
基于CNN-Head Transformer 编码器的中文命名实体识别
2022-10-16 12:27史占堂马玉鹏赵凡马博
计算机工程 2022年10期
史占堂,马玉鹏,赵凡,马博
(1.中国科学院新疆理化技术研究所,乌鲁木齐 830011;2.中国科学院大学,北京 100049;3.新疆民族语音语言信息处理实验室,乌鲁木齐 830011)
0 概述
命名实体识别(Named Entity Recognition,NER)是自然语言处理(Natural Language Processing,NLP)中的基础任务,包括关系抽取(Relation Extraction,RE)[1]、事件抽取(Event Extraction,EE)[2]以及实体链接(Entity Link,EL)[3]等下游任务,旨在给定的文本中判定相应实体的类型和该实体对应的左右边界。近些年,随着计算机运算能力的快速提高,深度学习成为命名实体识别的主流研究方法,并将命名实体识别转化为序列标注任务。由于中文词之间不存在潜在的分隔符,并且中文命名实体的边界是词的边界,因此最初中文命名实体识别将分词作为核心,并以词作为深度学习序列标注模型的输入,但该方式存在未登录词以及分词错误的问题,使得基于字嵌入的方式成为中文命名实体识别领域深度学习序列标注模型编码层的主流嵌入方式。
在基于深度学习的中文命名实体识别方法中,长短时记忆(Long Short-Term Memory,LSTM)[4]网络是应用较广泛的特征提取器,但是存在不能充分利 用GPU 并行计算的问 题。ZHANG等[5]提出的Lattice LSTM 通过添加词典信息在提高准确率的同时进一步增加了模型训练和测试时间。基于多头自注意力机制的Transformer[6]的提出缓解了LSTM 存在的问题,并在多种自然语言处理任务中取得了优异表现,逐渐取代了LSTM 成为自然语言处理领域主流的特征提取器,但是YAN等[7]的实验结果表明Transformer 在命名实体识别领域表现欠佳。
本文结合Transformer 编码器和卷积神经网络(Convolutional Neural Network,CNN)[8],提出一种用于中文命名实体识别的CHTE(CNN-Head Transformer Encoder)模型。在多头注意力机制中根据不同窗口大小的CNN[8]增强模型的局部特征和潜在词信息表示,并且利用门控残差连接融合自适应特征以进一步提高识别准确率。
1 相关工作
1.1 LSTM 与CNN
在Transformer 未被提出之前,LSTM 作为自然语言处理领域主流的特征提取器被广泛用于命名实体识别任务。HUANG等[9]使用Bi-LSTM 和条件随机场[10](Conditional Random Field,CRF)进行命名实体识别。PENG等[11]标注了中文社交媒体数据集Weibo,并使用Bi-LSTM 和CRF 在该数据集上进行实验。MA等[12]使用CNN 获取单词的形态学特征并结合单词的词嵌入,通过Bi-LSTM 和CRF 进行序列标注。针对LSTM 不能充分利用GPU 并行计算的问题,STRUBELL等[13]提出基于CNN 的ID-CNNs 模型,由于CNN 仅能获取固定范围内的局部特征,因此该模型通过对CNN 的堆叠逐层增加CNN 的感受野,使其获取全局语义信息,在保障相当F 值的情况下减少了运算时间。
依据中文命名实体的边界是词的边界,LIU等[14]将中文分词(Chinese Word Segmentation,CWS)作为中文命名实体识别的首要任务,但此方法存在分词错误以及未登录词的问题。为了缓解该问题,CAO等[15]依据NER 和CWS 之间的关联关 系,利用两种任务对抗学习的方式提高NER 性能。ZHANG等[5]通过外部词典并在字级别模型的基础上提出添加待抽取句中所有可能词特征的Lattice LSTM,但由于一个字可能匹配多个词造成实体识别错误的问题。GUI等[16]提出基于CNN 的模型,该模型通过重考虑机制自适应地融合句子中可能的词信息缓解了这一问题。此外,针对中文为象形文字特点,MENG等[17-18]提出使用CNN 提取中文字形信息的命名实体识别方法。张栋等[19]通过将每个字符拆解为五笔表示来获取字形特征,增强模型语义信息。尽管LSTM 被广泛应用于命名实体识别任务,但只能进行单方向建模获取单方向语义信息,即使通过双向LSTM 也只是将左右分别获取的单向特征进行拼接,无法完全捕获上下文语义信息。
1.2 Transformer
VASWANI等[6]将基于多头自 注意力机制的Transformer 模型用于机器翻译(Machine Translation,MT)领域,该模型较好地缓解了LSTM 无法充分利用GPU 并行计算以及获取上下文语义信息的问题,使其在自然语言处理领域取得了优异表现。在中文命名实体识别任务中,针对Tansformer 在注意力头的计算过程中会丢失方向和相对位置的问题,司逸晨等[20]提出一种能够保留相对位置和方向信息注意力头的计算方法,并将词级别的特征拼接到嵌入层字级别的特征中增强语义表示。XUE等[21]提出PLTE(Porous Lattice Transformer Encoder)模型,该模型中添加了词级别的嵌入特征以及定义了7 种token 之间的相对位置关系并对每个token 的位置进行编码,同时使用Porous 对自注意力机制进行限制。但是,在PLTE 中相对位置关系的编码方式不能还原出token 之间真实的位置信息,因此这种位置编码方式导致了位置信息的丢失。针对这一问题,LI等[22]提出使用每个词头和词尾的绝对位置来编码任意两个token之间相对位置信息的FLAT(FLATlattice Transformer)模型。上述将词典信息添加到Transformer 的方法同样存在一字多词的问题,而且还会增加额外的存储以及词典匹配时间。
本文在不使用外部词典和分词工具的情况下,利用Transformer 和CNN 在捕获全局语义信息和局部特征以及潜在词信息方面的优势,通过在多个注意力头中融入CNN 充分捕获全局语义信息并增强模型的局部特征以及潜在的词信息表示,同时应用自适应的门控残差连接融合当前层和子层特征,从而提升Transformer 在命名实体识别领域的性能表现。
2 CHTE 模型架构
本文提出的CHTE 模型架构如图1 所示,其中Q、K、V分别表示Tansformer中的Query、Key和Value 向量。该模型主要分为嵌入层、编码层以及解码层3 个部分,首先将输入的文本通过嵌入层获取字级别的词嵌入的向量表示,并在其中添加位置编码特征向量增强模型的位置信息,然后通过编码层获取增强局部特征的输入文本的上下文表示,最后通过解码层对输入文本进行序列标注。
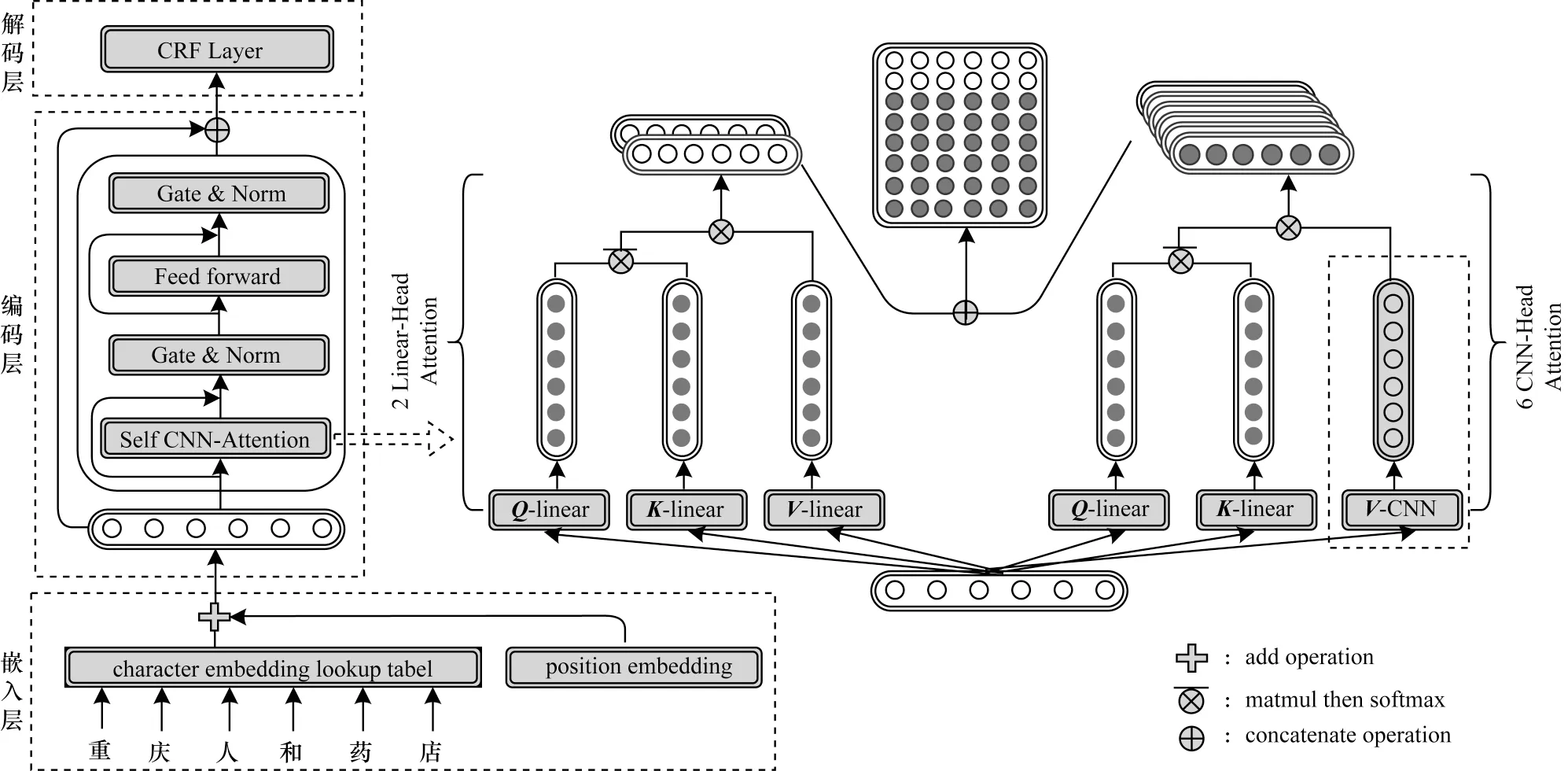
图1 CHTE 模型整体架构Fig.1 Overall architecture of CHTE model
2.1 嵌入层
在中文命名实体识别领域,当前主要的词嵌入方式为字级别、词级别以及两者融合的嵌入方式。词级别的嵌入方式存在分词错误以及未登录词的问题,字词融合的嵌入方式则会增加存储以及词典匹配时间。因此,本文使用字级别的词嵌入方式。
本文使用文献[5]中预训练的字级别词向量,假设模型的输入为s=(c1,c2,…,cn),其中cj表示输入句子s的第j个字,通过查表操作获取该字的特征表示为=[ec(cj);eb(cj,cj+1);eb(cj-1,cj)],其中,[;]表示向量的拼接,ec为字级别特征的查表操作,eb为bi-gram的查表操作,eb(cj,cj+1)表示以第j个字开始的bigram 特征,eb(cj-1,cj)表示以第j个字结束的bi-gram特征。使用Transformer 中的位置编码方式,获取位置j的位置编码特征,并将字级别的特征和位置特征相加得到嵌入层对文本句子的特征表示:
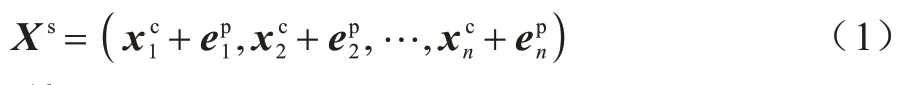
2.2 编码层
Transformer 作为使用多头自注意力机制的特征提取模型,缓解了RNN 无法充分利用GPU 平行计算以及长距离文本依赖的问题。本文依据其在实体识别任务中不能充分获取局部特征,对Transformer Encoder 中的多头自注意力机制进行改进,在保留2 个注意力头不变的情况下,将剩余6 个注意力头的Value 向量分别使用不同窗口大小的CNN 获取。注意力头的计算如式(2)~式(4)所示。保留原始Transformer 的2 个注意力头中Vl的计算如式(5)所示。剩余6 个注意力头首先使用dh个卷积核获取第j个字对应窗口大小为l的局部特征,然后通过池化层进行步长为2 的最大池化操作得到该字的特征表示,并利用滑动窗口获取每个注意力头中的Vc,计算公式如式(6)、式(7)所示。

其中:Wc,bc分别为卷积操作的卷积核以及偏移;表示向下取整操作。
将2 个线性注意力头和6 个CNN 注意力头得到的结果进行拼接,获得自注意力层对文本的特征表示=[Att(A,Vl);…;Att(A,Vc)],Transformer 中使用残差连接是为了将子层特征Xs和当前层特征直接相加,这种直接相加的方式赋予两个特征相同的权重,不能自适应地选择子层和当前层中对实体识别重要的特征信息。本文提出的门控残差连接通过在残差连接中融入门控机制,即首先通过门控机制计算门控得分G,然后通过该得分自适应子层特征和当前层特征(如式(8)、式(9)所示),之后将门控残差连接的结果进行归一化,最后分别通过前馈神经网络层、门控残差连接以及归一化操作后和嵌入层的特征Xs进行拼接,得到输入序列s最终的特征表示U(如式(10)所示)。

其中:为残差连接的输出。

其中:uj表示句子中第j个字经过编码层后的最终特征表示。
2.3 解码层
在基于深度学习的命名实体识别中,CRF 成为主流解码器,将实体识别问题转化为序列标注问题,通过状态转移概率来限制相邻标签之间的关系,进一步提高了命名实体识别的准确率。本文使用CRF作为模型的解码器,对于输入句s=(c1,c2,…,cn)标记为Y=(y1,y2,…,yn)的概率计算如式(11)所示:
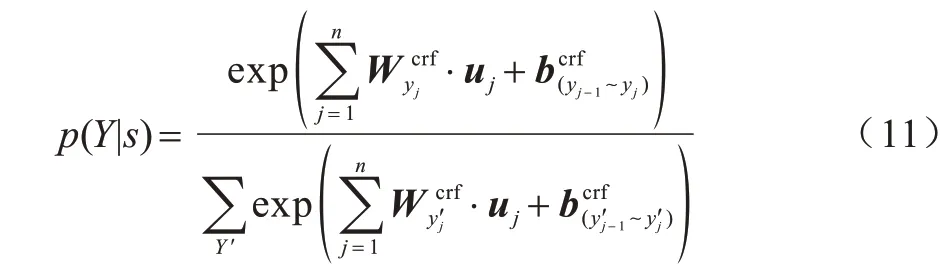
其中:为对应于uj的可训练权重参数为yj-1~yj的状态转移得分;Y′为输入句s所有可能的标记序列,通过Viterbi 算法查找最终的标记序列;Y为真实标记。
本文提出的CHTE 模型的损失函数是将概率p(Y|s)最大化,如式(12)所示:

3 实验设置与结果分析
3.1 数据集选取
选取Weibo 和Resume 数据集进行实验,其中Weibo 数据集[11,23]是从社交媒体新浪微博获取并标注的数据集,Resume 数据集[5]是从新浪金融网页中获取并标注的来自中国股票市场上市公司高级管理人员的简历数据集。本文采用文献[5]中的数据集划分方式,详细的数据集统计信息如表1 所示。

表1 数据集统计信息Table 1 Dataset statistics
3.2 参数设置
采用BMESO(Begin,Middle,End,Single,Outside)进行序列标注,使用精确率、召回率、F1 值作为评估指标,在使用预训练词嵌入和BERT 预训练语言模型两种情况下进行实验。通过验证集对模型中超参数进行调整,为防止过拟合,嵌入层和全连接层中的Dropout 分别设定为0.3 和0.2,注意力头中CNN 的窗口大小设定为(2,3,4,5,6,7),Batch 设定为16。依据FLAT 给定的注意力头的维度范围进行调整,并将前馈层的维度使用和Transformer 相同的设定,即8 个注意力头维度和的3 倍。在使用预训练词嵌入的情况下,需要重新学习模型的参数,因此学习率设定为1e-3。在Weibo 数据集中每个注意力头的维度设置为16,前馈层的维度设置为384,在Resume 数据集中两者分别设置为18 和432。在使用BERT 预训练语言模型的情况下,在BERT 的基础上微调,因此学习率设定为4e-5,当以BERT 作为嵌入层时,通过实验发现若输入CHTE 模型的维度小于768 时性能会下降,因此为了保持模型的性能以及计算量将模型的输入维度设定为768,即每个注意力头维度设置为96,前馈层的维度设置为2 048。
3.3 结果分析
本文分别与使用外部词典的命名实体识别模型、未使用外部词典的命名实体识别模型以及基于BERT 的命名实体识别模型进行比较。以未使用外部词典的命名实体识别模型TENER、使用外部词典的命名实体识别模型Lattice LSTM 以及预训练语言模型BERT 作为基础模型。使用与文献[5]相同的预训练字向量和词典YJ,对比实验数据均来自各模型的原文献。
3.3.1 对比模型选取
对比模型主要分为基于词嵌入的命名实体识别模型和基于字嵌入的命名实体识别模型两类。除了Word-based 和+char+bichar LSTM 是基于词嵌入的命名实体识别模型以外,其他均是基于字嵌入的命名实体识别模型,其中,+bichar+softword 是在charbased 模型上添加了bi-gram 潜入特性以及分词标记特征,Lattice LSTM、FLAT 是添加了词典信息且识别效果较好的模型,CAN-NER 和TENER 是未使用词典但效果较好的模型,FLAT 和TENER 是基于Transformer Encoder 的变换模型,FGN 是基于BERT的效果较好的模型。本文选取以上对比模型是为了说明本文提出的CHTE 模型在使用和未使用BERT作为嵌入层的情况下都能得到较好的识别结果。对比模型具体描述如下:
1)Word-based:以词作为嵌入的基本单位,并以Bi-LSTM、CRF 作为编码器和解码器。
2)+char+bichar LSTM:将字级别特征以及bi-gram字级别特征作为Bi-LSTM 的输入,并将字级别特征和对应词级别的特征拼接作为解码器CRF 的输入。
3)Char-based:对单个字进行嵌入,未使用词典信息。使用Bi-LSTM 作为编码器,CRF 作为解码器。
4)+bichar+softword:在字级别词嵌入的基础上添加了bi-gram 嵌入特征以及分词标记的嵌入特征。
5)Lattice LSTM:以字作为嵌入的基本单位,并将所有出现在词典中的词嵌入添加到序列中以该词开始和结尾的两个字中。使用Bi-LSTM 和CRF 作为编码器和解码器。
6)FLAT:将输入句子中存在的所有可能的词信息的相对位置跨度编码融入到Transformer 的多头注意力计算中。
7)CAN-NER[24]:使用卷积注意力获取字级别特征,并使用GRU 和全局自注意力机制获取相邻字的特征。
8)TENER[7]:针对Transformer 对位置不敏感的问题,提出一种能够捕获方向和位置的注意力计算方式,通过位置信息能够进一步增强命名实体识别的效果。
9)FGN[18]:将BERT 获取的字级别特征中融入通过CNN 获取的有助于实体识别的字形特征,并将LSTM+CRF 作为解码器。
3.3.2 基于预训练词嵌入的模型性能对比
在Weibo 和Resume 数据集上的命名实体识别结果如表2 所示,其中,最优指标值用加粗字体标示,N 表示未使用外部词典。在Weibo 数据集上,Char-based 模型相较于Word-based 模型的F1 值提高了5.44 个百分点,在Char-based 模型中添加2-gram 的字级别词嵌入和分词标记的特征信息后得到+bichar+softword 模型,其F1 值相较于Char-based 模型提升了3.98 个百分点,在Word-based模型中添加了字级别特征表示后的+char+bichar LSTM 模型的性能显著提高,但其F1 值还是低于Char-based 模型0.44 个百分点,本文CHTE 模型相较于未使用词典的TENER 模型的F1 值提高了4.39 个百分点,相较于使用词典的Lattice LSTM 模型的F1 值提高了3.77 个百分点,相较于融合外部词典的FLAT 模型的F1 值提高了2.24 个百分点。在Resume 数据集中,CHTE 模型相较于未使用词典的TENER 模型的F1 值提高了0.76个百分点,相较于使用词典的Lattice LSTM模型的F1 值提高了1.30 个百分点,相较于融合外部词典的FLAT 模型的F1 提高了0.31 个百分点。
由表2 可以看出,CHTE 模型在Weibo 数据集上的提升效果明显优于Resume 数据集,导致这一结果的原因可能为Weibo 作为社交媒体数据存在大量不规则语法、句法以及字丢失的文本内容,使得外部词典不能很好地匹配文本,引入错误的词信息,致使添加词典信息的模型在该数据集中的表现欠佳,而CHTE 模型使用CNN 在不需要匹配词典的情况下获取潜在的词信息,因此在Weibo 数据集上的识别性能更好。

表2 在Weibo和Resume数据集上的命名实体识别结果1Table 2 Named entity recognition results 1 of the Weibo and Resume datasets %
3.3.3 消融实验分析
如表3 所示,在Weibo 数据集上对CHTE 模型各模块进行分析,其中,add 表示CHTE 模型使用直接相加的残差连接方式,wo cat 表示CHTE 模型的编码层输出不拼接嵌入层特征,all CNN-Head 表示在所有注意力头中使用CNN,wo CNN-Head 表示使用原始Transformer 中注意力头的计算方式。相较于Transformer Encoder 直接相加的方式,使用本文提出的门控残差连接后F1 值提高了0.64 个百分点,这一结果可能是由于采用直接相加的方式对待子层以及当前层特征,不能自适应地选择子层和当前层中的特征。相较于Transformer Encoder 中的多头注意力的计算方式,使用本文提出的不同窗口大小的CNN的方式,增强了Transformer 局部特征的表示同时获取潜在的词级别的信息,使F1 值提高了2.32 个百分点。若将CHTE 模型中的注意力头的计算方式全部转化为Transformer Encoder 中的计算方式,则F1 值下降了1.88 个百分点,这说明即使在注意力头中增加了窗口大小为(8,9)的CNN 来计算Value 值,但长度大于7 的实体数量稀少,并且缺少全局语义信息导致最终F1 值降低。
由表3 可以看出,本文设计的基于不同窗口大小CNN 的注意力头对CHTE 模型的性能提升最明显,门控残差连接对CHTE 模型的性能提升也较明显,说明本文在中文命名实体领域针对Transformer提出两种改进方法能有效提升模型性能。
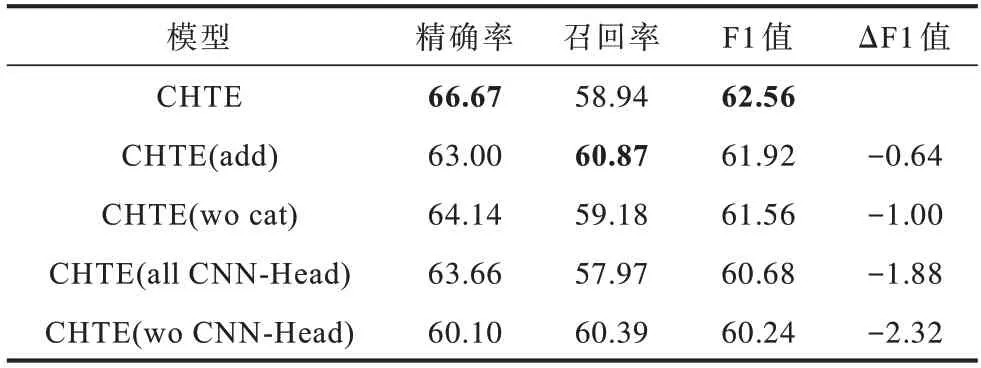
表3 消融实验结果Table 3 Results of ablation experiments %
3.3.4 基于BERT 的模型性能对比
由于本文对比的FLAT 和FGN 模型分别使用Chinese-BERT-wwm[25]和Chines-BERT-base[26]两个不同的版本的BERT,因此分别使用两个版本的BERT 进行实验,并以两个版本的BERT 作为基础模型。
如表4 所示,本文提出的CHTE 模型在两个数据集上相较于两个版本的基础模型Chinese-BERT-wwm 以及Chines-BERT-base均有明显的性能提升,其中在Weibo数据集上提升更明显,相比于Chines-BERT-wwm 模型的F1 值提高了5.29 个百分点,相比于Chinese-BERTbase 模型的F1 值提高了4.40 个百分点。同样地,相比于使用BERT 作为嵌入层的Chinese-BERT-wwm+FLAT模 型,Chinese-BERT-wwm+CHTE 模型在Weibo 和Resume 数据集上的F1 值分别提高了4.94 和0.31 个百分点。在Weibo 数据集上,Chines-BERT-base+CHTE 模型的F1 值相比于FGN 模型提高了0.27 个百分点,而在相对较大且规范的数据集Resume中的F1值相比于FGN模型降低了0.50 个百分点,这表明CHTE 模型在使用BERT 作为编码层后对实体识别效果同样有明显的提升,但由于FGN 模型中融合了中文文字的字形信息,因此相比于CHTE 模型在Resume 数据集上的识别效果更好。

表4 在Weibo和Resume数据集上的命名实体识别结果2Table 4 Named entity recognition results 2 of the Weibo and Resume datasets %
3.3.5 CNN 注意力头数量对模型性能的影响
图2 为CHTE 模型中CNN 注意力头数量对F1值的影响。图3 为在两个数据集上不同命名实体字符长度的占比情况,其中Weibo 数据集中实体字符长度范围为1~11,Resume 数据集则相对较大、实体较多,其中实体字符长度范围为1~36,但由于字符长度超过16 的实体数量较少,因此本文仅统计了字符长度为1~16 的实体数量。如图2 所示,当CNN 注意力头数量为6 时该模型在两个数据集中得到了最高的F1 值。如图3 所示,在两个数据集中实体字符长度主要集中于1~7,而采用6 个CNN 注意力头的窗口大小为(2,3,4,5,6,7),正好能够通过该范围内的窗口大小增强局部范围内的特征表示以及潜在的词信息,因此当CNN 注意力头数量取6时在两个数据集上具有较好的识别性能。

图2 CNN 注意力头数量对F1 值的影响Fig.2 Effect of the number of CNN attention heads on the F1 value

图3 命名实体字符长度占比Fig.3 Percentage of named entity character lengths
3.3.6 实体字符长度对比
为验证在多头自注意力机制中使用不同窗口大小的CNN 对不同字符长度的实体识别的影响,在Weibo数据集上对比分析本文提出的使用CNN 的CHTE模型以及未使用CNN 的CHTE wo CNN 模型。如图4 所示,CHTE 模型在字符长度为1~6 时实体识别F1 值均有提升,其中字符长度为1、5、6 以及≥7 的实体数据稀疏,出现F1 值较低、提升较大以及未提升的情况。在实体数据较多的字符长度范围内,字符长度为3 的实体对应的F1 值提升了0.03 个百分点,这说明使用不同窗口大小的CNN 可增强局部特征,不仅能提高具有较长字符长度的实体识别效果,而且能增强较短数据字符长度的实体识别效果。

图4 Weibo 数据集上不同命名实体字符长度的F1值Fig.4 F1 values of each named entity character length in Weibo dataset
3.3.7 可视化分析
图5、图6 为通过CHTE 模型得到的未使用CNN(Linear-Head)和使用CNN(CNN-Head)的注意力权重的可视化结果图。如图5 所示,Linear-Head 得到的注意力权重相对比较分散,这说明其更加注重获取全局语义信息,存在注意力权重没有集中在有意义的词上的问题。如图6 所示,CNN-Head 得到的注意力权重分布相较于Linear-Head 相对集中,这说明使用CNN 来获取Value 向量的方法能够有效地捕获句子中的局部特征,增加字符的局部特征表示,并且能够增强字符词级别的特征表示,进而增强模型实体识别能力。
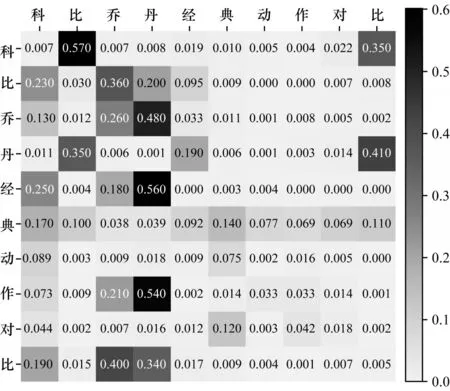
图5 Linear-Head 注意力权重Fig.5 Attention weight of Linear-Head
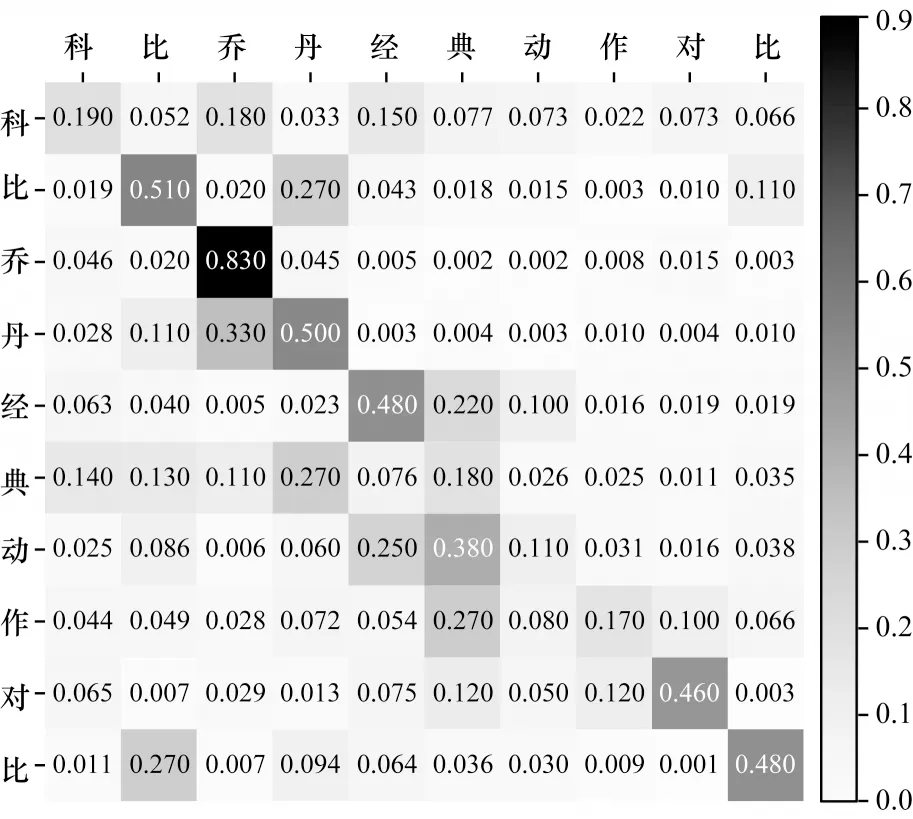
图6 CNN-Head 注意力权重Fig.6 Attention weight of CNN-Head
4 结束语
本文提出一种用于中文命名实体识别的CHTE 模型,通过在多个注意力头中融入CNN 充分捕获全局语义信息并增强模型的局部特征以及潜在的词信息表示,同时应用自适应的门控残差连接融合当前层和子层特征,提升了Transformer 对于命名实体的识别准确率。通过将CHTE 模型与使用外部词典信息模型、未使用外部词典模型以及基于BERT的模型在Weibo和Resume两个数据集上进行实验对比,结果证明了CHTE 模型具有更好的中文命名实体识别性能。后续将在CNNHead Transformer 编码器的基础上融合词典信息,进一步提升模型对于中文命名实体的识别准确率。
猜你喜欢
计算机研究与发展(2022年1期)2022-01-19
计算机应用(2020年12期)2020-12-31
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
英语文摘(2019年5期)2019-07-13
军事文摘(2018年24期)2018-12-26
晚晴(2018年3期)2018-12-06
家庭影院技术(2018年3期)2018-05-09
文苑(2015年9期)2015-09-10
中关村(2014年5期)2014-05-15
