
深度学习在有限视角稀疏采样光声图像重建中的应用
2022-10-13 08:40候英飒
数据采集与处理 2022年5期
孙 正,候英飒
(1.华北电力大学电子与通信工程系,保定 071003;2.华北电力大学河北省电力物联网技术重点实验室,保定 071003)
引 言
生物光声成像(Photoacoustic imaging,PAI)是一种新型复合功能成像技术,其原理是用短激光脉冲照射生物组织,组织吸收光能量后受热膨胀并向外辐射宽带(~MHz)超声波(即光声波),超声换能器采集光声波,送入计算机后进行图像重建,显示目标的形态结构和功能特性[1]。
高质量的图像重建是PAI技术的关键,常规重建方法有反投影(包括通用反投影(Universal back projection,UBP)和滤波反投影(Filtered back projection,FBP))、时间反演(Time-reversal,TR)、基于傅里叶变换的方法、延迟求和(Delay and sum,DAS)以及基于模型的方法等[2-3]。上述方法一般基于理想成像条件的假设,例如:入射光在被测目标表面均匀分布、组织中的声速恒定、忽略超声波在组织界面的反射和散射、探测器具有理想特性和足够带宽、采集光声信号的时间和空间采样率足够高且能够获得全视角完备测量数据等。但在实际应用中很难满足上述理想条件,采用代数重建技术(Algebraic reconstruction technique,ART)可在一定程度上提高图像质量,但由于在迭代过程中需要反复计算前向成像算子及其伴随算子,因而此类算法往往非常耗时,而且需要合理选择适当的正则化方法及其参数,重建图像质量很大程度上依赖于有关成像目标的先验假设模型,而该假设在实际应用中往往不能严格满足[4-6]。
近年来,深度学习(Deep learning,DL)已成为人工智能领域的研究热点,基于其在计算机视觉领域的巨大成功,利用监督学习进行图像重建也成为医学成像的一个新兴研究领域[7]。2017年,Antholzer等[8]首次利用卷积神经网络(Convolutional neural network,CNN)重建光声图像,CNN通过学习权值/滤波器提取最佳特征,以减轻逆问题求解中的不适定性。按照是否进行迭代,可将基于DL的光声图像重建方法分为两类:非迭代方法和学习迭代方法(Learned iterative method)[9],这两类方法的选择在一定程度上是重建速度与质量之间的权衡。本文从非迭代和迭代两个角度对根据有限角度稀疏测量数据重建光声图像的DL方法进行总结和归纳,分析各方法的优势和不足。
1 基于非迭代深度学习的光声图像重建
根据神经网络输入和输出的不同将非迭代方法分为3类:信号增强(信号到信号的转换)、图像增强(图像到图像的转换)和信号到图像的转换[9]。
1.1 信号增强
在对目标进行光声扫描时,由于生物组织的复杂性以及成像设备的局限性等,探测器采集的光声信号中通常存在噪声,信噪比较低,因此信号去噪和增强是图像重建之前的重要步骤。例如,Awasthi等[10-11]提出了一种对光声信号正弦图(Sinogram)数据进行超分辨率增强和去噪的方法,将含有噪声的正弦图数据作为CNN的输入,训练网络使其能够对输入数据进行去噪和增强,最终输出噪声明显减少的正弦图数据,进而利用标准重建算法(如FBP或TR)重建图像,得到伪影明显减少的图像。该方法不同于其他像素级的模型,它以正弦图作为输入,具有高鲁棒性和泛化能力。
1.2 图像增强
基于CNN的图像增强方法作用于图像域,主要分两个步骤进行:
步骤1初始重建,即采用标准重建算法(如FBP[6,8,12-14]、TR[5,15-17]、DAS[18-20]和基于动态孔径长度校正的UBP[21-22]等)根据探测器采集的原始光声信号重建低质量的初始图像。
步骤2后处理,即将初始图像作为训练后CNN的输入,对初始图像进行优化,以去除伪影,提高图 像 质 量。采 用 的CNN框 架 主 要 有U-Net[5-7,12,14,20-24]、S-Net[6]、全 密 集U-Net(Fully dense U-Net,FD-UNet)[15]、零空间网络(Nullspace network)[13]、残 差 网 络(Residual network,Res-Net)[13]、双 框 架U-Net[14]、紧框架U-Net[14]、具有梯度惩罚的Wasserstein生成对抗网络(Wasserstein generative adversarial network with gradient penalty,WGAN-GP)[16]、注意块U-Net(Attention block U-Net,AB-U-Net)[17]、在U-Net中加入Dropout层以限制模型过拟合的网络[19]以及生成对抗网络(Generative adversarial network,GAN)[25]等,如表1所示。

表1 基于DL的光声图像增强主要方法对比Table 1 Comparison of main methods based on DL for photoacoustic image enhancement
不同的网络体系对图像质量的改善程度也不同,例如双框架U-Net、紧框架U-Net、FD-UNet、WGAN-GP和GAN均优于U-Net,零空间网络优于Res-Net[13]。以“TR+WGAN-GP”方法为例,重建图像的峰值信噪比(Peak signal to noise ratio,PSNR)可达35.24 dB,结构相似度(Structural similarity,SSIM)可达0.99,明显优于“TR+U-Net”和TR重建质量[16],如图1所示,但WGAN-GP的训练时间是U-Net的两倍。此外,将多幅低质量图像同时输入网络可提高后处理效果。例如,Awasthi等[18]将分别利用两种标准重建方法得到的两幅图像作为训练后网络的输入,提取图像特征,并通过上采样和下采样重建最终的图像。
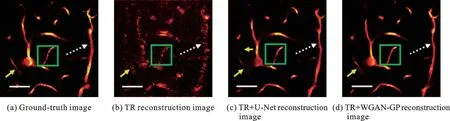
图1 双光子显微血管图像的重建结果[16]Fig.1 Reconstruction results of vascular two-photon microscopic images[16]
基于CNN的光声图像增强方法的局限性在于CNN重建图像的性能很大程度上取决于初始重建质量,在初始重建中缺失的图像特征很可能在CNN重建图像中仍然缺失或被错误地重建[15]。此外,由于隐含在实际测量数据中的细节信息在图像重建后会丢失,而CNN往往无法恢复出微弱信号,导致图像精细结构的丢失。
1.3 信号到图像的转换
基于DL的信号到图像的转换是通过“数据”驱动“学习”,直接利用探测器测量数据重建高质量图像。CNN学习信号到图像的映射,将探测器测量的原始光声信号或经过预处理的信号作为训练后网络的输入,网络提取光声信号中的有用特征并将其转换成图像的形式,最终输出高质量的重建图像。与图像增强方法相比,此过程省略了利用常规重建方法完成信号到图像转换的步骤。主要方法如表2所示,其中除“输入三维光声信号阵列+upgUNET方法”外,所列方法主要针对于光声层析成像(Photoacoustic tomography,PAT),是否适用于光声显微成像(Photoacoustic microscopy,PAM)则需进一步实验验证。

表2 基于DL的光声信号到图像转换方法对比Table 2 Comparison of methods based on DL for photoacoustic signal-to-image transformation
1.3.1 输入信号
CNN的输入数据包括以下5种:(1)探测器采集的原始光声信号[26];(2)线性插值后的光声信号[27];(3)像素插值后的光声信号[27];(4)将具有时间和探测器维度的二维光声信号转换成具有两个空间维度和一个信道维度的三维信号阵列[28];(5)归一化的光声信号及其时间导数,以提取原始信号在时间轴上的深层特征[29]。
当网络的输入数据不同时,重建图像的质量也不同。例如Guan等[27]提出的像素级深度学习(Pixel-wise deep learning,Pixel-DL)方法,将经过像素插值的光声信号作为网络输入,以达到将更多信息输入网络进而简化网络结构的目的,与将线性插值后的光声信号作为网络输入的方法(即改进的直接深度学习(Modified direct-DL,mDirect-DL))相比,重建图像质量更高,如图2所示。
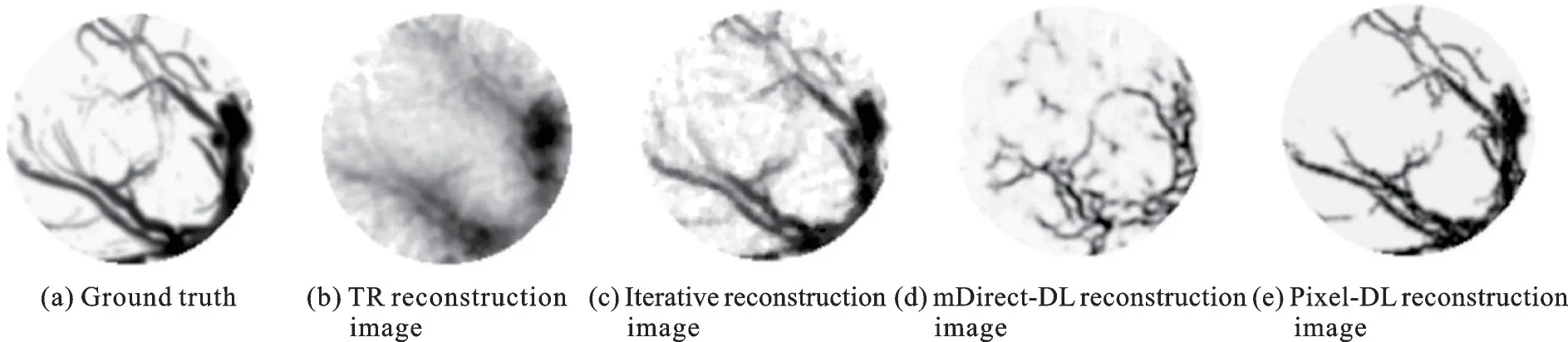
图2 小鼠大脑血管光声层析图像重建结果[27]Fig.2 Reconstructed PAT images of mouse brain vasculature[27]
1.3.2网络架构
Lan等[26]搭建了由两个并列U-Net构成的网络,称之为DU-Net,如图3所示。与标准重建方法和单一U-Net相比,该方法重建图像的PSNR和SSIM分别可达25.438 dB和0.611。Min等[28]提出了一种多通道输入网络upgUNET,如图4所示,该网络与U-Net的不同之处在于其输入信号是三维阵列。实验结果表明,该方法重建图像的PSNR和SSIM分别可达27.73 dB和0.754,重建图像质量明显优于U-Net和标准重建方法。Tong等[29]将特征投影网络(Feature projection network,FPnet)和U-Net相结合,将经过归一化处理的光声信号首先输入FPnet,完成信号域到图像域的转换,然后将生成的图像作为U-Net的输入,进一步改善图像质量,如图5所示。与标准重建方法以及图像增强中的FBP+U-Net[6]方法相比,该方法重建图像的质量明显提高。
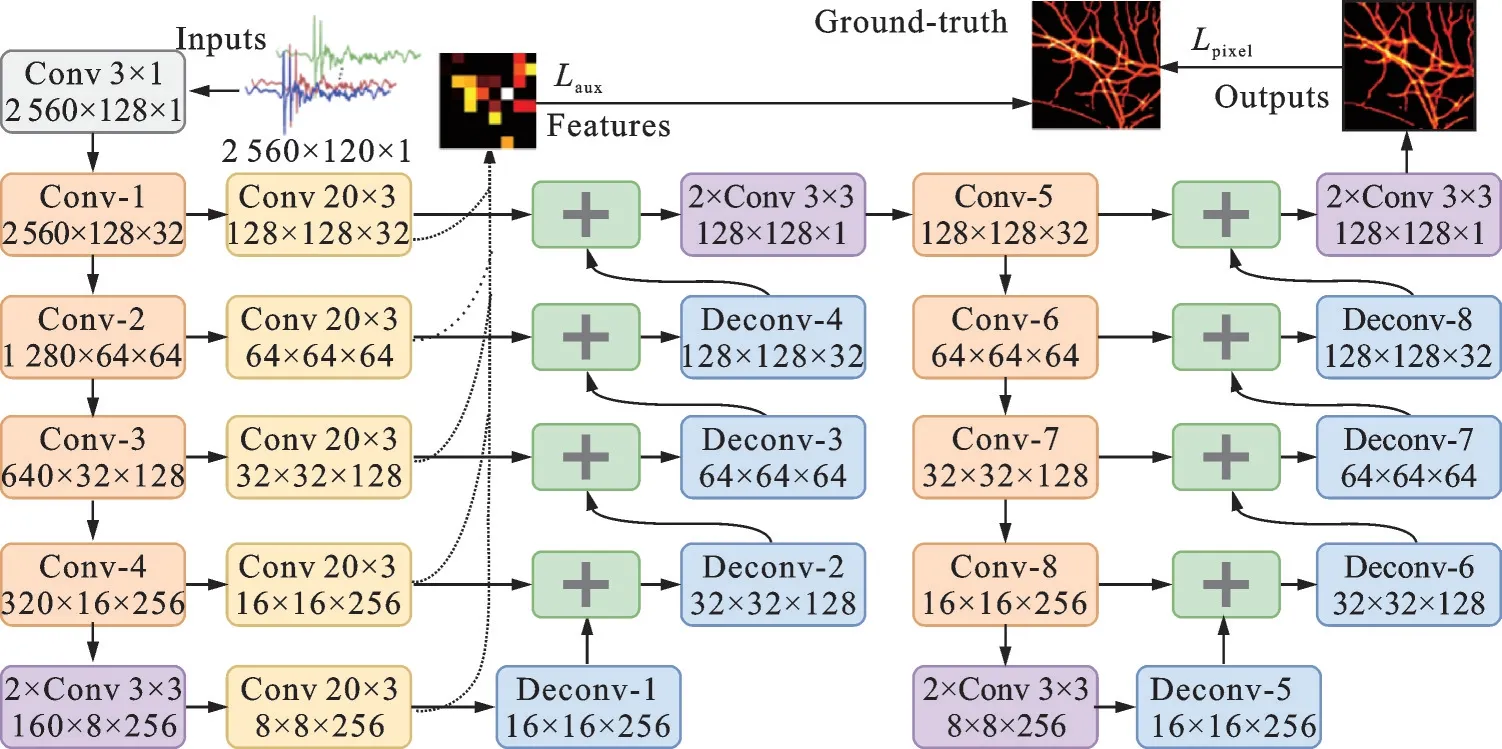
图3 DU-Net体系结构[26]Fig.3 Architecture of DU-Net[26]

图4 upgUNET体系结构[28]Fig.4 Architecture of upgUNET[28]

图5 FPnet体系结构(U-Net作为后处理)[29]Fig.5 Architecture of FPnet with the U-Net as a post-processing network[29]
采用不同网络架构重建图像的质量也会受到输入信号的影响。如1.3.1节中所述,以像素插值后的光声信号作为网络输入时得到的重建图像质量明显优于以线性插值后的信号作为输入时的重建图像,这是由于对探测器测量数据进行像素插值后,网络将不再需要额外学习时域到图像域的映射关系,因而提高了网络的工作效率。此外,将二维信号映射成三维信号作为网络输入也可以提高网络的学习效率[28]。
1.4 “图像到图像”与“信号到图像”转换方法的对比
以U-Net和FD-UNet网络框架为例,本节对“图像到图像”和“信号到图像”转换方法的性能进行对比。由于不同成像实验条件下超声换能器阵元数、光声信号采样率、训练和测试数据集及GPU的选取等均存在差异,因此只对比相同实验中不同方法的结果,分别如表3和表4所示。
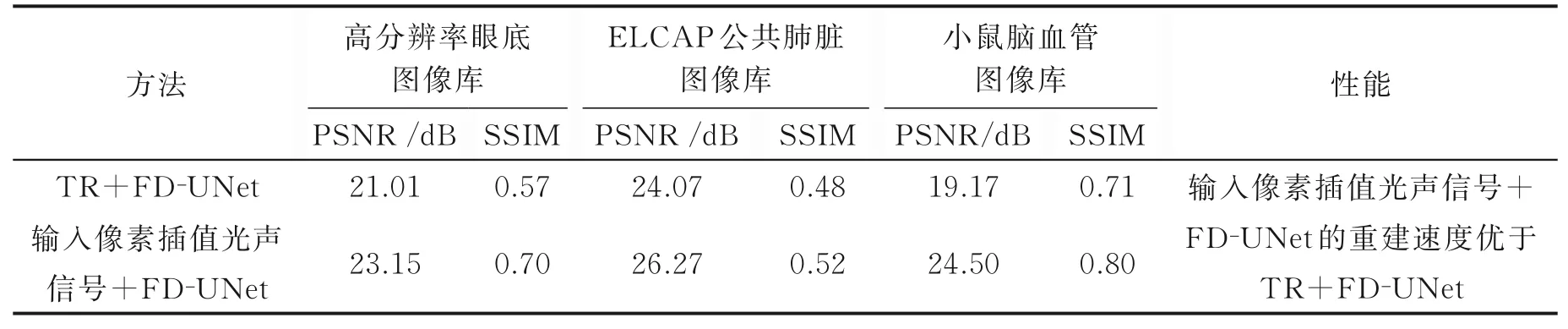
表3 基于FD-UNet框架的“信号到图像”转换方法与图像增强方法的对比[27]Table 3 Comparison between signal-to-image conversion method and image enhancement method based on FD-UNet framework[27]
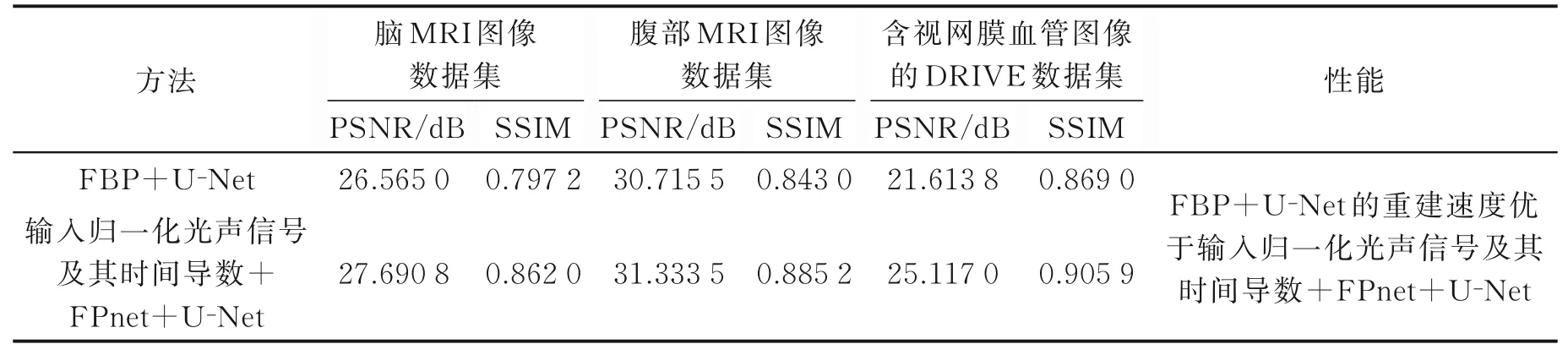
表4 基于U-Net框架的“信号到图像”转换方法与图像增强方法的对比[29]Table 4 Comparison between signal-to-image conversion method and image enhancement method based on U-Net framework[29]
与“信号到图像”的转换相比,“图像到图像”的转换中CNN的输入是采用常规方法重建的初始图像,而CNN不能直接访问探测器测量数据,图像增强的过程中可能丢失原始光声信号中隐含的有用信息,导致图像质量下降,因而此类方法的泛化性能较差,重建图像质量依赖于初始重建。“信号到图像”的转换方法以探测器采集的原始光声信号或者经过处理的光声信号作为网络输入,往往需要使用全连接或大卷积核的CNN处理信号矩阵的非对称性问题,且当仅使用原始光声信号作为网络输入时,难以映射出复杂目标的逆模型[9,30-31]。
1.5 “图像到图像”与“信号到图像”转换方法的结合
为弥补“图像到图像”和“信号到图像”两种方法的缺点,Lan等[31]提出了一种Y-Net框架,如图6所示,两个输入分别是原始光声信号(包含目标的细节信息)和采用DAS算法重建的含有伪影的低质量图像(包含图像的纹理信息),最终输出高质量图像。该方法可解决严重的有限角度伪影问题,但Y-Net框架受波束成形效应的影响,且没有充分利用稀疏数据的性能,重建图像中依然存在残留伪影。在此基础上,Guo等[9]提出了面向多特征融合的注意力导向网络(Attention steered network,AS-Net),如图7所示,两个输入分别是折叠变换后的光声信号和采用DAS重建的低质量图像。不同于直接使用原始光声信号作为输入,折叠变换可以更好地利用原始稀疏数据,更快地重建高质量图像。相比于Y-Net的直接编码解码,AS-Net利用全局上下块保留更多的空间信息。该方法的验证是在时域中进行的,未来可将其推广到频域。此外,Francis等[32]提出了一个基于GAN的框架,如图8所示,两个输入分别是增强的正弦图和采用TR算法重建的低质量图像,采用仿真图像的实验结果表明该方法可有效去除有限带宽和有限视角伪影,提高重建图像质量。
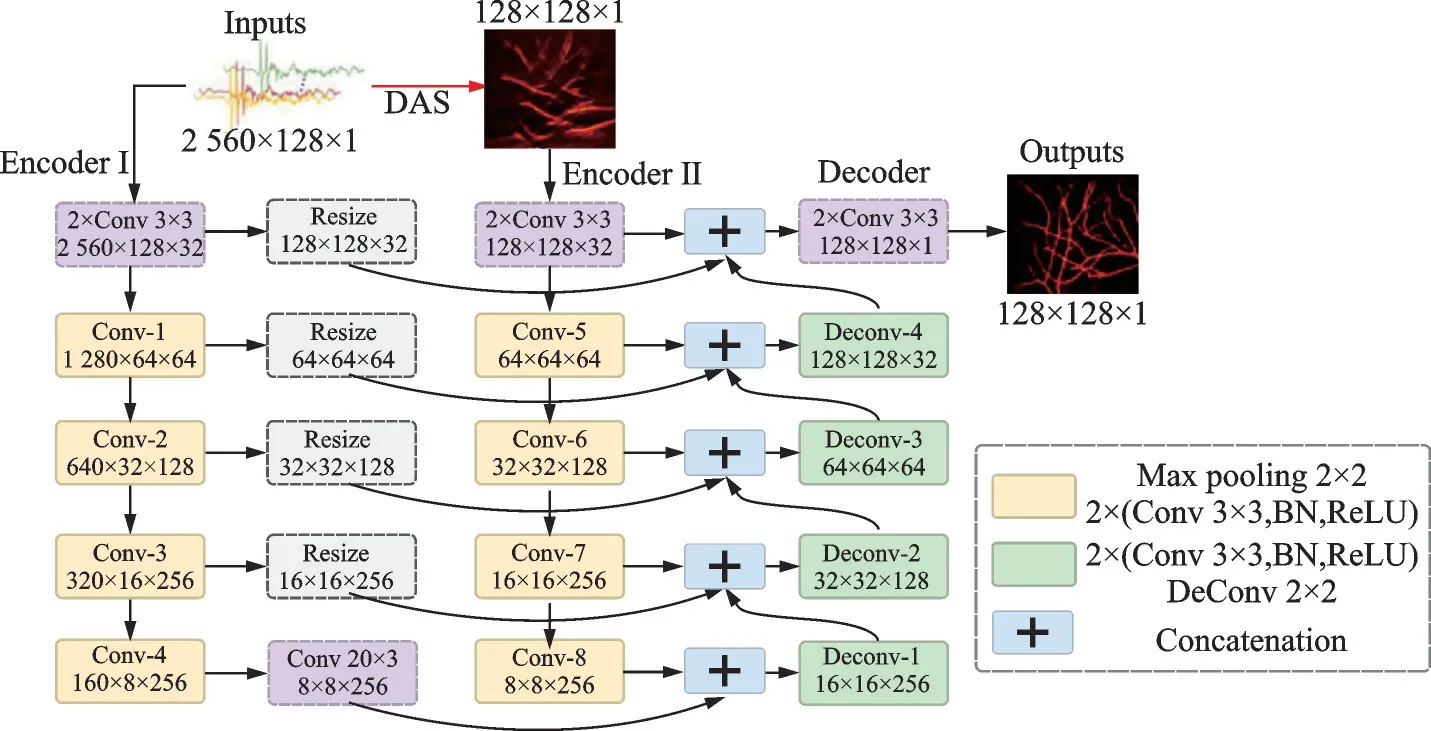
图6 Y-Net体系结构[31]Fig.6 Architecture of Y-Net[31]
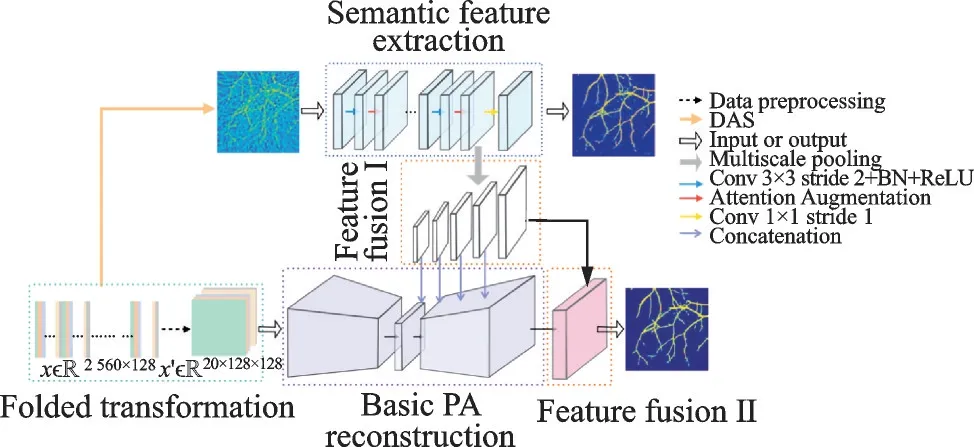
图7 AS-Net体系结构[9]Fig.7 Architecture of AS-Net[9]
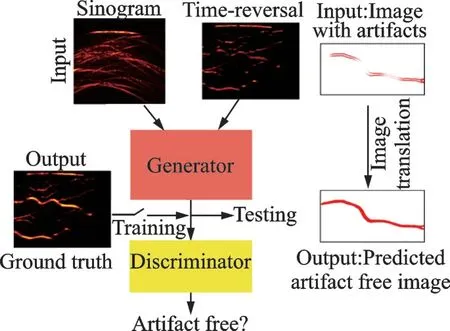
图8 GAN体系结构[32]Fig.8 Architecture of GAN[32]
2 基于学习迭代的光声图像重建
与图像增强方法相比,学习迭代方法不需要进行初始重建,而是直接使用前向算子和伴随算子重建图像。与信号到图像的转换方法相比,学习迭代方法不是学习光声信号到图像的映射,而是在迭代重建框架中引入DL,利用神经网络从训练数据中学习先验约束[27,33]。与传统迭代重建方法相比,学习迭代方法可用更少的迭代次数重建更高质量的图像,但是由于先验约束是由神经网络从训练数据中学习的,因而所需重建时间较长[27]。
学习迭代方法可分为两类:基于梯度下降的方法和深度正则化法。前者通过基于梯度下降的网络训练使每次迭代达到最佳[34-41],后者通过网络训练正则化工具提高重建图像质量[42-46]。
2.1 基于梯度下降的迭代深度学习
Kelly等[34]受近端梯度下降(Proximal gradient decent,PGD)算法的启发,用深度卷积神经网络代替近端算子,利用近似重建算子更新当前迭代结果,再用学习算子训练迭代结果的权重,验证结果如图9所示。该重建框架具有很高的通用性,可在框架中纳入其他近似重建算子,也可应用于图像重建以外的领域。虽然该框架采用的深度卷积神经网络相对较容易训练,但网络会对测量数据产生响应,且由于需要重复模拟物理模型,因而计算时间较长。

图9 根据噪声数据的光声图像重建结果[34]Fig.9 Photoacoustic images reconstruct by different methods from test noisy data[34]
Hauptmann等[36]提出了一种加速模型,利用深度梯度下降(Deep gradient descent,DGD)算法进行迭代更新,将前向成像模型包含到梯度信息中,并且将计算梯度信息的过程与网络训练分开,减少了网络训练对图形处理单元硬件的要求。与传统迭代方法和U-Net重建方法的对比结果表明,该模型可获得比迭代方法更好的鲁棒性(图10),且大幅减少了迭代时间,可用于三维稀疏数据高分辨率PAI中,但训练数据的质量会对最终重建结果产生影响。

图10 对肿瘤仿体的图像重建结果[36]Fig.10 Reconstructed images of a tumor phantom[36]
为了解决声速不均匀问题,Shan等[37]构建了同步重建网络(Simultaneous reconstruction network,SR-Net),通过在每次迭代过程中同时更新初始声压和声速,实现初始声压和声速空间分布的同时重建。该网络可以数据驱动的方式自动学习,确定迭代步长、正则化项以及数据保真度和正则化之间的权衡,且不需要与声速有关的数据保真度梯度。
Adler等[38]在原对偶(Primal dual,PD)算法的基础上提出了学习原对偶(Learned primal dual,L-PD)算法,它可看作是PD的学习变种。Boink等[39-41]利 用L-PD算 法对图像域 中 的原始算子和数据域中的对偶算子进行迭代更新,实现了对光声图像的同时重建和分割,如图11所示。为了提高方法的鲁棒性,需要针对多种图像和成像系统训练网络,非常耗时。未来可将L-PD与GAN相结合,用GAN学习真实图像的低维表示,通过对有限的成像系统设置进行学习,并对学习获得的流形(Manifold)插值,以覆盖所有合理的网络输入和系统设置。
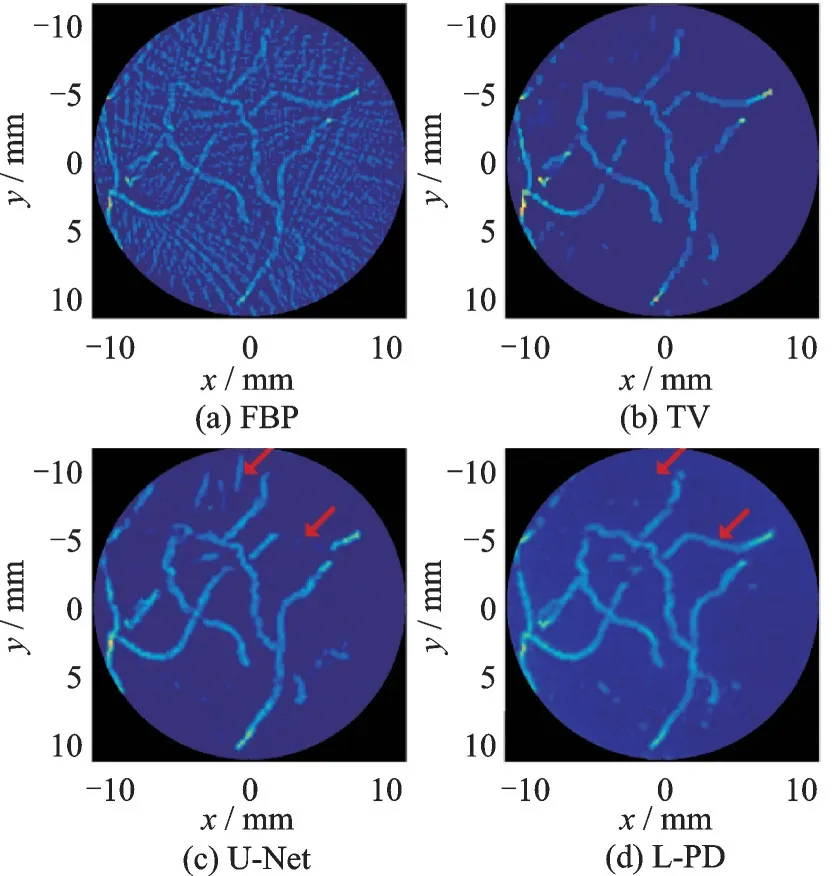
图11 对仿体的光声图像重建结果[40]Fig.11 Reconstructed photoacoustic images of an experimental phantom[40]
2.2 深度正则化
采用有限角度稀疏光声测量数据重建初始声压分布图是严重不适定问题,在经典迭代重建方法中,需合理选择正则化方法,常用的有L1正 则 化、L2正 则 化、TV正 则 化 和Tikhonov正则化等。深度正则化法是将深度神经网络与正则化方法相结合,用神经网络作为正则化项,求解图像重建问题[42-46]。
网络Tikhonov(Network Tikhonov,NETT)将经典Tikhonov正则化与深度神经网络相结合,该网络可以是用户指定的基于正则化泛化框架的函数,也可以是训练后的CNN[44]。利用NETT法进行图像重建的基本步骤是:首先进行初始重建,然后训练网络(即训练正则化项),通过调整参数,使误差函数或平均绝对误差函数最小,使网络达到最佳性能。实验结果表明,NETT能够很好地去除由低采样率导致的图像伪影,同时保留高分辨率的信息,如图12所示。

图12 采用NETT对Shepp-Logan仿体进行光声图像重建的结果[44]Fig.12 Results of photoacoustic image reconstruction for Shepp-Logan type phantom by NETT[44]
不同于NETT,Schwab等[46]提出了基于DL的截断奇异值分解(Truncated singular value decomposition,TSVD)重建框架,使用TSVD作为正则化工具,并结合DL重建图像,其中TSVD在该框架中的作用是近似重建图像的低频分量。采用该框架重建图像包括两步:第一步利用TSVD获得初始重建,将小的奇异值截断,防止噪声被放大;第二步通过随机梯度下降训练一个CNN,将初始重建映射到截断部分,恢复初始重建中缺失的高频部分,最终的重建图像是初始重建和网络输出的残差图像的总和。数值实验结果显示,基于DL的TSVD法重建图像的平均误差只有0.088 7,远低于TSVD的0.156 3,如图13所示。

图13 采用基于DL的TSVD法对Shepp-Logan仿体进行图像重建的结果[46]Fig.13 Image reconstructions of Shepp-Logan type phantom by DL-based TSVD[46]
3 结束语
在光声成像过程中,当探测器只能采集到不完备光声信号时,采用常规方法重建的图像中通常存在有限角度伪影,图像质量下降。近年来,将DL应用于有限角度稀疏测量数据的光声图像重建已成为该领域的研究热点。相较于常规方法,DL技术极大提高了重建图像的质量和效率,但目前仍然面临诸多问题。例如:图像增强方法受初始重建的影响;信号到图像的转换方法需要全连接或大卷积核处理信号矩阵的非对称问题,且当CNN直接输入原始光声信号时,仅在对简单目标的成像中表现出良好性能;基于学习迭代的方法是以牺牲重建时间为代价获得高质量的图像等。未来的研究中,可以考虑从以下几方面提高基于DL的光声图像重建质量。
(1)改变网络输入信号的类型:信号到图像的转换方法可以直接提取光声信号中的有用信息并用于重建高质量图像,而利用数学工具或者物理模型等对原始光声信号测量数据进行预处理,转换网络输入信号的类型,可提高网络的学习效率,进而提高重建图像质量和重建速度。
(2)扩展数据集:CNN需要大量的数据来训练和学习隐含的信息,而且构建训练数据集时需要尽可能多地包含测试集中可能观察到的图像特征,因此未来需要构建规模更大、质量更高的在体图像数据集,并使训练集适应使用真实光传播模型生成的图像。
(3)优化网络结构:复杂的网络结构虽然可以产生更好的重建结果,但往往是以重建速度为代价,对于三维图像重建来说,该过程将更加耗时,不利于实时应用。因此如何优化网络模型并改进训练策略,以更快的速度重建更高质量的图像是未来值得研究的问题。
(4)进行相同实验条件下不同方法之间的对比:目前评估图像重建方法的性能时,多与常规重建方法、同种类型方法及图像增强方法对比,在未来的研究中可进行相同实验条件下不同类型方法之间(如非迭代3种方法之间、非迭代方法与迭代方法之间)的对比,以分析不同方法的重建质量和效率。
猜你喜欢
农业工程学报(2022年13期)2022-10-09
航天返回与遥感(2022年2期)2022-05-12
燃气涡轮试验与研究(2021年6期)2021-08-01
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
南京大学学报(数学半年刊)(2020年1期)2020-03-19
上海师范大学学报·自然科学版(2018年3期)2018-05-14
