
软件定义网络面向异常流提取的自适应流抽样算法
2022-09-26 10:09谢欣
化工自动化及仪表 2022年5期
谢 欣
(昆明理工大学a.信息工程与自动化学院; b.云南省人工智能重点实验室; c.云南省计算机技术应用重点实验室)
软件定义网络 (Software Defined Network,SDN)作为一种创新性网络体系结构,其基于抽象网络的概念打破了控制逻辑与转发逻辑之间的紧耦合,控制接口开放化、标准化的特点解决了传统网络结构固有的诸多难题,近年来已成为业界学者们的研究热点[1]。 然而SDN网络集中控制的特性也使得它更容易遭受网络攻击,近年来出现了多起网络安全事件,较为典型的是微软“永恒之蓝” 漏洞引起的恶意勒索攻击、Mirai僵尸网络的DDoS攻击等[2]。
网络遭受攻击时通常表现为流量异常,即网络中存在不符合预期的行为模式的流量[3]。但目前信息化时代爆发的高维度海量高速动态流量使得实时在线的网络骨干链路全采集流量测量变得极为困难。 为解决上述问题,网络抽样技术应运而生, 并成为检测网络异常流量的重点技术之一。
传统的抽样技术如系统抽样、随机抽样等静态抽样方法在应用于流量监测时存在诸多缺点:一是布署困难,会消耗大量系统资源;二是需要人为配置, 网络流量会随时间呈现不同状态,传统抽样方法抽样比在抽样过程中无法改变,效果较差。 为了减小传统固定速率采样中产生的偏差和负载,在众多抽样方法中选择对流量进行动态自适应采样较为合适,即根据不同的流量速率选择相适应的抽样间隔。 目前,国内外学者针对网络流量自适应抽样采集测量已经进行了大量研究。 文献[4]构建了一种低开销的自适应采样算法, 该算法可计算SDN网络流当前时刻和上一时刻的吞吐量,根据预先设定的吞吐量变化率的上下阈值更改采样频率, 若吞吐量变化率超过阈值,则缩小采样轮询时间间隔,反之则增大间隔;然而该算法将流量变化情况根据所设阈值分为3种情况,过分依赖固定阈值,容易造成抽样精度及网络开销波动大的情况。 文献[5]提出一种基于聚类簇结构特性改进的自适应综合过采样法,首先采用谱聚类的方法对部分样本进行聚类分析并获取其结构分布特性,然后以少数类样本点和聚类簇心的几何中心进行自适应过采样。 虽然该算法相较于原始算法有所改善,但仍存在可能会破坏少数类样本原始分布的问题。
由于网络流量呈重尾性分布的特点,网络中存在大量大流,但异常流量大多是以小流的形式存在,因此提高小流的抽样概率对后续异常流量的检测至关重要。 文献[6]将流的源地址和目的地址进行分类划分并作为流标识,设置最大抽样比例,刻画异常流源地址熵值,根据熵值估算异常流源地址分散度,对正常流量和异常流量按不同刻画概率抽样,该算法在一定程度上能对异常流量进行分辨并抽样,但对异常估计不足,容易将流地址正常的异常攻击流当做非攻击异常流过滤,造成大量小流的丢失。 文献[7]改进典型的SGS算法, 将时间轴切割, 形成独立的片段观测段。 为保证小流抽样概率,牺牲一定的大流抽样精度, 抽取出每个片段观测段内观测流中第1个到达的数据包,同时结合SRAM和DRAM减少存储资源消耗。 由于该算法直接抽取符合条件的数据包,因此并不需要估算流长。 但是若存在大量小流在等长片段观测段内将造成大量的小流漏检。另外, 算法精度依赖于片段观测段划分长短,对于动态高维度的海量网络数据流量,动态划分时间片将占据大量的通信链路成本,难以保证划分的实时性和精度。
针对以上问题,笔者提出一种软件定义网络面向异常流提取的自适应抽样算法,该算法实时感知流量变化,首先利用图论的介数中心性算法进行流量抽样点决策,根据流量矩阵选择较优抽样位置,对不同交换机制定不同的抽样比。 然后对不同流量集的交换机监测流依据观测期间内流量流速大小匹配规则自适应地调整抽样比,以确保小流的抽样精度。 最后以流量曲线最近的3个轮询点近似曲率值为依据,自适应优化控制器轮询频率,从而降低网络开销。 经仿真实验佐证,该方法能在提高小流抽样精度的同时减少网络开销,为后续异常流量的检测划分提供了较优的低维度待测数据集。
1 相关工作
SDN网络中流量抽样采集方式大致可划分为基于数据推送的采集模式和基于数据请求的采集模式。
借助于来自SDN交换机的异步消息PackIn和FlowRemoved, 控制器可以直接接收数据流表统计的信息而不需要引入额外的数据流量,这种方式被称为基于数据推送的采集模式[8]。 这种通信方法,控制器不会向所有交换机下发关于流量统计的请求或消息, 不会直接造成通信性的开销,缺点是会严重占用所有交换机有限的通信流表时间,造成交换机的通信性能开销,同时控制器只有等待活动流到期或被移除触发FlowRemoved消息后才能执行采集动作,无法保证精准的实时性[9]。另外,FlowSense利用触发PackIn消息但还未被移除的流量在一定采集周期内的速率估算链路利用率,该方法存在时延,需等待活跃流到期在控制器接收FlowRemoved消息后方能进行计算,而且时延随流量的增加而递增[10]。 文献[11]提出一种基于推送和预测的低开销近实时流量采集算法,该算法基于自适应推送模型和时间序列预测模型,使用自适应轮询率在交换机上执行自适应推送,利用预测值将源节点的流信息直接推送至控制器而无需应答,该算法能够有效降低大量网络开销,但是牺牲了一定精度,还会存在少量的采集错误。
基于数据请求的采集模式是控制器通过向交换机或是对应流量下发数据信息采集消息,然后将消息答复返回给控制器。 理论上高频率的轮询交换机会获得较高精度的采集数据,但同时也会造成较大的网络开销,因此该方法需要尽可能平衡抽样精度和网络开销,在保证抽样精度的同时尽可能减少网络负载。 PayLess[12]位于SDN控制器的北向接口,能够解析应用层的请求任务并自适应地收集流信息, 不会产生显著的网络开销,同时对外提供了灵活的RESTful接口。但该框架只检测部分交换机以此来减少消息负载和开销,在真实高纬度网络中容易错失大量重要流量信息。文献[13]提出一种基于置信指数的新型自适应采样算法,该算法赋予流量信息一个初始置信指数,若控制器返回偏差信息,则对应流的置信指数将增加,否则将根据偏差度减小。 该算法能够在保证准确性的同时减少消息通信数目,有效降低网络开销,但该算法基于流量方差评判必定会产生误差, 而且算法并未在真实流量环境中实验,准确性和实时性还有待评估。
2 算法设计
2.1 设计思路
目前,在软件定义网络环境中流量采集大多是利用基于数据请求的采集算法实现的,它是一种细粒度的采集方法,会为网络中的所有数据流下发一个信息统计请求。 理论上来说,高频率的发送信息采集请求可以获得较高精度的流量数据信息,但同时也会引入较大的通信开销。 相反,若为了减少网络负载,势必要降低发送请求的频率[14]。 上述算法为了平衡网络通信开销和流量信息采集精度,都动态地对流量数据下发采集请求的频率进行了优化。 即便如此,若网络中存在大量的活跃流,则控制器会对交换机中的每个活跃流下发一次采集请求, 这势必会在SDN控制器和交换机之间造成庞大的通信费用[15]。
由于网络中交换机的数量不会动态变化,操作复杂程度远小于对每个流量制定抽样比,因此为减少网络开销,首先应为抽样动作找一个优势采集点,为网络拓扑中不同重要程度的交换机选择不同的抽样比进行流量采集以减少控制器与交换机之间的通信成本。同时,利用SDN环境中协议对各个交换机中的各个流定制相应流表规则的特点,根据不同时段不同流量的速率更改流表下发规则以自适应地对网络流量进行抽样,确保小流的抽样精度。 为了平衡轮询频率和抽样精度的关系,可利用流量曲率[16]作为平衡标准,自适应调整轮询频率,进一步减少网络负载。
2.2 自适应流抽样算法
2.2.1 抽样点决策
在软件定义网络环境中借由OpenFlow协议,基于数据请求的方法可在流量链路和交换机两种方式下获取数据信息统计消息[17]。 从流量链路获取是利用控制器为每一条活跃流下发一个数据采集请求,并由活跃流流经的交换机将每条流的流表信息统计数据传回控制器。 从交换机获取是利用SDN控制器直接向指定交换机下发流表信息统计指令,收到指令的交换机将流经该交换机的所有活跃流数据一同返回控制器。 尽管在SDN环境中可利用协议对每一个SDN交换机进行流量采集, 但高量度的快速流量数据集同样会导致控制器流表处理过程产生巨大的开销和通信开销[18]。上述两种获取流量的方法都存在对相同流重复抽样的情况。 因此在网络中选择合适的抽样点并排除冗余流量对降低网络开销尤为重要。
针对上述需求,笔者根据不同交换机在网络链路中不同时间点的不同重要程度,利用介数中心性算法进行抽样点自适应决策,基于最短路径对网络图中心性进行衡量,即每个交换机的介数中心性即为图论最优链路流经该交换机的次数,也就是该交换机在相应网络拓扑中作为抽样点的重要性,其被定义为:

其中,σst是交换机s与t之间所有最优链路总和,σst(v)为这些链路经过待抽样决策点v的次数。
传统的介数中心性算法首先选择源节点s进行一个以广度为基础优先的计算,然后在遍历的整个过程中将每个节点推入堆栈中,同时保留每个节点作为其他节点先驱的集合, 最后利用式(1)进行计算。
将该算法应用于网络流量时可以把某一顶点的重要程度量化成与其他顶点的拓扑关系。 假设任一节点有k个可能的最短路径, 那么在计算其中心性时,每一个路径的可能性都将被标记为1/k,而交换机的介数中心性则可以由控制器所提供的一个流经其中的流量信息来获得[19]。
以图1所示的简单网络拓扑矩阵为例, 其中相应的流量信息矩阵见表1。

图1 简单网络拓扑矩阵及示意流

表1 流量信息矩阵
设流信息矩阵Mat=[mij],其中mij为二进制数,若第i个流量流经第j个交换机,则mij=1,否则mij=0,Mat的尺寸是通过交换机数量表示的流量数。 则第j个交换机的介数中心数BCj表示为:

图1中各交换机的介数中心性依次可表示为2,1,2,3,2,3,1。
通常,位于网络核心周围的交换机会具有较高的介数中心性。 由于多个活跃流量流经多个交换机,会导致流被进行不必要的多次抽样,为避免某一中心性过高的交换机被过度抽样,将介数中心性最高的一个交换机给定一个Mat, 然后所有通过选定交换机的流都将排除在Mat之外,迭代更新Mat,直到流量信息矩阵中没有剩余流量。
选择抽样点后根据介数中心性为每一个交换机分配对应的抽样比, 设C表示交换机的抽样概率向量,若每个交换机原始抽样概率为ω,则第j个交换机的抽样概率可表示为:

2.2.2 抽样比调整
网络流量突发、自相似性等动态特征使得网络流量呈不平衡及重尾分布特性,网络中存在大量小流,异常流量的产生通常也是以小流的方式存在,因此提高小流的抽样比对后续的异常流量检测研究至关重要。 同时,为了在高速动态的网络流量中保证抽样采集数据的实时性和有效性,必须根据流量变化自适应调整抽样比,尽可能地使抽样数据分布逼近于真实流量数据分布。
在OpenFlow1.5标准协议基础上更改流表项,增加相应的流抽样准则,可更加细分网络中的目标流, 有针对性地对链路中的每条流进行操作,从而在误差允许范围内提高抽样精度[20]。 假设存在流集合F={f1,f2,…,fn},每条流fi在对应时间点{t1,t2,…,tw}的抽样流量信息为{in(t1),in(t2),…,in(tw)},若有流f经j交换机抽样,则x(f,td)为td时刻获取到该流的报文数量,若抽样概率为p,则该流在td到td+1观测段内的报文数据的传输速率可大致估算为:

根据抽样流信息可将流f在该时间段内的流速近似计算为:

引入一常数作为抽样比的动态调整常指数。一段时间内若报文传输速率和流速都较大,即网络中存在大量高速动态流,为避免抽样比短时间内过分变化, 造成抽样混乱增加不必要的负载,引入加权移动平均法进行优化,利用过渡系数加权前期及当下数据,以式(5)所估算的流速为依据,动态调整目标流的抽样比,估算流速与抽样比呈反比,即流速越小抽样比越大[21]。 同时,以观测周期内前一条流流速为基准,调整下一观测周期内对应流的抽样比,此时抽样比计算式为:

其中,η为比例调整常数参数;γ为过渡系数,表示当下抽样数据的重要程度,0<γ<1,γ越趋近于1, 则前期抽样数据的权重越低;pd为上一观测周期;p′d+1为当前观测周期内流f的抽样比。
依据流量信息矩阵, 可近似将过渡系数γ看作当前交换机的匀速采样的概率,经j交换机抽样的流f时的γ值计算式为:

此时,经j交换机抽样的流f在观测周期td到td+1时间对应的抽样比为:

2.2.3 轮询频率优化
在SDN环境架构下, 交换机本身未布署过多的转发控制逻辑,通过控制器定时发送请求消息轮询交换机获取网络流量状态信息。 短时间内高次数的轮询交换机,可以获得准确性较高的流表数据,但会造成较大的通信开销,但若要获取实时的流量统计信息又不得多次获取交换机信息,因此为了降低轮询频率、减少通信开销和控制器负载,应尽可能保证流量数据的精度,对交换机轮询频率进行调整,根据流量数据的变化自适应地调整其频率。
笔者将轮询问题转化为连续曲线抽样到离散点的问题,根据轮询数据曲线的变化调整轮询速率,利用流量曲线的瞬时曲率确定下一个离散点。 由于在网络环境中流量的瞬时曲率计算难以实现, 因此可以利用连续3个度量点斜率之间的百分比变化来近似表示曲率。 如果在轮询之间检测到明显曲率,则表示流量数据速率较快,增加轮询频率,反之则降低轮询频率。
算法步骤如下:
a. 设置阈值Δ、 轮询比例系数ε和μ以及轮询间隔范围,最大轮询间隔为ϑMax,最小轮询间隔为ϑMin,初始轮询间隔ϑ为1.5 s;
b. 设置两个数组分别存储最近3次轮询点的统计测量数据和时间;
c. 采用最后3次轮询点数据计算连续两点间的斜率,以图2为例,则最近连续两次轮询点的斜率分别为:

图2 流量统计曲线

d. 比较连续两点间斜率的百分比变化,即曲率的近似值,若比值大于所设阈值Δ,则减少轮询间隔,此时轮询间隔为:
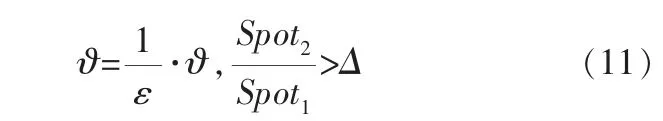
反之,若两点间曲率近似值小于所设阈值Δ,则增加轮询间隔,此时轮询间隔为:
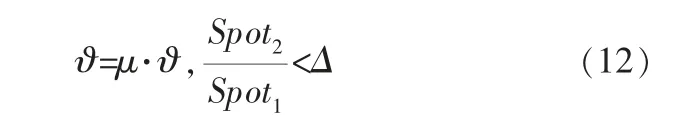
2.3 算法流程
算法具体执行过程如下:
a. 跟踪网络流量,建立流信息矩阵;
b. 图论化网络拓扑,利用介数中心性选择某一时段较优的抽样点;
c. 迭代更新流信息矩阵,排除最高中心性点流量信息,并为不同介数中心性值的交换机设置不同抽样比;
d. 根据观测周期内流速变化改造流表项动作集, 自适应调整对应交换机内相应流的抽样比,根据改造的不同流表抽样比规则执行抽样动作;
e. 选取最近3次轮询点计算两点斜率, 将其比值看做近似曲率,将其与所设阈值的大小关系作为调整轮询频率的依据,根据流量流速变化自适应调整轮询频率。
3 仿真实验与结果
3.1 算法仿真环境及网络拓扑
为验证本文算法的有效性, 使用WIDE项目中某日上午8时至8时15分的互联网实际主干跟踪流量数据以及CAIDA Attack 2010异常数据集,对本文算法进行实验仿真。 实验中,比例调整常数参数η=4。 实验基于ubuntu18.04 操作系统、Floodlight 控 制 器 和mininet 流 量 仿 真 环 境。 在ubuntu18.04环境下, 使用mininet构建如图3所示的网络拓扑。

图3 实验网络拓扑图
3.2 结果分析
3.2.1 异常流量检测情况
将WIDE的正常流量数据集和CAIDA Attack 2010的异常数据集按5∶1的比例随机抽取,分别构造10个包含18 000条数据流的实验测试子集。 每个子集包含3 000条异常流量和15 000条正常流量。 利用构造的实验测试子集分别测试随机抽样算法、文献[6]算法、文献[12]算法、文献[13]算法以及本文算法对于异常流量数目的保留情况,结果如图4所示。

图4 不同算法异常流保留情况
由图4可以看出,对于相同的实验测试子集,在同一测试环境下,本文算法能保持较高的异常流保留比例。 传统的随机抽样算法会抽取流量数据中占比较高的大流,导致以异常检测为前提的流量抽样效果较差,以本实验中的10个测试子集为例,平均异常提取率仅为6.46%;文献[6]基于对异常流源地址熵值的刻画能够抽取出数据样本中较大比例的异常流,但由于该算法并不完全适配于软件定义网络环境,对其流量感知变化较弱,因此异常提取率不佳,仅为62.47%;文献[12]算法对SDN环境中异常流有一定的检测能力,但由于该算法监测网络拓扑中的部分交换机,因此漏检率较高, 同时对异常流的提取不太稳定,该算法平均提取率约为49.57%;文献[13]算法基于置信指数和流量预测对网络流量进行评估,实验结果表明, 该算法具有较优的异常流提取能力,异常提取率可达到88.14%。 本文算法侧重于提高包含异常流比例较高的小流的抽样比例,实验结果表明,其平均异常流提取率可达97.76%,相较于该领域较新的文献[13]算法提高了9.62%,相较于传统异常抽样算法 (文献 [6]) 提高了35.29%。 由此可以看出,传统抽样方法并不能完全适配于软件定义网络,同时若不提高小流的抽样精度将造成大量的异常流漏检,本文算法在一定误差范围内对异常流有较优的抽样效果,具有较高的抽样精度。
3.2.2 数据流处理时间
利用构造的10个实验测试子集分别测试随机抽样算法、文献[6]算法、文献[12]算法、文献[13]算法以及本文算法的数据流处理时间,结果如图5所示。

图5 不同算法计算时间
从图5可以看出,对于相同的实验测试子集,在同一测试环境下,本文算法所需计算时间相对较少。 结合图4来看,随机抽样算法计算时间相对较长,但异常流保留能力过差,因此并不适用于异常流提取环境,以本实验中的10个测试子集为例,平均抽样处理时间为0.341 s;文献[6]算法虽然有较强的异常流抽样能力,但由于该算法需对流源地址熵值进行刻画,算法复杂度较高,同时对SDN流量感知不明显,因此所需计算时间长,平均抽样处理时间为0.723 s;文献[12]算法采用自适应轮询,同时由交换机选择器选择待轮询的交换机集,因此算法计算时间相对较短,平均抽样处理时间为0.195 s;文献[13]算法的轮询比例是基于计算和预测节点得出的,能有效降低控制器和交换机之间的交换消息数,因此具备较高的计算速率,其平均抽样处理时间为0.041 s;本文算法采用抽样点决策,优化了轮询频率,极大程度地降低了网络开销和通信负载,其平均抽样处理时间为0.015 s,相较于该领域较新的文献[13]算法提高了63.4%。 由此可以看出,本文算法在保留较高异常流抽样比例的同时数据流处理时间也相对较短,具有很好的应用价值。
3.2.3 链路利用率
使用链路利用率作为基本指标评估本文算法[22],随机选取WIDE数据集中连续的60 s流量数据作为测试子集。 设置算法最大轮询间隔ϑMax=4 s,最小轮询间隔ϑMin=0.3 s,轮询比例系数ε=4、μ=2,阈值Δ=10 MB,同时设置固定轮询间隔为1 s。
图6为观测时间内交换机1和交换机4之间的链路利用率。 可以看出,在同一观测环境下,文献[10]算法由于测量粒度较大,很难感知捕获流量峰值, 而且该算法控制器在接收到FlowRemoved消息后才进行计算,存在较大时延,测量值与实际流量数据出入较大;文献[12]算法由于轮询粒度问题,导致其测量值普遍小于实际流量;文献[13] 算法所得测量值接近于实际链路, 算法较优;文献[15]算法对部分峰值捕捉能力较弱。 相比之下,本文算法所得的测量值更接近实际链路的利用率。

图6 不同算法链路利用率
3.2.4 抽样成本
引入标准化的均方根误差来度量算法的准确性和系统开销,计算式如下:

成本函数定义为:

其中,Sampling表示抽样数据中异常流所占值,Actual 表示原始数据中异常流所占值,Expenses表示控制消息计数。
使用成本函数进行网络开销评估,并按成本比例比较上述5种算法。
表2为5种算法的均方根误差、消息计数和成本的统计结果。 本文算法相较于文献[10]算法、文献[12]算法、文献[13]算法、文献[15]算法的均方根误差分别降低了0.394 1、0.221 1、0.015 4、0.308 1,消息计数降低了571、108、9、5 796,成本降低了约334.133 2、68.761 2、3.383 5、2 280.286 2。由此可见,本文算法在误差允许的范围内对网络开销的减少是十分明显的,具有实际应用意义。

表2 抽样结果比较
4 结束语
高速动态高维度全链路流量数据采集极为困难,传统抽样技术并不适配于软件定义网络架构,而其固有的抽样手段又无法保证小流的抽样精度, 导致交换机轮询频率与抽样精度难以权衡,为此提出本文的解决方法。笔者结合SDN架构特点实时感知流量变化,首先利用图论的介数中心性算法进行流量抽样点决策,根据流量矩阵选择较优抽样位置, 对不同交换机制定不同抽样比。 然后改造流表项抽样动作,对不同流量集的交换机监测流依据测量期间内流量流速大小匹配规则自适应地调整抽样比进行抽样,以确保小流的抽样精度。 同时,以流量曲线最近的3个轮询点近似曲率值为依据,自适应调整控制器轮询频率,减少网络开销。 最后仿真实验结果表明,本文算法能在确保抽样精度的同时减少网络开销,具有较好的应用前景,为后续异常流量的检测划分提供了较优的低维度待测数据集。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
网络安全与数据管理(2022年3期)2022-05-23
移动通信(2021年5期)2021-10-25
数码世界(2020年11期)2020-11-23
电子制作(2019年20期)2019-12-04
网络安全和信息化(2019年7期)2019-07-10
计算机与数字工程(2019年2期)2019-02-28
电子制作(2019年24期)2019-02-23
中国教育信息化·基础教育(2018年3期)2018-04-12
科技创新导报(2016年27期)2017-03-14
