
基于蒙特卡罗树搜索
--强化学习的列车运行智能调整方法
2022-09-29 03:00:24王荣笙丁舒忻
中国铁道科学 2022年5期
王荣笙,张 琦,张 涛,王 涛,丁舒忻
(1.中国铁道科学研究院 研究生部,北京 100081;2.中国铁道科学研究院集团有限公司 通信信号研究所,北京 100081;3.中国铁道科学研究院集团有限公司 国家铁路智能运输系统工程技术研究中心,北京 100081)
我国高速铁路已进入大规模网络化运营时期,其路网规模、行车密度、场景工况、旅客发送量以及运输组织复杂性均为世界高铁之最。巨大的客流压力和多变的运营场景下,高铁路网呈现出前所未有的时空复杂度。同时,我国高铁跨越高原、高热、高湿、大风、地震等复杂工况地区,可能导致列车产生大范围延误,此时需要进行列车运行调整工作,恢复正常运行秩序。目前,我国高速铁路列车运行调整仍以列车调度员凭经验处置为主,现场工作强度较大,也难以同时保证调整策略的实时性和近似最优性。
高速铁路列车运行调整问题具有NP 难(NPhard)特性[1-2],该问题是指受突发事件影响,调整列车运行计划使列车恢复有序运行状态[3]。问题求解过程中列车和车站数量的增加会导致求解时间呈现指数级甚至阶乘式增长。国内外学者通常以晚点较小的扰动场景或晚点严重的干扰场景为出发点[4-5],或基于运筹学方法[6-8],或基于进化算法[9-10],对突发事件下各列车在各车站的进路、接发车时刻、发车次序进行调整或协同优化[11-13],力求获取近似最优的调整策略。但上述方法均需自行设计模型分支定界或启发式规则,模型构造严重依赖于个体经验,同时得到的模型在加快算法收敛速度和搜索近似最优解等方面的表现仍不理想。
以强化学习为代表的人工智能方法在实时求解列车运行最优调整方案上具有独特优势。强化学习方法通过智能体与环境之间的不断试错学习,以获取奖励函数最大(目标函数最优)的学习策略,生成的离线训练模型可直接用于问题的在线实时求解,无须对研究问题重新建模[14],即采用离线训练、在线调整的形式就能很好地同时满足调整策略在实时性和近似最优性方面的需求。目前,强化学习在软件项目分配方案、库存管理、车间作业调度等调度优化问题中得到广泛应用[15-17],部分学者也将其应用到列车运行调整问题中。如文献[18]通过分析铁路设施基础布局构建强化学习环境,离线训练生成的模型能实时优化初始晚点下的时刻表;文献[19-20]基于强化学习方法确定了不同优先级列车占用车站股道的次序;文献[21]利用深度强化学习方法优化列车在车站的发车次序,生成了列车总晚点时间最短的运行图调整方案。目前的研究虽然从宏观、微观不同角度构建出列车运行调整的强化学习环境,但在强化学习策略最优性验证方面的研究较少,仍存在极大的改善空间。
本文面向人工智能方法应用于列车运行调整的迫切需求,基于列车调度员的调图视角提出蒙特卡罗树搜索-强化学习(Monte Carlo Tree Search-Re‑inforcement Learning,MCTS-RL)的列车运行智能调整方法,包括MCTS-RL 的列车运行智能调整离线训练模型、强化学习方法、MCTS 的发车次序决策方法和冲突消解启发式规则。通过MCTS-RL 方法一次性离线训练生成在线调整模型,用于实时调整晚点场景下的实绩运行图,并通过与CPLEX 求解器下的运行图调整方案进行对比,验证MCTS-RL方法下学习策略的最优性。
1 高速铁路列车运行调整数学模型
1.1 问题描述
高速铁路列车运营中,突发事件会造成列车在车站的到达晚点或出发晚点,在列车运行图中表现为列车运行线的偏移,此时需要综合考虑列车的运行情况,通过调整各列车在各车站的接、发车时刻和发车次序,给出总晚点时间最短的列车运行调整策略,以保证列车运行效率。
列车在车站和区间的作业时间示意图如图1 所示。图中:L 为线路上列车总数,列车l∈{1,2,…,L};S为线路上车站数量,车站s∈{1,2,…,S};和分别为列车l在车站s的实际到站时刻和实际发车时刻;为列车l 在车站s+1 的实际到站时刻;tl,s,s+1为列车l 在区间(s,s+1)的实际区间运行时间;和分别为相邻2列列车l和l+1在区间(s,s+1)内通过任意位置x的通过时刻。由图1可知:以列车调度员调整列车运行图为视角,可将列车运行调整过程拆解为2 个阶段:首先选择列车在车站的发车次序,之后消解列车在车站和区间的运行冲突,这样一来,合理调整接、发车时刻和,可使所有列车在各站的总晚点时间最短。由此,列车运行调整可描述为以列车总晚点时间最短为优化目标,按时间顺序给出列车在沿线各车站最优发车次序的动态规划过程。
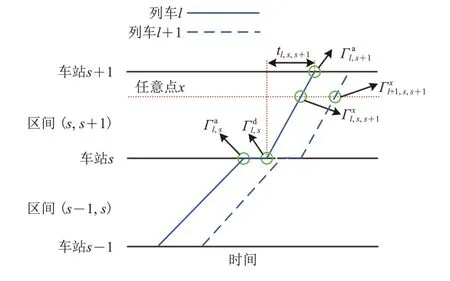
图1 列车在车站和区间的作业时间示意图
同时,为研究方便且不失高速铁路列车运行调整的一般实际性,做出如下基本假设:
(1)初始晚点发生后,线路将不再产生向其他线路传播的晚点;
(2)列车在车站的实际到达和出发时刻不早于图定时刻;
(3)相邻2 列列车的到达—发车和发车—到达作业若发生在同一股道,会产生作业时间冲突。因这种情况在实际中极少,可视为以上2 种作业全部在不同股道进行,互不影响。
1.2 数学模型
1.2.1 目标函数
突发事件引起列车晚点时,铁路运营方关注更多的是在调整各列车在各车站的接、发车时刻后,使线路上列车总晚点时间最短。故定义高速铁路列车运行调整数学模型的目标函数Z 为列车实际到站、发车时刻与图定到站、发车时刻的偏差之和的最小值,即

1.2.2 约束条件
高铁列车在线路上运行时,需要考虑车站作业时间约束和区间作业时间约束。
1)车站作业时间约束
为保证列车在车站到站、发车和接发旅客等基础作业的可行性,根据假设(2),列车l 实际的到站时刻和发车时刻不应早于对应的图定时刻,即

对于经停车站s 的列车l,其实际停站时间应符合最小值约束,即列车l 在车站s 的实际停站时间不小于该车在该站的最小停站时间。值得注意的是,停站列车应保证旅客的正常上下车,故停站列车的作业不能由“停站”改为“通过”,但通过作业的列车若为低等级列车,可将其作业由“通过”改为“停站”,供后行高等级列车越行

对于列车l经停的车站s,其接发列车数量ns应符合最大值约束,即ns不大于车站s 可接发列车的最大数量

当有相邻2 列列车l 和l+1 在车站s 相继执行到达、通过和发车作业时,涉及到的车站作业间隔时间共有7 种,分别为:通过—通过间隔时间通过—发车间隔时间通过—到达间隔时间到达—到达间隔时间到达—通过间隔时间发车—发车间隔时间发车—通过间隔时间。7 种车站作业间隔时间均存在最小值约束,不同类型车站间隔时间的最小值与车站类型、道岔操作方式等因素有关。为研究方便且不失实际性,令上述7种车站作业间隔时间的最小值均为(实际可根据车站具体要求进行修改),即
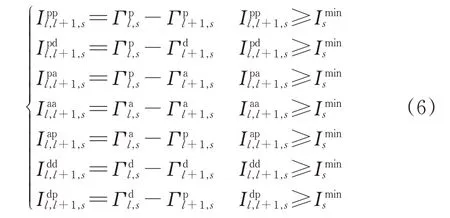
根据假设(3),故式(6)中不再考虑到达—发车间隔作业和发车—到达间隔作业。
2)区间作业时间约束
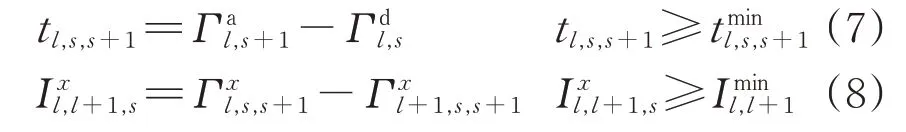
2 列车运行智能调整方法
要采用强化学习求解建立的高速铁路列车运行调整数学模型,需要分析强化学习机制与列车运行调整过程之间的对应关系,构建列车运行智能调整离线训练模型中的强化学习环境和智能体。对列车运行调整方案求解时,为了计算模型中列车总晚点时间最短下的列车发车次序,提出蒙特卡罗树搜索的发车次序决策方法;为了消解模型中列车在车站和区间的运行冲突,提出启发式规则。
2.1 蒙特卡罗树搜索--强化学习的列车运行智能调整离线训练模型
列车运行调整过程具有马尔可夫性质,即未来车站状态下的发车次序信息仅与当前车站状态有关,与过去车站状态的历史信息无关。强化学习方法本质上是1种基于动态规划思想且具有马尔可夫性质的半监督机器学习方法[14],包括智能体和环境。智能体相当于决策者;环境包括状态集、动作集和奖励函数。采用强化学习离线训练—在线调整的机制,学习该过程的列车运行最优调整策略。
对于图1 所示的列车运行调整过程来说,前一阶段选择列车在车站的最优发车次序时,采用蒙特卡罗树搜索(Monte Carlo Tree Search,MCTS)方法,该方法基于博弈树结构,整合了广度优先搜索和深度优先搜索的各自优点,被视为求解决策过程最优化的高效快速搜索方法之一[22],并已在围棋人工智能AlphaGo的策略选择问题中得到充分应用[23-24];后一阶段消解列车在车站和区间的运行冲突时,设计并运用启发式规则。
基于高速铁路列车运行调整数学模型和列车运行调整过程,构建强化学习方法的智能体和环境。其中:环境中的MCTS 方法和启发式规则先后用于生成列车发车次序和消解列车运行冲突;智能体与环境不断交互学习生成最终离线训练模型。在列车运行调整过程中,当输入列车接车或者发车晚点时,该模型可直接用于列车运行调整问题的实时求解,无须重新离线训练。由此得到基于蒙特卡罗树搜索-强化学习(Monte Carlo Tree Search-Rein‑forcement Learning, MCTS-RL)方法下的列车运行智能调整离线训练模型,其流程图如图2 所示。图中:Ss,As,Rs分别为强化学习训练至车站s时的状态集、动作集和奖励函数。

图2 列车运行智能调整离线训练模型流程图
图2 描述了智能体与列车运行调整强化学习环境不断交互,搜索列车运行最优调整策略的离线训练过程,步骤如下。
步骤1:智能体观测当前车站s 的状态集Ss,并基于MCTS从动作集As中随机选择1个动作;
步骤2:应用启发式规则检测并消解当前车站s 及下一区间(s,s+1)的列车运行冲突,然后判定当前车站s的状态集Ss是否为终止状态(是否调整至终点站);
步骤3:若当前车站s 的状态集Ss不是终止状态,则更新至下一车站s+1 的状态集Ss+1,并继续确定所有列车在该车站的动作集;
步骤4:若当前车站s 的状态集Ss处于终止状态(即已调整至终点站S),则表明从始发站训练至终点站S 的1 次训练片段结束,此时记录所有列车在之前所有车站(1,…,s,…,S)的动作集集合,组成强化学习策略,计算奖励函数Rs(即目标函数值)并传递给智能体,供其评估和改进学习策略,然后进入下一次训练片段,形成智能体和强化学习环境试错学习的闭环反馈过程;
步骤5:若当前训练次数未达到最大值时,则令当前的调整车站为始发站,转至步骤1 继续训练;否则,输出此时的列车运行智能调整离线训练模型,模型中的学习策略可直接用于列车运行图的实时调整。
2.2 强化学习方法
根据建立的数学模型和图2所示的离线训练模型流程图,设计列车运行智能调整的强化学习环境。
1)状态集Ss

式中:Ss中第1 列表示所有列车在当前车站s 下的到站时刻,由上一车站状态集Ss-1下的发车时刻和上述所有列车在区间(s-1,s)的实际区间运行时间决定;Ss中第2列表示所有列车在当前车站s 下的发车时刻,由动作集As决定。
2)动作集As
将As设置为列车在车站s所有发车次序情形的集合,即所有列车在车站s的第1 种发车次序为e1,第2 种发车次序为e2,一直到第L!种发车次序为eL!,有

结合式(9),调整Ss中第2 列(实际发车时刻)的向量顺序,形成不同发车次序下的动作集。
3)状态转移概率P(Ss+1|Ss,As)
表示当列车处于当前车站s的状态集Ss和动作集As时,转移到下一车站s+1 的状态集Ss+1的概率。若当前车站不是终点站,则一定会发生状态转移,由Ss转移至Ss+1,即P(Ss+1|Ss,As)=1;若当前车站是终点站,则一次训练片段结束,不再进行状态转移,即P(Ss+1|Ss,As)=0,此时输出奖励函数。
4)奖励函数R
将R 视为高速铁路列车运行调整数学模型的目标函数,对应于式(1) 列车总晚点时间奖励函数R 设置为列车总晚点时间的负值,即
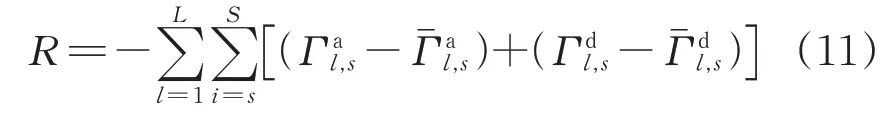
列车总晚点时间越短,奖励函数R值越大,说明列车运行调整策略越优。
5)智能体
强化学习智能体针对突发事件下列车晚点情况,在环境对约束条件(列车的车站作业时间和区间作业时间)的有效表征下,调整各列车在各车站的接发车时刻,故智能体相当于实际中给出列车运行调整计划的列车调度员。基于高速铁路列车运行调整数学模型设计强化学习方法的智能体和环境,智能体与环境的不断交互,最终生成总晚点时间最短的列车运行智能调整离线训练模型,模型策略可直接用于问题实时求解,无须重新离线训练。智能体中的学习策略π 是所有状态下沿线各车站动作集的集合,表示从始发站调整至终点站1个完整的发车次序集合,故某个车站选择的发车次序不同导致每次训练的学习策略也不同。
2.3 发车次序决策方法
2.3.1 可行发车次序的启发式规则
从运行图来看,当晚点列车的运行线发生偏移后,智能体会综合考虑不同的发车次序构成的不同强化学习策略,并从中选择使列车总晚点最短的列车运行调整策略。车站发车次序总数等于列车总数L 的阶乘,但并非所有L!种发车次序结果都是可行的,原因有二:其一,通过作业的2 列列车在车站不可能改变列车运行顺序;其二,某些发车次序并不满足车站作业间隔时间的约束。以图3为例说明这种不可行的发车次序。由图3可知:对于接连经过车站s+1 的停站列车和通过不停站列车,因存在车站作业间隔时间的约束关系,后行通过的列车l+1无法越行当前停站时间只有2 min的停站列车l,因此车站s+1 可行的发车次序有且只有{列车l,列车 }l+1 。故设计启发式规则对各车站的发车次序集合进行“剪枝”,剔除其中不可行的发车次序,以便最终输入到强化学习环境动作集中的沿线车站所有发车次序均是可行的。

图3 不可行发车次序示意图
2.3.2 可行发车次序树结构
通过启发式规则,输出各车站可行的发车次序。以相邻3列列车l,l+1和l+2为例,设计得到蒙特卡罗树搜索算法下博弈树的数据结构如图4所示。由图4 可知:始发站(车站1)的发车次序为树结构的根节点,车站2 的3 种发车次序为连接始发站根节点的3个子节点,以此类推,最终可遍历至终点站S发车次序的子节点。

图4 发车次序树结构示意图
2.3.3 蒙特卡罗树搜索的最优发车次序算法
结合上述发车次序的博弈树结构,提出MCTS的列车最优发车次序算法,步骤如下。
步骤1:输入始发站(车站序号s=1)根节点状态S1。
步骤2:判断其后的车站子节点(发车次序)是否被访问过,若已被访问,转步骤3;否则转步骤4。
步骤3:利用上限置信区间(UCT)算法求出各子节点函数值(算法和求解方法可参考文献[22]),选取函数值最大的子节点(发车次序)作为当前节点动作并转步骤4;若函数值相等,则随机选择1个子节点,转步骤5。
步骤4:随机选择1 个未被访问的子节点,转步骤5。
步骤5:判定当前节点是否为终点站子节点,若是,转步骤6;否则,转移至下一车站,转步骤2。
步骤6:扩展生成终点站子节点的动作(可行发车次序),随机选择1 个动作并在树结构中加入该动作的新状态,转步骤7。
步骤7:从根节点到当前节点,完成1 次完整回合的模拟训练,转步骤8。
步骤8:将模拟训练的胜负结果回溯至树中,更新UCT 算法参数,若当前回合数未达到所设定的最大值,转步骤1;若已达到设定的最大值,终止模拟,输出列车运行调整的最优发车次序。
2.4 冲突消解启发式规则
在MCTS 给出最优发车次序后,晚点列车和运行线发生偏移可能与后行列车在区间或者车站产生冲突,在列车运行图中表现为冲突列车的运行线在区间产生交点,或冲突列车在车站不满足车站作业间隔时间的最小值约束,严重影响行车安全。因此在蒙特卡罗树搜索生成列车在车站的发车次序后,基于消解列车运行冲突的传统方法[25]设计启发式规则,将其运用于列车在车站和区间运行冲突的消解,步骤如下。
步骤1:在强化学习环境中,输入晚点场景下的实际接发车时刻矩阵Ss。
步骤2:检测当前相邻2 列列车l 和l+1 在车站s的实际发车间隔时间(即是 否满足 最 小车站 作 业间隔 时 间的约束,若满足,转步骤3;否则,转步骤4。
步骤3:转移至下一组的相邻2 列列车,继续检测发车间隔时间是否满足的约束,若不满足,转步骤2;否则将继续检测该站所有其他列车,直到所有列车完成检测后,转步骤5。
步骤5:检测列车l 与后行受晚点影响列车在区间(s,s+1)是否存在冲突,若存在冲突,则运用启发式规则消解冲突;否则,转步骤6。
步骤6:检测当前相邻2 列列车l 和l+1 在车站s的到站间隔时间(即是否满足最小车站作业间隔时间的约束,若满足,转步骤7;否则,转步骤8。
步骤7:转移至下一组的相邻2 列列车继续检测到站间隔时间是否满足的约束,若不满足,转步骤6;否则将继续检测该站所有其他列车,直到所有列车完成检测后,转步骤9。
步骤9:基于MCTS-RL 方法调整所有列车在车站s 的发车次序,并选择其中1 种,当s=S 时,转步骤10;否则,转步骤2。
步骤10:计算列车总晚点时间下的奖励函数值,输出列车运行调整策略。
3 算例仿真
以京沪高铁北京南—泰安段的某日计划运行图作为初始数据输入,设置大量晚点场景并选择其中2 个作为典型场景,基于前述数学模型和列车运行调整过程,构建得到强化学习环境与智能体,并令其不断交互学习;基于MCTS-RL 一次性生成离线训练模型得到列车运行智能调整方法(简称MCTS-RL 法)。在列车运行调整过程中,当输入列车接车或者发车晚点时,该离线训练模型可直接用于列车运行调整问题的实时求解,无须重新建模求解。将MCTS-RL 方法下的方案与同样应用本文数学模型、但求解时分别采用先到先服务(First-Come-First-Served,FCFS)法[6]和CPLEX 求解器得到的调整方案进行对比,验证本文提出方法的有效性和最优性。
3.1 参数设置和晚点场景
以京沪高铁北京南—泰安段沿线的北京南、廊坊、天津南、沧州西、德州东、济南西和泰安7个车站为背景,某日线上共开行列车79列。列车在6个站间的最小区间运行时间分别为15,14,14,21,17 和15 min;最小停站时间和最小车站作业间隔时间均设置为2 min。
针对该日计划运行图中的全部79 列列车,随机设置10~30 min 的大量发车晚点和到站晚点场景,并从中选择2个较具代表性的场景见表1。
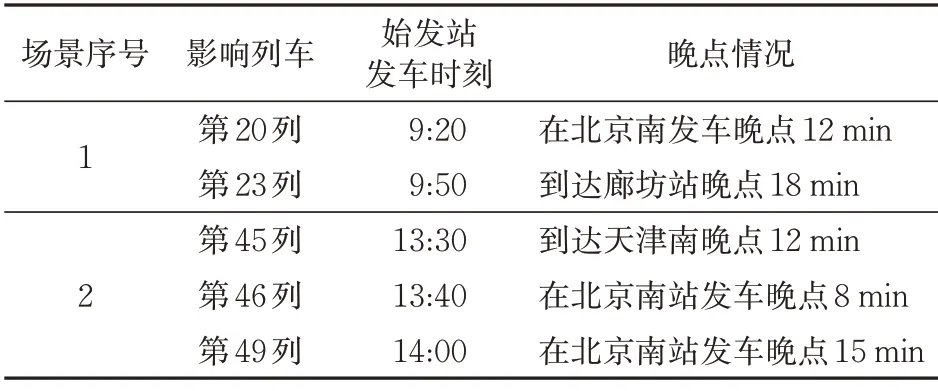
表1 典型晚点场景
3.2 计算结果
针对设置的大量晚点场景,基于Python 3.6.5编写强化学习环境,在Intel Core i7-4710MQ@2.5 GHz,12 GB 的电脑上一次性离线训练,生成最终的MCTS-RL 在线调整模型。强化学习训练时,列车运行图采用深度卷积神经网络进行状态集输入特征的学习,深度学习框架TensorFlow 版本为tensorflow-gpu 1.8.0。
经过多次强化学习训练交叉验证后,确定其训练参数见表2。表中:探索开发比表示训练阶段随机搜索策略占所有策略的比值;折算因子表示某个训练片段中随着车站状态集不断向前推移,奖励函数值所呈现的指数衰减趋势(即距离当前状态越远的车站状态集,对智能体影响越小)。

表2 强化学习的训练参数
以表1中的2个典型场景为例,分别采用FCFS法、CPLEX 求解器方法(简称CPLEX 法)以及MCTS-RL 法求解列车运行调整方案。FCFS 法用于验证MCTS-RL 法在减小列车总晚点时间上的有效性。考虑到CPLEX 法的求解结果一定最优,故以CPLEX 下的调整方案(即最优方案)验证MCTS-RL法下调整方案的最优性。
为表达FCFS法(或MCTS-RL法)下调整方案与CPLEX下最优方案之间的总晚点差值(Gap),引入η

式中:τ为FCFS 法/MCTS-RL 法下调整方案的总晚点时间,min;τopt为CPLEX 最优方案的总晚点时间,min。
1)3种方法下求解指标对比
FCFS、CPLEX 和MCTS-RL 这3 种方法下,求解得到调整方案的总晚点时间及求解时间对比见表3。由表3可得到如下结论。
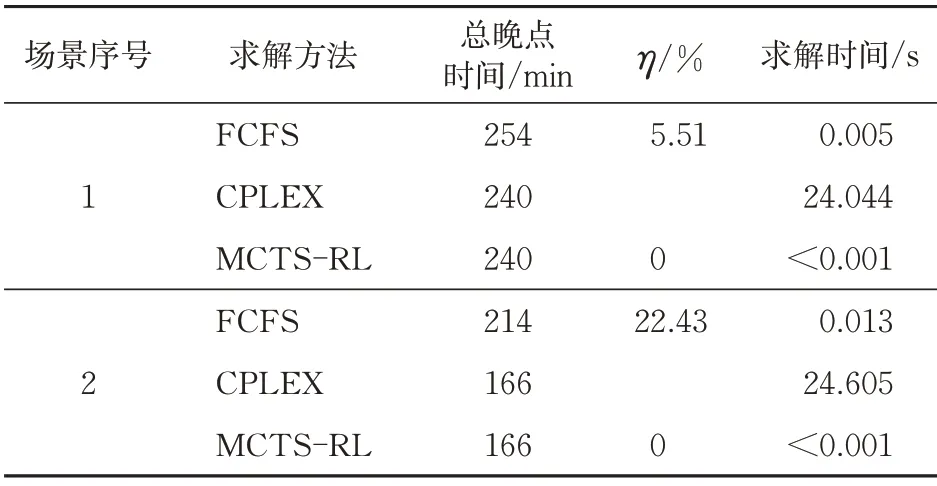
表3 FCFS,CPLEX和MCTS--RL的求解指标对比
(1) 在列车总晚点时间方面,CPLEX 和MCTS-RL 方法下的更短,分别比FCFS 法缩短14 min 和48 min;这意味着在2 个典型晚点场景下,CPLEX 和MCTS-RL 方法下最优方案能够分别缩短5.51%和22.43%的晚点时间。
(2)在列车运行调整求解实时性方面,FCFS法能分别在0.005 s和0.013 s内给出与图定发车次序相同的调整策略,具有较好的实时性;CPLEX求解器虽然得到总晚点时间最短的最优调整策略,但求解时间分别达24.044 s 和24.605 s,考虑到案例涉及参数、变量较少,若将其运用于真实场景下,求解时间可能会随着车站、列车数量的增加而呈现指数级增长;MCTS-RL虽消耗大量时间用于试错学习的离线训练,但训练结束后可产生总晚点时间最短的列车运行调整学习策略,智能体凭借该策略能够在短于0.001 s 时间内给出同样最优的列车运行调整策略。相较于CPLEX 法,MCTS-RL法的求解效率高很多。
2)列车运行图调整结果
针对2 个典型晚点场景,FCFS、CPLEX 和MCTS-RL 这3 种方法下的运行图调整结果对比,分别如图5 和图6 所示。图中:实线和虚线分别表示该方法下不需要调整、应进行调整的列车运行线;线型粗细用于区分运行线归属于不同列车。由图5和图6可得到如下结论。

图5 典型晚点场景1下计划运行图和FCFS法、CPLEX法/MCTS--RL法得到的运行图调整结果

图6 典型晚点场景2下计划运行图和FCFS、CPLEX法/MCTS--RL法得到的运行图调整结果
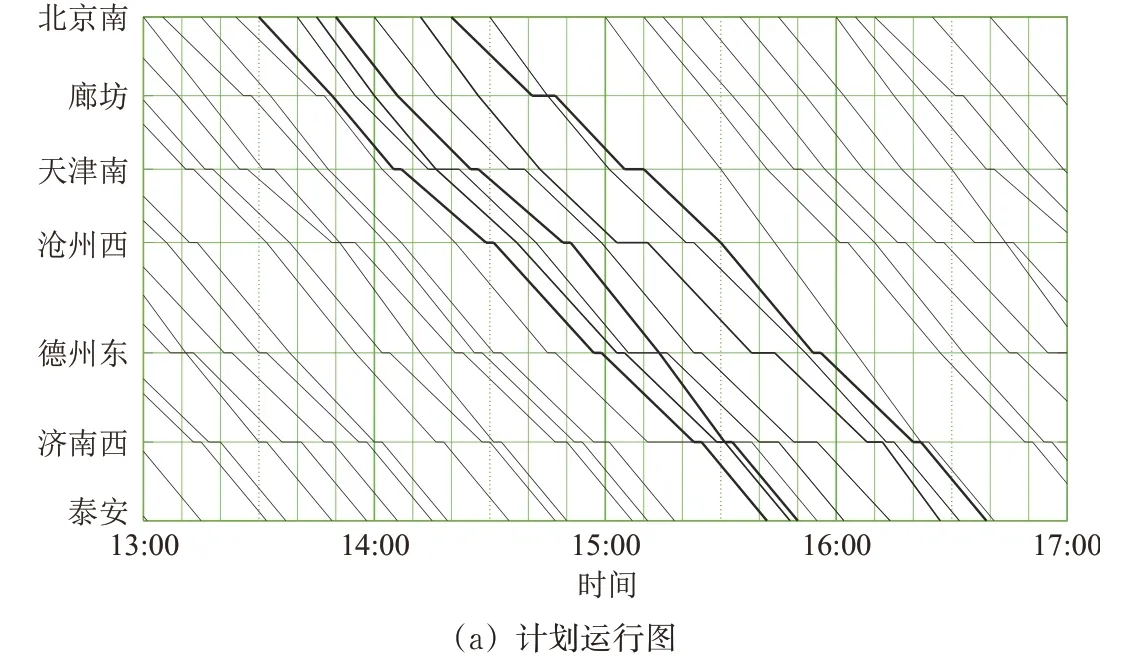
(1)CPLEX 求解器和MCTS-RL 方法下各列车在各车站的发车次序相同,这说明2 种方法下运行图调整结果是相同的,进一步说明本文所提出MCTS-RL方法能给出同样最优的调整策略;相比于CPLEX,MCTS-RL 的优势在于无须每次重新求解新问题,而是可直接根据离线训练模型下的学习策略,在线实时生成列车运行调整方案。
(2)与FCFS 法相比,CPLEX 法和MCTSRL 法均能够通过调整列车在车站的接发车时刻,生成总晚点最短的列车运行调整策略。例如图5中,最优方案调整了第20 列和21 列列车(图定9:30 始发)在北京南的发车次序和时刻,这样第20 列列车能够在沧州西站更早地恢复正点,但各列车在其余车站的发车次序与图定相同;图6中,最优方案调整了第47 列列车(晚点后13:45 始发)与第48列列车(13:50 始发)在天津南站的发车次序和发车时刻,增加了第50列列车(14:12始发)在天津南站的停站时间,令第49列列车(晚点后14:15始发)在该站越行,使列车总晚点时间最短。
4 结 语
针对路网中列车的到站和发车晚点,根据高速铁路列车运行调整数学模型,提出MCTS-RL的列车运行智能调整方法,设计由状态集、动作集、状态转移概率和奖励函数组成的强化学习环境。MCTS可给出总晚点时间最短下各列车在各车站的发车次序,然后设计启发式规则消解列车运行冲突。MCTS-RL 通过离线训练—在线调整的学习机制,实时辅助列车调度员调整列车运行图,提升晚点场景下应急处置效率。仿真结果表明,典型晚点场景下,MCTS-RL 方法下的在线调整模型能够在0.001 s 内给出与CPLEX 求解器同样最优的列车运行调整策略;与FCFS 方案相比,MCTS-RL 下最优调整策略的总晚点时间又分别缩短14 min 和48 min。
与既有研究不同的是,本文研究基于列车调度员的宏观调图视角,后续工作可考虑车站进路、线路信号设备布置和列车运行状态等实际微观约束,同时还可进一步研究严重晚点场景下动车组运用计划和列车运行图的协同调整。
猜你喜欢
历史教学问题(2023年6期)2024-01-18 08:45:06
铁道科学与工程学报(2022年10期)2022-11-30 13:02:12
金沙江文艺(2022年4期)2022-04-26 14:14:22
铁道通信信号(2020年1期)2020-09-21 08:55:16
西南交通大学学报(2018年6期)2018-12-18 02:23:24
小天使·六年级语数英综合(2017年8期)2017-08-04 00:44:51
铁道通信信号(2016年8期)2016-06-01 12:10:21
中国铁道科学(2015年6期)2015-06-21 06:54:54
小天使·五年级语数英综合(2014年11期)2014-11-06 09:49:03
都市快轨交通(2014年6期)2014-02-27 08:36:22
