
基于DMN的跨模态目标实例分割方法
2022-10-17 11:02熊珺瑶宋振峰
计算机工程与应用 2022年20期
熊珺瑶,宋振峰,王 蓉
中国人民公安大学 信息与网络安全学院,北京 100038
目标实例分割[1-2]是对输入图像中每个具体对象的位置标签进行预测的任务,实现不同对象的区分。早期的分割技术包括基于边缘的图像分割、基于阈值的图像分割、基于区域的图像分割等[3],这些方法的分割结果存在无边缘特征,噪声严重,被分割区域大小与实际目标不符等问题。近年来,基于深度学习[4]的目标实例分割技术得到广泛应用,这类方法通过RCNN[5]框架对图像数据的复杂处理抽象出细粒度特征,输出与输入图像同分辨率的二进制掩膜图,由于RCNN训练是多阶段的,每一阶段需要分开训练,难以优化,Fast RCNN[6]和Faster RCNN[7]框架的出现也逐渐解决了这一问题。但是,这些算法单单基于视觉特征对目标实例进行分割,仅仅考虑了目标的外观属性,当目标处于遮挡或者复杂背景的情况下,分割结果往往与实际情况不符。
跨模态实例分割以图片和自然语言指代表达式[8]为输入,通过自然语言指代表达式对图像中特定目标进行精准定位,分割出特定目标。跨模态实例分割不仅对目标外观属性进行提取,同时考虑了目标的动作、空间位置以及与其他对象的关系,特征更丰富,目标实例分割结果更准确。如何实现视觉语言两种模态的关联是跨模态实例分割任务中最重要的问题。Lu等人[9]提出了基于BERT(bidirectional encoder representation from transformers)[10]的视觉语言双流预训练模型,将BERT架构扩展到多模态,通过共同注意转换层将多模态信息进行交互,进而转移到多个不同的视觉语言任务中,实现视觉语言两种模态信息的交互;Yu等人[11]提出一个模块化网络,将指代表达式分解为目标外观、位置以及与其他对象关系的三个模块,网络分别学习三个模块的权重和注意力,计算三个模块与图像中对应部分的匹配分数,找出最高的匹配分数,更好地处理图像中不同对象之间的关系;Margffoy-Tuay等人[12]提出的DMN(dynamic multimodal instance segmentation guided by natural language queries)模型,分别对视觉和语言信息进行处理,并将提取的视觉、空间位置以及语言特征进行融合,进一步实现目标实例的分割,更好利用自然语言的上下文信息,获取目标对象的位置、类型以及与其他对象的关系信息。
本文在DMN的基础上提出了一种改进的跨模态目标实例分割方法。针对特征提取在不同的特征通道和空间位置重要性不一致的问题,在特征提取主干网络中引入通道注意力机制和空间注意力机制,动态调整特征表达,使提取出来的特征更具泛化性。其次,针对模型训练过程中批次量对网络性能的影响问题,在网络的归一化层中引入带阈值激活的归一化层FRN[13](filter response normalization layer),与BN[14](batch normalization)实现联合正则,消除网络对批次量的依赖。
1 DMN理论
DMN由一个模块化网络组成,整体框架如图1所示,分为四个部分,分别是视觉特征提取模块、语言特征提取模块、信息融合模块以及上采样模块。首先利用DPN92[15]网络作为视觉特征提取主干网络,SRU[16]作为语言特征提取主干网络;其次,DMN通过处理语言信息生成动态滤波器实现多模态的响应,得到的响应图与视觉特征和空间位置特征通过卷积进行融合;最后利用残差网络的思想实现上采样过程,以一种连续的方式不断融合不同尺度大小的视觉特征,使得分割过程中能获得更加精细的特征。
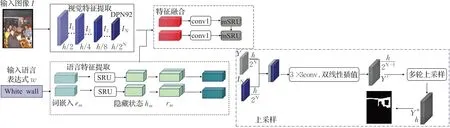
图1 DMN算法整体框架图Fig.1 Overall framework diagram of DMN algorithm
1.1 视觉特征提取模块
视觉特征通过DPN92网络进行提取,视觉特征表达为:

其中,I作为原始图像,In,n∈{1,2,…,N},是在进行特征提取之后的特征映射,N表示生成不同比例大小的特征图的数量,最终输出的特征图维数降低为原图的,在实验中,设置N=5,即使用5层卷积层对视觉信息进行编码。
1.2 语言特征提取模块
SRU作为语言特征提取网络,为整个引用表达式生成单个特征映射和一组动态滤波器,具体方法为:
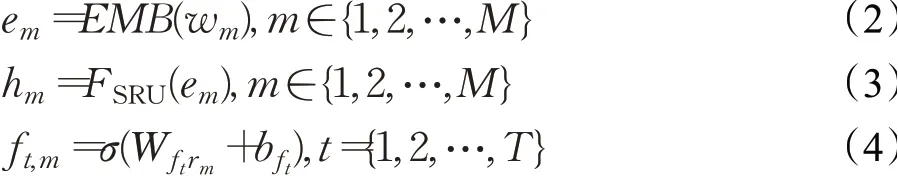
其中由M个单词组合而成的表达式,进行词嵌入操作后得到em,每个单词送入SRU单元得到对应的隐藏状态hm,将词嵌入的结果与隐藏状态结合rm(em,hm),送入多层感知器,生成一组动态滤波器ft,m,Wftrm与bft表示生成每个动态滤波器使用的超参数,σ表示使用sigmoid激活函数,t∈{1,2,…,T},T表示滤波器的数量,实验中设置T=10,表示每个单词生成10个滤波器与视觉特征图进行响应。
1.3 模态信息融合模块
模态信息融合模块是将多模态特征进行交互,首先由视觉特征提取模块得到的特征图I与空间位置特征结合,然后与语言特征模块生成的动态滤波器进行交互计算,得到T通道的响应图Dt,再将第N层卷积层生成的视觉特征图IN与位置坐标特征LOC以及响应图Dt进行结合,得到新的视觉特征表示I′,利用一个1×1的卷积层将信息进行整合[17-18],在每个时间步长得到一个结果Rtime,最后将结果通过多个SRU进行级联,具体方法为:

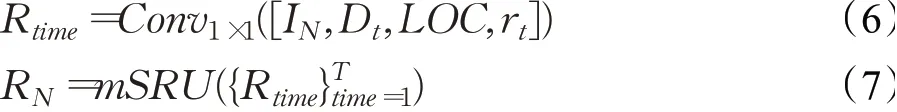
1.4 上采样模块
上采样模块是指将在视觉模块中每个阶段提取的视觉特征与每个时间步长得到的特征图进行融合。具体做法是将每个阶段得到的Rn与In进行连接,结果执行3×3卷积,再通过双线性插值将大小缩放2倍,生成下一阶段的输入,即Rn-1,此过程一共进行lbN次,最终产生于输入I1相同大小的输出掩码,利用1×1的卷积生成单通道的特征值,最终通过线性修正单元(rectified linear unit,Relu)进行激活得到分割结果[19],减少网络中参数的相互依存关系,缓解过拟合的问题,加速网络的收敛。
2 基于DMN模型的改进
DMN利用自然语言特征提取模块和视觉特征提取模块分别提取输入图像和语言的特征,生成动态滤波器实现特征的响应,对网络批次量的依赖性较强。本文基于DMN提出一种改进的跨模态目标实例分割算法,整体框架如图2所示。在视觉特征提取方面,为减小网络对批次量的依赖性,引入滤波器响应归一化层FRN,并与BN联合进行正则化,用于消除深层神经网络训练中对批处理的依赖;为增强通道和空间上的有用特征,抑制噪声,引入CBAM注意力机制[20],使输入特征图沿着通道和空间两个维度进行注意力值的计算和更新,得到自适应细化的特征图。

图2 改进后DMN算法框架图Fig.2 Optimized algorithm framework diagram based on DMN
2.1 FRN与BN联合正则化
BN层是对每一批次数据进行归一化,能够允许更大的学习率,大幅提高训练速度,主要通过假设数据都处于正态分布,将数据进行归一化,优化网络的训练效能。BN解决了梯度消失和梯度爆炸的问题,加快训练速度,提高网络的泛化能力。当任务复杂程度增加时,没有足够的显存存放较多的批量数据,若批次量太小,BN效果会有明显下降。FRN结构使输入特征图仅依赖于宽度和高度两个维度,避免了批次量和通道数对归一化结果的影响,在低批次量条件下性能依旧十分稳定。FRN分为带阈值激活的滤波器响应归一化和阈值线性单元两个部分,结构图如图3所示。

图3 FRN层结构图Fig.3 FRN layer structure diagram
带阈值激活的滤波器响应归一化是对于输入的四元组张量A,元素分别是批次量,图像的宽度和高度以及特征通道数。首先求出向量A在图像宽度高度上的方差V,根据所求v和一个极小的设定的量θ进行正则化,之后对正则化后的参数进行仿射线性变换,以便网络减小标准化的影响,其中γ和β是可通过训练学习到的参数,具体计算方式是:
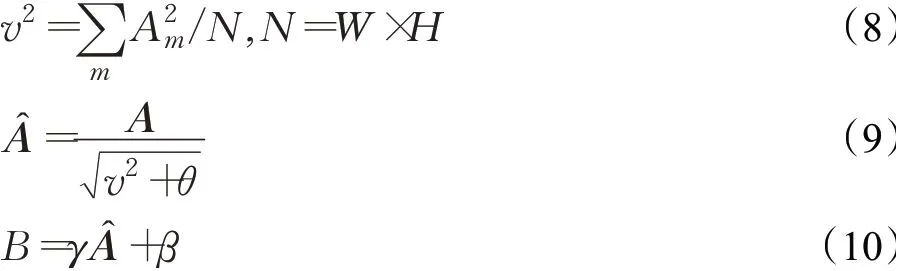
由于在带阈值激活的滤波器响应层中可能出现结果为0的偏差,这种偏差与Relu一起会对训练产生不利的影响,这里引入阈值线性单元来解决这一问题,具体方法如下:

其中,τ是可以通过学习得到的阈值。
本文在BN层中引入FRN正则化,减小网络对批次量的依赖。FRN虽然在自然语言处理网络中取得了成功,但由于在不同的领域还未进行探索,本文仅仅将FRN引入网络的低层,保留了BN层,即FRN与BN层各占一半的通道数,保证网络参数和计算量的同时保留了BN层对网络性能的优化。BN与FRN联合正则化结构图如图4所示。

图4 BN+FRN联合正则化结构图Fig.4 Union of BN and FRN structure diagram
2.2 双通道注意力机制CBAM
CBAM机制,也被称为“卷积块注意模块”,用于前馈神经网络,强调沿着通道和空间两个主要维度上有意义的特征,有效优化网络上特征的提取和信息的传递。机制分为通道注意力模块和空间注意力模块,在这两个模块上学习有用信息,抑制噪声信息,再使用卷积计算将通道注意力信息和空间注意力信息融合在一起。以一个特征图为输入,沿着两个独立的维度产生相应的注意力图,将注意力图与特征图进行点乘,实现自适应的特征细化,最终得到一个新的特征图。将输入特征用X∈RC×H×W进行表示,一次产生一个1维的通道注意力图MC∈RC×1×1和2维的空间注意力图MS∈R1×H×W,具体表示方法为:


其中⊗表示点乘。
2.2.1 通道注意力模块
为了有效地计算通道注意力,要对输入的特征进行池化操作,为获得精密且丰富的空间信息,CBAM机制同时使用平均池化和最大池化功能。通道注意力模块结构如图5所示。
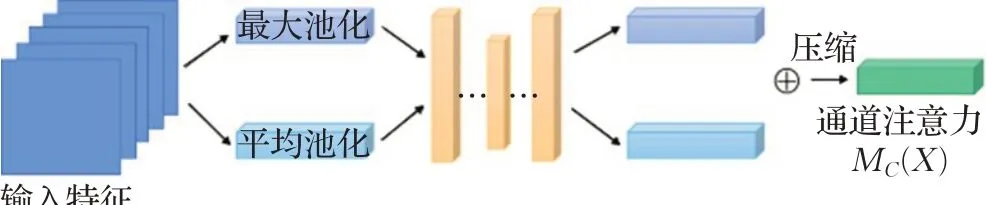
图5 通道注意力模块结构图Fig.5 Channel attention module structure diagram
首先利用平均池化和最大池化的方法来聚合特征图上的信息,生成两个不同的上下文描述符,用和分别表示平均池化和最大池化产生的描述符,将这两个描述符输入到一个共享网络(共享网络由一个带有隐藏层的多层感知器MLP组成,为了减少参数开销,将激活大小设置为表示的是缩减率),对元素进行求和合并得到输出特征向量,通道注意力实现方法具体如下:
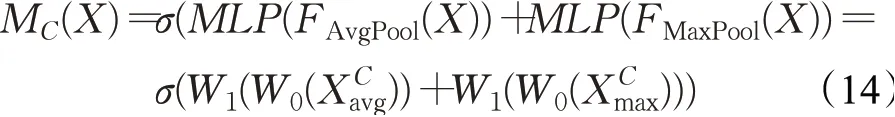
其中,σ表示的是sigmoid函数,MLP表示多层感知器,表示多层感知器中的权重参数,在输入上共享,注意力值经过权值W0处理后通过激活函数Relu。
2.2.2 空间注意力模块
利用特征之间的空间位置关系生成空间注意力图,空间注意力模块如图6所示。
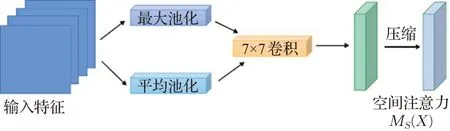
图6 空间注意力模块结构图Fig.6 Spartial attention module structure diagram


其中,σ表示sigmoid函数,f7×7表示一个7×7的卷积运算。
通道和空间注意力模块,分别计算互补的注意力,分别关注具体目标和空间位置信息,两个模块可以并行或以顺序的方式连接,本文采用顺序方式进行连接。
3 实验结果与可视化分析
3.1 数据集
本文在三个数据集上进行了训练和测试:ReferIt[21]、GRef[22]、UNC[23]。这三个数据集都是基于MS COCO[24],主要区别在于自然语言表达式中对象类型、表达式的长度、对象的相对大小。这些特征在这三个数据集上具有高度可变性,能对优化网络的泛化能力进行证明。ReferIt目前在19 894个图片中包含130 525个表达式,涉及目标数有96 654种;GRef数据集包含26 711幅图像,85 474个引用表达式,涉及目标数有54 822个;UNC数据集选择的图像包含两个或多个相同对象类别的对象,共收集19 994幅图像,142 209个表达式,涉及目标数有50 000个。
3.2 仿真环境
本文实验在NVIDIA GTX2060Ti GPU上使用Pytorch框架进行训练和测试。训练总轮数设置为30,利用Adam优化器[25]进行优化,初始学习率设置为1×10-5,第二个时期学习率设置为1×10-6,批次量设置为一个图像描述对。
3.3 仿真实验与可视化
实验1将CBAM模块引入DPN92网络,分别在ReferIt数据集GRef数据集和UNC数据集上对改进模型使用mIou(mean intersection over union)指标进行性能评价,mIou在实例分割应用中计算每个实例真实值和预测值之间的交并比,之后取平均,计算如下:
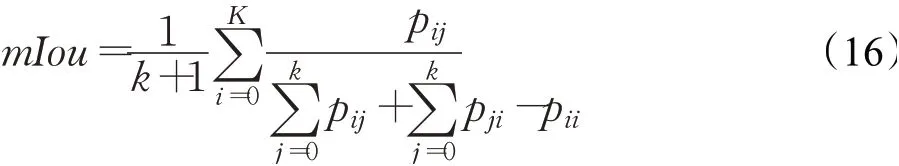
其中,k表示目标实例对象个数,i与j分别表示真实值和预测值,则pii表示结果预测为真实,pij表示预测值与真实值不相符,pji表示预测值为真实值,即预测结果正确。
实验2将FRN引入了正则化层,与BN进行联合正则化,共同引入DPN92网络中,分别在ReferIt、GRef数据集与UNC数据集上对改进模型使用mIou指标进行性能评价。
实验3将CBAM注意力模块和FRN+BN联合正则化共同引入DPN92网络中,在ReferIt,GRef与UNC数据集上使用mIou指标进行性能评价。
实验1、2、3评估结果如表1所示,可以看出引入CBAM注意力机制后,ReferIt、GRef数据集在mIou指标上分别提升了1.77和0.36个百分点,在UNC数据集的val、testA、testB上进行评估,分别提升了1.39、1.04和1.75个百分点;引入FRN+BN联合正则化的模型在精度上提升较小,在ReferIt、GRef数据集上进行评估分别提升了1.69和0.21个百分点,在UNC数据集的val、testA、testB上进行评估,分别提升了0.95、1.12和1.44个百分点;引入CBAM注意力机制和联合正则化的改进模型在mIou指标上都有提高。在ReferIt、GRef数据集上进行评估分别提高了1.85和0.52个百分点,在UNC数据集的val、testA、testB上进行评估,分别提升了1.98、2.22和2.75个百分点。
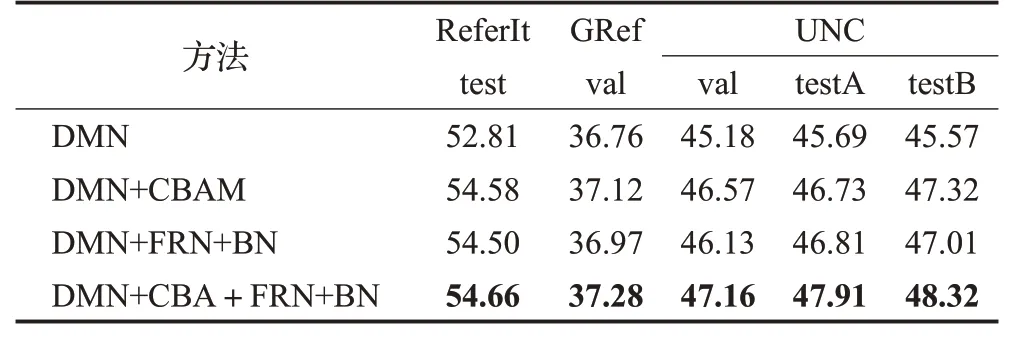
表1 实验评价结果Table 1 Evaluation results of experiment单位:%
为评估改进模型在目标实例分割上的效果,对上述实验进行可视化分析,实验结果如图7所示,输入指代表达式为dark looking guy on the right。其中图(a)、(b)、(c)、(d)分别表示原图像、真实图像掩膜、改进前模型生成的分割热图和改进后模型生成的分割热图,从图7(c)、(d)可以看出改进前改进后的模型相较改进前模型效果更优。

图7 目标实例分割效果图Fig.7 Segment result on object
为评估改进后模型的时间性能,记录下每一轮训练的时长,时间性能比较图如图8所示,曲线图分别描述了在本文实验环境下的原模型每轮训练时长以及改进后模型的每轮训练时长,横坐标表示训练轮数,纵坐标表示时长,可以看出,改进后的模型相较改进前模型训练时间有小幅度增加。
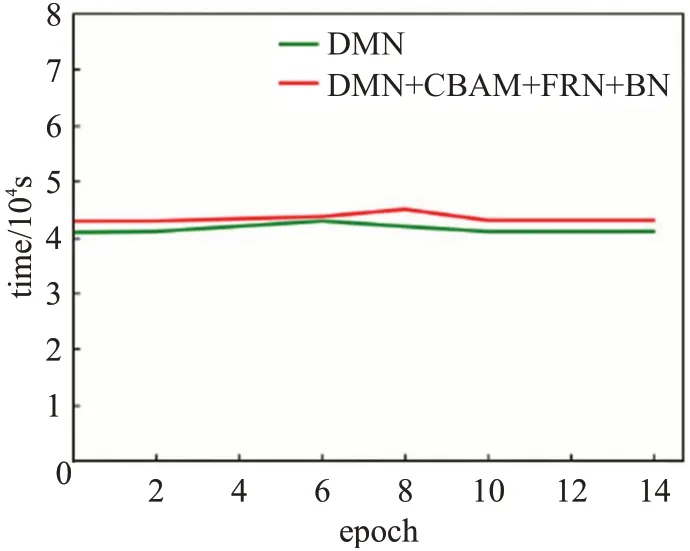
图8 时间性能比较图Fig.8 Time performance comparison
将改进的方法与跨模态实例分割的其他方法进行比较,在ReferIt、GRef以及UNC数据集上优于原模型,可以证明改进方法的有效性。对比评价结果如表2所示。
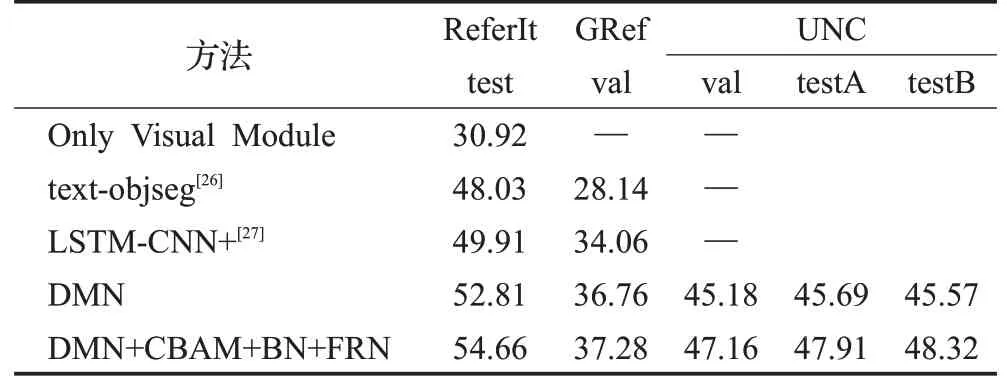
表2 改进的方法与其他指称表达方法的对比评价Table 2 Comparison results between improved method and latest referring expression segmentation method单位:%
4 结束语
本文提出了一种优化的跨模态目标实例分割方法,在DMN基础上,对主干网络DPN92进行了改进,并在ReferIt、GRef与UNC三个数据集上进行实验,以mIou评价指标进行评价。通过引入CBAM注意力机制,分别在通道和空间两个维度上强调有用特征,抑制无关的噪声,实验证明在前两个数据集上分别提升了1.77和0.36个百分点在UNC的三个验证集上分别提升了1.39、1.04和1.75个百分点;其次,引入FRN与BN的联合正则,改善了批次量对网络性能的影响,实验证明在前两个数据集上分别提升了1.69和0.21个百分点,在UNC的三个验证集上分别提升了0.95、1.12和1.44个百分点;最后将CBAM注意力机制与联合正则化同时引入网络中,实验证明,改进后模型在前两个数据集上分别提升了1.85和0.52个百分点,在UNC的三个验证集上分别提升了1.98、2.22和2.75个百分点。对改进的跨模态实例分割方法进行可视化实验和时间性能的评估,结果表明,改进后的模型在与改进前模型在训练时长相差不大的情况下,分割效果更佳。
由于数据集较大,且跨模态模型较复杂,需要处理两种模态的信息并进行响应计算,实验训练耗时时间较长,下一步将结合轻量级网络并减少实验参数对网络模型进行优化。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小学教学研究(2022年18期)2022-06-29
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年9期)2022-05-20
计算机研究与发展(2022年1期)2022-01-19
成长·读写月刊(2018年8期)2018-08-30
电机与控制学报(2018年9期)2018-05-14
计算机应用(2016年10期)2017-05-12
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
