
并行程序中同步瓶颈的检测和优化方法*
2022-10-04 12:46李柳旭
国防科技大学学报 2022年5期
张 杨,李柳旭
(河北科技大学 信息科学与工程学院, 河北 石家庄 050018)
锁是并行程序中比较通用的同步控制方式之一,主要用于在并发程序中确保数据访问和程序状态的正确性。然而在多核时代锁的使用容易导致锁竞争问题,该问题是由多个线程同时竞争临界区资源引起的,如果一个线程获得了锁,那么其他想获取该锁的线程都将被阻塞,直到持有该锁的线程释放锁。由于锁竞争会使多核处理器中只有一个处理核处于运行状态,其他处理核只能等待,严重降低并行程序性能。目前关于锁竞争的研究有很多,例如,Schörgenhumer等[1]通过JVMTI和字节码检测工具来收集有关Java应用程序中锁竞争的详细信息;Patros等[2]通过修改Java虚拟机记录线程驻留时锁竞争的数据信息;Zheng等[3]通过记录程序执行并且跟踪分析来识别不必要的锁竞争;Feng等[4]在程序运行时动态检测操作系统在Java应用程序上引起的锁竞争。
不恰当的同步控制会进一步加剧锁竞争,导致程序性能下降。为此,Rinard等[5]介绍了自适应复制技术,自动消除在对象上执行原子操作的多线程程序中的同步瓶颈。目前还有一些研究通过性能指标来识别性能瓶颈[6-7]。Free Lunch[8]工具通过计算线程在某个时间间隔内获取锁花费的时间百分比检测由锁导致的性能瓶颈。
很多学者对并行程序性能分析进行了研究。Trahay[9]在运行应用程序时收集数据,设计方法来检测OpenMP应用程序中的可伸缩性问题。Selakovic等[10]通过静态模式匹配性能问题。Kroening等[11]提出了针对C/Pthread的静态死锁分析,识别与死锁分析有关的语句,但静态分析有时存在误报率较高的缺陷。Zhang等开发的框架VarCatcher[12]使用并行特征向量来分析结果,通过查看不同的执行模式,在多个运行中查找多个程序执行之间会出现性能差异的地方。QURO[13]是一个查询感知的编译器,它可以基于锁竞争自动在事务代码内对查询进行重新排序,同时保留程序语义以提高性能。Cicirelli[14]用Max-Plus函数证明了在局部同步情况下效率存在一个非零下限,相对于全局同步具有一定优势。有一些研究[15-16]利用分散的锁管理器来实现高性能,NetLock[17]是新的集中式锁管理器,在不牺牲策略支持灵活性的情况下实现高性能。WAIT[18]工具为了测量锁的使用情况,对获取锁时被阻塞的线程数进行统计。GAPP[19]工具无须通过检查源码就可识别并行程序中的一系列瓶颈。Tallent等[7]提出并评估了3种锁竞争问题,分析了锁竞争导致的性能损失。然而,目前研究在检测性能瓶颈的同时未进一步提出优化建议。
关于针对并发程序的优化,Diniz等[20]对同一锁上过于频繁的同步进行粗化,以减少锁开销。Zhang等[21]将内置监视器转换为StampedLock,通过细化锁的方式减轻锁竞争的影响。Curtsinger等[22]使用因果分析方法来识别具有优化机会的代码。Yu等[23]提出了基于跟踪的动态方法来识别一般性能问题,并拆分锁来提升性能。Arbel等[24]提出了一个用于并发数据结构的代码转换方法,它在不牺牲正确性的情况下提高程序的可伸缩性。
从目前的研究现状来看,锁导致的性能瓶颈检测研究仍存在以下问题:①已有方法采用单一静态分析或动态分析,然而静态分析导致误报率较高,动态分析虽然可以增加准确性,但会导致检测时间显著增加,目前还没有采用动静结合的方法来检测同步瓶颈;②对于锁导致的性能瓶颈认识不清,对于如何检测锁导致的性能缺陷还需要进一步研究;③已有的方法虽然检测了性能瓶颈,但需要对这些性能瓶颈提出进一步优化建议。
针对目前研究存在的问题,本文提出了同步瓶颈检测和优化方法,该方法针对并行程序中锁相关代码,采用动静结合分析技术分析同步依赖关系,构建同步依赖图。通过增加程序工作负载,监测同步依赖图中所有临界区的变化来检测同步瓶颈。
1 研究动机
在并行程序中,只有一个线程处于运行状态,其他线程处于空闲状态。若临界区中存在耗时且不必要的同步操作,增加程序工作负载后,临界区执行时间增加,加剧锁竞争。这里以Apache的Xalan[25]工具中的releaseXMLReader()方法为例说明锁导致的性能瓶颈问题。该方法首先判断阅读管理器是否为空,若不为空则调用XMLReaderManager类中的releaseXMLReader()方法释放阅读器。该方法的执行情况如图1所示,图1(a)表示该方法增加工作负载之前的执行情况,可以看出线程1首先获得锁L1进入临界区CS1,当线程1释放该锁后线程2、线程3、线程4和线程5依次获取锁L1进入临界区CS1,虚线表示等待时间。图1(b)为增加程序工作负载后该方法的执行情况,可以看出在增加程序工作负载后,在每次临界区执行完之后会有1 ms的空闲,这可能是由于该方法中判断阅读管理器是否为空是读操作,使用同步锁导致程序的等待,加剧了其他4个线程竞争临界区CS1资源的情况。
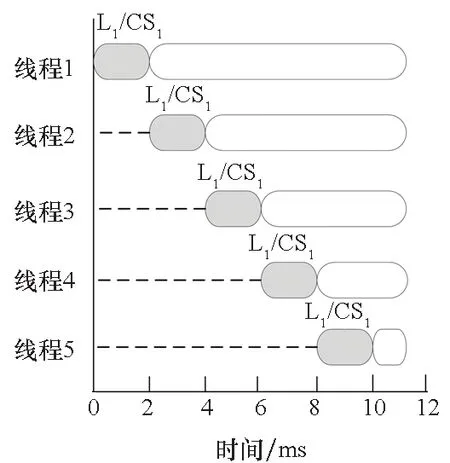
(a) 增加负载前(a) Before increasing the load
2 检测和优化框架
本节首先给出了方法的整体框架,然后对框架中的每个部分进行详细介绍。
2.1 方法框架
检测和优化并发程序中同步瓶颈的方法IdeSync。该方法首先进行静态同步依赖分析,使用控制流分析生成源程序对应的控制流图,再通过访问者模式分析遍历控制流图,检测源程序中的同步代码块和同步方法。考虑到同一个锁对象可能存在别名现象,使用别名分析找到存在别名的锁对象,增加静态同步依赖关系的准确性。在静态同步依赖关系的基础上结合程序执行路径进行动态同步依赖分析。通过增加程序的工作负载,在程序执行过程中监测同步依赖图中所有临界区的变化,检测同步瓶颈。最后针对发现的同步瓶颈提出优化建议,并通过重构程序进行优化,方法框架如图2所示。
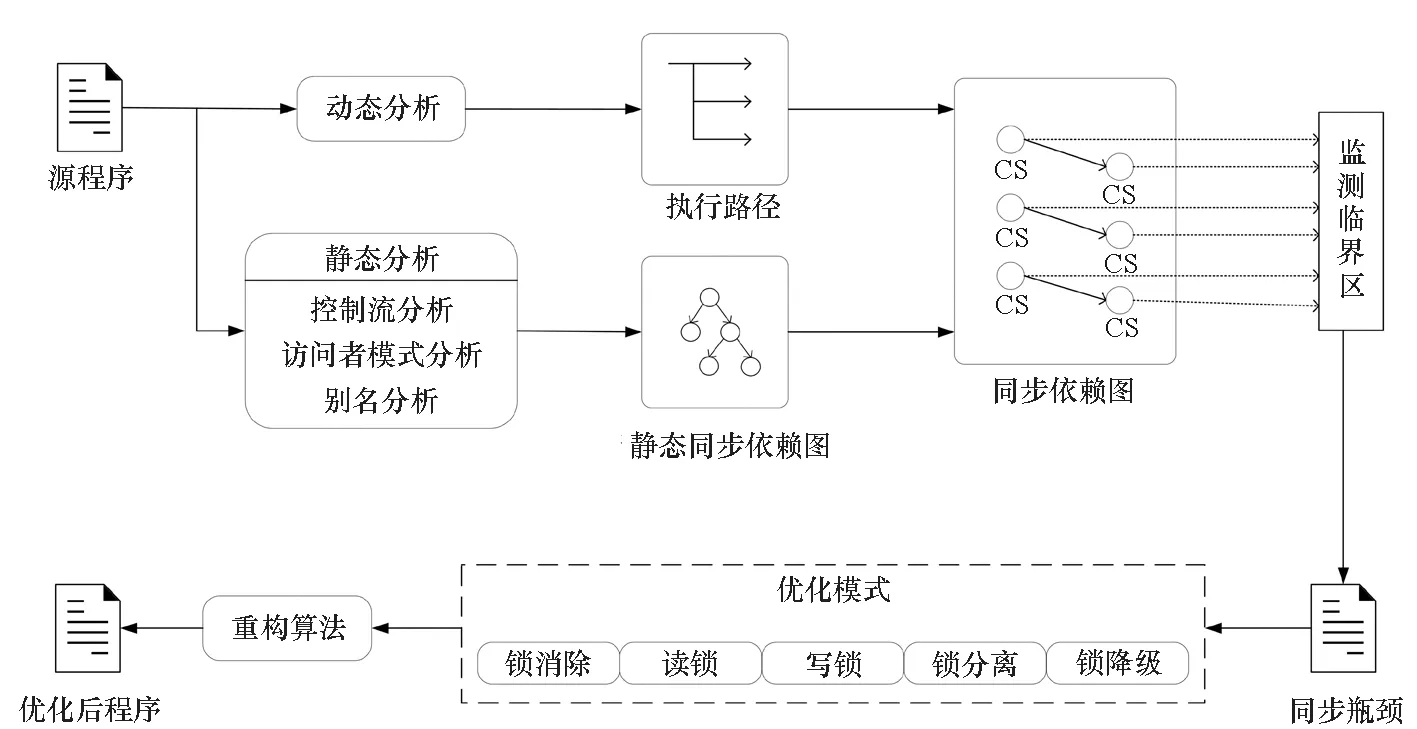
图2 IdeSync方法框架Fig.2 Framework of IdeSync
2.2 动静结合同步依赖关系分析
本节采用动静结合分析技术分析同步依赖关系,构建同步依赖图,采用动静结合分析技术增加了静态分析同步依赖关系的准确性,同时也降低了动态分析同步依赖关系的分析时间。
2.2.1 静态同步依赖关系分析
在源码的基础上使用控制流分析、访问者模式分析和别名分析静态分析方法。通过控制流分析生成有向控制流图,控制流图上包含程序执行的节点,其中包含监视器的进入和退出指令,同步代码块的开始是监视器的入口指令MonitorEnter,同步代码块的结束是监视器的出口指令MonitorExit。然后,使用访问者模式遍历源码,检测被synchronized修饰的同步方法,如果该方法是静态同步方法,则监视器对象是当前类的对象,如果该方法是同步方法,则监视器对象是当前类的实例对象。主要分析了以下4种同步依赖关系:同步方法之间存在调用关系;同步方法中存在同步块;同步块之间存在嵌套关系;同步块中调用同步方法。
同步依赖图T=(P,S),P为结点,S为边。P={P1,P2,…,Pn},Pi表示源程序中的同步方法或同步块,其中1≤i≤n。S={Pi→Pj},表示Pi为Pj的父结点,Pj依赖于Pi。构建静态同步依赖图的算法如算法1所示。首先生成临界区对应的中间表示IR,然后通过IR生成对应的指令集Ins,对每一条指令i进行遍历,调用buildGraph()方法构建同步依赖图(行1~4)。如果指令i为方法调用指令,则对该临界区指令集Ins1中的指令i1进行遍历;若指令i1为MonitorEnter指令,说明同步方法中存在同步块,则添加结点PM1、PB1和边S={PM1→PB1}(行9~10);若指令i1为方法调用指令,说明同步方法中调用了同步方法,则添加结点PM2、PM3和边S={PM2→PM3}(行11~12);若指令i为MonitorEnter指令,则对该临界区指令集Ins2中的指令i2进行遍历;若指令i2为方法调用指令,说明同步块中存在同步方法,则添加结点PB4、PM4和边S={PB4→PM4}(行18~19);若指令i2为MonitorEnter指令,说明同步块中存在同步块,则添加结点PB5、PB6和边S={PB5→PB6}(行20~21)。被关键字synchronized修饰的同步方法和同步块都持有相应的锁对象,可能存在锁对象不同但指向同一内存地址,因此需要进行别名分析,增加同步依赖分析的准确性。

算法1 构建静态同步依赖图
以SPECjbb2005中primeWithDummyData()方法为例,部分静态同步依赖情况如图3所示,图中每个结点与该结点的子结点存在同步依赖关系,序号1~19代表图中的19个结点。从图3中可以看出,多个节点之间存在相关的依赖关系,而且节点2对节点7和8都存在依赖关系。
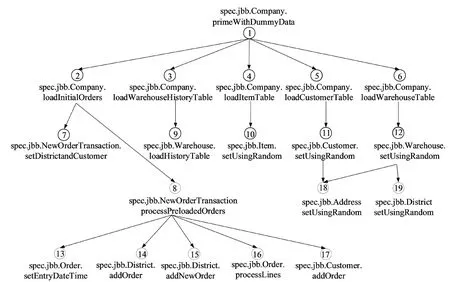
图3 静态同步依赖图Fig.3 Static synchronization dependency graph
2.2.2 动态同步依赖关系分析
对于给定的一个测试用例,使用动态分析获取程序的执行路径,使用JProfiler提供的API生成可记录的信息进行分析。首先为执行路径中出现的临界区创建节点,对存在等待关系的临界区添加边,用虚线表示;然后结合静态同步依赖图,判断执行路径中的临界区之间是否存在静态依赖关系,若有则添加边,用实线表示;最后删除执行路径中不存在等待关系和静态依赖关系的节点。
图4为SPECjbb2005的部分同步依赖图,图中的CS2对应图3中的primeWithDummyData()方法,CS3对应图3中loadInitialOrders()方法,由于CS2和CS3存在静态依赖关系,因此添加实线边,线程1中的CS1和线程2中的CS1之间的虚线表示存在等待关系。

图4 部分同步依赖图Fig.4 Partial synchronization dependency graph
2.3 监测临界区
在依赖图的基础上,对临界区的执行进行监控。首先,给定一个测试用例以及测试用例的一组工作负载W={W1,W2,…,Wn},以不同的工作负载执行程序监测临界区在不同工作负载下执行时间、临界区等待时间和CPU使用率的变化。需要监测同步依赖图中出现的临界区,并考虑同步依赖图中临界区之间的同步依赖关系来确定同步瓶颈。静态分析可以尽可能发现全部临界区,动态分析需要根据特定的执行路径,会暴露某些执行路径上的执行情况。
判断增加工作负载后程序中的临界区是否满足以下3个条件,判定该临界区是否为同步瓶颈。①临界区执行时间明显增加;②临界区的CPU使用率稳定;③临界区增加额外等待时间。
随着工作负载的增加,临界区执行时间通常也会增加。当增加工作负载后,如果临界区执行时间明显增加但CPU使用率稳定,则该临界区可能存在性能问题。然后,判断该临界区是否增加额外等待时间。将增加额外等待时间定义为:工作负载分别为W1和W2时,因竞争临界区资源增加的等待时间。结合同步等待关系发现同步瓶颈,此外需要根据同步依赖图中临界区之间的静态同步依赖关系进一步确定判定为同步瓶颈。例如,增加工作负载后,若图4中在CS2与CS3处增加的额外等待时间相同,则认为CS2增加的额外等待时间是由与其存在静态依赖关系的CS3导致的,因此,判定CS2不是同步瓶颈,CS3是同步瓶颈。
2.4 优化
以实现程序最大并行度为原则,对同步瓶颈进行优化。同步锁为互斥锁,读写锁可以提供比互斥锁更好的并行性。首先考虑对不必要的同步进行锁消除来缓解开销,然后对无法进行锁消除的同步瓶颈采用粗粒度的读写锁,即读锁、写锁和锁分解,替换同步锁增加程序的并行度,并在必要时添加细粒度的读写锁来缓解同步瓶颈,即锁降级。因此,使用5种同步瓶颈优化模式:锁消除、读锁、写锁、锁分解和锁降级。
1)锁消除:同步依赖图中一条边连接的两个临界区内均只存在读操作。
2)读锁:临界区内只包含读操作。
3)写锁:临界区内只包含写操作。
4)锁分解:临界区内不存在if判断语句,但同时存在读操作和写操作。
5)锁降级:临界区内只存在一个if语句且if语句最后有写操作和至少一个读操作。
负面效应分析用于分析临界区并生成读写字符序列,R代表读操作,W代表写操作,如果操作、方法或表达式修改了其本地环境之外的状态,会产生负面效应。遍历指令集中的每条指令,判断临界区内是否有写指令,若有则返回W,否则返回R,输出临界区的读写字符序列。根据读写字符序列确定同步瓶颈优化模式并进行重构,具体实现算法如算法2所示。首先输入同步依赖图中一条边连接的两个临界区:如果两个临界区为两个不同的临界区,则判断两个临界区内是否只存在读操作,若是,则消除后者的同步锁(行1~4);如果两个临界区表示同一个临界区,则调用refactor()方法分析两个临界区的读写字符序列(行5~7),若输入为图4线程1中的CS1和线程2中的CS1,则只需分析一次CS1的读写字符序列即可。获取临界区内if条件判断语句的数量(行9~15),如果临界区内不存在if语句,当临界区的读写字符序列为RW或WR时,将同步锁分解为读锁和写锁(行17~18),当临界区的读写字符序列为R时,将同步锁替换为读锁(行19~20),当临界区的读写字符序列为W时,将同步锁替换为写锁(行21~22)。如果临界区内存在一个if条件判断语句且if语句最后有写操作和至少一个读操作时,将进行锁降级(行24~25)。如果临界区不满足上述所有条件,则使用写锁(行26)。

算法2 重构算法
3 实验评估
本节对提出的检测方法IdeSync进行评估,首先对实验环境配置和选取的应用程序进行介绍,然后给出实验结果,并对结果进行分析。
3.1 环境配置
所有实验都在配有2.30 GHz英特尔酷睿i5 CPU和4 GB RAM的笔记本电脑上进行,操作系统使用64位Windows10系统,安装了JDK 1.8.0_271、Eclipse 4.13.0、WALA 1.5.3[26]和JProfiler 11.1.4[27]。
3.2 研究问题
RQ1:使用IdeSync方法,是否可以有效发现每个应用程序中的同步瓶颈?
RQ2:检测到的同步瓶颈在5个优化模式中的分布情况如何?
RQ3:同步瓶颈优化后的程序性能是否有所提升?
3.3 应用程序
选取的应用程序包括HSQLDB[28]、Jenkins[29]、JGroups[30]、SPECjbb2005[31]、Xalan[25]、RxJava[32]、Antlr[33]、Fop[34]、Kafka[35]、MINA[36]、Cassandra[37]和Jmeter-plugins[38]。HSQLDB是开源的Java数据库,Jenkins是一个开源的自动化服务器,SPECjbb2005是Java应用服务器测试程序,JGroups是群组通信工具,Xalan和Fop分别是Apache公司的XSLT转换处理器和格式化对象处理器,RxJava是Netflix公司的在Java VM上使用可观测的序列来组成异步的、基于事件的程序的库,Antlr是一个解析器生成器,Kafka是由Apache软件基金会开发的开源流处理平台,MINA是Apache公司的网络应用框架,Cassandra是Apache公司的开源分布式NoSQL数据库系统,Jmeter-plugins是Apache JMeter工具的一组独立插件。这些应用程序的版本号信息、源代码行数、同步方法和同步块数量见表1。

表1 应用程序及其配置
为了暴露同步瓶颈,针对不同应用程序选择了不同的工作负载。对于HSQLDB应用程序,通过增加客户数增加工作负载,分别为10、20、30、40;对于Jenkins应用程序,通过增加转移作业的数量增加工作负载,分别为50、100和150;对于SPECjbb2005应用程序,通过增加线程数增加工作负载,分别为1、2、3、4、5、6、7、8;对于JGroups应用程序,通过增加邮件数量增加工作负载,分别为1×106、2×106、3×106;对于Xalan应用程序,通过增加XML文档的数量增加工作负载,分别为1 000、1 500、2 000;对于RxJava应用程序,通过增加测试基准测试的数量增加工作负载,分别为12、24、36、47;对于Antlr应用程序,通过增加测试使用旧的和新的unicode流机制对某些unicode字形进行lex的速度的数量增加工作负载,分别为400、600、800;对于Fop应用程序,通过增加复制测试文件的数量增加工作负载,分别为100、200、300;对于Kafka应用程序,通过增加打印转换文档的数量增加工作负载,分别为20、40、60;对于MINA应用程序,通过向服务器发送消息的数量增加程序的工作负载,分别为1 000、2 000、4 000;对于Cassandra应用程序,通过增加忙碌的工作线程数量增加程序的工作负载,分别为1、2、3、4、5、6、7、8;对于Jmeter-plugins应用程序,通过增加循环的次数增加程序的工作负载,分别为20、40、60。
3.4 实验结果及分析
3.4.1 RQ1的评估
为了回答RQ1,对选取的12个应用程序中同步锁数量、同步瓶颈数量以及同步瓶颈所占同步锁的百分比进行了统计,如表2所示。从实验数据中可以看出,在12个应用程序中共检测到了72个同步瓶颈,有50个同步瓶颈主要分布在HSQLDB、SPECjbb2005和JGroups中,SPECjbb2005中存在的同步瓶颈数量最多,同步瓶颈百分比为13.2%;在MINA中只发现了1个同步瓶颈,但由于该程序中的同步锁数量较少,同步瓶颈所占的百分比高达8.3%,其次是在SPECjbb2005和Antlr中;在RxJava和Fop中同步锁数量比较少,因此共发现了3个同步瓶颈;虽然Kafka、Jenkins和Cassandra中的同步锁数量较多,但是在Kafka中只存在6个同步瓶颈,Cassandra中只存在2个同步瓶颈,Jenkins中未发现同步瓶颈。

表2 同步瓶颈情况
3.4.2 RQ2的评估
为了回答RQ2,对满足5个优化模式的同步瓶颈进行了统计,如表3所示。第3~7列分别为5种优化模式对应的同步瓶颈数量。从应用程序角度可以看出,只有HSQLDB、SPECjbb2005和Xalan中存在锁消除的情况;HSQLDB和SPECjbb2005中同步瓶颈数量较多,这两个应用程序中的同步瓶颈涵盖了5种优化模式;JGroups中同步瓶颈数量相对较多,但没有建议进行锁消除和锁分解的同步瓶颈;在Xalan和Kafka中均包含6个同步瓶颈,Xalan中没有建议进行锁分解的同步瓶颈,Kafka中没有建议进行锁消除的同步瓶颈;Fop和MINA中都只有1个同步瓶颈且均建议使用读锁;Antlr中的两个同步瓶颈均建议进行锁降级。从优化模式角度可以看出,检测到的72个同步瓶颈中建议进行锁消除的只有5个;有24个建议使用读锁,有4个建议进行锁分解,有11个建议进行锁降级,这3种优化在一定程度上都可以增加程序的并行度;建议使用写锁的有28个,其中来源于SPECjbb2005的有15个,在其他程序中建议使用写锁的情况较少。

表3 同步瓶颈在优化模式中的分布情况
将IdeSync和目前已有的重构工具ReLocker[39]进行了对比。ReLocker是一个可以在不同锁机制之间进行转换的自动重构工具, ReLocker工具在2010年被提出,只支持JDK1.6版本。计划将表1中所有程序进行两个工具对比,然而由于ReLocker版本问题,只找到了HSQLDB和Cassandra两个程序的适用版本,分别为1.8.0.10和0.4.0,由于版本差异,这两个程序中锁的数量跟表1中程序版本的数量略有不同,HSQLDB和Cassandra分别含有266个和57个同步锁。
表4给出了ReLocker和IdeSync重构结果的对比。在ReLocker中,对HSQLDB测试程序分别推荐了31个读锁和212个写锁,然而存在23个不能重构的问题;这种不能重构的问题在Cassandra中仍然存在,但数量仅有3个。相比之下,IdeSync不仅可以推断读锁和写锁,而且不存在不能重构的问题,它可以实现更为细粒度的锁重构,不仅推荐了一定数量的锁分解和锁降级,而且还推断锁消除的情况,这表明IdeSync可以更好地对锁的使用进行优化。从总体来看,IdeSync性能要优于ReLocker。

表4 ReLocker和IdeSync对比
3.4.3 RQ3的评估
为了回答RQ3,对不恰当地使用同步锁而限制了程序并行执行的同步瓶颈进行优化,并选取了HSQLDB、JGroups、SPECjbb2005和Antlr应用程序,对同步瓶颈优化前后的程序性能进行对比。
在HSQLDB程序中,同步瓶颈所在的方法分别为writeCommitStatement()、initPool()、getStore()、prepareStatement()、connect()、executeQuery()、setInt()、createStatement()、forceSync()、writeDeleteStatement()、writeRowOutToFile()、newSession()、getBundleHandle()和nextTask()。选取测试程序JDBCBench,测试优化前后事务数分别为1×105、2×105、3×105、4×105时,程序每秒处理事务的情况,结果如图5所示。从结果可以看出,随着处理事务数的增加,程序并行执行效果越明显,事务率均有不同程度的提高,分别提高了1.8%、4.8%、6.2%和8.4%。

图5 HSQLDB的性能对比Fig.5 Performance comparison in HSQLDB project
在JGroups程序中,同步瓶颈所在的方法分别为convertViews()、getThreadName()、startInfoSender()、startViewConsistencyChecker()、start()、clearViews()、addInfo()、installView()、adjustSuspectedMembers()、getNewThreadName()和addChannelListener()。选取测试程序RoundTripRpc和UnicastTestRpc,测试优化前后两个群组间消息的发送与接收能力,结果如图6所示。从结果中可以看出,优化后两个程序的请求处理率分别提高了4.8%和4.5%。
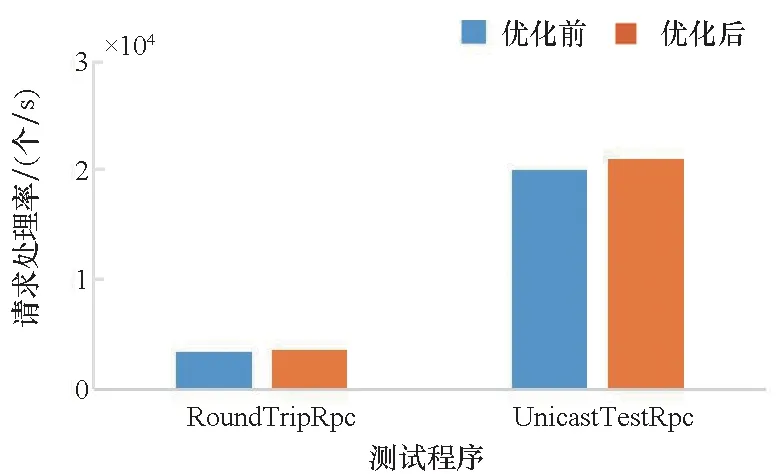
图6 JGroups的性能对比Fig.6 Performance comparison in JGroups project
在SPECjbb2005中,同步瓶颈所在的方法分别为newOrderIter()、getOrderPtr()、removeNewOrder()、addOrder()和process()等。程序优化前后的运行结果如图7所示。从结果中可以看出,在线程数为1、2和3时,优化前的堆内存使用比低于优化后的堆内存使用比,随着线程数的增加,当线程数为4、5、6、7和8时,优化后的堆内存使用比均低于优化前的堆内存使用比,分别减少了12.7%、36.9%、23.5%、1.1%和6.8%。

图7 SPECjbb2005的性能对比Fig.7 Performance comparison in SPECjbb2005 project
在Antlr中,同步瓶颈所在的方法分别为addDFAState()和addDFAEdge()。选取了测试程序TimeLexerSpeed,测试了优化前后使用旧的unicode机制对元素进行测试,结果如图8所示。从结果中可以看出,元素数为400时优化后花费的时间高于优化前花费的时间,但随着元素数量的增加,当元素数为600和800时,优化后花费的时间比优化前花费的时间均有所下降,分别缩短了2.1%和2.8%。

图8 Antlr的性能对比Fig.8 Performance comparison in Antlr project
通过对RQ3的评估,发现在SPECjbb2005程序中线程数为1、2和3时,以及在Antlr程序中元素数为400时,优化后程序性能未得到提升,这可能是由于优化后读写锁的获取和释放操作带来的开销所导致的,当程序线程任务或负载较小时,优化操作所需的开销高于优化效果。
3.5 有效性威胁
本节对实验过程中威胁有效性的几个因素进行了讨论:
1)由于并发程序执行的不确定性,性能测试的实验数据可能在一定范围内上下浮动。为了确保实验数据的有效性,所有实验结果都是在10次运行的基础上取平均值得到的。
2)本实验只选取了12个应用程序进行了评估,它们并不能代表所有程序。为了缓解这个有效性威胁,尽量选用涉及数据库、服务器等多个领域的程序。
4 结论
本文提出了检测和优化同步瓶颈的方法IdeSync。该方法首先使用静态分析方法检测程序源码中的同步方法和同步块,采用动静结合分析技术分析同步依赖关系,构建同步依赖图,增加了静态分析同步依赖关系的准确性,降低了动态分析同步依赖关系的难度。然后增加程序工作负载,监测临界区的变化检测同步瓶颈,最后针对检测到的同步瓶颈,给出优化建议,并在Eclipse JDT框架下以插件的形式实现自动优化重构工具。在实验中选取HSQLDB、SPECjbb2005和RxJava等12个大型实际应用程序验证了该方法的有效性。在接下来工作中,将使用更多的应用程序和更大规模的测试集对IdeSync方法进行验证。
猜你喜欢
现代电子技术(2022年8期)2022-04-13
云南画报(2021年8期)2021-11-13
北京航空航天大学学报(2021年6期)2021-07-20
网络安全技术与应用(2020年1期)2020-01-07
作文周刊·高二版(2019年43期)2019-01-06
专用汽车(2015年1期)2015-03-01
创业家(2015年9期)2015-02-27
科技传播(2013年22期)2013-08-15
体育师友(2012年1期)2012-03-20
计算机教育(2006年4期)2006-04-19
