
知识图谱中图结构特征信息学习算法优化*
2022-09-28 01:40:32佘学兵明帮铭
计算机与数字工程 2022年8期
佘学兵 李 祥 明帮铭
(1.东华理工大学信息工程学院 南昌 330013)(2.东华理工大学软件学院 南昌 330013)
1 引言
如何在浩瀚的信息量中寻找所需的信息变得越来越困难,推荐系统的出现帮助了用户快速、有效地获取所需内容[1]。在推荐算法中引入知识图谱数据,相当于引入了语义关联关系、各种实体之间的关系,一方面使得推荐能够从语义的角度上挖掘用户兴趣点,另一方面也使推荐结果更加发散,避免了推荐结果的单一[2]。现有的基于知识图谱的推荐系统使用知识图谱的方法主要有三种:基于内容、协同过滤、混合式[3]。图表示学习即图嵌入,是通过机器学习的方法将图中的实体与关系所包含的结构信息和语义信息表示为低维空间中的实值稠密向量,使得得到的向量形式可以在向量空间中具有表示以及推理的能力[4]。通过对图的拓扑结构信息以及语义相关信息进行抽象整合,能实现图特征的抽取与表达,学习到的向量具有复杂度低、计算效率高、可扩展性强的优势,于是能推广到图的各种应用中,如实体聚类、关系推理和个性化推荐等[5]。
基于图结构信息的学习方法与基于三元组的方法相比,前者可以将更加丰富的语义信息进行拟合,从而也能进一步高效学习到图谱中隐含的高维特征[6]。由于交易领域推荐问题中存在着非常多的网络结构,例如用户物品交互网络和物品属性关系网络,故而对图结构的特征进行学习,能挖掘出推荐任务相关特征,可以帮助推荐系统更好地学习用户的偏好,减轻信息过载问题带来的负面影响,增强用户对推荐系统的满意度[7]。其中具有代表性的,如,PER[8]方法是通过设计元路径来提升推荐性能,它比较直观地利用了图谱的网络结构,但需要人工设计元路径,元路径的优劣影响到推荐的精度。CKE[9]方法是将知识图谱作为辅助信息融入到推荐算法中,与传统方法比较提升了推荐的精度。但是,采用依次学习只把知识图谱作为多一维特征处理。KGCN[10]方法是基于知识图谱的图神经网络推荐算法,由于融合了图结构,所以在推荐性能上有了进一步提升。在这个算法中把物品的特征向量设定为与其直连的物品的特征向量之和,并且在相加之前使用了注意力机制。这个算法仍然有改进的地方,因为它忽略了物品之间的长依赖关系。
2 知识图谱中图结构信息提取
在推荐系统中,一般用U={u1,u2…um}表示用户集合,I={i1,i2…in}表示物品集合[11],用户-物品交互矩阵记为yu,i∈Rm×n。当yu,i=1 表示用户u 和物品i有交互(这个交互可以是显式信息反馈或者隐式反馈信息)[12]。在知识图谱中G=(E,R)表示物品关系网络,由于包含物品的属性信息,从而构成了复杂的物品关系网络。用户与物品的交互也具有网络图特征,通过对图的挖掘可以发现用户的偏好或者用户之间的相似性。因此,可以构建出图1 中用户-物品交互图(图a)、用户-用户图(图b)、物品-物品图(图c)。

图1 三类关系网络图
将用户的交互数据、物品的属性标签以三元组的形式提取出来,然后整合为图结构,步骤如下:
1)用户-物品图:定义为G1={(u,yu,i,i)|u∈U,i∈I}。
U 为用户集,I 为物品集,当用户i与物品j存反馈信息,则yu,i=1;否则yu,i=0。
2)物品关系图:含物品及其属性或标签类型,定义为图G2={(h,r,t)|r∈R,h,t∈E}。
E为实体集合,R为关系集合,一个三元组代表了头实体和尾实体的之间的关系。为了描述物品与实体之间的关系,定义H={(i,e)|i∈I,e∈E},其中I代表物品集或群,E 代表实体集。物品和实体之间通过关系链接,其被表述为一个三元组。如,物品书籍《推荐系统与深度学习》、实体作者黄昕,两者是写作关系。有了这个关系H 就可以把1)和2)整合到一张图,即有:

根据式(1)可以构建出实体之间复杂的关系网络,物品与物品、用户与用户的长依赖关系就能从知识图谱中直观地展示出来,节点属性聚合节点间的长依赖关系就形成了高维特征(用户与用户之间的高阶关系、物品与物品之间的高阶关系),这种高维特征应用到推荐任务中就能提升推荐的性能。
对图进行聚类挖掘,就能找到偏好相似的用户,形成偏好相同的用户族群,即用户-用户图;对物品关系图进行聚类操作也能找到相似属性的物品族群。于是,就可以利用用户-用户图,在同一族群中为没购买物品i 的用户u 推荐i;类比,利用物品关系图,可以为用户u 推荐购买过的物品i 所属物品族群中的物品j。
3 推荐模型设计
3.1 模型设计
为了获取用户特征建立用户族群、获取物品特征建立物品族群,采用图团体(graph community)算法;然后,通过循环神经网络按时序获取推荐序列,把这种方法称为GC-RNN算法,模型如图2所示。
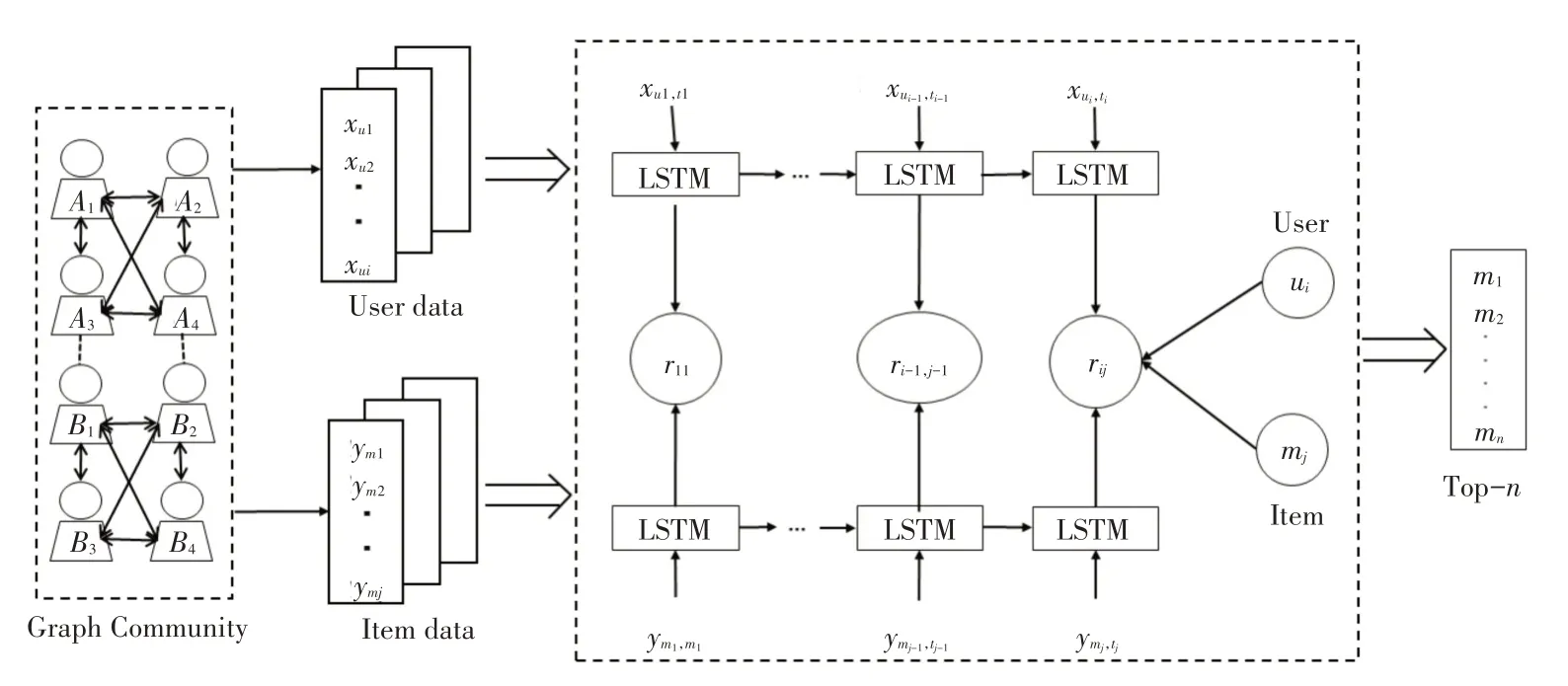
图2 GC-RNN模型
3.2 算法流程
图团体算法[13]常用在网络中找出联系比较紧密的样本。例如,在用户-用户图中顶点表示用户,连接顶点的边则表示用户之间具有关系(在无向图中用边表示有关系、无边则表示无关系),按照关系的紧密程度可划分成若干集合(也称为用户族群)。为方便计算,一般把图转成邻接矩阵的形式。图1中用户-用户图的邻接矩阵如表1所示。
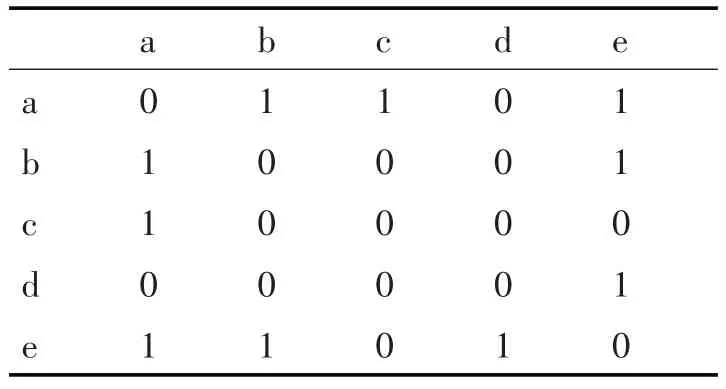
表1 用户-用户图的邻接矩阵
然后,计算模块性值M。该算法最终能把所有用户都分组成一个有相同偏好的族群中。
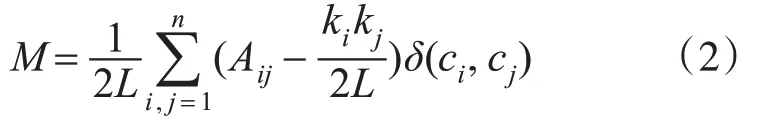
其中,L是图中边的数量,N表示图中顶点个数,ki是顶点i的度,Aij是邻接矩阵中的值,ci表示顶点i的聚类,δ为可罗内克函数,如果顶点i 和j 属于同一聚类,则δ(ci,cj)值为1,否则为0。
通过式(2)可以将知识图谱中的具有相似特征的用户聚合成一族,设长度为L,这对于该族内给定实体节点ui,可得到相邻节点序列(u1,u2…uL)。为了学习到节点的特征向量,引入特征向量函数g:u∈E→R|E|×de,从而把每个实体映射为一个de维向量。对于给定的三元组(h,r,t),在同一族群中融合了相邻节点信息的头尾实体可用hg=g(h)、tg=g(t)表示,则用户实体对的向量分别为

同理,可以得到物品实体对的向量为

在RNN 中,可将(Hu,r,Tu)看作三元短句,以此作为输入序列送进LSTM 中,利用LSTM 能对序列进行学习可以对图中的语义和逻辑特性进行建模[14]。LSTM 每一个时间段读取一个实体对应的embedding 向量,并将前两步输出H,u、r,输入到感知机网络。为了保留更多的H 和r 的信息,必须进行向量的组合拼接,如式(5)所示,为组合算子:

在传统的推荐系统中都是假设用户和物品的属性是静态的[15],但事实上,两者是随着时间的推移会发生变化。比如,用户的兴趣随着时间的推移发生改变或某些物品的受欢迎程度会由外部事件有所改变。所以,采用两个循环神经网络分别对用户和物品的时序性建模。用户和物品的静态属于ui和aj可由矩阵分解得到。用户的关联特征依赖于当前时刻对物品的评分yi,t-1和前一时刻用户的状态,物品的关联特征依赖于当前时刻用户对物品的评分yj,t-1以及前一时刻物品的状态。uit和ajt分别表示用户i、物品j在第t时刻的特征,那么用户i在第t时刻对物品i的评分可写成:

通过仿射变换可写成:

其中,uit和ajt表示用户i、物品j在第t时刻的关联特征,通过长短时记忆网络建模:
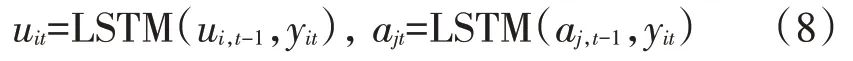
其中,yit和yjt分别代表用户i 和物品j 在第t 时刻的输入,可写成:

其中,Snew-usr=1 和Snew-itm=1 分别代表关联用户和关联物品,Wc为用户的参数投影矩阵,xit∈Rv表示用户i 在第t 时刻对物品的评分,V 是物品数量;xjt∈RU表示在第t时刻所有用户对物品j的评分,U 是用户数量。模型参数通过优化下面的目标函数求出:
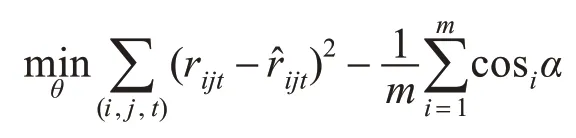
结合式(5)和式(9),将组合向量Z 输入到MLP中进行解码:
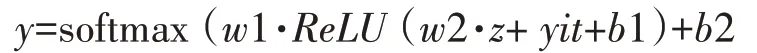
其中,w1 和w2 是权重矩阵、b1 和b2 是偏置向量。同理,可以得到物品的组合向量。是对特征向量进行数据降维。为了使得组合后的向量保持最优,采用该函数进行特征向量的映射变换,通过求得特征向量余弦的平均值,将变换误差控制在一个合理的范围内,以降低目标函数的重构误差。模型最终的结果是为用户生成一个最近时期的包含N 个物品的推荐列表,针对这个列表进行评估分析。
4 实验分析
使用TensorFlow 作为计算框架,硬件为CentOS台式服务器。实验采用的是亚马逊电商推荐系统数据集,将数据划分为训练集、测试集以及验证集,并将比例调整为8∶1∶1,采用分层采样的方式分割数据集,在验证集中使用K折交叉验证[16]。由于数据集数据量大、种类较多,故LSTMCell的num_units设置为64,即LSTM 输出的是64 维向量;max_time决定了RNN 中时间序列的长度,通过实验比较,max_time=5 可确保设定的长度足以区别不同类别数据。采用召回率、准确率两个常用评价指标,为探究不同推荐列表长度下模型的变化,N 的取值在[5,30]做等差变化,选择SVD[17]、PER、KGCN、CKE进行对比。
其中,AUC=(M、N 分别为正负样本数)。
对表2的观察有以下发现:

表2 数据集上不同模型AUC和ROC对比结果
1)作为经典的协同过滤算法SVD 在数据集上的表现最差,说明利用知识图谱所提供的辅助信息能有效地提升推荐算法的性能。
2)PER 和CKE 是表现较差的模型,这也正好说明了元路径的设计好坏决定了是否能有效地使用图谱中的有效信息。CKE 中使用的TransR 算法,在一定程度上说明不太适用与知识图谱相结合。
3)KGCN 和本文的GC-RNN 表现较优异,是因为都使用知识图谱作为辅助手段,充分利用了它的关联特征,这也说明把知识图谱引入到推荐系统是提升推荐的性能的一种比较好的方法。
然后,使用精确度、召回率两个指标衡量模型生成的TOP-N列表进行评估。
通过观察图3、4可知,CKE由于利用图谱提取到物品的一般特征信息、没能挖掘出内在的关联性,结果仅优于SVD;PER 模型使用人工定义的元路径,实验结果的优劣受元路径质量的影响,该模型的性能居中等;KGCN 模型使用图卷积网络建模知识图谱,取得了优等的结果,也再一次说明了借助知识图谱中的图结构信息能提升推荐的质量;本文提出的GC-RNN 模型在性能上能优于KGCN 是因为:首先,通过建立用户关系图、物品关系图,深刻描述了高维的关联特征和长依赖关系即加强了用户特征、物品特征信息的提取。其次,模型加入了时序特征,考虑到了用户最近一段时间内的行为特征,获取了用户、物品的更深层次的关联信息。
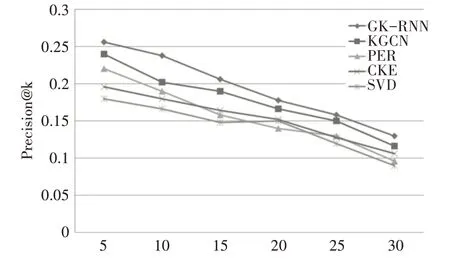
图3 所有模型在数据集上精确度随N值的变化
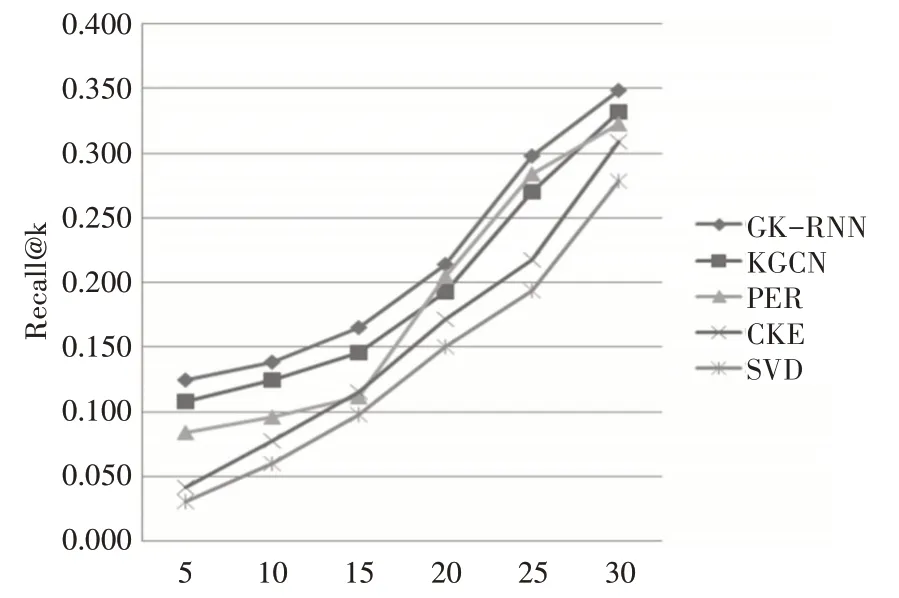
图4 所有模型在数据集上召回率随N值的变化
5 结语
本文提出的GC-RNN方法能获取用户、物品的高维关联特征,通过建模并实验,实现了用户的精准推荐,最大限度地满足用户的需求。通过在大量真实交易数据集上的测试,验证了本文方法的有效性。未来将使用不同的数据集验证模型的有效性,以及改进方法进一步提升推荐的精确度。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
少先队活动(2020年12期)2021-01-14 01:47:40
中国外汇(2019年18期)2019-11-25 01:41:54
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
哲学评论(2017年1期)2017-07-31 18:04:00
中成药(2017年3期)2017-05-17 06:09:01
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
领导科学论坛(2016年9期)2016-06-05 14:59:58
