
CNN融合PCA-DT模型的金属缺陷识别研究
2022-10-10 07:39唐东林周立吴续龙宋一言秦北轩
机械科学与技术 2022年9期
唐东林,周立,吴续龙,宋一言,秦北轩
(西南石油大学 机电工程学院,成都 610065)
我国工业快速发展,对产品的质量要求也越来越高,而金属缺陷对石油石化行业的输油管道和石油储罐等有很大影响,因此,金属缺陷检测近年来受到越来越多的关注[1]。依靠人工方式对缺陷检测信号进行判断不仅工作量大,且分类效果受主观因素影响。因此通过模式识别对缺陷检测信号进行识别分类具有重要意义[2]。模式识别方法就是用计算的方法根据已知样本的特征将未知样本进行识别分类,模式识别已广泛应用于缺陷识别领域。
目前模式识别方法主要分为机器学习方法和深度学习方法。机器学习中有支持向量机SVM(Support vector machine)、人工神经网络ANN(Artificial neural network)、无监督学习K-means聚类等,这些方法有着一些局限。例如,文献[3]采用小波平滑方法去除图像中的噪声,然后根据二值化图像的光谱测度提取出5个特征并输入SVM,其需要专门领域知识来设计缺陷特征并提取,繁琐费力且受人为因素影响[4-6];文献[7]利用logistic回归(LM)模型和ANN研究声发射检测识别金属缺陷和文献[8]利用人工神经网络预测管道破裂压力,这两种方式存在过拟合、迭代慢、所需训练样本大等问题;文献[9-10]利用无监督模式识别分析结合主成分分析(PCA)对缺陷进行实时检测和分类,但无监督模式识别K-means需要提前设定K值和选定初始聚类中心,而K值和初始聚类中心很难确定。
近些年随着深度学习的发展,卷积神经网络(Convolution neural network,CNN)在缺陷识别领域中成功应用,文献[11]提出了一种基于视觉长-短期记忆的集成CNN模型用于织物疵点分类,精度有所提高,但网络结构较复杂,迭代速度慢;文献[12-14]利用R-CNN及其变体对缺陷、焊点等进行分类定位,然而存在卷积操作低效,需要较大样本量和训练时间较长的问题。最近,深度学习结合机器学习被广泛关注,利用CNN模型在提取特征上的巨大优势,将其代替机器学习的人工提取特征,用机器学习对CNN提取的特征进行识别分类,能有效弥补CNN模型分类参数多、结构复杂、反向传播效率低的问题。文献[15]将灰度共生矩阵和Gabor提取的强特征与CNN隐藏层的抽象特征进行融合,并将融合后的特征输入SVM进行分类。文献[16]利用统计特征作为卷积神经网络的训练数据集,CNNSVM算法获得了准确的肌肉疲劳分类。文献[17-19]人工提取特征输入到CNN中然后用机器学习取代cnn的softmax层,其对于分类准确率有一定提升。由于CNN模型多用于图像数据,因此以上研究只针对图像缺陷数据,对于非图像缺陷数据并未涉及。
在此基础上,提出一种适用于中小规模数据的浅层卷积神经网络提取特征,决策树(Decision tree,DT)分类的算法模型,并引入主成分分析(Principal component analysis,PCA)降维。在中小规模数据中,本文模型相对于传统机器学习和深度学习,能更快速更准确地实现金属缺陷识别分类,且在非图像缺陷数据上也表现优异。
1 本文方法
1.1 CNN-PCA-DT模型
本文模型如图1所示,具体分类步骤如下:
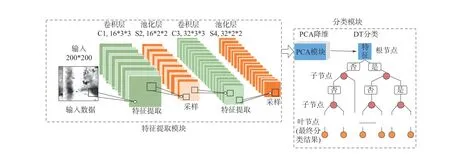
图1 CNN-PCA-DT结构图
1)将200*200的图像数据输入由卷积神经网络组成的特征提取模块提取特征;
2)为了减少冗余特征、过拟合和节约计算开销,将特征提取模块中提取的高维特征通过分类模块中的PCA进行降维处理,降维后将特征输入DT;
3)分类模块中分类模型采用C4.5算法建立DT模型,通过训练集训练DT模型,训练完成后,将测试集送入模型,通过特征提取模块提取特征,并用PCA降维,最后将特征送入训练好后的DT模型中得到结果。
1.2 特征提取模块
由于深度学习结构复杂、训练参数多,针对中小规模数据容易过拟合,因此特征提取模块主要由浅层的卷积神经网络组成,其由1个数据输入层、2个卷积层、2个池化层组成。其中数据输入层对输入的数据进行归一化和去均值等预处理,将预处理后的数据输入卷积层,卷积层由多个卷积核组成,卷积核一般有1×1、3×3和5×5等大小组成。C1层采用16个3×3大小的卷积核,步长为1,边缘填充1个单位来进行窗口滑动对数据做卷积运算进行特征提取,将得到的特征输入池化层S2。
池化层有2×2、3×3等滤波器,主要用于数据压缩,进行特征降维消除冗余信息,减少过拟合。S2层采用最大池化,池化块为2×2,采样步长为2,将数据压缩4倍,并输入卷积层C3。
C3层由32个3×3的卷积核构成,采用同C1层同样的操作进行特征提取,提取后输入池化层S4层,S4层采用同S2层同样的操作进行数据压缩,压缩后将其输入分类模块中。
1.3 分类模块
分类模块主要由DT和PCA组成。DT是一种树形结构的归纳学习分类器,在给定的无序训练数据中,创建出分类模型。同CNN的黑盒模型不同,DT是一个白盒模型,可解释性好且不需要对数据进行特别预处理,能在较短时间内对数据进行识别分类。
决策树算法有ID3,ID4,C4.5,C5.0,CART等,本文选择C4.5算法,该算法采用信息增益率作为不纯度指标,信息增益率使用的是信息论中的熵来度量,熵对于集合D定义为
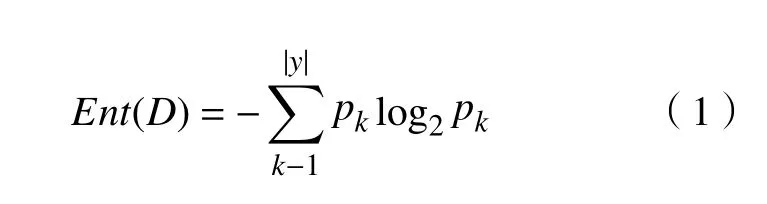
式中:|y|为样本种类;k为每一类;pk为每类对应的概率。
为引出信息增益率首先介绍信息增益(也称不纯度减少量),信息增益用特征将个样本进行划分,信息增益Gain(D,α)定义为
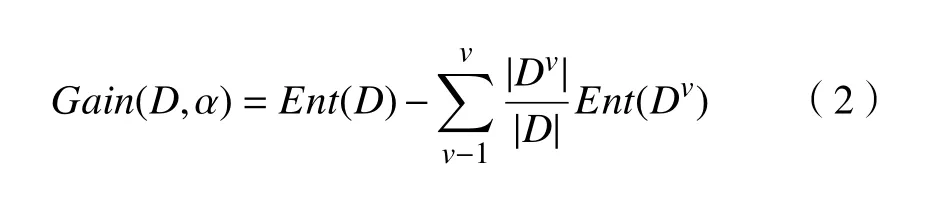
式中:α为样本集D中的离散特征;v为α的个数;Dv为第v个分支所包含的样本。
在信息增益的基础上,信息增益率Gain_ratio(D,α)定义为:
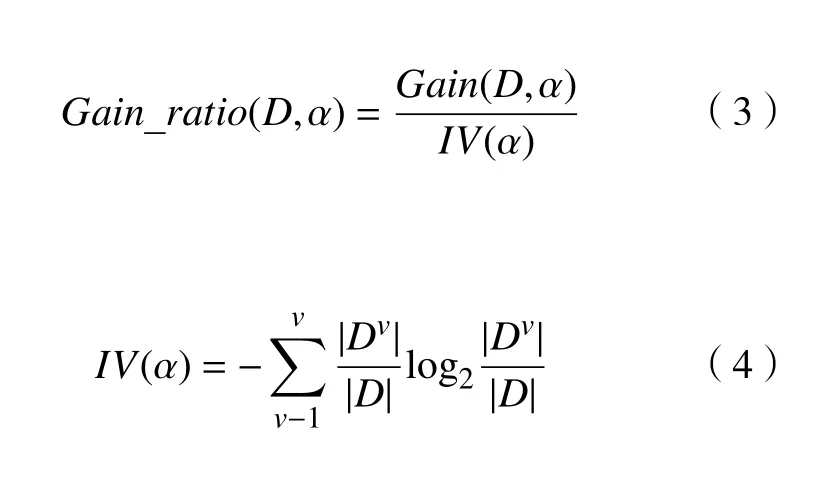
其中:IV(α)是特征α 的熵。
决策树在构造中,如果树枝多且深,可能会因为噪声和偶然性采样导致过拟合,为了防止决策树过拟合,有预剪枝、后剪枝、节点样本数门限等,本文采用了预剪枝来减小过拟合,预剪枝使部分无需展开的分支不展开,这不仅降低了过拟合的风险,还显著减少了决策树的训练时间开销和测试时间开销。
由于CNN提取的特征具有冗余性,为了减少过拟合和提升分类效率需要对特征用PCA降维。PCA是从一组特征中提取一组新特征,通过解协方差矩阵的特征值来求解主成分,其中特征值越大,对应特征向量越重要,按重要性从大到小排列,新特征之间互不相关,根据事先确定新特征代表数据总方差比例,来决定选取主成分个数。
2 实验数据和预处理
2.1 数据集
为了验证模型的性能,采用了NEU-DET数据集,并引入超声A扫描缺陷信号数据集ULTADET验证模型在非图像数据上的性能。
1)图像缺陷数据集NEU-DET
该数据集是开放的缺陷检测数据集[20],收集了热轧钢带的6种典型表面缺陷,即轧制氧化皮,斑块,开裂,点蚀表面,内含物和划痕。该库每类缺陷含300个样本,每个样本为200×200分辨率的灰度图像,如图2所示。
2)非图像缺陷数据集ULTA-DET
为模拟实际金属缺陷的不同深度和形状,在厚度为11 mm的Q235为样板上加工了2 mm、5 mm、8 mm这3种深度每种共80个,每种深度都有矩形、圆形、椭圆和不规则形状如图3a)所示,实验以缺陷深度为分类标准,共240个数据。该实验采用频率2.5 MHz、底部直径20 mm的超声探头,并通过数字式超声探伤仪、示波器来获取超声缺陷信号,其实物连接如图3b)所示,检测原理如图4所示,当有缺陷时超声回波将发生变化,探头接受回波并传回探伤仪中,最终示波器收集探伤仪的数据,示波器获取的每个缺陷信号为1×16384的数据,以csv文件格式储存。

图3 实验样本和设备
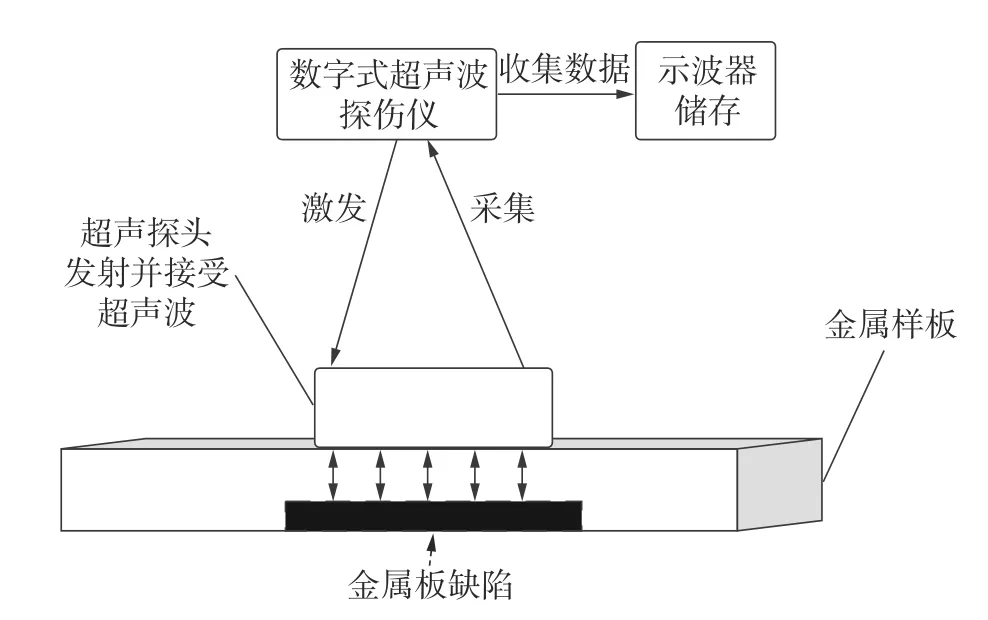
图4 超声检测原理图
因为两个数据集属于中小规模,划分测试集和验证集时会导致训练样本减少,进而分类器性能会受到影响,为消除影响,采用十折交叉验证对数据集进行划分,即将全部数据随机划分为十个等份,每一份轮流作为测试集,其他九份作为训练集,当每一份都作为测试集后共得到10个结果值,将10个结果值的平均值作为交叉验证的结果。因此,两类缺陷数据集按十折交叉验证取90%为训练集,10%为测试集。因为有了交叉验证所以不在划分验证集,具体缺陷样本分布如表1和表2所示。
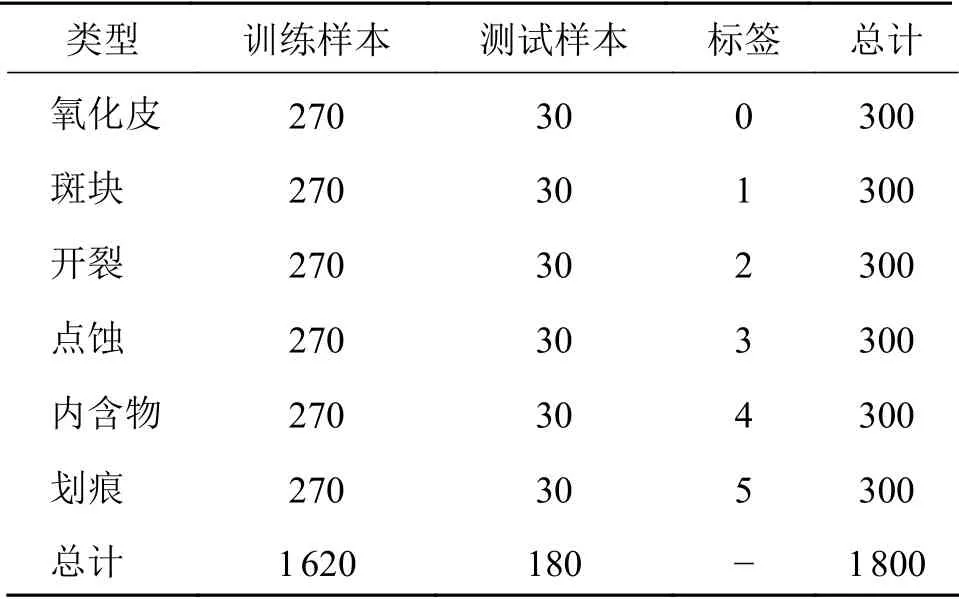
表1 图像缺陷数据集NEU-DET缺陷样本分布
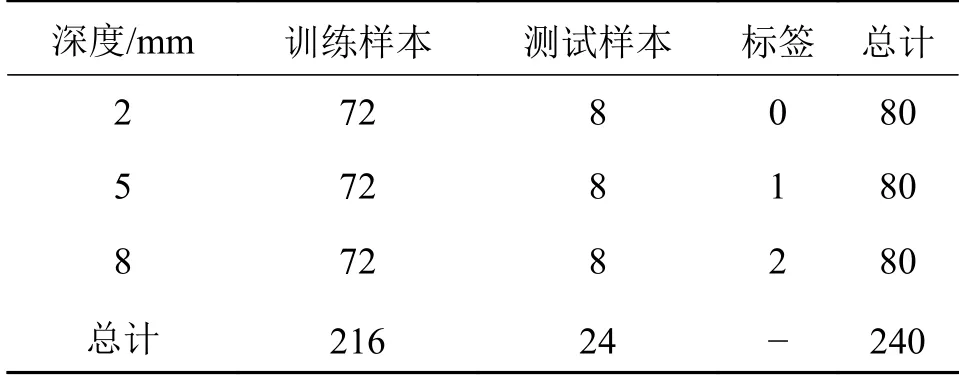
表2 非图像缺陷数据集ULTA-DET缺陷样本分布
2.2 实验环境和参数设置
本文实验平台为Pycharm,深度学习开源框架为Pytorch。
用CNN提取特征时,根据ULTA-DET数据集和NEU-DET数据集数据规模大小选择学习率和批训练块,其他参数选择通过一般性规律选择,具体如表3所示。

表3 CNN参数
3 实验结果与分析
3.1 人工与卷积提取特征对比实验
为了证明CNN提取特征在识别分类上的性能,本文在人工提取特征和CNN提取特征两种条件下进行实验。实验中人工提取特征方式需要进行图像去噪、图像增强、特征选择和特征提取。对于NEUDET数据集,用中值滤波去噪、直方图均衡化进行图像增强、并进行二值化、然后对样本进行了特征选择和提取,具体特征如表4所示,每个样本共11个缺陷特征。

表4 人工提取NEU-DET数据集的特征类型
这里采用准确率、6种缺陷的平均精准率和平均召回率作为性能评价指标,两种算法模型的分类结果如表5所示,可以看出,在相同数据情况下,CNN-DT在准确率、平均精准率和平均召回率上分别高出1.56%、1.22%、1.7%。运行时间上DT算法模型少用2459.4 s,这是因为前期人工选择并提取特征并未计入分类时间中,而DT算法模型在这一部分所用时间是远超于3459.9 s的,所以总时间还是CNN + DT更少。因此CNN提取特征用于缺陷图像分类有更好的分类结果。
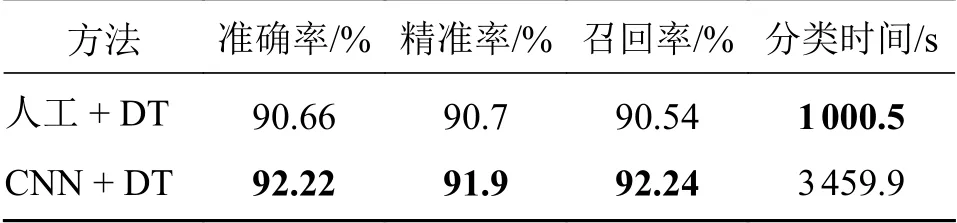
表5 人工提取特征和CNN提取特征在NEU-DET上的测试结果
3.2 有无PCA + DT模块对比实验
为证明本文模型性能,将本文模型和没有采用PCA-DT的浅层结构CNN模型进行对比实验。CNN模型训练过程如图5所示, CNN模型在迭代70次左右收敛,因为中小规模数据集数据过少且未做数据增强,CNN模型由于过拟合导致测试集准确率始终有一定的波动。
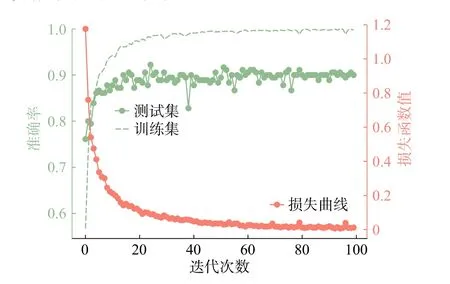
图5 CNN在NEU-DET上的学习曲线图
对于CNN-PCA-DT模型,PCA需要确定主成分个数,DT需要预剪枝,由于两个数据集的样本特征多但样本量不多,因此选择最大叶子节点数作为预剪枝参数,取不同PCA个数和最大叶子节点数个数得出数据集的准确率如图6所示,图中最高的是红色长方体94.76%,因此根据红色长方体主成分个数取400个,最大叶子数取64。用这两个参数进行实验,因为随机分批次,为提高分类结果统计性,对每类的训练和测试进行10次,取10次的平均值为最终结果, 并将分类时间作为效率评价指标。
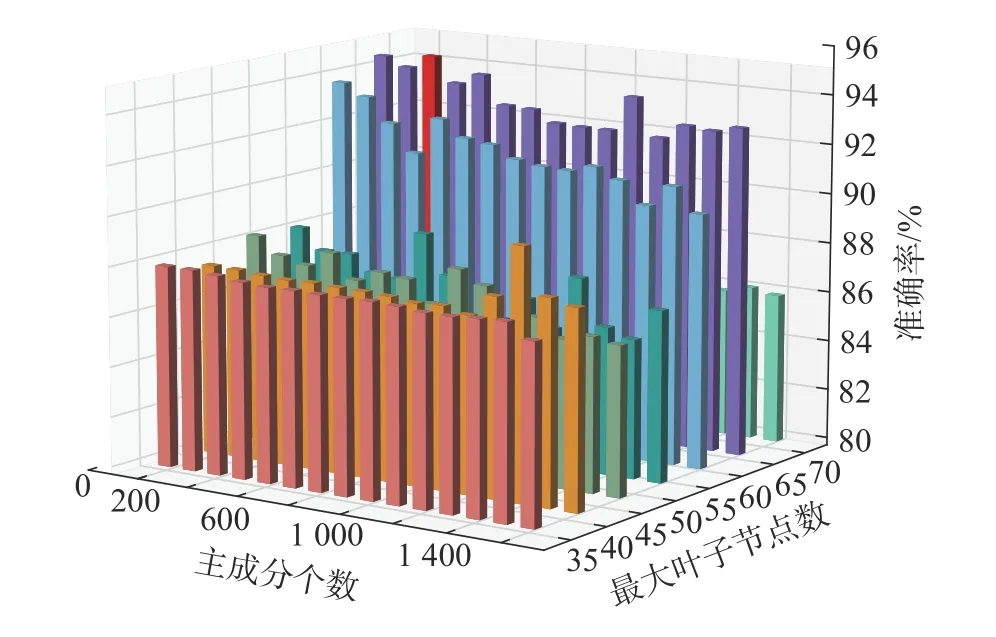
图6 PCA和最大叶子节点数对分类NEU-DET准确率的影响
最终对比结果如表6所示,本文模型是在准确率、精准率和召回率上皆优于CNN模型,这是因为数据量较少,CNN模型过拟合。且CNN用时约为本文模型的13.86倍,从信号处理的角度看,CNN的反向传播进行参数优化是低效的,这验证了本文模型的时间复杂度好,有利于实时在线分类,对于中小规模数据,本文模型能充分发挥其性能。
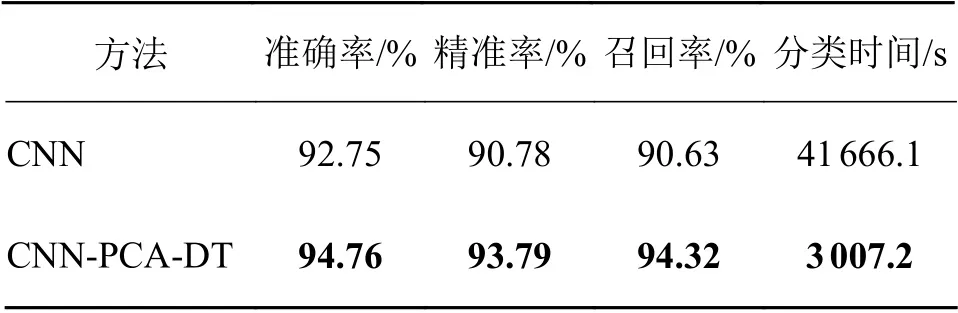
表6 有无PCA-DT在NEU-DET上的测试结果
3.3 综合对比实验
将本文模型与主流分类模型进行对比,并加入是否需要人工提取特征这一指标,以验证本文方法的有效性。对比的模型有基于机器学习的SVM和利用了一种能够提高缺陷识别率的新的特征描述子方法的文献[20],基于深度学习的GoogLeNet、VGG16和ResNet34。测试结果如表7所示,可知本文模型相对传统机器学习中的SVM是有优势的,与文献[20]在3个评价指标上差别不大,但是本文CNN提取特征的优势是文献[20]所不具有的;对于中小规模数据,3种深度学习方式在3个评价指标上与本文模型相比优势不大,且因为结构复杂参数多,分类时间上分别是本文模型的32.25倍、41.57倍、20.06倍,因此在算法模型的时间复杂度上,本文方法无疑效率更高。
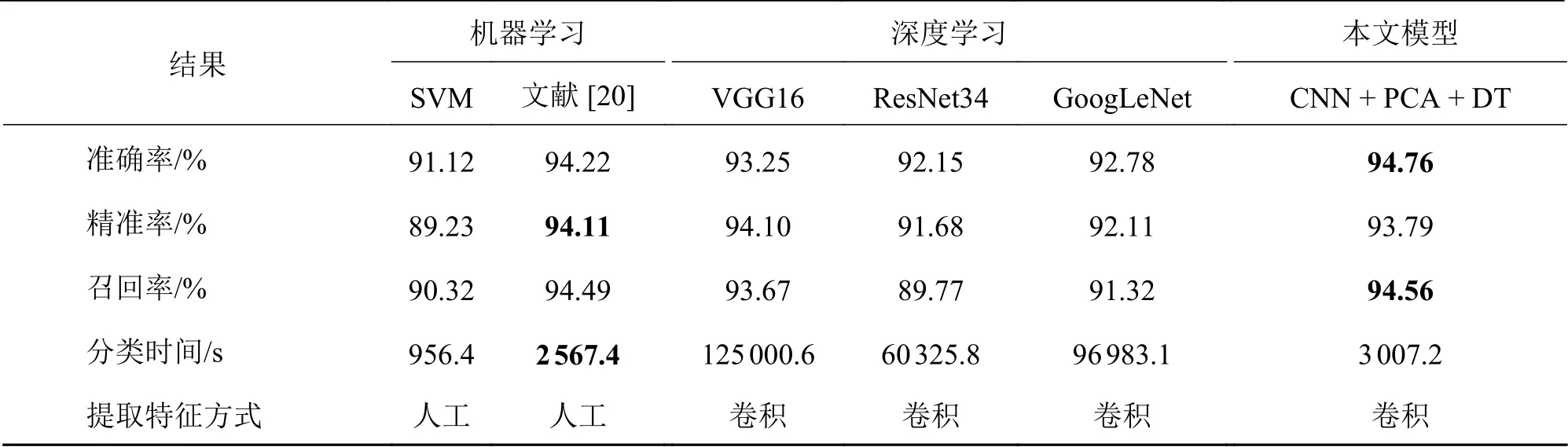
表7 不同算法在NEU-DET上的测试结果
3.4 非图像缺陷分类结果
CNN及其变体模型[16-20]多用于图像数据并未在非图像数据上进行实验,为验证本文模型在非图像缺陷数据上的性能,引入超声A扫描缺陷信号数据集ULTA-DET上,同处理图像数据一样,通过实验得到图7所示,求得PCA个数取100,最大叶子节点数取8。
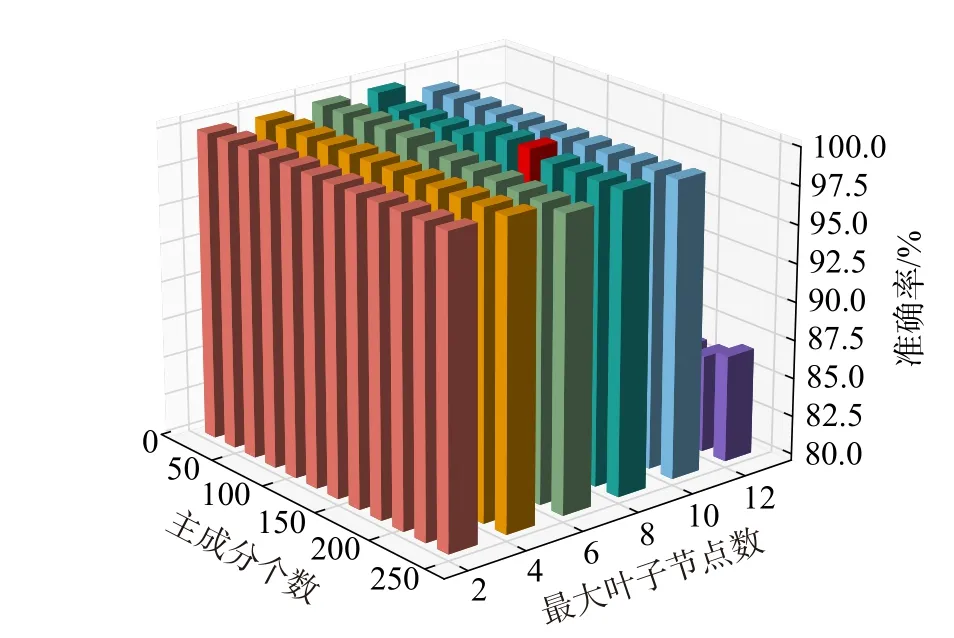
图7 PCA和最大叶子节点数对分类ULTA-DET准确率的影响
为与DT算法比较, 需要人工提取特征。超声数据集的人工特征提取利用经验模态分解(Empirical mode decomposition, EMD)[21],分解得到9个本征模式分量IMF,1个残差res,如图8所示。
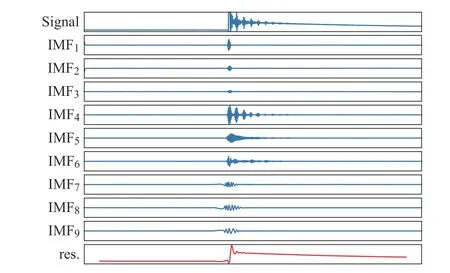
图8 ULTA-DET第15号样本的EMD分解图
选取能表征大部分缺陷特性的前7个IMF分量,以减小计算复杂度,选取时域指标参数作为缺陷信号的特征值,具体如表8所示,所以每个样本由前7个IMF分量可得7×12 = 84个缺陷特征。

表8 人工提取ULTA-DET数据集的特征类型
用单独的浅层CNN分类,学习曲线如图9所示,由图9得出迭代20次左右便达到稳定。
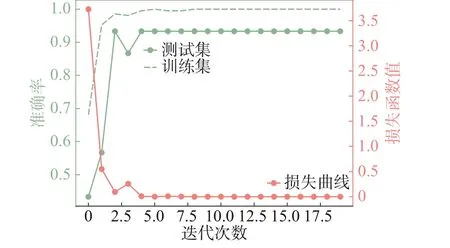
图9 CNN在ULTA-DET上的学习曲线图
测试结果见表9,本文模型在非图像缺陷数据集上准确率、精准率、召回率上较机器学习方法中的DT、SVM、文献[20]的算法有较大提升,在分类速度上稍慢于机器学习,但机器学习需人工提取特征。且3种机器学习方法对于NEU-DET数据集均能达到90%左右,而ULTA-DET数据集上则表现为70% ~ 80%,由此看出,机器学习的分类效果特别依赖特征提取和选择,而人工设计特征和提取特征非常不稳定,其对于最终分类结果影响巨大,这凸显了本文利用CNN提取特征的优势。
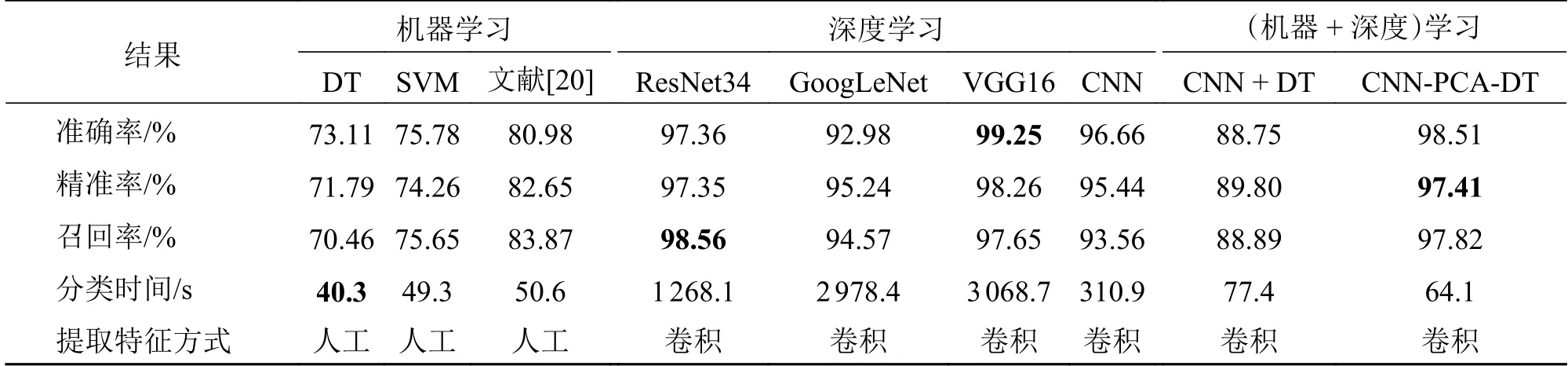
表9 不同算法在ULTA-DET数据集上的测试结果
本文模型与深度学习模型GoogLeNe、VGG16、ResNet34和CNN对比,在3个评价指标上差别较小,但因为本文方法结构简单参数少,所用分类时间更少,在性能上优于深度学习模型。此外,通过CNN + DT与CNN-PCA-DT对比,可以看出加入PCA能提升分类效果。因此本文方法适用于非图像类型缺陷,弥补CNN结合机器学习方法用于非图像缺陷数据分类的空白。
4 讨论
本文提出了一种针对中小规模数据集的CNNPCA-DT的缺陷分类模型,模型引入浅层的卷积神经网络提取特征来代替繁琐费时且不稳定的人工提取特征,因为CNN模型在小规模数据上容易过拟合,利用决策树对中小规模缺陷数据集进行分类来代替需要大样本的卷积神经网络;通过引入主成分分析,进一步对提取的特征去冗余化,减小过拟合性并提高模型运行效率;为验证本文模型的通用性,除图像缺陷数据集NEU-DET,加入非图像数据集超声A扫描缺陷数据集ULTA-DET。实验结果表明,本文方法能快速有效地对图像缺陷数据和非图像超声A扫描缺陷数据分类,因此对图像和非图像类型缺陷在线实时分类有现实意义。
由于深度学习对大规模数据有巨大优势,本文模型只针对中小规模数据集分类,因此对于十万、百万级等大型规模数据可以与深度学习方法比较和改进、进行深入地研究。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
电机与控制学报(2018年9期)2018-05-14
中国新通信(2017年9期)2017-05-27
计算机应用(2016年10期)2017-05-12
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
