
气象科普平台下山洪地质灾害信息共享方法
2022-09-29 00:56王省,刘波,马强
自动化技术与应用 2022年9期
王 省,刘 波,马 强
(1.中国气象局气象宣传与科普中心,北京 100081;2.国家气象信息中心,北京 100081)
1 引言
山洪地质灾害是由气象条件、地质条件、地貌条件、工程活动等多种因素造成的结果,其中,气象条件是造成山洪地质灾害的关键因素。单从降水这一因素入手,发现降水分布情况与山洪地质灾害分布情况存在着紧密的联系,由此可见,气象条件是预测山洪地质灾害的主要信息[1]。通过调查研究表明,虽然山洪地质灾害由多种因素控制,存在着较大的不确定性,但是依然具有一定的规律性,与当日降水量、前期有效降水累计值均存在着密切的关系。气象科普平台以有效降水累计值、日综合雨量为指标,对山洪地质灾害进行预测,并将预测信息共享给大众,尽可能地降低山洪地质灾害带来的损失[2]。
现今,每个行业信息平台的构建与发展逐渐加快,导致数据量逐渐增加,如何对数据资源进行合理地应用成为目前时代的重点研究课题之一。王燕云等人利用比拟法建模,运用支持向量机回归拟合算法,推求无资料小流域山洪灾害临界雨量,实现了降雨量预测[3]。Zhang等人提出了一种RBF神经网络[4]。基于粗糙集构建洪水损失评估模型,并将基于神经网络的洪水损失评估模型应用于洪水损失预测工作。为了保障山洪地质灾害信息的实时共享,保障气象科普平台的顺利运行。提高传统预测方法的预测实时性,本文提出了气象科普平台下山洪地质灾害信息共享方法。
2 山洪地质灾害信息共享方法研究
2.1 山洪地质灾害信息共享框架搭建
气象信息涉及的范围比较广泛,并具有异构性、自治性、分布性等特征,要想对其进行共享,具有较大的难度[3]。为了提升气象科普平台山洪地质灾害信息共享的实时性,此研究基于元数据与Web Service 搭建山洪地质灾害信息共享框架[4]。搭建框架忽略数据源与软硬件平台之间的差异,克服以往数据存储系统信息共享的局限,实现山洪地质灾害信息的透明共享,为防治山洪地质灾害提供精确的信息支撑,也为山洪地质灾害区域人员撤离争取更多充足的时间。气象科普平台下山洪地质灾害信息共享框架如图1所示。
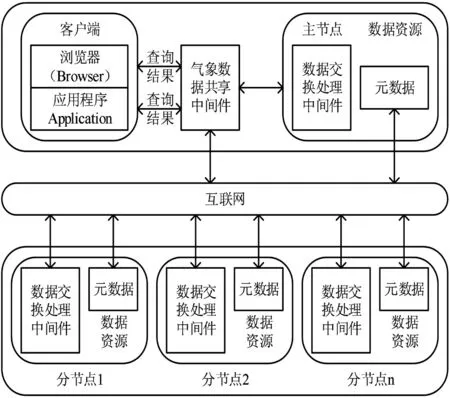
图1 山洪地质灾害信息共享框架示意图
如图1 所示,搭建框架主要分为两个部分,每部分均由多个节点构成,并且分节点信息资源来源可以是异构的[5]。气象科普平台的数据资源主要来源为各个地区的气象部门及其相关单位,并且数据资源以原始状态存储[6]。常规情况下,气象科普平台的数据对于用户是透明的,利用Web Service中间件即可实现山洪地质灾害信息元数据的访问[7],不需要对灾害信息存放的位置、平台等进行关注。以此为基础,对元数据结构与Web Service 中间件进行设计[8],为山洪地质灾害信息共享打下坚实的基础。
2.1.1 元数据结构设计
在气象科普平台下,山洪地质灾害主要由气象数据来预测,故山洪地质灾害信息主要呈现为元数据形式,其属性表结构信息如表1所示。
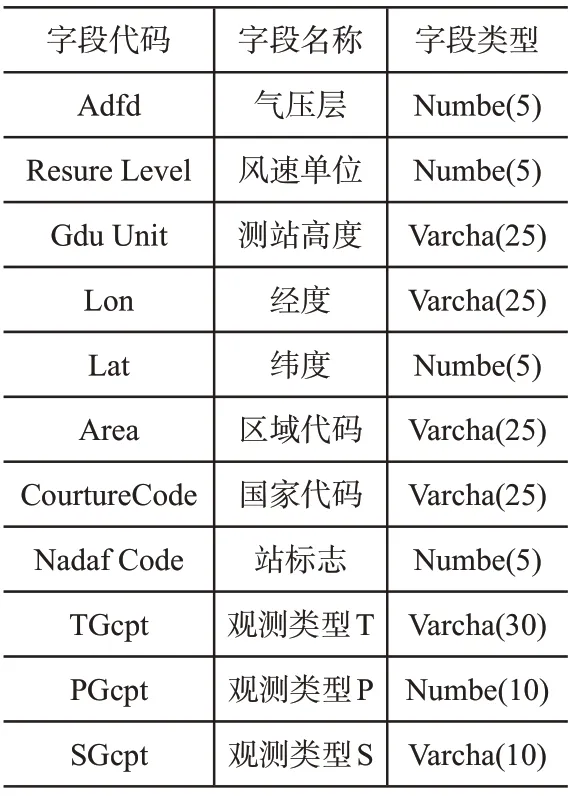
表1 元数据结构表
对于山洪地质灾害信息来说,每个元数据结构均包含属性信息,而属性信息又分为结构化信息与非结构化信息,由于篇幅的限制,不对其进行过多的赘述。
2.1.2 Web Service中间件设计
Web Service本质上就是应用程序,是构建信息共享的关键软件。在Web Service中间件设计过程中,采用Apache Axis作为Web Service中间件的引擎,设置信息共享格式为XML,利用Java对信息共享功能进行开发,使山洪地质灾害信息共享能够适应多种异构环境。
Web Service中间件服务流程如图2所示。
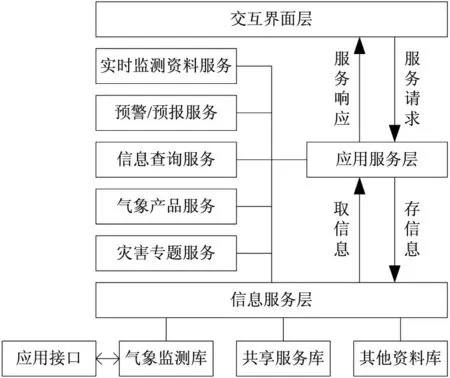
图2 Web Service中间件服务流程图
如图2所示,Web Service中间件主要由多个部分构成。
2.2 信息共享路径构建
为了保障山洪灾害信息共享的安全性与准确性,以信任为基础,构建信息共享路径,为信息共享做准备。山洪地质灾害信息共享可以表示为一个复杂的网络形式,将每一个共享用户、平台看作为网络中的一个节点,则用户之间的信任关系则可以由两者之间的大小与方向来表示。此研究利用邻接矩阵形式来表示,矩阵中的每一行与每一列对应的是网络中的一个节点。设置气象科普平台下山洪地质灾害信息共享中有n个单元,即为G={G1,G2,…,Gn},邻接矩阵表达式为
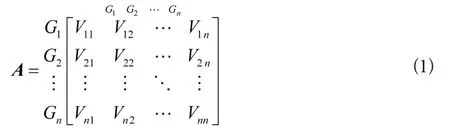
式(1)中,A表示的是邻接矩阵;Gn表示的是信息共享中的第n个单元;Vij表示的是用户i与j之间的信任关系向量。
依据公式(1)计算结果,将其中不为零的项作为山洪地质灾害信息共享路径,并对为零的项进行忽略或删除操作处理。
2.3 信息共享路径信任计算
以上述构架的信息共享路径为基础,对每条路径信任数值进行计算,并对其进行排序,依据信任数值从大到小的顺序进行信息共享,充分保障山洪地质灾害信息的准确度。由于每个信息共享路径中包含的节点数量是存在差异的,需要对路径信任向量进行合并运算。在合并运算中,需要将信任向量自身大小、路径节点数量均考虑在内,才能保障信任数值计算的准确性。信息共享路径信任向量合并运算公式为:

式(2)中,Vcom表示的是信息共享路径信任向量合并运算的结果;p表示的是信息共享路径的序号表示的是信息共享路径i在合并运算中占据的权重;Vi表示的是信息共享路径i的信任向量。为了精确地获取信任向量,需要将合并运算划分为两种情况,一种是相同节点数量的合并运算;另一种是不同节点数量的合并运算,具体运算过程如下所示:
(1) 相同节点数量合并运算
在节点数量相同的背景下,信息共享路径信任向量越大,在合并运算过程中占据的权重数值也就相应越大。根据反模糊化理论,对路径权重数值进行配置,配置结果为:

式(3)中,g(Vi)表示的是信息共享路径的节点数量;Pj表示的是第j个信任等级的量化数值;vij表示的是信息向量中每个分量的值。
将公式(3)计算结果代入公式(2),即可获得相同节点数量的合并运算公式为:

(2) 不同节点数量合并运算
在节点数量不同的背景下,第i条信息共享路径的权重数值由两部分计算而得,即:


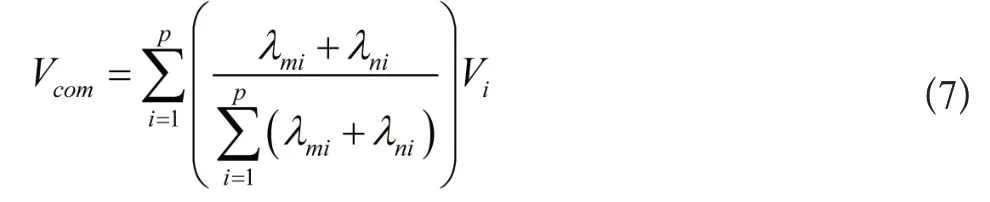
通过上述过程即可获得每条信息共享路径的信任向量,依照信任向量大小对山洪地质灾害信息进行共享,可以最大限度地保障信息的安全性,并能够满足用户的信息共享需求,为山洪地质灾害预警提供精准的信息支撑。
3 实验与结果分析
3.1 实验准备
选取某市气象科普平台作为实验平台,对其某一时间范围内的气象信息进行提取,根据获取的气象信息对山洪地质灾害进行预警,将山洪地质灾害预警信息作为实验数据,对其进行共享操作。
3.2 实验结果分析
以上述实验准备信息为基础,选取山洪地质灾害信息共享能力测度指标,采用灰色模糊综合评价法对信息共享能力进行量化测度,以此来直观地显示提出方法的应用性能,具体如下所示:
根据山洪地质灾害信息共享需求,选取信息共享能力测度指标,选取结果如表2所示。

表2 信息共享能力测度指标表
以表2选取的指标为基础,将其记为集合A=Aij,i,j=1,2,…,n,并且i≠j。在信息共享能力测度过程中,测度指标权重的确定至关重要。实验利用层次分析法对测度指标权重进行计算,为了保障信息共享能力测度具备统一的标准,构造判断矩阵,其表达式为:
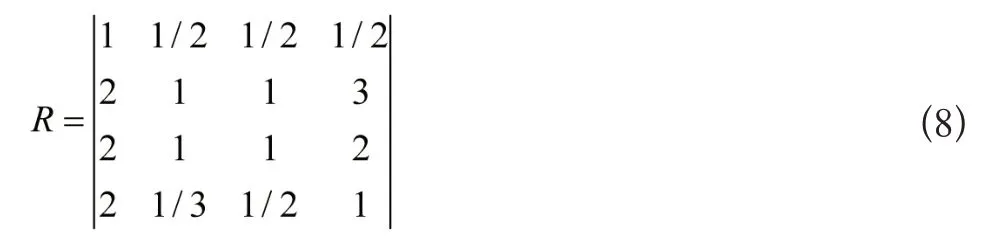
通过计算获得一级指标权重数值为W=(a1,a2,a3,a4)=(0.14.0.36,0.32,0.18),并且CR=0.04<0.1,指标权重计算通过了一致性检验,表明计算权重数值是有效的。
确定灰色模糊综合评价灰类,以此为基础,选择白化权函数,其表达式为:

依据公式(9)计算灰色评估数值,将其整合为权矩阵,记为Yi,结合权重数值计算模糊综合评价矩阵,计算公式为

式(10)中,Zi表示的是行向量,数值代表测度指标的等级隶属度。则最终信息共享能力测度结果记为:

依据上述过程对不同时段的山洪地质灾害信息共享能力进行测度,获得信息共享测度结果如图3所示。
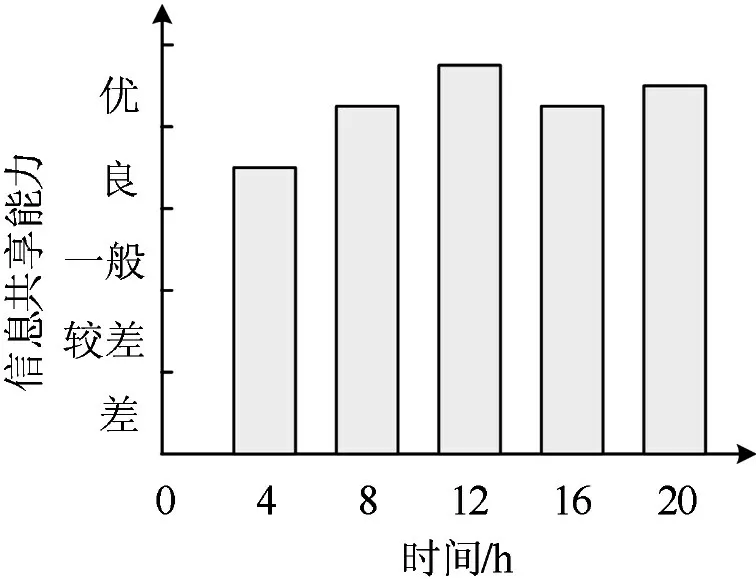
图3 信息共享测度结果示意图
如图3所示,应用提出方法后,山洪地质灾害信息共享能力在良等级以上,并且大部分时间处于优等级,充分证实了提出方法应用性能较佳。
4 结束语
此研究提出了新的山洪地质灾害信息共享方法,极大地提升了信息共享能力,能够有效地传达山洪地质灾害信息,为人员调度提供充足的时间,保障人民群众的安全,也为信息共享研究提供一定的参考。
猜你喜欢
作文周刊·小学一年级版(2022年24期)2022-06-18
福州大学学报(自然科学版)(2021年6期)2021-12-31
内蒙古气象(2021年2期)2021-07-01
华中师范大学学报(自然科学版)(2021年2期)2021-04-10
经济与管理(2020年4期)2020-12-28
小雪花·初中高分作文(2019年8期)2019-10-07
环球时报(2019-03-20)2019-03-20
领导决策信息(2018年46期)2018-04-20
百科探秘·航空航天(2017年11期)2017-12-20
数学教学通讯·高中版(2017年3期)2017-04-17
