
一种基于多任务CNN的多模态人脸识别模型*
2022-10-06 01:31宋梦媛
云南师范大学学报(自然科学版) 2022年5期
宋梦媛
(上海工艺美术职业学院,上海 201800)
计算机、网络、大数据、物联网和通信等技术[1-2]的不断发展为人机交互领域[3]的发展带来了契机,特别是为情绪识别[4]的发展奠定了基础.通过捕捉多模态数据之间的互补信息,可进一步提高情绪识别的鲁棒性和准确率;为了处理来自面部表情图像和语音的多模态情感识别问题,许多学者对此进行了研究;早期的多模态情感识别主要基于人工特征提取[5],但在精度和效率方面欠佳,存在较大提升空间[6].随着深度神经网络的出现,人们更倾向于探索一些深层特征并开发出一些新的识别方法[7-10],这些方法属于特征级融合,主要是将语音和面部表情特征直接结合起来,简单直观,但不能灵活表达每个特征的影响系数,导致特征维数过大,模型准确率较低;为改善这一问题,本文提出了一种基于多任务CNN的多模态情感识别模型,在视觉和听觉模态数据中分别提取语音特征和人脸图像特征,用于提高不同情感的泛化能力和识别精度.
1 多模态情感特征提取
1.1 语音特征提取
使用OPENSMILE提取音频特征,并组成音频特征集.该特征集包含帧级声学特征的各种统计信息,如响度、Mel频率倒谱系数(Mel-frequency cepstrum coefficients,MFCC)、线谱对(line spectral pairs,LSP)、基频(fundamental frequency,FF)、声音、微光和抖动等.由于不同语音特征的维数不一致,采用z-分数归一化方法对特征进行归一化,从而得到归一化的N×M特征矩阵,其中N为样本数据的数量,M为特征个数.
语音特征在语音情感识别中有很好的应用,然而缺乏时域信息.为了获得时域和频域信息的特征,可通过生成Mel谱图[11],使得不同频率下的信号随时间的强度或“响度”呈现在特定波形中.
1.2 人脸表情特征提取
首先对视频进行帧处理,从而获得一系列面部表情图像[12].考虑到实际情境中的情绪是一个渐进的过程,对于每个情感视频剪辑,选择视频中间的五个连续图像,一方面可以获得更丰富的情感信息,另一方面可以扩展训练数据的样本数,增强模型训练数据多样性.
1.2.1 基于空间注意CNN的像素级特征提取
像素级特征提取网络主要基于CNN[13]结构和VGG[14]网络,并使用空间注意模块作为VGG网络的像素特征提取器.网络具体结构如图1所示,网络各层详细配置如表1所示.可以看出,网络输入图像的大小为44×44.Conv(ks×ks×cin×cout)表示卷积核大小为ks×ks的卷积层,其中cin和cout分别表示输入通道和输出通道的数量.MaxPool(k×k)表示卷积核为k×k的最大池化层.此外,在每个卷积层后跟随批量归一化层从而减少变量迁移,并使用校正线性单元(Rectified Linear Unit,ReLU)进行激活.空间注意层通过估计表示相应像素组重要性权重,从而减少不相关信息.具体原则为:与人脸图像不相关区域将赋予低重要性权重.进一步,将提取的CNN特征输入注意网络,且该网络输出一个注意掩码,从而量化特征图中每个位置的重要性.接着,提取的特征通过注意掩码进行加权.一般情况下,将提取的特征映射表示为hc,注意掩码表示为Mc.因此,一维卷积模型下获得注意掩模可计算如下:
Mc=fa(Wc×hc+Bc);
(1)
式中,Wc和Bc分别是卷积层的权重和偏置,且Bc随机初始化;fa(·)为tanh激活函数.此外,注意掩码的值限制在(1,1)范围内,其中权重为正

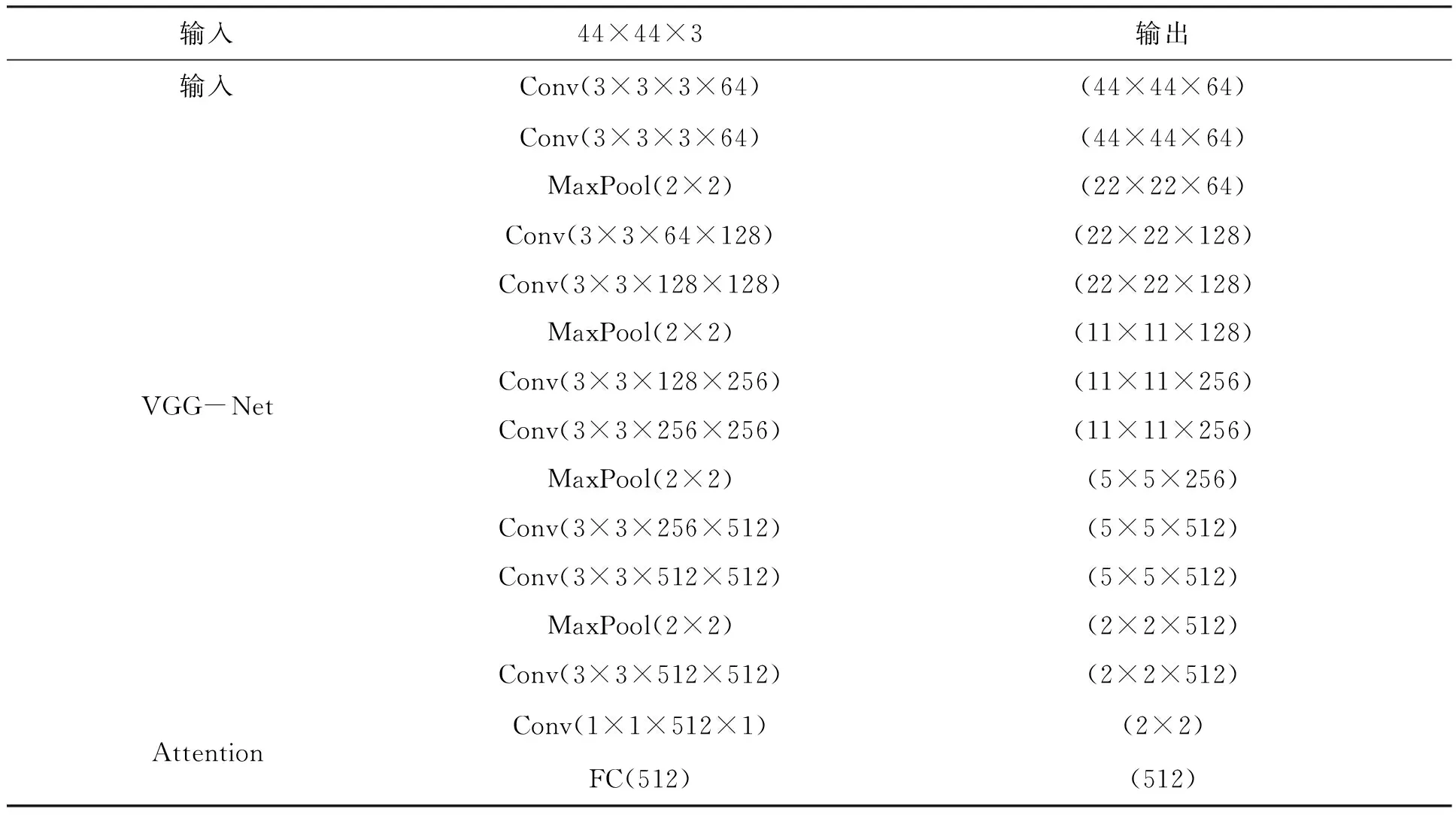
表1 基于像素级特征提取的空间注意CNN网络配置
的特征将视为与表达相关的特征;权重为负的特征将视为冗余特征,后期可过滤.通过对相应像素的重要性进行加权,可得到加权后的像素级特征映射hp,具体计算如下:
hp=Mc·hc.
(2)
1.2.2 人脸标志点检测与分组策略
令每个人脸标志点都由二维笛卡尔坐标表示为(x,y).考虑到面部表情由面部行为的变化引起,与某些特定区域密切相关,将面部标志点按其在面部的不同位置分为七组,包括左眉、右眉、左眼、右眼、鼻子、嘴巴和下巴.
1.2.3 基于几何级特征提取的LSTM注意网络
利用基于几何级特征提取的长短时记忆(Long and short term memory,LSTM)注意网络捕捉隐藏在不同面部区域标志点中的潜在信息,从而在分组的面部标志点的笛卡尔坐标中提取深层几何层次的表示.具体而言,通过七个LSTM获取相应的七个面部标志点序列vk(k=1,2,…,7),进而获取标志点相对位置相关性.因此,提取几何特征的过程可由以下公式递归表示:
it=σ(Wvivt+Whiht-1+Wcict-1+bi),
(3)
ft=σ(Wvfvt+Whfht-1+Wcfct-1+bf),
(4)
ct=ftct-1+ittanh(Wvcvt+Whcht-1+bc),
(5)
ot=σ(Wxovt+Whoht-1+Wcoct+bo),
(6)
ht=tanh(ct),
(7)
(8)
式中,it、ft、ct和ot分别是LSTM模型中输入门、遗忘门、存储单元和输出门的激活向量;vt和ht分别是第t个时间步的输入向量和隐藏向量;W表示权重矩阵;b为偏置;σ(·)为sigmoid函数.需注意,每个LSTM的单元数等于输入的面部标志点数.通过连接所有七个面部区域的所有单独学习的特征hi,从而获得整个面部的整体深层几何特征hl,具体描述如下:
hl=[h1,h2,…,h7].
(9)
考虑到不同的面部区域对表情识别的贡献是不平等的,因此需要区别对待不同面部区域中的标志点对分类的重要性程度,为此使用注意模块用于突出与表情相关的标志点中学习到的特征,将提取的所有七个LSTM的局部深层几何特征输入注意掩码网络,从而量化几何特征的重要性程度,同时对提取的特征进行加权.令提取的特征表示为hl,注意掩码为Ml,则卷积模型在注意掩码下获取的特征可计算如下:
hg=Ml·hl,
(10)
式中hg为面部整体几何特征.
2 基于多任务CNN的情绪识别网络
针对获得的Mel谱特征和面部表情特征,设计多任务CNN网络模型,从而提高单模态识别模型对用户情绪的敏感性.
2.1 网络结构
多任务CNN网络模型的结构如图2所示.该结构由五个卷积层和三个采样层组成,每层的参数和输出图像大小如表2所示.在CNN网络的顶部,使用Softmax函数计算训练过程的损失,并预测分类过程中的分类概率.Softmax的输入和输出分别表示分类的特征和类别.假设样本数据为{(x1,y1),(x2,y2),…,(xm,ym)},其中m为输入样本数据的数量.对于每个样本数据,首先执行分数线性映射:
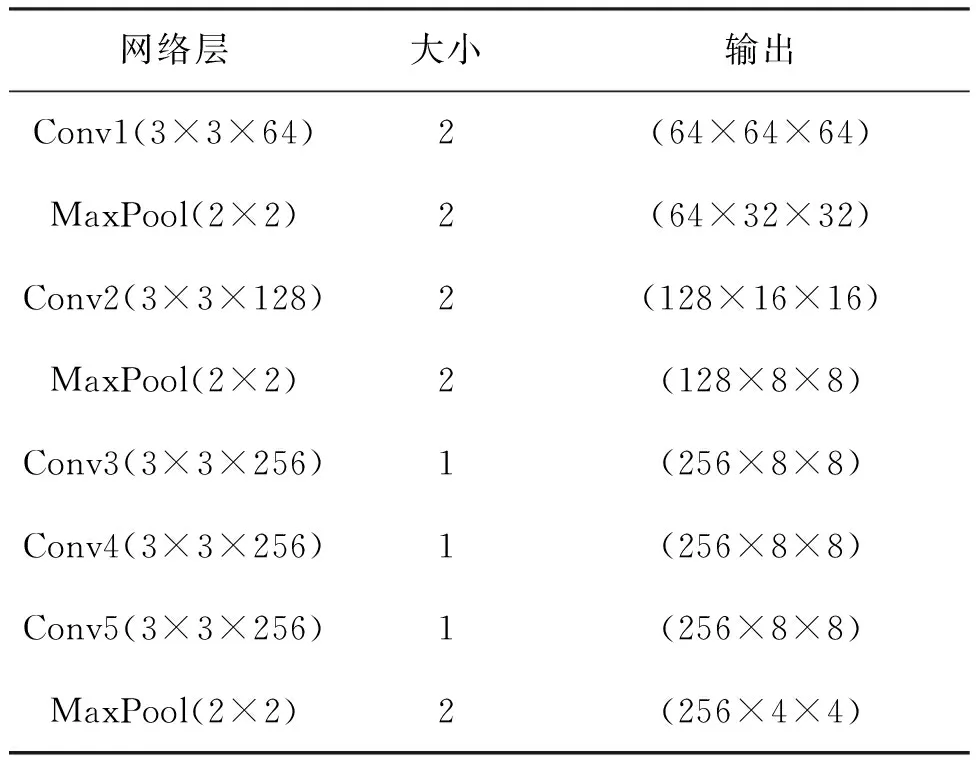
表2 多任务CNN网络配置
(11)
式中θj为输出节点j的权重参数.进一步,对上式执行归一化操作,则每个类别分类的概率
(12)
式中,K为输出类别的数量;P(y=j|x)为每个类别分类的概率,且有P(y=j|x)∈[0,1].最终,输出类别是分类概率最高的类别,即

(13)
式中f(x)为输出.
2.2 网络损失函数
考虑到网络执行两个任务,且不同任务可能不会同时收敛,为此,设计的损失函数为
Lt=α1Le+α2Lg,
(14)
(15)
(16)
式中Le和Lg分别为情绪和语音分类任务损失;α1和α2为不同任务权重;K1和K2分别表示两个任务分类的数量;y表示样本;P为预测概率.
2.3 集成学习模型
考虑到语音和面部表情中基本分类器的多样性,建立了一个集成学习模型,使用多种算法对模型进行融合[15].模型主要由两层组成:第一层为传统训练层,包括许多基本分类器;第二层是将基本分类器的输出重新组合到新的训练集中,从而训练更高级别的分类器.在训练第二层分类器时,将基础分类器的输出作为输入,对基础分类器的输出进行集成.集成学习过程如图3所示,其中C1,C2,…,Cm为第一层的分类器,E1,E2,…,Ej为第二层分类器,并采用logistic回归输出最终分类.

图3 集成学习过程
首先,将原始训练数据集按一定比例划分为训练数据集和测试数据集,其中训练数据集的比例约为60%-80%.然后,基于基础分类器C1,C2,…,Cm对训练集进行学习.模型训练后,预测结果为P1,P2,…,Pm.然后将每个预测结果序列视为一个新的特征,将其作为输入代入第二层集成学习模型.最后,利用logistic回归构造一个新的分类器对这些新特征进行训练,得到最终的识别结果.
3 仿真与分析
3.1 数据集与仿真环境
使用的数据集为eNTERFACE视听情感数据集,该数据集包含来自14个不同国籍的42个受试者(81%的受访者为男性,19%为女性;31%戴眼镜,17%的受试者留胡子)总共1 166个视频序列,实验者要求在用英语表达选定的句子时表现出六种基本情绪,即:愤怒、厌恶、恐惧、快乐、悲伤和惊讶.
模型使用python3.7编写主程序,并基于PyTorch搭建深度学习网络;深度学习网络运行在操作系统为ubuntu 18.04的联想服务器,CPU为英特尔i7-12700F,2.1 GHz,内存32 GB,显卡为NVIDIA RTX1080Ti,11 G.网络训练时,权重更新优化方法采用随机梯度下降(Stochastic Gradient Descent,SGD)算法,且初始学习率设置为0.001.此外,动量、权重衰减和批处理大小分别设置为0.9、0.000 5和32.同时,为了避免过度拟合,网络中采用了dropout策略,概率设置为0.2.面部特征提取网络中,LSTM的隐藏层和隐藏层节点数分别设置为2和128.
3.2 训练结果分析
表3所示为所提多任务CNN网络模型准确率、召回率和F1分数的实验结果.从表中可以看出,“快乐”和“惊讶”的识别准确率最高,分别为0.986 3和0.975 6;“恐惧”和“厌恶”相对难以区分,而且很容易错误分类,识别准确率较低,主要是因为缺乏这些典型面部表情的训练样本.图4所示为所提网络的受试者工作特征(Receive Operating Characteristic,ROC)曲线,从中可以看出所提模型取得了良好的性能,平均ROC曲线下面积(Area Under Curve,AUC)为0.973 9.
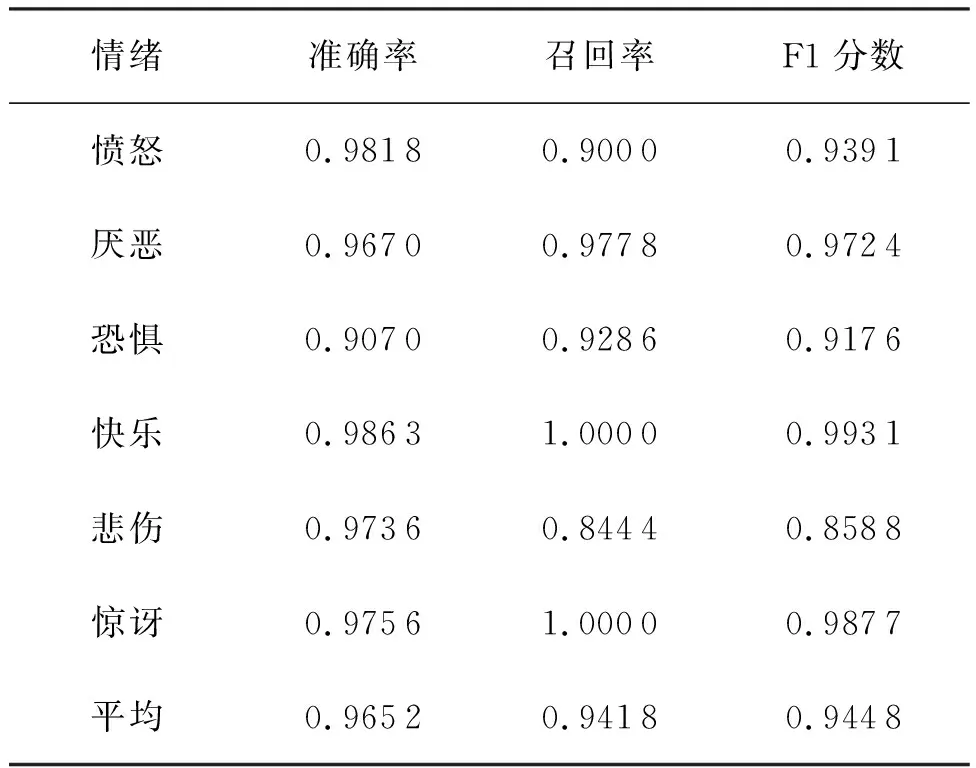
表3 多任务CNN网络准确率、召回率和F1分数的实验结果

3.3 对比分析
将所提多任务CNN网络模型与其他主流方法进行对比实验,平均准确率比较结果如表4所示.SVM和神经网络为传统计算智能方法,准确率最低.深度学习网络模型中,ResNet、VGG19和集成学习模型性能有所提升.多任务CNN模型性能最高,平均识别准确率为0.965 2,较ResNet、VGG19和集成学习模型分别提升10.14%、9.09%和4.89%.实验结果表明,所提模型可以有效地提高多模态情绪识别的性能.

表4 平均准确率比较结果
4 结语
基于神经网络模型对音视频情绪识别进行了研究与分析,提出了一种多任务CNN网络模型,从而提高单模态识别模型对用户情绪的敏感性.通过实验验证,所提多任务CNN网络可以有效提升多模态情绪识别的性能.
猜你喜欢
应用心理学(2022年5期)2022-11-05
电子产品世界(2022年4期)2022-04-21
北京大学学报(自然科学版)(2022年1期)2022-02-21
现代信息科技(2021年21期)2021-05-07
计算机系统应用(2021年2期)2021-02-23
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
电子技术与软件工程(2017年14期)2017-09-08
