
基于句法和全文信息增强的中文事件检测方法
2022-10-13 08:42吴浩正
数据采集与处理 2022年5期
王 红,吴浩正
(中国民航大学计算机科学与技术学院,天津 300300)
引 言
事件检测是事件抽取[1]任务中的一项重要子任务,旨在从非结构化文本中识别出事件的触发词并对其进行分类。事件由触发词和事件元素构成,事件触发词为标识事件发生的词或短语,事件元素是事件的主要组成部分。
早期的事件检测模型大多是基于人工定义的特征工程和模式[2-5]对事件触发词进行抽取,其研究的重点在于如何构建出有效的特征和模式来提高事件检测的效果。目前大多数事件检测的研究采用神经网络方法进行,相较于传统的特征工程方法,神经网络模型可以通过自主训练来拟合文本的语义特征,实现对事件触发词的自动抽取,避免了人工定义大量的特征。
由于中文事件检测中存在触发词不匹配的问题,目前中文事件检测模型大多将事件检测转化为对字的序列标注任务,并引入词语的语意信息来丰富特征,但这种方式无法学习到触发词和其他关键词语之间的关系,尤其是长距离依赖词语更容易受到很多无关信息的干扰。依存句法关系如图1所示。
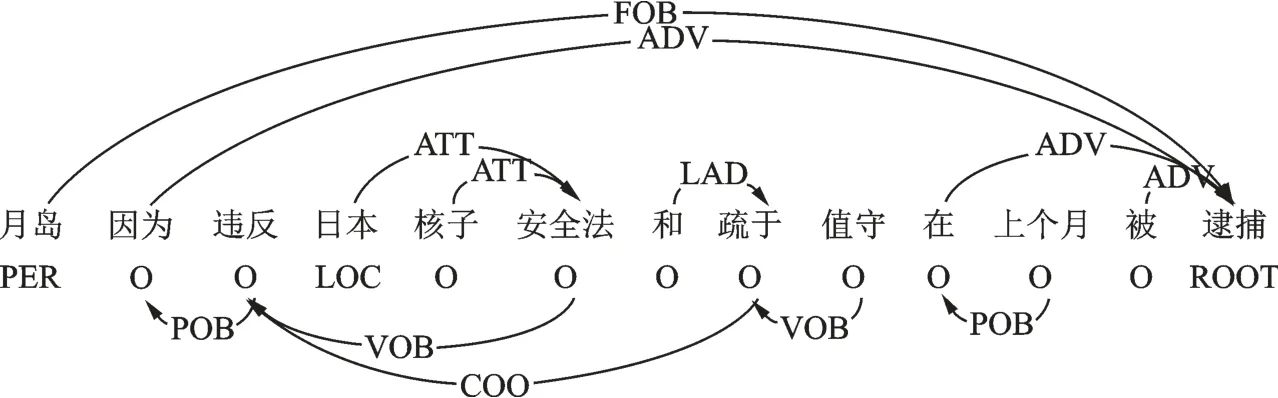
图1 依存句法关系Fig.1 Dependency syntax
从图1可知,若模型可以通过触发词“逮捕”和词语“违反”之间的联系,学习到“违反法律导致逮捕”的事理逻辑,就可以通过句法关系增强触发词特征。另外,当前中文事件检测模型大多以一个句子内的语义信息进行事件检测任务,缺乏对文章全局信息的考虑。如对于一篇主题为地震的文章,其中出现的事件大多与地震相关,如出现伤亡、财产损失事件的概率会更高。因此,如果模型能够借助句法关系和文章全局信息进行特征增强,将有助于提高触发词检测的效果。
在英文事件检测[6-16]任务中,Chen等[6]提出DMCNN模型,首次使用神经网络进行事件抽取任务,通过动态多池化机制,提升了事件抽取的效果。Zhao等[7]提出DEEB-RNN模型,通过分层机制使用文档嵌入增强特征,但会产生冗余信息干扰模型效果。Deng等[8]将事件实例和事件本体中预定义的事件类型连接起来,通过不同类型事件之间的联系,提升事件检测的效果。文献[11-13]基于句法关系使用图神经网络方法进行事件检测,其中,Nguyen等[11]第一次将GCN用于事件检测任务,证明了句法信息在事件检测任务中的有效性。Cui等[13]在句法关系的基础上引入了关系类型信息,并在训练过程中对关系进行更新,以学习出更优的节点和边的特征。还有学者探索了阅读理解[14]、无触发词[15]、跨媒体信息[16]的事件检测方法,但上述方法均基于英文语料进行事件检测,由于中文存在触发词不匹配的问题,因此无法直接运用在中文任务中。
针对中文事件检测[17-26]任务,大部分工作将其转化为基于字的序列标注问题,解决了中文触发词不匹配的问题。但中文的一个字所包含的语义信息相较于英文单词欠缺很多,因此后续工作转向将字和词的语义信息结合进行触发词的抽取。其中,Lin等[18]针对中文特性提出NPN模型,该模型使用两个DMCNN[6]模型分别提取字和词的信息,之后通过触发词块生成器实现触发词的抽取;Ding等[19]提出TLNN模型,通过Lattice机制动态融合字和词的信息,并增加外部知识库缓解词语的多义问题,但存在信息融合不完全的问题;丁玲等[20]通过融合多个粒度的信息和多种分词信息进行中文事件检测,一定程度上缓解了分词问题,但会造成信息冗余;Cui等[21]和吴凡等[22]将字词建模为图结构,通过图神经网络学习字词之间的关联。上述方法通过不同方式将字和词的信息融合,一定程度上丰富了特征,但没有考虑词语之间的关系和文章全局信息的作用。
针对上述问题,本文将GCN和Bi-GRU网络相结合,提出了一种基于句法和全文信息增强的中文事件检测(Syntactic and document feature enhanced event detection,SDEED)模型。该模型在基于字符的序列标注基础上,将句法和全文信息分别融入到词语和句子的向量表示中,同时引入注意力和门控机制动态融合多个粒度的特征信息,达到特征增强的目的。通过句法和全文信息的特征增强,旨在解决词语间句法关系利用不充分以及缺乏文章全局信息的问题,以提升中文事件检测的效果。
1 SDEED事件检测模型
本文提出的SDEED模型如图2所示。模型主要包含编码模块、句法特征增强模块、全文信息增强模块和输出模块。编码模块:编码模块将输入的字和词通过BERT-wwm[27]获得预训练的嵌入向量。句法特征增强模块:以句子中的词和句法关系构成的邻接矩阵为输入,通过GCN聚合与当前词语有关系的词语特征信息,学习到句法信息增强的词语表示,将其融合到字向量后送入下一层进一步提取特征。全文信息增强模块:首先通过Bi-GRU学习字符级别的上下文信息,之后使用注意力机制计算每个字的权重,加权求和得到句子的向量表示,再通过一层Bi-GRU将全文信息融合到句向量中。最后使用门结构将句向量和字向量融合,得到字的混合表示用于最后的序列标注。输出模块:输出层通过CRF模型计算标签概率并对序列中的每个字进行标注。
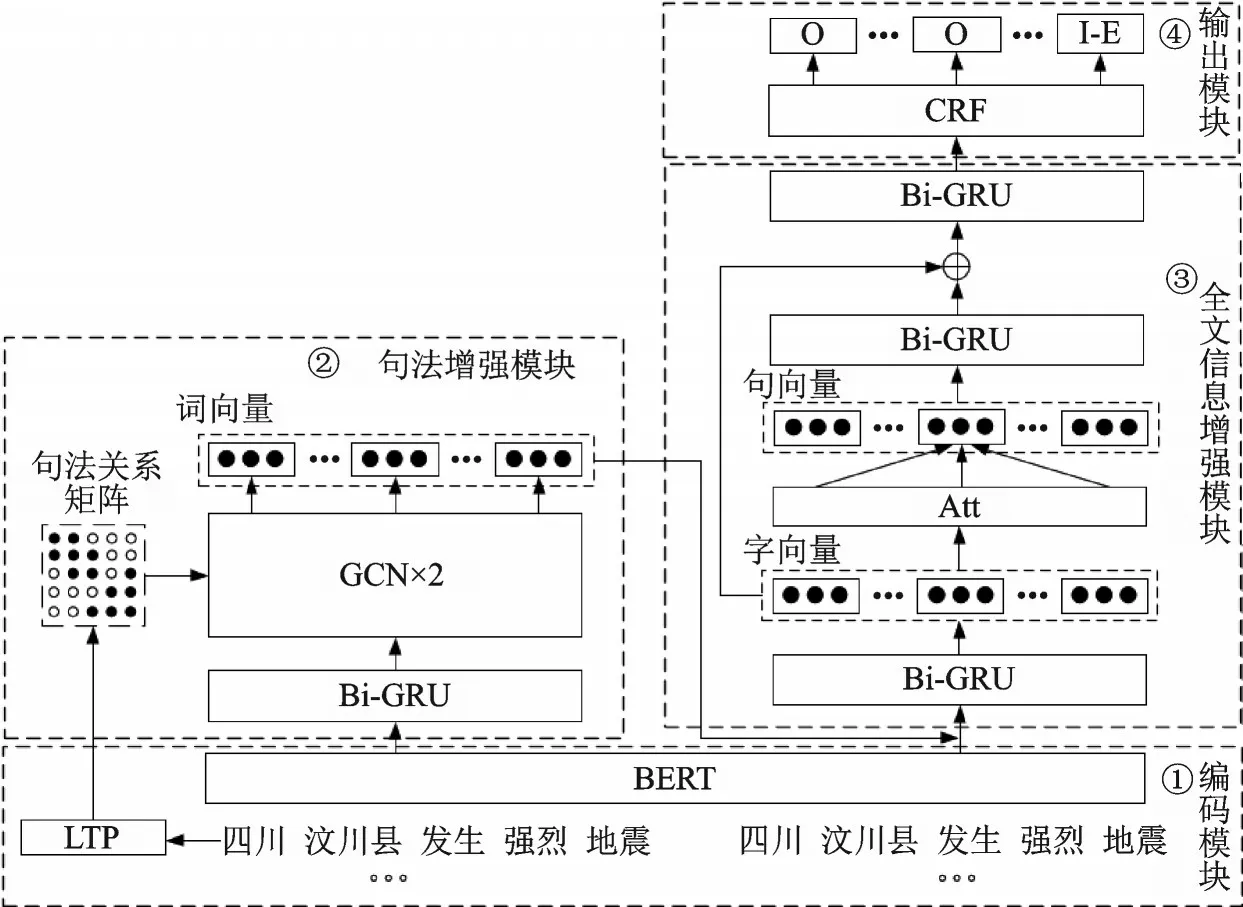
图2 SDEED模型Fig.2 SDEED model
1.1 编码模块
模型以事件文章作为输入,对于一篇输入的文章D={S1,S2,S3,…,Sn},其中Si表示文章中第i个句子。针对每一个句子Si,首先进行分字和分词处理,分字结果表示为Sc={c1,c2,c3,…,cx},其中ci表示句子中第i个字,分词结果表示为Sw={w1,w2,w3,…,wy},其中wi表示句子中的第i个词。分词工具使用哈工大发布的LTP语言技术工具[28],在分词的过程中加入了外部字典,最大限度降低分词错误带来的影响。之后将分字结果和分词结果分别送入BERT-wwm得到预训练的字向量Ec=BERT-wwm是在BERT的基础上加入了Whole word masking机制实现对中文的优化。由于BERT模型仅用来获取预训练好的字向量和词向量,并不参与模型训练,所以不会增加模型训练的复杂度。
1.2 句法特征增强模块
根据分词结果进行依存句法分析,并将句法关系建模成图结构作为图卷积网络的输入。由于句法关系可以直接将句子建模为图结构,因此本文使用图卷积网络来捕获词语之间的关系,从句法层面实现词向量的特征增强。
图卷积网络是将传统的卷积操作推广到图结构数据中,其核心思想是通过聚合图中与当前节点有联系的节点特征来更新节点的表示。其计算公式为

式中:A为邻接矩阵,存储着节点之间的关系;D为A的度矩阵;H为每一层的特征矩阵,对于第一层GCN来说,H就是输入句子的嵌入矩阵;W为可训练的参数矩阵;b为偏置项。使用图卷积网络来聚合与词语之间的特征信息,可以突出触发词和与之相关的关键词语的联系,避免无关词语的噪声干扰,从句法层面实现词向量的特征增强,有助于提升触发词识别的效果。
具体来说,模型首先使用LTP自然语言处理工具对输入的句子进行依存句法分析处理,得到句法分析结果。根据依存句法关系将句子建模为图结构,节点为句子中的词,边为词之间的句法关系。之后通过Bi-GRU首先学习词语之间的上下文信息,再使用图卷积神经网络学习词语的优化表示,最后将学习到的词语表示依次融合到BERT预训练模型得到的字向量中,以此实现句法特征增强的目的。句法特征增强模块如图3所示。

图3 句法特征增强模块Fig.3 Syntactic feature enhancement module
1.3 全文信息增强模块
1.3.1 字符上下文特征提取
GRU是由LSTM网络发展而来,减少了参数量的同时,解决循环神经网络中梯度消失的问题,其核心思想是通过门控机制来控制信息的流动。GRU的计算公式为
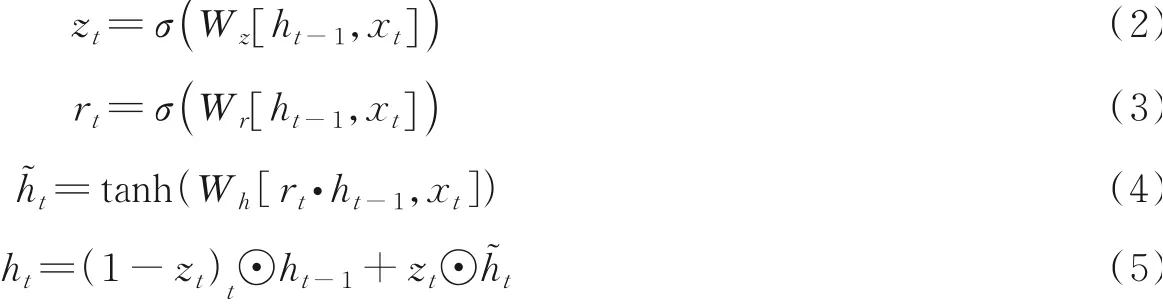
由于循环神经网络的特性,GRU只能根据之前的特征信息来预测当前的状态,但在自然语言文本中,当前时刻的状态不仅与上文的文本有关,还可能与下文的某些文本有联系。因此,模型以字为输入,使用Bi-GRU网络分别正序和逆序学习句子内字的上下文信息,最后将两个输出进行拼接,得到包含句内上下文信息的字符向量。
对于一个句子Si,首先通过句法特征增强模块获得句法关系增强的词向量表示,之后将其与BERT模型获得的字向量相融合得到句子级GRU的输入将Es送入句子级双向GRU中学习句内的特征信息,得到句子的正向表示Hsf和反向表示Hsb。将Hsf和Hsb拼接获得融合上下文信息的字符向量。

之后使用注意力机制计算句子中每个字对于句子含义的权重为

再根据权重通过加权求和的方式得到句子的向量表示。

1.3.2 全文信息特征提取
全文信息和字符上下文特征的提取方法相同,也采用Bi-GRU进行学习,区别在于字符级GRU的输入的基本单位为字,而篇章级GRU的输入的基本单位为句子向量,通过Bi-GRU来学习句子之间的上下文信息,可以将全文信息融入句子的表示中,使模型可以利用文章全局语境信息提升事件检测任务的效果。
篇章级GRU的输入为注意力机制学习得到的每个句子的向量表示将Ep送入篇章级双向GRU层中进行编码,得到句子的正向表示Hpf和反向表示Hpb。将Hpf和Hpb拼接获得融合上下文信息的句子表示Hp,即

之后通过门结构将字向量和句向量进行融合,其计算公式为

式中:W为门结构参数矩阵;b为门结构偏置向量;con为向量拼接操作;sigmoid为激活函数。通过式(10)计算得到门结构的值后,再使用式(11)将Hs和Hp通过门结构进行融合,得到文章上下文信息增强的句子向量。通过门结构可以使模型学习到不同上下文环境下两种粒度事件表示的重要程度,从而获得更加丰富的特征表示。
将各粒度的向量融合到字向量之后,再经过一层Bi-GRU,得到融合字、词、句法和文章全局信息的混合表示。
1.4 输出模块
输出模块以最终的混合表示为输入,通过CRF层对序列进行标注,标注采用BIO标注策略。通过Bi-GRU可以预测出序列中的字属于每一个标签的概率,但标签之间存在着一定的依赖关系,如“I-”标签应该出现在“B-”标签之后;“O”标签不能出现在“B-”标签和“I-”标签之间等。CRF是一种条件概率无向图模型,通过计算标签之间的转移概率,即一个标签后出现其他类型标签的概率,以保证标签预测的合理性。若通过Softmax分类器预测标签的结果,会忽略标签之间的依赖关系,导致标签预测错误。因此本文模型选择CRF模型来计算最终标签的概率。
在计算最终标签时可以将标签得分分为发射概率E(xi,yi)和转移概率T(yi-1,yi)两部分,发射概率由Bi-GRU输出得到,即每个字属于各个标签的概率,转移概率由CRF计算得到。将两部分相加得到所有可能路径的得分,选择得分最高的路径作为最终的标注结果。其计算公式为
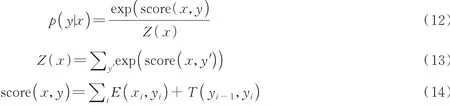
1.5 损失函数
模型使用交叉熵损失函数计算模型损失,对于输入的句子T={t1,t2,…,tn},其对应的标签序列为Y={y1,y2,…,yn},损失函数计算公式为

2 实验与分析
2.1 数据集与评价指标
本文选用ACE2005[1]和CEC[29]数据集进行实验。ACE2005中文语料库是中文事件检测中广泛采用的数据集,其中包含633篇中文文档,标注了事件的触发词和元素。中文突发事件语料库(CEC)是由上海大学语义智能实验室构建,语料库包括5种突发事件共计332篇突发事件的新闻报道。与ACE2005中文语料库相比,CEC语料库虽然规模较小,但是对事件和事件元素的标注更加全面。
实验采用的事件检测评价指标为精确率(P)、召回率(R)和F1值。精确率用来衡量被分类为正例的样本中,真实值也为正例的比例,其计算公式为

召回率用来衡量所有正例中被分类为正例的样本比例,其计算公式为

F-Measure是精确率和召回率的加权平均值,通过综合考虑精确率和召回率的结果来对模型进行较为准确的评价,其计算公式为

当参数α取值为1时,就是最常见的F1值,即本实验的模型评价指标,其计算公式为

2.2 实验参数及实验结果
实验的参数设置如表1所示。本实验将ACE2005和CEC语料按照8∶1∶1的比例分成训练集、验证集和测试集。

表1 实验参数Table 1 Experimental parameters
2.2.1 对比实验
本文选用了以下3个模型在ACE2005数据集上进行比较:
(1)Rich-C[5]模型针对中文的特性,通过人工设计的特征抽取文本中的触发词和事件元素。
(2)NPN[18]模 型 使 用DMCNN网络 分 别 学习字和词的语义信息,使用学习到的字词混合表示进行触发词的抽取。
(3)TLNN[19]模型融合字和多种分词结果的信息,并增加HowNet知识库缓解词语的多义问题。
(4)文献[20]通过融合多个粒度的信息和多种分词进行事件检测。
(5)L-HGAT[21]模型将事件标签信息融入模型计算中,同时通过图注意力网络学习字词之间的关系来优化字词的特征。
实验结果分别如表2,3所示。从表2,3可以看出,本文模型在触发词识别和分类上均取得了更好的结果,其中触发词识别的效果提升高于触发词分类的效果提升,证明本文方法对于触发词的识别更加有效。SDEED模型相较于Rich-C模型F1值提升了6.1%,证明基于神经网络的方法可以在避免人工定义特征的同时取得更好的效果。相较于NPN模型,本文模型两项任务均取得更好效果,由于NPN模型枚举窗口内所以字符的组合生成候选触发词,产生了较多冗余信息,因此影响了模型的性能。TLNN模型和文献[20]模型虽然通过分词工具减少了冗余信息,但依然无法避免冗余信息对结果的影响。与L-HGAT模型相比,SDEED模型由于加入了文章全局信息,因此取得较好结果。
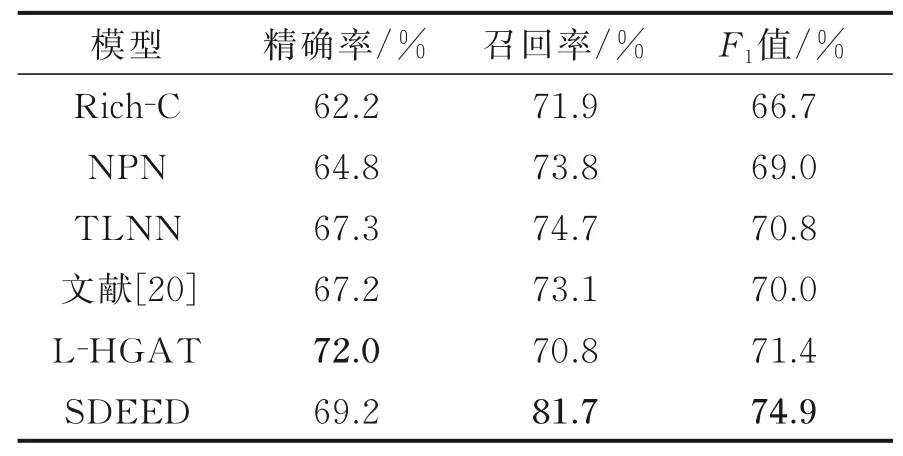
表2 ACE2005触发词识别结果Table 2 ACE2005 trigger identification results
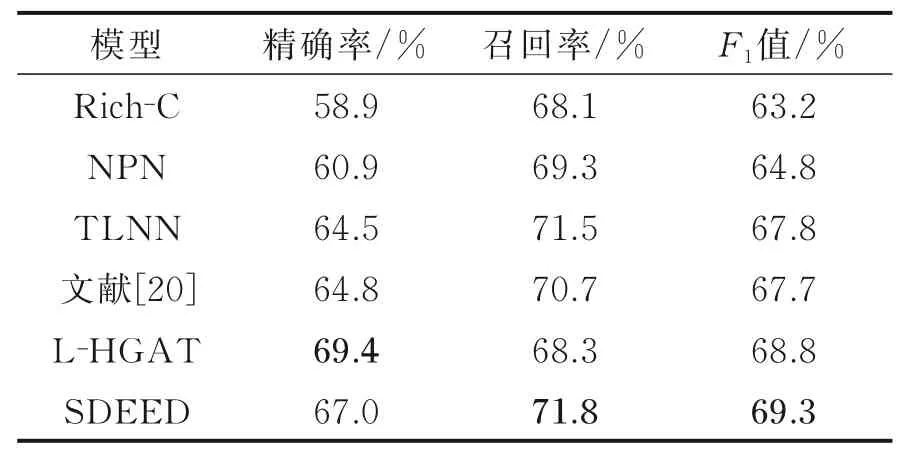
表3 ACE2005触发词分类结果Table 3 ACE2005 trigger classification results
在CEC数据集上,本文选用以下模型进行对比:
(1)DEEB-RNN3[7]模型通过分层和注意力机制,使用多层Bi-GRU提取句子和文章中的特征信息,进行事件检测任务。
(2)NPN[17]模型同上,在此不重复介绍。
(3)Lattice-LSTM[30]模型使用Lattice机制利用了不同分词结果的词语信息,缓解了分词错误的问题。
实验结果如表4所示。从表4可以看出,SDEED模型相较于DEEB-RNN3模型精确率提升了5.58%,召回率提升了3.12%,F1值提升了4.28%。原因在于此模型仅使用了词级别的句子信息,对于句内的语义信息利用不够充分。同时,该模型使用整个文档的嵌入向量来丰富每个词的特征,这样做融合了部分有效特征,但也融合了大量与当前词语无关的特征,造成了特征的冗余。SDEED模型相较于Lattice-LSTM模型F1值提升了2.14%,Lattice-LSTM模型通过分词工具进行分词,避免了冗余信息的产生,因此效果优于NPN模型。但两个模型均未考虑文章全局语义信息,且存在冗余信息干扰,因此效果低于SDEED模型。实验结果案例如图4所示。

表4 CEC实验结果Table 4 CEC experimental results

图4 事件检测案例Fig.4 Examples of event detection
2.2.2 消融实验
为证明句法和全文特征的有效性,在CEC数据集进行了消融实验,实验结果如表5所示。表5中,Char模型仅使用字向量作为输入,Char+Word模型在Char模型上使用词语的语义信息丰富特征,Char+Dep使用词语和句法信息进行特征增强,Char+Sentence仅使用文章上下文信息进行特征增强,SDEED使用词语、句法和文章上下文信息进行特征增强。从表5的实验结果可知:

表5 消融实验结果Table 5 Ablation experiment results
(1)Char模型仅使用字级别的特征进行事件检测效果较差,因为仅依靠字之间的语义很难学习到复杂的语义关系。
(2)Char+Dep模型将字级别特征和融合句法关系的词级别特征联合,相较于Char+Word模型,取得了更好的结果。原因在于通过图神经网络可以将句法关系中更加丰富的语义特征融合到词语的表示中,实现特征的增强。
(3)Char+Sentence模型融合了句子之间的上下文关系,相较于Char模型F1值提升了2.24%,这是由于文本中的事件之间是有一定联系的,通过学习事件之间的联系可以获得特征更丰富的事件表示。
(4)SDEED模型取得了最好的效果,原因在于通过图神经网络学习句法关系增强的词语表示,使得模型可以学习到在不同语境下词语的特征信息,避免了仅依靠词语的语义信息导致触发词识别错误的问题。通过Bi-GRU学习文章上下文中的特征信息有助于模型从全文的角度对事件触发词进行预测,保证了预测结果的一致性,提升了模型的整体效果。
通过消融实验结果证明本文通过句法和全文信息进行特征增强可以获得更丰富的语义特征,有助于提升中文事件检测效果。
2.2.3 GCN层数的影响
本节研究了GCN的层数对模型整体性能的影响,将GCN层数分别设置为1~6进行实验,实验结果如图5所示。从图5可以看到,在层数为2时,模型取得了最优的结果,之后随着层数的增加结果逐渐下降。出现这种情况的原因如下:首先,GCN层数为1时,模型只能利用到一阶句法关系,即有直接连接的句法关系,但大多数重要的句法关系是以二阶甚至更高阶得到形式存在的,一层GCN不足以利用到高阶的句法关系,因此表现较差;其次,当GCN层数越来越多时,通过多次的聚合操作会导致节点的表示过于接近,使得模型难以对节点进行分类,从而导致模型性能下降。
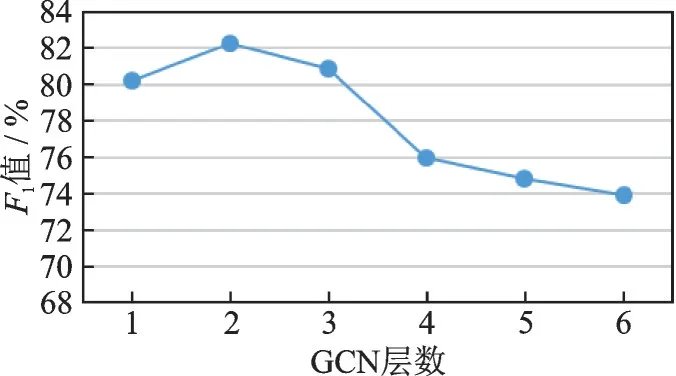
图5 GCN层数的影响Fig.5 Influence of GCN layers
3 结束语
本文提出了一种句法和上下文特征增强的事件检测神经网络模型SDEED,模型通过句法和文章上下文的语义信息丰富了事件的特征表示,解决了目前中文事件检测中句内语义信息利用不充分和缺乏文章全局语义信息的问题,提升了中文事件检测效果。未来可以优化字词的特征提取方法,如引入外部知识库将更加丰富的开放领域信息融合到字词的向量表示中或将多种分词结果和句法关系结合缓解分词导致的错误传播问题,从而进一步提升中文事件检测的效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
大连民族大学学报(2021年2期)2021-07-16
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
