
增强细节的RGB-IR 多通道特征融合语义分割网络
2022-10-16 12:27:46谢树春陈志华盛斌
计算机工程 2022年10期
谢树春,陈志华,盛斌
(1.华东理工大学 信息科学与工程学院,上海 200237;2.上海交通大学 电子信息与电气工程学院,上海 200240)
0 概述
遥感图像中包含非常丰富的地物信息,遥感图像的利用价值在于可对其进行重要信息的提取,但处理过程也非常复杂。遥感图像语义分割是提取遥感图像重要信息的前提,也是学术界和工业界的研究难点。遥感图像覆盖范围广,地物信息复杂多样,存在很多的小地物类别,使得分割难度加大,并且存在类间相似性和类内差异性问题,进一步加大了分割难度。
全卷积神经网络是目前实现图像语义分割的主流方法。基于全卷积神经网络提出的FCN[1]是深度学习应用在图像语义分割的代表方法,其为一种端到端的分割方法,应用于图像语义分割领域时得到了很好的效果。SegNet[2]和U-Net[3]是对FCN 的改进,SegNet 引入了更多的跨层连接,U-Net 在上采样阶段依然保留有大量的通道,使得网络可以将上下文信息向更高层分辨率传播。ERFNet[4]使用残差连接来加速特征学习以及消除梯度消失的现象,并使用深度可分离卷积来减少网络的参数数量,提高模型推算速度。SKASNet[5]构建了一个新的残差模块,通过调节感受野的大小获得多尺度信息。DeepLabv3+[6]引入语义分割常用的编解码结构并使用可任意控制编码器提取特征的分辨率,通过空洞卷积平衡精度和耗时。现有的遥感图像语义分割方法主要对上述模型进行微调与改进。文献[7-8]将基于U-Net 改进的网络结构用于遥感图像上进行语义分割时获得了可观的效果。RWSNet[9]将SegNet 和随机游走相结合,缓解了分割对象边界模糊的问题。
近年来,研究者设计了很多用于提高语义分割网络性能的模块,如受到广泛关注的注意力机制。注意力机制可以在网络训练过程中加强对一些重要特征区域或者重要特征通道的注意力,提升网络对特征的表达能力。在SENet[10]中,压缩、激励和重标定三个部分组成注意力机制,使网络利用全局信息有选择地增强有用特征通道并抑制无用特征通道,实现特征通道自适应校准。CBAM[11]将注意力机制同时运用在通道和空间两个维度上来提升网络模型的特征提取能力。卷积神经网络中的卷积单元每次只关注邻域卷积核大小的区域,是局部区域的运算。文献[12]提出了Non-local Neural Networks 用于捕获长距离关系。文献[13]在特征提取网络中加入注意力模块来减少分割精度损失。文献[14]基于U-Net改进通过注意力机制以提高模型的灵敏度,并抑制无关特征区域的背景影响。文献[15]通过全局注意力金字塔与通道注意力解码器来解决地物小和类内尺度存在差异的问题。
特征融合也是一种提高分割性能的流行方法。高层语义特征具有大的语义结构,但对小结构丢失严重,低层细节特征保留了丰富的细节信息,但语义类别信息很差。文献[16-17]通过设计一个优秀的特征融合方法进一步提高了网络的分割性能。FPN[16]最初用于目标检测任务,但是也可以应用于语义分割,通过按元素相加的方式来融合全局和局部特征,而PSPNet[17]特征融合更强调全局特征,文献[18]则提出了一种增强特征融合的解码器来提高语义分割模型的性能。遥感图像语义分割网络需要设计优异的特征融合方法来加强高低层特征的融合,对此,文献[19]通过高层语义特征和低层细节特征融合来提高模型的分割准确率,文献[20]设计了自适应融合模块(AFM)。一些通过结合边缘检测[21]和融入深度信息[22-23]的网络模型也能一定程度上提升语义分割的性能。此外,光照不足的条件也会导致RGB 图像质量下降。红外图像可以很好地弥补光照不足等问题,捕捉到更多RGB 图像所缺失的信息。基于RGB-IR(RGB 图像和相对应的Infrared 图像按通道维度叠加后得到RGB-Infrared 图像)的语义分割模 型MFNet[24]、RTFNet[25]通过融合RGB 和红外信息来克服光照不足以及天气条件恶劣等问题,提高了语义分割的性能。
现有基于RGB-IR 的语义分割模型没有很好地将RGB 和红外信息充分融合,也较少提取到RGB 图像相对于红外图像所缺失的信息。本文提出一个细节特征抽取模块来提取RGB 图像和红外图像的细节特征信息同时进行融合,生成更具区分性的特征表示并弥补RGB 图像相对于红外图像所缺失的信息。此外,提出一种特征融合注意力模块来有效融合细节特征和高层语义特征,得到具有更准确语义信息的优化特征图。基于以上模块,构建增强细节的RGB-IR 多通道特征融合语义分割网络MFFNet,通过融合RGB 图像和红外图像,解决现有方法地物边缘分割不准确、小地物分割效果差的问题,同时提升光照不足、恶劣天气条件情况下的分割效果。
1 RGB-IR 多通道特征融合语义分割网络
1.1 细节特征抽取模块
为了解决上文提到的遥感图像语义分割存在的难题,并提高模型的分割性能,需要提取更多的图像细节特征,以便后续融合到高层语义特征中来进一步丰富细节信息。此外,需要将抽取到的RGB 和红外图像的细节特征进行深层次融合,生成更具分辨性的特征表示,弥补RGB 图像相对于红外图像所缺失的信息,提高模型的特征表达能力,进而提升模型的分割性能。本文提出由注意力模块构成的细节特征抽取模块,如图1 所示。
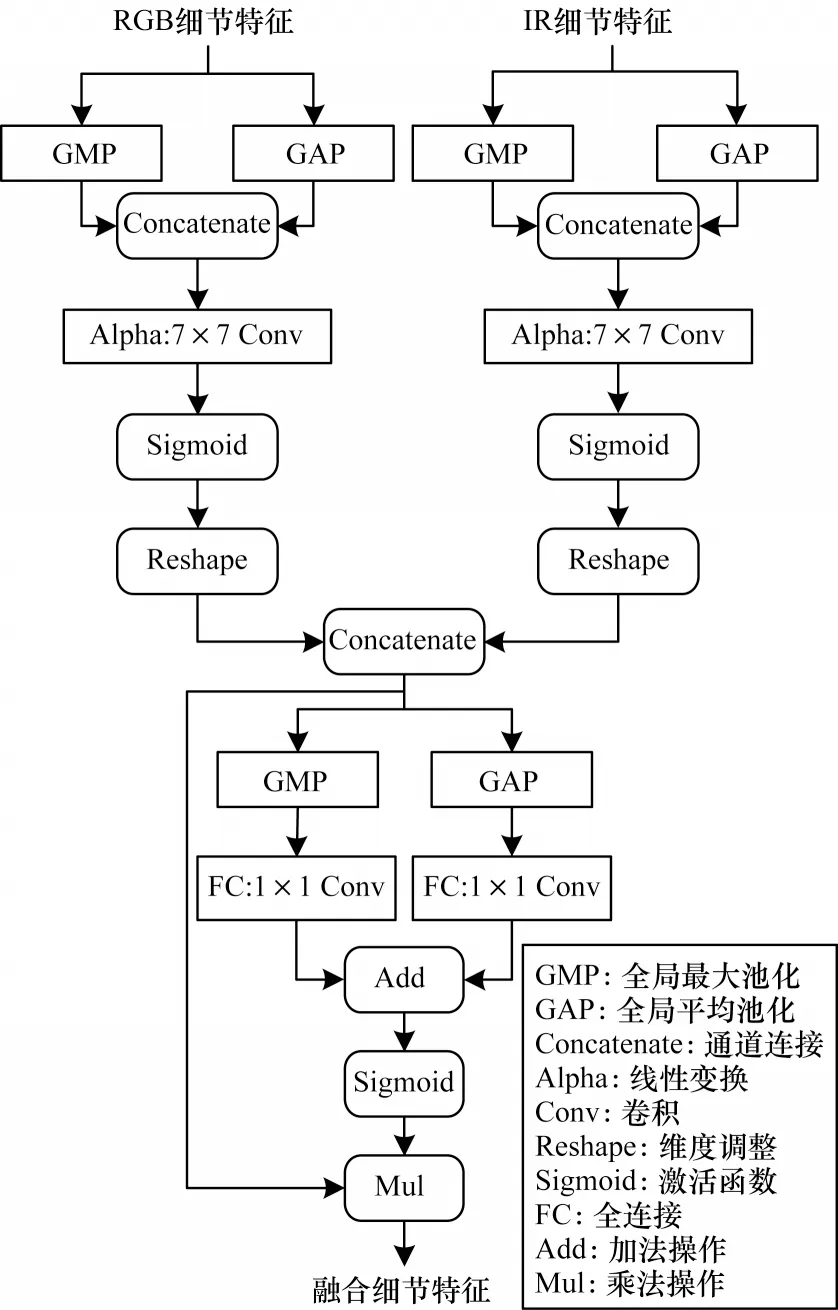
图1 细节特征抽取模块Fig.1 Detail feature extraction module
细节特征抽取模块首先对某一阶段的特征图X(X是从RGB 或红外图像中提取到的特征图)分别进行全局平均池化操作和全局最大池化操作,然后对得到的结果进行拼接操作,再进行Alpha 线性变换得到Alpha 特征,之后通过一个Sigmoid 激活函数来得到注意力权重以加强对重要特征区域的注意力,最后和特征图X相乘得到优化后的特征图Y。由于细节特征抽取模块是接在低层卷积层后的,因此Y包含了非常丰富的细节信息,并且一些重要的细节特征也是被加强的,此计算过程和文献[11]中的空间注意力相似,计算公式如下:

其中:X为输入特征图;Wα是可学习的权重矩阵,通过空间域的7×7 卷积实现;AvgPool 和MaxPool 分别为全局平均池化操作和全局最大池化操作。
分别对同一阶段RGB 和红外图像中提取到的特征图Xrgb、Xir进行上述计算得到Yrgb、Yir,然后再对这两个优化后的细节特征图采用拼接操作进行融合,再通过通道注意力来自适应地为通道重新分配不同的权重,以优化融合后的细节特征图,最终得到融合细节特征图Z。此过程的计算公式如下:

其中:σ为Sigmoid 激活函数为2D 卷积操作,卷积核大小为1×1,通道数从c减为为2D 卷积操作,卷积核大小为1×1,通道数从c/r增加到c,r为减少率;AvgPool 和MaxPool 分别为全局平均池化操作和全局最大池化操作。
至此,已经从RGB 图像和红外图像中抽取到了细节特征信息,并且得到了融合后的细节特征图。然后需要把这些融合后的细节特征图整合到高级语义特征中来增加丰富细节信息,以优化网络的特征表达能力,从而提高模型的灵敏度。
1.2 特征融合注意力模块
本文提出的特征融合注意力模块不像其他网络那样简单地将低层细节特征和高层语义特征进行相加或者拼接,这样做会把干扰或者无关信息同时也融合到高层语义特征中,并且不能很好地融合高低层特征。本文把通过细节特征抽取模块得到的RGB和红外图像融合后的细节特征通过特征融合注意力模块来融合进高层语义特征,从而在和高层语义特征进行融合时抑制干扰或者避免无关细节信息的影响,突出重要关键细节特征。此外,本文在特征融合注意力模块中嵌入通道注意力模块,产生更具分辨性的特征表示,以提高网络的灵敏度。
特征融合注意力模块如图2 所示。融合高低层特征的操作一般有拼接操作和相加操作。首先采用拼接操作来结合高低层特征,并通过一个卷积核大小为1×1 的卷积层来减少通道数,提高模型的推理速度,然后经过一个卷积核大小为3×3 的卷积层,最后通过一个通道注意力机制生成新的特征图Xfuse。

图2 特征融合注意力模块Fig.2 Feature fusion attention module
特征融合注意力模块的计算公式如下:
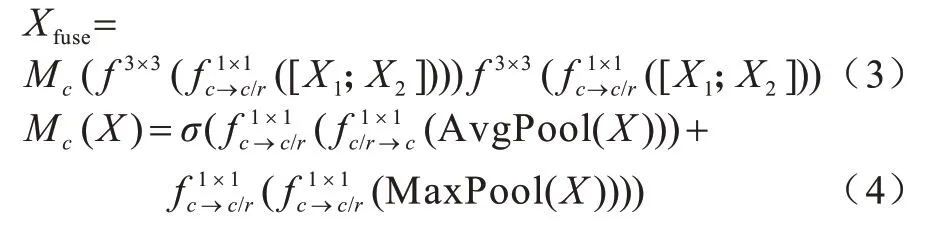
其中:X为输入特征图;σ为Sigmoid 激活函数为2D 卷积操作,卷积核大小为1×1,通道数从c减为为2D 卷积操作,卷积核大小为1×1,通道数从c/r增加到c,r为减少率;AvgPool 和MaxPool 分别为全局平均池化操作和全局最大池化操作;X1为细节分支生成的低层细节特征图;X2为高层特征图;f3×3为2D 卷积操作,卷积核大小为3×3,此卷积操作后跟随有BatchNorm 操作和ReLu 操作。
特征融合注意力模块融合细节特征抽取模块得到的RGB 和红外图像融合后的细节特征和高层语义特征,在每一次上采样阶段前都采用特征融合注意力模块进行特征融合来丰富细节信息和上下文信息,保证像素语义分类准确,同时优化小地物的分割效果,进一步提高模型的分割准确率,使网络模型更好地定位到边界。
1.3 多通道特征融合网络
本文基于细节特征抽取模块和特征融合注意力模块,提出一种增强细节的RGB-IR 多通道特征融合语义分割网络MFFNet,如图3 所示。

图3 MFFNet 网络结构Fig.3 Network structure of MFFNet
MFFNet 包括细节分支和语义分支这两个分支。细节分支通过细节特征抽取模块从RGB 图像和红外图像中抽取到细节特征信息,并且得到融合后的细节特征。语义分支使用轻量级的残差网络ResNet18 作为主干网络,从而进行快速下采样以提取高层语义特征。得益于BiSeNet[26]的启发,本文在语义分支中还利用了一个注意力优化模块来优化输出特征,注意力优化模块结构如图4 所示。最后,在MFFNet的上采样阶段把融合后的细节特征通过特征融合注意力模块整合到高级语义特征中来增加丰富细节信息,以优化网络的特征表达能力,从而提高模型的灵敏度。

图4 注意力优化模块Fig.4 Attention optimization module
1.4 损失函数
为了更好地指导模型训练进而提高地物边界的分割效果以及模型整体的分割性能,受文献[27]的启发,本文在遥感图像语义分割常用的交叉熵损失函数基础上加权边界损失[27]和Jaccard 损失。在损失函数中,加权边界损失可以指导模型训练进一步生成更好的地物边界分割效果。通过在损失函数中加权Jaccard 损失直接指导模型训练,能够有效提高模型整体的分割性能。
交叉熵损失函数是目前流行的语义分割任务中使用的损失函数,用于指导模型进行训练。交叉熵损失函数Eloss的定义如下:

其中:N是小批量样本的数量是样本n分类为c类别的softmax 概率;是以one-hot 编码时相应样本类别的标签;C是所有类别数。
交叉熵损失函数通过对所有像素的求和计算得出,不能很好地反映不平衡类。中位数频率平衡加权交叉熵损失函数考虑到了不平衡类问题,通过在训练集中统计类别的中位数频率和实际类别频率的比率来进行加权损失。中位数频率平衡加权交叉熵损失函数的定义如下:

其中:wc是类别c的权重;fc是类别c的像素的频率;median(fc|c∈C)是所有fc的中位数。
边界损失函数建立在边界度量边界F1得分的基础上,因此,应先定义边界准确率和边界召回率。边界准确率P和边界召回率R分别定义如下:
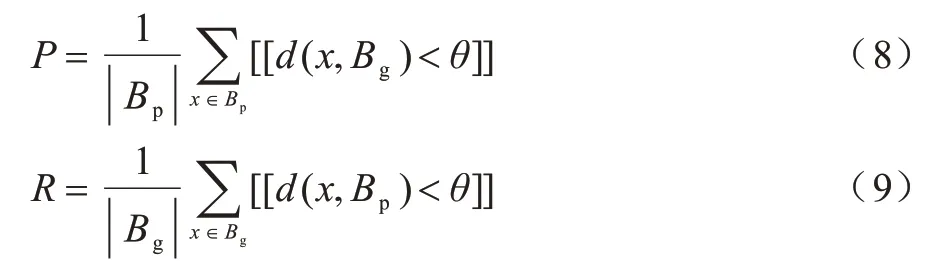
其中:Bp表示预测边界;Bg表示真实标签边界;θ是预定义的阈值,实验时默认取3;[[·]]表示逻辑表达式的指示函数。
边界度量边界F1得分和边界损失函数Bloss定义如下:

Jaccard 损失函数Jloss定义如下:

其中:yp和yg分别表示预测标签和真实标签。
总的损失函数Lloss定义如下:
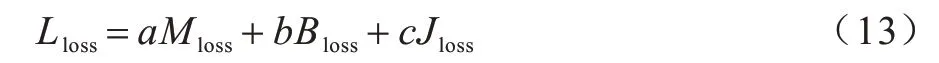
其中:a、b和c分别是中位数频率平衡加权交叉熵损失、边界损失和Jaccard 损失相应的权重系数。
2 实验与分析
2.1 数据集
实验使用的测试基准数据集是由国际摄影测量与遥感协会(ISPRS)组织发布的Postdam 数据集。摄影测量学的研究方向之一是从机载传感器获取的数据中自动提取城市物体。这项任务的挑战性在于,在高分辨率的图像数据中,诸如建筑物、道路、树木和汽车之类的地面物体,同类对象有着非常不同的外观,这导致了较大的组内差异,而组间差异却很小。Postdam 数据集包括6 种地面物体:不透水地面(例如道路),建筑物,低矮植被、树木,汽车,杂物。Potsdam 数据集包含38 张高分辨率的RGB 和IR 遥感图像,图像分辨率大小均为6 000×6 000 像素。图5 所示为Postdam 数据集的部分示例图。

图5 Postdam 数据集的部分示例图Fig.5 Part of sample images in Postdam data set
2.2 评价指标
平均交并比(Mean Intersection over Union,MIoU)是语义分割的标准评价指标,整体准确率、精确率、召回率和F1 分数是遥感图像语义分割最常用的评价指标。本文使用平均交并比、整体准确率、精确率、召回率和F1 分数来度量本文提出的模型。平均交并比是对每一类预测的结果和真实值的交集与并集的比值求和平均的结果,交并比(Intersection over Union,IoU)利用混淆矩阵得到,计算公式如下:

其中:TP代表真阳性,表示某一给定类别中被正确分类的像素数;FP代表假阳性,表示被错误分类到特定类别的其他类别的像素数;FN表示假阴性,表示一个给定类别被错误分类为其他类别的像素数。
整体准确率是正确标记的像素总数除以像素总数。精确率PPrecision、召回率RRecall以及F1 分数F1利用混淆矩阵得到,计算公式如下:

2.3 实验结果与分析
本文模型使用开源库PyTorch 1.7.1 和torchvision 0.8.2 实现,实验使用NVIDIA 公司的GeForce RTX 090 GPU,24 GB 的内存,CUDA 的版本是11.2。本文提出的模型是轻量级的,在训练时设置mini-batch大小为48,使用Adam 作为优化算法应对梯度下降问题,学习率大小设置为5×10-4,权重衰减因子设置为2×10-4,学习率衰减因子设置为0.1,每训练120 个epoch 调整学习率,共训练200 个epoch。
为了验证本文提出的MFFNet 模型对RGB 遥感图像和红外遥感图像融合的有效性,以及是否能够提高小地物和边界的分割效果,在公开的Potsdam 数据集上进行实验。Potsdam 数据集被广泛用于评估遥感图像语义分割模型的性能,包含38 张高分辨率的RGB 遥感图像和相对应红外遥感图像,每张图像分辨率大小为6 000×60 000 像素。本文将该数据集图像分为20 张训练图像、10 张验证图像和8 张测试图像,然后进行数据预处理,通过裁剪20 张训练图像,每张图像都用滑动窗口的方法进行裁剪,步长为滑动窗口的大小,获得225 张400×400 像素的图像,共得到4 500 张训练图像,然后再进行数据增强操作(包括旋转、模糊、添加噪声等)扩充一倍训练数据集,最后共得到9 000 张400×400 像素的训练图像。使用同样的滑动窗口方法裁剪验证集图像和测试集图像,得到2 250 张400×400 像素的验证集图像和1 800 张400×400 像素的测试集图像,相对应的红外遥感图像也以同样的方式进行裁剪。
本文使用平均交并比、整体准确率、精确率、召回率和F1 分数来评估MFFNet,实验结果如表1 所示,其中,加粗数据表示最优值,3c 表示网络是三通道,输入只有RGB 图像,4c 是将RBG 和IR 通道叠加作为输入,对比实验的网络模型中RTFNet采用残差网络ResNet50作为主干网络,DeepLabv3+和PSPNet 采用残差网络ResNet101 作为主干网络。对比表1 所有RGB-IR 四通道作为输入的网络模型实验结果可以看出,本文提出的MFFNet模型在上述的各个评价指标上都是最优的,对于语义分割的标准评价指标平均交并比,MFFNet较对比模型中最优的模型提升了2.72 个百分点,在其他各个评价指标上,MFFNet较对比模型中最优的模型也都有很大的提升:整体准确率提升1.14 个百分点,精确率提升3.69 个百分点,召回率提升0.04 个百分点,F1 分数提升2.04 个百分点。此外,对比表1 所有RGB-IR四通道作为输入的网络模型实验结果可以看出,本文提出的MFFNet 模型不仅仅是对于整体的分割效果是最好的,而且对于小物体类别车的分割效果在每个评价指标上也是最优的,相对于对比实验中最优的模型而言有非常大的提升:交并比提升7.3 个百分点,精确率提升9.52 个百分点,F1 分数提升4.6 个百分点。

表1 Potsdam 数据集上不同模型的性能对比Table 1 Performance comparison of different models in Potsdam data set %
从表1 中还可以看到,在对比模型中,除PSPNet和UNet 外,其他模型直接把RGB 三通道(3c)图像改为RGB-IR 四通道(4c)图像作为网络输入,不仅不能改善反而还降低了网络模型的分割效果,PSPNet 和UNet 直接把RGB 三通道(3c)图像改为RGB-IR 四通道(4c)图像作为网络输入,在整体分割性能上虽然有略微的一点提升,但对于小地物类别车的分割效果却受到大幅影响。
图6 和图7 为在Potsdam 数据集上的部分实验结果图,从中可以清楚地看到,对比模型不能很好地分割小地物类别车,小地物的边缘分割也是不准确的,并且小区域的分割效果也很差。本文提出的MFFNet 模型对小地物的分割效果明显优于对比模型,小地物的分割效果很好,不存在边缘分割不准确的情况,并且对于小区域的分割效果要好很多。由此可以证明,本文模型不仅可使遥感图像整体的分割效果有很大的提升,对于图像中小地物的分割,效果的提升也是非常明显的。

图6 Potsdam 数据集上的实验的结果图1Fig.6 Experimental result images 1 in Potsdam dataset
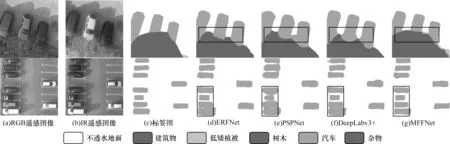
图7 Potsdam 数据集上的实验的结果图2Fig.7 Experimental result images 2 in Potsdam dataset
为了进一步说明本文提出的模型能够有效地整合RGB 图像和红外图像的信息,在Postdam 数据集上进行消融实验,将RGB 和RGB-IR 分别作为MFFNet网络输入。将RGB 作为网络输入时,微调MFFNet网络,去掉IR 细节分支,整体分割性能对比如图8 所示,小地物车类别分割性能对比如图9 所示,其中无填充的柱状图是RGB 图像作为网络输入的实验结果,有填充的柱状图是RGB-IR 图像作为网络输入的实验结果。在表2 中,3c 表示网络是三通道输入只有RGB 图像,4c 是将RGB 和IR 通道叠加作为输入。从表2 中数据的比较可以清楚地看出,本文提出的模型对红外图像融合具有有效性,对于整体的分割效果和小地物的分割性能均较优。
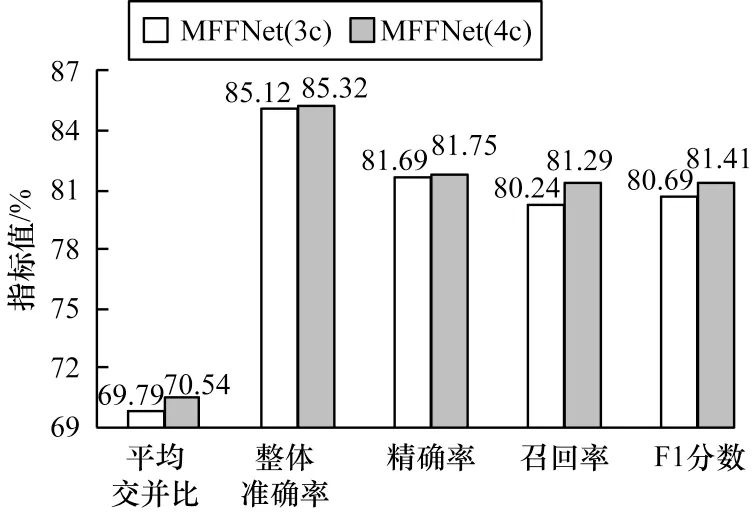
图8 RGB 和RGB-IR 分别作为MFFNet 网络输入的整体分割性能Fig.8 Overall segmentation performance when RGB and RGB-IR as input to the MFFNet network respectively

图9 RGB 和RGB-IR 分别作为MFFNet 网络输入的车类别分割性能Fig.9 Car category segmentation performance when RGB and RGB-IR as input to the MFFNet network respectively

表2 RGB 和RGB-IR 分别作为MFFNet 网络输入的具体性能对比Table 2 Spectific performance comparison when RGB and RGB-IR as input to the MFFNet network %
3 结束语
本文构建增强细节的RGB-IR 多通道特征融合语义分割网络MFFNet,以解决遥感图像语义分割中存在的问题。提出一种能够有效融合RGB 图像和红外图像的细节特征抽取模块,从而获取丰富的融合细节信息,并提出一种新的特征融合方法——特征融合注意力模块,将细节特征抽取模块提取到的融合细节特征充分融合进高级语义特征中,以优化网络的表达能力,提高模型的灵敏度。在Postdam 数据集上的实验结果证明了该模型的有效性。下一步将结合神经架构搜索(Neural Architecture Search,NAS)技术优化细节特征融合模块的结构,加强RGB 图像和红外图像细节特征信息的整合,提高模型的分割性能,同时降低模型的复杂度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
电视技术(2014年19期)2014-03-11 15:38:20
