
基于U-net 和ResNet 的图像缺陷检测*
2022-09-28 01:40:38肖东韩晨范文强
计算机与数字工程 2022年8期
肖东 韩晨 范文强
(烟台大学光电信息科学技术学院 烟台 264000)
1 引言
检测瑕疵产品的过程实质上是图像分类的过程,给你一幅图像,来判断是好的产品,还是带有瑕疵的产品。以2012 年Hinton 和他的学生Alex 设计的AlexNet[1]为起点,卷积神经网络开始逐渐在ILSVRC 获胜,成为竞赛的Winning algorithm,包括2013 年Zeiler 和Fergus 设计的ZFNet[2]、2014 年 牛津大学计算机视觉组合和Google DeepMind 公司一起研发的的VGGNet[3]、Christian Szegedy提出的GoogLeNet[4]和2015年何恺明提出的ResNet[5]。
但是利用卷积神经网络来检测带有缺陷的产品,也有不足的地方。首当其冲的问题就是数据,数据是OCR 研究中最重要的要素之一。目前在很多行业里,短时间内很难获得足够多的带有缺陷的产品图像,所以在应用深度学习进行缺陷检测时存在分类的准确率不高的问题。因此,寻找一个对数据需求少,分类准确率高的深度学习算法是一个值得研究的问题。本文的“UR”法就是结合U-net[6]和ResNet来实现少量数据高准确率的图像分类。
2 数据集
2.1 U-net数据集
使用U-net 进行植物叶片的图像分割,数据集需要包含两部分,植物叶片原图像和植物叶片图像的标签(label)。实验中从自然环境中采集了300枚植物的叶片。为避免由于数据集的分布规律过于简单而造成网络产生过拟合,因此实验中共采集了9种不同植物的叶片。
由于本次研究的目的是图像缺陷检测,所以对有缺陷的植物叶片的需求较高。在有缺陷的植物叶片较少的情况下,采取了在原有的无缺陷叶片的基础上自制有缺陷叶片的方法,主要采用了裁剪,撕取等方法。自然形成的有缺陷植物叶片和人工制作的有缺陷植物叶片如图1 所示。最终共采集到无缺陷叶片图像412幅,有缺陷叶片图像136幅,共548幅。

图1 自然形成和人工制作
U-net图像分割网络在进行训练过程对随机选取的71 幅原始图像用Labelme 进行标注后得到标签图。
2.2 ResNet数据集
ResNet 图像分类网络是使用U-net 图像分割的结果来训练的,用训练好的U-net 网络处理所有的图像数据,可以得到共548 幅分割图像。按照80%训练集,20%测试集的分配比例,随机取448幅图像作为ResNet 网络的训练集,100 幅图像作为网络的测试集以测试网络性能。和U-net 网络一样,ResNet也需要对图像打标签,但是和图像分割网络不同,这里的标签只是一个代表图像类别的字符,比如0代表有缺陷,1代表没缺陷。
3 UR法缺陷检测
3.1 U-net实现的特征提取
U-net 网络和ResNet 网络一样,都是卷积神经网络算法的一种,它们两种算法都主要用于分类问题,不过相比ResNet 网络,U-net 网络的分类是像素级别的分类,通过对组成图像不同部分的像素点进行分类来实现图像的语义分割。
U-net 网络在经过足够的训练后,可以清晰地把一副图像中叶片的轮廓分割出来,就像图2(b)所示的那样。分割后的图像相比原图,在形状上的特征变得更加明显,叶片的缺陷相比原图也更加的突出。因此,图像分割这一步骤,就相当于发挥了特征提取的作用。经过图像分割,用于进行区分缺陷叶片的轮廓特征变得更加明显,虽然叶片的颜色特征会被掩盖,但由于所研究的植物叶片的缺陷主要是形体上的缺陷,所以可以忽略被掩盖的颜色特征。

图2 灰度图和分割图
3.2 ResNet实现的图像分类
利用训练好的U-net 网络来处理采集的数据,相比原来未经处理的植物叶片图像,图像分割后产生的二值图像因为除了植物叶片外的背景全是白色,只有叶片是黑色,所以这样的图像相比背景复杂的图像,其中包含的特征会更加的明显,对于图像分类网络学习起来也更加简单,因此训练这样一个图像分类网络既不需要太多的数据,网络的深度也不需要特别深。实验中将从U-net 网络得到的数据按照80%训练集,20%测试集的分配方法进行分配,在将数据按照类别标记好之后,就可以用于ResNet-18网络的训练。
4 实验结果与分析
4.1 U-net特征提取模型
通过U-net 图像分割网络对植物叶片图像进行特征提取是本实验的第一步。图3 列出了当U-net 网络在训练集上训练100 次(右上),200 次(左下),300次(右下)时对植物叶片的分割结果。

图3 U-net网络分割结果
图4 为U-net 网络的训练状态曲线,实线的曲线为损失值(loss),虚线的曲线为准确率(accuracy),横轴为U-net 网络训练的次数。由图2、3 可见,在训练300 次时,网络仍还有很大的潜力进一步改善,但是考虑到本实验的目的并不是进行图像分割并且增加训练次数会增大训练的时间成本,所以最终U-net 模型训练了300 次。最终训练300 次模型的loss 值为0.12109,准确率为96.50%。可见,已经是很好的结果。

图4 U-net训练状态曲线
4.2 ResNet-18图像分类模型
实验中将ResNet-18 模型在训练集上训练了30 次,训练过程中使用minibatch 的方法,batchsize为16,图5为模型的训练状态曲线,最终,在经过30次的训练后,模型在训练集上的loss 值为0.0350,准确率为98.88%。将模型在含有100 张图像的测试集上进行测试,得到的loss 值为0.0907,准确率为98%。在测试集上98%的准确率这个结果已经相当的令人满意了,毕竟模型的训练集只有448 张图像,并且这个模型仅仅训练了30次。

图5 “UR”法ResNet-18训练状态曲线
4.3 与传统的ResNet-18网络对比
单纯的观察“UR”法的实验结果并不能发现“UR”法比其他的方法强在哪里,所以本节将对经过U-net特征提取后ResNet-18 的分类结果与不经过U-net特征提取ResNet-18 的分类结果进行对比分析。
实验中,为了确保对比的公平性,所用的ResNet-18网络与“UR”法所用的ResNet-18网络保持参数一致,训练次数一致,优化方法一致等。图6 是ResNet-18 直接对448 张大小 为256*256 的植物叶片的灰度图进行训练30次的训练状态曲线。
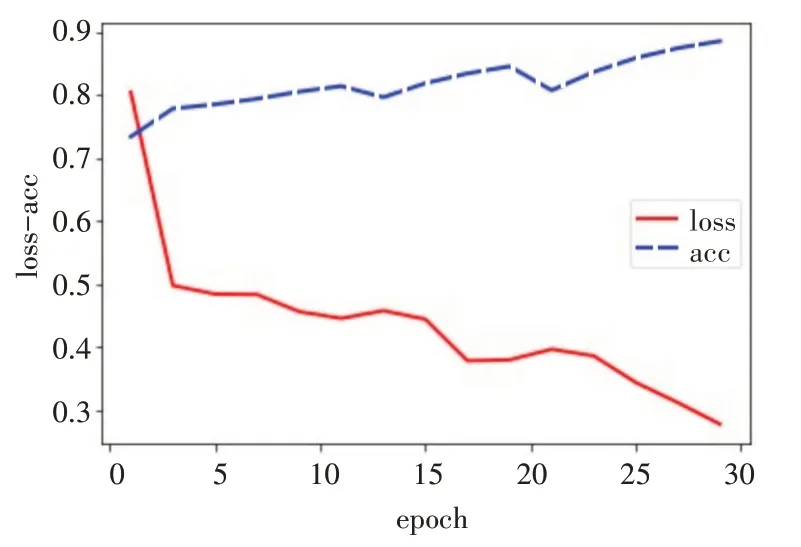
图6 ResNet-18 训练状态曲线
由图6可以看出,单纯用ResNet-18时,在训练集上训练了30 次之后,模型还没有收敛,loss 曲线仍然有下降的趋势,而“UR”法在训练15 次之后模型就已经收敛了。这说明,“UR 法”在模型优化的速度上比普通的ResNet网络要快很多。经过30次训练后,单纯的ResNet-18 网络的loss 值为0.2778,准确率为88.62%。将模型在100 张图像的测试集上进行测试,得到的准确率为85%。这里通过数据可以看出,只用ResNet 的分类准确率比“UR”法大约低了10%。
所以,由数据可知,与传统的图像分类算法相比,“UR”法可以用很少的数据就能够得到更好的分类准确率,并且模型的优化速度更快。
5 结语
本文针对上述问题,基于深度学习提出了一种和传统的图像分类不一样的思路。即在图像分类之前,先对所要分类的图像做一个“预处理”。这个“预处理”会将图像的特征进行提取,特征提取后,用于图像分类的特征会变得更加的“突出”。随后再在图像分类模型上进行训练,因为此时用于图像分类的数据的特征都变得非常的明显,所以在训练时,图像分类网络可以很容易地学习到图像的特征,因此训练耗费的时间就会少并且准确率也会提高。
由于实际生产中产品的缺陷检测大多是二分类问题,所以本文中以植物叶片为例对“UR”法的研究可以很好地泛化到其他更复杂的缺陷检测问题上。
猜你喜欢
天天爱科学(2022年12期)2022-11-10 08:33:28
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
装备制造技术(2020年1期)2020-12-25 05:19:10
电子制作(2018年19期)2018-11-14 02:37:08
中国交通信息化(2018年5期)2018-08-21 03:37:40
自动化学报(2017年11期)2017-04-04 02:52:58
航空学报(2015年4期)2015-05-07 06:43:30
噪声与振动控制(2015年4期)2015-01-01 07:08:21
