
一种基于Spark 的公路裂缝图像处理方法*
2022-09-28 01:40李杨刘庆华刘东华黄凯枫贾叙文
计算机与数字工程 2022年8期
李杨 刘庆华 刘东华 黄凯枫 贾叙文
(江苏科技大学 镇江 212000)
1 引言
我国公路里程规模位列世界前列,受车辆承载过重和自然环境侵蚀的影响,公路破损现象频现。公路养护不及时导致破损加重,裂缝是破损的前期表现,对于车辆交通安全存在隐患。自动化裂缝检测系统[1]面临图像处理负荷过重和路面复杂环境的干扰。针对目前提出的裂缝图像处理[2]方法,结合大数据处理,使得路面裂缝方法更加快速、高效,对提高公路裂缝自动化检测技术有重要意义。
随着云计算技术的发展,解决处理大规模裂缝图像数据的速度问题成为了可能。目前,对于裂缝图像数据,传统的方法只适用于小规模数据集,不适用于现在的大数据环境。以局部自适应阈值算法为例,虽然理论上可以处理任意大小的数据集,但对于需要大规模处理的裂缝图像,需要预留更多的空间来进行存储图像处理完成的图像文件数据、变量和灰度级。本文提出了一种基于Spark的公路裂缝图像处理方法,将Spark 与局部自适应阈值分割算法结合,实现并行处理图像。通过图像处理接口进行一系列图像的预处理转化操作[3],经过Spark 集群后存入HDFS。利用传递函数实现图像分割算法与Spark 的整合[4],可满足各类的图像处理算法接入平台。相比传统图像分割算法,本文利用大数据处理平台Spark提高了图像分割处理的效率,通过对局部自适应阈值算法的应用,保留其算法的分割准确率高的优势,并解决了大数据图像处理时间过长的问题。
2 相关工作
2.1 裂缝检测
路面裂缝是公路病害的初期表现,对其进行修复,减少后期的维护费用和维护道路安全。裂缝图像分割是从图像中提取需要的裂缝目标区域[5]的过程。对于裂缝分割,目前一些主流方法[6]包括:Li L[7]等提出一种利用Sobel边缘检测的算法,该模型可以得到路面裂缝分割的结果,处理多种病害交织的路面仍存在误判。唐磊[8]等对路面裂缝构建三维路面模型,利用空间检测算子来获取曲面中的裂缝。这类边缘检测算法检测图像中灰度突变来完成分割,若噪声过多时,易出现边缘不连续。
基于阈值的分割从全局阈值、局部阈值两方面考虑,是依据灰度阈值将图像进行分类。全局阈值分割是对整个图像计算确定阈值,获取了整体图像的阈值之后,然后对其进行分割。局部阈值分割是在每个图像切分的子区域之中计算得到对应的阈值。
Kieschke[9]等提出了基于直方图的阈值分割方法,先将路面图像分为不重叠的子块,根据子块的直方图图像来判断是否存在裂缝。孙波成[10]等提出一种全局阈值和动态阈值结合的最大类内、类间距阈值分割,来得到加权全局阈值之后,再获取动态阈值,将其两者结合得到新的阈值,但存在单独的噪点和不连续的裂缝。
一些学者提出新的分割算法,在证实后被应用。任炳兰[11]提出一种基于形态学的多尺度的裂缝分割算法,对抗噪声膨胀腐蚀边缘检测进行改进,但结构元素的选择易出现问题,导致处理时间较长。Huang和Tasi[12]提出一种基于动态规划的分割算法,通过对与处理的图像进行分割,将其分成多个网格,对裂缝多尺度特征分析,利用多尺度单元格中的连通元进行分割,
本文针对以上几点问题,根据裂缝图像数据特点和大数据时代背景,以裂缝检测和Spark 相结合的方式对传统算法改进。
2.2 Spark平台
Spark 是由加州大学伯克利分校的AMPLab 开发,着重考虑处理速度、复杂计算分析、易用性这三个方面,利用RDD 作为内存来实现计算和存储的功能,定义了不同的操作指令来实现转换和动作,来实现高效的数据处理。基于迭代优化的设计,Spark并行处理在处理大规模数据时更加快速。
Spark的核心是一种新的弹性分布式内存数据结构(RDD)[13],可以将迭代运算常用的数据放至于内存,也将数据存储到磁盘中,来进行数据的分区管理。为了优化迭代速度,Spark 将中间的临时数据存放在内存,RDD 作为内存抽象,大量减少磁盘IO,便于进行迭代优化。RDD 有两种操作类型,即转换(Transformation)和动作(Action)。转换操作是惰性求值,将RDD 封装为一系列具有血缘关系的RDD即有向无环图(DAG),在末尾遇到Action算子才触发RDD的运行结果。
Spark简单认为由驱动器程序、集群管理程序、执行器程序构成。驱动程序初始化应用,定义弹性分布式数据集,连接集群,进行任务调度和资源分配[14]。集群管理程序有1 个Master 节点和多个Slave节点,Master是集群的核心,管理Slave并维持集群的正常运行,Slave 节点进行任务计算,定期向Master 节点汇报自身状态信息。Spark 中的任务运行流程如图1所示。
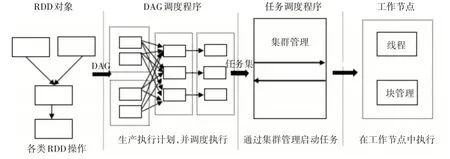
图1 Spark任务运行流程
3 关键实现
3.1 算法描述
基于Spark的公路图像并行处理作为一种通用的并行处理方法,在Spark中利用图像处理算法,实现并行处理。本文在图片处理接口上添加了局部自适应阈值分割算法[15],局部指图像中逐像素滑动的小窗口,自适应阈值指算法计算出匹配每幅图像对应的阈值。其流程如下:
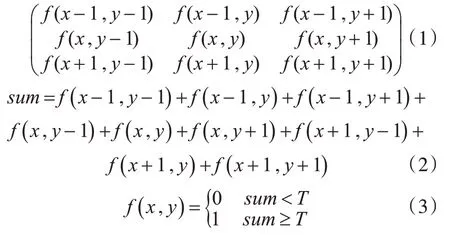
如公式所示,预设像素大小的窗口进行逐像素滑动,遍历整个图像。预设的窗口匹配的是图像分割后的子区域,窗口内所有像素的像素值之和sum,sum 大于或等于阈值,定义窗口正中间的值为1,反之定义窗口正中间的值为0。0为背景,1为目标。
遍历图像作为算法中需要时间占比最多的,需要的存储空间也是相应的图像大小,时间复杂度为T(n)=O(n2)和空间复杂度S(n)=O(n2)。
本方法对裂缝图像进行分割,开始形成若干小窗口,然后对小窗口进行逐像素滑动,来进行小窗口的像素值判断,若干的小窗口与周围环境进行交互。随着边缘部分的灰度级是发生变化,其像素值也随之发生“梯度”变化的规律。当开始阈值判断时,如果只对单个像素点来判断会导致错误的分析,此时我们需要对小窗口中的数值进行计算,对应的数值为所有像素的灰度级总和,通过总和来进行判断。这样才能根据图像的数据进行统计,得到最后的结构。结合多个小窗口判断,减少对目标误判的可能性,适应性较好,抗噪声能力较强。在图像分割的过程中,同时对图像进行了二值化,降低了后期处理的计算工作量,不会占用大量的存储资源。
为了解决拍摄裂缝时由于光照不均匀所造成的路面有阴影遮盖的状况,可以先通过计算图像中的像素点领域像素值的大小,再根据值的大小由此得出这些像素邻域的自适应阈值。接着采用局部自适应阈值分割,取局部邻域为m×m,将处于这个范围内的邻域像素做高斯加权平均处理,可以获得此时的局部自适应阈值。为了进一步取得完整的裂缝区域,可取当前与邻域高斯加权平均值的差值数值为20。利用图像中连通域的行踪和面积特征,得到处理后的裂缝图像,再分别提取裂缝区域和噪声区域。经过以上处理之后,进一步提取图像中的连通域轮廓,再计算提取到的轮廓的圆形度和面积,从而裂缝区域,具体流程如图2所示。

图2 裂缝分割处理流程
3.2 裂缝图像并行处理方法
3.2.1 图像的预处理与转换
Spark无法直接识别DRI、JPG 等照片常用的图片格式,由于Spark支持文本文件读入处理,可以将图像进行预处理转换[16],以便于工作节点访问数据,进行Spark 的处理。将路面裂缝图像进行队列化,通过Spark 在图像处理接口处对图像队列进行转换操作,将图像转化为对应的二进制文本文件进行存储到HDFS分布式文件系统。
Spark 对二进制文本文件提供文本接口,然后开始读取文本文件,将其生成为弹性分布式数据集,这样图像便有了对应的RDD,对图像的处理就变成简单的RDD 转换操作。RDD 转换操作可以视为运用某种计算方法的数值组合的转换操作,然后通过传递函数,将局部自适应阈值算法导入Spark的图像处理接口,实现对RDD 实例的转换操作,结合不同的路面裂缝图像算法与大数据平台的结合。具体实现如图3所示。
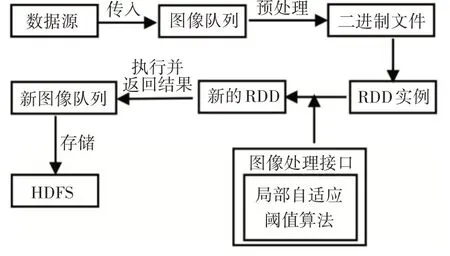
图3 函数传递过程
3.2.2 裂缝图像并行处理的实现
基于Spark的裂缝图像并行处理由分布式文件系统(HDFS)、Spark 集群、图像处理接口方面组成,并行处理流程如图4所示。
1)分布式文件系统(HDFS):将预处理转换的图像和信息存储,为了确保读写速度和存储容量,在图像规模增长过程中,适当增加存储节点。
2)Spark集群:将转化后的图像文件读入,然后多个执行节点并行处理,在主节点与从节点之间协调集群作业调度及资源分配。
3)图像处理接口:负责图像预处理、转换,将图像处理算法至Spark驱动程序结合。
HDFS通过图像处理接口存储预处理转换后的图像,然后Spark 读取HDFS 的数据过程中,为对象创建各自的RDD。对RDD 进行转换操作,同时整合传递函数传入的图像处理算法,触发动作操作,返回结果,并行处理结束后,将处理后的结果输入到HDFS。处理流程如图4所示。
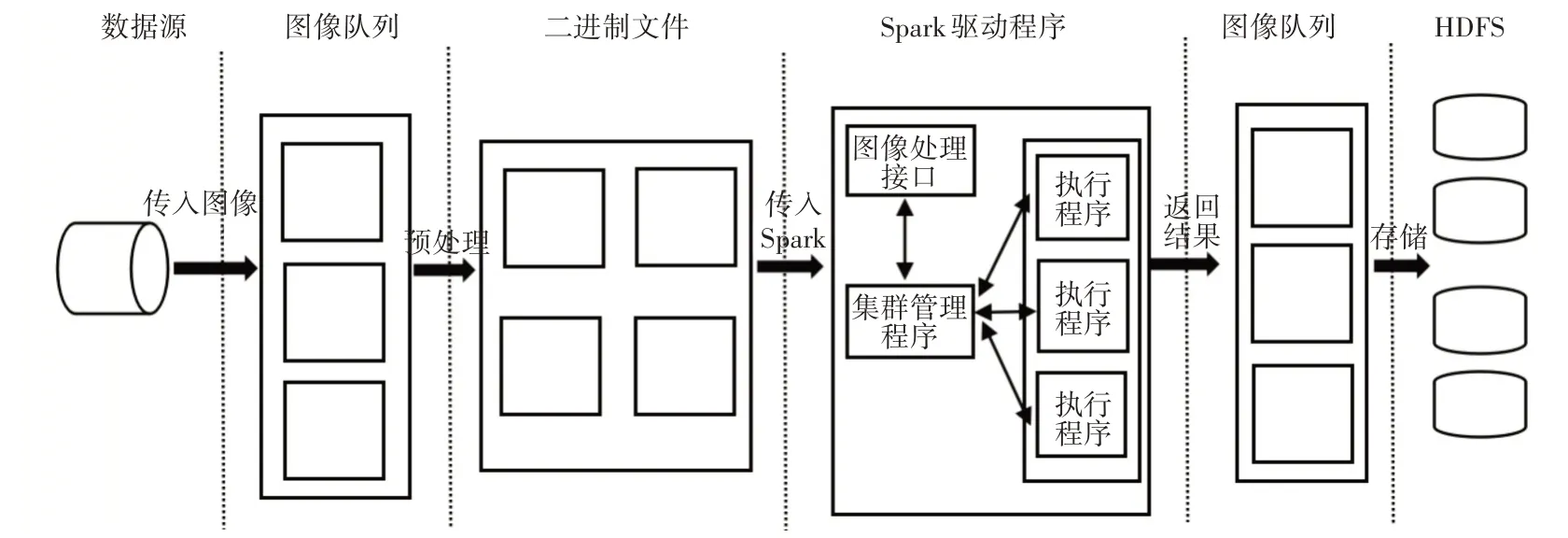
图4 并行处理流程
对图像裂缝处理算法进行封装,通过传递函数将大数据平台和局部自适应阈值算法整合,从而使Spark 适用各类图像裂缝处理算法,实现了通用性。RDD 转换操作执行后,返回动作操作,操作完成。Spark开始处理传入图像,查看数据量规模,进行任务的分配。考虑到集群的节点数量,适当地将任务合理分区,分配到工作节点。工作节点计算完成,返回数据到HDFS。将图像数据与任务之间合理分配,减少读取数据时间。
3.2.3 并行图像处理的通用方法
大规模图像数据需要分布式存储和计算时,不再需要将图像处理算法转换为需要匹配MapReduce 模型的并行算法,避免了代码转换的时间,减少代码转换时的编写成本,使得基于Spark 的并行图像处理方法具有通用性[17]。采用Python 编写的图像处理算法,利用Python 丰富的图像算法库,实现各种裂缝图像处理。Python 面向对象、可移植的特点,被应用到各类图像处理的领域,缩短了代码的任务编写量。首先将编写的算法添加到图像处理接口,然后利用传递函数的方式,最后实现图像处理算法与Spark驱动程序的结合。
因此,基于Spark 的图像并行处理将是一种具有快速且通用性的图像处理方法,减少了图像处理的时间,提升了处理效率,为大规模数据处理的实现提供了可能,为实现路面裂缝图像快速处理提供了一种有效的方案。
4 实验与讨论
4.1 实验环境及数据来源
本文的实验集群主要针对基于Spark 的裂缝图像并行处理。实验集群选取1 个主节点为Master,4 个从节点为Worker。操作系统均为Centos7,硬件配位为Inter Core(TM)i5-8300H CPU@2.30GHz,2GB 内存。所有节点都已经配置好Spark的相关环境,Python3.0以及关于Python的图像处理包,如Numpy、PIL 等。通过Python 接口编写程序,实现Spark 驱动程序以及路面图像处理方法。Spark Standalong 模式进行任务部署。考虑到确定的规模数据处理负载能力,选择局域网内网,分别定义各台主机的节点名,形成内网IP 映射,实现无密码互传文件。集群的搭建如表1所示。

表1 集群配置
本文中采用的图像数据均来自个人采集的路面裂缝图像。裂缝图像来源于手机拍摄采取的裂缝图像,采取简单的增强方法[18]翻转、平移、旋转、缩放,获取更多数据集,采集的图像以JPG 格式存储,图像大小在3M左右。在本文中,通过对一万张图像库中存在的裂缝图像处理。
4.2 实验设计与内容
实验采用局部自适应阈值分割方法处理裂缝图像的Python实现算法,针对实验需要完成图像处理快速性和有效性的要求,选取若干的裂缝图像作为数据集测试。
4.2.1 与传统方法的性能比较
将传统方法与本文的并行处理方式比较,本研究方法采用5 个节点,1 个主节点,4 个从节点。采用确定的图像数据规模分别为2000 张、4000 张、6000 张,8000 张实验,进行分割裂缝,提取裂缝的同时,查看两者方法处理图像需要的时间,将反映处理裂缝图像的时间与数量之间的关系,如图5 所示。

图5 传统处理方法与并行处理方法实验结果
图5 反映出基于Spark 的并行处理方法相较于传统处理方法,在处理100 张裂缝图像时,两种方法时间消耗差距不大。但随着图像数据规模增加至2000 张时,基于Spark 的并行处理方法利用多节点计算的时间只有传统处理方法的30%,传统处理方法需要的时间更长。可以看到,在选择6000 张和8000 张图像时,并行处理方法时间开始缓慢增长,只有传统的方法的16.5%,可进行大规模图片数据的快速处理。
4.2.2 多节点的处理速度
在拍摄的路面裂缝图像数据集中,选择1000张、3000 张、5000 张图像进行实验,然后改变集群的工作节点数量,查看节点增加的情况下,节点与时间[19]的关系,基于Spark 的路面裂缝并行处理方法实验结果如图5所示。

图6 不同节点数目的处理时间
从图5 得知,对于5000 张裂缝图像数据,在单个工作节点处理的情况下,需要5.7h 的处理时间,然后增加至4 个节点,所需时间大幅度减少,仅需要1.9h的处理时间。在选择的1000张和3000张图像数据下,4 个节点运行速度没有明显加快,处理时间较为接近。当数据上升到5000张图像时,4个节点的优势就可以体现出来,时间降低的速度和处理时间都更加具有优势。在处理5000 张图像数据下,逐步增加节点数量,4 个节点下运行速度更快,最快情况下比3个节点的处理时间减少17.8%。采用确定范围的节点数量与图像数量,比较处理时间与节点数的关系。
4.2.3 加速比评估
加速比[20]是指同一任务在单个节点与多个节点执行任务所需要的时间之比,加速比是测试并行处理系统性能的重要参考指数。加速比公式为Sp=T1/Tp,T1指单个计算节点完成处理的时间,Tp指P 个计算节点完成处理的时间。理想加速比指在一定的图像规模和节点数量范围内,加速比指数会随着节点数增加而增加,且加速比与节点数的比率趋近于1。选取表2 中的1000 张,3000 张,5000 张裂缝图片进行加速比值实验,结果如图7所示。
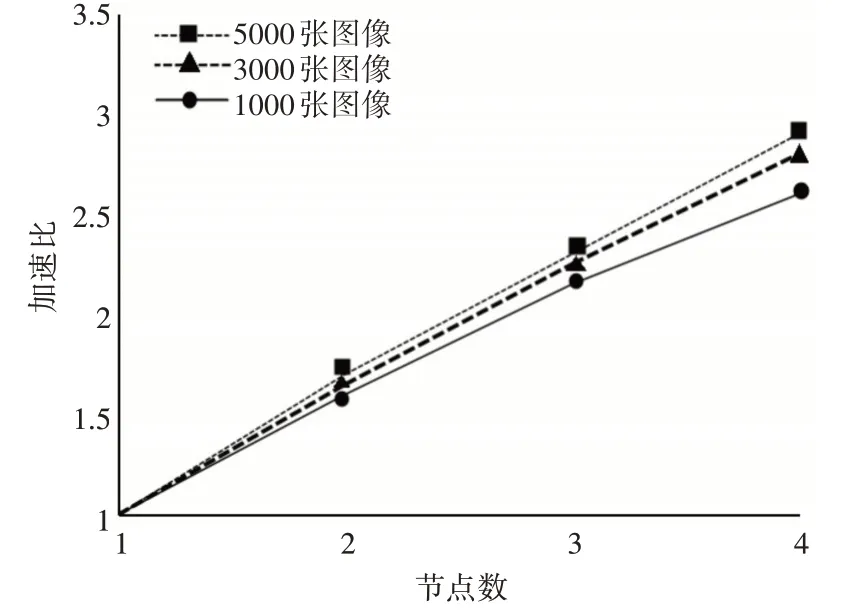
图7 加速比测试
从图7 可以看出,并行处理图像时,分别在1000 张、3000 张、5000 张图像数据确定规模前提下,随着工作节点数量的增加,加速比在线性增长。实验中加速比与节点数的比率都不是理想加速比,节点数量的增长,可见比率在一直趋近于1。当加速比与节点数的比率超过0.5,并行处理系统可以达到较优性能。在一定的数据规模和确定的节点下,这个加速比评估证明了基于Spark 的路面裂缝图像并行处理方法可以实行较好的集群扩展,在一定范围内增加节点,来完成大规模的路面裂缝图像处理。
现有的图像分割大多采用准确率衡量图像分割算法的性能,定义了一组指标来进行裂缝分割算法的比较。Pr为准确率,TP为正确检测的对象数量,FP为误检的对象数量。Pr=TP/(TP+FP)。裂缝图像分割的对应准确率的参数如表2所示。

表2 裂缝图像分割的准确率比较
由表2 可以看出,在准确率上,本研究方法局部自适应阈值算法可以达到86.3%,比其他传统算法提升显著,可以较好地提取裂缝结果。
5 结语
基于Spark 的并行路面裂缝图像处理,将各类路面裂缝图像分割算法与Spark 大数据框架结合,实现对大规模路面裂缝图像的快速通用处理。在一定范围内,通过增加节点的方式,能够提升处理速度,适应更大的图像处理规模。通过对处理的图像进行转化为二进制文本文件,再进行存储,实现图像可以读入到Spark 平台。利用图像处理接口,对图像裂缝处理算法进行封装,通过传递函数将大数据平台和局部自适应阈值算法整合,从而使Spark 适用各类图像裂缝处理算法。由实验得出,本研究方法可添加通用的处理算法实现并行处理,且满足大规模数据处理的需要。在确定千余张图像数据规模时,双节点比单节点处理时间更少,最多减少了20.4%。在图像分割的准确率方面,已经由之前方法的47.5%提高到了86.3%。这表明本文的方法对数千张图像数据进行处理时,利用Spark通过增加节点的方式可以有效提高图像分割的效率,而且在准确率方面相比传统分割方法有明显提高。但是,本文算法在分割时的准确率仍有需要完善提高的空间,后续工作将着重于如何提升在处理大规模图像分割时的准确率。
猜你喜欢
农业工程学报(2022年11期)2022-08-22
农业工程学报(2022年7期)2022-07-09
现代电子技术(2022年11期)2022-06-14
电脑知识与技术(2022年9期)2022-05-10
电脑知识与技术(2022年9期)2022-05-10
计算技术与自动化(2022年1期)2022-04-15
建材发展导向(2021年19期)2021-12-06
科技研究(2021年15期)2021-09-10
分析化学(2017年12期)2017-12-25
知识就是力量(2017年2期)2017-01-21
