
基于BiGRU 的数据通信加解密模型的研究*
2022-09-28 01:40:30张仕忠彭艳兵
计算机与数字工程 2022年8期
张仕忠 彭艳兵
(1.武汉邮电科学研究院 武汉 430070)(2.南京烽火天地通信科技有限公司 南京 210019)
1 引言
目前,神经网络已成功应用于许多学科领域,通信及其保密通信作为神经网络的重要研究领域之一,当然也已成为神经网络的应用研究热点,而密码学技术作为保密通信中的关键技术,也一直受到重要的关注。从信息科学的角度出发,神经网络和密码学都属于研究信息处理的学科,而随着神经网络被应用于越来越复杂的任务,自然也可以应用于端到端的任务,比如端到端的通信。密码学主要就是确保信息的完整性和保密性,即明文只能从正常通信的密文中通过正常解密得到,而攻击者无法从密文中得到有用的明文信息。因此将神经网络与密码学相结合便构成了神经密码学这个综合学科,作为综合学科,神经密码学能够推动神经网络和密码学的共同发展[1~4]。
在密码学中,明文和密文是作为具有复杂映射关系的数据对而存在的,而神经网络根据自身的特征,是可以学习到明文和密文之间的映射关系的,因此可以选择合适的深度学习模型来用于密码学的研究。近年来,神经网络在密码学领域的应用颇多,2015 年Qin K 等提出关于两种混沌神经网络密码算法的密码分析[5]。2016 年Google Brain 团队Abadi等利用以卷积神经网络为核心的对抗神经网络结构进行了安全通信方面的研究[6]。2019 年J Aayush Jain 等提出基于神经网络的轻量级分组密码分析[7]。
本文提出使用BiGRU 应用于数据通信中数据加解密模型的研究,即密码算法的生成方式由神经网络自动生成,不再使用传统密码学中的数论思想,并且利用神经网络的黑盒性质来保证整个数据通信模型的通信安全性。通过以BiGRU 为核心的神经网络结构进行整个模型的构建,并在同文献[6]的Alice、Bob 和Eve 的N 位密钥对称加密系统方案相对比下,实现一个更加稳定的可正常加解密并能抗窃听的数据通信模型。
2 研究方法
2.1 对称密钥加密体系
文献[6]中提出基于对抗神经网络的对称密钥加密系统,通信双方Alice与Bob以及窃听者Eve均以卷积神经网络(CNN)为核心构建自身的神经网络模型[8]。Alice 通过密钥K(Key)对明文P(Plain-Text)进行加密,加密后生成密文C(Ciphertext)。然后,解密者Bob 与窃听者Eve 均能够获取到完整的密文C。Bob 则是通过密钥K 对密文C 进行解密,解密后获得解密明文PBob。而Eve 则是在没有获取密钥K 情况下对密文C 进行解密,从而得到猜测的明文PEve。在整个系统训练的过程中,Alice 与Bob组成的加解密通信模型与Eve 的窃听模型在对抗训练过程中不断互相优化,最终使得PBob与明文P尽量相等,即Bob 可以通过密钥K 和密文C 可以解密出与明文几乎相同的内容。而PEve与明文P 之间的差异尽量大,即PEve最终会近似等于一个随机猜测的结果。对称加密体系如图1所示。
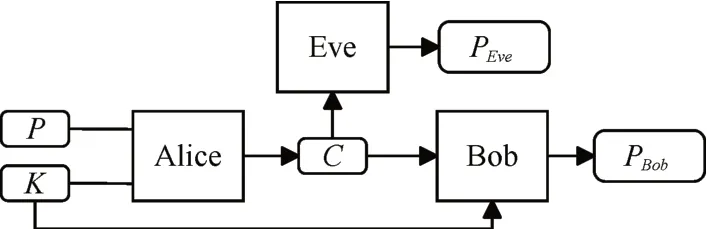
图1 对称密钥加密体系图
2.2 GRU模型
由于传统的循环神经网络(RNN)在处理序列时会出现严重的梯度消失问题,而为了解决梯度消失问题,Hinton 等提出了长短时记忆神经网络(LSTM)[9]。但是随着LSTM 的不断被应用,有关于LSTM 的训练时间长、参数较多、内部计算复杂等缺点也逐渐的暴露了出来。为了解决这些缺点,Cho 等在2014 年进一步提出了更加简单的、将LSTM 的单元状态和隐层状态进行合并的、还有一些其他变动的GRU(Gate Recurrent Unit)模型[10]。GRU 又称门控循环单元,整个单元主要是由更新门和重置门两个门组成,而在计算隐藏状态方面与传统的循环神经网络相比也因此大有不同。GRU结构具体如图2所示。
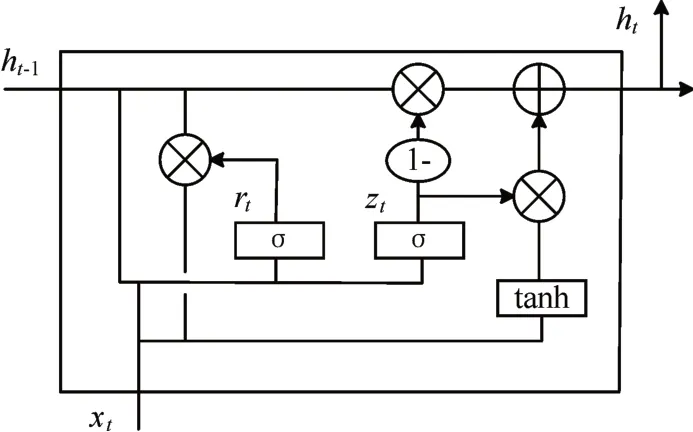
图2 GRU结构图
图2 中的xt是输入数据,ht是GRU 单元的输出,rt是重置门,zt是更新门,rt和zt共同控制了从ht-1隐藏状态到ht隐藏状态的计算,更新门同时控制当前输入数据和先前记忆信息ht-1,输出一个在0~1之间的数值zt,zt决定以多大程度将ht-1向下一个状态传递。具体的门单元计算公式为
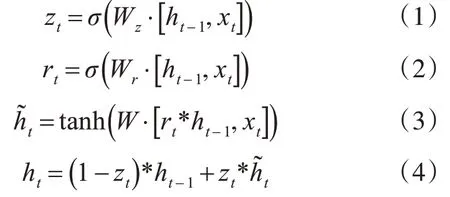
其中:rt表示t时刻的重置门;zt表示t时刻的更新门;σ是Sigmoid 函数;Wz,Wr,W分别为更新门,重置门,以及候选隐含状态的权重矩阵;为t 时刻备选激活状态;ht为t 时刻的激活状态;ht-1为(t-1)时刻的隐层状态。
由于单向的GRU 只能得到前向的上下文信息,而忽略了后向的下文信息,有时会由于信息获取不足,从而使得GRU 的实际应用效果不好。而BiGRU(双向GRU 神经网络)可以从前向和后向上同时获取上下文信息,从而提高训练过程中的特征提取的准确率。另外还可以利用BiGRU 提高整个神经网络模型的响应速度。因此本文采用BiGRU来构建模型,BiGRU结构如图3所示。
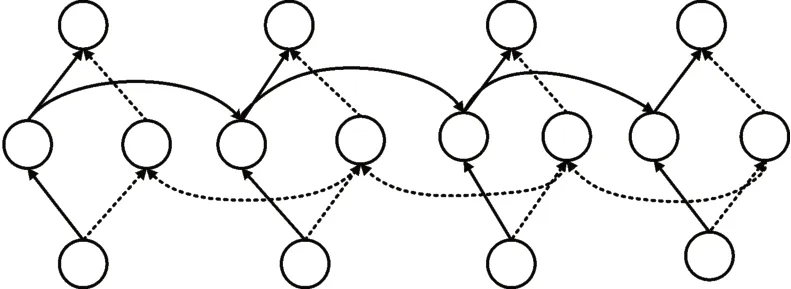
图3 BiGRU结构图
2.3 基于BiGRU的数据通信加解密模型
本文的数据通信体系采用图1 所示的对称密钥加密体系,然后采用以BiGRU 为核心的神经网络单元来构建整个模型的网络结构[11~13]。由于传统的密码函数一般是不可微分的,而这与深度神经网络的中随机梯度下降是相矛盾的,所以直接用神经网络去学习密码学的传统数论理论的函数是比较困难的。但是神经网络是可以去学习如何保护数据通信过程中的数据机密性,即在通信过程中,直接由神经网络自身去学习数据通信的加解密过程,整个过程中无需为通信模型规定特定的密码学算法,从而保证了数据通信的安全性和机密性。
在通过对明文密文对的特征分析后,明文密文数据对的关系其实可以转换成文本序列问题,从而通过RNN 在处理文本序列问题上的优势,学习明文密文数据对之间复杂的映射关系,从而实现正常且安全的数据通信加解密模型[14~15]。模型结构图如图4所示。
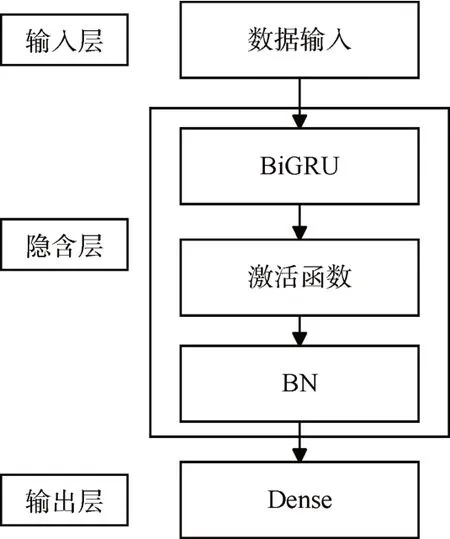
图4 模型结构图
图中模型总共为三层,第一层为输入层,即输入需要进行训练的已经预处理好的数据。第二层为隐含层,由BiGRU 加上激活函数再加上一个BatchNormalization 层构成。第三层为输出层,由一个4N×N 的全连接层构成。下面对模型的Alice、Bob以及Eve三个组件的网络结构进行构建。
Alice网络构建:
1)明文P 与密钥K 横向拼接作为Alice 的输入(设明文与密钥长度均为N);
2)输入层的输入传入BiGRU 网络中,输出经过激活函数tanh[16~17];
3)经过激活函数的输出传入BatchNormalization层[18];
4)经过BatchNormalization层的输出传入4N×N全连接层;
5)全连接层输出的结果为密文C。
Bob网络构建:
1)密文C 和密钥K 横向拼接作为Bob 的输入(设密文与密钥长度均为N);
2)网络结构与Alice一致;
3)输出结果为Bob所解密的明文结果PBob。
Eve网络构建:
1)密文C单独作为Eve的输入;
2)网络结构与Alice一致;
3)输出结果为Eve所解密的明文结果PEve。
2.4 模型损失函数设计
关于模型的损失函数,本文采用Bob 生成的明文PBob与实际明文P 的L1 距离,以及Eve 生成的明文PEve与实际明文P 的L1 距离作为模型的损失函数标准。设实际明文P 和解密明文Pd的长度均为N,本文使用L1距离来定义两者之间的距离公式:
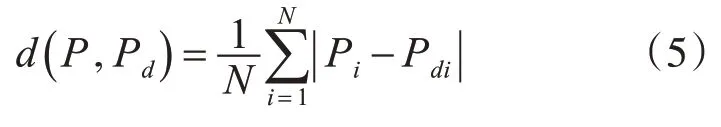
其中|Pi-Pdi|代表解密明文Pd与实际明文P 在每一位上的误差值,而d(P,Pd)代表明文P 与解密明文Pd的N 位误差的平均值。Eve 作为解密的组件,它的目标就是尽可能准确地重建明文P 的值。因此它的损失函数定义为
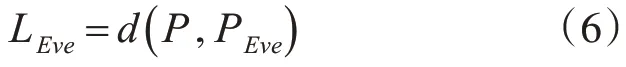
因为Alice 与Bob 之间需要保证准确的数据通信,而且它们也要对Eve 的窃听行为具有抵抗能力。为了达到最优的效果,本文结合Bob 和Eve 两者训练的损失最优值来定义Alice 和Bob 的联合损失函数:
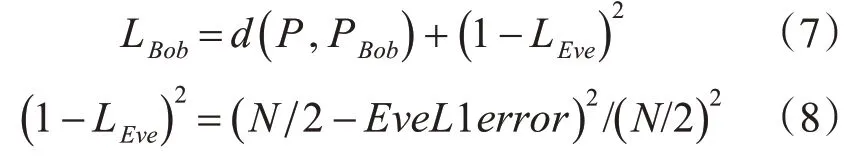
其中式(7)的d(P,PBob)代表Bob 所得的解密明文PBob与实际明文P 的L1 距离,(1-LEve)2代表Eve 的Loss对Alice与Bob这两者通信的影响,但是在整个模型定义中,Eve 的解密效果不应该比随机猜测做得更好,即当Eve所得明文PEve的N/2消息位是正确的且另外N/2 消息位是错误的时,Eve 这个组件对整个模型的影响力是最小的。之所以选择二次公式(8),是为了当Eve 解密出正确明文时,使得Eve给整个模型带来更少的损失影响,从而提高训练的鲁棒性。
3 实验验证
3.1 实验环境
本文模型采用的编程语言为Python 3.6,深度学习框架为Pytorch,运行的操作系统为Linux,在NVIDIA GTX1080Ti上进行实验。
3.2 实验参数设置
实验中输入的明文P 和密钥K 的位数N 取值为16,并且P 和K 中每一位随机取值为-1 或者1。训练的batchsize 设置256,epoch 为10000。实验中Alice、Bob 和Eve 均采用Adam 优化器进行模型优化,Adam 算法具有适用于基于适应性低阶矩估计并且能够解决包含高噪声或稀疏梯度问题等优点[19~20]。学习率固定设置为0.001。因为训练过程中,Alice、Bob 和Eve 三个组件会互相影响,设置固定的学习率可以让它们三者保持对彼此的变化做出较强的响应,整个模型在保证Alice 和Bob 的通信趋于稳定的同时还对Eve的窃听具有抵抗能力。
3.3 实验结果与分析
3.3.1 训练结果与分析
对于一次成功的训练,Bob 的重建明文误差和Eve 的重建明文误差随着训练步骤数的变化曲线如图5所示。
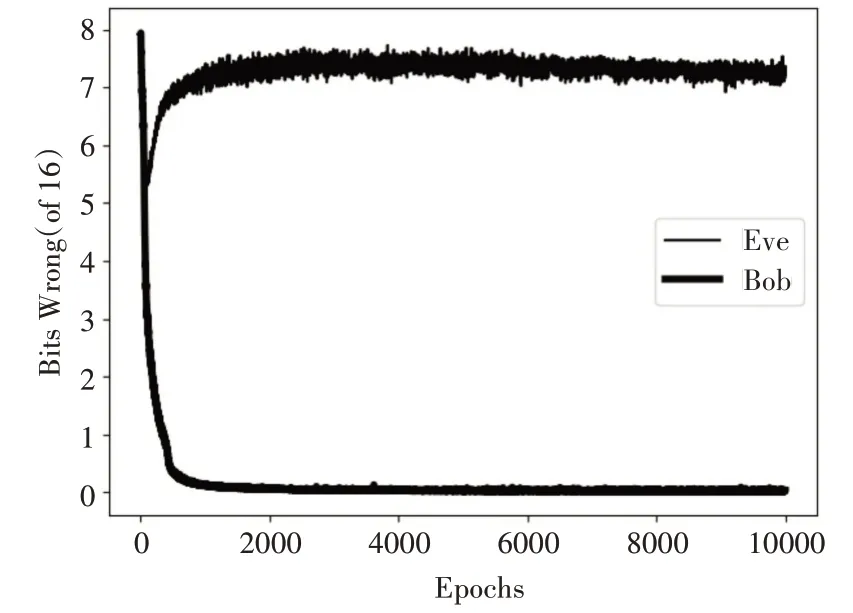
图5 Bob与Eve的重建误差训练图
图5中的每个点是256个示例的平均误差。理想的训练结果是Bob 的重建明文误差降到零,Eve的重建明文误差达到8 位(即错误位数为一半)。如图的训练例子中,两个组件的重建误差刚开始都很高,但是经过一定的训练步骤后,Bob 的训练误差开始不断减小,Alice和Bob之间能够进行有效的交流,同时,Eve 的解密能力也在提升。然后,在1000 步左右,Eve 的训练误差开始回升,这是因为Eve 在向随机猜测的目标方向前进,而Bob 的重建误差不断下降,逐渐趋近于0。经过约3000步,Bob的重建误差基本接近于0,而且Eve 的误差也在7位到8 位之间浮动,接近随机猜测的结果。继续进行训练,Bob和Eve的重建误差都基本趋于稳定。
3.3.2 测试结果对比与分析
将之前基于CNN 的数据通信模型[6]和本文的基于BiGRU 的数据通信模型对比加解密效果。取epoch为1000进行测试,基于CNN 的数据通信模型测试结果如图6所示,基于BiGRU 的数据通信模型测试结果如图7所示。
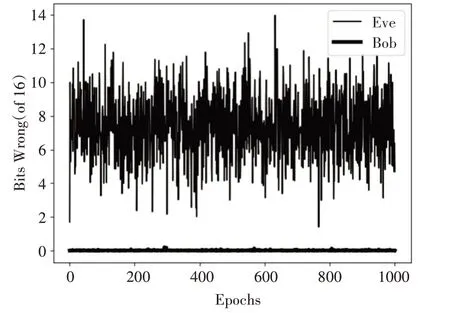
图6 基于CNN的通信模型测试效果图
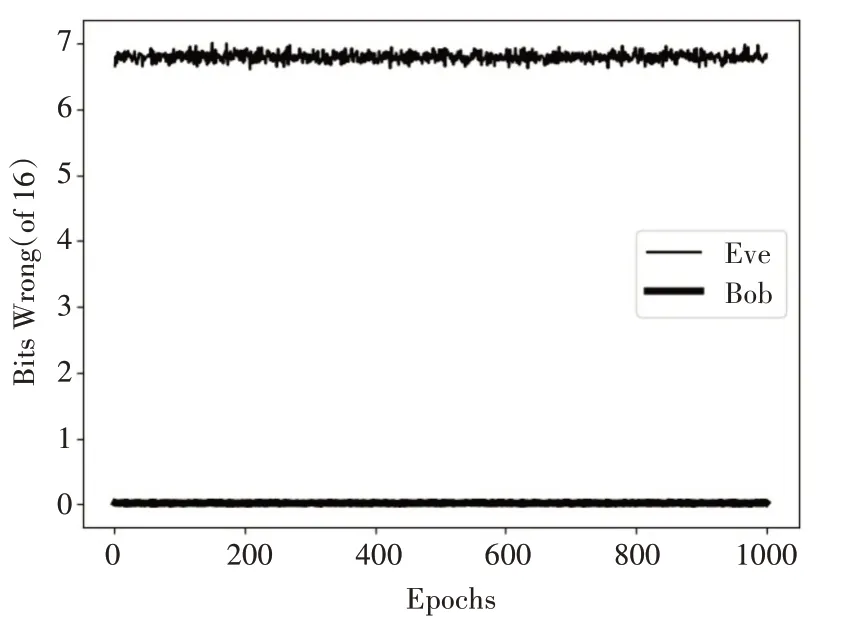
图7 基于BiGRU的通信模型测试效果图
从两个模型的测试对比效果来看,两者在Bob的解密能力方面差别不大,基本都能实现与Alice的正常通信,基于CNN 的通信网络的解密效果稍微会有些波动,而基于BiGRU 的通信网络相对更加稳定。关于Eve的解密能力对比,基于CNN的通信的Eve解密误差波动幅度较大,在16位明文的前提下,差异值最高到12 位以上,而最低则是快接近0 位,可以看出该模型中的Eve 是能窃取到大量信息的,模型的抗窃听能力存在不足。而基于BiGRU的通信网络的Eve 解密误差基本稳定在7 位左右,接近随机猜测的效果。说明基于BiGRU 的数据通信模型比基于CNN 的数据通信模型具有更好的抗窃听能力。
4 结语
本文提出一种基于BiGRU 的数据通信加解密模型,通过循环神经网络来学习密码学中的明文密文对的映射关系,从而通过神经网络实现端到端通信的加解密过程。并且与之前的基于卷积神经网络的数据通信模型进行对比,本模型能够在实现正常通信的前提下,并且具有更好的抵抗窃听的能力。
关于神经网络在数据通信加解密的应用方面,本文提出了一种新的方案,并通过实验验证了可行性。随着信息的安全通信问题受到越来越多的关注,信息的加解密问题已然成为当前研究的热点,因此研究神经网络在数据通信领域的应用有着十分重要的价值和意义。
猜你喜欢
工程与建设(2019年3期)2019-10-10 01:40:18
中国电子报(2019年74期)2019-09-26 14:36:48
铁道通信信号(2018年5期)2018-06-28 03:06:20
计算机教育(2018年3期)2018-04-02 01:24:40
网络空间安全(2016年3期)2016-06-15 20:27:07
电子技术应用(2016年6期)2016-03-18 05:41:13
火控雷达技术(2016年2期)2016-02-06 02:28:59
九江学院学报(自然科学版)(2015年2期)2015-11-12 03:34:23
电子设计工程(2015年3期)2015-02-27 12:03:57
软件工程(2014年11期)2014-11-15 20:02:46
