
基于注意力机制的端到端合成语音检测
2022-10-11 08:52:38王锦阳华光黄双
信号处理 2022年9期
王锦阳 华光 黄双
(1.武汉大学电子信息学院,湖北武汉 430072;2.武汉第二船舶设计研究所,湖北武汉 430064)
1 引言
语音伪造技术主要包括语音合成(Text to Speech,TTS)、语音转换(Voice Conversion,VC)、语音模仿(Impersonation)、重放攻击(Replay Attack,RA)和对抗攻击(Adversarial Attack)[1-2]。语音合成技术,即文本转语音,是一种能够将任意输入文本转换为目标说话人合成语音的技术。传统的语音合成主要有波形拼接和参数合成两条技术路线,近年来,深度学习技术的迅速发展给语音合成开辟了新的方向,许多研究团队提出了基于神经网络的端到端语音合成系统,例如Tacotron 2[3]、Deep Voice 3[4]、Transformer TTS[5]和FastSpeech 2[6]等。随着深度伪造技术的迅猛发展,合成语音的自然度越来越高,而且具有与真实语音相似的声学特征,生成语音的速度也在不断提升。语音合成技术可以提高语音交互的用户体验,在语音导航、阅读听书等应用中得以广泛使用,还可以用于教育、医疗、泛娱乐等领域,然而合成语音也带来了严重的安全隐患,一旦被不法分子利用,将会给全球的政治、经济、民生和社会造成威胁,这对合成语音检测的研究提出了挑战[7]。语音转换技术则是将源说话人的语音转换成目标说话人的语音。本文主要研究语音合成和语音转换的检测问题。
合成语音检测技术的本质是寻找合成语音和真实语音之间的特征差异来判断真伪,这种特征与语音表达的内容无关。合成语音检测系统一般由前端特征提取器和后端二值分类器组成。传统检测系统前端的区分性特征通常采用精心设计的手工特征,包括声纹特征、频谱特征等。Xiao等人[8]研究了高维幅频特征的表现,使用对数幅度谱(Log Magnitude Spectrum,LMS)与残差对数幅度谱(Residual Log Magnitude Spectrum,RLMS)构建的检测系统得到了理想的效果。相位特征,例如群延迟(Group Delay,GD)、修正的群延迟(Modified Group Delay,MGD)、相对相移(Relative Phase Shift,RPS)、基带相位差(Baseband Phase Difference,BPD)等也适用于合成语音检测任务[9-11]。倒谱系数特征是检测合成语音的有效特征之一,包括线性频率倒谱系数(Linear Frequency Cepstral Coefficients,LFCC)、梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)、线性预测倒谱系数(Linear Prediction Cepstral Coefficients,LPCC)等[12-14]。由于合成语音不能很好地模拟时间特征,频谱特征的一阶、二阶动态差分也有助于合成语音的检测。Massimiliano 等人[15]设计的基于常数Q 变换的倒谱特征(Constant-Q Cepstral Coefficients,CQCC)常被用作竞赛中的基线特征。与全带变换相比,子带变换能更有效地捕获合成语音中的伪影,Yang等人[16]提出了基于子带变换的特征,并通过特征组合显著提升了合成语音检测的效果。近年来基于深度神经网络(Deep Neural Network,DNN)的特征提取算法逐渐被应用于语音特征提取任务中[17],Nanxin 等人[18]使用深度神经网络瓶颈(DNN-BN)特征构建了一种语句级的s-vector 特征。常用的后端分类器有基于高斯混合模型(Gaussian Mixture Model,GMM)的分类器、支持向量机(Support Vector Machine,SVM)分类器以及基于深度神经网络模型的分类器。Alzantot 等人[19]构建了基于深度残差网络(Deep Residual Network,ResNet)[20]的合成语音检测模型,使用MFCC、CQCC、频谱图三种前端特征并进行分数融合。Wu 等人[21]提出了引入最大特征图激活函数的轻量卷积神经网络(Light Convolutional Neural Network,LCNN),该网络提炼度高、空间占用小,在后续提出的模型中被广泛应用[22-24]。Luo 等人[25]提出了基于胶囊网络(Capsule Network,CapsNet)的检测系统,对动态路由算法进行改进,使模型更关注伪造语音中的伪影,提升网络的泛化能力。
研究表明,网络结构、损失函数和训练方法的设计可以提高合成语音检测模型的性能,但是模型的潜力根本上取决于初始特征中捕获的信息。手工特征的制作会丢失部分信息,很大程度上影响了对于未知攻击的检测,因此,我们需要更高效、更通用的表征来提升模型的鲁棒性。手工特征对基于DNN 的合成语音检测并不是必须的,已有许多文献提出了端到端合成语音检测方案[26]。Tak等人[27]将改进的RawNet2 网络应用到合成语音检测领域,使用一组Sinc 滤波器通过时域卷积直接对原始波形进行操作,然后通过残差模块和GRU 学习深层次的区分性信息并聚合话语级表征。Tak等人[28]又提出了RawGAT-ST模型,使用频谱—时间图形注意力网络(Spectro-Temporal Graph Attention Network)来对跨越不同子带和时间段的关系进行建模。Hua 等人[29]基于ResNet 的跳层连接和Inception[30]的并行卷积结构设计了两种轻量级端到端时域合成语音检测网络(Time-domain Synthetic Speech Detection Net,TSSDNet),其中Inc-TSSDNet更加轻量级,在没有使用Mixup[31]训练技巧的情况下泛化性更好。
CNN 中常用的注意力机制有通道注意力(Channel Attention)和空间注意力(Spatial Attention)等。近年来,基于通道注意力、空间注意力以及将二者结合的轻量级嵌入型模块在计算机视觉(Computer Vision,CV)领域中的应用越来越受到关注,将SE 模块(Squeeze-and-Excitation Module)[32]、CBAM(Convolutional Block Attention Module)[33]等嵌入到ResNet、Inception、ResNext[34]等原始网络中能够显著提升网络在图像分类、图像分割、目标检测等任务上的表现。考虑到模型复杂度和泛化性,我们选择Inc-TSSDNet 作为基线模型,由于模型在ASVspoof2019 测试集上的表现不够理想,为了降低等错误率(Equal Error Rate,EER),本文提出一种基于通道和空间注意力机制的端到端合成语音检测模型,将现有先进轻量级模块中的注意力机制改进为适用于语音序列的通道注意力和一维空间注意力(One-dimensional Spatial Attention),然后将模块分别嵌入到Inc-TSSDNet 中,使网络能够重点关注某些对于检测真伪更关键的通道或区域。改进网络在参数量增加较少的前提下,测试集等错误率和最小串联检测代价函数(Minimum Tandem Detection Cost Function,min t-DCF)[35]有明显的降低。下文将详细介绍本文提出的基于注意力机制的端到端合成语音检测系统。
2 基于注意力机制的Inc-TSSDNet
2.1 注意力机制
注意力机制和人类对外界事物的观察机制类似,即在众多信息中人们会倾向于把注意力集中在某些重要的局部信息上,选择对当前事物更关键的信息,来形成对事物的整体印象。近年来,注意力机制广泛应用于自然语言处理(Natural Language Processing,NLP)和CV等领域。注意力机制可分为软注意力和强注意力,其中软注意力更加关注通道或区域,是可微的。在神经网络模型中,注意力机制的表现形式通常是一个额外的神经网络,能够帮助模型硬性选择输入的某些部分,或给输入的不同部分赋予不同的权重。注意力机制的基本思想是利用特征图来学习权重分布,再将学习得到的权重施加到原始特征图上进行加权求和。
2.1.1 通道注意力和一维空间注意力
对于二维图像,CNN 的每一层会输出一个尺寸为C×H×W的特征图,其中C表示通道数,也是卷积核的数量,W和H表示原始图片经过压缩后的宽度和高度。而对于一维语音序列,输出特征图的尺寸为C×L,L表示原始序列经过压缩后时间维度的长度。
按照注意力权重施加的方式和维度不同,软注意力的关注域主要有通道域、空间域和混合域。通道注意力机制是在通道维度上,通过自动学习的方式获取每个特征通道的重要程度来组成一个权重矩阵,权重数值越大,对应的通道越重要,该通道与关键信息的相关度越高,而空间维度上的权重相同,这样可以让神经网络重点关注某些特征通道。空间注意力机制作用于空间维度,在二维平面上,对每个像素点学习到一个权重,对H×W的特征图得到一个权重矩阵,而对于一维序列,在每个时间点学习到一个权重,对长度为L的特征图得到一个权重矩阵,在C个通道维度上权重相同。本文提出的模型使用了通道注意力和一维空间注意力。
2.1.2 适用于一维序列的注意力模块
现有的轻量级注意力模块大多是针对二维图像相关任务设计的,本文对SENet[32]、CBAM[33]、scSE[36]、ECA-Net[37]和SA-Net[38]五篇文献中提出的注意力模块进行调整,使他们适用于一维语音序列,能够应用在端到端合成语音检测任务中。
SE模块引入了通道注意力机制,显式地建模特征通道间的相互依赖关系,其结构如图1 所示。首先是Squeeze 操作,对输入的C×L特征图U=[u1,u2,…,uC]进行空间的全局平均池化(Global Average Pooling),将每个通道长度为L的一维特征压缩成一个实数,得到尺寸为C×1的全局特征z,其中z的第c个元素可以表示为:

图1 SE模块结构Fig.1 The structure of SE module

然后是Excitation 操作,通过两个全连接层组成瓶颈(Bottleneck)结构来建模通道间的相关性生成权重s:
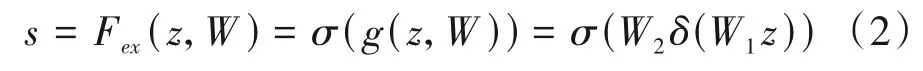
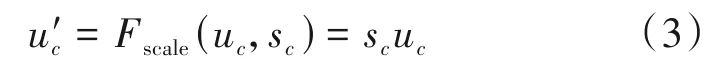
CBAM 结合通道注意力和一维空间注意力机制,沿通道和空间两个维度依次计算注意力权重并对原始特征图进行加权,其结构如图2 所示。在通道注意力模块中,首先对输入的C×L特征图U分别进行空间维度的全局最大池化(Global max pooling)和平均池化得到两个C×1 的特征描述,然后分别送入一个共享的两层神经网络,两层神经元个数分别为C/r和C,实现方法与SE 模块类似,再对两个输出向量进行对应元素相加(Element-wise Summation)后经过Sigmoid 激活函数得到通道注意力权重Mc,最后用Mc和U对应元素相乘(Element-wise Multiplication)得到通道加权后的特征图U':

图2 CBAM结构Fig.2 The structure of CBAM
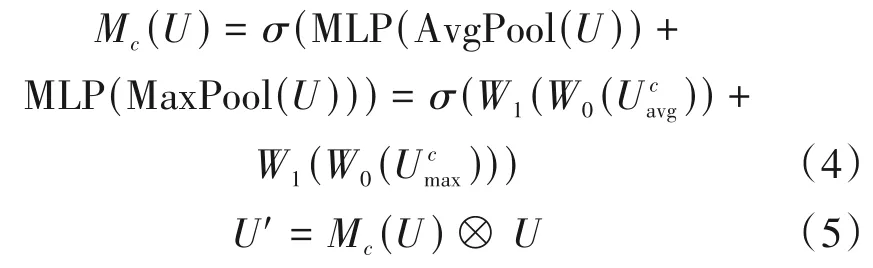
在一维空间注意力模块中,将通道注意力模块输出的特征图作为输入,在通道维度上使用最大池化和平均池化得到两个1×L的特征描述,再对两个特征进行基于通道的连接(concat)得到2×L的特征,然后经过一个一维卷积降维成1 个通道,再经过Sigmoid 激活函数得到空间注意力权重Ms,最后用Ms和U'对应元素相乘得到加权特征图U'':

其中σ为Sigmoid 激活函数,f7表示卷积核大小为7的1D卷积,⊗表示对应元素相乘。
scSE(Spatial-Channel Sequeeze &Excitation)模块是基于SE 模块改进的一种变体,将通道注意力cSE 模块和一维空间注意力sSE 模块并行结合,其结构如图3 所示。cSE 模块与SE 模块结构相同,核心操作是全局池化和两个全连接层,最终得到通道加权的特征图,由公式(1)、(2)、(3)可推导出如下公式:
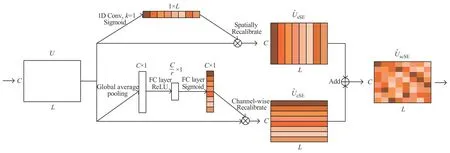
图3 scSE模块结构Fig.3 The structure of scSE module
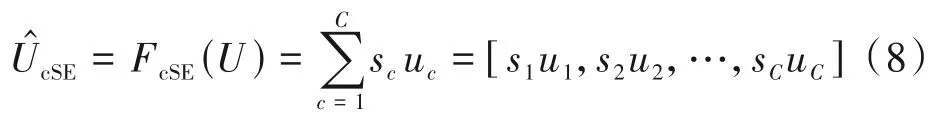
其中sc为归一化权重,U=[u1,u2,…,uC]表示输入特征图,uc∈R1×L。
在sSE模块中,对于输入特征图U=[u1,u2,…,uL],ui∈RC×1,先通过一个卷积核大小为1 的一维卷积降维得到1×L的特征图q,再经过Sigmoid 激活函数归一化到0 至1 之间并与原始特征图对应相乘得到空间加权的特征图,公式如下:

其中σ(qi)表示特征图中一维序列位置坐标i的重要性。将上述两个结果相加得到scSE 模块的最终结果:

ECA(Efficient Channel Attention)模块是一种极轻量级的通道注意力模块,它通过一维卷积实现不降维的跨通道信息交互,在兼顾复杂度的情况下提升模型性能,其结构如图4所示。文献[37]的作者认为SE模块中的降维操作对捕获所有通道之间的依赖关系是低效且不必要的,而适当的跨通道交互有助于学习高效率和高性能的通道注意力。对输入特征图U进行空间维度的全局平均池化后通过一个卷积核大小为k的一维卷积,其中k还表示局部跨通道交互的覆盖率,根据k与通道维数C成正比提出一种自适应确定k的方法:

图4 ECA模块结构Fig.4 The structure of ECA module

其中γ=2,b=1,|x|odd为选择最近的奇数。最后经过Sigmoid 激活函数得到通道注意力权重,再与原始特征图对应相乘得到加权特征图U'。
SA(Shuffle Attention)模块采用特征分组和通道置换将通道注意力和一维空间注意力有效地结合起来,是一种超轻量的注意力模块,其结构如图5所示。对于输入的特征图U∈RC×L,首先沿通道维度划分成G组,即U=[U1,…,UG],Uk∈,每组特征再沿通道分成两个分支,即Uk1,Uk2∈,分别计算通道注意力和一维空间注意力。在通道注意力中,先进行空间的全局平均池化,得到×1 的全局特征z,然后通过Sigmoid 激活的简单门控机制,与Uk1对应相乘得到输出:

图5 SA模块结构Fig.5 The structure of SA module

在一维空间注意力中,先对Uk2进行组归一化(Group Norm,GN)[39]得到空间域的统计信息,然后采用Fc(·)进行增强,与Uk2对应相乘输出:

其中参数W1,W2,b1,b2∈。将两个分支的结果连接起来得到。最后将所有子特征聚合起来,通过与ShuffleNet v2[40]类似的通道混洗(Channel Shuffle)操作实现沿通道维度的跨组信息交互,得到最终的加权特征图U'。
2.2 基于Inc-TSSDNet的改进网络
Inc-TSSDNet 网络由第一层1×7 卷积层、堆叠的M个类似Inception 结构的模块、全局池化层和三个全连接层组成,每个类似Inception 的模块之后都使用了最大池化层,每个卷积层之后都跟随有批标准化(Batch Normalization,BN)层和ReLU 激活函数,除了最后一层外每个全连接层后都使用了ReLU 激活函数。为了增大感受野并控制模型的复杂度,文献[29]在原始Inception的基础上进行改进,类似Inception 的模块中使用扩张卷积(Dilated Convolution),所有卷积层使用1×3的内核、填充与扩张率相同且步长为1,池化层的步长等于对应内核大小。为了兼顾检测表现和模型复杂度,本文选取M=4、4分支的Inc-TSSDNet 作为基线模型,在每个类似Inception 的模块之后分别引入上文所述的五种注意力模块,将模块分别嵌入最大池化层前后进行实验,改进网络的结构如图6所示。
图6 中网络参数M=4,CI={8,16,32,32},CA={32,64,128,128},CL={64,32},图6(a)中LA={24000,6000,1500,375},图6(b)中LA={6000,1500,375,1}。
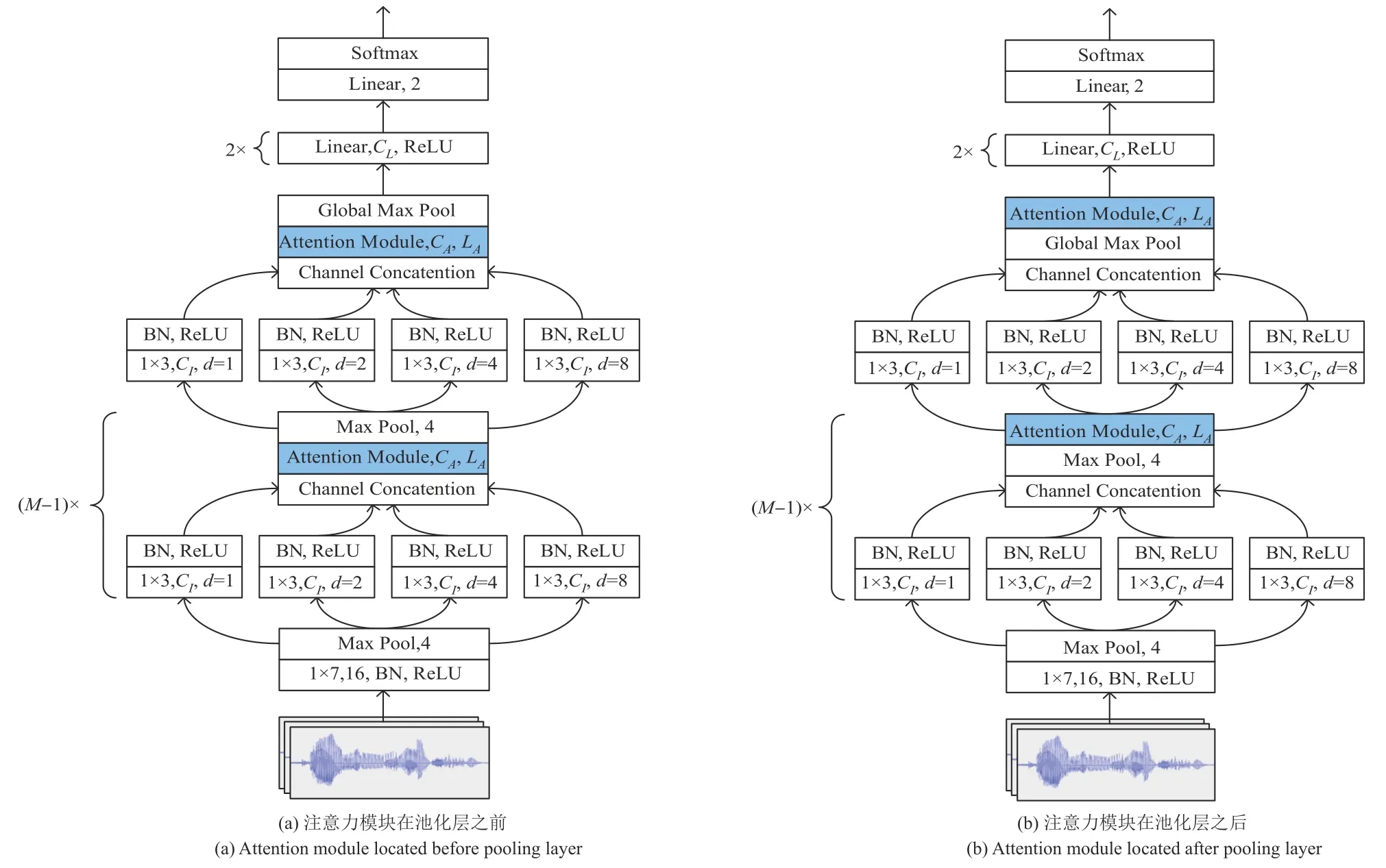
图6 基于注意力机制的Inc-TSSDNet结构Fig.6 The structure of Inc-TSSDNet based on attention mechanism
3 网络训练及实验结果
3.1 数据集及预处理
本文使用了ASVspoof2019数据集和ASVspoof 2015 数据集。ASVspoof2019数据集包含LA和PA两个子集,我们使用LA子集来研究语音合成和语音转换攻击,LA的训练集有20个说话人(8名男性、12名女性),包括2580 段真实语音和22800 段伪造语音,验证集有20 个说话人(8 名男性、12 名女性),包括2548 段真实语音和22296 段伪造语音,测试集有67 个说话人(30 名男性、37 名女性),包括7355 段真实语音和63882 段伪造语音。ASVspoof2015 数据集的验证集有35 个说话人(15 名男性、20 名女性),包括3497 段真实语音和49875 段伪造语音,测试集有46 个说话人(20 名男性、26 名女性),包括9404 段真实语音和184000 段伪造语音。同一数据集的训练集、验证集、测试集中说话人互不重叠。
进行数据预处理,从数据集提供的语音片段中截取6 秒,不足6 秒的片段先复制再截取,音频采样率为16 kHz。将截取的6秒语音片段直接输入网络进行端到端训练,即输入特征图的长度L=9.6×104。
3.2 网络训练
实验中端到端合成语音检测系统基于Pytorch进行训练和测试。由于真实语音片段的数量远小于伪造语音片段,本文在训练阶段采用加权交叉熵(Weighted Cross-entropy,WCE)损失来处理样本不平衡的问题:
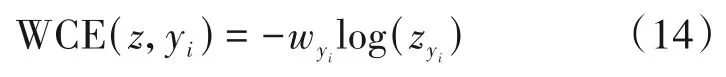
其中yi表示标签,∀i,yi∈{0,1},z=[z0,z1]是经过Softmax后两个类别的概率,权重与训练集中标签yi的数量成反比。在训练过程中,批量大小(batch size)设置为32,使用Adam优化器和默认设置,按指数衰减调整学习率,系数设置为0.95,选择100个阶段内模型在验证集上产生最低EER的阶段进行测试。
本文采用等错误率(EER)和串联检测代价函数(Tandem Detection Cost Function,t-DCF)来评估基于注意力机制的端到端合成语音检测系统性能优劣。伪造语音检测是一种二分类任务,错误接受率(False Accept Rate,FAR)是伪造语音中被错误分类为真实语音的比例,而错误拒绝率(False Rejection Rate,FRR)是真实语音中被错误分类为伪造语音的比例,给定系统检测得分和阈值θ,错误接受率Pfa(θ)和错误拒绝率Pfr(θ)的计算公式如下:

阈值为θ时EER 对应FAR 和FRR 相等时的值,即EER=Pfa(θ)=Pfr(θ),EER 越小,合成语音检测系统的效果越好。
t-DCF 是一种综合评估指标,通过最小风险贝叶斯决策来评估ASV 系统的可靠性,能够反映在现实场景中合成语音和检测系统对ASV 系统性能共同产生的影响,其计算过程可简化为:
其中系数β由误判成本、伪造攻击优先级和ASV 系统检测性能决定。t-DCF 越小,合成语音检测系统的泛化性越好。
3.3 实验结果及分析
本文基于上述参数设置和数据集,针对五种注意力模块、两种注意力模块嵌入位置得到的十种网络结构进行实验,对比分析基于注意力机制的端到端合成语音检测系统的网络复杂程度、EER、min t-DCF、统计性能和跨库性能。
不同模型在ASVspoof2019数据集的验证集和测试集下的EER和min t-DCF如表1所示。表中的降维系数(ratio)是SE 模块、CBAM 和scSE 模块中的超参数,组数(group)是SA 模块中的超参数,均通过多次实验确定最佳取值。由于所提模型的实验结果具有波动性,表中的结果为在最佳降维系数或组数的情况下重复训练30次得到的最低测试集EER。两种注意力模块嵌入位置的模型参数量相等,而将注意力模块嵌入池化层之前的计算量会高于嵌入池化层之后。表中数据显示,在增加参数量较少的前提下,嵌入注意力模块的Inc-TSSDNet在ASVspoof2019测试集下的EER 和min t-DCF 都比基线模型有一定程度的降低,这表明引入通道注意力机制和一维空间注意力机制能使检测系统更加关注某些对于检测真伪关键的信息来提升系统表现,增强系统的泛化能力,其中在池化层之前嵌入CBAM 的模型在测试集下EER最低,嵌入ECA模块的模型测试集min t-DCF最低。

表1 不同模型在验证集和测试集下的EER(%)和min t-DCFTab.1 EER(%)and min t-DCF of different models in development set and evaluation set
对于五种注意力模块,SE模块和ECA模块只引入了通道注意力机制,其余三种模块结合了通道注意力和一维空间注意力。文献[32]列出的实验结果表明在原始网络中嵌入SE 模块可以提升模型在图像分类(ImageNet 2012、CIFAR-10、CIFAR-100 数据集、ILSVRC 2017)、场景分类(Places365-Challenge数据集)、目标检测(Microsoft COCO 数据集)任务中的表现,文献[33]的实验结果显示嵌入CBAM 能够提升模型在图像分类(ImageNet-1K数据集)、目标检测(Microsoft COCO、PASCAL VOC 2007 数据集)任务中的表现,文献[36]的实验仅证明了嵌入scSE 模块对于图像分割任务(医学数据集MALC 和Visceral)是有效的,文献[37]和[38]表明嵌入ECA模块和SA 模块可以提升模型在图像分类(ImageNet-1K数据集)、目标检测(Microsoft COCO 数据集)、实例分割(Microsoft COCO 数据集)任务中的表现。SE模块、CBAM、ECA 模块和SA 模块在一些分类、分割、目标检测任务和数据集上具有普适性,适用于合成语音检测任务的可能性更大,文献中的实验大多是将这四种注意力模块嵌入ResNet 网络,而本文的基线模型是由类似Inception的并行卷积结构堆叠而成的。此外,图像分类等任务需要关注图片的内容,虽然合成语音检测也是一种分类任务,但我们并不关注语音中讲述的内容,只关注能区分真假的特征,这与上述其他任务不同。综上所述,注意力模块在其他任务中的表现与本文实验结果无直接关联,我们可以根据实验结果推测得出:使用两个全连接层和自适应一维卷积来捕获通道间相关性的设计对于合成语音检测都是有效的,同时使用最大池化层和平均池化层能够使检测系统获得更丰富的信息,而将通道注意力模块和一维空间注意力模块并行连接和特征分组的设计对合成语音检测任务的作用不大。
不同模型在ASVspoof2019 测试集每种攻击(A07-A19)下的EER 如表2 所示。可以明显看到攻击A08 和A17 严重影响了合成语音检测系统的性能,而引入通道注意力机制和一维空间注意力机制能够使系统更好的应对A08,将SE 模块、CBAM、scSE 模块嵌入池化层前的三个模型在A08 下的EER 显著降低,但引入注意力机制并没有提升系统检测A17 的表现。A08 是一种语音合成攻击,使用了基于神经源滤波器(Neural Source-filter,NSF)的非自回归波形生成模型[41],这与训练集中合成语音使用WORLD、WaveNet等声码器的波形生成机制有一定差异,可能对合成语音检测造成了干扰,引入注意力机制能使网络更关注神经网络声码器时域波形建模方法的特性来改善系统性能。A17是一种语音转换攻击,使用直接波形修正(Direct Waveform Modification)的方法[42]来生成波形。A17 的欺骗性极强,许多现有先进合成语音检测系统在A17攻击下的表现最差,文献[27]的作者根据A17 的伪造特征能够被RawNet2检测系统中的固定Sinc滤波器捕获,推断认为这种特征与相位相关,而本文提出的网络结构不包含线性相位滤波器,引入注意力机制也不能提升系统检测A17的能力。
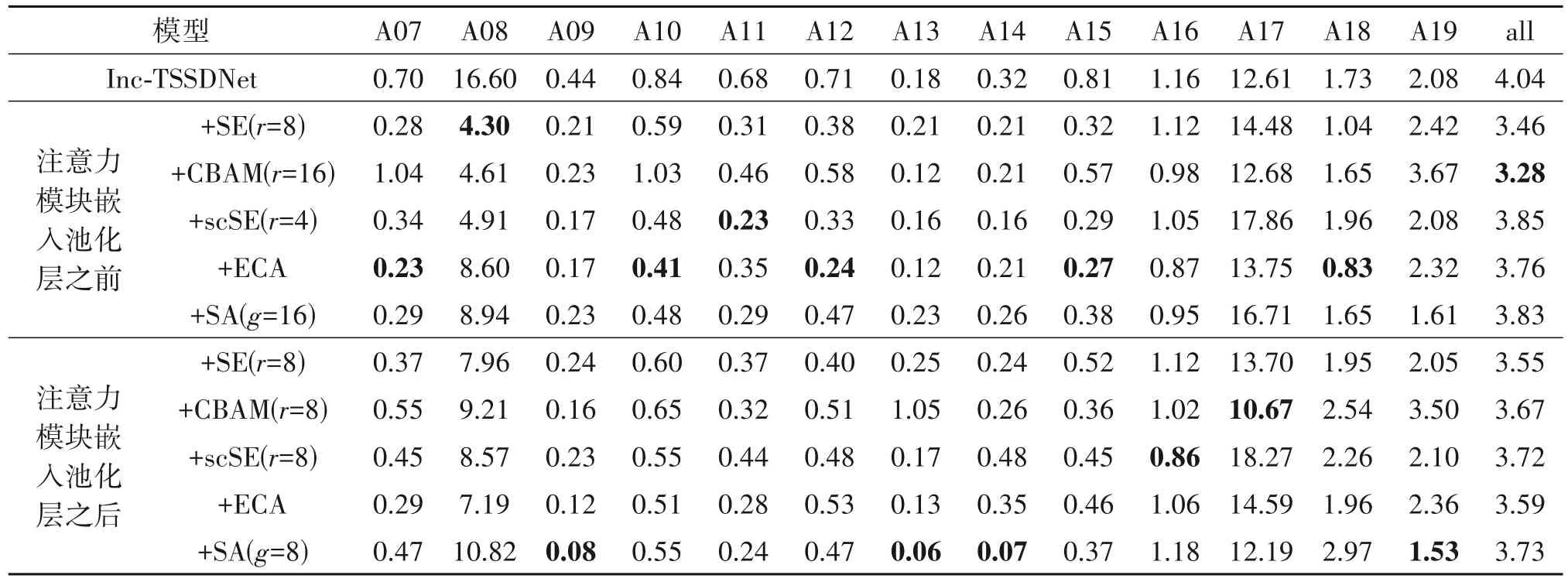
表2 不同模型在测试集每种攻击(A07-A19)下的EER(%)Tab.2 EER(%)of different models for each attack in the evaluation set(A07-A19)
下面将本文所提系统与领域最前沿方法进行对比,各种方法在ASVspoof2019测试集下的EER和min t-DCF 如表3 所示。比较表明,在权衡测试集下表现和模型复杂度的情况下,本文提出的基于注意力机制的Inc-TSSDNet 具有一定优势,所提系统在测试集下的表现优于Spec+CQCC+ResNet+SE[43]、LFCC+LCNN-4CBAM[44]等使用类似注意力机制的方法和端到端检测系统RawNet2[27]。虽然所提系统的测试集EER 和min t-DCF 略高于CQT+Res2Net+SE方法[45],但其网络复杂度和计算复杂度远小于后者,其参数量是后者的十分之一左右,且所提系统是端到端的,不需要计算手工特征,更加方便快捷。

表3 所提系统和最前沿方法在测试集下的EER(%)和min t-DCFTab.3 EER(%)and min t-DCF of the proposed and state-of-the-art methods in the evaluation set
下面分析系统的统计性能,固定所有超参数后,使用ASVspoof2019 训练集分别对十个模型进行30次从头开始的训练,在验证集和测试集下的EER如图7所示,其中基线模型Inc-TSSDNet的数据来源于文献[29]。由图可见,将ECA 模块嵌入池化层前的模型在统计性能方面表现最好,训练30次的结果波动范围最小,测试集EER 都落在3.76%到5.03%之间且有3次低于3.8%的结果,比基线模型的统计性能有较大提升。其余模型虽然最好一次或几次结果的测试集EER 比基线模型最好结果有所降低,但测试集EER的波动范围也会变大。

图7 不同模型的统计性能图Fig.7 Statistical performance diagram of different models
为了检测系统的泛化能力,本文使用在ASVspoof2019 数据集上训练得到的网络模型在ASVspoof2015 数据集的验证集和测试集上进行测试,结果如表4 所示。从结果上看,除了将scSE 模块和ECA 模块嵌入池化层之后的两个模型,其余模型的跨数据集EER 都有所降低,在池化层之前嵌入CBAM 的Inc-TSSDNet 模型最好结果在ASVspoof2015的验证集和测试集下的EER 最低,表明在Inc-TSSDNet的合适位置引入通道注意力机制和一维空间注意力机制可以增强网络的泛化性。

表4 不同模型的跨库EER(%)Tab.4 Cross-dataset EER(%)of different models
4 结论
本文在端到端合成语音检测系统Inc-TSSDNet网络的基础上,引入通道注意力机制和一维空间注意力机制,使网络重点关注某些对于检测真伪更关键的通道或区域。实验结果显示,在Inc-TSSDNet的合适位置嵌入注意力模块可以提升检测系统的性能,在池化层之前嵌入CBAM 的Inc-TSSDNet 模型最好结果在ASVspoof2019测试集下的EER为3.28%,较基线模型降低了18.8%,且模型参数量增加较少,该模型还具有优秀的跨库性能,其最好结果在ASVspoof2015的验证集和测试集下的EER 较基线模型分别降低了67.3%和36.8%,在池化层之前嵌入ECA模块的Inc-TSSDNet 模型最好结果在ASVspoof2019 测试集下的min t-DCF 为0.0861,较基线模型降低了11.8%。本文仅调整并使用了五种注意力模块中的算法,后续工作将进行消融研究,分别关注通道注意力机制、一维空间注意力机制、特定网络层等在系统性能中起到的作用,设计更适合合成语音检测任务的注意力模块以进一步提升检测系统性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
