
基于Look-alike和K-means算法的音乐冷启动问题研究
2022-09-29 01:10:22王屯屯
电脑知识与技术 2022年23期
关键词:冷启动
王屯屯


摘要:在音乐推荐领域,根据用户的行为习惯进行偏好建模并进行推荐。但是对于热度较低的音乐,由于很少有用户进行消费,几乎得不到推荐,导致系统中的马太效应越发明显,不利于音乐平台的长期发展。基于look-alike框架针对冷门音乐分别进行建模,训练周期较长,且由于样本数量少,模型效果不理想。利用K-means算法对冷门歌曲进行聚类,再投入look-alike框架进行训练,训练周期大幅度缩短,且推荐准确率更高。
关键词:Look-alike;kmeans;音乐推荐;冷启动
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)23-0001-02
1引言
随着互联网的飞速发展以及智能移动终端的普及,随时随地听音乐已经成为当代社会的一种常态。面对海量音乐,主动检索和排行榜成为很多人的选择。推荐系统的推出,可以很好地主动为用户提供音乐[1]。推荐系统一般需要大量用户日志信息作为支撑[2],但是冷门音乐相关训练数据较少,推荐效果不佳,因此需要针对冷启动状态下的音乐制定特殊推荐算法。一种可行的思路是根据冷门音乐的消费群体,找到与这些用户相似的目标用户进行推荐。而look-alike的工作机制就是基于用户画像和社交关系找到相似用户,因此该算法适合用于解决音乐冷启动问题。但是在该算法框架中,需要为每首音乐进行模型训练,使得推荐的音乐数量较少,并且每首音乐消费用户较少,训练样本不足,导致模型准确率不高。K-means算法作为复杂度较低的聚类算法,可以快速地将相似的音乐进行聚类,然后将该群体下音乐集中起来进行训练,不仅可以扩大样本数量,还可以提高look-alike的效率。
2 相关工作
针对推荐系统物品冷启动问题,很多研究者提出自己的算法。SAVESKI等人[3]综合考虑物品的内容特征和消费该物品的用户产生的行为特征,将这两个特征矩阵一起分解。借助矩阵分解可以实现精准的推荐,在此基础上利用物品的内容特征实现物品冷启动。LIU等人[4]在协同过滤的基础上,再次进行内容过滤实现物品冷启动。通过虚拟分配项目的信息文件,在进行内容筛选的基础上,借助传统的协同过滤框架得到推荐结果。陈克寒等人[5]基于两个阶段的聚类过程,在考虑图摘要算法的基础上,通过常规的内容相似算法,得到较为理想的推荐结果。文献[6]基于look-alike框架,借助于种子用户与目标用户间的行为相似性,达到受众扩展目的。此外,考虑到种子的不同成员,为了达到目标用户的自适应学习的健壮性,在局部attention单元的基础上,还精心设计了全局attention单元。为了降低时间性能消耗,对Seeds进行了聚类操作,不仅训练变快,而且最大限度地减少了种子信息的丢失。
3 模型介绍
3.1 Look-alike
Look-alike模型由Facebook公司于2013年发表,最初的目的是为广告主寻找与已有广告(种子)类似的潜在用户群体。本文将冷门音乐作为广告,根据已经消费过冷门音乐的用户,发掘相似的用户进行音乐推荐,从而提高冷门音乐的热度,缓解系统中的马太效应。Look-alike框架根据具体实现的算法,主要分为三种:基于相似度,基于逻辑回归以及基于注意力深度学习模型。
(1)基于相似度的look-alike模型
基于相似度的look-alike模型是最直观、最简单的一種方法:选取某种相似度评价指标,计算种子用户与目标用户的相似度,降序排序并取头部用户进行投放。常用的相似度指标包括:余弦相似度和Jaccard系数。
余弦相似度主要针对具备连续值属性特征,具体定义如下:
其中N表示特征数量,Uik和Ujk分别表示用户Ui和Uj的第k维特征的取值。
Jaccard系数主要针对具备离散值属性特征,具体定义如下:
其中U(i,j)表示用户Ui和用户Uj特征值相同,TUik和TUjk分别表示用户Ui和Uj在k维特征上进行的截断值。
定义好两个用户间的相似度后,需要定义目标用户Ut与种子用户群体Seeds间的相似度,主要方式有取最大值simmax和平均值simmeans,具体定义如下:
其中sim(Ut,Us)的计算方式,要根据具体需求确定。基于相似度的实现方法设计比较简单,但是当数据规模较大时,时间复杂度比较高。
(2) 基于逻辑回归的look-alike模型
该方式将look-alike作为概率预测问题,而该问题通常借助二分类任务进行,通过逻辑回归预测目标用户的喜欢程度。模型的效果取决于样本的质量,因此数据集的生成至关重要。正样本比较好获取,可以直接采用种子用户的行为,对于负样本一般选择所有非种子用户的数据。
(3)基于深度学习的look-alike模型
该实现方式最具代表性的是由腾讯发布的look-alike系统,用于缓解微信的“看一看”中存在的马太效应。该模型将用户的行为送入word2vector模型训练,得到Embedding特征,并且将特征分为离线训练和在线处理两部分,并且将常用的softmax改为negative sampling,而损失函数则采用传统的sigmoid cross entropy。
3.2 融合K-means模型
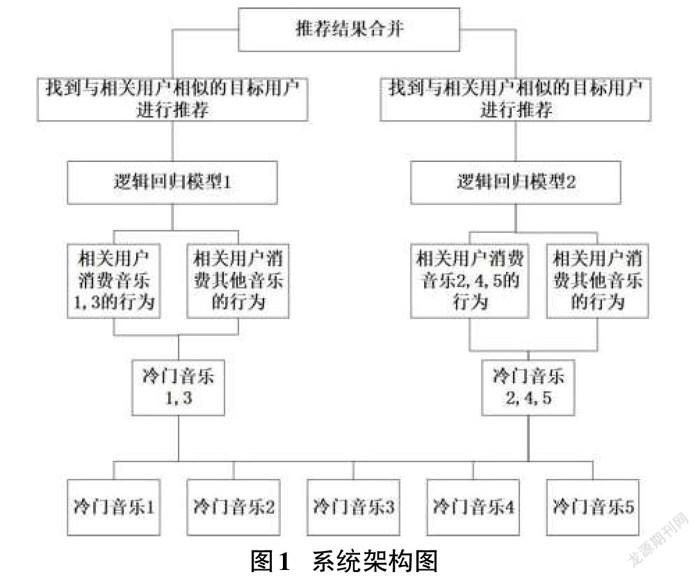
本文采用基于逻辑回归的look-alike模型解决音乐冷启动问题,模型结构如图1所示:
传统的look-alike框架会为每一首音乐训练模型,并进行推广。但是这样会对计算性能要求比较高,训练周期较长。此外,单首音乐的样本数据较少,模型训练效果不佳。根据启发式算法,相似的音乐会被同一批人喜欢,这里将所有音乐送入K-means模型进行聚类,将相似的音乐归入一类进行模型训练和目标用户投放。
图中音乐1和音乐3比较相似,被划分为一个簇,音乐2、音乐4和音乐5被划分到另外一个簇。将这两个簇内相关用户对簇内音乐的行为作为正样本,相关用户对簇外音乐的行为作为负样本,分别训练逻辑回归模型。最后将目标用户送入训练好的模型,提取消费概率最高的用户进行投放。
4 实验
本章节对算法框架进行了详细的阐述,将通过投放准确度和时间消耗两方面分别验证本文所提模型的优势。本文实验所采用数据为真实互联网公司脱敏后的用户行为数据。
4.1 评价指标
在投放准确度方面,这里采用AUC评价指标,具体定义如下:
其中Rk表示第k个正样本所在的位置,i表示正样本数量,j表示负样本数量。该评价指标的取值范围为[0,1],值越大,代表模型的效果越好。
在对模型的时间消耗评价方面,会计算每个模型推送M首音乐时所需要的总时间。总时间分为数据预处理、模型训练、结果预测以及数据推送四个步骤。由于数据预处理和数据推送对每个模型保持一致,因此只计算模型训练和结果预测的时间进行对比。
4.2 实验设置
提取用户的音乐历史行为,行为类型包括:播放,收藏以及下载。将播放时间小于10秒的用户行为设置为负样本,其他行为设置为正样本。此外,考虑到负样本数量太少,将这些用户对应的其他音乐收藏下载行为也设置为负样本。
将“用户-音乐”行为进行倒排,获取每首音乐对应的用户数量UNUM,将UNUM分布在[10,100]的音乐作为冷门音乐进行实验。数量小于10的音乐,用户行为过少,训练出来的模型效果较差;数量大于100的音乐,暂时不认定为冷门音乐。
4.3 实验结果
本文所提模型LAKM(Look-alike based on K-means),首先将所有音乐的以后行为送入K-means模型进行聚类,将相似的音乐作为一个整体,每个簇训练一个逻辑回归模型,预测目标用户对簇的喜欢程度,按照打分降序取TOPN进行推荐。对比模型look-alike直接为每一首音乐训练逻辑回归模型并进行投放。具体实验结果如图2和图3所示:
通过实验结果发现,本文所提模型LAKM在AUC和TIME上均优于对比模型look-alike。LAKM模型通过K-means方法进行聚类,该聚类算法较为简单,耗时较短,而以簇为单位进行投放,训练的逻辑回归数量远远小于对比模型,因此所需时间极大缩减;相较于单首音乐,多首相似音乐的用户行为明显较多,训练出来的模型效果更好,因此能够更好地进行音乐推送。
5 总结与展望
在利用look-alike框架投放冷门音乐时,需要每一首音乐训练逻辑回归模型。利用K-means對冷门音乐进行聚类,找到相似的音乐作为一个整体进行推荐,不仅可以提高样本数量,还降低了训练模型的数量,在提高投放准确度的同时,降低了训练时间,使得更多音乐可以得到投放机会,解决音乐推荐的冷启动问题。在特征选择方面,只采用了音乐的Embedding特征,后续将考虑加入更多音乐特征。
参考文献:
[1] 田杰,胡秋霞,司佳豪.基于深度信念网络DBN的音乐推荐系统设计[J].电子设计工程,2021,29(23):162-165,170.
[2] 乔雨,李玲娟.推荐系统冷启动问题解决策略研究[J].计算机技术与发展,2018,28(2):83-87.
[3] Saveski M,Mantrach A.Item cold-start recommendations:learning local collective embeddings[C]//Proceedings of the 8th ACM Conference on Recommender systems.Foster City,Silicon Valley,California,USA.New York:ACM,2014:89-96.
[4] Liu H S,Goyal A,Walker T,et al.Improving the discriminative power of inferred content information using segmented virtual profile[C]//Proceedings of the 8th ACM Conference on Recommender systems.Foster City,Silicon Valley,California,USA.New York:ACM,2014:97-104.
[5] 陈克寒,韩盼盼,吴健.基于用户聚类的异构社交网络推荐算法[J].计算机学报,2013,36(2):349-359.
[6] Liu Y D,Ge K K,Zhang X,et al.Real-time attention based look-alike model for recommender system[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.Anchorage AK USA.New York,NY,USA:ACM,2019:2765-2773.
【通联编辑:闻翔军】
猜你喜欢
环境污染与防治(2022年9期)2022-09-22 05:15:52
重庆大学学报(2022年6期)2022-06-23 07:32:50
Advances in Atmospheric Sciences(2022年6期)2022-04-02 05:29:02
汽车实用技术(2021年17期)2021-09-23 09:46:36
客联(2021年2期)2021-09-10 07:22:44
佳木斯大学学报(自然科学版)(2020年1期)2020-02-12 05:24:23
北京汽车(2017年6期)2017-12-29 00:34:38
商业经济(2017年6期)2017-06-15 07:56:12
科技创新与应用(2017年3期)2017-02-18 15:49:29
科技视界(2016年13期)2016-06-13 17:04:56
