
基于深度学习的虚拟角色制作系统设计与实现
2022-10-14 08:53吴梓龙徐炳权邓炫烨
现代信息科技 2022年16期
吴梓龙,徐炳权,邓炫烨
(广州软件学院,广东 广州 510900)
0 引 言
目前市场上能看到的很多虚拟角色,作品品质精良,热度也非常高。但是,大多数的虚拟偶像作品使用的是脸部标记,需要一套完整昂贵的动作捕捉设备系统来进行演员动作信息采集工作,并且需要专业技术人员才能完成一个较为真实的虚拟角色驱动,虽然使用影视级专业设备效果较好,但是制作周期长,受成本限制,内容也比较短。因此本文探讨了基于深度学习技术结合Kinect V2摄像头的虚拟角色制作系统,利用数字化三维模型及深度学习算法,实现低成本的虚拟角色制作流程。

表1 动作捕捉软硬件公司及其产品
1 虚拟化角色简介
虚拟化角色是指在现实世界中不存在的人物角色,是由人设计出来的,存在于电视剧、电影、游戏、动漫等虚拟世界里的角色,虚拟角色的产生能够满足人们对内心的形象进行构建,因此,虚拟角色在世界各地都具有良好的市场。虚拟化角色的本质是一段程序代码,通过获取真人的动作姿势序列,计算出虚拟角色所需进行的动作姿势序列。虚拟角色的形象在电脑屏幕,电视机,VR眼镜等设备上显示。当真人的动作发生改变时,虚拟角色的形态也随之进行变化,以及利用算法生成当前帧虚拟角色的脸部表情,从而实现角色的虚拟化。
1.1 动作捕捉技术
动作捕捉(Motion capture)的实质就是要测量、跟踪、记录物体在三维空间中的运动轨迹。是指记录并处理人或其他物体动作的技术。它广泛应用于军事,娱乐,体育,医疗应用,计算机视觉以及机器人技术等诸多领域。一般来说常用的运动捕捉设备一般由一下几个部分组成:
传感器:传感器可以获取运动物体的运动位置信息,一般是固定在运动物体的表面或内部。
信息捕捉设备:不同的动作捕捉系统所需的信息捕捉设备不同,如果是机械动作捕捉系统则是利用线路板对电信号进行捕捉。如果是光学动作捕捉系统则利用红外线摄像机。
数据传输设备:对于动作捕捉系统获得的大量动作信息,最终要传送到计算机进行数值处理,数据传输设备就是用来实现此传输过程。
数据处理设备:动作捕捉系统所获取的动作数据是单一的数字数据,需要经过处理后,利用三维模型对数字数据进行可视化展示,完成虚拟角色的动画展示。这个过程需要用到数据处理软件或硬件来实现。数据处理设备如果性能更好,则渲染出来的虚拟角色动作将更加自然、更接近人类的动作姿势。
目前主要的商用动作捕捉技术有以下几种:
(1)机械式运动捕捉:机械式运动捕捉采用机械设备来进行动作的捕捉以及动作轨迹的测量
其优点是成本低,精度高,能够实时测量并同时测量多个角色。缺点是使用方式不方便,机械装置本身会对表演者的动作造成阻碍及限制。使得表演者不能流畅地展现动作姿势。
声学式运动捕捉:常用的声学式运动捕捉设备由发射器、接收器以及处理单元组成。其优点是设备成本较低,但其缺点也比较明显,声学式运动捕捉设备对运动的捕捉有较大的延迟和滞后,不能实现较高的实时性,由于利用声学原理,工作过程中受噪音和多次反射等干扰较大。由于声波在空气中的传播速度受气压、湿度、温度等常规因素的影响较大,需要在其动作捕捉算法中对相应的影响因素进行特定的调整来进行补偿。
(2)电磁式运动捕捉:电磁式动作捕捉设备是较为常用的运动捕捉设备,因为其优点明显,能够记录六位信息,在一帧内得到空间位置、方向位置两种信息,由于表演者需要排练、修改调整节目,电磁式运动捕捉的速度快,实效性高的特点能够满足表演者复杂的需求。设备的定标过程较为简单,目前电磁式运动捕捉技术的发展也较为成熟,鲁棒性好且成本较为低廉。但缺点是对环境的要求较为严格,表演场地不能有金素物体,否则会造成电磁场畸变。导致信息捕捉过程受影响。由于电磁式运动捕捉设备需要连接电缆,表演者的活动范围会大幅降低。而对于剧烈的运动和表演,电磁式运动捕捉设备则不能适用。
(3)光学式运动捕捉:光学式运动捕捉设备通过对物体上所预先设置的特定光点的监视和跟随来完成动作捕捉的过程。由于运用了较少的侵入式设备,光学式运动捕捉系统能够提供范围大,无电缆,无机械装置的空间,表演者能够无束缚地进行表演。其采样率也相对较高,能够满足大多数高速运动的捕捉。所需标记物也可随意增添删减,这使得系统的规模能够根据需求进行灵活变动。光学式运动捕捉的缺点是设备价格及维护价格昂贵,后处理的工作量巨大,适合科研类研究。
(4)惯性导航式动作捕捉:惯性导航式动作捕捉设备是通过惯性导航传感器AHRS(航姿参考系统)、IMU(惯性测量单元)等传感器对表演者的运动加速度、位置、倾斜角等信息进行采集,其优点是没有表演环境的限制,捕捉精确度高,采样快。因为其传感器尺寸小重量轻,表演者佩戴后不会受到肢体的限制。但由于MEMS器件存在明显的漂移,惯性导航式动作捕捉设备无法长时间的人体对动作进行精确的跟踪。
为了获得不受周围光照影响的骨骼信息,本文采用无标记光学编码技术进行设计,光编码(Light coding)是利用连续光(近红外线)对测量空间进行编码,经过感应器读取编码的光线,交由晶片运算进行解码后,产生一张具有深度的图像。其关键的技术在于Laser Speckle镭射光散斑,当其照射到粗糙物体或穿透玻璃后,会形成随机的反射光斑,称之为散斑。散斑具有高度随机性,会随着距离的变换而改变图案,因为空间中的散斑都都具有不同图案,所以任何进入该空间的物体,以及移动的事物,其位置都可以被准确的记录。
1.2 人脸表情生成技术
对于面部驱动模块,本文采用通过VOCA(声控角色动画)进行驱动效果实现。该技术是通过对语音特征提取并训练输出,再对该数据进行解码并通过改变权重来驱动面部表情。可以不受语言的限制,并且无需使用摄像头,提高了便利性。
2 虚拟主播制作方法
2.1 虚拟主播肢体驱动
动作捕捉以微软公司的KinectV2摄像头作为主要的人体肢体动作信息获取方式。所获取的图像效果如图1所示。

图1 三维模型捕获实验
KinectV2在获得深度图像后,Kinect运用分隔技术将人体从复杂的背景中抠像出来,在这个过程中,在深度图像中为每个被跟踪的人创建所谓的分割遮罩(分割遮罩为了排除人体以外背景图像,采取的图像分割的方法)Kinect需做的下一件事情就是寻找图像中较可能是人体的物体,接下来kinect会对景深图像(机器学习)进行评估,来判别人体的不同部位。之后利用已训练好的决策树分类器对人体身体部位进行分类识别,最后生成骨架系统。Kinect人体骨架图如图2所示。

图2 Kinect人体骨架图
2.2 虚拟人物表情生成
在 Intel(R) Core(TM) i7-8700K CPU @3.70 GHz×12,32 GB内存,Ubuntu 20.04.3LTS系统,GeForce RTX 2080 Rev显卡的计算机上验证实现。
通过Anaconda安装Python3.6.8的虚拟环境,并搭载Tensor flow 1.14.0,安装以下所需库numpy、scipy、chumpy、opencv-python、resampy、python-speech-features、scikit-learn、image、ipython、matplotlib、trimesh、pyrender。在虚拟环境安装网格处理库MPI-IS/mesh,该库需要编译Python和c++文件,所以还需安装boost进行编译。
下载经过训练的VOCA模型、音频序列和模板网格、FLAME模型、DeepSpeech模型 (v0.1.0)并置于对应的文件夹。VOCA网络架构与模型架构如表2,图3所示。

表2 VOCA网络架构
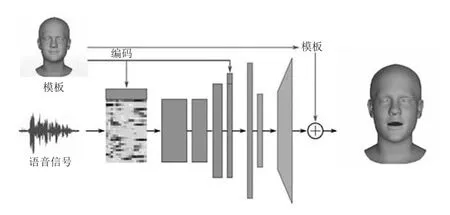
图3 模型架构
3 实验结果及分析
3.1 肢体驱动实验结果
在实验测试中,测试者对虚拟主播形象进行肢体动作控制,共测试了6种不同的肢体动作(如表3所示),测试者共测试了18次,系统成功捕捉到肢体动作并计算出骨骼信息,成功控制了虚拟主播形象17次,成功率为94.4%,识别率达到设想水平。

表3 肢体驱动实验
3.2 表情生成实验结果
在实验测试中,共生成100帧人脸表情动画,其中80帧符合实验预期效果,成功率为80%,数据如表4所示。

表4 表情生成实验
4 结 论
基于深度学习的虚拟角色制作系统能最大程度地轻量化虚拟角色制作的过程,使虚拟角色动作更加真实,展示出广阔的创新空间。高度拟人化的虚拟主播形象,使得其更具有人格化魅力。早期的虚拟主播只是对真人进行模仿,往往以真人主播为原型。本系统通人工智能技术,运用KinectV2摄像机对人体骨骼进行捕捉,获生成对应的骨架。再将训练好的VOCA模型、音频序列和模板网络、FLAME模型、DeepSpeech模型置于对应文件,获得对应的面部表情。从而,让虚拟主播的人物美化度逐渐趋于完善。虚拟角色的制作不受人力物力的限制,节约了制作成本,使得虚拟角色能够以简单轻便的形式展现。突破了传统虚拟角色制作的复杂冗余的障碍。根据对相关市场调查,虚拟数字人相关产业规模正在不断扩大,通过头豹研究所数据可知,当前虚拟数字人市场规模已超2 000亿元,预计2030年将达到2 703亿元,其中身份型虚拟人将在未来发展中占据主导地位。因此,基于深度学习的虚拟角制作系统,能够为不同的需求的虚拟人物进行个性化定制。
猜你喜欢
现代艺术(2022年1期)2022-02-07
动漫界·幼教365(大班)(2021年4期)2021-05-23
看世界·学术上半月(2019年12期)2019-09-10
新民周刊(2017年6期)2017-03-20
名人传记·财富人物(2016年9期)2016-11-10
名人传记·财富人物(2016年9期)2016-11-10
少儿科学周刊·少年版(2015年4期)2015-07-07
小天使·五年级语数英综合(2015年4期)2015-04-20
小品文选刊(2012年6期)2012-05-08
品质·文化(2009年7期)2009-07-17
