
基于INGARCH的电力企业话务流量预测
2022-09-27 08:36翟洪婷孙丽丽张延童
山东电力技术 2022年9期
杨 坤,翟洪婷,孙丽丽,张延童,李 亮
(国网山东省电力公司信息通信公司,山东 济南 250001)
0 引言
随着电网企业规模的不断扩大,电力专网内部的电话业务不断拓展,用户数量持续增加。受到当下国际政治、经济形势不断变化的影响,电力调度电话和行政电话等用于电力企业内部生产、办公的话务流量急剧增加。话务流量的快速增长使得话务流量的分析和预测建模变得比以往任何时候都重要。为了快速、准确和安全地进行电网调度指挥通信,方便快捷地提供办公联络,需要更准确的话务流量预测模型,预测范围包括行政交换网、调度交换网、调度数据网等。
话务流量的发生过程可以看作是一个随时间变化的随机过程,其预测模型应该能够捕捉到流量的特征规律。过去十几年内,科研人员对互联网的流量特征进行了大量分析研究[1-2],文献[1]提出基于训练的模型设计、经验评估和行为分析,从而来预测单个链路的吞吐量。通过对不同链路的实际网络流量进行实验,从误差的角度研究了训练集、延迟、数据力度等参数对预测性能的影响。文献[2]认为流量分析和预测是确保数据安全可靠和稳定性的重要方法,并对现有的网络分析技术和各种线性、非线性模型进行分析和组合。文献[3]最先提出骨干网中的数据包到达过程具有泊松分布特征。此后,有很多研究证明,在各类大型网络中的数据包到达过程符合泊松分布,如文献[4]研究了互联网流量特征,通过使用泊松点过程和时间序列的数学原理,证明在无拥塞的互联网中,数据包的到达过程趋于泊松过程,而时间序列则趋于独立。文献[5]研究了物联网中的周期性流量特征,并将其与泊松过程进行比较。研究表明,泊松过程的准确性和适用性随着性能指标的变化有很大误差,因此需要建立更复杂的流量模型。文献[6]在IEEE802.11 无线局域网中使用数据包泊松到达理论,提出一种基站周期性ON/OFF模型来更准确计算基站吞吐量,从而提高流量分析精准度和准确性。文献[7]使用泊松点过程模型和随机几何数学工具,在考虑同层干扰和跨层干扰的前提下,分析了异构蜂窝网络下行性能,为后续研究提供理论依据。
预测模型可分为线性模型、非线性模型、混合模型和分解模型[2]。传统的时间序列模型中,自回归移动平均模型(Auto -Regressive and Moving Average Model,ARMA)和自回归移动平均模型(Autoregressive Integrated Moving Average Model,ARIMA)是线性模型,广义自回归条件异方差模型(Generalized Auto-Regressive Conditional Hetero-skedasticity,GARCH)和整数值广义自回归条件异方差模型(Integer GARCH,INGARCH)是非线性模型。时间序列模型和人工神经网络(Artificial Neural Network,ANN)的发展已经从线性时间序列[8]发展到混合模型[9],甚至发展到神经网络(Neural Network,NN)模型[10]。混合模型是将线性模型和非线性模型进行了组合,如ARIMA+GARCH 的组合等。神经网络模型是非线性模型,如卷积神经网络(Convolutional Neural Networks,CNNs)和长短期记忆递归神经网络(Long Short-term Memory Recurrent Neural Network,LSTM RNN)。在模型分解过程中,时间序列被分解为四个分量:趋势、周期性、季节性和不规则成分。此外,时间预测方法还包括隐马尔可夫链[11]、熵分析[12]、高斯过程回归[13]、指数平滑法[14]等几种分析方法。
近年来神经网络模型[15]受到了科研人员的广泛关注,其优点是具有较高的精度和能够处理复杂模型的能力;缺点是黑箱性,即很难确定数据流中的直接因果关系。为了克服神经网络的这些缺点,被称为“学会学习”的元学习(Meta-learning)方法越来越被科研人员关注。元学习是为网络模型设计的,它可以通过少量的训练样本快速学习新技能或适应新环境[16]。
时间序列建模的优点在于,当缺乏底层数据信息时,可以将预测变量与其他解释变量联系起来。特别是非线性统计模型可以在数据较少的情况下表现出很高的预测精度。此外,文献[17]对数据的长相关性进行了理论和应用研究,发现GARCH 模型可以用来捕获数据的长相关性。文献[18]详细地解释了长相关性与时间序列模型的阶数关系,将时间序列由分形维度D和赫斯特参数H进行表征,其中分形维度D用于度量时间序列的粗糙度,赫斯特参数H用于度量时间序列长相关性。同时该文献提出一种基于柯西相关模型的统计模型,该模型是一种新的幂律相关模型,具有局部和全局行为解耦的特点。文献[19]使用元学习方法对时间序列进行分析,提出了这一种通过分层方式分别对局部和全局趋势进行学习、用于降低时间序列噪声的元学习算法,并与传统的时间序列人工神经网络方法进行结合,来提高对时间序列的趋势预测效果。同时,对于无法分解的时间序列,采用移动平均方法创建元信息来指导学习过程的方法,仍然优于传统方法。文献[20]提出一种整数值自回归分数积分移动平均(Integer-valued Auto Regressive Fractionally Integrated Moving Average,INARFIMA)模型,给出了模型的数学原理,然后通过该整值模型,分析和预测了金融市场股票交易数量。在文献[21]中,给出了INGRACH 模型的存在条件,讨论了参数的极大似然估计问题。INGARCH 是经典的GARCH 模型的改进,其参数同样遵循泊松过程,尤其是在所有参数都为1的情况下,INGRACH过程是一个标准的自回归移动平均过程。
随着时间序列模型的不断发展,可用于流量预测的模型也在不断丰富,人们对互联网流量预测逐渐成熟,但是对特定专用网络,如电力专网内的电力企业话务流量预测却较少。在目前对已有的网络拓扑流量模型研究中,数据包的分组到达都呈现泊松过程。电力通信网作为专用网络,话务数据包的到达过程也可以视为泊松到达过程。另外,在各种模型中,需要找到一种能够更准确地捕捉电力企业话务流量特征并进行更准确预测的模型。为了更好地对电力企业话务流量进行预测,在本研究中,引入INGARCH 作为话务流量预测模型。通过对INGARCH 过程参数的估计和对未来泊松过程参数的预测,建立了预测模型。采用经典条件极大似然估计(Conditional Maximum Likelihood Estimation,CMLE)拟合算法来估计INGARCH 过程的参数,然后采用“预处理、训练、预测和更新”4 个步骤来预测泊松参数,从而得到电力企业话务预测模型。采用山东电力工作日内的话务流量数据作为实验数据,将INGARCH 与ARIMA、GARCH、LSTM 等三种不同典型模型的性能进行比较,得到话务数据提前预测的最佳训练比例并对各模型的预测性能进行对比分析。
1 网络流量预测模型
1.1 INGARCH(p,q)过程和条件极大似然估计
设{Xt}t∈Z为一个整数值序列,Ft是由{Xt}t∈Z生成的σ域,即{Xs:s≤t}。则INGARCH(p,q)过程定义如下:
1)定义1。{Xt}t∈Z过程满足以下条件:
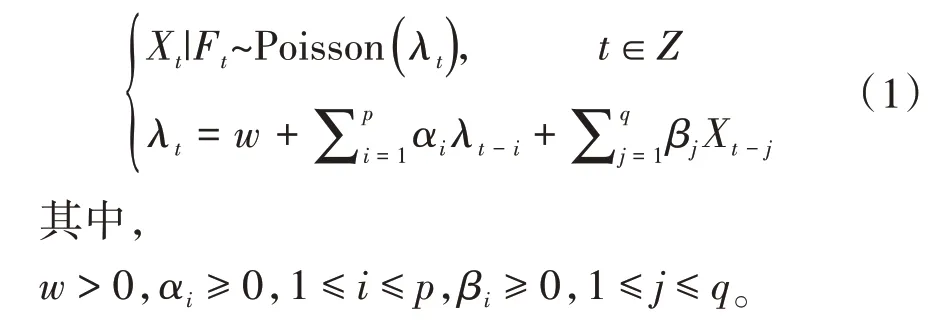
式中:w为大于零的常数;α和β均为大于零的常数序列;p和q为不小于1 的整数值。λt为整数值序列{Xt}t∈Z在t时刻的均值。
对于特定的泊松INGARCH模型,根据条件泊松分布的性质,方差一般等于均值。根据文献[21],如果INGARCH是静止的,则
2)定义2。定义E(Xt+n|Ft)为Xt在t时刻的第n步预测值,即Xt+n在Ft域内的条件期望。

设定最优的w、α、β组合为θopt={w,αi,βj},则λt可以表示为λ(θopt,Ft)。为得到最优θopt,使用文献[21]和文献[22]中提到的条件极大似然CMLE 拟合估计方法,预测话务流量相当于估计参数的最大化条件似然函数(Conditional Likelihood Function,CLF)。在对实际工作的数据进行预测过程中,要获得,初始值必须是已知的。因此,CLF 就变成
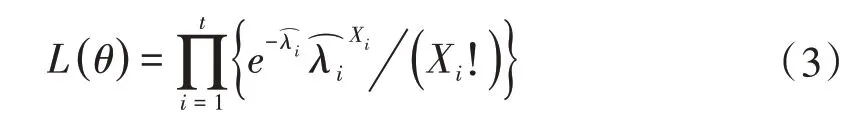
其对数似然函数可以表示为
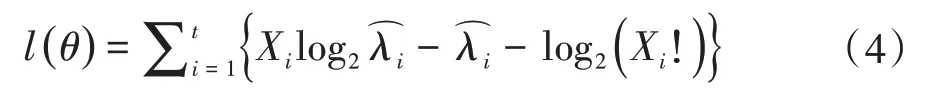
1.2 话务预测INGARCH过程
在时间序列预测的INGARCH 模型中,两个常量p和q需要通过自相关函数(Auto Correlation Function,ACF)和偏自相关函数(Partial Auto Correlation Function,PACF)[21]得到。但是,由于我们研究的核心是该模型对话务流量的适应性,考虑话务流量更依赖于短期时间内的发生情况,因此,在INGARCH 模型中参考文献[22]建模的方法,将p和q均设置成“1”。则由式(2)得到
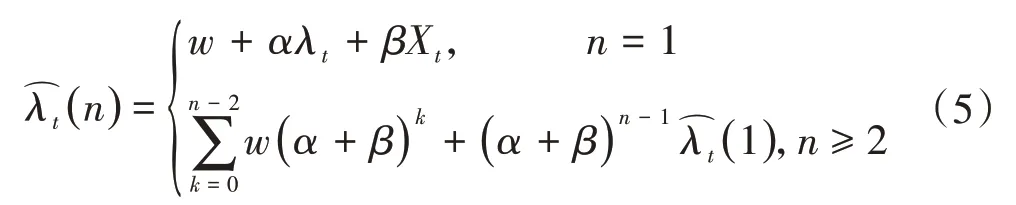
1.3 预测过程
1)数据预处理。

4)更新。
将N1逐渐增加到N,并逐一重复执行步骤2)和步骤3)。
2 性能指标
为衡量各方案的准确性,使用两种指标来衡量个模型方案的性能:归一化平均绝对误差(Normalized Mean Absolute Error,NMAE)NMAE和归一化平均平方误差(Normalized Mean Squared Error,NMSE)NMSE。其定义分别为:
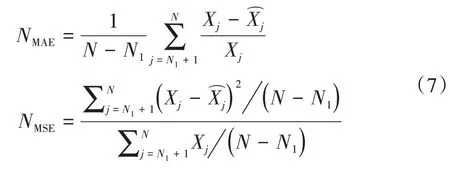
3 仿真实验
3.1 数据处理

参考文献[22]中的仿真参数,设定ARIMA(p,d,q)和GARCH(p,d,q)模 型 中 的d=1,(p,q)=(5,1)。对GARCH,同样使用条件极大似然拟合估计方法进行处理。对于LSTM,由于网络由输入层、包含LSTM 块的隐藏层、以及进行预测的输出层组成,参考文献[23]中的数据设定,最终在实验中选择了3个输入层和6个包含LSTM块的隐藏层。
3.2 实验结果
为确定训练集和测试集的最佳比例,对不同训练比例进行了比较,以便提前对各方案性能进行度量,选择出最优训练比例。图1 比较了各方案的性能指标随着不同训练比例的变化,其中图1(a)比较了不同方案的归一化平均绝对误差随训练比例的变化情况,图1(b)比较了不同方案的归一化平均平方误差随训练比例的变化情况。从图1(a)中可以看出,随着训练比例的变化,GARCH 方案和LSTM 方案的归一化平均绝对误差先降低后上升,INGARCH 方案和ARIMA 方案变化幅度较小,随训练比例变化基本保持不变。从图1(b)中可以看出,随着训练比例的变化,GARCH 方案的归一化平均平方误差在训练比例为0.2 至0.3 时变化不大,但在训练比例在0.4 至0.6时迅速降低。ARIMA 方案的归一化平均平方误差随训练比例变化而出现小幅度波动,而INGARCH 方案则基本保持不变。当训练比例r约为0.6时,各方案的归一化平均绝对误差和归一化平均平方误差接近最小,各方案性能趋于最佳值。同时,随着训练比例变化,INGARCH 方案的性能一直最佳,这是由于INGARCH 的预测程序中包含了更新过程。在此基础上,为了更好地对各方案预测效果进行分析,在后续实验中将以训练比例为0.6的条件下,对各方案的预测性能进行对比。
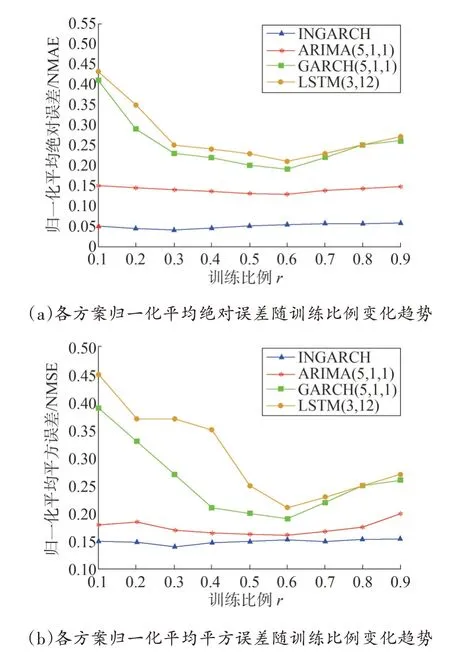
图1 各方案性能指标随训练比例的变化
图2 为山东电力话务真实数据与INGARCH 提前1 步预测的对比,其中横坐标轴代表某天工作时刻08:00—20:00,纵轴代表山东电力话务中继占用爱尔兰指数。蓝色曲线表示真实的话务数据指数,红色曲线代表INGARCH 方案训练比例r为0.6 时的提前1 步预测。从图中可以看到,山东电力话务数据在每天08:00—13:00 和13:00—18:00 呈现双波峰形状,可以用两个泊松函数进行拟合,从而验证了电力话务数据呈现泊松过程的假设。同时可以看到,使用INGARCH 方案进行提前1 步预测的效果非常好,仅在少量时间点(如08:30 左右)出现预测误差较大情况。经过计算得到,INGARCH提前1步预测的归一化平均绝对误差为0.011,归一化平均平方误差为0.00012,预测效果非常好。
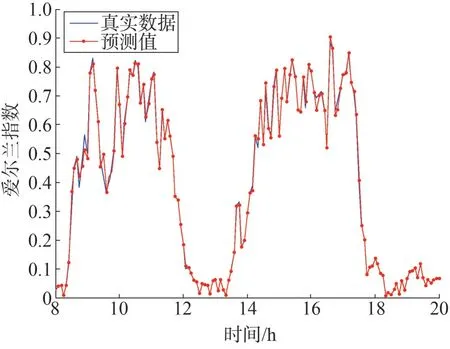
图2 真实数据与INGARCH提前1步预测对比
图3 给出了真实数据与各方案在提前4 步预测的结果对比,真实数据使用的是山东电力某日15:00—18:00 话务中继占用爱尔兰指数。图3(a)为INGARCH 方案的提前4 步预测结果与真实数据对比,从图中可以看到,该方案预测值相比真实值存在一定的延时,预测值晚于真实数据,但整体趋势预测相对准确。图3(b)为GARCH 方案提前4 步预测结果与真实数据对比,从图中可以看到,该方案预测值明显高于真实数据,且该方案预测值较为平稳,因此对数据波动性的感知较差,无法感知话务中继占用的波动性。图3(c)为ARIMA 方案提前4 步预测结果与真实数据对比,可以看得该方案的预测值接近于真实数据的平均值,且与GARCH 方案一样,该方案预测值较为平稳,对数据波动性的感知较差。图3(d)给出了LSTM 方案提前4 步预测结果与真实数据对比,可以看得该方案的预测值远小于真实数据,但该方案对数据波动性感知较好,预测结果与真实数据波动一致,整体趋势相对准确。通过图3 对各方案预测能力的对比我们发现,INGARCH 方案对真实数据的提前4 步预测结果比其他方案预测准确性高,同时对数据波动性敏感,预测效果较好。因此,将INGARCH 方案作为电力话务流量预测模型是可行的。
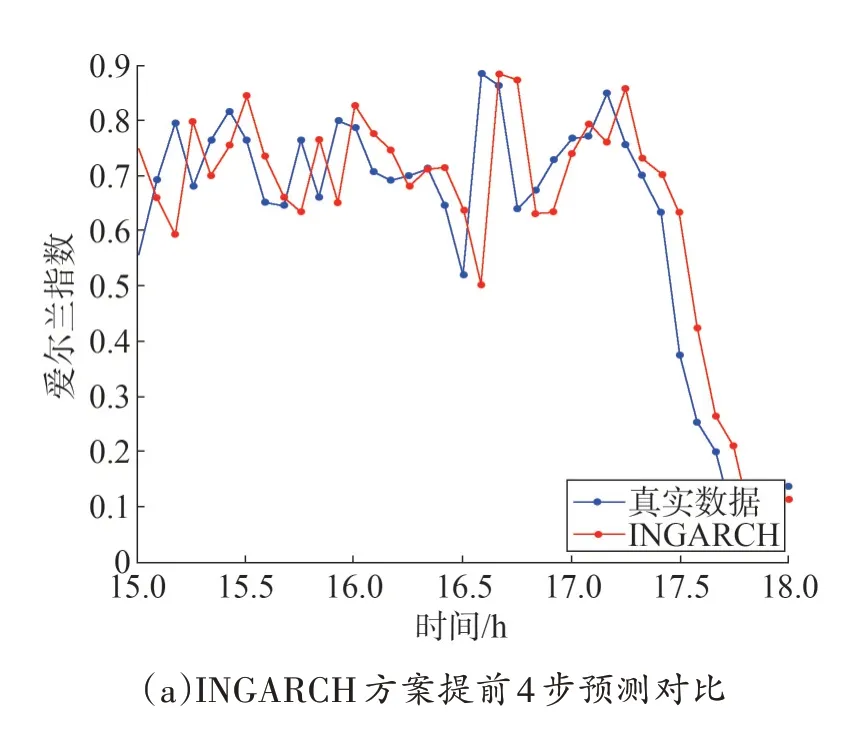
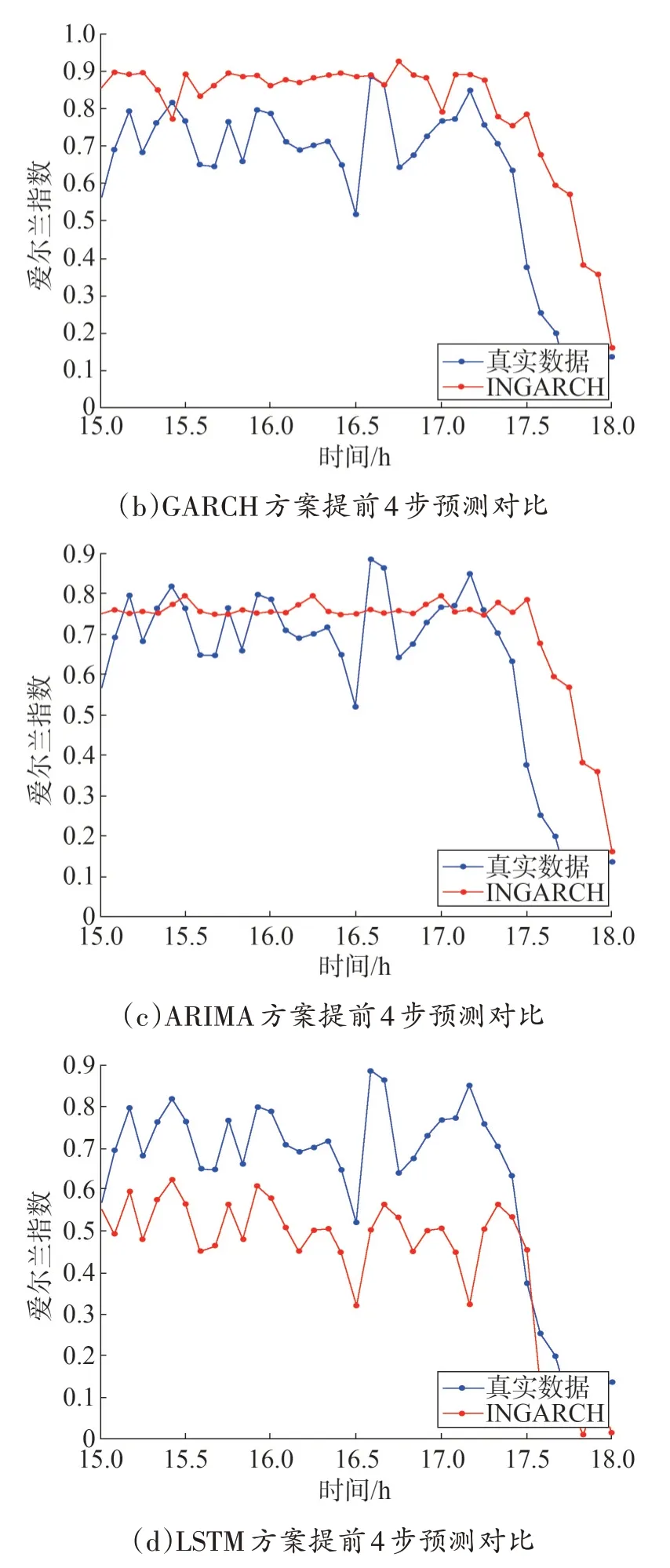
图3 真实数据与各方案提前4步预测对比
4 结语
引入整数值广义自回归条件异方差(INGARCH)模型作为电力系统话务流量时间序列预测模型,详细介绍了模型定义和预测方法的数学原理,然后通过四步法对未来过程的泊松参数进行预测。采用山东电力工作日内的话务流量数据作为实验数据,并将INGARCH 与ARIMA、GARCH、LSTM RNN 三种不同模型的性能进行比较。结果表明,泊松假设在电力系统话务数据中仍然有效,INGARCH 方法的提前1步预测效果非常优秀且提前4 步预测效果明显优于其他三种典型模型,因此,INGARCH 模型能够很好地对电力企业未来话务量进行预测。未来,将把该模型用于实际的电力话务流向分析平台中,并积极对该模型进行优化改进,持续提高模型预测准确性。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
玩具世界(2022年2期)2022-06-15
莆田学院学报(2021年5期)2021-11-13
房地产导刊(2021年8期)2021-10-13
成都信息工程大学学报(2021年1期)2021-07-22
出版人(2020年4期)2020-11-14
时代经贸(2019年33期)2019-12-02
信息技术时代·中旬刊(2019年1期)2019-10-21
电子制作(2017年23期)2017-02-02
中国新技术新产品(2010年6期)2010-09-07
