
融合MPEG-7 和声门特征的病理嗓音识别方法研究*
2022-10-20 01:09:30朱欣程伍远博赵登煌张晓俊陶智
电子器件 2022年3期
朱欣程,伍远博,赵登煌,张晓俊,陶智
(苏州大学光电科学与工程学院,江苏 苏州 215006)
嗓音疾病直接影响人们的健康和社会交流。由于受工作压力、环境影响或长期吸烟等因素的影响,我国有约9%的人患有不同程度的嗓音疾病,其中从事着需要长期用嗓职业的人群,诸如教师、播音员等,嗓音疾病患病率更高,而声带疾病在所有嗓音疾病中占据很大的比例[1-2]。嗓音疾病的预防和早期发现可为患者的治疗和康复提供有益的帮助。目前喉部嗓音疾病诊断方法大都采用诸如肌电图描记,动态镜检查、喉镜检查等,这些均为侵入式的检测方法,患者会感受一定程度的不适。因此如何采用声学分析的方法设计出一种具有无创性,客观性和便携性等诸多特点的病理嗓音智能识别系统,成为当前一个研究热点[3]。
病理嗓音识别系统通常由特征提取和模式识别两部分组成。因此如何有效提高识别系统性能的关键在于特征参数和分类器的选取。根据特征所代表的嗓音信号的声学特征的差异,可分为扰动特征,非线性特征、以及倒谱特征等。扰动特征描述了由嗓音疾病引起的声带的不规则振动所产生的非周期性噪声(例如基频微扰百分比、振幅微扰和相对平均扰动)[4]。研究发现语音产生过程中,当气流通过声带腔体时会产生涡流,并且涡流区域也会对语音信号有调制作用,从而会存在非线性现象[5]。然而,非线性特征和扰动特征的计算有赖于窗口长度的适当选择和对基频的准确估计[6]。在谱分析特征领域,线性预测倒谱系数(Linear Predictive Cepstral Coefficient,LPCC)、梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)等倒谱特征不依赖于基频的准确估计,但是它们更倾向于表征声道系统,而不能够描述直接由嗓音疾病引起的声带振动机制的变化。除了上述特征以外,MPEG-7 特征[7]和声门特征[8]在语音特征提取方面具有广泛的应用前景。Wu 等[9]通过MPEG-7 特征结合随机森林分类器的病理嗓音二分类识别率达到了99.12%。声门波形从信号角度直接反映了正常声带振动与病理声带振动的差异。近年来,特征融合因其可以获得不同特征之间的最具有差异性的信息的特点,在病理实验识别中广泛应用[10-11]。
本文提出了一种融合MPEG-7 和声门特征的非侵入式病理嗓音检测方法,通过声门逆滤波方法获取语音信号的声门特征,再融合MPEG-7 特征,以细致地表征病理性声音与健康声音之间的差异,最终以TMS320VC5509A 为核心来设计该病理嗓音识别系统。
1 病理嗓音特征提取方法
1.1 声门逆滤波算法
大多数嗓音疾病都会破坏声带的组织结构,这将直接影响声带的灵活性、对称性和其他物理性质,从而导致声门波产生变化,需要采用声门逆滤波的算法来实验嗓音声门波信号的提取。Fant[12]基于发声原理,提出了一种声源滤波理论:发声系统由声门激励模型、声道滤波器模型和口唇辐射模型组成。其中声门波信号提供的体积速度谱用G(z)表示;声道气道的传递函数表示为V(z),该传递函数赋予在幅度谱中表现为共振峰的共振影响;口唇辐射效应是将嘴唇处的体积速度转换为声压的微分器,由L(z)表示。语音信号S(z)通过声道滤波器模型和口唇辐射模型组成的滤波器进行逆滤波处理,由此可以得到声门波G(z)。假定语音信号S(z)和滤波器之间是线性无关的。在Z域中,数学表达式为[13]:
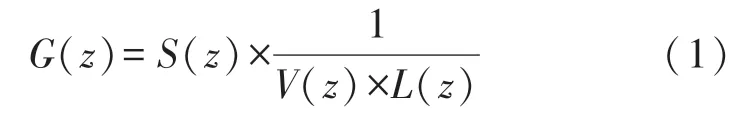
声门激励模型G(z)、声道滤波器模型V(z)、口唇辐射模型L(z)同时组成语音信号S(z)的频谱倾斜。LPC 线性预测在基于声门激励源G(z)的频谱倾斜效应消除的情况下可以较为精准地估计声道。声门逆滤波的具体过程如图1 所示。

图1 声门逆滤波过程
声门源信号是由肺部气流引起的声带振动直接产生的,即声门波形从信号角度直接反映了正常声带振动与病理声带振动的差异。图2 显示了原始正常和病理的语音信号波形和用声门逆滤波方法得到的正常嗓音和病理嗓音的声门波波形,上两张图是正常声音和病理声音的原始语音信号,下两张图是正常嗓音和病理嗓音的对应声门波形。对于相应的声门波形,不仅两个语音样本的谐波成分不同,而且正常嗓音的归一化值远高于病理嗓音的归一化值。
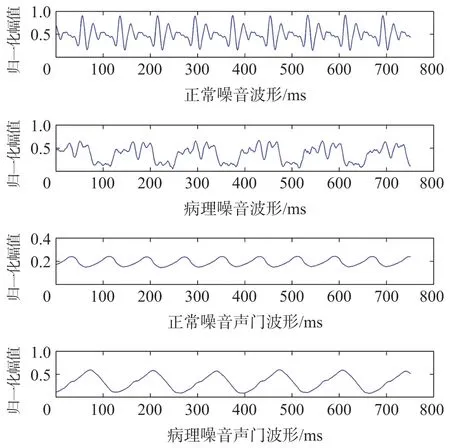
图2 正常及病理语音信号波形和声门波形
1.2 病理嗓音声学特征参数提取方法
1.2.1 MFCC 特征参数
在人耳听觉感知实验中发现,人类的听觉系统是一个特殊的非线性系统,人耳就像一个滤波器组,对不同频率的声音具有不同的灵敏度。梅尔频率倒谱系数(MFCC)是精确符合人耳听觉感知特性的特征参数。其基本原理是把线性频谱映射到基于人耳听觉感知特性的梅尔非线性频谱中,然后再映射到倒谱上。在语音信号中,低频信号部分包含大多数信息,高频信号部分易受到噪声的干扰。MFCC 系数加强语音的低频信息,因此具有一定的鲁棒性。MFCC 特征提取具体流程如图3 所示。
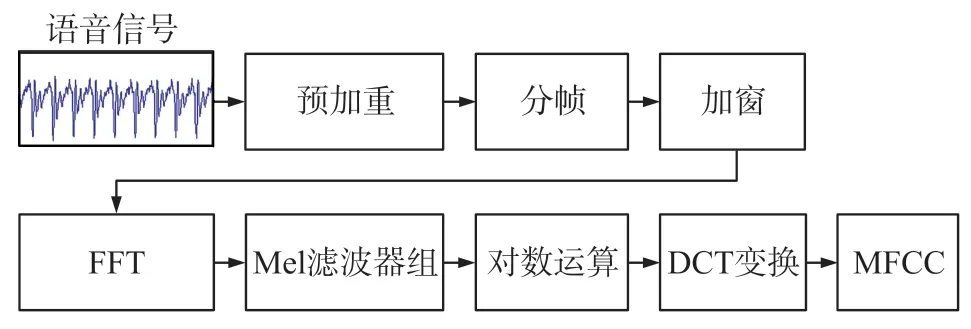
图3 MFCC 特征提取流程图
1.2.2 LPCC 特征参数
线性预测倒谱系数(LPCC)是目前倒谱类特征提取应用最广泛的方法之一。首先将预处理后的语音信号进行线性预测编码(Linear Prediction Coding,LPC),随后进行倒谱运算后便可以得到LPCC。LPC 通过某个采样时间之前某个时刻采样值的线性组合进行估计和预测。首先利用传统的全极点模型计算LPC,再利用快速傅里叶变换(Fast Fourier Transform,FFT)运算,对结果进行对数运算,最后通过傅里叶逆变换便可得到LPCC。LPCC 特征提取具体流程如图4 所示。

图4 LPCC 特征提取流程图
1.2.3 MPEG-7 特征参数
多媒体内容描述接口(MPEG-7)音频特征参数[14]来自基于ISO/IEC15938 的国际多媒体内容描述标准,该标准由视频和音频部分组成。由于MPEG-7 音频特征在声学研究中的高度差异性,它们已被用于各种声学研究中。MPEG-7 特征是低级特征,有两种类型:标量和矢量。整个MPEG-7 特征集的维数为45,矢量类型特征包括音频频谱包络(3维特征),音频频谱平坦度(22 维特征),音频频谱基础(2 维特征)和音频频谱投影(2 维特征)。其他是标量类型的特征包括音频波形(2 维特征),音频功率,音频频谱质心,音频频谱,音频协调性(2 维特征),音频基频(2 维特征),对数起音时间,时间质心,频谱质心,谐波频谱质心,谐波频谱偏差,谐波频谱扩展和谐波频谱变化。
1.2.4 声门特征参数
当气流通过声带时,声带会产生振动。气流因为声带的振动而变成空气脉冲。空气脉冲形成的压力信号是准周期的,称为声门波。声门脉冲是声门波的一个周期。其声门波波形的计算公式如下:
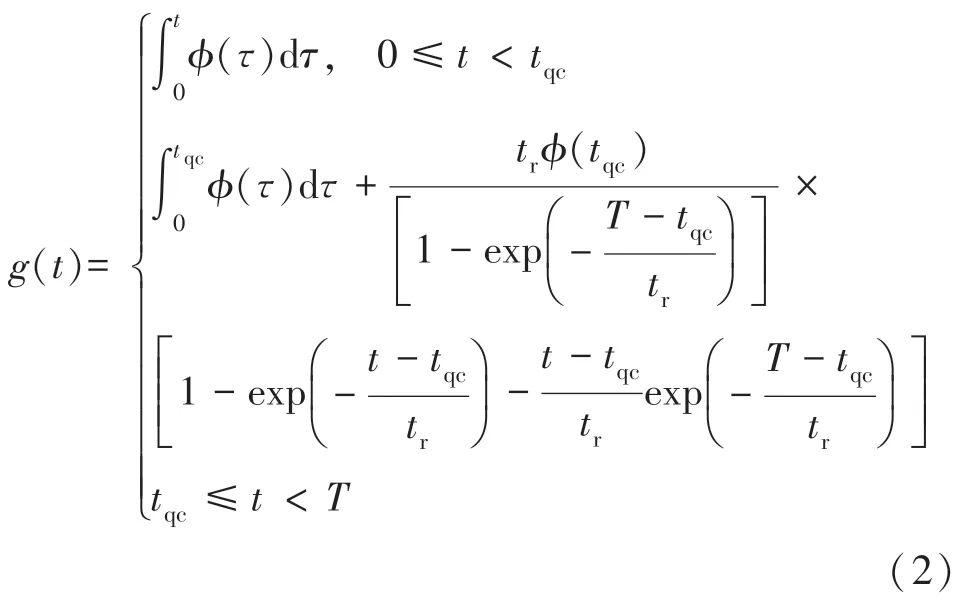
式中:函数ϕ(t)表示直到声门激发时刻的声门脉冲时间导数,tqc表示声带碰撞的瞬间,T表示声门脉冲周期,tr表示最大兴奋瞬间之后的时间间隔,称为返回阶段。
根据文献[15]中提出的声门流模型,ϕ(t)可以通过下面的公式计算出来:

式中:Ad指的是声门脉冲时间导数的振幅。
用声门逆滤波方法,从声源提取出来的声门特征可以分为两组:时域特征和频域特征。时域特征可以是通过使用不同的相位和瞬间来描述。此外,声门源信号在不同相位的幅度还用于计算基于振幅的声门源特征。与时域特征不同,频域特征反映了频谱倾斜本质,是从声门频谱计算出来的。本文具体所采用的声门特征描述及公式[16]如表1 所示。
表1 中,tmax为声门信号幅值最大对应的时刻,tc为声门关闭时刻;to1和to2分别为声门主要、次要打开时刻;tqc和tqo定义为声门波曲线的振幅越过曲线的50%和峰峰值幅度水平的时间数值。Aac为声门波峰峰值脉冲幅度,Admax为声门脉冲时间导数幅度最大值,Admin为声门脉冲时间导数幅度最小值,f0为基音频率。HW代表第W次谐波的幅值,H1表示基音频率的幅值。b为声门波频谱衰减参数,bmax为DC 函数衰减参数。

表1 声门特征参数集
2 病理嗓音检测系统设计
病理嗓音识别系统主要包括音频采集模块、电源模块、DSP 处理模块、逻辑控制模块、外部储存模块和JTAG 操作模块。系统框图如图5 所示。DSP芯片采用的是TMS320VC5509A。语音信号通过音频采集模块TLV320AIC23 进行AD 转换和滤波处理,再将滤波后的数字信号通过 DSP 芯片TMS320VC5509A 进行预处理、特征提取和识别。

图5 病理嗓音识别系统
该系统的软件主要依靠可视化编程的CCS 3.3环境。DSP 系统运行主程序和信号的数据处理、采样、传输控制、训练、识别等部分。采样、传输控制、信号分析处理等采用编程方法来完成。识别系统流程如图6 所示。语音信号通过声门逆滤波处理后提取其声门特征;针对病理嗓音识别,本系统提取病理嗓音识别常用的MFCC、LPCC 和MPEG-7 特征参数。将声门特征与这三种特征参数进行特征融合后进行机器学习,得出识别结果。
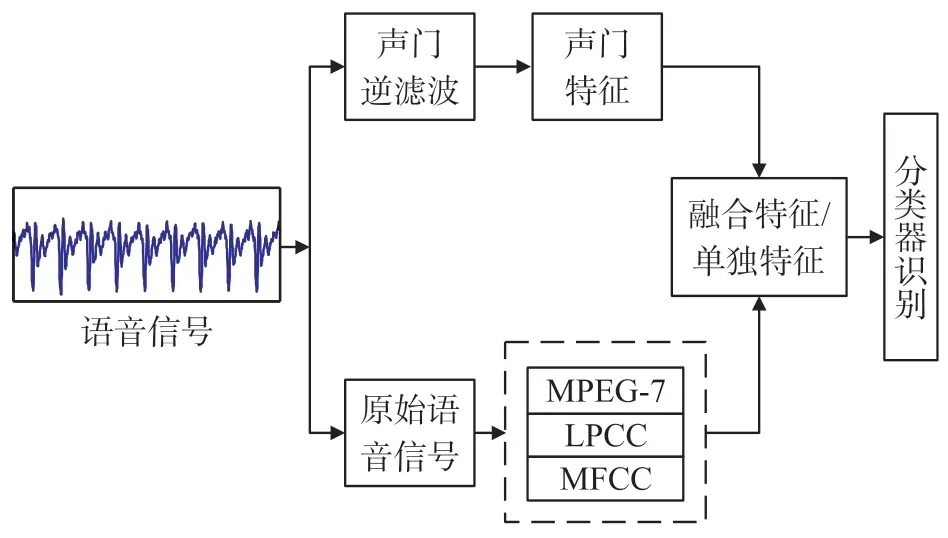
图6 病理嗓音识别流程图
3 实验及结果分析
实验采用MEEI 数据库[18],该数据库包含了1 384例病理嗓音/ɑ:/(选择元音/ɑ:/作为测试集,一方面因为/ɑ:/音较少地受到口腔的影响,二是因为/ɑ:/音会更多地受到听觉反馈的影响),并给出了专家诊断结果。从该数据库中选取53 个正常嗓音和149 个病理嗓音作为数据子集,选用这个子集是考虑了各种病理嗓音的种类以及正常和病理嗓音库的性别和年龄分布情况。具体统计表如表2所示。

表2 嗓音情况统计表
实验采用十折交叉验证的方法,采用当今主流的机器学习算法:支持向量机(SVM)、贝叶斯网络(Bayes Net)、BP 神经网络(BP)、局部加权线性回归(LWL)、简单逻辑回归(SL)5 种分类器进行识别实验。实验结果如表3 所示。
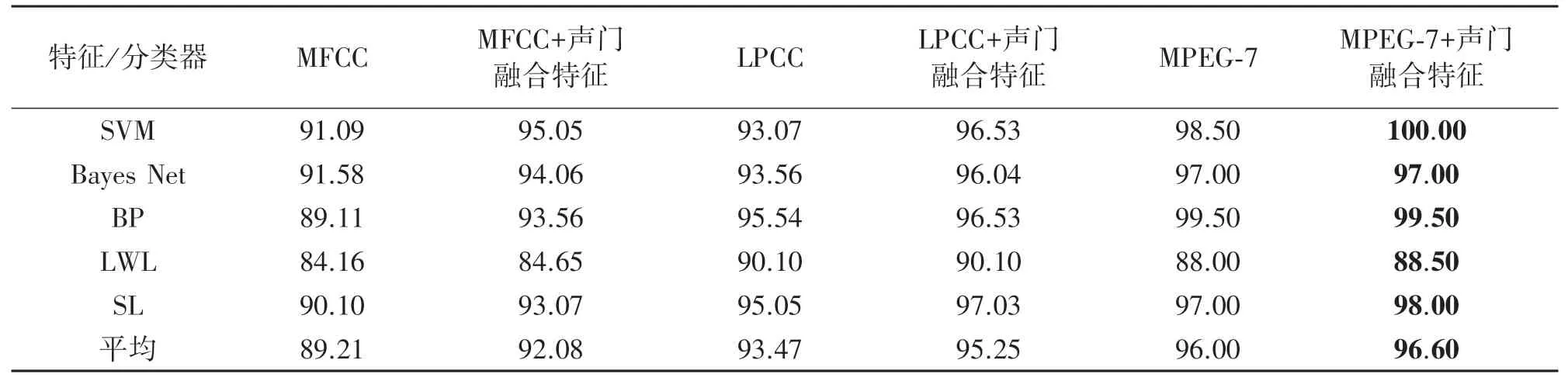
表3 声门融合特征识别率统计表 单位:%
在贝叶斯网络(Bayes Net)、BP 神经网络(BP)、简单逻辑回归(SL)、支持向量机(SVM)、局部加权线性回归(LWL)5 种机器学习分类器识别下,MFCC、LPCC 及MPEG-7 融合声门特征的识别率优于传统的MFCC、LPCC 及MPEG-7 特征的识别率。其中MFCC 融合声门特征的平均识别率比MFCC 特征平均识别率高2.87%,LPCC 融合声门特征的平均识别率比LPCC 特征平均识别率高1.78%,MPEG-7 融合声门特征的平均识别率比MPEG-7 特征平均识别率高0.6%。MPEG-7 融合声门特征结合SVM 分类器更是达到了100%的识别率。
为了探究声门特征区分正常声音和病理声音的能力,对MFCC、LPCC、MPEG-7 融合声门特征的正常和病理嗓音的盒图进行对比,结果如图7 所示。从图7 可以看出,正常和病理声音的特征总体分布,三者融合声门特征的盒图中正常声音和病理声音之间几乎没有数据重叠,这也意味着融合声门特征可以更好地区分正常声音和病理声音。

图7 正常与病理嗓音融合特征的盒图对比图
图8 显示了声门特征融合MPEG-7 特征的前三个区别特征(glottal-MPEG-7 1,2,3)的三维散点图。从图中可以看出,虽然正常(圆圈)和病理(十字)样本有轻微的重叠,但这两类样本总体分布的高度分化表明,声门特征融合MPEG-7 特征能够有效地将正常声音与病理声音分离开来。
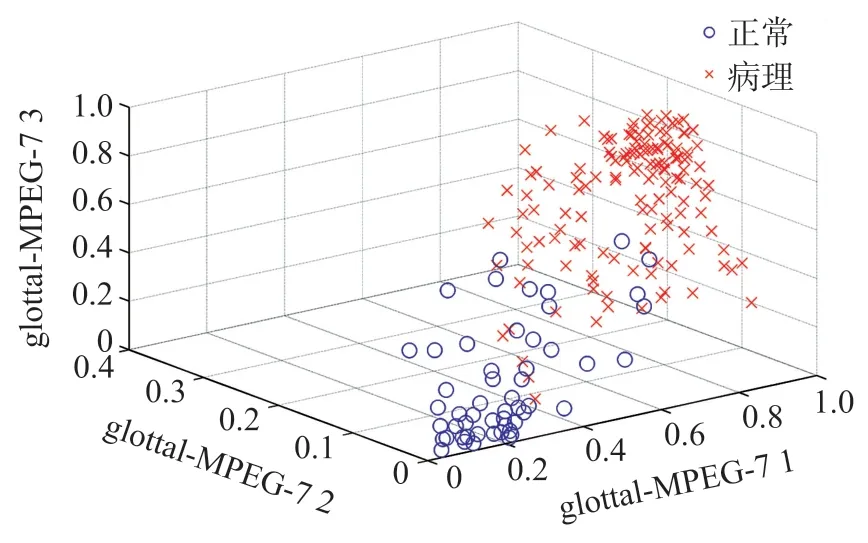
图8 三维散点图(glottal-MPEG-7 1,2,3)
表4 为MFCC 特征、MFCC 融合声门特征、LPCC 特征、LPCC 融合声门、MPEG-7 特征、MPEG-7融合声门特征在SVM 分类器下的正确率、卡帕统计量、平均绝对误差和相对绝对误差指标。可以看出在SVM 分类器下,本文所提出特征的正确率和卡帕统计量最高,平均绝对误差和相对绝对误差最低,客观表明本文方法精确度最高,误差最小,算法性能最佳。
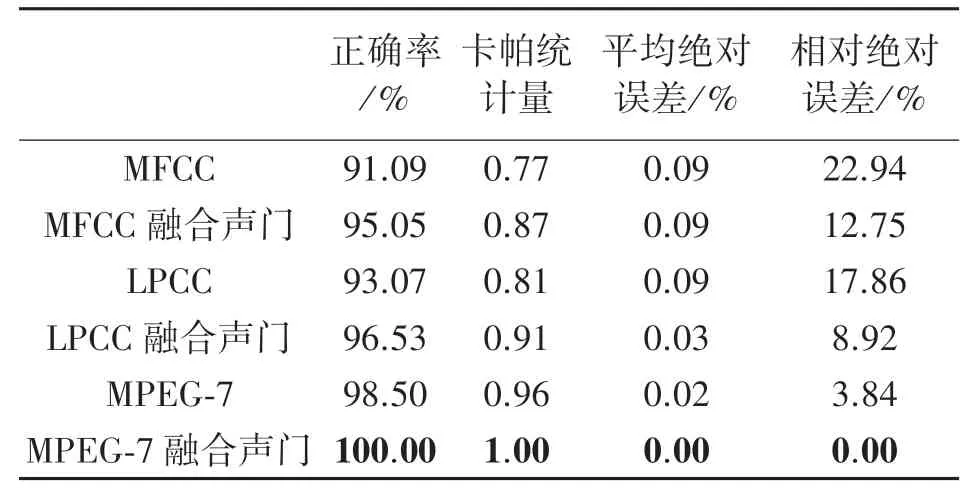
表4 识别结果指标对比表
4 总结
为了提高病理嗓音系统检测的性能,本文采用声门特征与MPEG-7 特征融合的方法,并且以DSP 芯片TMS320VC5509A 为核心设计了高精度的非侵入式病理嗓音识别系统。根据实验结果,病理嗓音在5 种主流机器学习方法下的平均识别率为96.6%。其中结合SVM 分类器可达到100%的识别率,并且卡帕统计量最高,平均绝对误差和相对绝对误差最低。充分表明声门与MPEG-7 的融合特征能更好地刻画病理性声音与健康声音之间的丰富细节内容和差异度。
在今后的实验中,可通过优化SVM 中的核函数等方法,以进一步提高病理嗓音的识别率。此外,考虑到单一数据库的局限性,未来将采用更多的病理嗓音数据库进行二分类及细分类的研究。
猜你喜欢
星星·散文诗(2023年28期)2023-11-09 17:35:18
保健与生活(2023年6期)2023-03-17 02:49:51
健康必读·下旬刊(2020年5期)2020-05-29 18:40:26
岭南现代临床外科(2020年1期)2020-03-14 02:49:32
文萃报·周二版(2019年20期)2019-09-10 02:57:29
儿童故事画报·发现号趣味百科(2018年4期)2018-11-14 02:33:22
海峡姐妹(2017年12期)2018-01-31 02:12:21
歌剧(2017年6期)2017-07-06 12:50:21
中国继续医学教育(2015年3期)2016-01-06 01:36:34
文艺生活·中旬刊(2015年7期)2015-10-28 23:35:29
