
一种减少数据特征值鸿沟的方法
2022-10-14 02:01林游龙
网络安全技术与应用 2022年9期
◆林游龙
(福州数据技术研究院有限公司 福建 350019)
随着信息时代的高速发展,如何对自然语言文本进行挖掘,特别是对其按照设定的语义进行正确的归类,已经成为组织大量文本信息的一个关键问题,这就是文本挖掘中很重要的一类任务一文本分类[1]。自动文本分类(Automatic Text Categorization)或者简称为文本分类,是指计算机将一篇文章归于预先给定的某一类或某几类的过程[2]。随着文本信息量的快速增长,文本分类已成为信息检索、知识挖掘和管理等领域的关键技术[3-4]。文本分类的精确程度取决于特征提取[5]和分类算法[6]。人们提出了很多文本分类方法,例如k-最近邻分类法,贝叶斯分类,决策树和神经网络[7]。最广泛使用以及效果最好的文本分类方法是支持向量机与KNN 方法[8-9]。
支持向量机是由Vapnik 等人提出的一种学习技术,是借助于最优化方法解决机器学习问题的新工具。它集成了最大间隔超平面、Mercer 核、凸二次规划、稀疏解和松弛变量等多项技术[10]。由于其具有全局最优、结构简单、推广能力强等优点,近几年得到了广泛研究并应用于文本分类、模式识别等领域[11]。
k-最近邻居分类(KNN)方法基于类比学习[12],采用SVM(向量空间模型)[13]表示文档,是一种非参数的分类技术,在基于统计的模式识别中非常有效,对于未知和非正态分布可以取得较高的分类准确率,具有鲁棒性、概念清晰等诸多优点[14]。
本文在对基于向量空间模型的分类方法(如SVM[15-16])的研究发现,基于向量空间模型的分类方法存在不合理之处,即特征值之间的“鸿沟”,这种鸿沟会导致向量空间模型中两点之间距离的计算出现偏差,由于目前基于向量空间模型的分类方法都没有考虑到这种鸿沟,因此分类效果受到了一定的限制。如果要想进一步提高分类效果,就必须解决这种偏差。
本文介绍了一种使用虚点的方法,这种方法消除了特征值之间的鸿沟,使得分类的效果得到了提高。该方法是通过重新定义特征权重,调整向量空间模型中点的特征值,即相当于重新定义向量空间中的点,这样的点是相对于原来向量空间模型中的点的矫正映射,即就好像是虚拟点一样,最后问题归结为计算向量空间模型中的点与虚拟点的映射函数。理论分析表明虚点方法能提高基于向量空间模型的分类方法的效果,在SVM 中运用虚点方法的实验结果表明,运用虚点方法的SVM 的精确度得到了提高,这种结果验证了本文提出的虚点方法的有效性。
1 向量空间模型
向量空间模型(Vector Space Model,VSM)[8]是康奈尔大学Salton 等人上世纪70 年代提出并倡导的,文档可以转化为标引项(term)及其权重组成的向量表示,都可以看成空间中的点。向量之间通过距离计算得到向量的相似度。VSM 中有三个关键问题:
(1)标引项(term)的选择
(2)权重的计算,即计算每篇文档中每个Term 的权重
(3)空间中文档之间距离的计算。
Term 可以是能代表文档内容的特征如:字、词、短语或者某种语义单元(比如:所有同义词作为1 维)。对于权重计算,目前广泛使用的方法是TF*IDF 方法,其中TF 代表Term 在文档中出现的次数。IDF 代表Term 的文档频率DF 的倒数。两者相乘然后做线性编号就是此方法。计算完Term 的特征权重后就可以在向量空间模型中用特征向量表示一个文档,即一个文档可以表示为一个向量空间模型中的一点。文档之间距离的通常有欧式距离、向量夹角余弦、向量夹角正弦和马氏距离等[9]。
2 虚点原理
2.1 虚点方法产生的背景-特征值鸿沟(GBF)
如图1 所示,假设一个类的构成只有2 个Term,其中Term 权重用TF*IDF 表示,则每个类都可以表示为一个带权重的Term 的特征向量,假设类别1 的分类中心为(1,1)。类别2 的分类中心为(3,2),可知两者的对角点为(3,1),对角点相对于其他的点来说,特殊之处在于它对类别1 的分类中心的距离只跟Feature1 相关,而跟类别2 的分类中心的距离只跟Feature2 相关。那么问题就归结为对角点的分类问题,按照原来的向量空间模型,对角点有两个(1,2),(3,1)。其中(3,1)跟分类中心1(1,1)的Feature1 的距离为特征Feature1 的差值2.跟分类中心2(3,2)的Feature2 的距离为特征Feature2 的差值1。可以知道应该将对角点分到类别2(3,2)那一组,但从理论上可知,属于同一特征的值,可以用量来表示,但是属于不同特征的值无法用量来表示,因为两者的判定的标准不一样。Feature2 的差值为2 的数不一定大于Feature1 的差值为1 的数。因此仅仅从此对角点的分类问题应该无法判断到底属于哪一类。也就是Feature2 的差值为2 的数应该与Feature1 的差值为1 的数相等。此时对角点到两类的距离相等,符合无法判断类型的情况。因此原向量空间模型没考虑到这个问题,这就是特征值的鸿沟问题(GBF)的产生。如图1 所示鸿沟为θ=1。
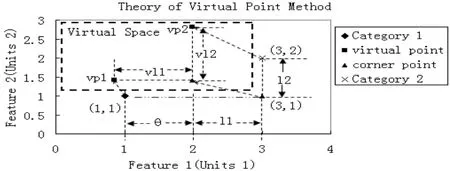
图1 虚点原理示意图
为了消除特征值之间的鸿沟。可以认为存在原分类点的虚点,这些点是由调整特征权重的分配来得到的。它们必须满足两个条件:
(1)归一化条件。
(2)调整后的两个类别虚点到虚对角点的距离必须相等。
如图所示,vp1 和vp2 分别对应分类点1 和分类点2 的虚点。现在的问题归结为本文提出的特征鸿沟理论到底存不存在,用即特征鸿沟的消除能不能带来分类效果的提高,从如图2 所示,就是要证明在虚点空间中用vp1 和vp2 分类比原向量空间中分类的效果更好。
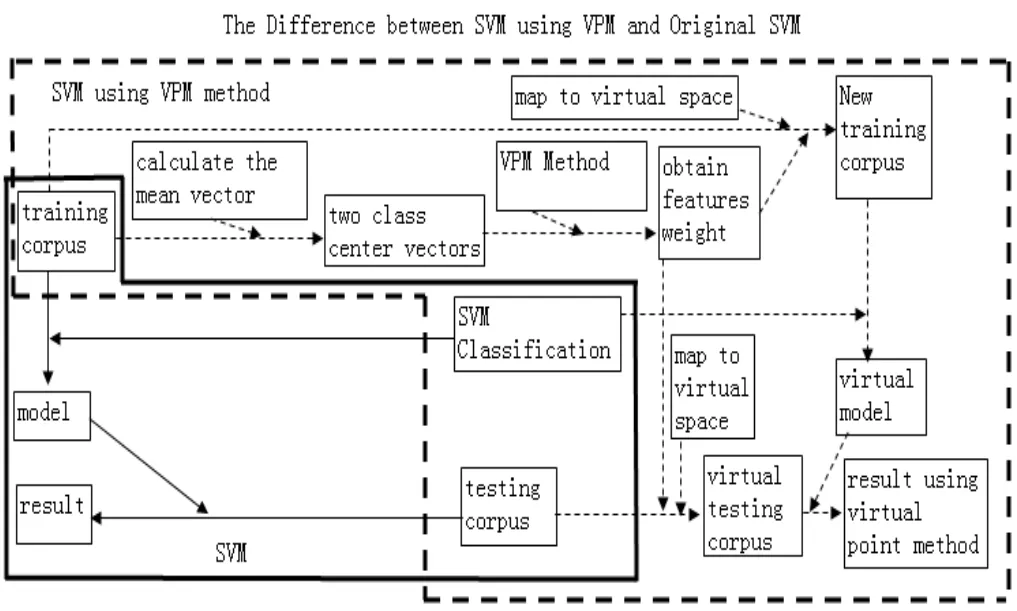
图2 原SVM 分类方法与使用了虚点方法的SVM 分类方法
2.2 虚点方法介绍
变量定义:假设向量空间模型中的分类点为类别1 的分类中心α和类别2 的分类中心β,必然存在一个点a,它跟α的距离只跟Feature(1)相关,即特征距离,假设其为l(1),跟β的距离只跟Feature(2),设为l(2)相关,这个点称为α和β的对角点。易知α和β的对角点有两个,任选其中的一个Feature(1)与Feature(2)之间的距离鸿沟d(12)定义为:d(12)=|l(1)-l(2)|。
虚点方法:存在特征权重λ(1),λ(2)满足归一化条件,并且使得分配权重后的向量空间中的点,即原空间中的α和β在虚点空间中的分别对应的点的虚点α’和β’的2 个特征距离相等,即α’和β’到它们虚点空间中的对角点的离相等:l(1)=l(2)。这样在虚拟空间中特征之间的距离鸿沟就为零了。
关于对角点的说明:虚点空间与原空间的对角点不是独立存在的,他是针对分类点,以及虚点空间中分类点的虚点而提出的一个抽象的概念,它在现实中可能不存在。
到目前为止就只有一个问题了,即特征值鸿沟的观点是否存在?
2.3 虚点方法的例子
为了形象说明整个流程,举个例子:比如判断一列火车属于快车与慢车的标准为:快车为,平均车厢的数量为10 节,速度平均为180公里/小时;而慢车的为:平均车厢30 节,速度平均为80 公里/小时。如果此时,有一列特殊的列车,车厢为10 节,速度为80 公里/小时。那么根据向量空间模型的公式,可以算出这种列车对快车的差异为速度相差100 公里/小时,车厢没差异。对慢车的差异为车厢相差20 节,速度没差异,进行标准化以后(假设速度的标准化为原值除以180,车厢的标准化为原值除以30),差异分别为100/180,20/30。从而知道此列车属于快车。但是理论上可知此列出应该不能判断归属,因为20 节车厢跟100 公里/小时这两个数无法比较。此时鸿沟为差异值的差值即|100/180-20/30|=0.11。而这列车可能现实中不存在,它只是针对快车和慢车而提出的一个概念。
因此本文设特征权重λ(1),λ(2)来分别调整火车车厢跟火车速度的权重,设归一化条件λ(1)×λ(2)=1。此时λ(1)×(20/30)=λ(2)×(100/180)。可以得出λ(1)≈0.9129,λ(2)≈1.0954。此时虚拟分类点为快车平均节数为:9.129 节,速度为197.172 公里/小时:慢车平均节数为。27.387 节,速度为:87.632 公里/小时。此时就能用虚拟点分类了。可以计算特殊列车在虚点空间中的映射点为9.129 节与 87.632 公里/小时,从而计算得到鸿沟为0,此值小于<0.11。说明使用快车,与慢车的虚点用来分类比使用原点分类来得更接近实际。
2.4 虚点方法的另一种解读
假设原空间中存在分类点α(0,0)点和β(a,b)点。根据虚点方法可知,它们在虚点空间中分别对应虚点α’(0,0)和β’(aλ1,bλ2),其中,λ1λ2=1 设α’和β’的距离为c,则根据直角三角形公式以及直角三角形不等式可知:
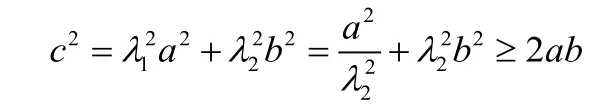
其中当aλ1=bλ2,时c有最小值。而aλ1=bλ2是虚点空间中的虚点满足的条件。因此虚点方法就转化为求虚点空间中虚点之间最小距离。即2.1 节提出的虚点满足的两个条件变为:
(1)归一化条件。
(2)调整后的两个类别之间的距离最小。
2.5 虚点方法的求解
输入变量定义:假设向量空间模型由n维特征向量构成,类别1的分类中心为α(a1,a2,...an),类别2 的分类中心为β(b1,b2,...bn)。
输出变量:特征权重λ1,λ2,λn。
求解原理:

限制条件为:
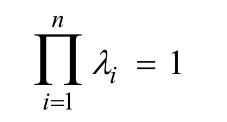
根据以上可知,这是最优化问题,因此本文使用拉格朗日乘数来解决此问题。得到如下函数:
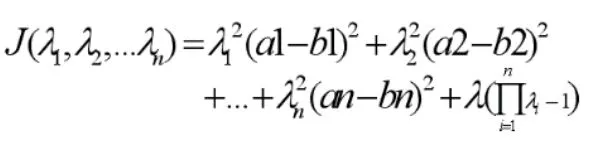
其中λ为拉格朗日乘数。为了求λ1,λ2,…λn。将函数分别对λ1,λ2,…λn求偏微分得:
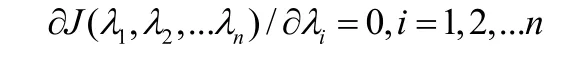
即式子
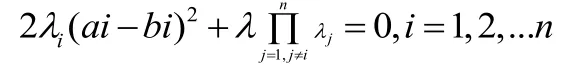
解得:
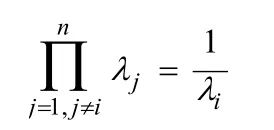
因此第i个特征权重为:

从以上式子可以看出,iλ跟α’和β’的第i个特征的差值成反比。此结果证实了给人的感觉,即为了缩小特征鸿沟,特征值差异越大的,应该将它们分配的权重越低。
3 SVM 与使用虚点原理的SVM
支持向量机方法是建立在统计学习理论的VC 维理论和结构风险最小原理基础上的[17],根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折中,以期获得最好的推广能力(Generalizatin Ability)。支持向量机方法的几个主要优点是:1、可以解决小样本情况下的机器学习问题;2、可以提高泛化性能;3、可以解决高维问题;4、可以解决非线性问题;5、可以避免神经网络结构选择和局部极小点问题[18]。
根据虚点方法可知,在SVM 中使用虚点方法的步骤如下:
(1)在训练集中,根据虚点算法调整特征权重,映射到虚点空间。其中权重应满足归一化条件以及虚点空间中虚点之间的距离最小。
(2)在虚点空间运用SVM 方法,即找出最优分类超平面,此时的最优超平面是虚点空间的最优分类超平面。
(3)用虚点空间的最优分类超平面来分类,即使用虚点空间建立的模型。
如图所示2 对于步骤1,首先分别求训练集中类别1 和类别2 的分类中心,可以用分别求类别1 和类别2 中向量的平均值的方法。然后使用介绍的求解虚点的方法,求出特征权重。根据特征权重重新计算特征向量,相当于将原点映射到虚点空间,此时产生的新的训练集即虚点空间中的训练集。
对于步骤2,跟运用SVM 方法的差别仅仅是训练集的不同,即虚点空间运用的是步骤1 产生的训练集。
4 实验
LIBSVM 是台湾大学林智仁(Chih-Jen Lin)博士等开发设计的一个操作简单、易于使用、快速有效的通用SVM 软件包,可以解决分类问题、回归问题以及分布估计等问题,提供了线性、多项式、径向基和S 形函数四种常用的核函数供选择,可以有效地解决多类问题、交叉验证选择参数、对不平衡样本加权、多类问题的概率估计等。
本文使用 libsvm 附带的包含 47,236 个特征值的数据集rcv1.binary,其中数据量为20,242,本文将此数据集分为10 份做交叉测试即,每份2,024 个数据,最后一份是2,206 个数据。然后依次选取10 份中的一份做测试集,其他9 份合并为一个训练集。核函数选取径向基函数[19]。因为其对应的特征空间是无穷维Hilbert 空间。而Hilbert 空间推广了高斯空间的概念,这点跟虚点方法(VPM)很相似。数据集都是经过了归一化的了。虚点方法参数λ=2,测试的是分类精度。实验结果如表1 所示:
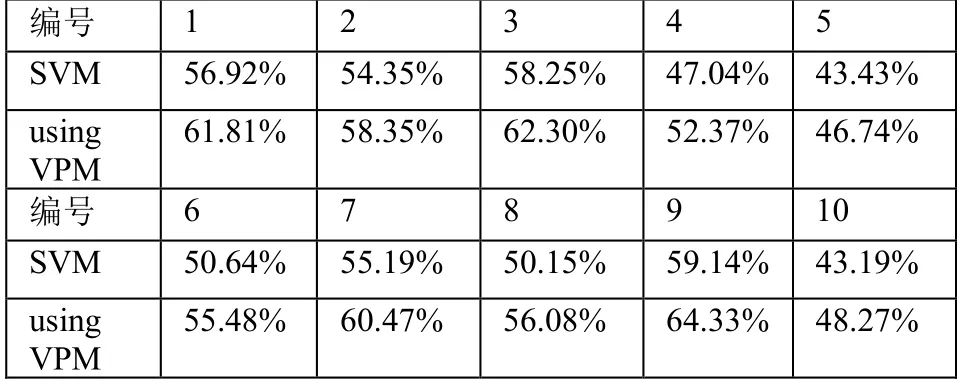
表1 交叉测试结果
由实验结果可知,使用了虚点方法调整的权重后分类的精度得到了一定的提高,这种结果验证了本文提出的虚点方法的有效性。
5 结束语
本文提出了特征值之间存在鸿沟的问题,并介绍了一种使用虚点的方法,这种方法降低了特征值之间的鸿沟,使得分类的效果得到了进一步的提高。该方法是通过重新定义特征权重,调整向量空间模型中点的特征值,即相当于重新定义向量空间中的点,这样的点是相对于原来向量空间模型中的点的矫正映射,即就好像是虚拟点一样,最后问题归结为计算向量空间模型中的点与虚拟点的映射函数。理论分析和实验结果表明运用了虚点方法的基于向量空间模型的SVM 的分类方法的精确度都得到了提高,这种结果验证了虚点方法的合理性。
本文的主要贡献是:
(1)本文提出了特征值之间存在鸿沟的问题,
(2)介绍了一种使用虚点的方法来降低特征值之间的鸿沟。
本文介绍的虚点方法,证明了分类中存在特征鸿沟的问题,提高分类的效果,本文使用的是用平均值求特征值鸿沟的方法,这种方法具有一定的局限性,因此研究求特征值鸿沟的方法以及使用训练集的启发式知识来定义特征值鸿沟与权重分配将是下一步要做的工作。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
数学物理学报(2021年5期)2021-11-19
数学物理学报(2021年3期)2021-07-19
数学年刊A辑(中文版)(2021年2期)2021-07-17
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
海峡姐妹(2019年11期)2019-12-23
数学大王·低年级(2018年4期)2018-05-07
小火炬·阅读作文(2018年4期)2018-03-04
中学生(2015年3期)2015-03-01
散文百家(2014年11期)2014-08-21
