
基于机器学习的数学成绩预测系统设计
2022-10-18 08:57:20王博
电脑知识与技术 2022年25期


摘要:数学教育作为基础教育最重要的环节,是提高学生数学成绩的重要方式。从某方面而言,数学成绩是反映学生数学学习能力的重要工具,但由于数学成绩评价与学生学习能力、现场发挥等方面存在直接关系,其所反映的方面具有较强局限性,根本无法准确反映出学生实际学习情况。尤其是在信息化时代背景下,随着信息技术应用到教育行业,给数学教育带来质的突破,出现大量机器学习的数学成绩预测系统,来帮助教师更好地掌握学生实际情况,有效提高了中学基础教育效果。文章通过分析教育数据挖掘技术中的机器人学习预测理论,来探究影响学生数学成绩的因素,再根据因素提出有效的解决策略。
关键词:教育数据挖掘;机器学习;数学成绩预测;自我认知;母语
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)25-0026-03
开放科学(资源服务) 标识码(OSID) :
1 前言
在信息化时代背景下,互联网模式已逐渐普及到各行业,尤其在教育行业应用范围最广。慕课教学模式作为目前数学教育最常见的教学模式,已成功突破传统教学限制,能给数学教学提供丰富的数据资源[1]。同时,随着线上教育产业数量不断增加,给互联网教育带来巨大的空间,我国政府部门愈发重视教育数据挖掘工作,并加强对现代教育研究的重视程度。给教育数据挖掘带来较强的推动作用,将教育数据挖掘上升到战略高度,这给拓展教育数据应用范围提供了法律支持。目前,由国互联网教育产业还停留在初级阶段,数据分析要加强对线上推销和精准推送的研究力度,确保商品能具有明显特征,而不是将立足教育发展作为中心思想,这导致教育数据挖掘作用流于表面,无法发挥其真正作用。并且与国外相比,数据资源多样化是我国最大优势,无论是线下数据还是线上数据全部有明显优势,但如何将多样化教育数据转变为教育动力是目前教育研究者急需考虑的问题[2]。
2 机器学习分类算法
2.1 K-近邻
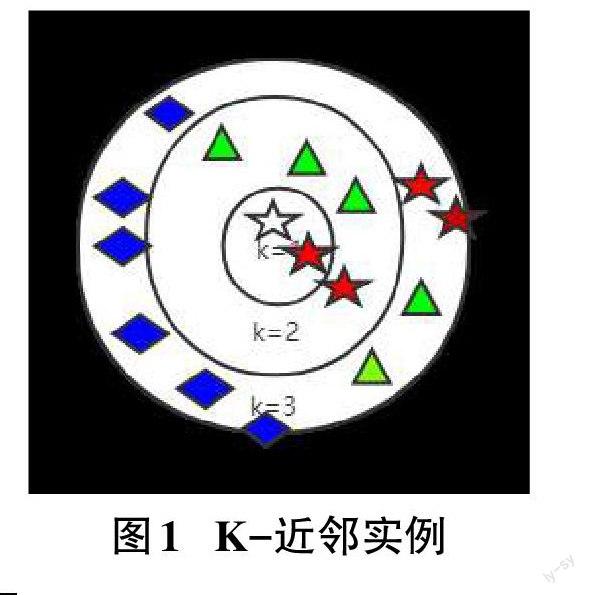
K-近邻算法属于有监督机器学习算法,其是根据各数据不同特征值间的距离为载体,合理分析数据内容,再利用不同类型数据值来确定正确的数据类型。如果在特征空间内有一个样本和相邻K各样本都属于同一类型,可确定该样本同样属于该类型,K值会取整数。其数学原理是将不同数据比作多维空间的点,再利用欧氏距离公式[d(x,y)=n1(xi-yi)2]或麦哈顿距离公式[d(x,y)=n1xi-yi]来计算不同测试数据和训练数据之间的距离,再根据升序方式将数据进行依次排列,再将最高频率类型作为测试数据的预测分类(如图1所示) 。
2.2 逻辑回归
逻辑回归算法在很多方面与K-近邻算法存在一定的相似性,都具有监督机器学习算法的功能。经过专业人员分析发现,这两种算法间具有较大差异性,如在输出变量类型方面存在差异,通常线性回归模型输出值是连续变量,线性回归预测函数为[y=xθ]。而逻辑回归输出值是离散变量,故逻辑回归并不属于回归,是属于分类。同时,可将逻辑回归作为线性模型,如图2所示,[y=g(z)=11+e-z]。
2.3 决策树
决策树算法将学生数学成绩利用树状图像的方式提供给教育工作者认识,能有效确定概率分布基本情况。目前,国内教学行业决策树出现频率较高(如图3所示) 。该教学方式是利用圆形节点为载体,将不同数据用原点、箭头、矩形节点、三角节点等方式呈现出来,有利于教师能准确收集这些信息[3]。
2.4 支持向量机
近年来,随着社会经济不断发展,给教学行业带来较大的发展空间,而数学作为教育行业重要的环节,在学生未来发展之中同样发挥着极其重要的作用。但从目前数学教学的实际情况而言,还存在很多方面的问题,给教学效率带来严重影响。而由于数学本质上具有较强的趣味性和丰富性。因此,教师可将支持向量机合理利用在学生学习过程中来帮助学生了解数学中真正的魅力。支持向量机算法是能对数据实现二元分类的线性分类器,其算法原理是正确划分训练数据集的最大边距超平面(如图4所示) 。
2.5 贝叶斯
贝叶斯分类器是以贝叶斯理论为基础的弱分类器,其都假设样本每个特征与其他特征无任何联系。所谓朴素是假设不同特征和判定目标类别的概率分布上是相互独立存在的。因此,概率公式为[P(cx)=P(cx)PcP(x)],在正常情况下,很容易构建朴素贝叶斯分类器,为此贝叶斯经常被应用在大型数据中。
3 CEPS数据分析预测
3.1 CEPS数据分析预测流程
数学本身是一门非常复杂的学科,在学习过程当中很容易遇到各种问题,如果这时候教师仍然使用传统的教学方式,很有可能会激发学生抵触情绪,引发 学生学习困难。针对这种情况,教师可在教学中结合学生日常生活,以日常生活为切入点,为学生构建CEPS数据分析预测流程,来分析学生在日常生活中遇到的难题和心理状态,来帮助学生找到正确的数学规律,从而提高学生问题意识。CEPS数据分析预测流程是为拉萨数据分析做对比,一方面在程序上来分析各种所需指令;另一方面CEPS数据预测结果给拉萨数据研究提供依据,从而验证评价机器学习中决策树、线性支持向量机等模型在成绩预测方面的效果,并确保最适合的预测分类模型。同时,CEPS数据分析根据作用不同可分為结果分析、模型训练、预测流程预处理、模型优化四个环节。其中数据预处理主要包括异常值处理、类型转换、数据获取等环节;模型训练又支持向量机、线性支持向量机、决策树等十二种模型的训练,并取得不同模型预测结果;模型优化是对测试模型结果较高的XBG分类模型和逻辑回归模型参数进行调整[4]。
3.2 数学成绩预测系统需求分析
学生用户画像系统作为专门服务不同教学阶段学生的数据产品,主要是以网络教育平台为基础,从不同方面来分析学生的行为数据,给网络教育平台正常运行提供丰富的数据资源。而学生作为整个系统的核心点,系统通过利用大数据技术来分析学生多样化行为方式,将学生行为动作变成大量的数据记录。系统在开始阶段会利用预处理的方式来记录学生的日常行为,再将结构化数据利用数据挖掘措施来统计处理后的数据,再将数据完全呈现在用户眼前,让教师能进一步掌握学生实际的心理状态和学习情况,能及时察觉到学生异常情况,针对学生存在的问题提出有效的解决措施,来提高学生的学习成绩。同时,学生画像系统是利用自动化系统,来分析学生的行为数据,给教师提供全方位的功能,将学生在线答题模块进行对接,帮助工作人员突破数据隔离的限制,在上传大量学生数据的同时,有效处理各种数据内容,进而满足教师对于数据的分析要求[5]。本系统最大的优点在于能将数据采集过程标准化,能将各种结构的数据利用自动化方式来进行处理,避免由于人工操作的方式出现失误影响,降低教育工作者的工作量,让其能将所有的注意力全部放在教育学生方面。同时,大数据方式能提高系统效率,能让教育工作者及时查看学生具体情况,避免其在传统教学中无法掌握学生学习状态的问题,还能避免信息滞后所引发的问题。
3.3 成绩预测系统
成绩预测系统在画像系统中发挥着至关重要的作用,主要体现在挂科预警模块和成绩预测模块内,模块共有两个功能,能合理分析学生期末成绩和学生知识点,成绩预测是以分类算法为基础,来准确计算出学生能答对多少道题目。知识点分析是在进行分类功能时,来进一步研究影响性较大的特征,通过分析这些特征,来了解到学生对目前数学知识所掌握的具体情况,来提高各种类型题目的正确率,让教育工作者能准确掌握学生整体学习情况。在正常情况下,成绩预测模块主要是利用机器学习流程来进行,通过采用Xgboost算法为载体,利用不同数据的特征性,来优化分类目标的各种方法,再提取数据库中的学生数据周期性,进而提高训练强度和数据,让整个模型的表现效果达到预期的效果,使学生成绩预测系统能提供更好的帮助。
3.4 数据异常值处理
数据冗余删除通常是将人工因素和环境条件相结合,来构建全新的数据知识,从而降低数据维度。首先,要删除特征值缺失超过大量的列数,一旦其缺失值超过一半,则其并不具备研究意义。再根据CEPS调查手册、教育学心理学有关数据成绩因素、Stata变量标签的研究,要删除任何和数学成绩没有必然联系的列数。虽然CEPS数据拥有大量特征,但由于其中大量特征和数据成绩关联性不强,通常是将教育学心理学作为成绩影响因素研究成果[6]。
数学是一门极具灵性的课程,能让学生留下深刻的经验,给其未来发展具有至关重要的作用。因此,教师要严格遵循以学生为核心,服务于学生发展原则,有效提高学生的综合素质,使得学生的世界观、人生观、价值观沿着数学学习的深入,慢慢地走向正确的方向。随着数学教学的不断深入,能进一步发掘学生们的创造性,给学生营造丰富多彩的想象力,提高学生的数学素质,促使学生综合发展。因此,进而利用数据异常值处理对系统进行分析。可发现异常值,再通过合理数据可视化特征,来帮助教师分析数学成绩标准分数密度曲线,但经过大量实践证明数学成绩标准分数并未全部超过标准值,这与数据正常分布情况具有一定的差异性,会给调查统计的数学成绩带来严重影响[7]。经过统计发现,异常值未超过三十个,与总数据相比,其占据较低部分,这对整体数据带来严重影响。
特征转换是通过合理利用数据分布特点,来实现教育和数据深度融合,从而预测出学生成绩及格率,并将数学成绩标准分数利用科学方式转换出来,让其基本成绩能高于平均值判定及格,低于平均值则被判定不及格,并对所有样本数据进行统计(如图5所示) 。从层次上而言,数据分布相对比较均匀,未出现数据分布极为不平衡的现象。在大规模数据情况下,不及格数据占据绝大部分,能满足数据训练预测要求。可利用编码技术将所有对象型数据进行独热数字编码,给后期模型训练做好准备[8]。同时,应加强学生学习热情和兴趣,如果学生能在实际学习当中具有较高热情度,那势必会给教师教学活动带来较强助力,教师在数学教学过程当中,要注重培养学生学习兴趣和学习热情,并探究学生学习特征,制定多元化教学模式,丰富教学内容,从而激发学生学习积极性,确保让学生能长期处于愉悦的环境中学习数学,从而提升课堂效率和质量。
4 总结
綜上所述,从分类预测技术层面来看,证实分类器、决策树、逻辑回归等分类模型相比在二元分类成绩层次预测方面具有较好的效果。从影响数学成绩因素而言,可将其分为两个部分,可将让学生对数学学习感觉自我认知和成绩层次有初步了解,从测试数据来说,学生对数学学习自我认知非常重要,且会成为预测学生学业成绩的重要特征。再根据特征相关分析、学生各科成绩分析,都充分说明其对学生数学层次划分的重要性,再结合高中数学教学现状,应加强对母语文化教学的重视程度,才能让学生全面发展。
参考文献:
[1] 孙鑫,黎坚,符植煜.利用游戏log-file预测学生推理能力和数学成绩——机器学习的应用[J].心理学报,2018,50(7):761-770.
[2] 金城,崔荣一,赵亚慧.基于机器学习的高考信息与大学程序设计课程成绩相关性分析研究[J].延边大学学报(自然科学版),2020,46(4):366-370.
[3] 刘研,陈勇,邢宇明,等.基于机考机评系统的成绩挖掘和个性化分析方案研究[J].教育现代化,2021,8(12):106-108.
[4] 杜佳恒,邱飞岳.机器学习在数学成绩预测中的应用研究[J].教育教学论坛,2020(16):101-102.
[5] 王博.基于Logistic Regression的数学成绩预测系统的应用研究[D].南昌:南昌大学,2018.
[6] 张瑞,贾虎.基于多变量时间序列及向量自回归机器学习模型的水驱油藏产量预测方法[J].石油勘探与开发,2021,48(1):175-184.
[7] 张宝一,李曼懿,李伟霞,等.基于机器学习的地球化学采样下伏基岩类型判别-以青海省察汗乌苏河地区为例[J].中南大学学报(英文版),2021,28(5):1422-1447.
[8] 邢俊利,豆长江.藏族中学生成就目标对数学成绩的影响:自我效能感的调节作用[J].民族教育研究,2021,32(4):129-134.
【通联编辑:梁书】
猜你喜欢
草原歌声(2020年3期)2021-01-18 06:52:02
草原歌声(2017年3期)2017-04-23 05:13:47
新一代(2016年17期)2016-12-22 12:15:37
新教育时代·教师版(2016年29期)2016-12-05 19:13:37
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
科学与财富(2016年28期)2016-10-14 21:19:17
商(2016年24期)2016-07-20 11:05:18
中国市场(2016年8期)2016-03-07 09:41:18
