
基于多粒度特征分割的车辆重识别算法
2022-10-09 00:42蓝章礼杨晴晴
重庆交通大学学报(自然科学版) 2022年9期
蓝章礼,王 超,杨晴晴,金 豪
(重庆交通大学 信息科学与工程学院,重庆 400074)
0 引 言
车辆重识别(Re-ID)旨在从多个非重叠摄像机拍摄的图像中识别出同一车辆,可将其看作图像检索的子问题[1]。通过车辆重识别技术可对目标车辆进行快速查找、定位及追踪。因摄像头视角变化带来的类内差异性和类间相似性问题,使得车辆重识别成为一个极具挑战性的任务,如图1。
早期研究者主要基于车辆全局外观特征进行车辆重识别。X.LIU等[2]提出将纹理特征和颜色特征进行融合作为车辆特征表示,以实现车辆重识别;D.ZAPLETAL等[3]提出了一种结合颜色直方图、HOG特征并使用SVM作为分类器的车辆重识别方法;H.LIU等[4]提出了一种深度相关距离学习方法,能较好缩小类内差异并扩大类间差异,但存在需消耗大量计算资源的问题;Y.BAI[5]等提出了一种组内敏感的三元组嵌入方法来处理类内方差,并给出了均值三元组损失,以缓解训练阶段三元组采样不当带来的负面影响。
全局特征在识别外观相似的车辆时存在一定局限性,一些研究学者开始利用局部特征来实现车辆重识别。J.PENG等[6]提出利用空间变换网络对局部区域进行定位以学习到判别性特征;H.CHEN等[7]提出将特征图在不同维度上均等分割成4块以提取局部特征;J.QIAN等[8]提出将特征图沿纵向分割成8块以提取细粒度的局部特征;H.WANG等[9]提出将特征图沿纵向和横向均等分割成6块以得到车辆局部细节特征。但上述方法忽视了显著性特征对潜在显著性特征的掩盖问题,并且缺乏对通道维度的关注,导致提取的局部特征不够充分。
为了使提取的特征更具代表性,常在网络中嵌入注意力模块。A.SUPREM等[10]提出联合全局和局部注意模块的车辆重识别方法,全局注意模块用来降低输入层的稀疏性,局部注意模块用来自动提取局部零件的特征;J.YANG等[11]为解决视角变化引起局部特征丢失的问题,利用空间注意力模块学习全局特征,并从粗到细构建金字塔以学习不同尺度上的局部特征;D.MENG等[12]针对不同视角导致的类内差异大、类间差异小的问题,提出基于解析的视点感知嵌入网络,以实现视点感知特征对齐和增强,该算法能捕捉到不同视角下车辆的稳定性判别信息。
综上,笔者提出一种基于多粒度特征分割的车辆重识别算法,以ResNeSt-50[13]为骨干网络提取初级特征,并将骨干网络复制成三个独立的分支,分别在纵向、横向、通道三个维度上进行多粒度特征分割。又在ResNeSt-50的每个split-attention block中嵌入了空间注意力模块(spatial attention module,SAM)以挖掘更丰富、更具判别性的特征信息,增强了车辆表征的鲁棒性。
1 多粒度特征学习算法
1.1 算法网络结构
笔者所提出的算法网络结构如图2。首先,通过骨干网络提取图像初级特征,骨干网络采用三分支结构,当一张车辆图像输入到骨干网络后会生成三个独立特征图;然后,特征图将沿纵向、横向、通道方向被分割成不同粒度的分块,不同分块可提取到不同的局部信息;接下来,对所有特征图执行池化操作,其中,整体特征图采用全局平均池化以保留丰富的车身整体外观信息,分块特征图采用全局最大池化以提取区分性局部特征信息;最后,为统一特征向量的维度和防止过拟合,对池化层输出的所有特征图执行核大小为1×1的卷积操作及批归一化处理,并使用全连接层作为分类器。
1.2 网络中的关键组件
1.2.1 骨干网络
ResNet-50[14]在图像分类、语义分割上广泛使用,目前重识别工作大都采用ResNet-50作为骨干网络提取图像的初级特征。但其会受到感受野的限制,同时缺乏跨通道间的相互作用。而ResNeSt结合通道注意力(channel attention module, CAM)和特征图注意力可实现不同特征图跨通道间的关联,在图像分类、对象检测、语义分割等方面都达到了更先进的水平。
鉴于车辆图像本身的复杂性及各部件之间存在相关性,采用去除掉最后的全局平均池化层和全连接层的ResNeSt-50作为骨干网络,在Conv4_1层之后复制卷积层以便将ResNeSt-50分成三个独立的分支,将三个分支分别命名为纵向分支、横向分支、通道分支。为得到更深、更丰富的车辆整体外观信息,将Conv5_x卷积层的池化操作的步长设置为1。并在ResNeSt-50的每个split-attention block中嵌入了空间注意力模块,以挖掘更关键的特征信息并抑制无关噪声。
1.2.2 三分支结构
笔者主要研究如何充分提取车辆局部细节信息来提高车辆识别准确率,为得到车辆不同空间维度的细节特征,将特征图沿纵向和横向进行分割,如图3。

图3 纵向分割与横向分割示意
具体的说,将骨干网络输出的两个独立特征图分别命名为Fh和Fw,即图2的纵向分支和横向分支。然后将独立特征图分别在纵向和横向上分割成若干个分块特征图,具体表示如式(1):
(1)
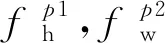
由于过多分割会降低最终外观特征中的全局特征权重,过少分割会使得局部特征接近全局特征。且神经网络提取的总是某个区域内的显著性特征,即在某个区域内权值较大的特征信息。那么在对特征图进行分割以提取局部特征时,局部区域的大小不同,显著性特征对潜在显著性的局部细节特征的掩盖程度就不同。因此,采用多粒度的分割方式,结合粗、中、细三种不同级别的分区粒度可以提取到不同的内容粒度信息,尽量避免潜在显著性局部特征被掩盖的问题。其中,将未分割的特征图定义为“粗粒度”,将分割为两块的特征图定义为“中粒度”,将分割为四块的特征图定义为“细粒度”。因此,式(1)中的p1,p2={1,2,4}。
此外,卷积层中的滤波器会生成通道信息,即使输入相同,它们也独立地学习和更新参数,即每个单一通道学习到不同的特征。而每个卷积核进行卷积操作时都会生成一个通道,特征图的通道是由许多个单一通道组合而成,每个单一通道独立表达信息,但当它们组合成为一个整体之后即为平时所认知的通道,这个特征信息为全局信息,那么在特征图的通道维度上执行池化操作时就会丢失通道上的局部细节信息。因此笔者还将特征图沿通道方向进行分割以提取到不同于全局特征的局部特征,将其作为横向和纵向上的补充。在通道方向上同样采用多粒度的分割方式,如图4,具体的表示如式(2):
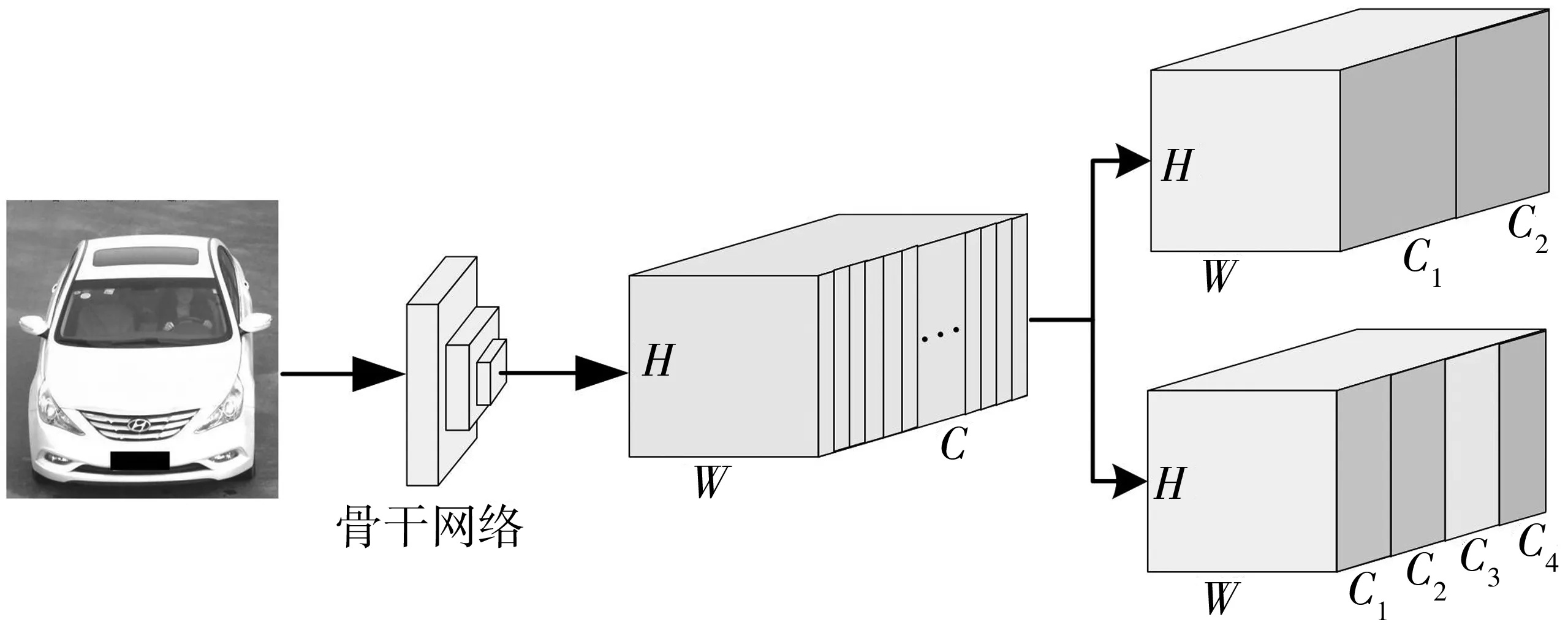
图4 通道分割示意
(2)
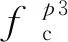
1.2.3 注意力机制
注意力机制最早是用于图像识别领域,之后广泛用于自然语言处理领域[15]。研究发现联合通道注意力和空间注意力能更好的提取区分性特征,因此在ResNeSt-50的每个split-attention block中嵌入了SAM以构成注意力模块SS-Net,从而达到同时对通道维度及空间维度上的特征图进行加权处理的目的。SAM采用的是卷积块注意模型[16](convolutional block attention moudle, CBAM)中的空间注意力模块。SS-Net的结构如图5。
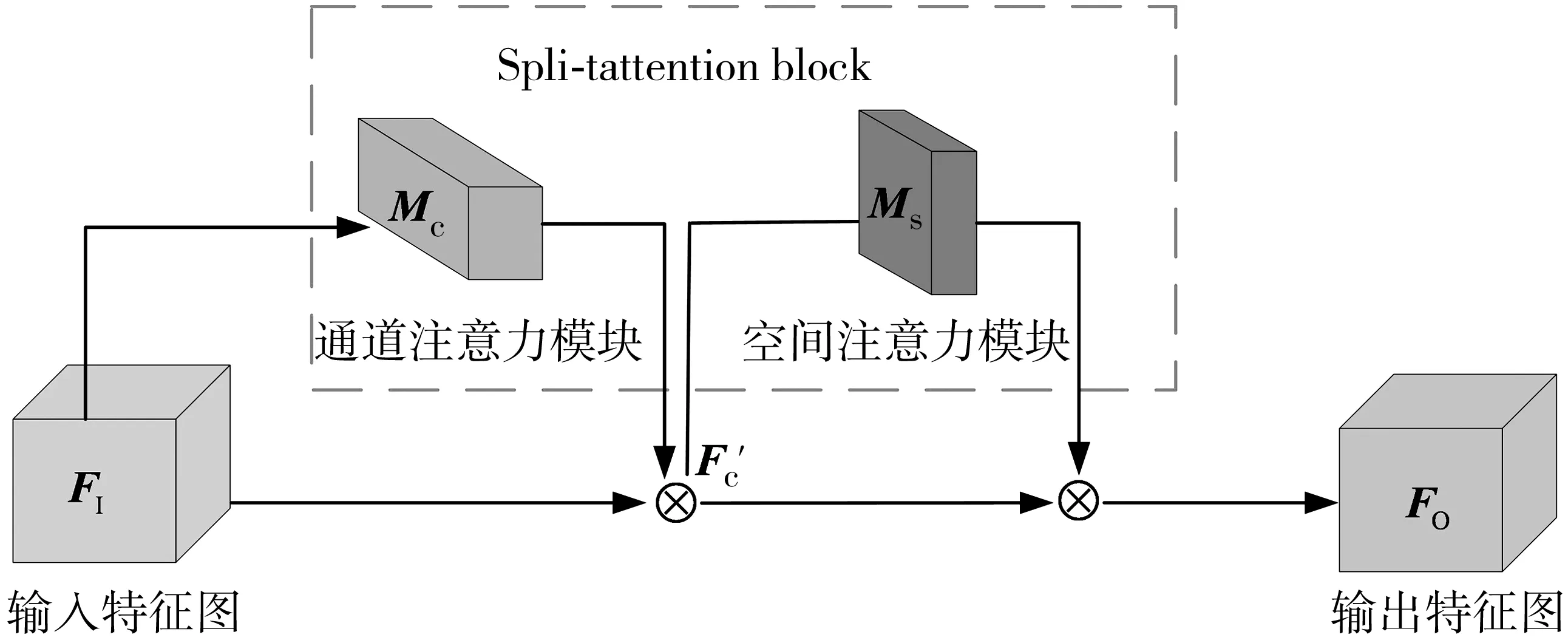
图5 SS-Net结构
假设输入的特征图(也称为特征矩阵)为FI∈RW×H×C(H、W、C分别为特征图的高度、宽度、通道数目),在SS-Net内部依次沿着通道维度和空间维度推断出通道权重矩阵Mc∈R1×1×C和空间权重矩阵Ms∈RW×H×1。为了使特征矩阵可以自适应调整,以重点关注更具区分性的前景信息,首先将通道权重矩阵Mc∈R1×1×C与输入特征图FI∈RW×H×C逐元素相乘,生成通道注意力特征图F′c∈RW×H×C,然后将F′c∈RW×H×C与与空间权重矩阵Ms∈RW×H×1逐元素相乘,可得到同时经通道维度及空间维度加权处理后的最终注意力特征图FO∈RW×H×C,⊗表示特征矩阵的逐元素相乘,SS-Net的计算过程为:
F′c=Mc(FI)⊗FI
(3)
FO=Ms(F′c)⊗F′c
(4)

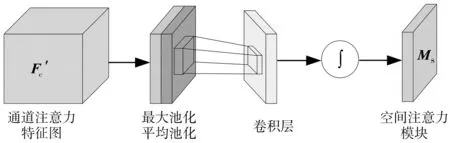
图6 空间注意力模型结构
Ms(Fc′)=σ{f7×7{[AP(F′c);MP(F′c)]}}=
(5)
式中:AP(·)及MP(·)分别为平均池化和最大池化操作;F′c为经过CAM的通道注意力特征图;σ(·)为sigmoid激活函数;f7×7为核大小为7×7的卷积运算。
1.3 损失函数
车辆重识别任务可以看作是分类任务,并且可视为一次性学习任务,这样模型训练很可能过拟合,因此采用经过标签平滑正则化处理的交叉熵损失函数,它利用车辆图像身份ID标签进行有监督地学习,能使网络学习到具有身份辨别性的特征。原始交叉熵损失函数计算如式(6):
(6)
式中:N为车辆的总类别数;y为真实样本标签;pi为对输入的图像预测为类别i的概率值。
经标签平滑正则化处理后的标签分布qi变为q′i,如式(7):
(7)
经过标签平滑正则化处理的交叉熵损失函数如式(8):
(8)
式中:ε为平滑因子,用来防止模型在训练过程中产生的过拟合问题,ε=0.3。
车辆重识别本质上是个图像检索问题,它通过计算查询集(query)与图库集(gallery)之间的特征相似度进行排序。采用硬三元组损失[17]作为相似性度量的损失函数,在包含P个身份和每个身份K张图像的小批次中,每张图像(原样本a)具有与其相同身份的K-1张图像(正样本p)和与其不同身份的(P-1)×K张图像(负样本n)。传统三元组损失通过网络训练拉近正样本对(a,p)图像的距离,同时拉开负样本对(a,n)图像的距离实现正负样本的分开,从而更好的进行相似度度量学习。而硬三元组损失旨在将更多的权重放在最接近的负对和最远的正对上以更好的优化模型。硬三元组损失的计算如式(9):
(9)
式中:ai,pi,nj分别为原样本、正样本和负样本的特征向量;α为约束不同类别样本距离的阈值。
但若只采用硬三元组损失进行模型训练,只进行相似度的度量学习,缺乏车辆ID标签的监督,会导致学习到的具有身份辨别性的特征相对较少,且模型收敛速度缓慢,因此,结合交叉熵损失和硬三元组损失各自的优势对模型进行训练优化。网络总体损失Ltotal的计算如式(10):
(10)
式中,Nc和Nt分别为交叉熵损失和硬三元组损失的数量;λ为平衡两种不同损失的权重系数。
计算中,网络全连接层学习到的21个概率分布向量[g′h,g′w,g′c,fh1,…,fh6,fw1,…,fw6,fc1,…,fc6]用于计算交叉熵损失,批归一化层学习到的三个全局特征向量[gh,gw,gc]用于计算硬三元组损失,因此Nc=21,Nt=3。
2 实验设计及结果分析
2.1 数据集和评估指标
网络训练及评估采用的数据集是车辆重识别领域中使用最频繁、关注度最高的VeRi-776[18]和VehicleID[19]数据集。
VeRi-776数据集总共包含776辆汽车共近50 000 张图片。由分布在不同位置的20个摄像机拍摄而成,该数据集将其中576辆汽车共37 778张图片用于构建训练集,其余的200辆汽车共11 579张图片用于构建为测试集。在测试期间,使用测试集中的1 678张图片作为query,其余的图像作为gallery。根据VeRi-776数据集的设置,使用平均精度均值(mean average precision, mAP)和Rank-1、 Rank-5匹配率作为算法在VeRi-776数据集上的性能评价指标。
VehicleID数据集中包含26 267辆汽车共221 763 张图片,训练集包含13 164辆汽车共113 346张图片。该数据集提供了3个不同大小的测试集,分别命名为small、medium、large,其中所具有的车辆ID数量分别为800、1 600、2 400。测试时,在测试集中每个ID的几张图片中,随机抽取一张图片加在gallery中,其余的图片加在query中。根据VehicleID数据集的设置,使用Rank-1、Rank-5匹配率作为算法在VehicleID数据集上的性能评价指标。
2.2 实施细节
2.2.1 实验环境
采用开源的Pytorch作为深度学习的框架,版本为1.7.0;采用Python编程软件,版本为3.6.4;主机的CPU为Intel®CoreTM i9-10900K,显卡为GeForce RTX 3090,内存为32GB,GPU配置为CUDA 11.0及cuDNN 8.0.5;操作系统采用Win10。
2.2.2 训练阶段
三分支神经网络采用多任务联合训练方式,共享骨干网络权重,之后针对每个分支的全局特征和局部特征设计不同的损失函数,以指导特征的生成。
所有输入图像的大小都设为384×384,批次大小设为8×4,并通过概率为0.5的随机水平翻转、随机擦除来增强数据集。所有实验中,使用Adam作为梯度优化器,L2正则化的权重衰减因子设为5e-4,Ltriplet中的α设为1.2。训练轮数设为500轮,初始学习率设为2e-4,为了使网络尽快寻找到全局最优解,在第300和第400轮时将学习率分别设为2e-5、2e-6。
2.2.3 评估阶段
在评估时,将批归一化层的所有特征向量进行串联作为车辆图像的外观特征向量,如式(11):
f=concat{gh,gw,gc,lh1,…,lh6,lw1,…,lw6,lc1…lc6}
(11)
由于在训练阶段采用了随机水平翻转以增强数据集,提升模型的泛化性。所以在评估阶段将原图和水平翻转后的图像分别输入到网络中得到相应特征向量f1及f2,然后将两个特征向量的平均值f′作为车辆图像最终外观特征向量,最后采用欧式距离对不同车辆外观特征向量进行相似度衡量,并按相似度从大到小进行排序得到检索结果。
2.3 消融分析
为验证所提出的网络结构中的关键组件的有效性,在VeRi-776数据集上做了大量的实验,比较了不同网络结构、有无空间注意力模块、不同损失函数时的性能,以找到最优网络结构。
2.3.1 网络结构

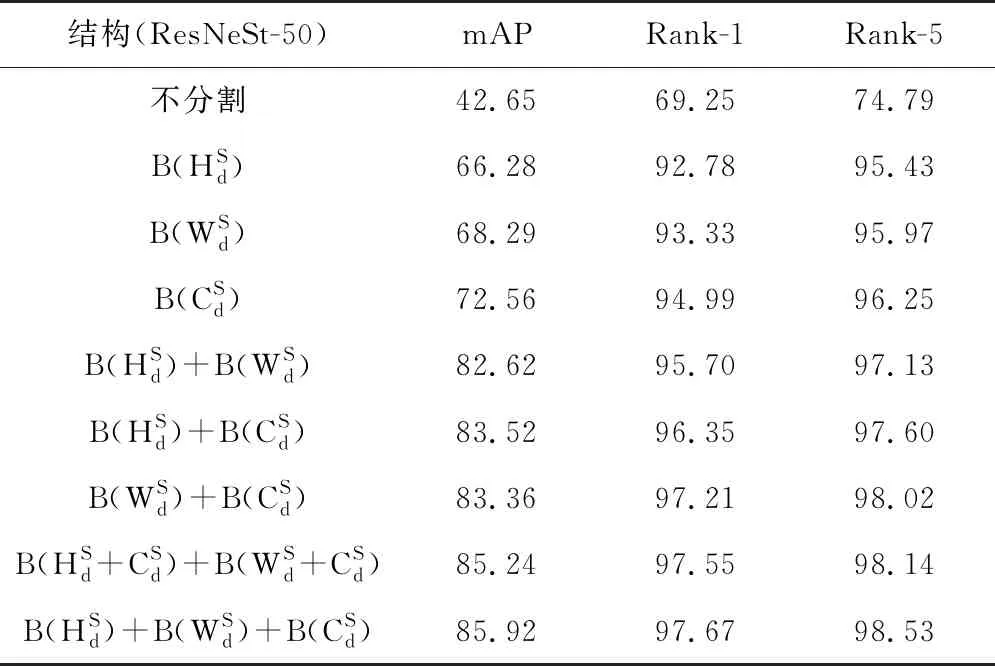
表1 不同网络结构的性能对比
结果表明分割通常可以提升神经网络的性能,在三种分割类型中,通道分割带来的改善明显优于横向和纵向分割。并且不同类型分割的组合比单个分割产生更好的性能,三种类型分割的并行组合能使网络结构性能最佳。
2.3.2 空间注意力模块
主要比较在ResNeSt-50的每个split-attention block中是否嵌入SAM时网络结构的性能。实验结果如表2,结果表明嵌入SAM的网络结构能显著提升车辆重识别的性能。这得益于空间注意力模块可学习车身部件之间的空间位置相关性,增强局部特征的鉴别力。
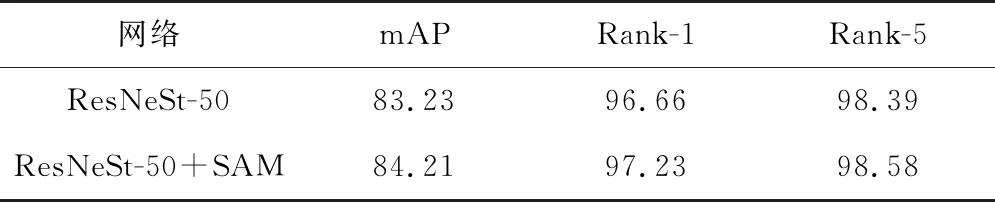
表2 空间注意力模块的消融实验
2.3.3 损失函数
交叉熵损失主要应用于正常样本上,而硬三元组损失主要应用在难样本上。为平衡两种损失对正常样本和难样本的贡献度,需要确定一个权重参数λ。对Ltotal设置了几种可能性,在表3中展示了λ取不同值时的性能,结果显示硬三元组损失能略微改善模型的性能,将更多的权重放在交叉熵损失上的性能明显更好。但是随着λ增大,性能反而下降,并且收敛缓慢。因此,将λ设置为2。

表3 λ取不同值时的性能比较
2.4 现有算法对比
为验证笔者算法的有效性与优势,将提出的算法与现有先进算法在VeRi-776和VehicleID数据集上进行对比,选择的对比算法包括GS-TRE[5]、MRM[6]、PRN[7]、SAN[8]、TCPM[9]、GLAMOR[10]、PSA[11]、PVEN[12]。算法对比结果如表4、表5。表中的RR代表再排序算法(re-ranking)[20],再排序是一种后处理算法,能提高最终结果的精确度。
从表4可以看出,笔者算法在VeRi-776数据集上的mAP、Rank-1、Rank-5分别达到了85.92%、97.67%、98.53%,当不使用再排序算法时,mAP和Rank-1分别降低了1.71%、0.44%,而Rank-5反而增加了0.05%,几乎保持不变。当同时去除空间注意力模块和再排序算法时,mAP、Rank-1、Rank-5分别降低了2.69%、1.01%、0.15%。同样都使用再排序算法,与性能最好的GLAMOR算法相比,笔者算法在mAP和Rank-1上分别提高了5.58%、1.14%,在Rank-5上也仅仅降低了0.09%。
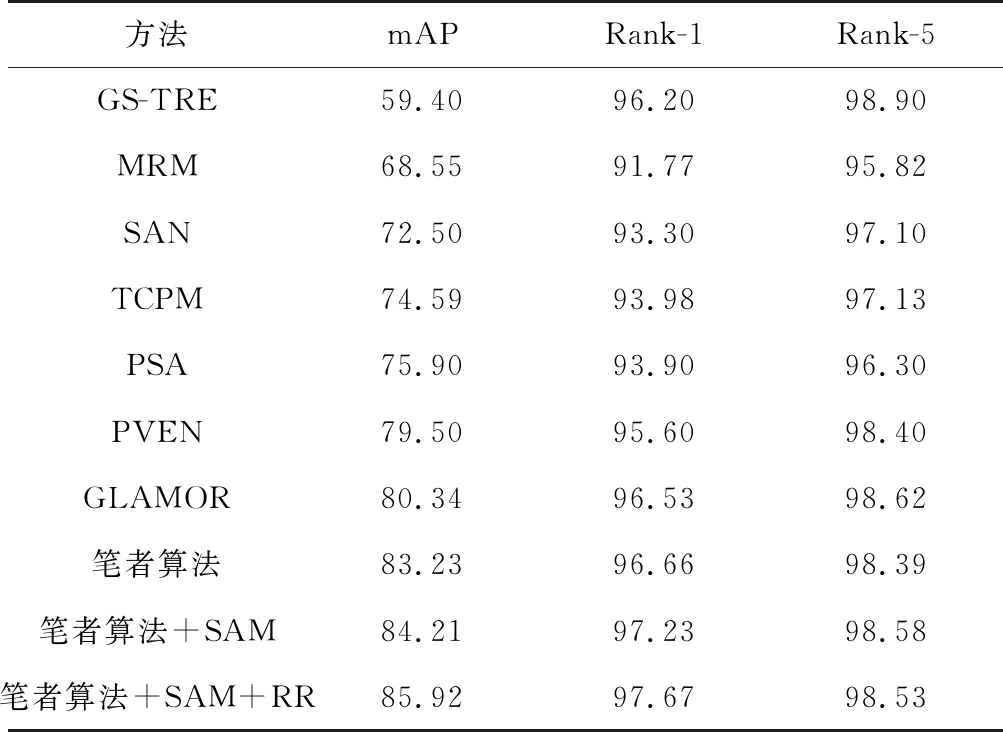
表4 在VeRi-776数据集上的性能比较
鉴于VehicleID数据集的特殊性,在评估时一般不使用再排序算法。从表5可以看出,与其他算法相比,笔者算法在small、medium、large三个测试集上均取得了最好的识别效果。即使与性能最好的PVEN相比,所提算法在三个测试集上的Rank-1 及Rank-5分别平均提高了2.78%,2.01%。

表5 在VehicleID数据集上的性能比较
通过对两个数据集的实验,验证了笔者算法的有效性,这得益于所提算法采用多粒度的分割方式将特征图沿纵向、横向进行分割以提取局部特征,并对通道维度进行关注以作为纵向和横向上的补充。采用多粒度的分割方式优势在于不只是关注具有固定语义(车窗、车灯等)的特定部分,而是覆盖了所有可区分(排气筒、装饰物等)的信息,同时还可以尽量避免固定大小的局部区域对潜在显著性局部信息的掩盖问题,使得网络提取到更充分的局部细节信息。除此之外,还在骨干网络中嵌入了SS-Net模块使得网络提取到强判别性的特征,能更好的解决类内差异和类间相似问题。
2.5 可视化分析
笔者算法的检索结果可视化如图7。测试了8张查询图像,包含不同车辆类型、不同光照强度、不同遮挡程度、不同背景复杂度几种情况。检索结果根据相似度大小从左到右依次排序,正确检索用灰色标注,错误检索用黑色标注。

图7 笔者算法检索结果可视化
从可视化结果可以发现,在图片清晰、没有遮挡或有较少遮挡时,笔者算法可精确检索;在强遮挡、背景复杂、图片分辨率低时,笔者算法也能较准确检索。但在检索相同车型及相同颜色的车辆时会存在较多错误检索,这在于外观极其相似的车辆本身仅存在细微差异,并且受光照、分辨率、遮挡等因素的影响,这些细微差异很难提取出来,即使人工检测也会出现错误。因此车辆重识别技术仍是一个极具挑战性的任务。
3 结 论
笔者为解决以往算法提取局部特征不充分和潜在显著性局部特征易被掩盖的问题,提出基于多粒度特征分割的车辆重识别算法。采用三分支网络结构,将车辆图像特征图沿纵向、横向、通道方向进行分割以提取多粒度局部特征,并联合通道注意力和空间注意力以挖掘更丰富、更具判别性的特征信息,增强了车辆表征的鲁棒性。算法在VeRi-776数据集上的mAP、Rank-1、Rank-5指标分别达到85.92%、97.67%、98.53%;在VehicleID数据集的三个测试集上,Rank-1指标分别达到了88.36%、84.19%、78.89%,优于现有大部分主流算法,研究结果表明该算法具有先进性和有效性。
猜你喜欢
今日农业(2022年15期)2022-09-20
山花(2022年5期)2022-05-12
散文诗(2020年1期)2020-07-20
小天使·二年级语数英综合(2019年10期)2019-11-08
新作文·高中版(2017年6期)2017-07-06
东方艺术·国画(2016年3期)2017-02-08
科技与企业(2015年12期)2015-10-21
读者·校园版(2015年19期)2015-05-14
海外英语(2013年8期)2013-11-22
图书与情报(2013年6期)2013-08-11
