。
1 面部特征点与人脸姿态
1.1 准备工作
头部姿态的变化与面部特征点有着紧密的联系,在头部进行动作时,面部特征点位于头部前方观测方向上的投影会随着头部动作进行变化。而面部特征点的变化具有选择性,并非所有特征点都对头部动作有着明显的响应;且某些特征点具有代表性,例如眼睛瞳孔的位置可良好地表达眼部整体的位置。因此若将全部面部特征点用于头部姿态估计则会加重神经网络的任务,过多的噪声特征点也会影响识别精度。
为探究面部特征点与头部姿态同时变化时的相关性,寻找随头部姿态变化较为明显的面部特征点以设计多任务神经网络,排除无关特征点的干扰,本章基于相关性分析设计实验,对面部特征点与人脸姿态的关系进行探究。
1.2 相关性实验
实验基于AFLW 数据集,随机挑选出2 000 张覆盖各种头部姿态的图片,其中每张图像经处理裁切为450×450 pixel,对应3 个头部姿态参数yaw、pitch 以及roll,如图1 所示,以及21 个二维面部特征点坐标,如图2 所示。
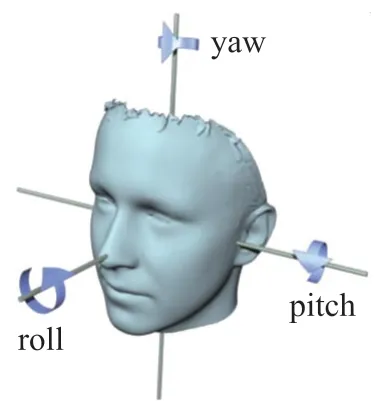
图1 3 个头部姿态参数

图2 面部特征点转化为欧氏距离的示例
由于面部特征点坐标位置无法直接与三个头部姿态参数进行对比,因此对二者进行转化处理。首先建立二维坐标系,对于数据集中的共21 个面部特征点,使用该特征点与原点的欧氏距离d(式(1))来表达面部特征点的位置,其中(xi,yi)代表第i个特征点在该坐标系下的坐标,(x0,y0)则代表该坐标系的原点。转换后的特征点数据可视化如图2 所示;后基于三个用于描述头部姿态的欧拉角ψ(yaw,偏航)、θ(pitch,俯仰)以及φ(roll,桶滚),求得旋转矩阵R(式(2))以表达头部姿态。
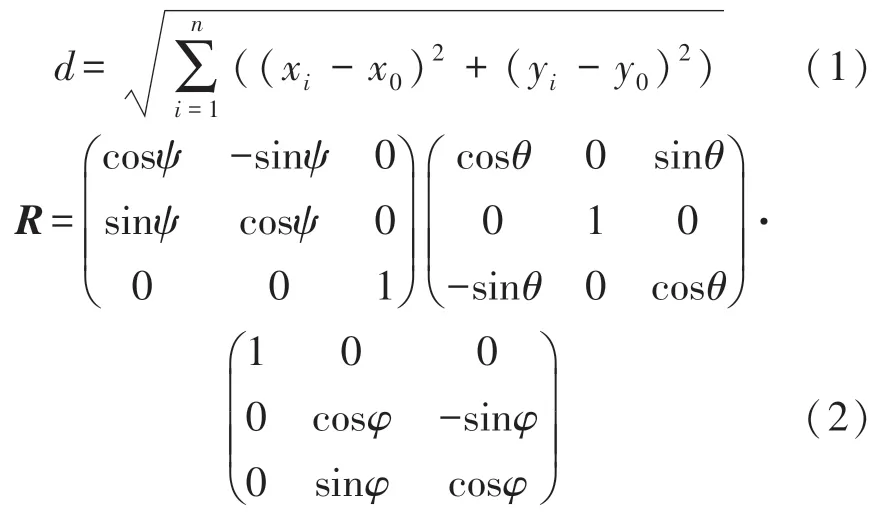
部分通过式(1)计算出的欧氏距离数据分布如图3 所示。KS 检验(Kolmogorov-Smirnov test)是比较一个频率分布f(x)与理论分布g(x)或者两个观测值分布的检验方法。实验使用KS 检验方法检验数据是否符合正态分布,部分显著性检验值p-value如表1 所示,结果显示求得的欧氏距离数据并非呈正态分布。

图3 鼻子和嘴巴中点数据分布

表1 K-S 检验结果
使用复相关分析的方法研究面部特征点与头部姿态的联系。由于特征点为手动标注,且被遮挡的、不可见的特征没有对应坐标,因此对空值做剔除处理。以清洗后数据求得的欧氏距离d作为自变量,将通过三个欧拉角求得的旋转矩阵R设置为因变量,基于数据并非呈正态分布且存在异常值的特点,选择spearman 相关系数探究面部特征点与头部姿态同时变化时的相关性,计算结果的热力图如图4所示,部分特征与头部姿态的spearman 相关系数绝对值如表2 所示。

图4 spearman 相关系数计算结果

表2 部分spearman 系数结果
实验结果表明眼部、嘴部以及鼻子部位的特征点变化对于头部姿态变化的响应较为明显,达到了强相关。故选取与头部姿态相关性较高且具有位置代表性的双眼瞳孔、鼻尖以及两嘴角共五个面部特征点作为目标特征点。使用相关性较高的特征点不仅能使多任务学习卷积神经网络快速准确地标注面部特征点,也使其更精准地预测头部姿态。
2 基于多任务学习的卷积神经网络MTL-CNN
普通学习器一般可以学习到输入中大量且普遍存在的特征,却忽视掉少量不常见但对模型有用的特征,而多任务学习则可避免这样的情况发生,两任务相互促进,不同任务的信息有助于共享的隐藏层学习到更好的内部表示,有效增加了样本大小,且能使两任务的泛化能力大大提高。
经相关性实验表明,特定面部特征点与头部姿态的变化呈强相关性,进而本章基于多任务学习设计了一种多任务学习卷积神经网络MTL-CNN,可同时进行特定面部特征点检测与头部姿态估计。
2.1 MTL-CNN 整体框架
MTL-CNN 采用的是多任务学习中的硬参数共享策略,应用到所有任务的所有隐藏层上而保留任务相关的输出层,其结构如图5 所示,包含核心网络(Backbone)与两个子网络(Task1 与Task2),即面部特征点检测与头部姿态估计。两个子网络共享一个由卷积神经网络组成的核心网络,共享两任务间的内在联系以及复杂的非线性映射关系。

图5 MTL-CNN 结构
核心网络包含8 个卷积层,4 个池化层,1 个全连接层,使用ReLU 作为激活函数,通过添加较多的卷积层以稳定地增加网络深度,在所有层中卷积滤波器被设置为3×3 大小,有效地减小参数,可更好地提取深层特征。连接核心网络的两个子网络如图5 中Task1 与Task2 所示,共含有5 个全连接层,Task1 中的2 个全连接层连接核心网络输出5 个面部特征点的位置;Task2 中的3 个全连接层连接核心网络输出3 个头部姿态参数。
2.2 MTL-CNN 工作流程
Dlib 开源库[29]是一个优秀的机器学习库,可广泛应用至许多场景,MTL-CNN 的输入图像使用Dlib中的人脸定位并添加宽容度策略,如算法1 所示,使裁剪区域变大,确保裁剪出的人脸图像完整,后将将图片重新调整至128×128(即图像存储在128×128的矩阵中)以送入MTL-CNN。

算法1 宽容度策略
MTL-CNN 以经过算法1 处理的存储在128×128×3 三维矩阵中的二维彩色人脸图像为输入,首先经过核心网络以提取特征。图像通过核心网络的处理被映射至1×1 024 矩阵中的特征图以进行后续处理。输出的特征图将被分别送至两子网络处理,子网络基于总特征图各取所需,选取适用于目标任务的特征作为输入进行处理。
2.3 MTL-CNN 的训练
核心神经网络在5 个面部特征点位置和3 个头部姿态参数的监督下学习人脸图像的深层特征,后经过两个子网络输出预测的1×10 的面部特征点和1×3 的用于表达头部姿态的欧拉角。
对于子网络Task1,其输出为1×10 的五个面部特征点,分别为双眼瞳孔、鼻尖以及嘴角两侧,将其视为回归问题,对于每个特征点数据与预测数据计算欧氏距离作为网络的损失函数,即L2 范数损失函数(式(3)),其中∈R10,为预测的面部坐标,为该样本的真实坐标。
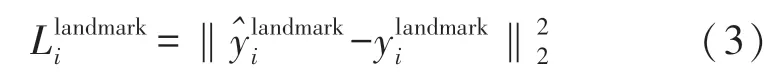
子网络Task2 的任务为估计头部姿态,输出为1×3的三个欧拉角yaw、pitch 以及roll。与Task1 一样将其视为回归问题,对于每个样本,采用L2 范数损失函数(式(4)),其中∈R3,代表预测的欧拉角值,为真实欧拉角值。
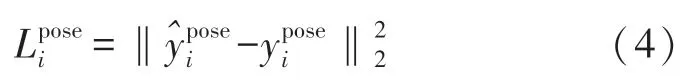
由于Task1 与Task2 采用了不同的损失函数,不同任务的损失尺度差异对MTL-CNN 的影响较大,且使用加权求和时模型性能受权值影响,对此MTL-CNN 基于文献[12]提出的使用任务间的同方差不确定性给损失函数赋权,通过神经网络的输出来平衡两个损失函数,如式(5)所示。其中为网络输出,式中右侧前两项与后一项存在抑制关系,解决了尺度差异以及两值相差过大的问题。
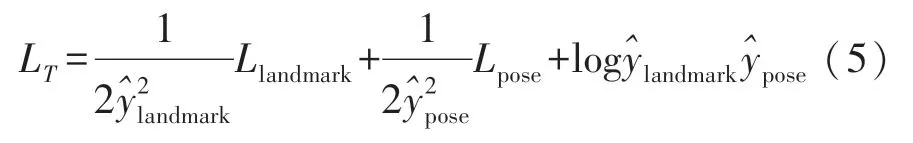
3 MTL-CNN 测试实验
为探究MTL-CNN 的实际表现,本章将基于不同数据集设计多种实验以测试MTL-CNN 的性能。本次实验在配备Intel Xeon E-2224G 处理器及Nvidia RTX 2080ti 工作站上进行,实验环境配置为CUDA10.0,tensorflow1.14.0,首先测试MTL-CNN 的整体性能,后进行两个任务的分离实验。
3.1 实验数据集
实验共选取AFLW[15]、AFW、CMU Multi-PIE[20]以及BIWI[27]共4 个相关数据集。
(1)AFLW 数据集是一个包括多姿态、多视角的大规模人脸数据库,图像来自于flickr,共有21 997张图像,2 593 张面孔,59%为女性,41%为男性。每张图像中标注了21 个关键点,大部分图像为彩色图。AFLW 在多角度人脸检测、关键点定位以及头部姿态估计领域是非常重要的一个数据集。
(2)AFW 中有473 张标记的人脸图像,每一张人脸图像都提供了方形边界框,含有6 个关键点和3 个头部姿态参数。
(3)CMU Multi-PIE 由美国卡耐基梅隆大学建立,包含337 位志愿者的75 000 张多姿态面部图像,每位志愿者的多视角图像由15 个围绕在该志愿者周围的摄像机同时拍摄,如图6 所示。

图6 CMU Multi-PIE 数据集
(4)BIWI 数据集包含1 000 个高质量的3D 扫描仪和专业麦克风采集的3D 数据,其中有14 个人,6 个男性与8 个女性,以25 帧/s 的速度获取密集的动态面部扫描,如图7 所示。

图7 BIWI 数据集
3.2 训练实验
MTL-CNN 以处理过后的AFLW 数据集作为训练数据。训练流程如图8 所示。
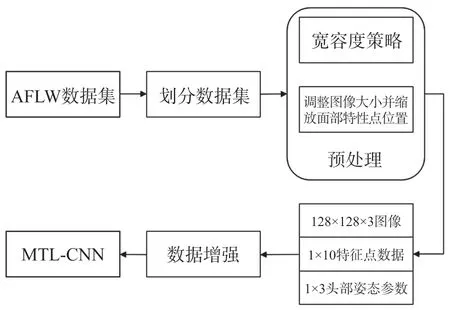
图8 MTL-CNN 训练流程
由于AFLW 中的图片大都包含人脸以外的区域,因此首先使用2.2 节中的方法对其进行裁切以排除无关区域,并确保裁剪出的人脸包含目标面部特征点,如算法1 所示,后根据裁剪尺寸对面部特征点的位置进行缩放调整,提取出双眼瞳孔、鼻尖和嘴角两侧的特征点数据以及yaw、pitch 和roll 三个头部姿态数据,通过对图像数据进行随机平移、旋转变换等数据增强操作将训练数据扩充至原训练数据的30 倍,得到完整的训练数据。
采用Adam 优化算法[28]进行训练时,基于训练数据迭代地更新神经网络模型的权重,初始学习率设定为0.001,dropout 设定为0.5,训练结果如图9 所示,横坐标表示训练次数,从训练结果来看,MTL-CNN 对于两个任务都有较好的表现。

图9 MTL-CNN 训练结果
MTL-CNN 于划分的测试集进行验证,Task1 的平均准确率为97.75%,Task2 的平均准确率为98.21%,平均准确率为97.98%。为进一步探究MTL-CNN 中两个任务的精准度,采用不同的数据集分别对面部特征点检测与头部姿态估计进行测试。
3.3 Task1 与Task2 的分离测试实验
对于Task1,面部特征点检测任务,MTL-CNN 基于AFLW[15]、AFW 数据集进行测试。以MTL-CNN 标定的各点与原数据集中标定各点的偏移为度量,MTL-CNN 的表现如表3 所示,平均准确率为97.30%。
对于头部姿态估计任务,将MTL-CNN 用于CMU Multi-PIE 数据集[20]进行测试。以MTL-CNN 预测的三个头部姿态值与原数据集中头部姿态的三个值的误差为度量,MTL-CNN 的表现如表3 所示,平均准确率为98.10%。

表3 MTL-CNN 在AFW、AFLW 和CMU Multi-PIE数据集上的测试结果
为进一步探究多任务方法相较于单任务方法的优点,对于面部特征点检测任务,实验首先对AFLW中的测试集与AFW 数据集进行预处理,并整理至一起,后选取不同的特征点定位方法包括ESR[19]、TSPM[16]、RCPR[18]、TCDCN[23]、SDM[24]、TCNN[25]、CDM[26]与MTL-CNN 进行对比,结果如图10 所示,实验表明多任务的处理方法有着更稳定的表现和更好的鲁棒性。

图10 MTL-CNN 在面部特征点检测上与其他单任务方法对比
对于头部姿态估计任务,实验选取CMU Multi-PIE 与BIWI 中的数据并进行预处理,使用文献[7]、文献[9]、文献[17]中的单任务方法与MTLCNN 进行对比,结果如图11 所示。
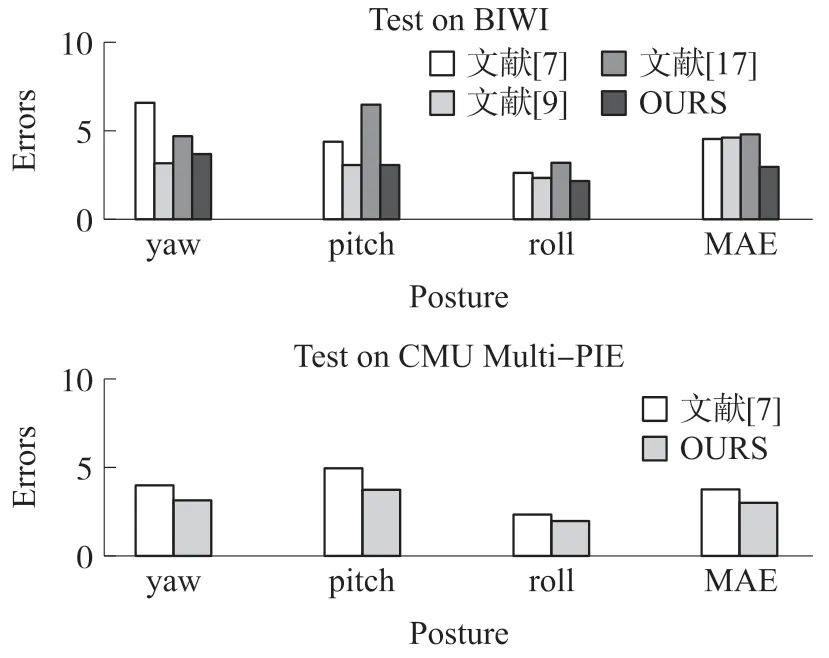
图11 MTL-CNN 在头部姿态估计上与其他单任务方法对比
从检测精度来看,基于多任务卷积神经网络的MTL-CNN 有着良好的效果,相比于单任务方法有着更为出色的表现。MTL-CNN 充分利用了面部特征点与头部姿态变化的内在联系,使其在许多环境因素的影响下,比如光照弱等,表现出了比单任务方法更高的鲁棒性。
同时,在相同平台上,MTL-CNN 的性能与以上单任务方法的对比如表5 所示。由于两个任务共享核心卷积神经网络以提取特征,在与单任务方法处理时间相当的条件下可同时进行面部特征点与头部姿态两个检测任务。

表5 MTL-CNN 与单任务方法的性能对比 单位:ms
3.4 MTL-CNN 的应用测试
MTL-CNN 的应用测试如图12 所示,从综合两个任务进行的测试以及分任务进行的测试来看,MTL-CNN 的准确性高,在受到不同光照等外界因素影响时也能拥有良好的表现,鲁棒性较好,在头部动作大导致的人脸大面积遮挡时也能准确的检测到可见特征点、估计出头部姿态,且有着不输于单任务方法的性能,不失为一种良好的面部特征点检测以及头部姿态估计方法。

图12 MTL-CNN 的应用测试
为探究模型在难度较高的检测场景下的表现,实验将原测试集人脸图像由0.1 至1 区间内放缩以进行测试,测试样例如图13(a)所示。对于Task1,以预测的各特征点与原数据集中标定各点的偏移为度量,对于Task2,以预测的三个头部姿态值与原数据集中头部姿态的三个值的误差为度量,模型精度如图13(b)所示。
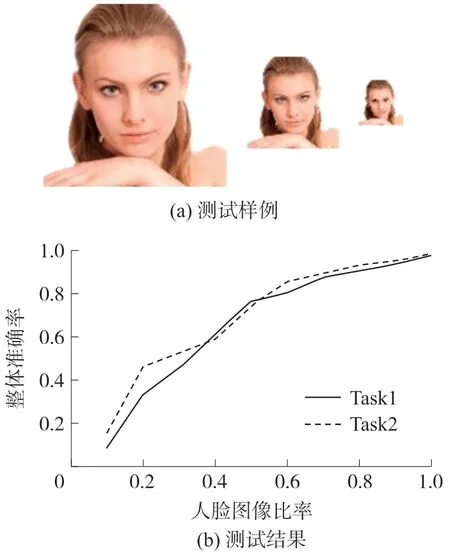
图13 不同比率人脸图像测试样例和测试结果
4 结束语
文中设计的相关性实验证明了头部姿态与面部特征点的强相关性,提出的基于多任务学习设计的卷积神经网络(MTL-CNN)通过将面部特征点检测和头部姿态估计这两个强相关任务联合起来的方式,深度挖掘两者之间的映射关系,使其共享硬参数,并通过精心设计的损失函数去差异化策略,使得MTL-CNN 可同时以高准确率进行这两个任务,在智能化系统飞速发展的时代,为面部特征点检测与头部姿态估计提出了新的方法。下一步的工作则是深度挖掘面部特征点与其他面部、头部特征的关系,研究加入更多相关任务的方法,并进一步扩大数据集并根据数据特点对MTL-CNN 进行调优,使其拥有更好的性能。
猜你喜欢
应用心理学(2022年5期)2022-11-05
北京大学学报(自然科学版)(2022年1期)2022-02-21
少儿美术·书法版(2021年9期)2021-10-20
汽车零部件(2021年9期)2021-09-29
奥秘(2021年5期)2021-06-15
现代信息科技(2021年21期)2021-05-07
发明与创新·大科技(2017年9期)2017-09-14
中国新技术新产品(2016年23期)2016-12-26
米娜·女性大世界(2016年8期)2016-08-17
奇闻怪事(2014年5期)2014-05-13
