
作业名层次化聚类算法预测作业运行时间*
2022-10-04 12:46周隆放杨文祥韩永国张晓蓉冯景华李宇奇吴亚东王桂娟
国防科技大学学报 2022年5期
周隆放,杨文祥,韩永国,张晓蓉,喻 杰,冯景华,张 健,李宇奇,鲜 港,吴亚东,王桂娟
(1. 中国空气动力研究与发展中心 计算空气动力研究所, 四川 绵阳 621000;2. 西南科技大学 计算机科学与技术学院, 四川 绵阳 621010; 3. 国防科技大学 计算机学院, 湖南 长沙 410073;4. 国家超级计算天津中心, 天津 300457; 5. 四川轻化工大学 计算机科学与工程学院, 四川 自贡 643000)
在高性能计算领域中,提升系统资源的使用效率长期以来是研究的热点[1-4]。提升硬件资源的使用率和优化作业的吞吐率会在很大程度上减少系统的开销[5-6]。在系统作业调度策略方面,调度策略决定着作业运行的先后次序,从而很大程度地影响着系统作业的吞吐率和资源使用效率[7-8]。传统的作业调度采用先来先服务策略,然而,在先来先服务的策略下,所有作业按照提交时间先后的顺序一次进入等待队列,不同作业请求资源的数目和运行时间都不同,当队首作业不能分配到足够数目的资源时,会等待其他作业运行完成后释放资源。
为了提升系统调度性能,短作业优先策略从等待队列中选运行时间最短的作业运行,这有利于短作业的及时运行,但容易造成长作业处于饥饿状态;时间片轮转策略给每个作业固定的运行时间但是会造成更长的平均等待时间[9];回填调度策略[10-13]在不推迟队首作业正常运行的前提下,选取运行时间最合适的作业抢占空闲资源而运行,该策略能在缩短平均等待时间的同时提升系统的吞吐量,但是作业的预计运行时间难以估计。通常,用户提交作业时会附上该作业的预计运行时间,但是实际上,许多系统的用户并没有被要求去附上作业预估时间甚至用户通常高估作业运行时间。为了回填策略的高效运行,已有大量的算法预估作业运行时间。
近几年机器学习[14-15]的快速发展对于高性能领域的作业时间预测问题有很大的推动。机器学习可以基于大量的历史作业,根据其作业的特征和作业运行时间建立一个作业的预测模型来预测新提交作业的运行时间。传统的预测方法是选取作业的部分特征放入模型中训练[16-17],比如作业的中央处理器(central processing unit, CPU)数量、提交时刻、用户名等。作业名具有作业的语义信息,对描述作业运行特征有重要意义。
聚类是机器学习中提升数据质量的方法之一。作业名由许多数字、字母和特殊符号组成,其结构较为复杂,传统的聚类算法很难将相似的作业名聚类。比如作业名的字母大小写不能区分作业名的相似程度、由相同的字母组成的作业名但字母顺序不同或者字母之间被不同的符号连接、数字仅仅表示值的大小或者时间的先后但无实际的意义。因此仅通过字符串的相似度很难将相似的作业名聚类。用户命名作业的规律:所有的作业名都由字母、特殊字符和数字三个成分组成,用户命名作业往往用字母(英文字母或者拼音或者二者的缩写)表示作业所执行的功能;特殊字符指的是下划线、横线、点和加号等,用户往往用特殊字符连接中间两部分内容,它起到结构化作业名的作用;数字往往被用户用来表示作业的参数或者时间等。根据相似作业的特点,提出字母-结构-数字(letter-structure-number,LSN)的作业名聚类算法,它总共通过三层聚类作业名:第一层是通过作业名中字母的相似程度聚类;在第一层聚类的基础上,再通过特殊字符的相似程度二次聚类;最后通过数字的相似程度聚类得到最终的作业名聚类结果。
本文采集两个超算中心2020年9月—2021年9月一年的历史作业数据,抽取数据特征,采用LSN作业名聚类算法将相似的作业聚类,采用经典的机器学习模型预测作业的运行时间,包括支持向量回归(support vector regression, SVR)、随机森林(random forest, RF)等。同时采用传统的字符串聚类方法聚类作业,并为之训练模型,通过对比预测精度来评估作业名聚类的效果。
1 相关工作
已经有很多文献提出了作业运行时间预测算法。其中文献[18]在Mira 和 Intrepid 两台超算上根据用户的提交作业的习惯和特点预测用户新提交作业的运行时间。文献[19]将作业运行时长按照长度区间离散化,然后再综合支持向量回归、贝叶斯岭回归和随机森林回归三种模型,最后通过贝叶斯分类实现运行时间的二次预测;同时该文献还基于径向基的神经网络方法预测作业运行时长。文献[20]通过自定义的特征集合,即模板,预测与之相似的作业的运行时长。文献[21]挖掘半结构的历史作业日志并用隐马尔可夫模型预测作业的剩余运行时间。文献[22]用K近邻(Knearest neighbors, KNN)算法预测作业的运行时长并且用留一法和十字交叉验证和统计学的方法为其查找相关系数。文献[23]以用户提交最近的两次作业的平均时长预测作业的运行时间。文献[24]用多项式模型提高作业运行时间预测的精度,它也是通过机器学习的方法,期望通过预测时间从而优化回填调度算法。文献[25]基于KNN算法用模板找寻相似的历史作业,并用遗传算法为模型寻找最佳的参数。文献[26]预测特定类型的应用,预测精度有一定的提升。文献[27]提出为避免异常,当预测时间严重偏离应该提醒管理员。文献[28]总结了机器学习的应用,提出了多种表征特征的方法。
作业名由用户命名,用以指征作业的特征,通常表述作业所执行的功能和运行参数等,拥有相同作业名的作业执行的功能类似,所以运行时间可能相近。文献[20]通过作业名将长短作业分离,进一步定义模板训练机器学习模型,但同一作业名下也有可能同时出现长作业和短作业。Last-2[23]算法简单高效地寻找相同历史作业名的最近两次提交的平均时间作为预测时间,但预测精度到60%后存在瓶颈。有大量的文献对数据的新特征进行探索:文献[29]在预测有关原子应用时加入原子的库伦矩阵特征从而提高特定应用的预测效果;文献[30]在输入的特征中加入作业运行的路径从而提高的预测效果。
有大量的研究将作业名按照字符串的距离[25]或者仅保留字母信息的手段将相似的作业名归类,再利用机器学习的手段预测作业的运行时间,但对于命名复杂的作业名,难以通过以上的方法将相似的作业名聚类。本文通过分析用户的命名习惯,将作业名分为三种组成成分,不同成分的聚类方式不同且成分之间的聚类顺序也不同,最后实验表明所提出的LSN聚类方法能有效地将作业名更好地聚类,从而提升了数据质量,进一步地提高了预测的精度。
2 作业时间预测框架
数据来源于两台高性能计算机器:国家超级计算天津中心(天津超算中心)和中国空气动力研究与发展中心(CARDC)。两台机器的数据都是由Slurm[31]记录的真实作业数据。数据处理流程如图1所示。

图1 实验流程概览Fig.1 Overview of experiment process
步骤1:数据预处理阶段是清洗作业日志中的脏数据,比如空值、运行时间为0的作业、Linux脚本文件等少部分对预测时间没有效果的作业,详情见表1。

表1 被过滤的作业名称
步骤2:仅仅保留作业状态为“Completed”的作业。其他状态(“Canceled”“Node_fail”“Pending”等)的作业无作业完整的生命周期,所以不考虑预测它们的运行时间。
步骤3:根据提出的LSN聚类算法聚类相似的作业名。
步骤4:过滤小量作业的用户,因为机器学习模型的良好性能得益于大规模的训练数据。小量的作业对提升模型性能没有帮助且不预测小量作业的时间对系统的性能影响较小。
步骤5:过滤相似作业集合中的小作业集,相似作业集来源于LSN作业名聚类的结果。为了取得较为规整的作业数据,保留所有含有100条以上作业的集合。
步骤6:将过滤后的数据用于时间预测,将整体的数据按照3 ∶1的比例分成训练集和测试集,训练集训练时间预测模型,测试集用训练好的模型来预测时间。
3 LSN聚类算法
3.1 作业名的相似性
传统的时间预测方法是选取能表示作业运行的特征放入机器学习模型中训练,比如作业的CPU数量、作业提交的时刻、用户的名称、队列名称等。作业名是作业重要的特征之一,它由用户命名,并且含有作业运行的语义信息。作业名的样例如表2所示。

表2 超算中真实作业名的样例
如图2所示,集群中的作业名种类繁多,结构丰富。虽然难以归纳作业名的命名规律,但是许多作业名之间彼此相似,相似的作业往往有相似的运行时间。为提高数据的质量,可聚类拥有相似作业名的作业。

图2 作业名的样例和彼此相似的作业名Fig.2 Sample of job names and job names that are similar to each other
3.2 LSN聚类详细内容
根据集群中作业名的相似性提出LSN聚类算法,目的是将相似的作业名聚类。LSN聚类的流程如图3所示。LSN算法由字母聚类、结构聚类和数字聚类三个聚类层级组成,如算法1所示。作业名集合经过第一层字母聚类后,其中的作业名被聚合成若干个子集1;每个子集1经过第二层结构聚类后被聚合成若干个子集2;每个子集2经过第三层数字聚类后被聚合成若干个子集3。整个作业名集合经过LSN聚类后生成若干个子集3,聚类的结果输出为所有子集3的集合。

图3 LSN聚类算法Fig.3 LSN clustering algorithm
3.2.1 作业名的成分特征
作业名实际上是字符的集合,如图2所示。作业名的组成成分可被归纳为字母、数字和特殊字符。作业名的主体为字母和数字,而特殊字符连接字母序列或数字序列,凸显字母或数字序列的层次关系,起着结构化作业名这一重要作用。

算法1 LSN作业名聚类算法
作业名的相似性可归纳为字母、结构和数字这三个成分特征的相似性。因为相似作业名的成分特征极为相似,所以LSN算法以聚类作业名的成分特征为主要思想,根据各个成分的重要性,构造出字母-结构-数字的层级聚类算法。
3.2.2 LSN聚类层级1:字母聚类
因为作业名中所包含的语义信息很大程度上来源于字母,所以LSN层级聚类的第一层为字母聚类。字母聚类的流程如图4所示。首先仅保留作业名中的英文字母,紧接着统一大小写,剩余的字母序列为该作业名的特征,最后将含有相同特征的作业名聚合为一类得到若干个图3中的子集1。字母聚类能聚合具有一定相似度的作业名,并且在CARDC的数据集中取得了较好的聚类效果。作业名中包含的字母个数越多,字母聚类的效果就越好,但是当作业名中字母个数较少甚至没有字母的时候,子集1内容易存在大量互不相似的作业名。如表3所示,含有相同的字母在结构上或者参数类别上有较大的差异。

图4 字母聚类流程Fig.4 Letter clustering algorithm flowchart

表3 作业名的字母聚类算法的结果
3.2.3 LSN聚类层级2:结构聚类
LSN聚类的第二层是结构聚类,因为作业名中含有结构化的语义信息。作业名集群中含有的特殊字符如表4所示,其中被标红字符常被用户用来连接字母或数字序列,包括“+”“=”“-”“_”和空格(称之为结构字符)。LSN中由此提出“结构聚类”的概念,因为在拥有相同的字母特征的作业名集合里,作业名之间仍然存在明显的差异,这个差异主要来源于作业名的命名结构,如表5所示,这9个作业名经过字母聚类后属于3个类别,但每一类的内部作业彼此之间结构不同又可以进一步细分成更小子集。结构聚类的方法是将每个字母聚类子集里的作业名以结构字符分节分成若干小节,若小节之间的连接方式相同,则聚为一类。连接方式的相同包括结构字符的数量相同、种类相同、顺序相同。

表4 作业名的字符组成

表5 有着不同结构的相似作业名
如图3所示,每个子集1在结构聚类层级上聚类分成若干个子集2。经过结构聚类后,字母量较少的相似作业名在结构聚类层级能被较好地聚类。但在无字母的作业名集合中,每个子集2仍然包含相互之间存在明显差异的作业名。因此LSN针对无字母的作业集合,附加额外的聚类层级——数字聚类。
3.2.4 LSN聚类层级3:数字聚类
LSN聚类的第三层级是数字聚类。作业名集合中含有大量的无字母的作业名,该类作业仅仅由数字和特殊字符组成。由于字母不能为该类作业提供丰富的语义信息,LSN将该类作业名在结构聚类后附加数字聚类。在结构聚类层级上,每个作业名被结构字符分割成若干个子节,LSN抽去子节中的非结构特殊字符(“.”除外),所有的子节由数字组成。由于数字的差异无实际意义,因此LSN将数字归类。数字可归为4个类别——小数、自然数、编号、长序列,如表6所示。LSN判别小数的依据是子节带有“.”;判别编号的依据是子节以0开头并且长度大于2;若非0开头但是字符长度大于3,则属于长序列类别,并且不同的子节长度对应不同的长序列子类别,此时日期就被分为长序列中的四位数的类别,比如2020;最后LSN将不属于上述所有类别的数字类型归为自然数类别。LSN将每个子节的数字类别都相同的作业名聚类,如图3所示,每个子集2在数字聚类层级上聚类为若干个子集3。
若字母仅存在作业名的后缀中,该类作业同样也无语义信息,将后缀名为“.sh”和“.txt”类型的作业名也纳入数字聚类。

表6 数字类别
3.3 聚类结果评估
与传统的聚类算法对比,LSN算法具有较强的作业名聚类效果。分别以近邻传播(affinity propagation, AP)聚类算法和最大相似长度聚类算法与LSN聚类算法进行对比验证。
3.3.1 AP传播聚类算法
AP传播算法无须先指定类别的数量,从而达到自动化聚类的效果[32]。它将样本中所有的数据点视为潜在的聚类中心,在表示样本之间相互距离的矩阵中,对角线上的值越大,则对应该位置的样本就越有可能成为聚类的中心。AP算法迭代所有的点,判断该点和中心点的吸引度、归属度,直到产生所有的高质量的聚类中心停止。采用字符串之间的编辑距离表示两个作业名之间的相似度,距离越大相似度越低。
AP算法聚类作业名后,每个类别的作业名称都较为相似,但是类别的数量过多且相似的作业名分散在不同的类别里,如表7所示。AP算法的聚类效果较差。

表7 AP算法聚类结果
3.3.2 最大相似长度聚类算法
相似的作业名之间包含相同的子字符串,如表8所示。最长公共子序列[33](longest common sequence, LCS)可衡量两个作业名的相似度。

表8 含有公共子序列的作业名集合
由于作业名的长短差异很大,相似的短作业名的公共子序列也较短。因此用公共子序列的长度与作业名的总长度的比值来判断相似。作业名之间若含有公共子序列并且子序列的长度超过各自作业总长度的75%则聚为一类。
LCS聚类结果与AP聚类算法相比有明显的改善,类别的数量有明显的减少,并且每类别的作业名都有公共的子序列。聚类的效果如表9所示。虽然每个类别的作业名都有公共的子序列,但是每个类别的作业名的相似程度有所降低。

表9 LCS聚类结果
3.3.3 LSN算法聚类结果
LSN聚类算法由字母聚类、结构聚类、数字聚类三个层级组成。聚类结果如表10所示。虽然不同类别的作业名之间存在一定的相似性,但是同一类别下的作业名相似度极高。
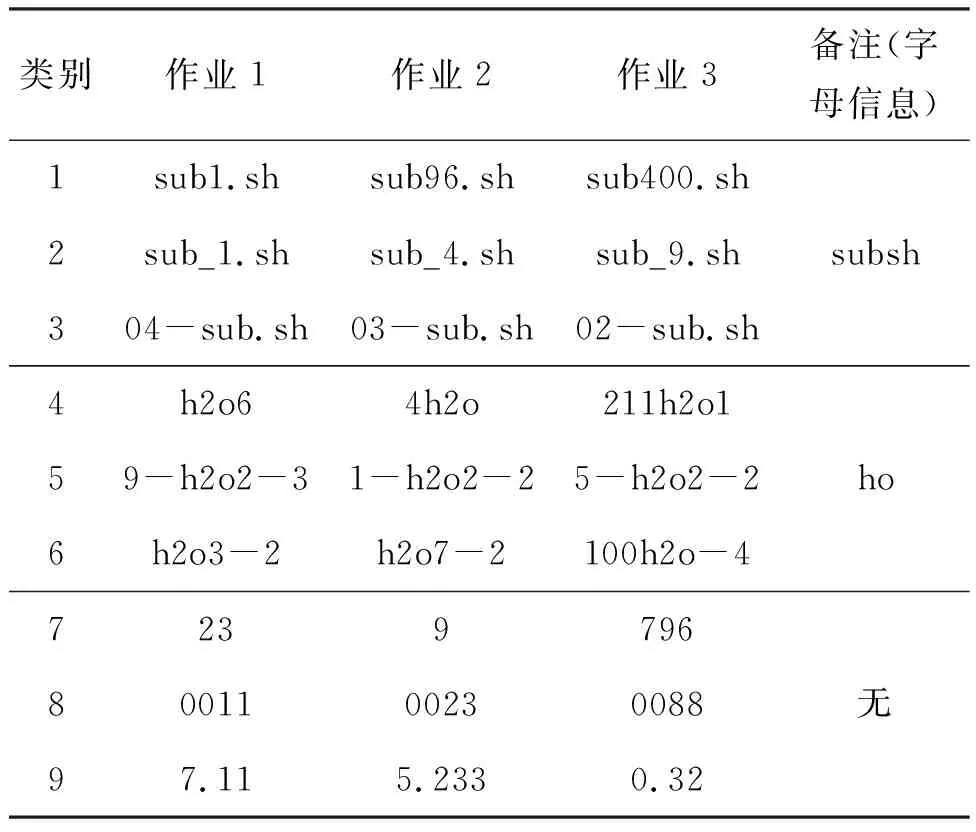
表10 LSN算法聚类结果
4 实验结果与分析
4.1 实验流程和评估方法
本实验从CARDC的机器得到的历史数据集一共57 064条,从天津超算中心得到的数据集一共67 821条。只保留完成状态的作业,经过作业状态和作业名的筛选后,CARDC数据集中共有有效数据53 332条以及2 000余种作业名,天津超算中心数据集共有有效数据62 073条以及7 285种作业名。将以上两个有效作业数据集合作为实验的输入。经过LSN聚类后,每个作业名都对应一个所属类别的编号。将用户名和作业名类号进行哈希编码。
由于机器学习模型只接受数值型的输入字段,因此在输入的作业字段中,用UID代替用户名;相对时间戳代替作业提交时刻,其计算方法如式(1)所示;作业名所属聚类编号代替作业名;用户所申请的CPU字段表示CPU数量,因为用户申请的CPU数目实际上是申请的核数,其数值等于或者小于作业占用CPU字段的核数,因此用户申请CPU更加能准确表示作业的资源占有数目。
trelative_i=ti-min(t1,t2,…,tn)
(1)
式中,trelative_i表示相对时间,ti表示第i个作业的真实时间。
将历史作业数据集按作业提交时间的先后排序,以3 ∶1的比例分成训练集和测试集,训练集中作业的UID、提交时间、申请CPU和作业名类别作为训练特征,作业的实际运行时间作为训练的目标。以预测精度评估预测的准确性,如式(2)所示。Acc指的是预测精度,tpredict是预测的时间值,treal是该作业实际运行时间的真实值,时间单位是s,精度用百分位表示。
(2)
4.2 时间预测模型
时间预测的方法采用机器学习的经典预测模型:SVR[34]、决策树[35](decision tree, DT)和RF[36]。
SVR是一种监督机器学习方法,它在n维输入变量之间构建线性回归函数,计算综合损失函数的值,并且将特征通过核函数映射到高维空间,是非线性回归预测。
DT是一个树形的模型,它内部的节点在训练的时候根据信息熵分裂,选取基尼系数评判信息增益,是监督机器学习的经典模型之一。
RF是构造多颗决策树并且最终的输出值由多个决策树共同决定,在很多的预测算法上都体现了其优势性,其也是经典的机器学习方式之一。
4.3 预测结果
基于两台机器2020年9月—2021年9月一年的真实历史作业数据,采用同样的实验方法,包括数据预处理、作业名聚类、时间预测。以预测精度评估预测的准确性。
4.3.1 作业名有无聚类对比
将未被聚类的作业数据集和经过LSN聚类的数据集分别放入模型中训练。在CARDC的数据集中一共获得53 332条有效数据,其中近40 000条数据作为训练集,剩下的近13 000条作业作为测试集。分别用SVR、DT和RF的机器学习模型预测作业运行时间,实验结果如图5所示。在CARDC的数据中,在无作业名聚类的情况下,所有模型的预测精度在69%~79%之间;SVR模型的预测精度较低仅为69.2%,DT和RF的预测精度差距较小,都在78%左右。在LSN作业名聚类的情况下,这三个模型的预测精度均有1%~3%的提升,预测精度在71%~80%之间。

图5 CARDC的作业运行时间预测结果Fig.5 CARDC′s job running time prediction result
在天津超算中心的数据集中,一共获得了62 073条有效数据,同样以3 ∶1的比例分成近47 000条作业作为训练集、近15 000条作业作为测试集。SVR、DT和RF的模型的预测结果如图6所示。在无作业名的聚类情况下,三个机器学习模型的预测精度是62%~74%,天津超算中心的作业预测精度整体较低于CARDC的预测精度,主要原因是天津超算中心的作业种类更多、数据量大、用户多,作业的时间较难预测;经过LSN聚类后,SVR预测精度由62.8%上升至74.6%,DT预测精度由70.2%上升至75.7%,RF预测精度由73.5%上升至76.8%。相比于CARDC的数据,天津超算中心经过作业名LSN聚类后时间提升精度更大。天津超算中心的数据中含有7 000多种作业名而CARDC的数据中仅含有2 000多种作业名。天津超算中心的作业数据种类更丰富,应用LSN算法的聚类效果更明显,时间的预测精度提升更大。
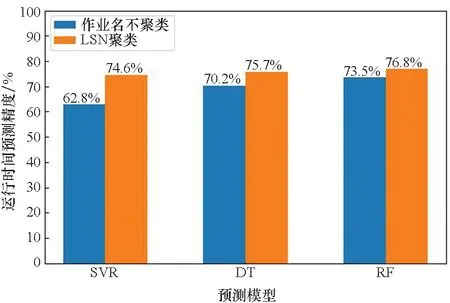
图6 天津超算中心的作业运行时间预测结果Fig.6 Job running time prediction result of Tianjin supercomputer center
在两台机器的数据集中,三个预测时间的模型里,SVR的预测精度相对低于DT和RF的预测精度,这主要是因为不同的模型训练的算法不同,SVR属于非线性回归预测,DT和RF属于分类预测。由于作业的运行时间范围差异较大,从数秒到数十万秒不等,回归算法建立所有数据之间总损失最小的超平面,因此容易在时间范围差异较大的数据集中产生与真实值偏离较大的预测值,从而降低作业时间的预测精度。分类算法的预测值从真实值中产生,因此分类预测更适用于时间范围差异大的数据集合。
4.3.2 不同聚类算法的对比
将AP聚类算法、LCS聚类算法和LSN聚类算法得出的三种聚类结果分别放入相同的模型中预测时间。CARDC的作业的三种聚类算法的预测结果如图7所示。在AP传播算法的聚类结果中,三个模型的预测精度在69%~79%;在LCS的聚类结果中,三个模型的预测精度在68%~80%;在LSN算法的聚类结果中,三个模型的预测精度在71%~80%。仍然是DT和RF算法的预测精度整体上较高于SVR,而且经过LSN聚类后的数据集的预测精度在每个模型上都高于经过其他算法聚类后的数据集,主要是由于LSN聚类的效果相对于其他聚类算法更好,数据的质量更高。
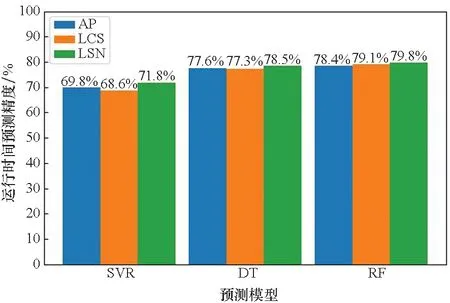
图7 CARDC作业不同聚类算法运行时间预测结果Fig.7 Runtime prediction results of different clustering algorithms for CARDC jobs
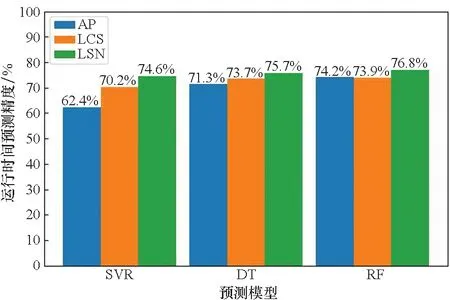
图8 天津超算中心作业不同聚类算法运行时间预测结果Fig.8 Runtime prediction results of different clustering algorithms for Tianjin supercomputer center jobs
天津超算中心的作业的三种聚类算法的预测结果如图8所示。在AP传播算法的聚类结果中,三个模型的预测精度在62%~75%之间;在LCS的聚类结果中,三个模型的预测精度在70%~74%之间;在LSN算法的聚类结果中,三个模型的预测精度在74%~77%之间。不同聚类算法对SVR的精度影响较大,对DT和RF的精度影响较小,但是聚类的质量对时间预测的准确性均有一定的影响。在每个模型中,LSN聚类算法的数据均比其他两种聚类算法的数据预测精度高,因为LSN的作业名聚类效果更好,相应的数据质量更高。于是采取基于LSN聚类算法的分类模型预测的结果作为时间预测的最终结果,即79.8%的平均精度。
4.3.3 LSN聚类的特征重要性对比
DT模型的训练过程是通过基尼系数判断信息增益最大的特征,分裂新的分支而形成的一个树形结构的预测模型。分裂次数多的特征在整个决策树模型的构建过程中起到了相对重要的作用。对比DT模型下的各个特征在LSN聚类前后的重要性。如图9(a)所示,在CARDC的数据中提交时间特征的重要性达到91.5%,作业名的重要性仅为2.7%。如图9(b)所示,数据经过LSN聚类后,所有其他特征的重要性变化均很小但作业名特征的重要性有升高。如图10(a)所示,在天津超算中心的数据中提交时间特征重要性仍然最高,但相较于CARDC的数据其重要性降低,作业名的重要性上升为12.3%。如图10(b)所示,经过LSN聚类后作业名特征的重要性上升至15.3%,上升程度明显,因为LSN聚类的特征在模型构建过程中的贡献度有所提升。

(a) 作业名聚类前各个特征的重要性(a) Importance of each feature before job name clustering

(a) 作业名聚类前各个特征的重要性(a) Importance of each feature before job name clustering
5 结论
本文的数据来自CARDC和天津超算中心2020年的真实历史数据,通过数据清洗整理出较高质量的作业数据。为提升时间预测效果,提出LSN算法聚类作业名。该算法在CARDC和天津超算中心的作业名聚类中获得了显著的聚类效果。将预处理后的数据分别放在SVR、DT和RF的机器学习模型上训练和预测。实验证明经过作业名聚类的数据在这3个模型上都取得了时间预测精度的提升,能达到79.8%的精度。在未来的工作中将进一步改进作业名聚类算法,深入挖掘作业名包含的语义信息,关联作业名和作业运行时间,提高作业运行时间的预测精度。
猜你喜欢
一重技术(2021年5期)2022-01-18
现代装饰(2020年6期)2020-06-22
现代计算机(2018年27期)2018-10-25
电子制作(2018年11期)2018-08-04
学苑创造·B版(2017年3期)2017-05-03
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
华人时刊(2016年16期)2016-04-05
现代计算机(2016年17期)2016-02-28
职业·中旬(2009年12期)2009-06-01
