
基于关联规则的语境情感搭配词组挖掘算法
2022-10-10 05:59苏靖枫娄鑫坡赵军民
河南城建学院学报 2022年4期
苏靖枫,娄鑫坡,赵军民
(河南城建学院 计算机与数据科学学院,河南 平顶山 467036)
语言学界往往将词语的情感倾向称为词语的感情色彩,即词语所附带表示褒义或贬义态度的色彩[1-2]。根据词语的感情色彩是否具有稳定性将情感词分为2类:一类是情感词不随语言环境而改变,具有比较稳定的情感色彩,例如漂亮、善良、丑陋;另一类情感词会随着环境的不同改变其情感色彩,例如,词语“骄傲”在“我为祖国的四大发明感到骄傲”中表现出了褒义的情感倾向,在“他考了99分就骄傲了”表现出了贬义的情感倾向。再如词语“高”在“服务质量高、水平高”中呈现了正面的情感倾向,而在“耗油高、价格高”中呈现了负面的情感倾向,称此类词语为语境情感词语。
近年来,自然语言处理逐渐成为人工智能的研究热点[3-4],情感分析又是自然语言处理中的研究重点和难点[5-7],而情感词语情感倾向性的识别对情感分析极其重要。近几年,有关文本情感分析方面出现了很多研究成果[8-9],主要是采用规则与统计相结合的方法对文本进行识别,语言的复杂性导致其准确度提升的难度较大。不少研究机构将其研究成果构建了情感倾向性词典,例如HowNet情感分析词语集[10-11]、同济大学褒贬义情感词典[12]、大连理工大学的DUTIR文本倾向性分析知识库[13]等。尽管这些词典给研究者提供了极大的便利,但是这些情感词典对于每个词语仅仅给出褒义或贬义的情感标记,而语境情感词语的情感色彩往往是由上下文来决定的,只简单地给出单个词语的情感倾向是无法直接使用的。并且,由于缺乏统一的构建标准,同一个词语在不同的情感词典中可能会标记不同的感情色彩,如“风流”在HowNet中既有褒义又有贬义,而在台湾大学的NTUSD中却只是贬义。这就会给情感词典的使用带来混乱。因此,将通用情感词语和语境情感词语进行区分,构建准确度更高的情感词典十分必要。
本文将情感词语的识别分为两个方面:通用情感词语的识别和语境情感搭配词组的识别。对于语境情感词语,研究发现当它们与某些词语搭配后往往能够呈现出比较稳定的情感倾向。
本文提出了一种基于关联规则的语境情感搭配词组的挖掘算法,本算法主要用于语境情感搭配词组的识别。首先利用关联规则中的支持度、置信度和可用度,从语料文本中识别出与语境情感词具有搭配关系的常用词语组合;然后,综合利用搭配词组所在句子以及相邻句子信息对其倾向性进行分析,进而构建领域相关的情感词语搭配集合。
1 基于关联规则的语境情感搭配词组挖掘算法
1.1 相关概念
定义1:设T={w1,w2,…,wk…,wm}。其中wk表示项集T的数据项,m表示数据项的个数。
定义2:P{wi→wj}表示词wi出现时wj出现的概率。其中wi,wj⊆T,且wi∩wj=Φ,wi≠Φ,wj≠Φ。
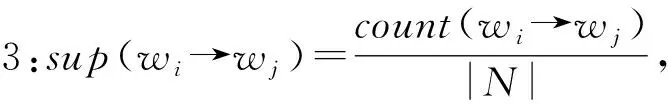
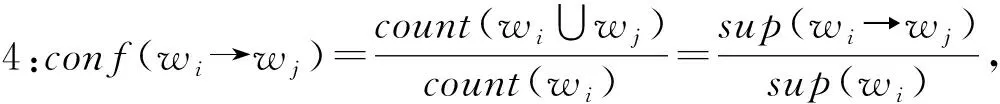
定义5:如果sup(wi→wj)≥min_sup且conf(wi→wj)≥min_conf,则认为wi、wj满足强关联规则。
其中:min_sup为最小支持度阈值,min_conf为最小置信度阈值。
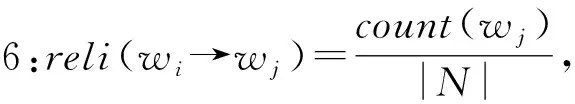
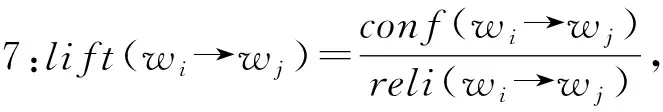
1.2 语境情感搭配词识别
从1.1节定义可知,支持度是关联规则挖掘[14]重要度的评价标准,其中支持度越大,表示词在数据项集合中出现的频率越高,则该词在数据项集合中越具有代表性。置信度是衡量关联规则准确度的评价准则,其置信度越大表示其准确度也越大。对于关联规则挖掘,只有支持度和置信度都大时挖掘出的规则才有价值。如果有规则支持度低但置信度高,说明该规则出现的概率较小,在数据集中不具有代表性。在文本集合上采用规则挖掘算法,其期望可信度表示后面一个词在没有前面词作用下的自身支持度。
作用度则表示前面一个词对后面一个词的影响力,其作用度越大表示前面一个词对后面一个词的影响力就越大。在本文中,认为作用度大于1的规则才是有价值意义的规则,说明前面一个词对后面一个词有促进作用。
在一些具体的话题领域,语境情感词往往会有一些常用的语用习惯,例如在电子产品评论中,情感词“大”往往出现在含“屏幕、噪声、声音、存储”等词语的句子的概率较高,则可以认为这些词语之间存在着关联关系。因此,本文提出了一种基于关联规则的语境情感搭配词组挖掘算法,能够从产品评价语料中挖掘语境情感词语的常用搭配词组合。首先将语料中含语境情感词的语句提取出来,然后计算其支持度、置信度和作用度,进而得到语境情感词的常用搭配。
基于关联规则的语境情感搭配词组识别算法如下:
输入:文档集合T,歧义情感词表AW
输出:常用搭配词表FW
1 for每一个文本t∈Tdo
2 for 每一个词wk∈tido
3 ifwk∈AWdo
4ti→事务集合TN
5 end if
6 end for
7 end for
8 for 每一个文本ti∈TNdo
9 计算sup、conf、lift
10 iflift≥1 andsup≥min_supandconf≥min_conf
11 (wi,wj)→FW
12 do if
13 do for
1.3 语境情感搭配词组的倾向性分析
语境情感词本身并不具备情感倾向性,但当其与某些词搭配之后往往表现出较强的情感倾向[15-16],本文称之为“语境情感词+搭配词”组合。当前,“语境情感词+搭配词”组合并没有情感词典可供其查询。因此,要求算法不仅能够识别出该组合,同时也要能够判断出该搭配词组合的情感倾向性。由于“语境情感词+搭配词”组合受语境影响较深,往往随语境的不同表现出差异较大的情感倾向性,即在某些语境中该组合表现为正向的情感倾向性,当语境改变时,同样的搭配词组合表现为负向情感倾向性。因此,“语境情感词+搭配词”组合需要充分考虑其语境的上下文信息。本文提出的基于“语境情感词+搭配词”算法充分考虑该词组所在句子以及前后句信息来综合判断其情感倾向。
通常情况下,人们用语言对事情进行描述时呈现一致性和连续性。例如,当人们对某种事物进行描述时,往往是先进行赞扬,再指出其缺点;或者相反,先进行批评再对其某一部分或者特征进行肯定,一般情况下不会表扬和批评交替进行。因此,如果句子中出现转折连词,则转折连词前后其情感倾向性相反。如果未出现转折连词,但句子中出现多个情感词,与其前后句中出现的多个情感词的情感倾向性相同的概率较大。如果该句表现为正向的情感倾向性,则其中情感词的情感倾向性为正向的概率较大。相反,如果该句表现为负向情感倾向性,则句子中情感词为负向的情感倾向性概率较大。因此,本文提出了一种基于句内和前后相邻句的语境情感词搭配组合情感识别算法。该算法充分利用语境情感词词组的相邻情感词来确定其情感倾向性。
规则1:句中出现转折连词,则转折连词前后情感倾向相反,否则,句中未出现转折连词则情感倾向性相同。例如:“苹果新推出的iPhone11 plus屏幕大但电池不耐用”,其中搭配词“电池-不耐用”是负向的情感搭配词组,可以推出“电池-耐用”是正向的情感倾向。因为句中出现转折词“但”,则“屏幕-大”是一个正向的情感倾向。“那款车油耗低而且车内布局宽敞”,其中搭配词组“油耗-低”是一个正向的词组,因为宽敞是一个正向情感词,而且在此起递进作用。在没有转折句的句中“MS surface很好,满足了学习的所有需求,功能很强大,外观漂亮”,可以根据通用情感词“漂亮”判断“功能-强大”是一个正向的情感搭配词组。
规则2:如果无法通过本句识别其中的情感句,则可以通过前后相邻句子的情感倾向性来识别该句子。如果前后相邻句子之间出现转折连词,则前后两个句子情感倾向相反,否则前后句子情感倾向性相同。例如“这房间隔音差、房间小、性价比较低、卫生也不好”,该句中不含通用性情感词,但可以通过其句子前后句判断其倾向性,句中“卫生-不好”是负向的情感倾向性,则可以判断“隔音-差”、“房间-小”、“性价比-低”也是负向的情感倾向。
一般情况下,“语境情感词+搭配词”的情感倾向性在句子中较稳定,一旦识别出来,则可以将其加入情感词典中去。但是少数词组会随语境的变化表现出不同的情感倾向性。例如,“华为MATE40的屏幕太大了”,该句中“屏幕-大”是一个负向的情感词搭配词组。而在“华为P40屏幕大,能耗低”中“屏幕-大”是一个正向的搭配词组。此时需要考虑在大多数情况下,该搭配词的情感倾向,一般认为用户评论“屏幕-大”是好事,可以认定是一个正向的情感倾向词。另外,该算法还可以根据同义词、反义词和搭配词组中是否有否定词等扩展搭配词词组,例如,出现“能耗-大”是一个负向的情感搭配词词组,则“能耗-小”就是正向的搭配词词组。
综上,则基于语境情感词的倾向性识别算法如下:
输入:句子集合S,搭配词集合FW,情感词典PW,连接词词表DC
输出:搭配词集合FW中搭配词的情感倾向性
1 for 每一个句子si∈Sdo
2 ifPW∈sido
3 ifDC∈sido
4FWj←~PW//搭配词与PW倾向性相反
5 end if
6 else do
7FWj←PW//搭配词与PW倾向性相同
8 end else
9 end if
10 else ifwi-1&PW∈si-1do // 如果前一个句子si-1存在,且si-1包含情感词语PW
11 ifDC∈si-1do
12FWj←~PW//搭配词与PW倾向性相反
13 end if
14 else do
15FWj←PW//搭配词与PW倾向性相同
16 end else
17 end else if
18 else ifsi+1&PW∈si+1do
19 ifDC∈si+1do
20FWj←~PW//搭配词与PW倾向性相反
21 end if
22 else do
23FWj←PW//搭配词与PW倾向性相同
24 end else
25 end else if
26 else do
27FWj←0//FWj无情感倾向性
28 end else
29 end for
2 实验结果分析
2.1 语境情感搭配词组识别
(1)将候选情感词表中的非通用情感词都作为语境情感词语,词语数目共计4 769个。语境情感词语有:屏幕、靓、均匀、手感、颜控、口味、捂持感、颤抖、信赖、方便、皮实、扛用、运行、速度、流畅、快、轻盈、性价比、满足、简约、大气、高级、便宜、低廉、夸张……
(2)利用关联规则挖掘技术从语料集合中识别语境情感词语的常用搭配组合。利用关联规则首先要确定文本语料的事务集。由于在评论文本中,人们经常使用简短的句子进行评价,而不倾向于用长句来表达观点,因此与语境情感词语具有搭配关系的词语大部分都在歧义情感词附近,一般前后距离不会超过6个词语。另外,一些独立性差、无实义的虚词或停用词也很难成为有效的搭配词,为此实验只选择以歧义情感词为中心前后M个名词、动词或形容词的语句片段组成事务集。
(3)利用本文1.2节提出的基于关联规则的语境情感搭配词组识别算法从语料库中挖掘出相应的“语境情感词+搭配词”组合,在评论文本和微博文本中,文本较短,直接表述观点,一般词性为名词、形容词和动词等更容易做搭配词,并且位于语境情感词相搭配的搭配词前后M个词的位置。
本实验在Linux操作系统环境下,采用Java语言编写,实验的数据集主要采用NLPCC2012和COAE2014关于微博文本情感分析的评测数据。实验参数设计,α表示关联规则的最小支持度阈值,β表示关联规则的最小置信度阈值。考虑到中文词的低频性和歧义性,本实验认为词与词之间共同出现超过10次则认为这2个词之间具有关联性。因此α=10/N,其中N表示文本的总数。为了确定实验最优化的参数,则设计窗口大小W的取值为3、4、5、6共4组,参数β的值设置了0.001、0.005、0.01、0.015、0.02、0.03共6组。最后,实验选择电子产品、酒店和旅游3个领域的文本作为实验数据集,选择“高”、“大”、“差”等词作为基础词来确定W和β的值,M表示搭配词的数目。其中本实验的正确率P、召回率R和F值公式分别对应公式(1)、(2)和(3)。
(1)
(2)
(3)
不同参数设置下获取的搭配词组数目见表1,实验结果见表2~表4。

表1 不同参数设置下获取的搭配词组数目

表2 不同参数设置下的正确率

表3 不同参数设置下的召回率

表4 不同参数设置下的F值
由表1可知:最小置信度阈值越小,窗口越大获取的搭配情感词越多。由表2和表3可以看出:随着窗口W的逐渐增大,搭配词组识别的正确率有所下降,但召回率有所提升。这是由于随着窗口的逐渐增大,能过的词被算法捕获到,不仅捕获了更多情感搭配词,同时也捕获到了噪声词。
由表4可以发现,当窗口大小为4,最小置信度阈值β为0.001时,F值最高,达到0.63。因此将W的值设置为4,将语境情感词语前后各4个词语组成的语句片段提取出来作为事务,最小置信度β取值0.001。
2.2 搭配词组倾向性分析结果
搭配词组倾向性分析主要利用搭配词的上下文关系来进行判断,实验分别从数码产品、娱乐媒体和金融证券3个领域中共识别褒义情感词组2 372组和贬义情感词组466组,具体情况见表5。

表5 搭配词组的识别结果
3 结论
提出了一种基于关联规则的语境情感搭配词组的挖掘方法,首先利用关联规则中的支持度、置信度和可用度,从语料文本中识别出与语境情感词具有搭配关系的常用词语组合。然后,综合利用搭配词组所在句子以及相邻句子信息对其倾向性进行分析,进而构建与该领域相关的情感词语搭配集合。实验结果表明,本文提出的基于关联规则的语境情感搭配词组挖掘算法能够挖掘出大量情感搭配词语。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
体育科技文献通报(2022年3期)2022-05-23
小型微型计算机系统(2022年4期)2022-05-09
有色金属(矿山部分)(2021年4期)2021-08-30
天津医科大学学报(2021年2期)2021-03-29
魅力中国(2018年11期)2018-08-06
计算机应用(2018年5期)2018-07-25
中国科技纵横(2016年20期)2016-12-28
高中生学习·高三版(2014年3期)2014-04-29
