
一种轻量型YOLOv5交通标志识别方法*
2022-09-28 07:08李志刚
电讯技术 2022年9期
李志刚,张 娜
(华北理工大学 人工智能学院,河北 唐山 063210)
0 引 言
随着深度神经网络的发展,交通标志图像识别精度越来越高,与此同时其层数也在不断加深,从而增加了模型的复杂度,导致了交通标志识别实时性不佳的问题。
在交通标志识别领域中,YOLO(You Only Look Once)深度学习算法因其良好的识别性能格外引人注目,从2016年Redmon等人[1]提出目标识别领域的YOLOv1模型开始,YOLO系列便不断推陈出新,2020年推出了YOLOv5模型,其性能最佳,适合实际工程的应用。目前许多学者将YOLO系列应用于交通标志领域,取得了不错的效果[2-3]。对于交通标志识别,实时性是一个非常重要的指标。虽然上述研究中针对YOLO系列模型提出了一些轻量化的方案,但是最小模型内存也为14 MB,对于一些资源受限的平台达不到实时性的要求。因此,对于车载系统的部署,仍需进一步轻量化模型,来达到实际工程应用的目的。
为了降低YOLOv5模型的复杂度,提高交通标志识别速度,降低YOLOv5模型对自动驾驶环境感知硬件配置的要求,本文提出了一种轻量型YOLOv5模型。在保证识别精度的同时提高交通标志识别的速度,更适合自动驾驶环境感知设备的部署。
1 轻量型YOLOv5模型
图1给出了轻量型YOLOv5模型结构,可以看出一共由输入、主干网络、Neck和识别四部分组成。本文以YOLOv5神经网络为基础模型,对主干网络进行整体替换。由于轻量级目标检测网络Peleenet[4]中的Stem模块可以在不增加计算量的情况下提取到更多的图像特征,因此首先采用Stem模块作为交通标志图像的特征提取模块。在目前的轻量化神经网络中,Shufflenetv2[5]神经网络采用分组卷积和通道清洗技术实现了速度和精度的平衡,因此本文采用Shufflenetv2模型的基本单元结构来替换YOLOv5的主干网络,达到轻量化模型的目的。Neck部分进行卷积、上采样、连接等操作,混合和组合主干网络提取的交通标志图像特征,并将图像特征传递到识别任务,最后输出交通标志识别的结果。
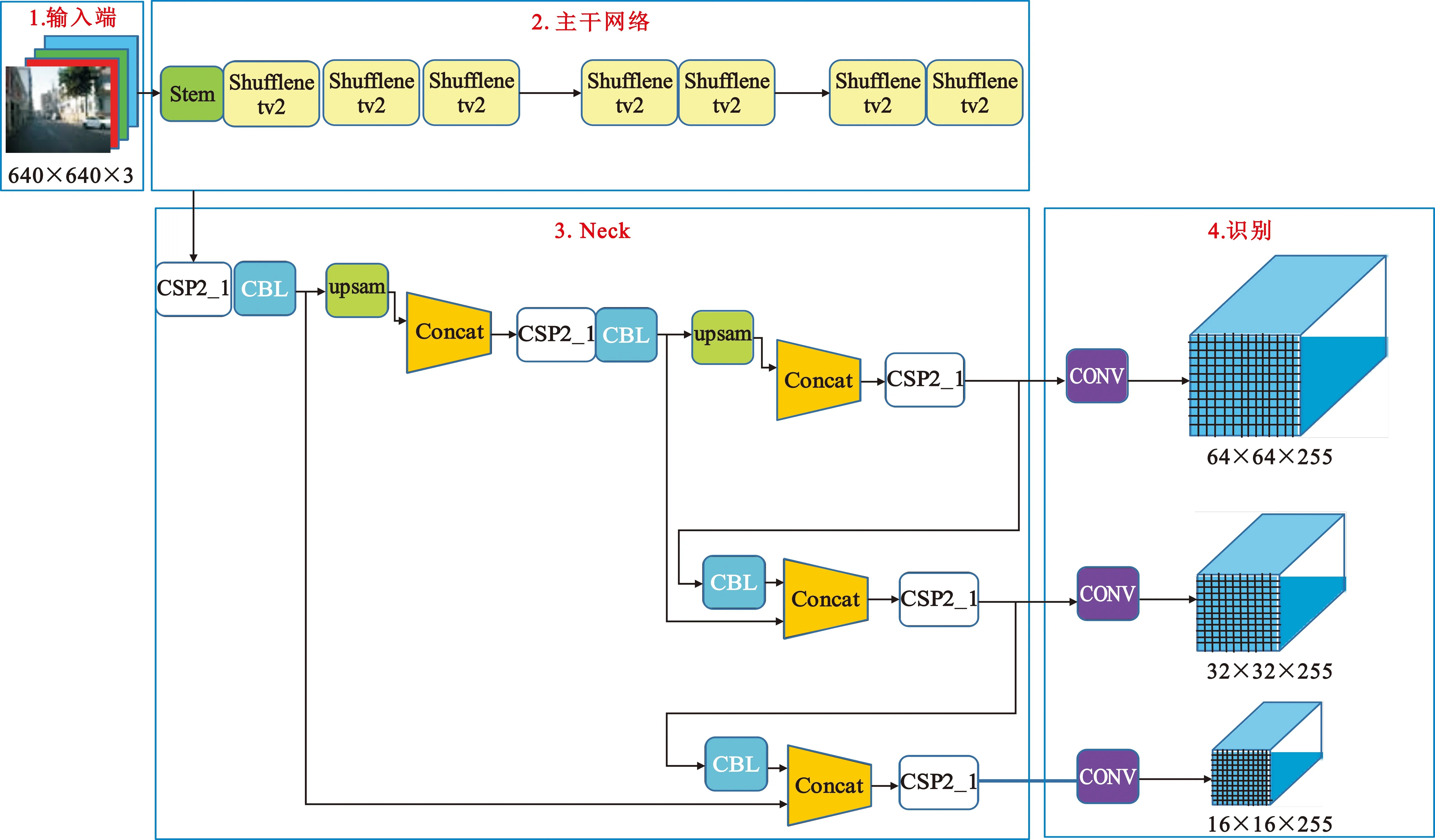
图1 轻量型YOLOv5模型结构
本文采用遗传学习算法和K-means聚类首先确定适合交通标志识别的锚框(anchor),然后再将合适的anchor应用到轻量型YOLOv5模型上进行训练。为进一步提升交通标志识别的准确率,采用了集成学习技术。
1.1 主干网络
1.1.1 Stem模块
Stem模块来源于移动端实时目标检测模型Peleenet。图2给出了Stem模块结构图:首先进行快速降维操作,采用卷积核为3×3步长(stride)为2的卷积层实现;然后采用了两分支的结构,一个分支用步长为1卷积核为1×1的卷积层和步长为2卷积核为3×3的卷积层,另一个分支使用了一个步长为2卷积核为2×2的最大池化层(maxpool)。Stem模块增加了输入图像空间维度的通道数,进行了第一次降采样任务,可以丰富特征层保持较强的交通标志图像特征表达能力,不增加额外的计算量,是一个代价较小的模块。
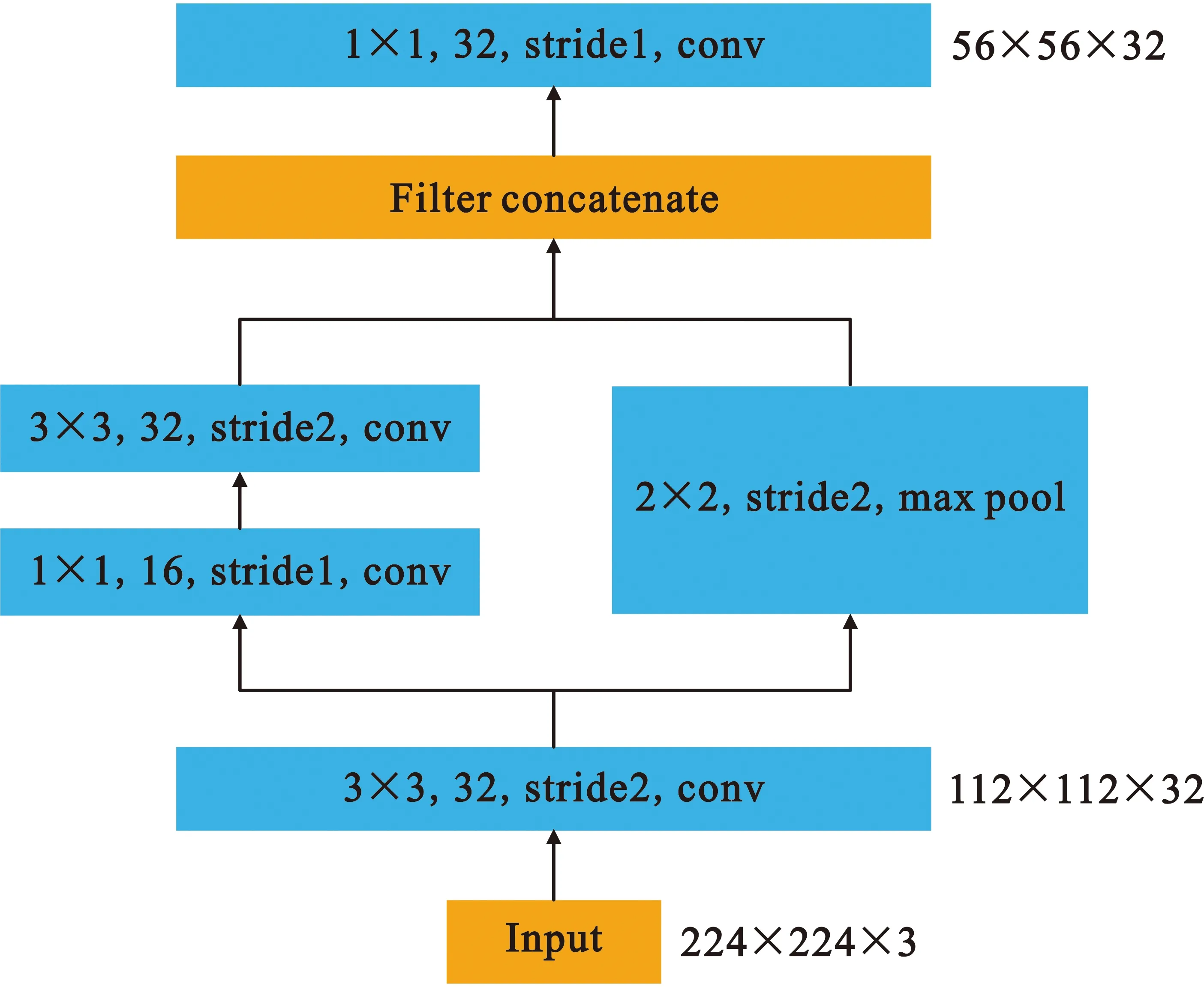
图2 Stem模块结构图
1.1.2 Shufflenetv2基本单元结构模块
图3(a)给出了Shufflenetv2的基本单元结构示意图,可以看出采用通道拆分(Channel Split)的操作,每个基本单元将通道的输入拆分为两个分支,一个分支做恒等映射,另一个分支经过两个卷积核为1×1的普通卷积层(Conv)和一个卷积核为3×3的深度可分离卷积层(Depthwise Convolution,DWConv)之后将两个分支进行拼接(Concat),保证输出通道数与输入通道数相同,达到提高速度的目的。图3(b)给出了Shufflenetv2的空间下采样单元结构,可以看出空间下采样单元步长为2,去掉了通道拆分运算,因此,输出通道数量变为输入数量的两倍。YOLOv5的主干网络则采用Shufflenetv2的基本单元和下采样单元交替堆叠而成,可以极大地降低YOLOv5模型复杂度,减少所需内存和参数量,达到轻量化模型的目的。
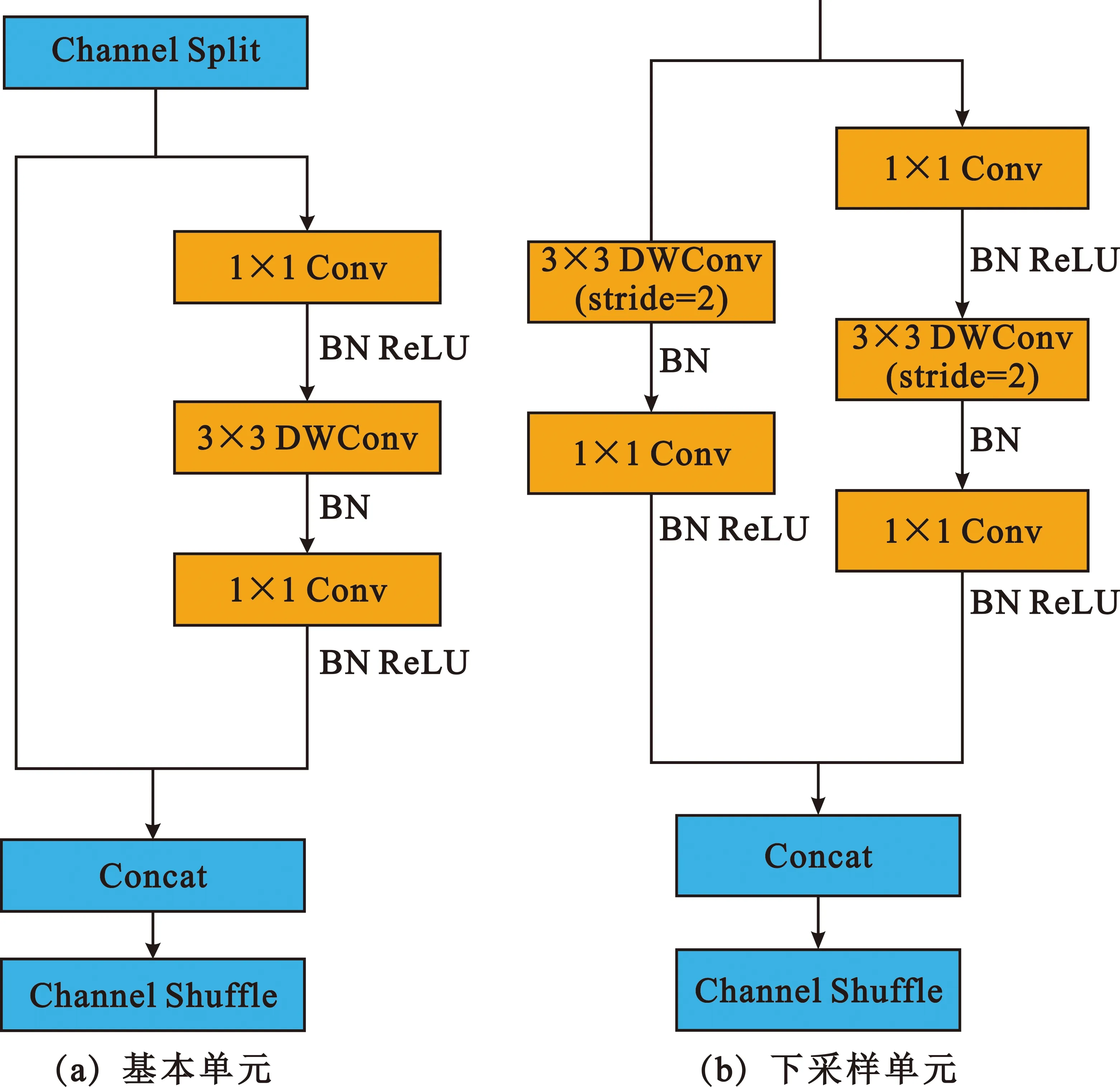
图3 Shufflenetv2结构
1.2 遗传学习算法和K-means聚类
本文将遗传学习算法应用到K-means聚类上,来自动寻找全局最优的交通标志锚框。图4给出了选择交通标志锚框流程图,可以看出只有当初始设定锚框的最佳召回率小于0.98时才会应用遗传学习和K-means聚类去选定适合交通标志小目标的锚框。
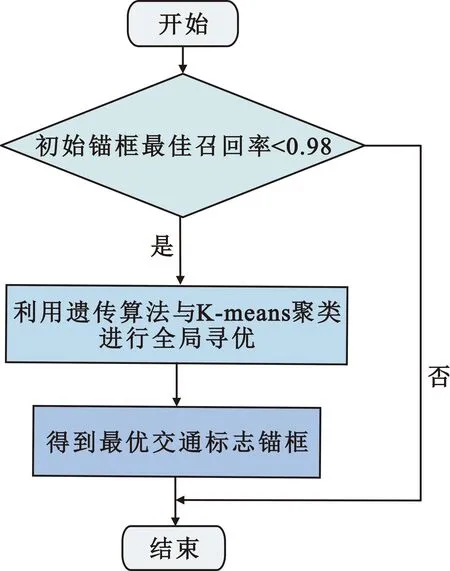
图4 交通标志锚框流程图
1.3 集成学习
集成学习[6](Ensemble)是指通过不同方法或算法训练的模型,组合起来产生最终结果的过程。集成学习可以胜过单一算法模型,该方法在进行交通标志识别时寻求群体的智慧。即使集成模型在模型中具有多个基础模型,它仍作为单个模型运行和执行,即运行一次就可以得出结果。
本文采用集成学习技术,将经过交通标志数据集训练的YOLOv5模型的权重和轻量型YOLOv5模型的权重进行集成,可以达到进一步提升交通标志识别准确率的目的。
2 实验与分析
2.1 实验配置和评价指标
实验平台为Ubuntu18.04操作系统,Pytorch深度学习框架,硬件配置为GPU NVIDIA GeForce GTX 2080 Ti,12 GB显存。本文模型及对比模型实验结论均在此实验配置环境中得出。
为评价轻量型YOLOv5模型在中国交通标志检测数据集上的性能,与Faster RCNN[7]模型、YOLOv4模型、YOLOv5模型在上述统一实验配置环境中进行对比实验,采用检测速率帧每秒(Frame per Second,FPS)以及均值平均精度(Mean Average Precision,mAP)、内存大小、参数量和每秒符点运算次数(FLOPs)作为评价指标。AP和mAP的计算如公式(1)所示:
(4)重砂异常标志:矿区主要的铌钽矿脉与铌钽铍重砂异常晕圈长轴方向基本吻合, 铌钽铍等稀有金属重砂异常可以作为重要的找矿标志。
(1)
式中:mAP是计算交通标志三大类别的平均精度(Average Presison,AP)的均值。
2.2 实验数据
实验数据来源于中国交通标志检测数据集[8](CSUST Chinese Traffic Sign Detection Benchmark,CCTSDB),该数据集共有训练集15 724张图片,测试集400张图片。图4给出了交通标志每类的样例,可以看出一共三大类,即警告交通标志、指示交通标志和禁止交通标志。

图4 交通标志
图5给出了三类交通标志图片数量,可以看出警告标志(warning)4 000余张图片,指示标志(mandatory)6 000余张图片,禁止标志(prohibitory)10 000余张图片。
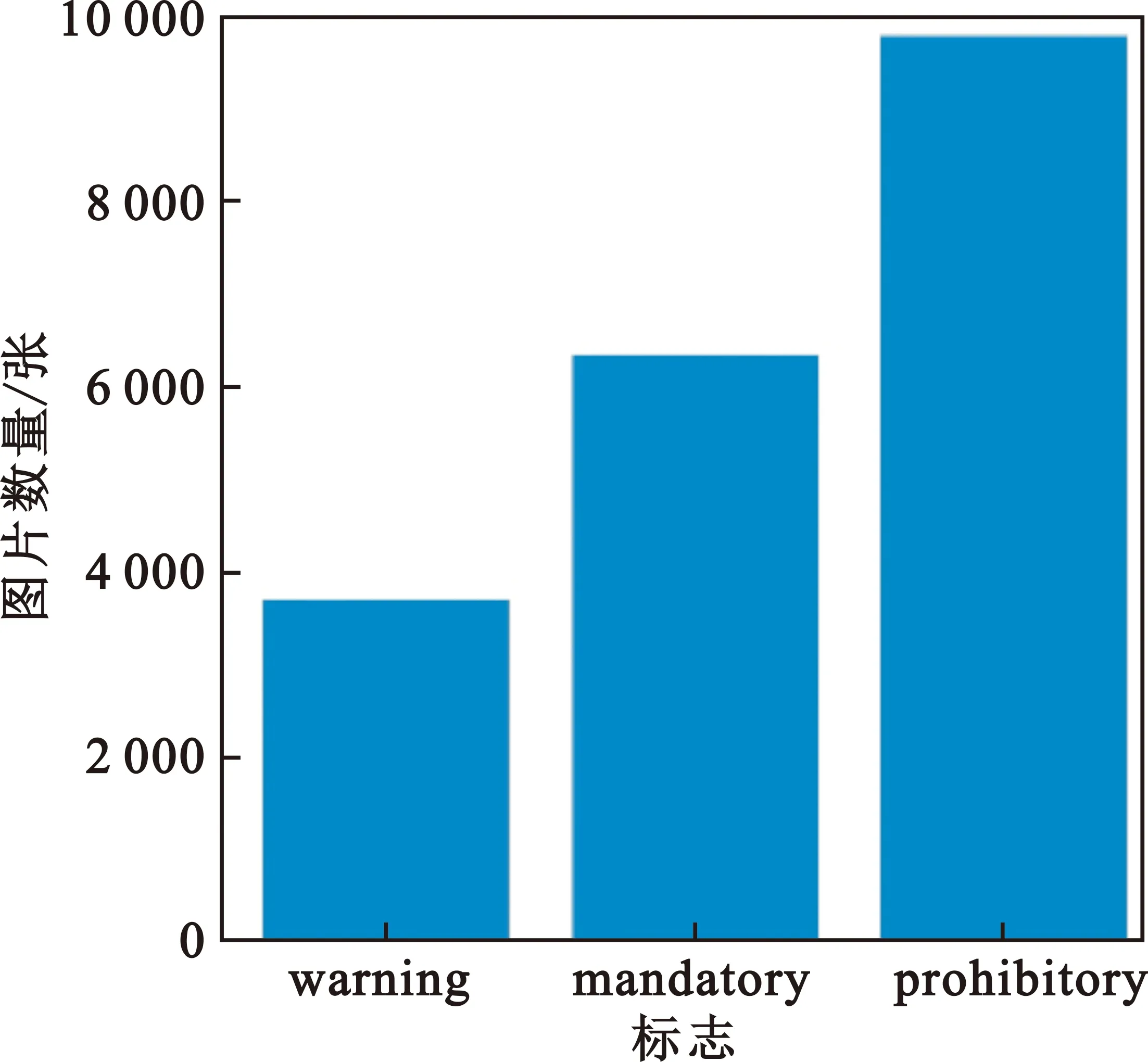
图5 交通标志图片数量
2.3 数据预处理
2.3.1 anchor的设置
对于交通标志识别,anchor的设置会影响到轻量型YOLOv5模型的最终效果。本文anchor是根据CCTSDB数据集中交通标志图像的大小设置的。采用初始的anchor基于shape阈值对bbox计算最佳召回率,如果召回率大于0.98,则不用设置,如果小于0.98,则采用K-means聚类和遗传学习算法对CCTSDB数据集进行重新设置。本文小于0.98,因此需要重新设置适合交通标志小目标识别的anchor,重新设置的anchor值为[11,11,15,15,18,18]、[24,23,15,40,33,32]和[31,81,53,53,102,113],其中第一行数据是最大交通标志特征图上的anchor,第二行数据是中间交通标志特征图上的anchor,第三行数据是最小交通标志特征图上的anchor,对本文交通标志识别实验是合理的。
2.3.2 数据增强策略

图6 mosaic数据增强
2.4 实验结果与分析
表1给出了轻量型YOLOv5模型的超参数设置,可以看出训练代数为50代,批次大小为4张。在正式训练之前,首先进行了3代预热学习,其中预热学习动量为0.8,预热初始学习率为0.1,目的是使模型经过预热学习慢慢趋于稳定,再进行正式训练交通标志识别的效果更佳。其余超参数设置如表1所示。
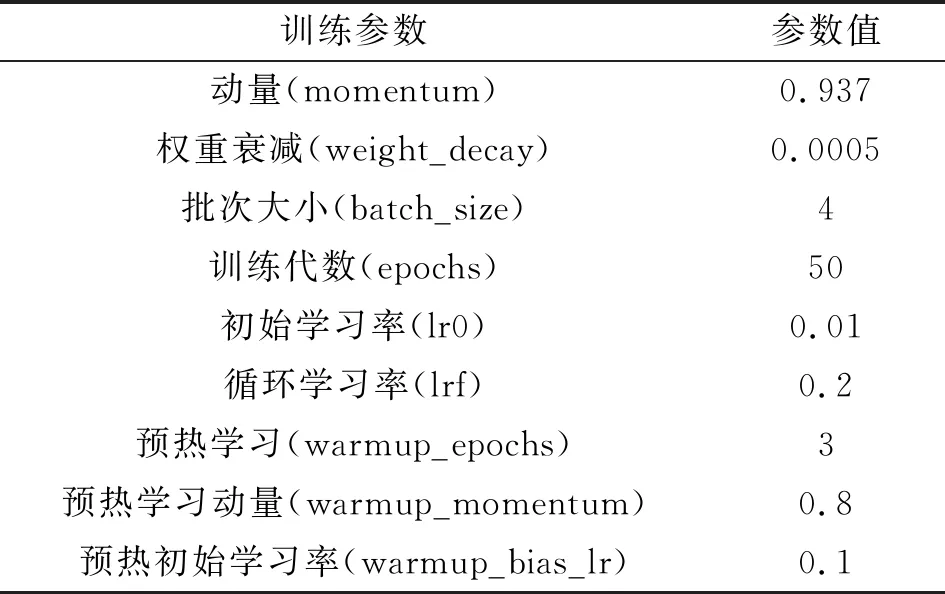
表1 超参数设置
2.4.1 模型大小对比
本文首先从模型的大小来进行分析,与Faster RCNN模型、YOLOv4模型、YOLOv5模型进行对比实验。表2给出了不同模型的三项衡量指标,可以看出轻量型YOLOv5所需内存为0.84 MB,参数量为321 504,FLOPs为74 620 728,与Faster RCNN、YOLOv4、YOLOv5模型相比所需内存分别减少了99.2%、99.6%、93.9%,参数量分别减少了98.7%、99.5%、95.4%,FLOPs分别减少了99.97%、99.7%、92.5%,极大地降低了模型的复杂度,显示了轻量型YOLOv5模型运用在交通标志领域优越的性能。
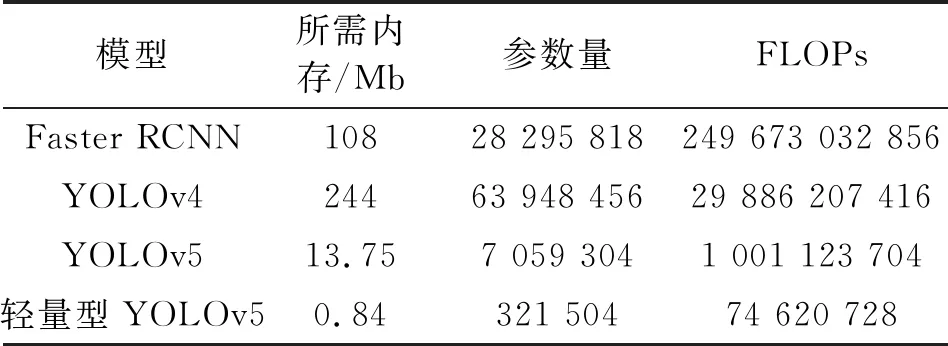
表2 模型大小对比
2.4.2 模型性能对比
其次,从模型的性能来进行分析。表3给出了不同模型在交通标志上识别的结果,可以看出在CCTSDB数据集上,本文所提出的轻量型YOLOv5模型mAP可达95.9%,相对于Faster RCNN、YOLOv4分别提高了24.3%、16.2%,与YOLOv5模型相比下降了约1.9%。关于识别速度,在性能一般的GeForce GTX1650、显存大小为4 GB的GPU上,轻量型YOLOv5模型的识别速度为143 frame/s,相对于Faster RCNN、YOLOv4、YOLOv5模型识别速度分别提高了97%、90%、80%;在资源受限i5-9300H、内存大小为8 GB的CPU上,轻量型YOLOv5模型识别速度为20 frame/s,相对于Faster RCNN、YOLOv4、YOLOv5模型识别速度分别提高了99.9%、99.8%、75%。通过上述实验数据分析可知,本文提出的轻量型YOLOv5模型在保持mAP为95.9%的前提下,在性能一般的GPU甚至CPU上都极大地提高了交通标志识别的速度。因此,本文轻量型YOLOv5模型在保持较高mAP为95.9%的同时提高了在交通标志识别上的实时性,降低了对自动驾驶环境感知硬件设备的依赖性,对交通标志识别有一定的实际应用价值。
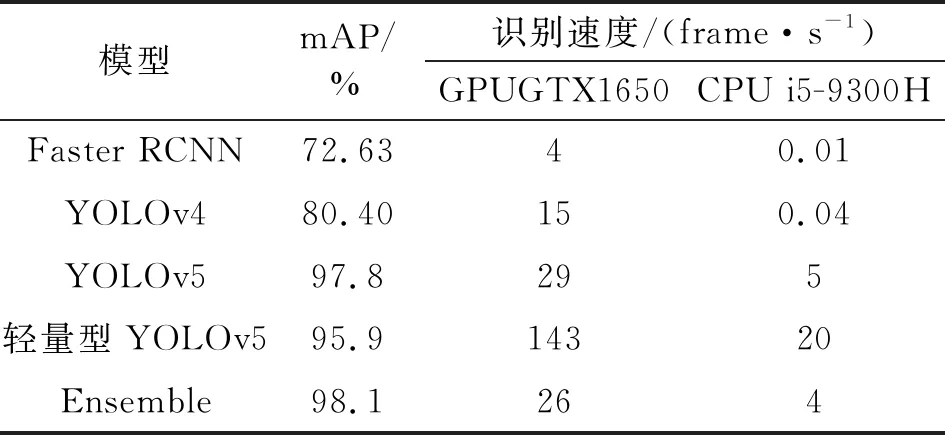
表3 模型性能对比
为进一步验证轻量型YOLOv5模型的实用性,从唐山市交通路况中随机采集两张交通标志图像进行识别,两张图片包括了三大类型的交通标志,具有一般代表性。图7给出了轻量型YOLOv5识别结果,可以看出左图交通标志图片识别效果良好,三个禁止标志和一个指示标志共四个交通标志都识别出来且识别正确;右图交通标志图片中前方学校的警告标志被识别出来且识别可信度为0.94,验证了轻量型YOLOv5模型在交通标志小目标识别上的实用性。

图7 轻量型YOLOv5识别结果
2.4.3 集成学习
最后,为了进一步提升交通标志识别准确率,本文采用了集成学习方法将YOLOv5模型训练的权重和轻量型YOLOv5模型训练的权重进行集成,表3的最后一行给出了集成的效果,可以看出mAP达到98.1%,优于YOLOv5模型的97.8%和轻量型YOLOv5模型的95.9%。由于采用集成学习,因此无论是在GPU上还是CPU上识别速度均有所下降,但在配置良好的环境感知硬件设备上,也能得到实际应用价值。图8给出了集成学习识别交通标志结果,可以看出左图四个交通标志全部识别出,且识别可信度为0.94,优于上述轻量型YOLOv5识别结果可信度的0.65;右图单张交通标志识别可信度为0.94,与上述轻量型YOLOv5识别结果可信度0.94相同,证明了集成学习有利于提升交通标志识别精度,显示了集成学习应用于交通标志识别的有效性。

图8 集成学习识别结果
3 结束语
交通标志识别在无人驾驶中具有举足轻重的地位。本文提出了一种轻量型YOLOv5交通标志识别算法,采用Stem模块提取交通标志图像特征,并与轻量化模型Shufflenetv2基本单元网络一起替换YOLOv5主干网络,达到降低模型的复杂度的目的。与一些经典的交通标志识别算法在CCTSDB数据集上进行对比实验,结果表明在保持交通标志图像mAP为95.9%的同时,在性能一般的GPU上速度可达每秒143帧,相对于YOLOv5模型实时性提高了79.7%;在资源受限的CPU上速度可达每秒20帧,相对于YOLOv5模型实时性提高了75%,无论GPU还是CPU上都极大地加快了交通标志识别的速度,降低了对自动驾驶环境感知系统硬件设备的要求,更适合实际工程的部署,对自动驾驶的发展具有推动意义和实际应用价值。但在现实交通路况中,我国交通标志细分种类多达上百类,本文所用CCTSDB数据集是综合的三大类,因此,需要在数据集中进一步增加交通标志种类数来达到实际应用的目的。增加交通标志种类数或采用权威的细分交通标志种类数据集进行实验,将是下一步的研究工作。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
汽车实用技术(2022年9期)2022-05-20
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
羽毛球(2020年3期)2020-06-22
垂钓(2018年6期)2018-09-10
小天使·一年级语数英综合(2016年8期)2016-05-14
小天使·一年级语数英综合(2014年7期)2014-06-26
秀·美的(2013年4期)2013-07-02
