
基于铁路旅客常住地与行程环的年度出行特征分析体系
2022-09-29 03:00:22孔德越吕晓艳
中国铁道科学 2022年5期
孔德越,程 默,颜 颖,吕晓艳
(1.中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081;2.中国国家铁路集团有限公司 客运部,北京 100844)
随着我国铁路客运市场化改革程度不断加深,传统面向客运市场的整车、整区间的宏观客流特征分析方法逐渐无法满足管理部门精准营销、精细化管理的现实需要。对于新时代高度市场化的铁路客运,要做好针对性服务营销与个性化产品设计,就需要有意识地根据旅客出行目的进行客流成分结构划分,精准把握不同客流的共性出行需求。但目前对不同旅客群体出行行为特征及客流结构的研究仍属空白,不同出行目的旅客的独特出行特征和实际需求被湮没在宏观市场呈现的表象之中。这造成铁路客运管理时,各旅客群体的出行需求没有得到足够关注,更导致铁路客运产品不能更好满足旅客需求的问题日益凸显,构建合乎实际的铁路旅客全年出行特征分析体系迫在眉睫。
目前,国内外相关研究均缺乏对不同客流结构年度出行特征的深入分类分析。国内对旅客行为特征的研究主要停留在画像层面,即总结提炼旅客出行偏好,形成旅客标签,并将其应用于客流预测或产品改进,如文献[1-7]基于旅客出行选择偏好,分别从不同层面提炼出旅客需求,针对性制定营销方案策略。在国外,相关研究如文献[8-10],主要根据旅客出行需求的不同,或构建数学模型或基于机器学习算法,研究列车能力安排、旅客换乘选择、客流发生预测等具体运营问题。总之,既有的旅客出行偏好研究虽是对旅客行为特征研究的良好探索,但常用的分析方法还停留在归纳与总结层面,对旅客出行需求的挖掘不够深入。对铁路客运管理来说,旅客出行偏好的提取结果是旅客选用铁路客运产品的必要不充分要素,因此实践中往往难以准确了解旅客出行动机并预判旅客需求。
旅客在某个时间段内的1 个往返行程可抽象为1 个行程环,按日期顺序排列的一系列行程环可抽象为1个出行链,链上相应汇集空间、时间、活动类型及出行方式等信息。以单一出行链为研究对象,按旅客在空间和时间上的出行顺序梳理行程特征,从而更深入地分析旅客出行习惯偏好与路径选择。当前,关于城市出行链的研究主要集中于一次出行中不同交通方式的出行选择及换乘行为上,如文献[11-13]。而铁路出行链研究,则更侧重于通过一段时间内旅客的出行频次、目的地等特征分析出行习惯,推断出行动机与目的。然而,如果要开展更深程度地旅客行为特征属性挖掘,则有必要系统、全面、成体系地通过特定分析手段进行深入分析,以便相关决策部门能够准确判断客流结构成分并理解其具体需求,从而更加准确、及时地调整运力,改进产品。
传统技术手段着重于宏观客流规律的总结、提炼,在大数据全样本下的客流结构划分与出行特征分析问题中显得力不从心。在此背景下,首次提出基于铁路旅客常住地与行程环的旅客群体年度出行特征分析体系,包括旅客常住地识别、行程环划分、行程环与出行链的拓扑结构构建。先通过随机森林算法,识别旅客群体的唯一常住地;再构建基于常住地特征的改进DBSCAN基本元聚类模型,用于划分旅客行程环;然后,分类图形化展示行程环和出行链,得到两者的拓扑结构,用于分析旅客全年出行规律。通过构建基于旅客常住地与行程环的铁路旅客年度出行特征分析体系,以期充分利用出行信息挖掘旅客需求,为相关管理部门提供决策支持。
1 数据集构建和基本假设
分析旅客年度出行特征时,常住地与行程环是最重要的构建单位,是挖掘旅客行为特征的分析基础。其中:常住地指旅客在1年中停留时间最长的城市,是旅客铁路出行主要的出发地与目的地;行程环指旅客从离开常住地至返回常住地的一次出行中所有铁路行程的集合,是分析旅客出行目的的基本单位。
建立旅客年度出行特征分析体系,首先要基于铁路出行大数据构建数据集并训练机器学习模型,对常住地与行程环进行准确识别和划分。旅客出行行为受主观因素影响,具有较强随机性,为保证数据建模的可靠性与普适性,构建数据集时须以真实、主流的铁路行程数据为基础。
1.1 数据集构建
选用2019年10 万份经脱敏处理后的全年铁路行程数据构建数据集,数据来自线上问卷(12306的APP 及微信公众号)、线下调研(车站和车厢)等渠道,并采用人工分析及问卷获取的方式标记数据集中的常住地与行程环。
构建常住地识别与行程环划分模型时采用交叉验证法,取数据集中的8万份数据作为训练集,用于模型参数训练;另2 万份数据作为测试集,用于模型精度验证。
1.2 基本假设
旅客出行行为随机,不同个体出行习惯差异较大。为提高模型使用和运算效率,需要排除少数极端情况,使模型对主要旅客群体有效。故建立分析体系时,对旅客年度出行特征进行以下合理化假设,从而圈定主要研究范围。
1)假设1:旅客在1年中有且只有1个常住地
绝大多数旅客仅围绕唯一城市往返出行,这个城市就是他们的主要居住城市,即常住地;小部分旅客会在多城市有居住点(如异地求学的学生、在多子女家中轮换居住的老人等),则认为其在1年中实际停留时间最长的城市是唯一主要常住地。
2)假设2:旅客行程环全部为闭环,且起止城市为常住地
如果数据集中出现铁路行程停留在非常住地的情况,则认为当前行程或尚未完成,会在未来某时刻会返回常住地;或已经完成,属于采取其他交通方式返回的单边行程。
3)假设3:旅客抵达常住地时,如果未衔接常住地的同城换乘出行,则当前行程环结束
旅客抵达常住地后即回家休整,结束当前行程。如果旅客抵达常住地后短时间内进行同城换乘出行,则认为旅客换乘后抵达常住地;如果旅客抵达常住地后短时间内又从常住地出发至其他城市,则认为其开始了1个新行程。
4)假设4:旅客在常住地有铁路出行记录
识别旅客常住地时需参照其铁路出行行为。如果旅客在常住地未发生铁路出行,难以通过既有铁路出行数据判断其真实常住地点,则认为铁路出行时首选车站所在的城市是其常住地。
2 旅客常住地识别
基于行程特征数据构建模型时,需要从数据集中旅客的全年所有到发城市中分析、推断出铁路行程中围绕的主要核心城市,这即是旅客常住地识别。经过数据训练并优化后的模型,能够根据全年所有行程的出行顺序、出行时期、出行次数、停留时长、与籍贯地相关性等一系列要素特征,判断出旅客在某年度的唯一常住地。
2.1 常住地候选城市及相关属性
根据假设4,旅客在常住地有铁路出行记录,因此常住地需要在历史到发城市中筛选、判断得出。而常住地的候选城市,是旅客具有较高出行倾向特征的主要核心城市,通常具有以下一系列特征:停留时长最久、到发次数最频繁、与籍贯地相关、是全年第1 次出行的出发点或最后1 次出行的到达点、是节假日出行的起止点以及持特殊票种出行等。根据常住地具备的主要特征,筛选出以下6类常住地候选城市。
1)时长地
时长地指旅客1年内停留时间最长的城市,主要属性包括旅客在该市的停留时长和停留期间的日期属性。当铁路行程连贯时,任意城市的停留时长可根据相邻2 次行程的出行日期差计算得出;旅客在某市的停留时间越长,将其作为常住地的可能性就越高。旅客总倾向于在节假日期间外出旅游或探亲,此时经停的城市大概率不是常住地,因此通过在某市的非节假日停留时长,能够辅助判断该市是否为旅客的常住地,即:当旅客在2个城市的总停留时间相同时,可进一步使用日期属性判断其常住地。
2)次数地
次数地指旅客1年中到发次数最多的城市,主要属性为旅客经由该市的出行次数,即行程中在某市的乘车出发次数与到达次数之和,此时换乘行为(在该市停留时间不超过4 h且不属于往返出行)的到发次数不计入其中。当两地距离过近且旅客在两地均有铁路出行、但没有两地间行程时,考虑旅客可能居住在两市之间,会根据出行、换乘的便捷度自行选择出发地点,这种情况下,计算次数地时考虑将两地出行次数合并,计入两地中到发次数更多的城市。
3)首末地
首末地指旅客1年中首次出行的出发城市(首发地)及末次出行的到达城市(末达地)。旅客全年仅出行1次时,旅客的首末地分别是该行程上的出发车站所在城市和到达车站所在城市。全年内首次出行前,旅客在首发地的停留时长与末次出行后在末达地的停留时长决定了模型中首末地的权重大小,停留时间越长,首末地对应的权重越大。
4)籍贯地
籍贯地多为本人出生时祖父居住地、父亲籍贯地或本人出生地。截至2019年底,我国流动人口占比仅16.9%[14],多数旅客的常住城市仍是其籍贯城市。
5)节假日首末地
旅客在节假日中的行程通常连贯、完整,因此节假日行程环的首、末地具有较高参考价值。但由于出行时可能拼假,因此确认节假日首末地时还须进行如下特殊处理:①充分考虑拼假可能,拉长数据观察范围;②根据行程连贯性,过滤节假日行程途径地;③根据停留时长,剔除换乘城市。
6)学生旅客的学校所在地
1年之内,学生旅客在学校停留时间相对更长,因此以学校所在地标识学生旅客的常住地。特别地,根据《铁路旅客运输规程》,学生票优惠区间为家庭至院校,因此学生旅客购买学生票出行时,常住地可根据出行区间精准识别。
2.2 常住地识别模型构建
常住地识别问题的本质是基于全年复杂出行特征的分类问题。考虑到模型数据集具有数据量大、数据属性多、属性间有相关性、数据项存在空值的特点,且模型输出结果应有较高的可解释性,相较其他分类模型方法(如支持向量机、近邻算法以及朴素贝叶斯模型等),决策树方法的求解效果更优。该方法属于白盒模型,其建模结果不仅能够很好地还原到旅客的出行行为特征上,而且对大数据量、多维数据集的建模效率较高。
考虑到异常值和过拟合对单一决策树建模效果的影响,选用多决策树方法来构建常住地识别模型,即随机森林算法。随机森林算法具有准确率高、运算效率高、结果易解释的特点,在图像处理、特征分析、行为识别等诸多领域均有良好的应用实例[15-16]。
基于随机森林算法的常住地识别模型(简称为“随机森林模型”)构建主要分为5步,如图1所示。首先,在构建初始数据集后,对其进行数据预处理并将其分为训练集和测试集;其次,通过可放回地抽样,选取训练集中部分样本和特征,构建多个不同的子数据集;然后,针对每个子数据集分别采用ID3 算法训练决策树,形成随机森林;接着,采用测试集对模型进行交叉验证,计算当前森林的计算率;最后,不断调整随机森林的主要参数(树的棵数、叶子节点最小记录数等),进一步提高算法效率。随机森林算法是较为成熟的算法,具体建模过程不做赘述。经反复测试,常住地识别建模过程中当决策树的棵数取100 棵、叶子节点最小记录数取500时,模型的分类效果最佳。

图1 常住地判断算法建模过程
2.3 常住地模型结果翻译
常住地识别模型建成后,翻译模型中每棵决策树独立决策流程的对应规则,筛选整理所有决策树均采用的共性规则,并按属性权重与决策顺序进行排序,形成常住地识别的整体规则流程,梳理结果如图2所示。

图2 随机森林算法识别旅客常住地具体流程
从图2 可以看出:旅客全年出行频次不同,算法流程也有所不同;当旅客全年仅出行1次时,籍贯地是判断常住地的重要依据,这与实际情况相符,旅客出行频次较低,表明旅客出行需求较少,停留在籍贯地的可能性较高;旅客全年出行2 次时,出行的首末地是判断常住地的重要依据,2 次出行时往返出行的可能性较高,因此首末地大概率相同且为旅客实际常住地;旅客全年出行3次以上时,因有更多行程参考,次数地与时长地就成为权重更高的常住地判断依据;当旅客在次数地的到发次数、在时长地的停留时长高于某定值时,参考这2项要素后能够输出符合预期的常住地识别结果。
3年度出行特征分析体系构建
3.1 基本概念
以高效划分并归集旅客杂乱出行轨迹为目标,对铁路出行信息进行拓扑抽象,将单一旅客的全年铁路出行行程中的出发城市与到达城市视为“点”,将出行的单次行程视为“线”,将其中所有行程的拓扑结构视作“面”,按拓扑性质相应定义基本元、断元、行程环与出行链。在此基础上,为清晰梳理旅客年度出行特征,先根据常住地划分行程环,再根据旅客年度出行的行程环特征得到全年出行链拓扑结构。
1)基本元
基本元指旅客铁路出行行程中,1 张火车票票面对应的发站—到站单次行程。旅客的1个基本元严格对应1张车票行程;铁路联程票(多张车票联程)、空铁联程票(铁路与航空票联程)、同站或同城换乘均算做多条基本元。
2)断元
断元指旅客铁路出行中出现的不连贯行程间的基本元,此时易出现的2 种情况如图3 所示。图中:实心节点(A地)表示旅客常住地;空心节点(B 地和C 地)表示旅客的其他到发城市;实线和虚线箭头分别表示行程中相应方向的基本元和断元。由图3(a)可知:在某次行程中,当旅客上一基本元的到达城市B 与下一基本元的出发城市C不同时,判断旅客采取其他交通方式产生了从B地至C地的位移,且认为此时旅客在两地之间有且仅有1条断元出行。由图3(b)可知:只有当B 地和C 地均不是旅客常住地,且A—B,C—A 分属于2个不同行程时,可认为B地和C地之间有可能存在2 条断元,且均连接常住地;其他情况下,B 地和C 地之间仅可存在1 条断元,这是因为对于普通的不连贯行程,若B 与C 之间出现2 条断元,那么这2条断元之间的非常住地节点将无法被唯一确定。
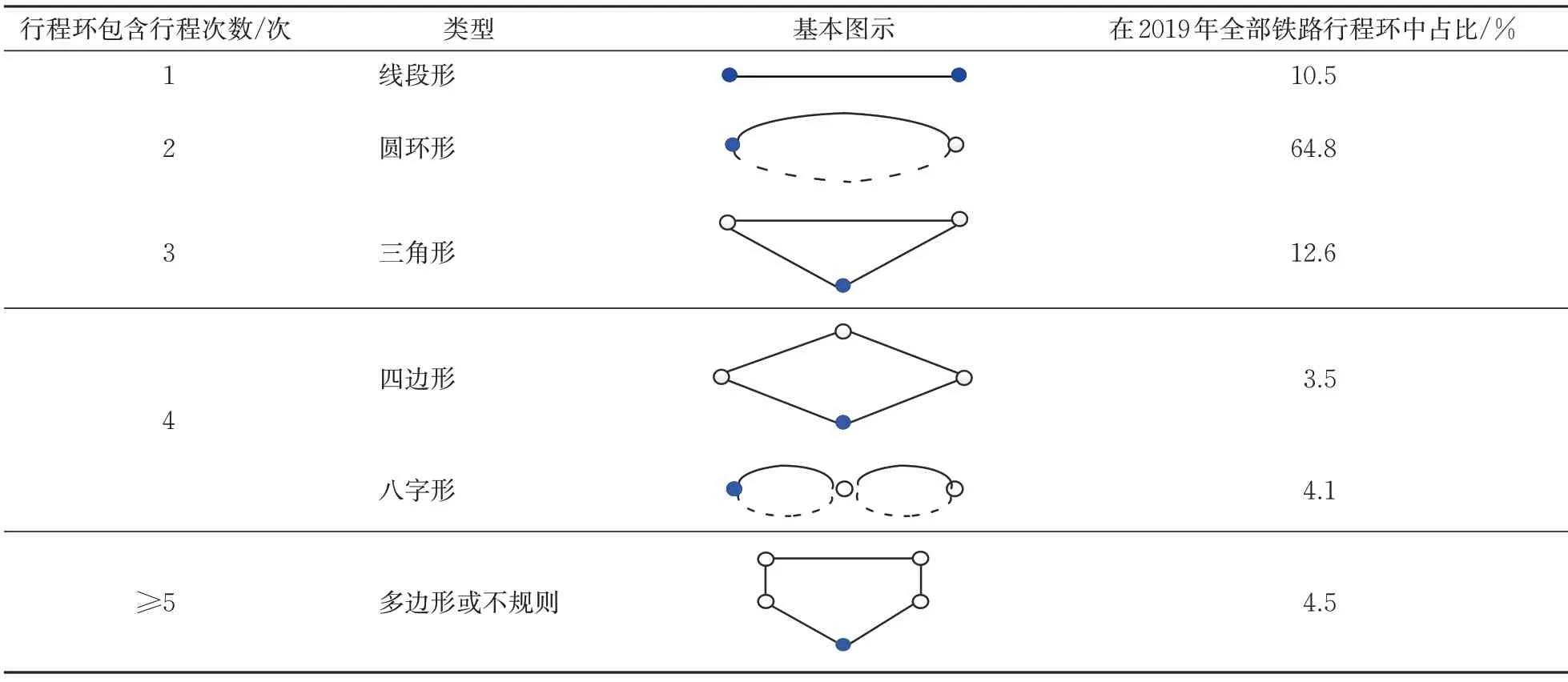
3)行程环
行程环指旅客目的性的单次出行行程中,所有铁路基本元和断元的集合,是由旅客常住地出发、经过一段时间、一系列行程后返回常住地的完整出行闭环,如图4 所示。旅客行为特征分析体系中,行程环分析是最重要的分析基础,也是实现客流成分分类及出行目的划分的基础分析单位。

图4 行程环
4)出行链
出行链指旅客一段时间内所有完整行程环的集合,是旅客在一段时间内所有出行轨迹按日期顺序相连形成的完整出行链条。出行链中的节点即为旅客全年铁路出行行程中所有到发过的城市;出行链中的线段即为基本元或断元,如图5所示。因研究时关注年度为单位的旅客出行特征,文中所有出行链时间段长度均指1年。

图5 出行链
3.2 参数与变量定义
针对出行链和行程环,定义:m为旅客出行链中铁路基本元的总个数;n为旅客出行链中的所有完整行程环总个数;Ci为旅客出行链中所有行程按日期顺序排列后的第i个铁路行程环,是这1年中旅客第i个目的性行程中所有基本元和断元的集合,i=1,2,…,n;C为旅客本年度的出行链,也是所有完整行程环的集合,C={Ci,i=1,2,…,n};ni为行程环Ci的全部节点个数。
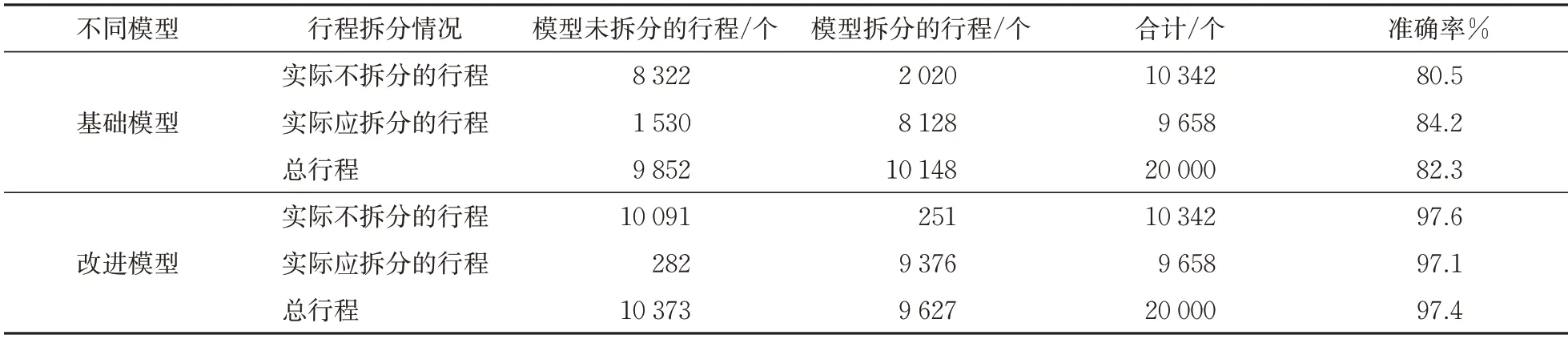
针对基本元和断元,定义:K 和K'分别为旅客出行链中基本元和断元的总个数;ki和k'i分别为行程环Ci中基本元和断元的个数;t(a),t(b)分别为按日期顺序排列后第a 个和第b 个基本元的乘车日期(采用符合GB/T 7408—2005 的日历日期基本格式记录(yyyymmdd)),a,b=1,2,…,m,a 针对行程环中的城市节点,定义:Sscz(xt(a))和Sxcz(xt(a))分别为基本元xt(a)的上车站、下车站所在城市节点;Sscz()和Sxcz()分别为断元的出发、到达城市节点;Sczd为旅客的常住地;N为出行链中全部节点的个数;Nj为出行链中某城市节点j的总个数,1,2,…,n};NSczd为出行链中常住地节点的个数;ni,j为行程环Ci中某城市节点j的个数。 针对旅客换乘行为,定义:Nhj为出行链中旅客在某节点j的换乘总次数,j∈{Sscz(xt(a)),Sxcz(xt(a)),Sczd|∀a=1,2,…,n};NhSczd为旅客在常住地节点的换乘次数。 结合概念和定义,可以得出出行链具有如下4点性质。 性质1:完整出行链开始于常住地、停止于常住地,即 性质2:完整出行链中,任意非常住地节点不连接2条断元,即 性质3:行程环及出行链中所有节点个数均等于所有基本元和断元个数之和加1,即 性质4:出行链中常住地节点个数为旅客常住地同城换乘次数与行程环个数和的2倍,即 性质1—性质3 可以根据行程环的定义或基本假设直接得出;性质4中,除同城换乘外旅客抵达常住地后行程环即停止,因此出行链中常住地节点个数只与行程环个数和常住地同城换乘次数相关。 行程环划分问题要依据出行特征对所有基本元进行归集和识别,将属于同一次出行的基本元划分至同一行程环,不同出行行程的基本元划分至不同行程环,从而实现对全年出行链的准确拆分,并对行程环中的不连贯行程进行断元补充。 定义任意2 个基本元xt(a)与xt(b)间距离为da,b,为保证行程环的划分结果能够满足同一行程环内的基本元距离最小、不同行程环间的基本元距离最大,考虑采用同行程环内基本元距离之和与不同行程环间基本元距离之和的比值,构造目标函数Z为 3.4.1 基础DBSCAN基本元聚类模型 从行程环划分问题的描述可知,其属于机器学习问题中的聚类问题。在行程环识别完成前,由于出行行程个数未知,即聚类簇个数不能作为已知参数代入模型,因此以基于密度的聚类算法DB‑SCAN 作为解决该问题的首选。DBSCAN 算法无须预先设定簇数量,具有效率、准确度和鲁棒性均较高的特点,已成功应用于多个领域[17-18],十分契合行程环识别问题。 DBSCAN 算法基于数据要素本身的欧式距离或绝对值距离对所有数据进行聚类,已较为成熟,具体建模过程不再赘述。 3.4.2 基于常住地特征的改进DBSCAN 基本元聚类模型 采用常用的欧式距离构建DBSCAN 算法基本元聚类模型(简称为“基础模型”),但其聚类结果无法完全捕捉旅客出行行为的主观性与随机性,导致模型精度差强人意,需要改进。为此,引入旅客的常住地属性及旅客年龄、出行日期、行程特征等一系列要素,深度捕捉旅客出行行为特征,提高模型精度。构建基于常住地特征的改进DBSCAN基本元聚类模型(简称为“改进模型”)的具体步骤如下。 1)步骤1:定义距离 基本元与基本元之间的距离计算是构建聚类算法的主要依据,对算法的精度具有重要影响。建模数据集是按出行顺序排列的行程记录集合,因此基本元间出行日期的时间距离可被视为定义距离的首要条件;之后,根据假设2 和假设3,基本元是否途径常住地是划分行程环的重要标准,若某基本元途径常住地,则可定义其与相连的基本元距离极大,从而进一步划分行程环;此外,基本元的其他相关出行属性也应作为参数计入距离之中。 因此将距离da,b的定义方式进行如下改进 其中, 式中:I1(·)和I2(·)均为逻辑变量;d0为模型设定的行程环划分阈值,当da,b 因所有距离项均不取负值,通过设定dp(xt(a),d0以满足业务上的行程环划分需求。所有距离不应小于阈值d0,即当出现da,b≥d0时,认为基本元xt(a)与基本元xt(b)不属于同一簇类、不在同一行程环之内。 对模型进行初始化设定,使X0=∅,X,为进入步骤2做好准备。 2)步骤2:准备新行程环Ci并随机选取初始基本元xt(a) 3)步骤3:将与初始基本元xt(a)属于相同行程环的基本元归入Ci 重复式(11)—式(15),直至Xb=∅。 4)步骤4:划分所有基本元 Xb为空后,表明未分类的基本元集合里无基本元可划入当前行程环Ci,当前行程环Ci包含的基本元划分完毕。此时若不为空,则继续重复步骤2—步骤3,直至=∅,表明基本元划分完毕。 5)步骤5:补充所有断元 (1)补充行程环内部的断元。若行程环内部断元出现在同一行程环内相邻的2 个基本元xt(a),xt(a+1)之间,当上一基本元的下车站与下一基本元的上车站不相同时,在该行程环内补充从xt(a)的下车站城市至xt(a+1)的上车站城市的断元,即 (2)补充行程环未在常住地结束的断元。当行程环Ci的最后1 个基本元xt(a)的下车站城市不是常住地时,在该行程环最后补充基本元xt(a)的下车站城市至常住地的断元即 (3)补充行程环未从常住地开始的断元。当行程环Ci的首个基本元xt(a)的上车站城市不是常住地时,在该行程环内补充常住地至基本元xt(a)的上车站城市的断元。根据断元的上一程分别为无行程(xt(a)为全年首个基本元时)、基本元或断元,其补充结果有所不同。 当xt(a)为全年首个基本元时,需补充断元即 6)步骤6:结束 当所有行程环断元补充完成时,计算结束。 3.4.3 行程环划分准确度验证 为验证对行程环划分的准确程度,将2019年的2 万份年度铁路行程数据作为测试集,分别代入基础模型和改进模型进行聚类分析并划分行程环,得到的结果见表1。由表1 可知:以常用的欧式距离为要素进行建模后,基础DBSCAN 模型的准确率为82.3%,实际应拆分行程的准确率略高于不拆分行程的准确率;引入旅客的常住地并采用通勤、跨节假日、基本元行程不连贯等出行行为特征属性后,改进模型对行程环的识别准确率大幅提升,达到97.4%;改进模型识别结果中发生第一类错误(拒绝正确值)和第二类错误(接受错误值)的概率相当,不存在显著偏差。 表1 2种DBSCAN模型的行程划分情况对比 划分得到所有旅客的行程环后,便可基于行程环对旅客的宏观行为特征进行深度分析。为直观展现旅客行程环状态、方便分类分析,将行程环按总行程个数分类后进行图形化展示,形成基本拓扑结构,直观展现旅客1个完整的行程环。在划分行程环拓扑结构的基础上,进一步形成旅客出行链拓扑结构,从而实现对旅客全年出行规律的直观、深入分类分析与总结沉淀。 3.5.1 行程环拓扑 对2019年全部铁路行程环进行统计,得到的行程环拓扑结构及其占比见表2。表中:行程环包含行程次数统计了所有的基本元和断元。由表2 可知:常住地的同城或往返行程环占比达75.3%;绝大多数旅客的行程环结构简单,出行目的地单一,行程环内基本元加断元不超过4个的行程占比超95%。 表2 旅客行程环拓扑结构 3.5.2 出行链拓扑 将旅客全年所有的行程环拓扑进行聚合,合并常住地与常到发目的地,会形成不同的出行链拓扑结构。基于不同的出行链拓扑状态,可以对旅客的年度出行特征进行直观、准确归类。 虽然旅客的单一行程环结构通常简单明确,但多数旅客的全年出行链为1种或多种不同类型的行程环结合形成。为实现对旅客出行链的清晰划分,按出行链中占大多数的行程环结构对出行链进行分类,可以形成6类不同的旅客出行链拓扑结构,分别将其命名为蒲公英型、宫灯百合型、荷花型、石竹花型、向日葵型以及白子莲型,如图6所示。 图6 常见出行链拓扑结构 每类出行链具有不同的行为特征,因此可以对应不同类型旅客的出行习惯,有效辅助相关决策部门判断旅客的出行需求与客流成分,为旅客全年出行规律与行为特征的深度挖掘与探索提供明确的分析框架和基础。 1)蒲公英型 对于呈现蒲公英型出行特征的旅客(简称为“蒲公英型旅客”,后同),全年出行链中超过50%的基本元属于关于常住地的同城或往返行程环,且这些行程环不是针对单一城市出行的。这类旅客群体的工作和生活均围绕唯一常住地展开,出行有较明显的规律,多为城市常住人口。 2)宫灯百合型 对于宫灯百合型旅客,全年出行链中超过50%的基本元属于围绕常住地和另一目的城市(通常为籍贯地)的往返或通勤行程环。这类旅客常在两地间往返出行,这种出行形式也是我国多数铁路旅客的典型出行状态。旅客群体多为学生、离乡在其他城市工作/通勤的人群、双城生活的老人等。 3)荷花型 对于荷花型旅客,全年出行链中超过50%的基本元属于“8”字形行程环。这类旅客在常住地停留时间最长,有较多行程环途径另一城市,或围绕该城市起止;也很可能短时间内居住于另一城市,并在该城市有较多出行,或者每次出行均需要经过大城市节点进行换乘。旅客群体多为异地长期项目、实习或者培训的人群。 4)石竹花型 对于石竹花型旅客,全年出行链中超过50%的基本元属于三角形、四边形或多边形行程环拓扑。这类旅客的行程环均围绕常住地起止,但通常每个行程环的目的地不只1个。旅客群体多为常在多地讲座的教师、多地出差的职员、多地旅游的旅客等。 5)向日葵型 对于向日葵型旅客,全年出行链中超过50%的基本元集中在同一个行程环中,且该行程环有多个目的地,并且持续时间也较长。这类旅客群体全年多数时间在外漂泊,仅在大型节假日或特定时点返回常住地;除常住地外,这类旅客在任意城市不会停留太久时间,出行也较为随机。旅客群体与石竹花型类似,但出行频次更高。 6)百子莲型 对于百子莲型旅客,全年出行链为多种类型行程环的组合,且每类行程环占比均未达到50%。这类旅客的出行不明显具备某特定链型的特征,或在不同时间段内的出行呈现不同的特征。 3.5.3 出行链拓扑结构统计 对2019年全年的旅客出行链进行分类,各类出行链拓扑结构比例如下图7 所示。由图7 可知:各类出行链中,蒲公英型与宫灯百合型旅客占比最多,合计占比72.4%,表明多数铁路旅客为单常住地散射状出行或双城间频繁出行;石竹花型旅客占比21.9%,这部分旅客的行程环会途径多个城市,每次出行目的地不单一或需要较多次换乘;荷花型和向日葵型旅客占比较低,仅存在于小部分特定旅客群中。 图7 2019年出行链拓扑结构占比 基于旅客常住地与行程环构建的年度出行特征分析体系使得许多传统铁路客运营销分析与管理难点问题得到解决,其中最具代表性的1项工作是实现了对铁路客流成分结构的划分。 传统面向宏观市场的营销分析手段无法有效识别旅客每次出行的目的,而不同的出行目的,如探亲、旅游、出差,旅客在出行时的经济承受度、时间紧迫度与旅行舒适度需求均不尽相同,并形成了不同的客流结构特征,传统的综合性铁路客运产品往往无法面面俱到地满足不同成分客流的实际出行需求。 旅客出行链拓扑结构为出行目的的识别提供了方法。在旅客出行链拓扑结构的基础上结合常住地、出行习惯、出行时期以及其他重要属性和要素,将复杂的客流结构识别问题简化拆分,实现旅客出行目的分类,其基本规则框架见表3。对于其中未涵盖到的类别,则可以在深入引入其他要素后进一步进行判断,不在此过多罗列。可以看出,在出行链拓扑结构的分类基础上,不同旅客的行程特征都得到清晰、准确的划分,使后续相关部门对旅客出行目的的判断更为准确、高效,并为铁路客流成分结构划分提供良好基础。 表3 旅客出行目的划分基本规则框架 运用2019年(疫情前)和2020年(疫情后)的全部铁路行程数据对铁路客流结构进行划分,并结合实际经验,验证划分效果及模型在实际业务中的适用性。根据2019—2020年的全部铁路行程数据对铁路客流结构进行划分的结果如下图8 和图9所示,可以看出许多显著的出行规律,与实际经验相符合。 图8 2019—2020年铁路客流成分结构划分 图9 2019—2020年不同客流结构占比月波动 (1)2年内的铁路客流中,公务客流占比最大,其次为探亲、旅游客流;对比2019年,2020年公务及探亲客流同比提升、旅游客流同比下降,符合疫情影响下的旅客出行需求变化规律。 (2)1年之中,1—2月春运期间的探亲客流占比显著提升,与春节传统习俗相符;五一假期、十一假期及暑期期间旅游客流占比显著提升,与旅客出游季节相符;其他时期,尤其是年底期间公务客流占比较高,符合生活经验。 (3)2020年2—4月疫情较严重期间,公务、旅游客流受影响最大,占比显著下降;剩下的铁路客流以刚需探亲(返程)为主;4月之后,全国疫情不断反复,旅游客流因此也维持在较低比例。直至“十一”长假,疫情全面好转,旅客“报复性出游”,旅游客流占比达到40%;5月起公务客流快速回升,并维持在35%~40%左右。 (4)对比不同客流结构在不同时期的占比表现可以发现,疫情对不同类型客流影响程度不同:探亲客流出行是“刚需”出行,受疫情影响相对较小;旅游客流最敏感,受疫情影响最大;公务客流受疫情影响后恢复速度最快。 可以看出,基于旅客年度出行链拓扑结构的客流结构划分与实际出行习惯基本相符,能够较好地反映旅客出行目的。基于不同客流结构所展现的不同特性,可以为管理部门灵活调整运力提供了辅助决策支撑。旅客年度出行特征分析体系的建立,为铁路管理部门深入了解旅客需求与市场动态提供了良好的分析手段和技术支撑。 除客流结构成分划分外,基于常住地与行程环的年度出行特征分析体系在许多重要的铁路客运日常工作中可以起到良好的应用效果。借助旅客的常住地与行程环,可以判断高峰期旅客的越站乘车风险,从而实现高峰期列车的超员预警,保障列车行车安全;借助旅客常住地的迁移和出行城市的变化,可以对未来不同地区的客流需求量变化进行预测,从而为构建车、时、价相协调的市场化定价机制提供助力,提质增效;通过分析旅客出行习惯的变化,可以对列车折扣票实施效果进行深入评价,为客运管理部门精准施策提供辅助参考。在许多传统客运营销手段表现得差强人意的场景中,年度出行特征分析体系能够为管理部门解决问题提供新角度、新思路,使客运管理部门能够更加准确、深入地把握旅客需求,从而提升产品服务能力,最大化能力运用效率。 未来,基于年度行为特征分析体系可进一步深入探索挖掘旅客真实出行需求的方法与手段,拓展在客运市场化营销工作中的潜在应用场景,辅助客运管理部门了解旅客出行习惯,捕捉客运市场变化趋势,实现面向旅客的客运服务质量升级与个性化客运产品优化。 (1)为研究旅客出行特征规律,提出旅客常住地、行程环、出行链拓扑结构等概念,构建能够全面覆盖旅客全年出行行为中所有点(到发城市)、线(单次行程)、面(出行链拓扑结构)的铁路旅客群体年度出行特征分析体系。 (2)基于随机森林算法构建旅客常住地识别模型,经数据训练并优化后,能够根据旅客全年行程数据,准确判断其在该年度的唯一常住地。 (3)在明确出行链性质的基础上,构建基于常住地特征的改进DBSCAN 基本元聚类模型。统计2019年2万份年度铁路行程数据,证实改进模型对行程环的识别准确率大幅提升,达到97.4%,且识别结果符合实际工作经验。 (4)根据2019年旅客铁路行程数据,得到旅客行程环与出行链的拓扑结构,结合工作经验可知拓扑结构及占比均符合实际工作经验,能够将旅客杂乱的出行轨迹高效划分与归集。从行程环来看,当年常住地的同城或往返行程环占比达75.3%;绝大多数旅客的出行目的地单一,超95%的旅客铁路年内出行次数不超过4次;从出行链来看,当年多数铁路旅客为单常住地散射状出行或双城间频繁出行,占比72.4%。 (5) 利用旅客年度出行特征分析体系分析2019~2020年全部铁路行程数据,证实这一体系得到的客流结构划分结果与实际出行习惯基本相符,能够将传统复杂的客流结构识别问题简化拆分,对旅客出行目的进行判断和识别。该分析体系可为相关管理部门挖掘旅客出行需求、灵活调整运力提供辅助决策支撑。3.3 出行链性质

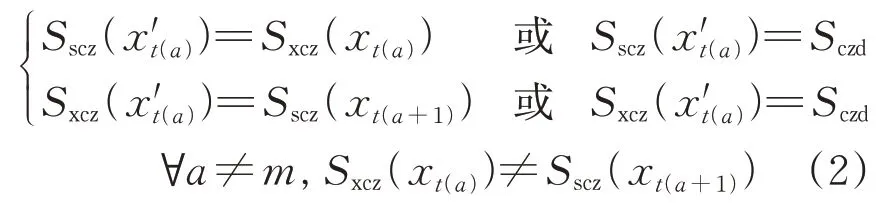
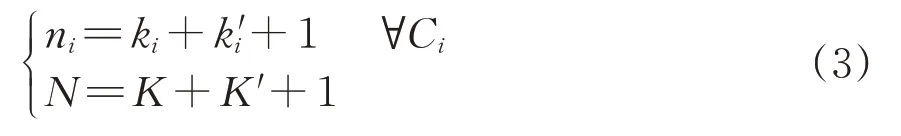

3.4 行程环划分建模


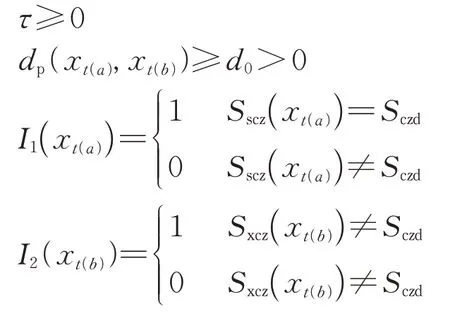

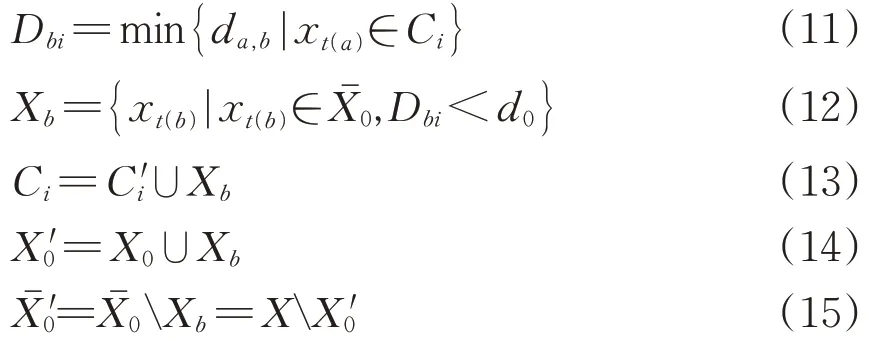
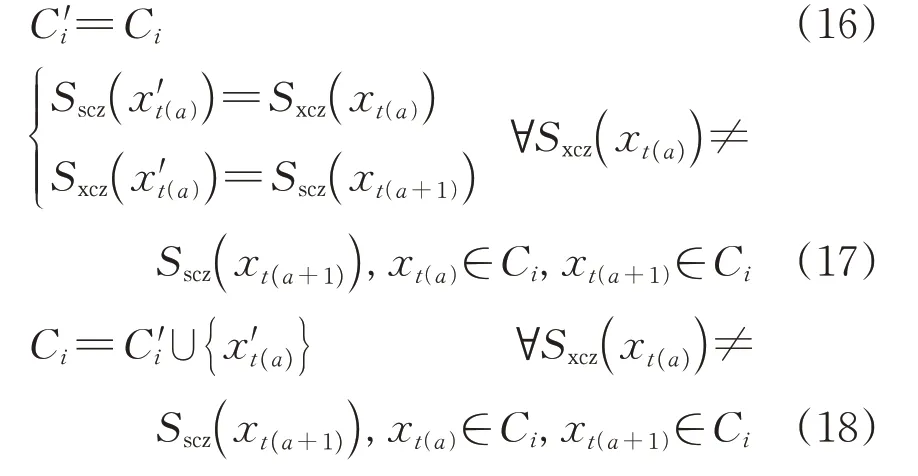

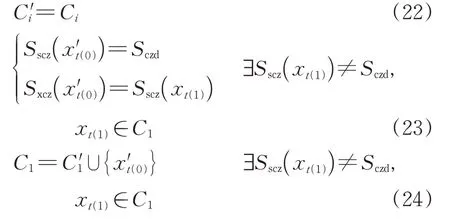

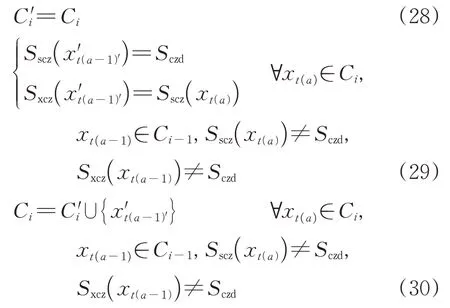
3.5 行程环与出行链拓扑结构

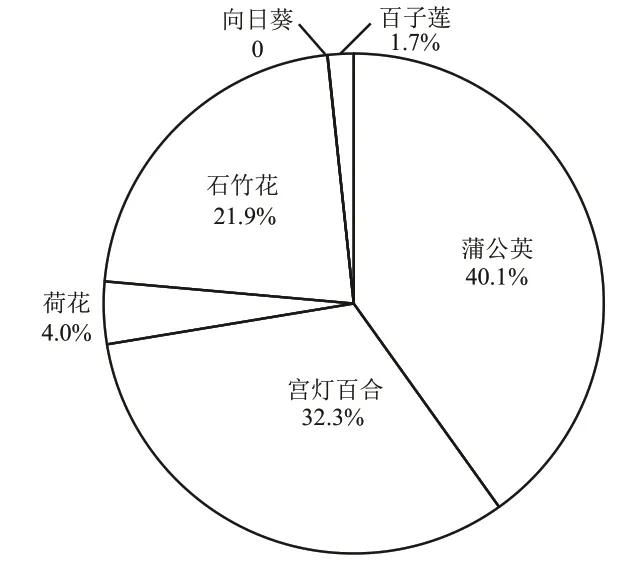
4 模型结果应用
4.1 铁路客流成分结构划分
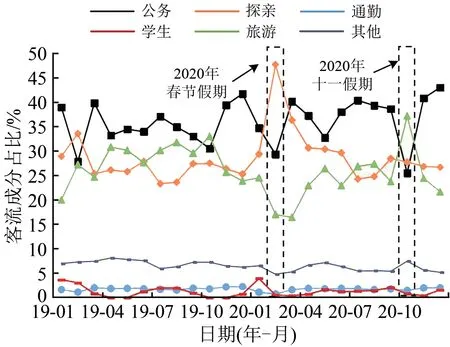
4.2 实例分析

4.3 应用拓展及展望
5 结 论
猜你喜欢
环球时报(2022-12-12)2022-12-12 17:14:03小哥白尼(趣味科学)(2021年3期)2021-07-16 07:47:32云南画报(2021年12期)2021-03-08 00:50:54铁道通信信号(2018年7期)2018-08-29 01:17:04故事大王(2018年3期)2018-05-03 09:55:52空中之家(2016年1期)2016-05-17 04:47:43通信电源技术(2016年4期)2016-04-04 02:58:04工程建设与设计(2016年3期)2016-02-27 10:50:46北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:37中央民族大学学报(自然科学版)(2015年2期)2015-06-09 08:45:20
