
Ghost-YOLO:轻量化口罩人脸检测算法
2022-10-11 08:52:32陈继平陈永平谢懿朱建清曾焕强
信号处理 2022年9期
陈继平 陈永平 谢懿 朱建清,2 曾焕强
(1.华侨大学工学院,福建泉州 362021;2.厦门亿联网络技术股份有限公司,福建厦门 361015)
1 引言
2019 年的新型冠状病毒在全世界范围内迅猛传播给人类健康带来了严峻的挑战。佩戴口罩能够有效地防止新型冠状病毒的传播,因此,口罩已是每位出行者必须佩戴的防护设备。在疫情之前,深度学习在人脸检测任务中已有广泛应用,例如毛秀萍[1]将通用目标检测模型应用至人脸检测任务,以及文献[2]提出的基于深度学习的人脸实时检测方法等。但是,这些人脸检测多数处理完整人脸,并不完全适应疫情情况下口罩人脸检测,因为人脸戴上口罩后丢失了几乎一半的特征信息。因此,口罩人脸检测是一个亟待研究的课题。
得益于深度学习的高速发展,学术界涌现出很多基于深度学习的目标检测模型,例如:你只需看一次(You Only Look Once,YOLO)[3]、单帧多框检测器(Single Shot Multi-Box Detector,SSD)[4]和以区域卷积神经网络(Region Convolutional Neural Network,R-CNN)[5]为基础的Fast R-CNN[6]、Faster R-CNN[7]等目标检测算法。目标检测模型在嵌入式设备中落地部署时,由于嵌入式设备性能低下,使得在嵌入式设备中很难平衡算法的精度与速度。为此,嵌入式设备上的目标检测模型往往采用轻量化网络,如MobileNet[8-9]、SqueezeNet[10]等,通过压缩再扩展结构或使用深度可分离卷积(Depthwise Separable Convolution)[11]来提高模型推理速度或者减小权重大小,但代价是其精度会降低。NanoDet[12]、MobileNet 以及Pelee[13]等模型的参数量大小虽然不到10M 甚至不到1M,但其mAP 表现分别只有23.5%、22.4%,MobileNet 家族的V1、V2、V3 以及V3-small 的mAP 表现均不超过22.2%。而在YOLO家族中的YOLOv4-tiny[14]以及YOLOv3-tiny[15],虽然是从YOLOv4、YOLOv3这些大参数量且高精度的模型进行轻量化改造而来,但其参数量大小分别为6.06M、8.86M,mAP 仅为21.7%、16.6%,均达不到当前轻量化模型的性能。而YOLOv5-s[16]这个参数量只有7.3M 的模型,在COCO[17]数据集中获得36.7%的mAP 性能指标。因此,在这些目标检测模型中,YOLOv5-s模型能够较好地平衡检测速度和检测精度,在目标检测领域中备受青睐。
除了采用轻量化网络,GhostNet[18]指出了通过卷积所得的特征图中存在着大量冗余的特征,为此他们提出了鬼影模块(Ghost Module)来实现高效的特征去冗余。Ghost Module[18]能用更少的参数来获得与普通卷积输出的相同通道数的特征,相比于MobileNet 中使用的大量1×1 卷积,Ghost 模块可以自定义卷积核尺寸大小,而且其先使用的一组用来减少通道数的普通卷积,使得后一层的分组卷积能够减少高通道数带来的高参数量。
为了解决在嵌入式设备上口罩人脸检测算法的检测速度与精度的平衡问题,本文设计了一个少参数量、检测速度和精度都能处在一个较高水平的目标检测网络。关于检测网络模型,本文使用了YOLOv5-s目标检测算法,并在其架构上引入了基于Ghost Module 改进的HAG 模块,设计出Ghost-YOLO轻量化目标检测算法,该模型相比于YOLOv5-s 减少了大量参数。另外为了解决口罩人脸数据集较少的问题,本文整理了口罩人脸的数据集来扩充训练数据集。结合以上模型与数据集,本文设计了基于Ghost-YOLO的口罩人脸检测器。
2 轻量化Ghost-YOLO网络设计
YOLOv5 模型的主体基本由基于跨阶段部分模块(Cross Stage Partial,CSP)[19]结构组成,由于模型中大部分卷积计算和参数都集中于该模块,因此本文首先对CSP 模块进行改进,提出一种轻量化的高激活性鬼影跨段部分(High Active Ghost Cross Stage Partial,HAG-CSP)。紧接着,基于轻量化的HAGCSP 结构,本文进一步构建出一个轻量化Ghost-YOLO 模型。接下来,本文对HAG-CSP 结构和基于HAG-CSP 的轻量化Ghost-YOLO 模型分别进行介绍,并设计基于Ghost-YOLO 模型的口罩人脸检测器。
2.1 轻量化的HAG-CSP结构
本文首先在Ghost Module 的基础上提出一种高激活性鬼影(High Active Ghost,HAG)模块;其次,使用所提出HAG 结构设计出轻量化的HAG-CSP结构。
2.1.1 高激活性的鬼影结构HAG
HAG 结构如图1 所示,其中的CBH 模块包括一个k×k尺寸卷积层、一个Batch Normalized 层和一个Hard-Swish[9,20]激活函数,在卷积层后使用了Batch Normalized 层来对数据进行归一化,以加快训练速度,再使用激活函数来激活有效特征。HAG 的前一部分由一个1×1 大小、输出通道数为输入通道数的一半、分组为1 的CBH 模块组成,后一部分以前一部分CBH 模块输出的结果作为输入,经过一个3×3大小、输入输出通道数相同、但分组数与输入通道数相同的CBH 模块,最后将两部分输出的特征图进行拼接操作,将其作为HAG的最终输出特征图。在HAG结构中对特征图的操作不会改变其高宽。

图1 改进后的Ghost Module模块HAG,图中展示了其工作流程及特征图尺寸维度变化Fig.1 HAG is improved based on Ghost Module,and its workflow and dimension change of feature diagram are shown in the figure
可从HAG的工作流程中发现,其输出的特征图中一半通道数的特征图A 是输入特征图经过第一个CBH 后得出来的,而另一半通道数的特征图B 是特征图A 经过第二个CBH 后得出来的,所以特征图A会影响特征图B生成的内容。
在Ghost Module 模块中,两次卷积操作之后都使用了修正线性单元(Rectified Linear Unit,ReLU)[21]作为激活函数,而在本文初期工作中使用原始的Ghost Module 模块改造的Ghost-YOLO 模型进行训练时,随着训练世代数的升高,拥有大量卷积层的Ghost-YOLO 就越可能出现梯度消失的情况。由于ReLU 激活函数在横坐标负半轴的梯度为0,导致负的梯度在经过ReLU 处理之后被置为0,梯度为负值的部分会被稀疏掉,某个神经元可能不再会有任何数据被激活,使得该神经元“坏死”,导致模型无法学习到有效的特征。
因此,同采用ReLU 激活函数的原始的Ghost Module 相比,本文的HAG 结构采用的Hard-swish 激活函数在x∈(-3,0)时函数值非0,对于ReLU函数负半轴为0 的特性,Hard Swish 有效地防止负梯度信息被稀释,具有更高的激活性。在计算成本方面,相比于Swish[20]激活函数包含的sigmoid 函数,Hard-Swish激活函数使用了ReLU6(x+3)进行线性计算来减少计算量,并且保持了Swish 函数无上界有下界的特点,因此使用Hard-Swish 激活函数不仅能够拥有与Swish 相似的特性,并且能够降低计算开销,对嵌入式设备较低性能的运行条件更友好。
2.1.2 基于HAG的轻量化HAG-CSP结构
图2 为基于HAG 的轻量化HAG-CSP 结构。在HAG-CSP 中我们将多个HAG 模块串联组成Multi-HAG 作为特征提取的主要模块,通过多层的卷积的堆叠来充分提取特征。

图2 基于HAG模块改进的HAG-CSP结构Fig.2 The Improved HAG-CSP structure based on HAG module
特征图进入HAG-CSP 后,首先分成两个分支Branch A 和Branch B 分别进行运算,两个Branch 先均使用1×1 卷积层来进行通道缩减,从而优化了HAG-CSP 模块的时间复杂度和空间复杂度;在Branch A 中将通道缩减后的特征图送入Multi-HAG进行特征提取,然后经过1×1 卷积层进行通道特征整合;之后通过Concatenate 将两个Branch 输出特征图拼接起来,由于拼接之前一个操作是使用了单个卷积层进行卷积,拼接后得到了线性特征,因此之后需通过BN 层和Hard Swish 激活函数转化为非线性特征;最后再经过卷积核尺寸为1×1 的CBH 模块实现特征的融合。相比原YOLOv5中CSP 结构使用的普通卷积来进行特征提取,HAG-CSP 由于使用了HAG模块,使之能够降低大部分参数量。
接下来对HAG-CSP 结构的轻量化特性给予证明。对于单一的普通卷积层和HAG结构,假设输入与输出特征图的尺寸均为Fin=Fout=RH×W×2C,H、W、C表示特征图的高、宽和通道数,HAG 中的分组卷积尺寸为Y=k×k×(C/g),k、g分别为卷积核的尺寸和分组数,为了比较普通卷积与HAG模块中的两个卷积层的参数量,因此设特征图R 经过尺寸为3×3 的普通卷积层处理后的参数量为r1=3×3×2C×2C,而特征图R 经过HAG 模块所得卷积层参数量r2为式(1):

其中加法的前部分为第一层卷积的参数量,其使用了尺寸为1×1 的卷积核,并且输出通道数为C,即为输入通道数的一半,后一部分为分组卷积的参数量,将输入通道分为g组分别进行卷积操作,在本文中,分组卷积核尺寸k取3,g取特征图R 一半通道数,即与第一层卷积输出的通道数相同为C。式(2)中对r1和r2两个公式进行简化:
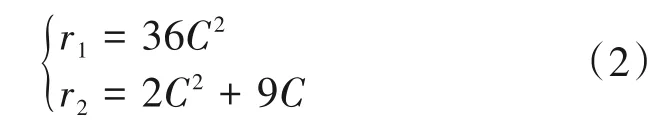
之后再对其求比值,因此普通卷积与HAG模块的参数量比值如式(3):

按照式(3)的比值结果,当通道数越大,比值Z也就越大,因此在输入相同尺寸的特征图时,本文的HAG 所用参数更少,并且随着通道数的升高,将普通卷积模块替换为HAG 模块后获得的减少参数量的收益越大。经过多个HAG 模块的堆叠,致使HAG-CSP 相比于CSP 能够减少大量的参数,因此证明了本文HAG-CSP结构的轻量化的特点。
在HAG中,本文之所以将分组卷积的卷积核尺寸设定为3×3,是因为嵌入式设备的计算性能较弱,同时当前的硬件与软件对于3×3卷积核进行了计算优化,虽然大尺寸卷积核能更好地联系像素与周边之间的信息,但会带来更多的参数,因此堆叠多个小卷积核来达成大卷积核的效果。
2.2 基于HAG-CSP的轻量化YOLO模型
经过以上对Ghost Module、CSP结构的轻量化改进,本文将其引入至YOLOv5-s 模型进行轻量化改造。本文通过对YOLOv5-s 中的CSP 结构改进为成本文的HAG-CSP 结构,进而得到了如图3 的Ghost-YOLO 模型的网络结构。与YOLO 系列算法相同,Ghost-YOLO 中包含了特征提取结构Backbone、特征融合结构Neck 以及预测结构Prediction。以下对其分别进行介绍。
Backbone 为Ghost-YOLO 的第一个结构,输入图片首先经过Focus[16]模块,通过类似于临近采样的方法在图片中每隔一个像素取一个值,总共取4 组值来得到4 组特征图,由于是隔像素取值,因此这4 组特征图基本保持了原图片的特征分布,之后将4 组特征图进行拼接操作,最后经过1×1 卷积层进行特征整合,从而能以不损失特征的方式实现下采样操作。随后使用多个堆叠的HAG-CSP 结构进行特征提取,图3 中堆叠的HAG-CSP 模块之间使用步长为2的卷积层进行下采样操作,Focus结构后的第二和第三次下采样之后各使用了3 个HAG-CSP结构进行串联来加深网络结构。最后经过空间金字塔池化(Spatial Pyramid Pooling,SPP)[22],使得模型能够适应不同尺寸的输入图片。本文将Backbone的输入图片尺寸规定为640×640 由于Backbone结构的总步长为32,因此图片经过该结构的特征提取后,输出了3 个尺寸和通道数分别为20×20×512、40×40×256、80×80×128 的特征图给Neck 进行特征融合。
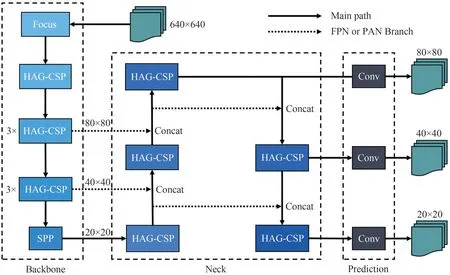
图3 Ghost-YOLO模型结构(图中省略了上采样、下采样操作)Fig.3 Model structure of Ghost-YOLO(up-sampling and down-sampling operations are omitted in this figure)
特征融合是使多个含有不同信息的特征通过拼接、相加等方法进行融合,从而能在一组特征中包含更多的信息,例如阮海涛等人[23]通过特征金字塔网络来得到不同尺度下的信息,而本文在Neck中使用了YOLOv5 中的特征金字塔网络(Feature Pyramid Networks,FPN)[24]结构和路径聚合网络(Path Aggregation Network,PAN)[25]结构,即通过上采样、下采样和Concatenate 等操作,将两个尺寸与通道数不相同且经过不同卷积操作的特征图进行融合,如图3中的虚线分支部分,让两个特征图所提取的特征细节进行融合,从而实现不同尺寸目标的识别。最后将Neck 中输出的三个尺度的特征融合结果输出给目标预测模块Prediction,通过卷积核尺寸为1×1 的卷积层便输出三个尺寸分别为20×20、40×40、80×80 的最终预测结果,尺寸越大则能够检测出越小的目标,因此Ghost-YOLO 能检测不同尺度的目标。
2.3 采用轻量化Ghost-YOLO 模型的口罩人脸检测器
本文基于Ghost-YOLO 设计了口罩人脸检测器,训练所需数据集类别需有为三类:非人脸、未带口罩的人脸以及戴上口罩的人脸,其中非人脸一类仅作为背景,并不对其进行检测,实际检测目标为未戴口罩人脸和戴上口罩的人脸。
该口罩人脸检测器的工作流程为:将特征图分成S×S个区域Grid,由存在目标中心点的Grid 负责检测。首先在每个区域中会生成a个预测框,其中每个预测框会预测(5+2)个值,其中前5个值代表该预测框的中心坐标距当前Grid 左上角起点的距离tx和ty、预测框的高宽缩放系数tw和th以及预测框的置信度c,另外2个值代表未戴口罩人脸以及戴口罩人脸的分类概率。之后,对于同一类且在空间上是同一个目标所生成的多个预测框,对其预测框和目标的真实框计算交并比(Intersection of Union,IoU),从所得交并比中选择交并比最大的预测框,即为最终所得预测框。

预测框位置的4个预测值在进行损失计算时会转换为相对位置,其转换公式如式(4),其中符号σ(x)为sigmoid函数,cx和cy为预测框所在Grid的左上角点坐标,lw和lh为预测框的宽和高。
为了使生成的预测框更贴合实际目标,以及提高对目标分类的准确度,因此在检测器的损失函数方面,Ghost-YOLO 使用了YOLOv5 的损失函数,其由三种损失组成:如式(5)的置信度损失、式(6)的分类损失以及式(7)的预测框位置损失,其总损失函数如式(8)所示:

上面的式子中,c、w、h、x、y为模型得出的预测值,S2代表图片划分成S×S后的Grid,a为某一Grid中的第a个预测框,代表第i,j处若有包含目标中心点,则其值为1,否则为0,而与其相反。对于置信度损失Lobj,理想情况下,当框中有物体时,置信度值ci为1,否则为0,式(5)中λnoobj和λobj分别为无目标和有目标的置信度损失系数。当预测框中的置信度达到阈值后,即认为框中有目标存在,则进行分类损失Lclass计算,式(5)中λclass为分类损失系数,pi(c)为类别预测。与分类损失相同,预测框位置损失Lbox只在包含目标中心点的预测框中进行损失计算,通过计算预测框与真实框的位置差异来施加惩罚。结合以上损失函数以及检测器的工作方法,设计出了基于Ghost-YOLO的口罩人脸检测器。
3 实验与评估
3.1 实验数据及环境
本文收集并整理了人脸与戴口罩人脸的图像数据集,该数据集包含9817 张口罩人脸图片,其中包括了医用口罩、N95 口罩、防毒面具、带颜色花纹口罩等多种类型的口罩,图像分辨率从100×100 至5989×3993,用于训练的有8836 张图片,其中有6661个戴口罩人脸标注框,14884个人脸标注框;另外有889 张图片作为测试集,其中有645 个戴口罩人脸标注框,1734 个人脸标注框,标注效果如图4所示。

图4 人脸与戴口罩人脸数据集的标注示例Fig.4 Annotation examples of face and mask wearing face data sets
另外,本文还使用了AIZOO 数据集(https://github.com/AIZOOTech/FaceMaskDetection)以及FMDD数据集(https://www.kaggle.com/wobotintelligence/face-mask-detection-dataset)来验证本文算法。AIZOO数据集包含了7959张带标注信息的图片,其中6120张用作训练集,1839 张用作测试集。FMDD 数据集拥有20 个类,本文参照文献[27]的方法,从中选取标签为“face_no_mask”和“face_with_mask”两类共3384 张图片作为数据集,其中训练集包含2707 张图片,测试集包含677张图片。
自YOLO9000[26]开始引入的Anchor-base[7]方法帮助其取得了更高的性能表现,因此需要一组提前设定好尺寸的Anchor,本文采用了K-means 聚类方法,对每个真实框未经过值归一化的长宽进行了统计。最后得出9 组Anchor 尺寸,分别为[(9,12),(25,32),(32,38)]、[(50,61),(56,80),(76,78)]、[(93,103),(141,166),(177,234)],小尺寸Anchor被使用在Neck 输出的20×20 尺寸的特征图上进行预测,另外两个尺寸则分别使用在40×40、80×80 的特征图上进行预测。
本文算法的实验评估工作均在NVIDIA Jetson Xavier NX 嵌入式设备上进行,模型训练过程所使用的显卡为一块NVIDIA GeForce GTX TITAN X,操作系统为Ubuntu18.04,深度学习框架为PyTorch1.6,CUDA版本为10.2。
企业要通过工业化建设来提升企业整体效能,进而提升获利空间,首先要树立工业化思想,针对实际情况,不断研究与实施先进的劳动组织与管理,生产资源优化、工艺改造与革新、工序重组、系统信息化建设、员工操作技能培训,而不是单纯地投入先进的生产设备、扩大生产规模或者招收更多的员工。
3.2 实验细节及评价指标
Ghost-YOLO的训练过程中,为了尽可能实现公平对比,以下参数值设定和损失函数系数设置与YOLOv5[16]所提供的设置一致:输入分辨率为640×640,选择Adam 优化器进行参数优化,模型的初始学习率为0.01,权重衰减系数为0.0005,训练世代数Epoch 设定为150,Warmup 的世代数为3,在Warmup 中的学习率动量为0.937,偏差学习倍数设置为0.2。经过Warmup 的3 个Epoch 后,进入余弦退火学习周期,该周期的学习率为模型初始学习率乘以当前Epoch 的余弦退火学习率,余弦退火学习率初始值设定为0.02,随着Epoch 的增加而减少。在损失函数系数的设置中,检测框位置损失系数为0.05,分类损失系数和置信度损失系数都为0.5。对于数据增强参数,对图片的色调、饱和度和亮度的参数分别设定为0.015、0.7、0.4,图片左右翻转概率设定为0.5,Mosaic 数据增强的系数为1。关于参数设置,与YOLOv5 的唯一不同之处在于本文将BatchSize 设置成16,以尽可能合理利用本地显存资源。
在检测实时性方面,使用平均单张图片平均处理时间作为评价指标。在检测准确性评价指标方面,本文选择在目标检测领域中常用mAP50 和mAP 0.5∶0.95 指标[17]。mAP 表示平均精度均值(mean average precision),其计算公式如下:
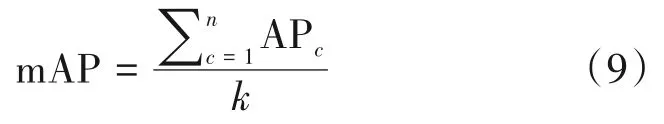
其中,n表示类别数量;APc表示第c类的平均精度(average precision,AP),即为精确率-召回率(Precision-Recall,P-R)曲线的曲线下面积。实践中需要预先设定预测框与真实框交并比(Intersection of Union,IoU)阈值,再将所有预测框的精确率和召回率组合绘制出P-R曲线。mAP50指IoU阈值取50%时的mAP值。进一步的,将阈值从50%开始,以5%为步长逐渐升高至95%,获得不同阈值下的mAP,最后对所有mAP求均值即获得mAP 0.5∶0.95。
3.3 消融实验
为了验证本文的Ghost 轻量化方法的效果,在共同应用YOLOv5-s 骨架网络的前提下,对采用本文设计的Ghost 轻量化方法和不用本文设计的Ghost轻量化方法进行性能对比,结果如表1所示。

表1 采用Ghost轻量化方法改进前后的YOLOv5-s在各数据集上的性能对比Tab.1 The performance comparison of YOLOv5-s on each dataset before and after Ghost lightweight method improvement
在模型大小上,采用Ghost轻量化方法的模型相较于不采用Ghost轻量化方法的模型减少了8.6 M。在本文自建数据集、AIZOO 数据集以及FMDD 数据集上,采用Ghost 轻量化方法的模型在mAP50 上较不采用Ghost 轻量化方法的模型分别提升了1.1%、0.4%、1%,而在mAP 0.5∶0.95 指标上则分别提升了1.9%、2.4%、3.8%。以上数据说明本文的Ghost轻量化方法能够在减小模型大小的同时提高检测精度,证明了本文方法的优越性。
3.4 Ghost-YOLO在数据集上性能分析与对比
为了证明本文算法的性能,在表2 中给出在本文数据集上本文算法与其他轻量化目标检测算法在模型大小、mAP50 和mAP 0.5∶0.95 指标上的表现。另外在表3中给出了在AIZOO 数据集和FMDD数据集上本文算法与其他目标检测算法的精度对比。
由表2 可见,在检测的准确性能方面,本文的Ghost-YOLO 在口罩人脸数据集中达到了84.9%的mAP50 和51.9%的mAP 0.5∶0.95,相比本文算法基础的YOLOv5-s 分别提升了1.1%和1.9%;相对于YOLOv4-tiny 则有3% 的提升。对比NanoDet-320,本文算法在mAP50 上有21%的领先,在mAP 0.5∶0.95 上领先幅度达到15%。在模型大小方面,表2 中模型权重均以32 位精度保存,本文算法模型的大小均小于YOLOv5-s 和YOLOv4-tiny,虽然NanoDet-320 在模型大小上有非常大的优势,但是其检测性能远低于Ghost-YOLO。因此,本文的Ghost-YOLO 算法在模型大小和准确性表现方面都优于表内的其他轻量型目标检测算法。

表2 本文算法与其他检测算法在本文数据集上的性能比较Tab.2 The performance comparison between our algorithm and other detection algorithms on our dataset

表3 本文算法与其他检测算法在AIZOO数据集和FMDD数据集下的性能比较Tab.3 The performance comparison between our algorithm and other detection algorithms in AIZOO dataset and FMDD dataset
在模型推理速度方面,图5给出采用不同Batch Size 时不同算法在NVIDIA Jetson Xavier NX 嵌入式设备上的推理速度比较。本文算法在Batch size 为8 时,其推理速度达到最高为24.72 ms,相较于该实验最快的YOLOv5-s的24.42 ms仅多出了0.3 ms的推理时间,而相对于YOLOv4-tiny和NanoDet分别减少了23.62 ms 和3.8 ms。因此,结合表2 的检测精度比较结果和图5 的检测速度比较结果,证明本文算法具备了优秀的推理速度和更好的识别性能表现。
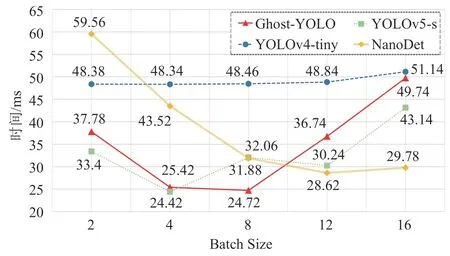
图5 采用不同Batch Size时,不同模型的推理速度比较Fig.5 The comparison of inference speed of different models via different batch sizes
3.5 特征图可视化
为了分析神经元坏死的情况,以及证明本文基于Ghost Module 改进的HAG 的有效性,本文以ResNet18[31]为基础,分别使用本文的HAG 和Ghost Module 来替换ResNet18中的卷积模块,从而构建出两种模型。在同一数据集下经过相同训练之后,分别对其第二个经改造后的卷积模块输出的特征图进行观察,其可视化结果分别如图6(a)和图6(b)所示,使用原Ghost Module 改造的ResNet18 模型输出的特征图中,有几个通道的特征图为空,而使用了本文HAG 改造的ResNet18 模型输出的特征图中未出现特征图为空的问题。

图6 第二层卷积层特征图可视化,(a)为使用原Ghost Module时的结果,(b)为采用HAG时的结果Fig.6 Visualization of feature map.The left figure(a)shows the result when using the original Ghost Module,and the right figure(b)shows the result when using HAG
对其原因进行分析,本文认为对于一些离散的数据,由于原始Ghost Module中ReLU激活函数的特性,致使部分神经元“坏死”导致的图6(a)中部分特征图消失,影响了后续的特征提取操作。而图6(b)中,由于HAG 中的Hard-Swish 激活函数能够把一些负值信息进行激活,使得不丢失负值信息,因此相比左图能够保留更多信息。
3.6 TensorRT加速与参数量化对比
TensorRT[32]为NVIDIA 开发的一个专用于NVIDIA 系列计算核心的高性能深度学习推理SDK。它包括一个深度学习推理运行优化器,为深度学习推理应用程序提供低延迟和高吞吐量。由于本文实验评估所用的NVIDIA Jetson Xavier NX 设备支持该SDK。在深度学习发展前期,例如文献[33]等基于非深度学习模型的人脸检测算法能够实现实时人脸检测,但卷积等深度学习基本模块的运算量远大于之前的方法。因此为了进一步提高模型在嵌入式设备的推理速度以及减少模型的占用空间,在该实验中对比了本文算法使用TensorRT 进行模型加速前后以及参数量化的效果,同时也对YOLOv5-s进行了对比,相关结果置于表4。
由表4 可见,Ghost-YOLO 经过TensorRT 加速过后,其单图平均处理时间从24.72 ms 减少至18.41 ms,其每秒传输帧数(Frames per second,FPS)约为54.318,并且模型通过FP16 量化后,其权重大小从21M 缩减为13M;而经过TensorRT 加速和参数量化后的YOLOv5-s,其处理时间也仅为21.22 ms,FPS 约为47.125,权重大小从29.6M 减小至17.5M。可见,经过加速后的Ghost-YOLO 与YOLOv5-s 在检测上都有提升,并且经过参数量化后,模型占用空间也得到进一步减小,减少了算法在嵌入式设备上的对性能存储空间的需求。
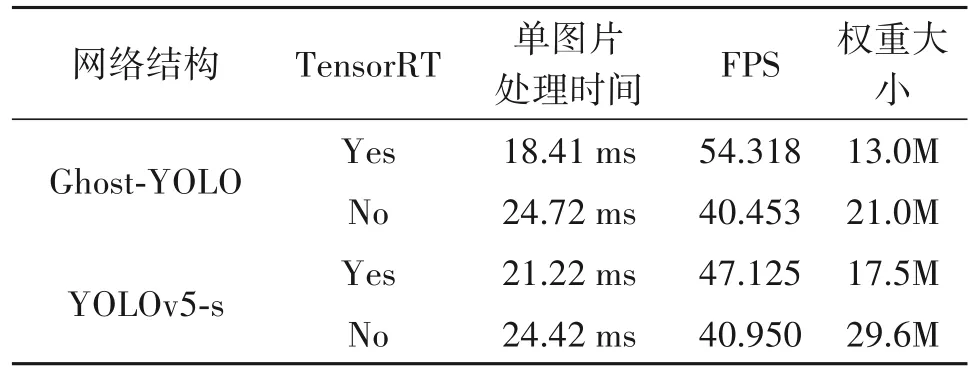
表4 Ghost-YOLO与YOLOv5-s经过TensorRT加速后的性能表现及权重大小对比Tab.4 The comparison between Ghost-YOLO and YOLOv5-s when using the TensorRT acceleration
4 结论
本文提出了一种面向嵌入式设备的Ghost-YOLO 口罩人脸检测算法。先通过所设计的高激活性鬼影(High Active Ghost,HAG)模块来减少特征图中的冗余,再利用HAG实现的高激活性鬼影跨段部分(High Active Ghost Cross Stage Partial,HAG-CSP)模块对YOLOv5-s 模型进行轻量化改造,从而构造出口罩人脸检测器。最后的实验结果显示,本文提出方法在NVIDIA Jetson NX 嵌入式设备上,对尺寸为640×640 的单图片处理时间为24.72 ms,相比于其他轻量型目标检测模型有更快推理速度且有更高精度的优势。本文不足之处在于HAG 模块对前一组特征利用线性转换得到的后一组特征,若前一组特征存在冗余信息,则后一组特征难免相应存在冗余。后续的改进思路可以考虑在HAG 模块线性转换得到的特征之间设计约束项,降低特征之间相关性,减少特征冗余。
猜你喜欢
精密成形工程(2022年2期)2022-02-22 05:44:14
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
意林(2020年9期)2020-06-01 07:26:22
海峡姐妹(2020年4期)2020-05-30 13:00:08
作文大王·笑话大王(2019年3期)2019-04-22 23:58:02
智富时代(2019年2期)2019-04-18 07:44:42
动漫星空(2018年9期)2018-10-26 01:17:14
作文评点报·低幼版(2017年8期)2017-03-11 20:44:08
专用汽车(2016年1期)2016-03-01 04:13:19
专用汽车(2015年4期)2015-03-01 04:09:07
