
基于深度学习的红外图像人体参数识别研究
2022-10-14 00:58:10唐明武刘盼龙赵睿雯刘卓辰吴小舟
东北电力大学学报 2022年4期
唐明武,李 果,刘盼龙,赵睿雯,刘卓辰,吴小舟,高 洁
(1.大连理工大学土木工程学院,辽宁 大连 116024;2.大连大学建工学院,辽宁 大连 116622)
现今社会,大部分人80%的时间都在室内度过.随着社会发展,人居环境已经得到了较大的改善,空调也变得越来越普及.如何通过室内热湿环境调节手段来保证室内人员的舒适性至关重要.在上世纪七、八十年代,丹麦Fanger教授根据人体热平衡方程和ASHRAE七级热感觉标度提出了热舒适评价指标——预测平均投票值(PMV)和预测不满意百分数(PPD)[1],该指标同时被国际标准ISO 7730[2]、欧盟标准EN 15251[3]和美国标准ASHRAE Standard 55[4]所采用.该指标综合考虑了四项环境参数(空气温度、平均辐射温度、空气流速、空气湿度)和两项人体参数(人体活动状态和着装情况)对人体热舒适的影响,并对人体热舒适程度进行了量化.通过测量上述四项环境参数和两项人体参数并输入人体热舒适方程,可以计算得到PMV和PPD指标,从而判断当前人体是否舒适,为空调系统的运行控制提供依据.
在影响人体热舒适的六项参数中,四项环境参数可以根据环境传感器进行监测,相关测定方法及仪器已比较成熟[5].相对而言,两项人体参数的测量更复杂,一般可分为接触式测量、半接触式测量、非接触式测量三类[6].接触式测量方法是将测量得到的心率、脉搏等生理参数与人体热舒适构建相应的关系,此类方法最大的障碍在于会使人员产生较大的异物感,且无法获得着装情况;半接触式测量方法是将传感器集成到可穿戴设备上,实时监测人员的热舒适性,此类方法未能直接考虑人员活动状态及着装情况对热舒适的影响;非接触式测量方法为基于视频/图像处理的方法来实现对人体参数的测量,这样可以避免对人员活动的干扰及避免可穿戴设备的异物感.而红外热成像测量技术作为非接触式测量方式的一种,原理是通过红外传感器接收物体发出的红外辐射,经由统一的信号处理系统将物体的热分布转变为可视图像[7],对于人体不同活动状态和着装情况下的红外特征均能体现出差异性与可识别性,是目前适合监测人体参数的一种潜在测量方法.
在计算机视觉领域,对人体行为活动的识别研究较为流行,主要侧重于基于不同模型识别方法对可见光波段图像/视频进行识别研究,相关方法均需要进行特征提取[8-10].相对于可见光波段图像,红外成像取决于天气、时间环境等参数,对图像的特征提取更为复杂.解决问题的灵感来自动物的视觉皮层,特别是卷积神经网络(CNN)的深度学习方法,在对红外图像进行识别时展现了较为先进的性能.Lee等[11]展示了使用卷积神经网络(CNN)识别红外图像中的户外可疑人类行为.Aparna Akula等[12]搭建了卷积神经网络框架进行人类行动识别工作,通过训练和测试评估系统的性能,发现深度学习方法的测试精度为87.44%,更优于最有竞争力的传统识别方法.王召军等[13]提出一种基于低分辨率红外阵列传感器采集红外热图像,运用卷积神经网络算法自动提取特征,通过步态识别实现身份识别以及实现跌倒、坐下和行走动作的识别,测得行走、坐下和跌倒的检测准确率分别为100%、90%和90%.
本文主要研究工作在于构建深度学习神经网络,建立以不同人体活动状态和着装情况为分类依据的红外图像数据集,并对神经网络进行识别训练,探讨其用于人体参数识别的可行性.
1 红外图像采集及识别
1.1 红外图像采集
1.1.1 采集方法
相对于可见光成像技术,红外成像对光照环境无要求,在光照不充足时也可进行拍照识别.人体的发热与环境物体的热辐射特性有较大差异,因此红外成像下的活动状态具有可识别性;红外成像也可以反映人体表面温度分布情况.根据红外图像成像特点,可将其用于不同人体活动状态和着装的测量之中.在红外图像数据的采集方面,使用红外热成像仪进行不同场景下的图像拍摄工作,感应不同场景下发射的热量,并以图像的形式进行显示和保存.
人体的红外特征是高度可变的,同时受到环境和人体各项参数的影响,因此拍摄图像时要充分考虑现实情况的变化.为保证深度学习网络训练的正常进行,测试建立的用于人体参数识别红外图像数据集要求能正确且较为全面地反映出现实情况中室内人体行动以及着装穿着情况的主要特征,且确保数据集中图像的多样性以及足够的样本数量.具体拍摄要求与变化见下表1.实验过程拍摄时保证摄像范围只有一个人,但实际多人情况时,需要计算机视觉的其他相关技术,诸如语义分割、目标检测识别等来实现多人图片的单体分割,获取个体图片,这是本专业可利用的技术.

表1 采集参数及仪器
1.1.2 采集结果
实验测试的内容包括红外图像中的人体活动状态及着装情况识别.测试用的图片有低分辨率相机拍摄的80×60和高分辨率相机拍摄的160×120两种初始图片.
经过长达一年的测试,已建立活动状态样本总数为1 172(低分辨率)+1 178(高分辨率)=2 350(混合分辨率)、着装情况样本总数1 129(低分辨率)+1 195(高分辨率)=2 324(混合分辨率)的人体参数红外图像数据集,按照不同标签进行的具体分类如表2所示.

表2 人体参数分类
将拍摄的红外图像按照不同标签类型分类,组成人体参数识别红外图像数据集.数据集依据两项人体参数分别进行划分,活动状态识别分类主要按照能代表人体不同活动状态划分,分为躺着、静坐、静坐阅读、静坐打字、站立、站立整理文档六类标签;着装情况识别分类主要根据一年四季不同的着装情况,按照国际标准ISO 7730来计算总着装热阻,并根据大致区间范围进行划分,分为夏季着装、过渡季着装、冬季着装三类标签.活动状态分类以及着装情况分类的典型红外图像如图1~图2所示.由于人体热辐射和环境热辐射的不同,人体可从环境中很容易区别出来;同样,因为服装热阻不同,人体的表面辐射也不同,图像中人体也就出现了颜色差异[14],这也就能实现着装情况的识别.

图1 活动状态分类典型图像
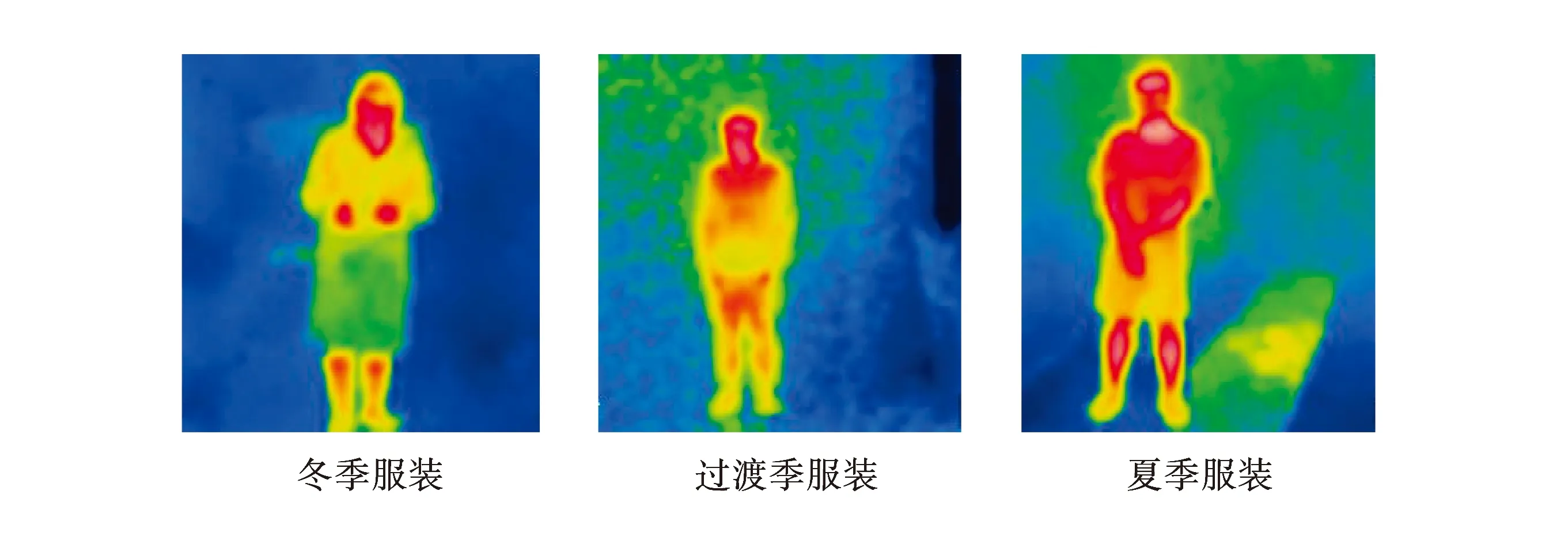
图2 着装情况分类典型图像
1.2 红外图像识别
1.2.1 红外图像识别流程
依据深度学习的发展和前人的经验,图片的识别和处理的方式越来越多,效果也越来越好.不过,针对于红外图像的识别研究还相对较少,据Aparna Akula等[12]的研究,基于卷积神经网络的多层深度神经网络在红外图像识别上较早期的支持向量机、SVM等有更好的效果.因此,本文在此基础上给出的深度学习模型是基于CNN的LeNet和ResNet两种神经网络所建立的.LeNet网络作为早期发展中以体量小、效果好而被大家所熟知,而ResNet则是近几年发展中有着突破性进展且具有代表性的网络结构.我们考虑是否可用更简单的网络(LeNet)来达到比较好的效果,同时也比较目前较先进的网络结构(ResNet)在红外图像方面的识别效果.
卷积神经网络作为一种监督学习,在面对图像这类高纬度的多参数数据时能有效避免图像展开为向量时丢失空间信息.卷积神经网络主要包括5类层:输入层、卷积层、池化层、全连接层和输出层,如图3所示.其内部ReLU函数起到激活卷积的作用,卷积层和全连接层也会考虑到神经元权值w和偏置项等.
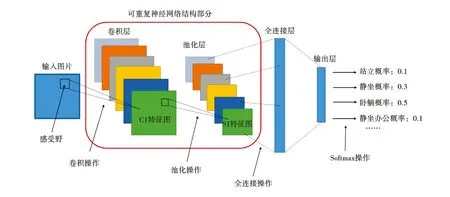
图3 神经网络图片识别简要流程图
1.2.2 识别网络
(1)LeNet网络
基于LeNet的模型架构相对较简单,该架构因其在数字字符识别方面的成功而流行.由于前人研究的经验以及红外图像数据有限的缘故,首先考虑了这一简单而有效的框架.其网络过程如图4所示,其中包含了两次卷积池化和三次全连接,将根据其用于着装分类或活动状态分类而改变分类数目.输入的图像尺寸我们进行了更多类的划分:32×32,48×48,64×64,80×80,96×96.不同种类的图像在最后节点的输出都一样的,它表示分类的结果,并通过Softmax函数归一后挑选其最高概率值作为最后的分类执行动作.最终挑选了——48×48类型图片,具体结果如表3所示.
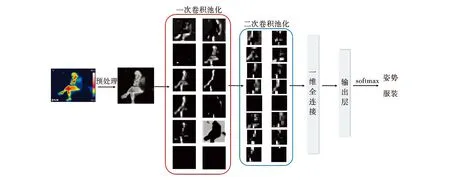
图4 LeNet网络实际训练过程演示图

表3 不同尺寸图片训练准确率
注:准确率由神经网络收敛后取50个Epoch测试准确结果取平均
从训练结果的数据可以看出,LeNet网络在面对48×48时的图片输入时能保证较高的准确率.因为LeNet网络深度较浅,最早应用于手写字识别的图片尺寸相对较小,且进行过灰度处理,所以在对LeNet模型导入所拍摄图片时同样也进行了图片尺寸以及灰度的处理.针对不同尺寸图片的不同准确率结果表现,其呈现出不规律性,研究猜测其应与LeNet模型自身算法相关,该网络可能对某些尺度下的信息能好的关注和识别,图片过大关注更多局部信息,图片过小或更关注整体信息,或存在某个阈值且与图片种类相关.
目前拥有的红外数据集数量相对较小,用于训练任何深度神经网络体系都有可能导致过度匹配的问题而产生过拟合的结果.因此采用Dropout函数对神经元进行控制,让其在卷积到下一层时随机把部分神经元的值进行归0处理,用以减小神经元相互间的关联性,也避免神经网络自认为从一张图片上学到太多.最终将Dropout定为30%,它能有效的为神经网络提供噪音输入从而避免过渡匹配.LeNet网络所损失函数采用的是交叉熵损失函数,它通常更适用于多分类问题.优化器的选择为Adam,它结合了自适应优化算法RMSProp和AdaGrad的优点,同时考虑梯度的一阶矩估计和二阶矩估计来更新步长,使得梯度下降更为平滑.
(2)ResNet网络模型
ResNet残差网络,是CNN网络的一个变种,如图5所示.该网络属于短路连接方式,当输入和输出维度一致时,可以直接将输入加到输出上.但是当维度不一致时,这就不能直接相加,可采用Zero-Padding增加维度,此时一般要先做一个Downsamp(下采样),可以采用Stride=2的Pooling,这样不会增加参数.
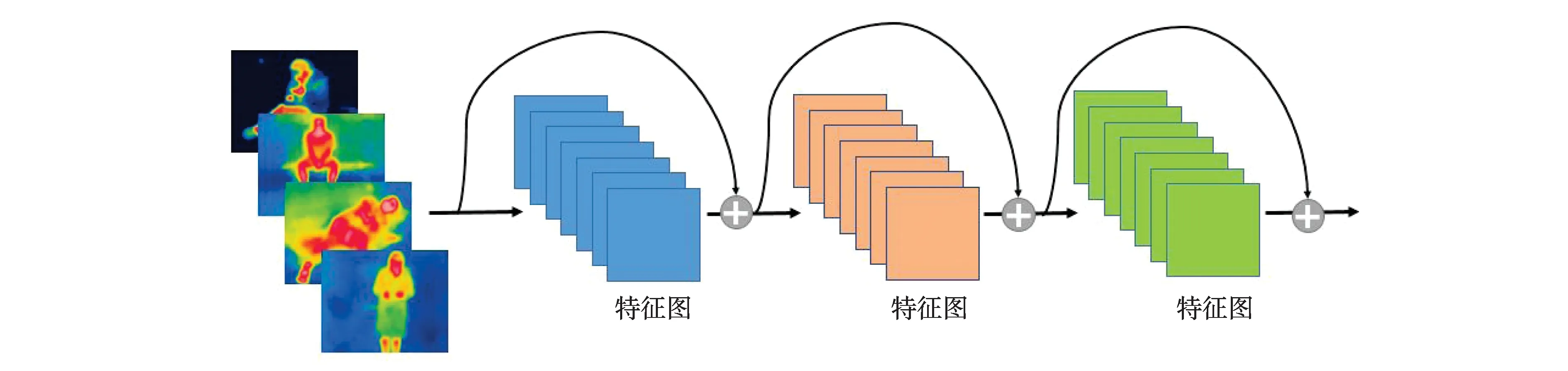
图5 ResNet短路连接机制操作(元素级相加)
ResNet网络模型对数据集数量有一定的要求.而由于拍照条件的限制,本实验的数据集图片数量相对较小,所以在ResNet模型训练时加入对图片的一些多样化处理方式实现数据增强,以减少小数据集应用于高级网络的不足.处理方式包括图片的Resize、旋转、翻转等过程.图片处理方式的Resize过程是将输入的图片归一到同一大小,因为采用了两种不同分辨率的相机进行实验所以在统一训练时需要进行图片大小统一.旋转过程则是让图片在输入训练时有概率的绕其中心旋转,旋转角度为-10°~10°之间一个随机数值.翻转过程主要为水平翻转和上下翻转,实验中发现上下翻转会极大程度的改变图片的原始特征,如图6所示.原本静坐姿态的图片在上下翻转后呈现出极大差异,不仅没有达到增加数据量的要求,还额外的为网络训练带来了噪音,所以取消了对图片的上下翻转处理.

图6 图片数据增广操作—翻转(从左至右依次:原图、水平翻转、上下翻转)
LeNet网络和ResNet网络模型深度及图片处理方式不同,为了增加两种网络模型的可比性,将其内部模型参数设置基本相同.LeNet网络和ResNet网络模型的学习率取值均为0.01,激活函数均为Relu,并都通过Softmax函数进行最后的概率挑选,损失计算函数都采用CrossEntropyLoss(交叉熵损失函数),优化器都选择Adam函数,衰减率γ取值依据训练轮数而定(本实验分别在训练50、100、200Epoch时分别进行0.5、0.4、0.3倍数的学习率衰减,之后固定为0.9).为了保证数据的充分应用和避免偶然性结果,增强可信度,输入两个神经网络模型的图片并没有固定的划分为训练集和测试集,而是在每一个Epoch开始进行随机的8:2划分来获得训练集和测试集.
本文采用的LeNet和ResNet模型是通过Python编程语言在Anaconda软件环境中调Torch、Torchvision等神经网络环境相关库、包来实现计算的.
2 结果与讨论
2.1 人体活动状态识别结果
采用不同分辨率图片及不同网络模型的人体活动状态识别结果如图7~图9所示.
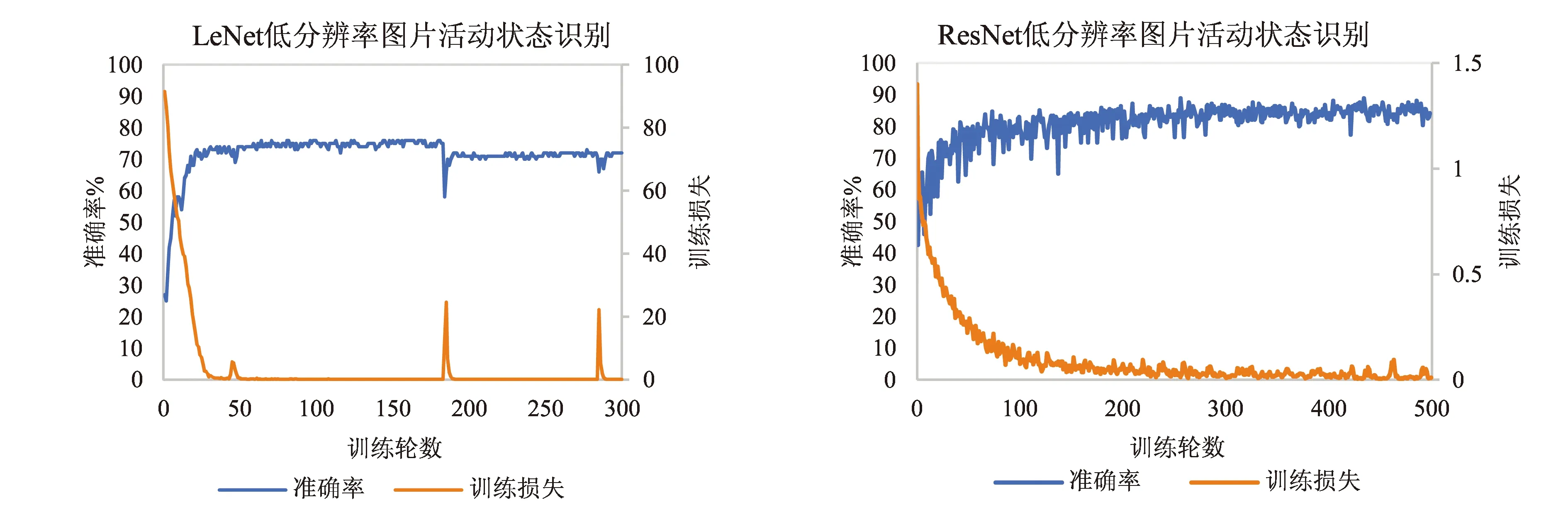
图7 不同网络模型低分辨图片活动状态识别测试结果
从以上不同网络模型测试的结果中可以看出,所建立模型都能一定程度上识别红外图像的人体活动状态,但相互之间存在差异.从图7~图9可知,ResNet模型从整体训练效果来看要优于LeNet模型,但从训练损失的下降曲线来看,LeNet模型总是更快的达到收敛,致使模型训练学习过程过早的结束.
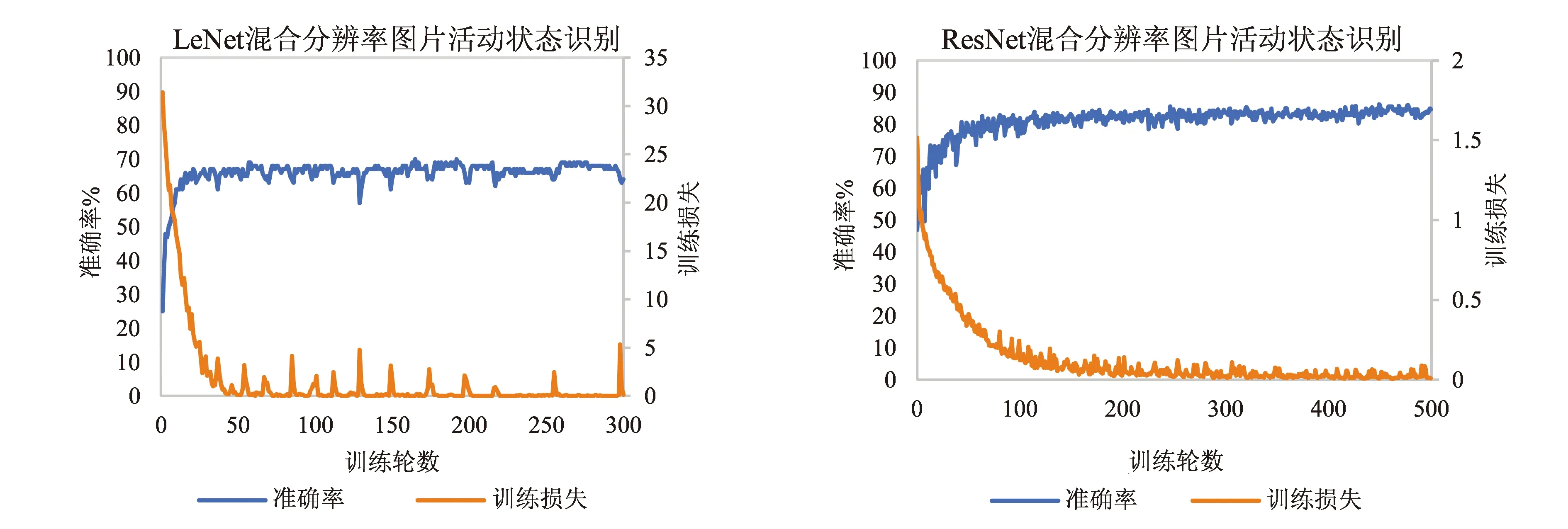
图9 不同网络模型混合分辨率图片活动状态识别测试结果
此外,图7和图8的LeNet网络模型训练的准确率曲线中可以看出,在模型收敛后出现了准确率降低的情况,这表示模型出现了过拟合现象,即模型随着训练过程的进行而过多关注图片的某一部分信息,而使模型变得局部化,缺失了对信息的整体性考虑,进入了误区(过拟合程度受模型算法、图片分类处理、图片训练和测试量等多方面影响).而ResNet网络模型训练整体相对平稳,收敛后的准确率都能达到80%以上,并且没有出现过拟合现象.
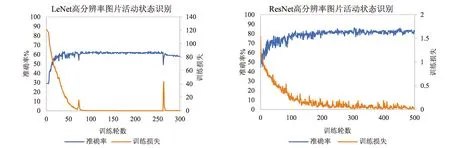
图8 不同网络模型高分辨率图片活动状态识别测试结果
此外,对比图7和图8可以看出,采用高分辨率图片后不同网络模型的训练收敛时间明显增大.这主要是由于高分辨率图片所包含的像素点更多,相对而言输入网络的参数也包含着更多的有用信息,所以收敛速度较慢于低分辨率的图片,而混合后测试的收敛速度处于二者之间.可以看出,找到信息量和图片尺寸的平衡是重要的,特别是在实际应用过程中.
2.2 人体着装情况识别结果
采用不同分辨率图片及不同网络模型的人体着装情况识别结果如图10~图12所示.
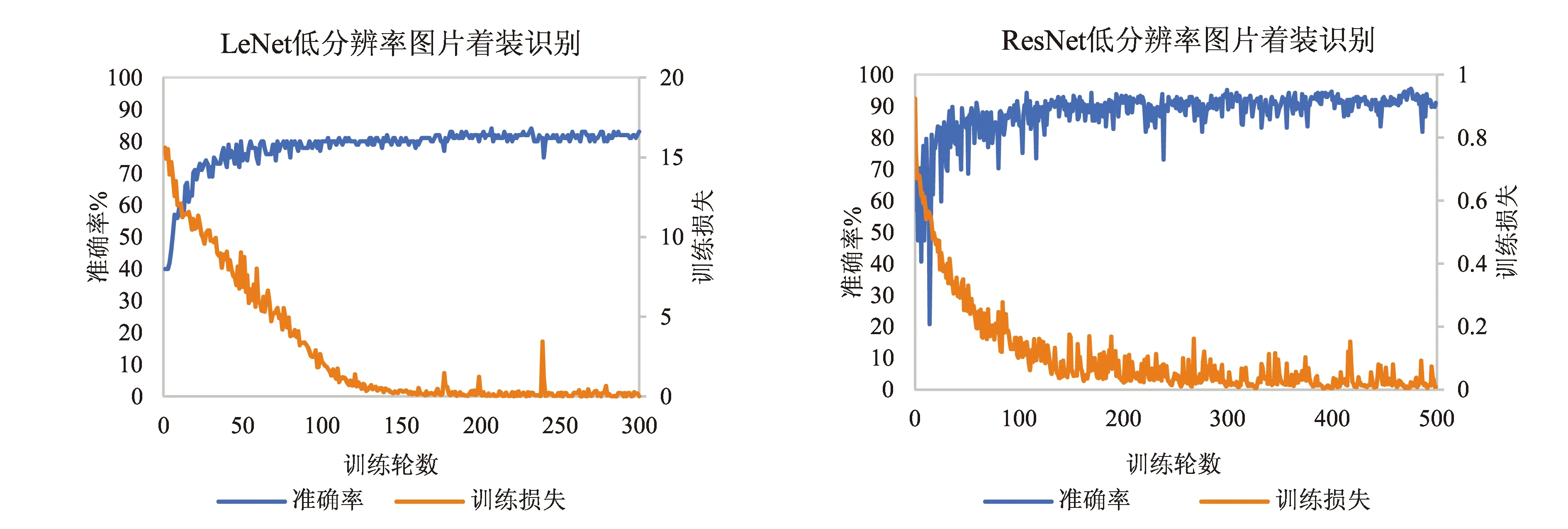
图10 不同网络模型低分辨图片着装识别测试结果
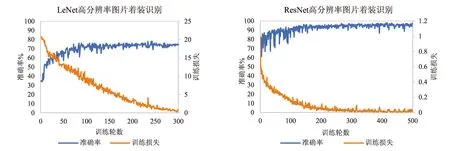
图11 不同网络模型高分辨率图片着装识别测试结果
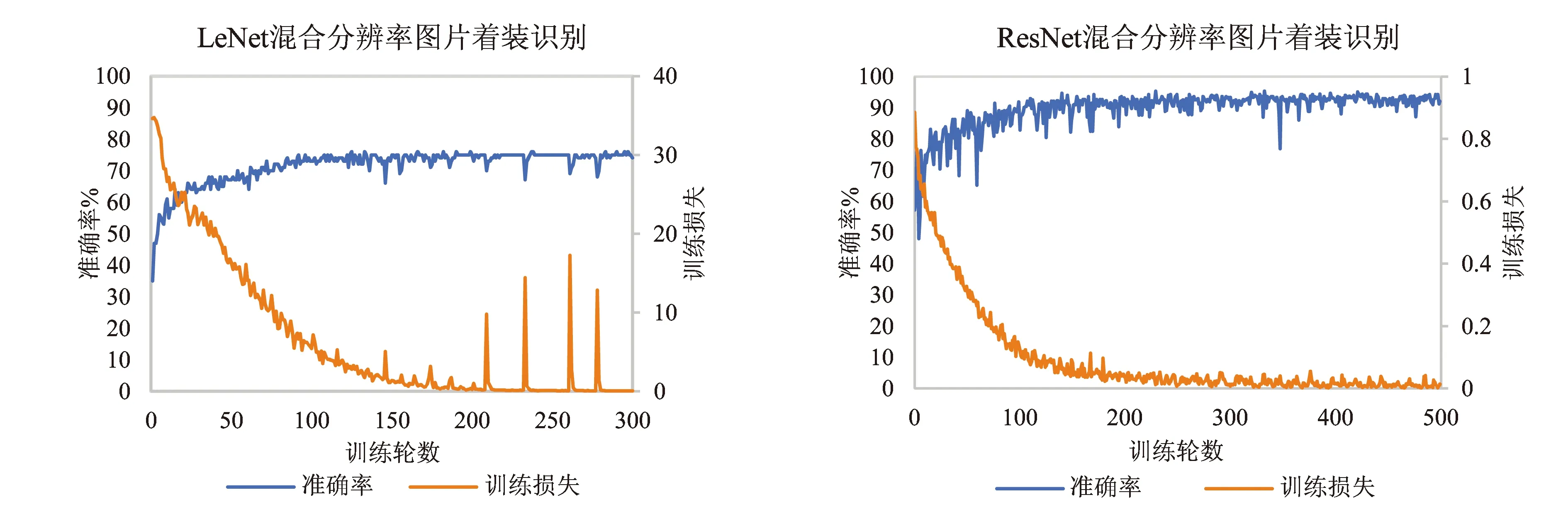
图12 不同网络模型混合分辨率图片着装情况识别测试结果
从图10~图12可以看出,ResNet模型在着装识别的准确性上要高于LeNet模型,整体准确率能达到90%以上,而LeNet模型准确率只在70%~80%之间浮动.但就收敛速度而言LeNet模型更快于ResNet模型,前者在200 epoch之前就差不多已经收敛,而后者在接近300 epoch时才收敛.就模型的稳定性而言,LeNet模型训练相对稳定,只在图片进行混合训练时出现较大波动,但最终趋于平稳;而ResNet模型训练前期波动较为剧烈,而后逐渐趋于平稳,二者在着装识别方面都没有出现过拟合现象.
与人体活动状态识别的情况相同,高分辨率的图片同样影响不同网络模型的收敛速度,高分辨率的图片因为信息更多导致学习时间更长.值得注意的是,在图片混合后进行着装识别时,LeNet模型出现了严重的波动现象,可能的原因为高分辨率的图片为统一输入尺寸缩小后丢失了部分热感信息,而且两个相机的热敏感程度不同也会导致图片之间存在差异,造成识别困难.而ResNet模型因其网络的深度,可以获取到更多的特征,从而克服这样的差别.
综合两个实验结果,就模型训练过程的波动而言,着装识别比人体活动状态识别更剧烈.这可能受相机热敏感程度、图片原始尺寸大小、人为分类依据和准确性等多方面影响.热敏感程度高则热信息更多更全面,这将有益于模型对着装热阻的分类识别;图片的像素则决定了信息量的大小,如何确定一个统一化输入的尺寸将利于模型的训练;数据集的初始分类标准和准确性直接决定了模型训练所能达到的上限.就本专业而言,这三方面的研究工作对模型的后续改进和准确率提高也十分重要.
2.3 综合对比
通过以上方式进行网络模型训练,训练结果识别准确率由模型收敛后取均值计算,综合对比如下图13所示,主要分为两种分辨率的红外图像以及LeNet与ResNet两种网络的对比.
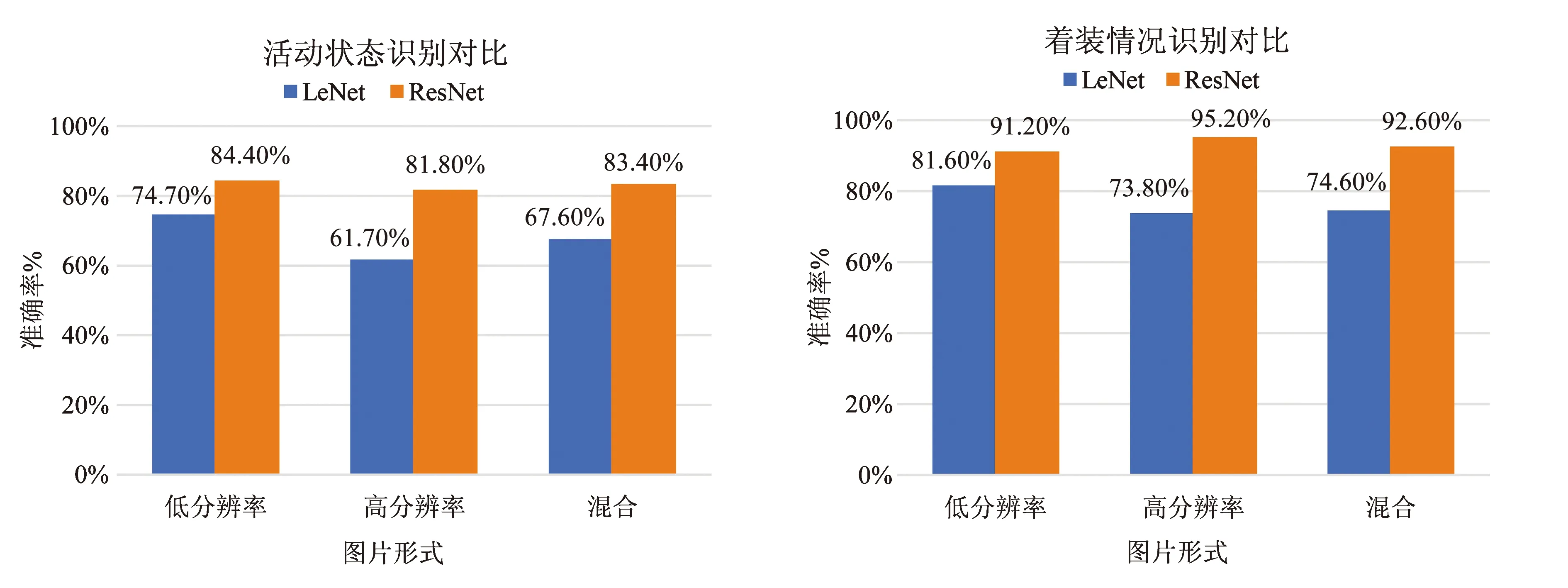
图13 不同分别率图片和网络人体参数识别结果综合对比
从图13可以看出,ResNet模型对人体活动状态的识别准确率达到了81%以上,对着装情况识别准确率达到了91%以上,两方面都优于LeNet模型.但无论是何种分辨率的图片,着装情况的识别整体效果较好.而从上图中不同分辨率图片的训练结果来看,LeNet模型在不同分辨率图片的识别上存在较大差异,且在低分辨率图片识别时的准确率要高于高分辨率的图片,而ResNet模型在两者之间的差异较小,但出现了高分辨率着装识别准确率高于其他,但活动状态识别准确率低于其他的现象.
首先就不同分辨率图片的结果比较而言,LeNet模型由于其网络层较浅,在面对同样处理48×48输入的训练图片时,对于原高分辨率的图片,每个像素点是原图片更多信息的集和,而且在面对小数据集训练时更难捕捉到这些融合性的信息特征,出现高分辨率图片训练结果更差的现象.ResNet模型更具深度,更好的识别并提取了高分辨率高图片所携带的更多热感信息特征,但由于高分辨率相机热敏感较优于低分辨率相机,导致在部分环境下所拍摄的红外图片中人体与环境的差异不够明显,且还存在人为分类和拍摄的误差等问题,所以导致ResNet模型训练结果出现上述现象.这些差异和问题同样也影响着LeNet模型的训练结果.
其次就两项人体参数识别结果比较而言,人体着装情况的识别准确率均高于活动状态,总结其原因是着装情况只划分了三类,分类难度相对较低,模型未准确识别而猜对的概率较高;此外,热红外成像图特有的优势是包含的冷热信息比活动状态信息更多,用于着装识别更具优势.
综合来看,ResNet网络模型作为深层次的网络,即使面对较小的数据集,其考虑到的特征参数更多,所以能学习到的东西更多,导致耗时较长,收敛较慢;而LeNet网络模型简单,能捕捉到图片的有用特征较少,而且用于训练的数据集较小,导致模型过早的收敛.因此,目前小数据集训练条件下ResNet网络模型整体上优于LeNet网络模型.未来需要进一步扩充训练数据集,在大数据集条件下对比ResNet网络模型和LeNet网络模型.此外,本文对着装情况方面的分类识别范围相对较大,未来需缩小不同着装情况分类直接的差别,并扩展识别网络神经系统,实现对更多着装情况分类进行识别.
3 结 论
本文构建了具有人体参数特征的红外图像数据集,并结合红外图像处理技术和卷积神经网络识别技术对两种人体参数进行识别,得到以下结论:在识别两种人体参数方面ResNet网络比LeNet网络更具优势,六类活动状态识别准确率达80%以上,三类着装识别准确率达90%以上.该研究工作证明了基于深度学习网络进行红外图像人体参数识别的可行性,为今后考虑人体参数的建筑环境个性化智能控制提供了支持.
猜你喜欢
环球时报(2022-05-23)2022-05-23 11:28:37
小哥白尼(趣味科学)(2022年1期)2022-04-26 14:21:08
大科技·百科新说(2021年10期)2021-12-31 07:24:02
基层中医药(2021年5期)2021-07-31 07:58:34
健康之家(2021年19期)2021-05-23 11:17:39
金桥(2021年4期)2021-05-21 08:19:20
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年7期)2019-04-25 13:17:14
中国交通信息化(2018年5期)2018-08-21 03:37:40
