
基于BERT模型的中华典籍问句分类方法研究
2022-09-24 14:32刘忠宝贾君枝
晋图学刊 2022年3期
刘忠宝,贾君枝
(1.北京语言大学 语言智能研究院,北京 100083;2.中国人民大学 信息资源管理学院,北京 100872)
0 引言
近年来,党和国家对中华传统文化高度重视,多次在重要文件和讲话中强调中华传统文化的重要性。作为中华传统文化重要载体的中华典籍是中华优秀传统文化的强大根基,越来越多的国人开始关注和学习中华典籍。互联网的飞速发展助推了这种学习热潮,这无疑会增加互联网上中华典籍的提问和搜索数量。
传统搜索引擎通常要求用户将检索请求表示为少量关键词的组合,返回的结果是与检索请求相关的信息列表,上述检索方式存在信息过分冗余、检索精度不高等问题。问答系统的出现有效地解决了上述问题。该系统允许用户使用自然语言提问,并返回确切的答案。问句分类是问答系统的一个重要环节,如“成语‘背水一战’出自哪里?”“《新唐书》作者是谁?”等问句主要问及中华典籍的出处和基本信息。问句分类是指在明确分类依据的前提下,根据问句的语义和答案的特点,来确定问句的类型。明确了问句类型,不仅能够降低答案检索的时间代价,而且还能够提高查找答案的准确率。因此,有必要对问句分类问题进行研究,以提高问答系统的工作效率,进而为中华典籍的学习和传播提供有利支撑。
1 研究进展
当前,问句分类的研究方法可归纳为三类:一是基于规则的问句分类方法;二是基于统计学习的问句分类方法;三是基于深度学习的问句分类方法。
基于规则的问句分类方法通过提取各类问句中关键词(如疑问词、相关词等)的特征规则来判断问句类别。如问句中出现“哪”“在哪”等词就可以判断答案与地点相关。早期的问答系统都基于规则的问句分类方法。Magnini等在DIOGENE问答系统的基础上扩大了问句的类型,利用340余条规则来识别问句的特征,并根据上述特征给出问句的类型[1];Yang等引入语义技术,利用基于规则的算法对问句进行命名实体识别,以提高问句分类的精度[2];樊孝忠等借鉴本体和知网思想,给出基于问点块和语义块的规则,实现了金融领域问句的自动分类[3];辛霄等面向实际应用场景,将自动问答技术与网友问答内容相结合,以网友问答内容作为知识库,利用自动问答技术建立规则,并基于此从知识库中找到合适的答案[4];贾君枝等在分析农民问句特点的基础上,提出基于“特殊规则表”的疑问句和短语的问句分类方法,以期解决问句归类问题[5]。基于规则的问句分类方法实现简单,分类速度快,在解决特定领域问句分类问题时具有较高的效率。但该方法依赖于规则,当语料规模增大时,需要人工定义更多的规则,这无疑增大了工作量。此外,当问句表示形式和问句分类体系发生变化时,这些规则灵活性不够、适用性不强。因此,近年来该方法的研究没有很大进展。
基于统计学习的问句分类方法在标注部分问句的基础上,选择具有代表性特征来对问句建模,通过训练模型实现问句分类。常用于问句分类的统计学习模型有支持向量机(Support Vector Machine, SVM)、贝叶斯网络(Bayesian Network, BN)、最大熵(Maximum Entropy, ME)模型等。Zhang等提出基于树核函数的支持向量机,该模型在问句分类时将问句的句法结构考虑在内,因而其具有较高的分类效率[6]。Li等融合问句的句法信息、语义信息以及WordNet词典知识来进行问句分类,UIUC数据集上的分类准确率达91.60%[7];Zhang等利用改进的贝叶斯模型融合词频和词性特征对问句分类[8];Wen等利用贝叶斯分类模型将问句的主干和疑问词及其附属成分作为分类特征[9];Dai等针对问句所属领域经常变化的情形,利用KL距离衡量不同领域之间的差异并借助最大似然模型对问句分类[10];Liu等在支持向量机的基础上引入句法依存树和问句属性核函数来对问句进行分类[11];Li等充分利用少量标记样本和大量未标记样本,提出一种基于集成学习的半监督问句分类方法[12];Momtazi利用无监督的隐狄利克雷分配模型解决社区问答系统中的问句分类问题[13];Muhammad等提出一种基于逻辑回归(Logistic Regression, LR)的数据转换方法,用于解决多标签生物医学问句分类问题[14]。国内开展相关研究较晚,典型代表有:余正涛等分析和定义了汉语问句的类型,建立了以支持向量机为基础的问句分类模型[15];贾可亮等引入HowNet义原树来计算问句之间的语义相似度,并构建基于k-近邻算法的分类器实现问句分类[16];范云杰等针对社区问答系统中的问句分类问题展开研究,首先将问句的特征词映射为维基百科概念,接着利用维基百科重定向和消歧页解决同义词和多义词问题,然后提出基于链接结构和类别体系的概念关联度计算方法,以提高问句的语义表达能力[17]。
基于统计学习的问句分类方法涉及以下问题:一方面需要事先完成问句标注、句法分析以及语义分析等任务;另一方面人工选择特征具有一定的随机性和主观性;再者应用于问句分类的统计学习方法往往存在数据稀疏性问题。上述三方面制约了该方法效率的提升,因此,随着深度学习的出现,上述方法逐渐被基于深度学习的问句分类方法所取代。
基于深度学习的问句分类方法的优势在于:其一,该方法通过训练模型能够自动获取问句的特征以及问句类型之间的语义关系,上述过程无需人为干预,降低了人力成本,提高了分类效率;其二,该方法没有使用经典的N-Gram语言模型,而是自动获取并利用问句的词序特征,如卷积神经网络(Convolutional Neural Network, CNN)模型中的过滤器即发挥了N-Gram语言模型的作用。目前常用于问句分类的深度学习模型包括卷积神经网络(CNN)、循环神经网络(Recurrent Neural Network, RNN)、长短期记忆网络(Long Short-Term Memory, LSTM)、双向长短期记忆网络(Bidirectional LSTM, BiLSTM)等。Xiao等通过共享粗粒度分类和细粒度分类的上下文信息来构建多任务卷积神经网络模型,对法律问句进行分类[18];Xia等在长短期记忆网络的基础上引入注意力机制,该架构能够有效地提取问句的局部特征以及全局特征,因而具有较好地问句分类能力[19];Pota等提出一种基于词嵌入和卷积申请网络的问句分类方法[20];杨志明等在深入分析卷积神经网络的基础上,提出意图分类双通道卷积神经网络算法,用以解决问句意图分类问题[21],该方法利用Word2Vec工具提取问句中的语义特征,分别利用字级别的词向量和词级别的词向量进行卷积运算,利用字级别词向量辅助词级别的词向量发现文具中的深层次语义信息。中华典籍问句分类研究的成果不多,典型代表是王东波等利用支持向量机、条件随机场、深度学习模型对先秦典籍问句分类的研究,研究结果表明BiLSTM模型具有更优的分类能力[22]。
2018年底由Google提出的BERT(Bidirectional Encoder Representations from Transformers)模型创造了自然语言处理领域的多项记录。鉴于此,本文以《史记》《汉书》《三国志》《新唐书》《战国策》《资治通鉴》《聊斋志异》《儒林外史》《搜神记》《世说新语》等十部中华典籍的相关问句构成的语料集为基础,引入一系列深度学习模型,特别是BERT模型,以期进一步提高中华典籍问句分类的效率。本文后续章节安排如下:第3节介绍支持向量机(SVM)、循环神经网络(RNN)、长短时记忆神经网络(LSTM)、双向长短时记忆神经网络(BiLSTM)、BERT等深度学习模型。第4节首先引入问句分类体系以及中华典籍语料集,然后对比分析SVM、RNN、LSTM、BiLSTM、BERT等模型的实验结果,最后给出中华典籍问句分类系统平台。第5节对全文进行总结并指出下一步研究设想。
2 模型引入
2.1 SVM
支持向量机(SVM)最初由Vapnik等提出,是建立在统计学习理论和风险最小化原理基础上的分类模型。该模型通过构造一个超平面将两类分开。
给定训练集(xi,yi),i=1,2,…,n,支持向量机优化目标函数和约束条件如式(1)所示。
s.t.yi(wTφ(xi)+b)≥1-ξi,i=1,2,…,n
(1)
其中,w是超平面的法向量,b为偏置量,ξi为松弛变量,表示对噪声的容忍度,C为惩罚因子。
支持向量机一般应用于二分类场景。但中华典籍问句分类问题是一个多分类问题。本文通过组合多个二分类支持向量机来解决问句多分类问题。
2.2 深度学习模型
2.2.1 循环神经网络
循环神经网络(RNN)具有独特的序列结构,因而其适合捕获问句内部的语序特征。RNN由输入层、隐藏层、输出层和分类层组成,其基本结构如图1所示。
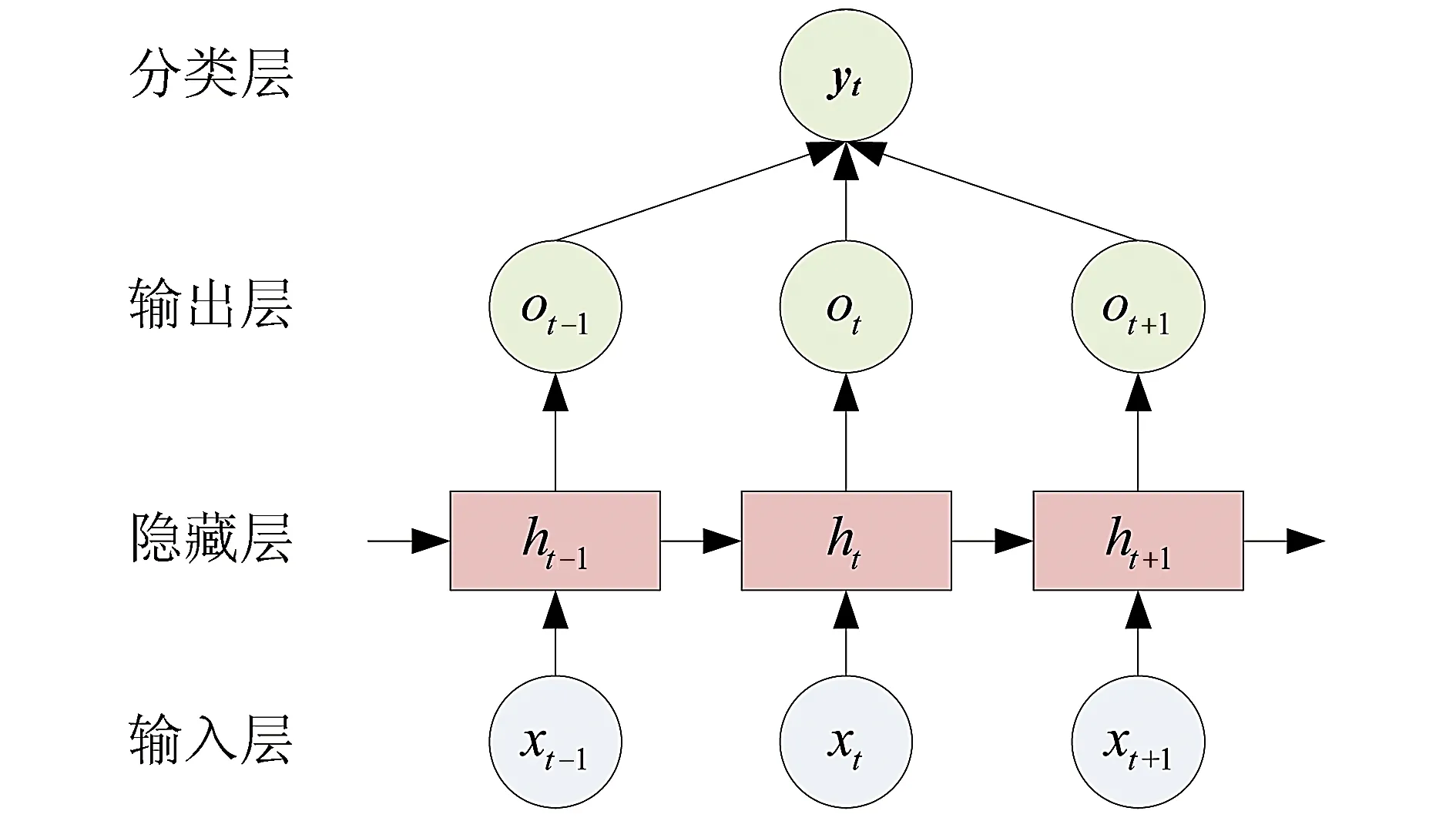
Fig.1 The structure of RNN图1 RNN结构
RNN的基本工作流程是:首先,将分词后的问句(x1,…,xt-1,xt,xt+1,…,xn)依次输入模型;然后,利用RNN的隐藏层(h1,…,ht-1,ht,ht+1,…,hn)提取问句的深层语义特征并得到特征向量(o1,…,ot-1,ot,ot+1,…,on);最后,依据分类函数得到问句的分类结果。
2.2.2 LSTM和BiLSTM
与RNN相比,长短期记忆网络(LSTM)和双向长短期记忆网络(BiLSTM)在隐藏层引入了门结构,该结构能对从输入层传来的问句信息进行更深层次的特征提取。LSTM和BiLSTM具有相似的工作机理,其不同在于:与LSTM相比,BiLSTM具有正向LSTM和反向LSTM两层结构,如图2所示。以BiLSTM为例,介绍其基本工作流程:首先,将分词后的问句(x1,…,xt-1,xt,xt+1,…,xn)依次输入模型;然后,利用BiLSTM隐藏层分别从正向(h1,…,ht-1,ht,ht+1,…,hn)和反向(hn,…,ht+1,ht,ht-1,…,h1)两个维度提取问句的特征;接着,将两个方向的特征进行拼接,得到特征向量(o1,…,ot-1,ot,ot+1,…,on);最后,利用分类函数得到问句的分类结果。
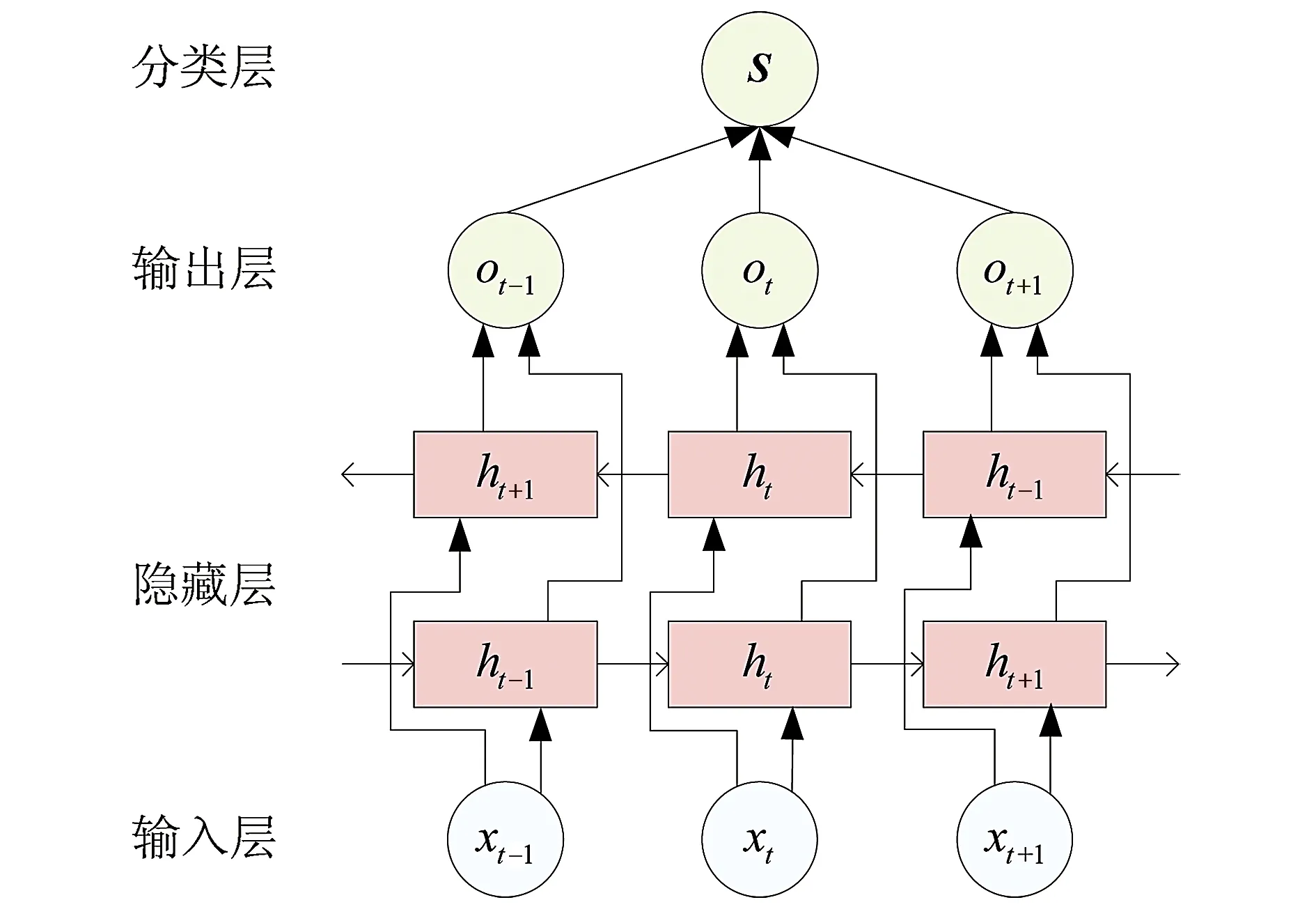
Fig.2 The structure of BiLSTM图2 BiLSTM结构
2.2.3 BERT模型
与传统的深度学习模型相比,BERT模型进一步增强了词向量模型泛化能力,充分描述问句字符级、词级、句子级甚至句间关系特征。该模型的基本结构如图3所示。
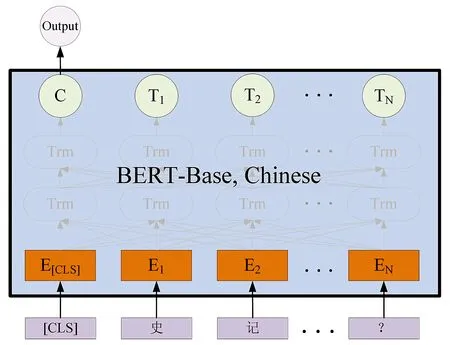
Fig.3 The structure of BERT图3 BERT模型结构
BERT模型的基本工作流程是:第一步,在问句开始位置增加一个起始标记[CLS],将该标记与问句一同输入模型;第二步,对起始标记和问句进行向量化表示(E[CLS],E1,E2,…,EN);第三步,经多层自注意力机制Trm进行特征提取后生成特征向量(C,T1,T2,…,TM);第四步,将起始标记[CLS]对应的特征向量C作为整个问句的语义表示,其原因是:[CLS]标记独立于问句存在,经特征提取后,该标记能够很好地表征问句特征,如果额外地增加其他特征,反而会效率降低;第五步,根据问句分类体系判断C的类型,即问句的类型。
3 实验设计与分析
分别从“百度知道”和“知乎”获取《史记》《汉书》《三国志》《新唐书》《战国策》《资治通鉴》《聊斋志异》《儒林外史》《搜神记》《世说新语》等十部中华典籍的相关问句2 000条,并人工进行类别标注。按照五折交叉验证的方式进行实验,避免单次实验的偶然性。五折交叉验证是指将语料集等分为五份,将任意四份作为训练集,剩余一份用作测试,取五次实验结果的均值作为最终的实验结果。
3.1 实验设计
3.1.1 问句分类体系
问句分类首先要明确分类体系,目前还没有一个统一的分类体系。常见的问句分类体系有:Lehner等提出的概念分类体系,包括:因果的前因、因果相随、目标导向、验证、启用、析取等[23]。Li等提出的分类体系包括缩写、实体、描述、人物、位置、数量等六类[7]。上述分类体系是针对英文问句提出的。在中文问句分类体系研究中,文勖等提出的分类体系包括人物、地点、数字、时间、实体和未知等七类[24]。董才正等提出的分类体系包括定义、事实、过程、原因、观点、是非、描述等七类[25]。上述分类体系并未考虑中华典籍的特殊性,均不适用于解决中华典籍问句分类问题。因此,本文给出一种适用于中华典籍的问句分类体系,如表1所示。
3.1.2 问句语料标注及预处理
实验中的2 000条问句具体分布情况是:《史记》《汉书》《三国志》《新唐书》《战国策》《资治通鉴》《聊斋志异》《儒林外史》《搜神记》《世说新语》分别有243、158、224、193、201、247、265、209、133、127条
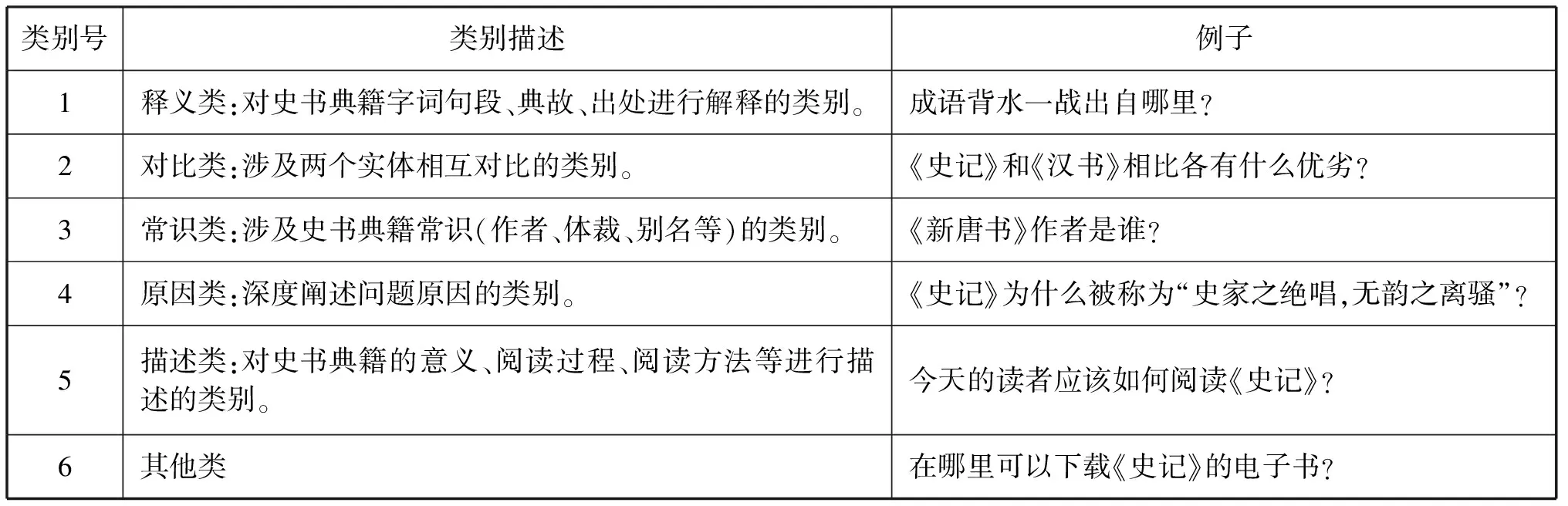
表1 中华典籍问句分类体系Table 1 The classification architecture of Chinese classics question
问句。对上述问句进行人工标注生成“中华典籍问句分类语料集”。在人工参与下,借助jieba汉语分词工具对问句进行分词。如,对“《史记》是一部什么体的史书?”分词后得到“《/史记/》/是/一部/什么/体/的/史书/?”。即使是较为困难的释义类问句也能达到较好的分词效果,如,“成语负荆请罪出自哪本书?”分词后得到“成语/负荆请罪/出自/哪/本书/?”。又如,“‘廉颇闻之,肉袒负荆,因宾客至蔺相如门谢罪’是什么意思?”分词后得到“‘/廉颇/闻/之/,/肉袒/负荆/,/因/宾客/至/蔺相如/门/谢罪/’/是/什么/意思/?”。在分词的基础上,需要将问句转化为向量表示。SVM利用Doc2Vec模型将每个问句表示为问句向量。由于问句向量包含的语义信息有限,故要对问句向量进行特征提取。利用TF-IDF算法统计各类问句的特征词,并将其按重要程度由高到低排列,人工选择最具代表性的特征词,如“相比”“哪个”常出现在对比类问句中,“是”常出现在常识类问句中,“为什么”一般出现原因类问句中,“如何”一般出现在描述类问句中。RNN、LSTM、BiLSTM等深度学习模型利用Word2Vec模型生成问句的词向量表示,由于BERT的工作原理基于字而非词,因而其无需进行分词处理。
3.2 实验步骤
3.2.1 利用SVM对中华典籍问句分类实验
SVM问句分类实验包括三个步骤:首先,拼接问句向量和特征词向量后输入到分类模型进行学习,得到分类依据;其次,根据分类依据对新到问句进行类型判定;最后,利用精度、召回率、F1值对分类结果进行评价。在SVM中,惩罚系数C的确定较为关键,多次实验结果表明,惩罚系数C=0.5时问句分类效果最优。常用的核函数有两类:线性函数和径向基函数,其中线性函数适用于线性可分的情况,其参数少且运算快;径向基函数适用于线性不可分的情况,其参数多且运算慢。综合考虑实验需求,采用线性函数作为核函数。图4展示了利用SVM对中华典籍问句分类的系统界面。
3.2.2 利用深度学习模型对中华典籍问句分类
深度学习模型问句分类实验包括三个步骤:首先,利用前面提到的预处理方法,将中华典籍问句表示为词向量,并依次输入深度学习模型;其次,利用反向传播算法调整模型参数,经多次迭代,得到最优分类模型;最后,利用分类模型,对新到问句进行类型判定,并对分类结果进行分析评价。RNN、LSTM、BiLSTM等深度学习模型的参数设置如表2所示,其中隐层神经元数表征深度学习模型的规模;参数batch_size表征一次学习的样本规模;学习率反映深度学习模型的更新幅度;Dropout值用来规避“过拟合”现象的发生;最大序列长度表示问句的最大长度;Epoch表示全体样本参与学习的次数。
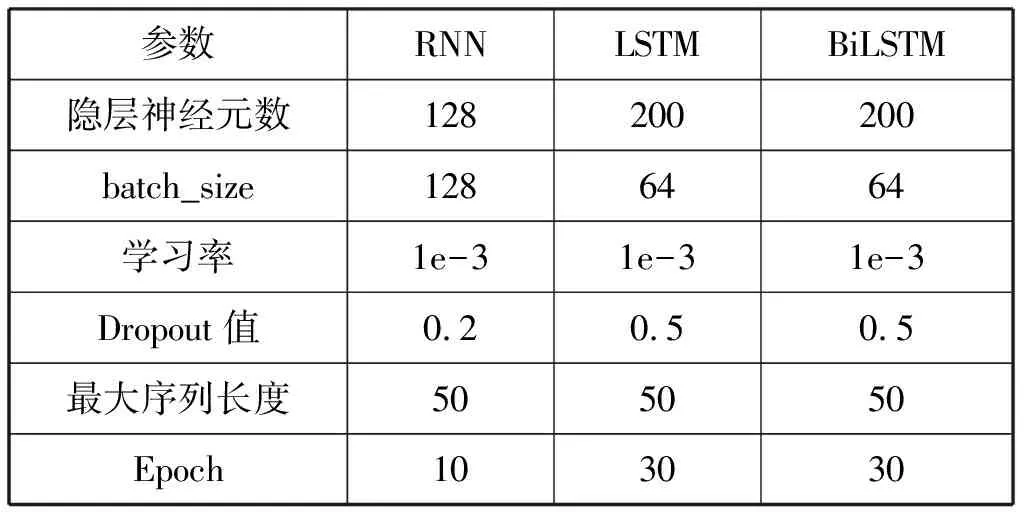
表2 RNN、LSTM、BiLSTM参数设置Table 2 The optimal parameters of RNN, LSTM and BiLSTM
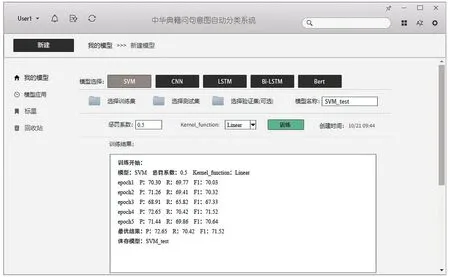
Fig.4 The interface of Chinese classics question system based on SVM图4 利用SVM对中华典籍问句分类的系统界面
图5、图6、图7给出了利用上述三类深度学习模型对中华典籍问句分类的系统界面。
3.2.3 BERT
BERT模型问句分类实验包括三个步骤:首先,将中华典籍问句逐字输入模型;然后,利用多层注意力机制进行特征提取;最后,依据问句分类体系,判断输入问句的类型。BERT模型的参数设置如下:batch_size设置为16,epoch设置为5,学习率设置为2e-5。
图8展示了利用BERT模型对中华典籍问句分类的系统界面。
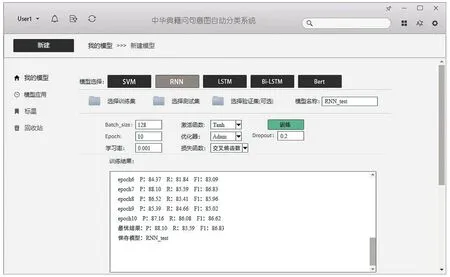
Fig.5 The interface of Chinese classics question system based on RNN图5 利用RNN对中华典籍问句分类的系统界面
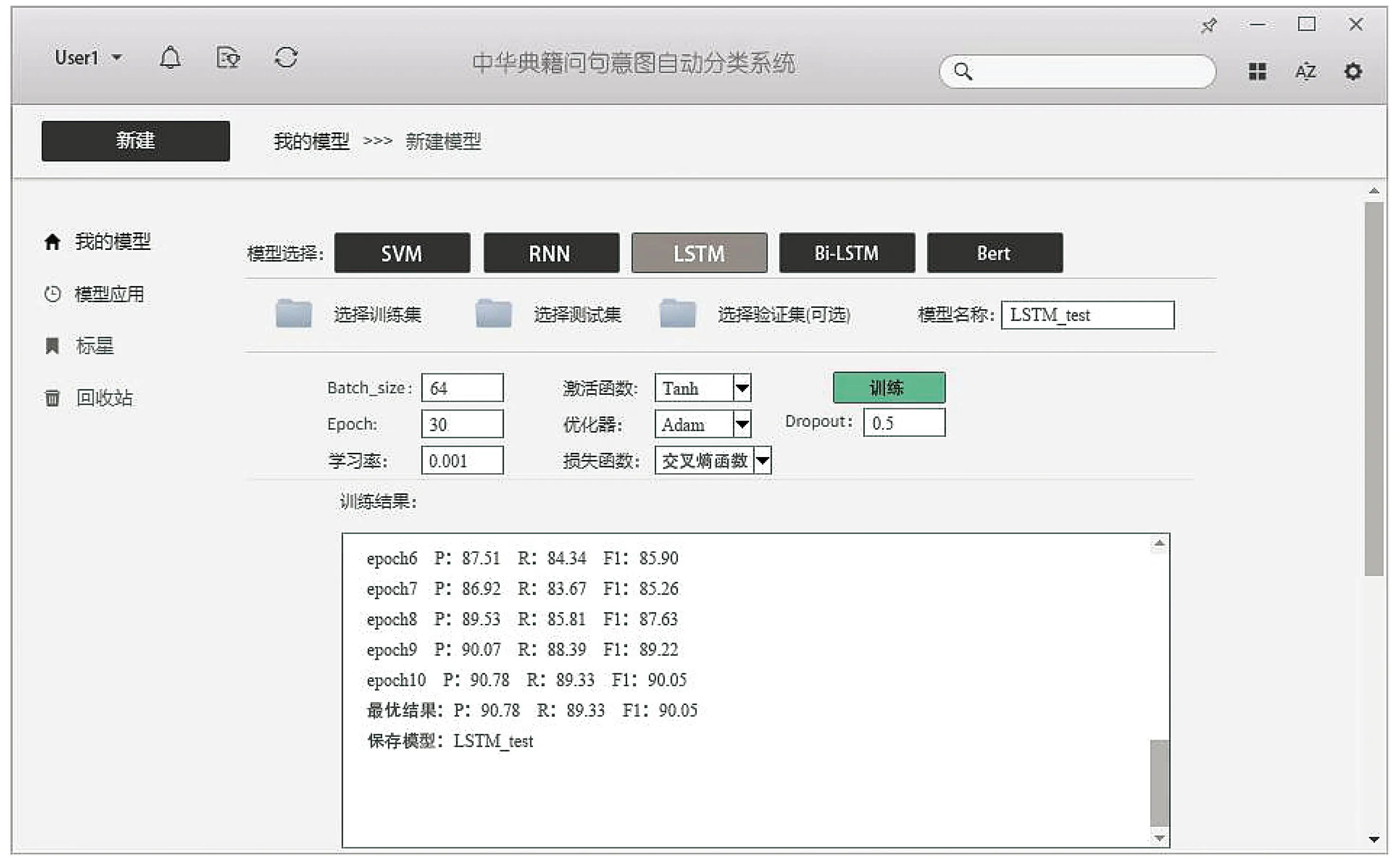
Fig.6 The interface of Chinese classics question system based on LSTM图6 利用LSTM对中华典籍问句分类的系统界面
Fig.7 The interface of Chinese classics question system based on BiLSTM图7 利用BiLSTM对中华典籍问句分类的系统界面
3.3 实验结果与分析
实验所用评价指标包括精度P(Precision)、召回率R(Recall)、F1值,定义如下:
在中华典籍问句分类语料集上先后运行SVM、RNN、LSTM、BiLSTM以及BERT等方法,将实验结果记录于表3。
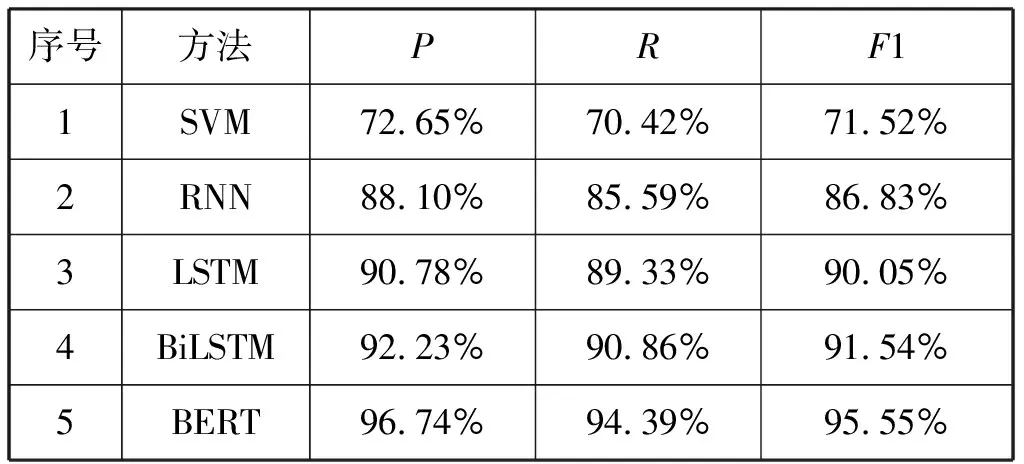
表3 不同方法的运行结果Table 3 The performances of different classification methods
Fig.8 The interface of Chinese classics question system based on BERT图8 利用BERT对中华典籍问句分类的系统界面
由表3可以看出:与深度学习模型相比,SVM由于特征提取能力弱,故问句分类能力较差;RNN利用序列化神经元对词向量抽取时间序列上的特征,因而问句分类能力较之SVM有了一定提升,但效率依然不高,究其原因是当问句较长时,过长的传播路径会导致该模型出现“梯度爆炸”和“梯度消失”的问题;LSTM通过引入门结构来控制信息的传递和遗忘,有效地缓解了RNN面临的两大问题,因而与RNN相比,该模型在一定程度上提高了问句分类能力,其精度、召回率、F1值分别提高2.68%、3.74%、3.22%;BiLSTM是双层LSTM结构,该模型较之LSTM具有更强的特征提取能力,因而其分类精度、召回率、F1值均有不同幅度的提升;BERT引入多层注意力机制不仅能够捕获长距离特征,而且还能有效区分问句特征词的重要程度,因而其分类能力最优。上述实验表明,BERT在中华典籍问句分类任务中具有一定优势。
3.4 模型应用
图9给出了中华典籍问句分类系统界面。该系

Fig.9 The interface of Chinese classics question system图9 中华典籍问句分类系统界面
统包括模型选择、模型训练、结果展示等功能。该系统的基本应用流程是:首先,点击界面左侧的“模型应用”按钮进入模型应用界面;然后,点击“模型选择”按钮进行模型类型选择,或点击“选择已有模型”按钮加载事先训练好的模型;接着,将问句输入“待分类问句”输入框,点击“分类”按钮即可在下方的文本框显示分类结果。
4 总结与展望
本文以《史记》《汉书》《三国志》《新唐书》《战国策》《资治通鉴》《聊斋志异》《儒林外史》《搜神记》《世说新语》等十部中华典籍的相关问句构成的语料集为基础,对SVM、RNN、LSTM、BiLSTM、BERT等模型的问句分类性能进行了比较研究。实验语料集共包含2 000条问句,按照五折交叉验证方式设计实验,取五次实验F1的均值作为最终的分类结果。实验结果表明,与SVM和传统深度学习模型相比,BERT模型具有更优的问句分类能力。本文对典籍问句标注采用人工方式进行,该方式费事费力,能否对典籍问句进行自动化标注值得进一步研究。
猜你喜欢
社会科学战线(2022年5期)2022-07-23
新高考·高一数学(2022年3期)2022-04-28
金桥(2021年4期)2021-05-21
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
红楼梦学刊(2019年2期)2019-04-12
东方教育(2017年11期)2017-08-02
东方教育(2017年11期)2017-08-02
东方教育(2017年11期)2017-08-02
东方教育(2017年11期)2017-08-02
高中生学习·高三版(2016年9期)2016-05-14
