
基于模糊聚类的高速列车车速识别
2022-09-24 03:45:50吴俐滢朱宏平曾永平蔡剑桥颜永逸
高速铁路技术 2022年4期
翁 顺 吴俐滢 朱宏平 张 敏 曾永平 谢 毅 蔡剑桥 颜永逸
(1.华中科技大学,武汉 430074;2.中铁二院工程集团有限责任公司,成都 610031)
随着我国高速铁路的快速发展,列车高速运行对桥梁动力性能提出了更高的要求。高速列车运行会对桥梁产生低周疲劳荷载作用,列车荷载是影响桥梁使用寿命的主要因素之一。列车的车速和荷载识别可为桥梁的安全评估与检定提供重要依据。
目前,桥梁移动荷载识别研究的主要方法可以分为3类:
(1)在桥面上布设动态称重系统(WIM)来实现对车辆荷载的在线监测。此种方法优点是适用性广,可用于不同形式的桥梁结构,且可长时间采集数据[1];缺点是费用昂贵且所得的测量结果与实际值偏差较大。
(2)利用车-桥耦合系统振动方程求解任意时刻车辆与桥梁接触处的相互作用力,并将其用以识别移动荷载。如1988年O’Connor和Chan[2]将简支梁简化为由无质量弹性梁连接的质量集中在节点的模型,将桥上的移动荷载、惯性力、阻尼力等视为集中力,推导出的识别车桥相互作用力的计算方法,即解析法Ⅰ(IM Ⅰ)。Law和Chan基于系统识别理论提出了两种荷载识别方法:时域法(TDM)[3]和频时域法(FTDM)[4];随后与解析法Ⅰ相类似的解析法Ⅱ[5]也被提出。此类方法需要的系统参数多,识别结果(即动态接触力)受路面不平顺、行驶速度等因素影响大[6]。
(3)根据动力响应如动应变等直接识别桥上车辆的轴数、轴距、轴重和车速等。20世纪70年代Moses[7]等利用单一移动荷载的动响应和测点弯矩影响线成比例的特性,由跨中应变响应提出了最初的BWIM移动荷载识别方法;Peters[8]在已有BWIM的基础上通过动应变曲线的面积得到总重量,并结合最小二乘原理迭代计算分配各轴重;王宁波等通过寻找应变曲线峰值点识别车辆行驶速度、轴数、轴距,并采用影响线拟合动应变响应的思路识别车辆各轴轴重。此类荷载识别方法在公路桥梁中广泛应用,待识别信息量大,实时性有待提高。
与公路桥的车速识别不同,高速铁路列车的行车速度有严格的要求,常固定不同的车速区间,因此判断和识别高速车速时需要更高的精度。本文依据高速铁路桥梁健康监测系统采集的桥梁动力响应监测数据,提出基于模糊聚类分析的高速铁路列车车速识别方法,建立列车经过桥梁时的桥梁加速度响应自回归模型(AR模型),通过对自回归系数的模糊聚类结果来判断车速的浮动区间。
1 高速列车车速识别基本理论
1.1 加速度响应时间序列模型
基于时间序列中各时间点的观测值间的相关关系,可依据已知的历史数据对未来的发展进行预测,时间序列分析是研究此种相关关系的方法[9]。高速列车的加速度响应数据就是一种典型的时间序列。当高速列车通过铁路桥梁时,列车车速和车辆荷载的激励将会导致不同车速列车对桥梁产生不同的加速度响应,依据这种差异性便可由模糊聚类分析识别车速。
1.1.1 加速度时间序列自回归模型
自回归模型(Auto regressive,简称AR)是一种常用的处理时间序列的方法[10]。假设有一零均值的加速度时间序列为{at},t=1,2,3,…,n,对其进行自回归拟合,结果如下:
at=φ1at-1+φ2at-2+φ3at-3+…+φpat-p+et
(1)
式中:at——加速度时间序列在t时刻的观测数据值;
φi(i=1,2,3,…,p)——自回归系数;
p——AR模型的拟合阶数;
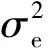
式(1)建立的模型可称为AR(p)模型。
1.2.2 AR(p)模型的阶数p
若要建立AR(p)模型,首先需要确定AR(p)模型的阶数p,合适的阶数p将极大地提高模型的精确度。目前,确定AR(p)模型阶数p的方法包括AIC准则、BIC准则和FPE准则等[11]。本文将综合采用AIC准则和FPE准则确定阶数p值。其中,AIC准则的表达式如下:
(2)
式中:N——用于建立AR(p)模型的加速度时间序列的长度;
由式(2)可知,AIC的值主要由两部分组成,前部分主要与模型的残差相关,后部分与模型的阶数相关。模型越精确,则前部分的值越小,而后部分的值越大。因此,AIC值取得最小值时对应的p值为模型的合适阶数。
FPE准则的表达式为:
(3)
FPE值取得最小值时对应的p值为模型的合适阶数。
1.2.3 AR(p)模型的参数估计
求得模型的阶数p后,由实测的加速度时间序列便可求得对应的AR(p)模型。对AR(p)模型的参数估计的方法可分为两类:一类是对时间序列{at}进行直接估计,如Yule-Walker法[12]、Ulrych-Clayton法[13]、最小二乘估计[14]等;另一类是对时间序列进行递推估计,如Burg法[15]、LUD法、Levinson法和递推最小二乘法等。本文采用Yule-Walker法,具体的求解过程如下:
对式(1)两边同乘at-k,k≥0,得:
at-kat=φ1tt-kat-1+φ2tt-kat-2+…+φptt-kat-p+at-ket
(4)
同时对式(4)的两边取期望,得:
E[atat-k]=φ1E[at-1at-k]+φ2E[at-2at-k]+
…+φpE[at-pat-k]+E[etat-k]
(5)
其中E[atat-k]为加速度时间序列{at}的自协方差函数:
E[atat-k]=Rk=R-k=E[atat+k]
(6)
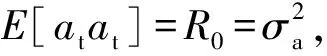
Rk=φ1Rk-1+φ2Rk-2+…+φpRk-p,k>0
(7)
两边同除R0,得到:
ρk=φ1ρk-1+φ2ρk-2+…+φpρk-p,k>0
(8)
其中ρk=Rk/R0,式(8)可表达为:
(9)
式(9)称为Yule-Walker方程。可记为:
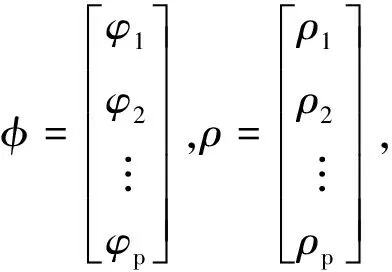
(10)

则根据式(10),式(9)可表达为:
φ=Γ-1ρ
(11)
根据式(11)可得到参数φi(i=1,2,3,…,p)的Yule-Walker估计。
1.2 车速聚类分析理论
聚类分析包括系统聚类法、模糊聚类法、有序样品聚类法等多种分析算法[16-17],其中模糊聚类法为其中应用范围最广、使用频率最高。模糊聚类法引入了隶属度的概念,隶属度取值为0~1,每个聚类样本根据隶属度的大小被分到多个类中。
众多的模糊聚类算法中使用最为广泛的是基于目标函数的算法。1974年,由Dunn提出并经Bezdek推广了模糊C-均值算法(FCM算法)[18-19],FCM算法建立每个点到聚类中心的距离与隶属度乘积之和的目标函数,通过对目标函数的迭代优化达到对样本空间划分。FCM算法优化的目标函数为:
(12)
式中:ci——第i类的加速度时间序列AR模型系数聚类中心;
rj——第j个AR模型系数聚类样本;
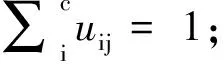
m——模糊聚类参数,一般取为2[20-21]。
(13)
(14)
通过不断迭代式(13)和式(14)来可优化目标函数J,并使其达到最优。
FCM算法的迭代过程如下:
(1)设置聚类的个数c和初始隶属度矩阵,初始隶属度矩阵的设置只需满足元素值为0~1且每个样本对各个聚类中心的隶属度之和为1即可。
(2)根据设置的初始隶属度矩阵,由式(13)求各个聚类中心ci,i=1,2,…,c。
(3)根据求得的聚类中心ci,由式(14)求隶属度矩阵uij。
(4)如果前一次迭代和后一次迭代求得的目标函数的差值满足条件|J(q)-J(q+1)|<ε则停止迭代,其中q为迭代次数。否则,重复第(2)~第(4)步,直到满足要求为止,此时得到的聚类中心和隶属度为满足要求的聚类中心和隶属度。
2 高速列车车速识别分析方法
2.1 列车过桥判定
高速列车以不同车速通过桥梁时,桥梁结构的加速度响应和环境激励所产生的加速度响应间存在明显差异,其加速度响应时间序列如图1所示。在该段加速度时间序列中,测点序列为0~900时为无列车通过时桥梁的加速度响应时间序列(区段1);测点序列为900~1 200 时为列车通过时桥梁的加速度响应时间序列(区段2);测点序列为 1 200~2 000 时为列车通过后桥梁的加速度响应时间序列(区段3)。
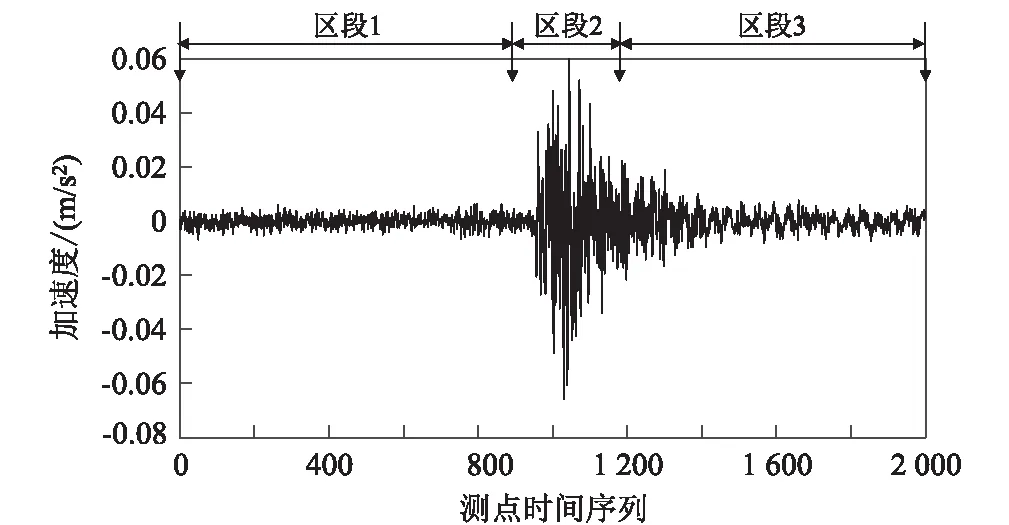
图1 列车通过时桥梁加速度响应时间序列图
实际应用中,区段2数据对计算结果的准确性影响最大,因此AR建模的时间序列必须包含区段2,而减少区段1和区段3的数据点数。列车以高速通过桥梁时在桥上的滞留时间很短,受限于采样频率区段2的时间序列长度很短,不一定能满足模糊聚类的长度要求,且可能会降低聚类计算结果的精度。因此,本文选取全部区段2、部分区段1和部分区段3的数据进行分析。
桥梁健康监测系统采集加速度响应数据是实时连续进行的,而列车经过桥梁的时间很短且不定,在列车经过桥梁的起止时间未知的状况下,如何提取区段2的加速度时间序列成为亟待解决的问题。本文提出了两种方法用以提取区段2的加速度时间序列:阈值判断法和样本区间统计值法。
(1)阈值判断法需对加速度设定某一阈值,当加速度响应超过阈值时将该时间点前后某一区间视为高速列车通过桥梁的时间。假设无列车通过时的加速度响应统计极值为amax,则设namax为所需阈值,其中n为依据实际情况采用的放大系数。假设有某一加速度时间序列{ai},i=1,2,…,n,经判断at≥namax,认为{ak}为高速列车通过时桥梁的加速度响应时间序列,其中k=t-x,…,t-1,t,t+1,…,t+y,{ak}⊆{ai},x和y为根据实际情况采取的时间段距离参数,可令x=y。
由于环境荷载的影响和传感器的采集误差,可能出现某一个加速度响应数据点超过阈值,但对应时间点并无列车通过的情况,该点被称为“坏点”。为区分所需测点与“坏点”,本文采用的方法为:在目标测点前后某一区间内重复判断其他实测数据是否超过阈值,若存在多个点超过阈值的情况,则可判断为所需的测点值,否则为“坏点”。
(2)样本区间统计值法将某一加速度响应时间序列{ai},i=1,2,…,n划分为多个样本区间{ak}m,k=1,2,…,l,m=1,2,…,t,{ak}m⊆{ai},分别求各个样本区间的方差,当其中某一个区间的样本方差与其他区间样本方差相差较大时(一般相差100倍以上)可认为该区间的数据为所需的区段2中的数据。
与阈值判断法相比,样本区间统计值计算量较大,在实时采集数据的监测系统中不一定能适用,因此本文采用阈值判断法。
2.2 监测数据标准化处理
在对加速度时间序列计算前,需对其进行标准化处理,即提取趋势项、零均值化和标准化。由于本文加速度时间序列长度并不大,在环境温度或者其他因素的影响下,不能产生明显的趋势项,因此只对其进行零均值化和标准化处理。
(1)零均值化
传感器可能存在系统误差,导致监测数据均值并不为0,为了减小这种误差,剔除监测数据的均值。假设加速度时间序列{at},t=1,2,…,n的均值为μ,则零均值化后的时间序列为:
a′t=at-μ
(15)
(2)标准化
对于监测得到的加速度时间序列{at},t=1,2,…,n,其值过大或者过小都会影响AR建模的效果,因此一般需对其进行标准化处理。假设加速度时间序列{at},t=1,2,…,n的均值为μ,方差为σ2,则标准化处理后的时间序列为:
(16)
经标准化处理后的时间序列{a′t}服从正态分布,即a′t~N(0,1)。
2.3 加速度时间序列AR模型
假设高速列车在已知车速行驶过程中的某一测点的加速度时间序列样本空间S,S={{a}1,{a}2,…,{a}m-1,{a}m},其中{a}i为在已知车速Vi下桥梁的加速度时间序列,i=1,2,…,m。同一测点在未知车速下的加速度时间序列样本空间为D,D={{a}m+1,{a}m+2,…,{a}m+l-1,{a}m+l},其中{a}j为在未知车速Vj下桥梁的加速度时间序列,其中j=m+1,m+2,…,m+l。此时所有数据已经过预处理。
(1)确定AR模型的阶数
由式(2)和式(3)分别计算AIC指标和FPE指标,令模型阶数p从1~100变化,观察两个指标的变化趋势,确定p所处的大概范围,再由MATLAB计算每个p值下AR(p)模型的拟合匹配率,选取匹配率变化拐点时的p值作为本文所建立的AR模型的阶数。
(2)建立AR(p)模型
分别建立加速度时间序列{a}i和{a}j的AR(p)模型如下:
(17)
(18)
式中:ai,t——时间序列{a}i中t时刻的值;
aj,t——时间序列{a}j中t时刻的值;
φk——时间序列{a}i的AR模型自回归系数;
φk——时间序列{a}j的AR模型自回归系数。
对于样本空间中的某一个时间序列,称[φ1φ2…φp]或者[φ1φ2…φp]为一个聚类样本,分别对应于已知车速状态和未知车速状态。基于样本空间S={{a}1,{a}2,…,{a}m-1,{a}m}和样本空间D={{a}m+1,{a}m+2,…,{a}m+l-1,{a}m+l},定义两个不同状态下的聚类样本空间(或称为AR模型系数矩阵),分别为:
(19)
(20)
为通过聚类识别车速,需将未知车速下的Φd的聚类结果与已知车速下的Φs的聚类结果进行对比,因此在实际的计算过程中,将Φd和Φs合并为总体样本进行聚类计算,该总体样本可写为Φ=[Φs;Φd]的形式,Φ中的每一行即为式(13)中的一个样本。
2.4 FCM聚类识别车速
FCM聚类识别车速的过程主要包括确定聚类中心个数和未知车速识别。根据求得的AR(p)模型系数矩阵Φs,该矩阵中的AR系数为已知车速条件下求得,每个AR(p)模型分别对应列车车速Vi,i=1,2,…,m,可先由Φs的聚类结果确定合适的聚类中心个数c。此时车速Vi将被划分为c个区间,在识别未知车速时将以这c个车速区间为参考对象,c越大,即聚类中心个数越多,车速区间越多,识别结果越精确。然而,随着c的增大,FCM聚类分析的结果越难判断,因此选用合适的c值尤为重要,本文经研究确定合适的聚类中心个数c为3。采用FCM算法对总体聚类样本Φ=[Φs;Φd]进行聚类划分,得到隶属度矩阵:
(21)
式中,uij表示第j个样本对第i个聚类中心的隶属度。由隶属度矩阵可判断车速所在区间。
3 某铁路桥高速列车车速识别
3.1 算例及工况介绍
某铁路桥梁设计行车速度 250 km/h,预留行车速度350 km/h,正线线间距5.0 m,铺设无砟轨道。主桥结构全梁长572.1 m(含梁缝)。边跨及部分中跨主梁为预应力混凝土箱梁,中跨主梁为箱形钢-混凝土结合梁。主梁采用混合梁结构,梁端至中跨155.75 m范围内采用混凝土箱梁结构,其余采用箱形钢-混凝土结合梁,中间采用钢混结合段过渡。索塔采用人字形混凝土塔,两座索塔全高分别为124.5 m、127.6 m,桥面以上塔高88 m,为主跨的 1/3.409。主塔采用分离式桩基础,两承台间设置系梁。斜拉索采用采用抗拉标准强度 1 670 MPa 镀锌平行钢丝拉索,空间双索面体系,扇形布置,全桥共 48 对斜拉索。
实测加速度数据采集频率为30 Hz,共选取4个加速度测点,监测截面皆为中跨,编号分别为10-ZD02、10-ZD03、11-ZD02和11-ZD03。已知和未知车速下桥梁动力响应数据信息如表1所示。
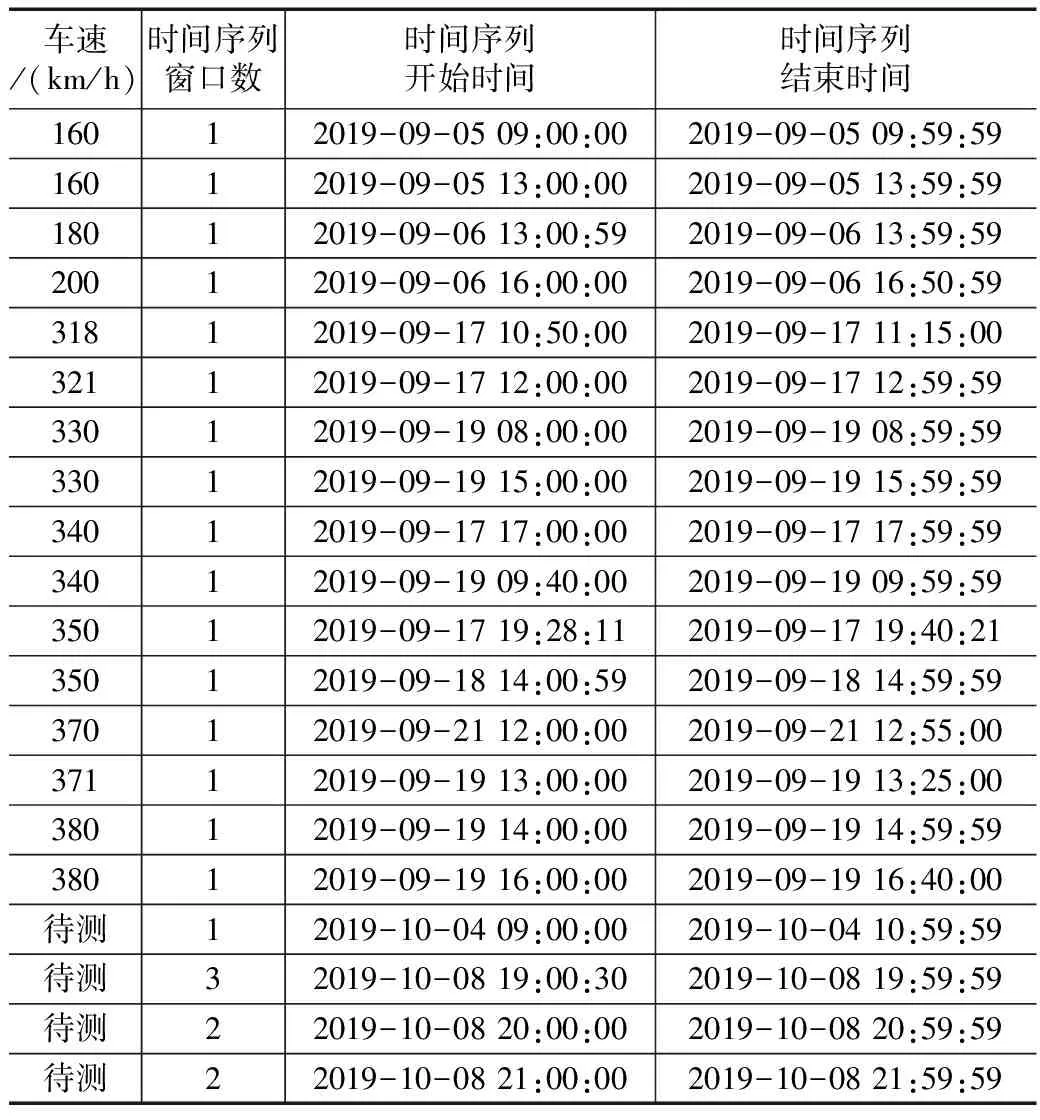
表1 不同车速下加速度动力响应时间序列信息表
以表1中的不同车速建立工况,其中时间序列窗口数是指监测时间段内列车经过桥梁的次数(即可用于车速聚类的不同加速度响应时间序列窗口个数)。每一个时间序列窗口对应于一种车速工况,则共划分为25种工况,其中已知车速工况17种,未知车速工况8种。已知和未知车速工况如表2和表3所示,未知车速用Vi表示。
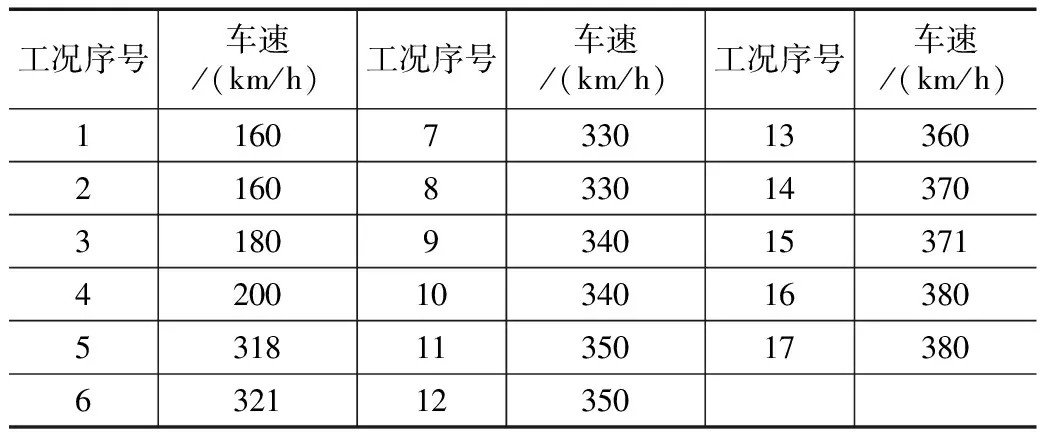
表2 已知车速工况信息表
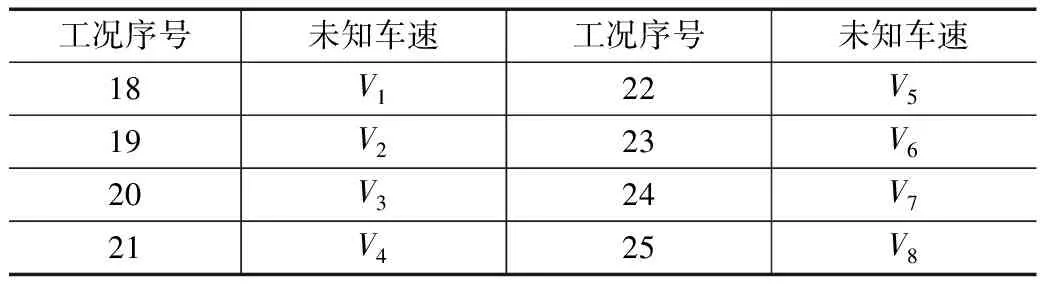
表3 未知车速工况信息表
3.2 监测数据选择和预处理
目前桥梁暂处于试运行阶段,经过的高速列车16节车厢编组,由此计算得到列车在桥梁上的运行时间为10~30 s,又因加速度数据的采集频率为30 Hz,为取完所需数据,将时间序列的窗口长度定为 2 000。以工况17为例,根据2.1节介绍的阈值判断法,4个测点所需的时间序列如图2所示。
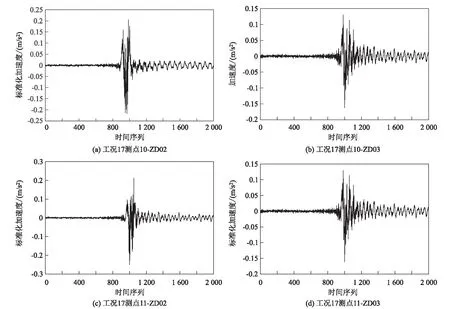
图2 工况17时间序列图
截取完所需数据点后,根据2.2节中的方法对数据进行预处理,得到的时间序列如图3所示(以工况17为例)。
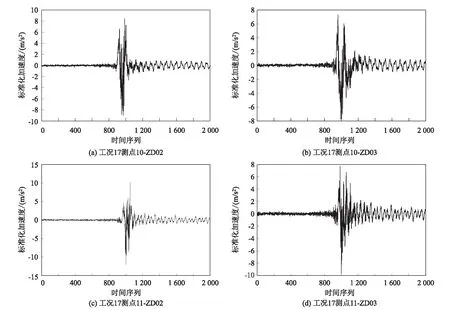
图3 工况17预处理后的时间序列图
3.3 加速度时间序列AR(p)模型建立
(1)确定AR(p)模型的阶数
取工况5下测点11-ZD03的加速度时间序列来确定模型阶数,根据AIC准则和FPE准则计算模型阶数,结果如图4和图5所示。
由图4和图5可知,随着AR模型阶数的增加,AIC和FPE的值都在不停的减小,但均存在明显的拐点。当模型的阶数从1~10和10~100变化时,AIC的值和FPE的值的递减速率存在较大的差异,模型阶数大于10阶后两个指标基本没有变化。由图6可知,大于10阶后模型匹配率变化较小。综合考虑,取AR(p)模型的合适阶数为10阶。

图4 AIC曲线图
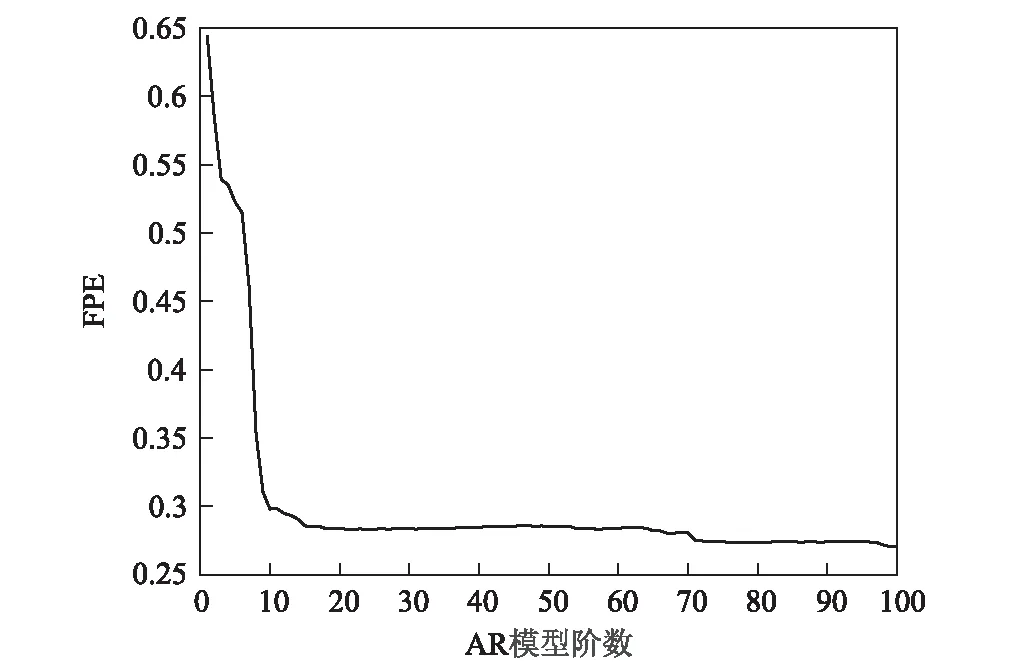
图5 FPE曲线图
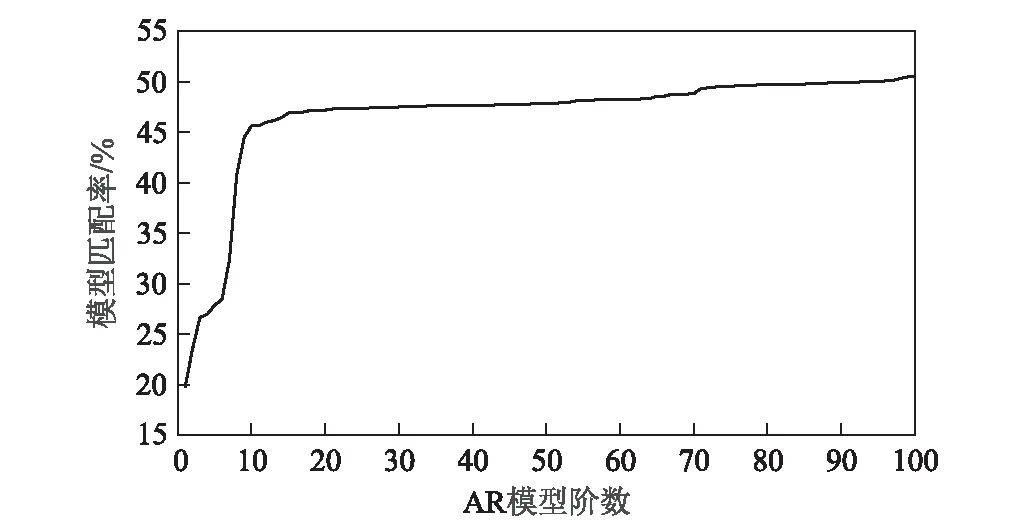
图6 模型匹配率曲线图
(2)建立AR(p)模型
为了验证AR模型的准确性和可靠性,计算对应时间窗口长度的时间序列,将原时间序列与求得的时间序列进行比较,由此判断AR模型是否符合要求。以工况5为例,AR模型的自回归系数如表4所示。各测点的原始时间序列与模型求得的时间序列比较曲线如图7所示。由图7可知,AR建模预测得到的加速度时间序列与实测的加速度时间序列的变化趋势基本一致,可用于聚类分析。
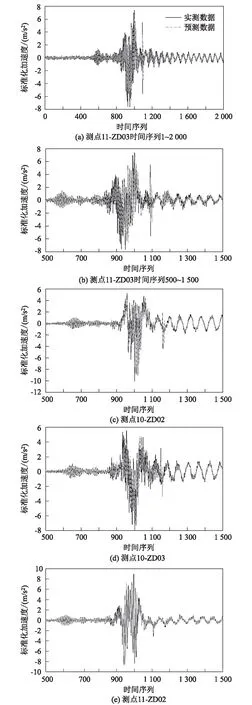
图7 工况5各测点数据对比图
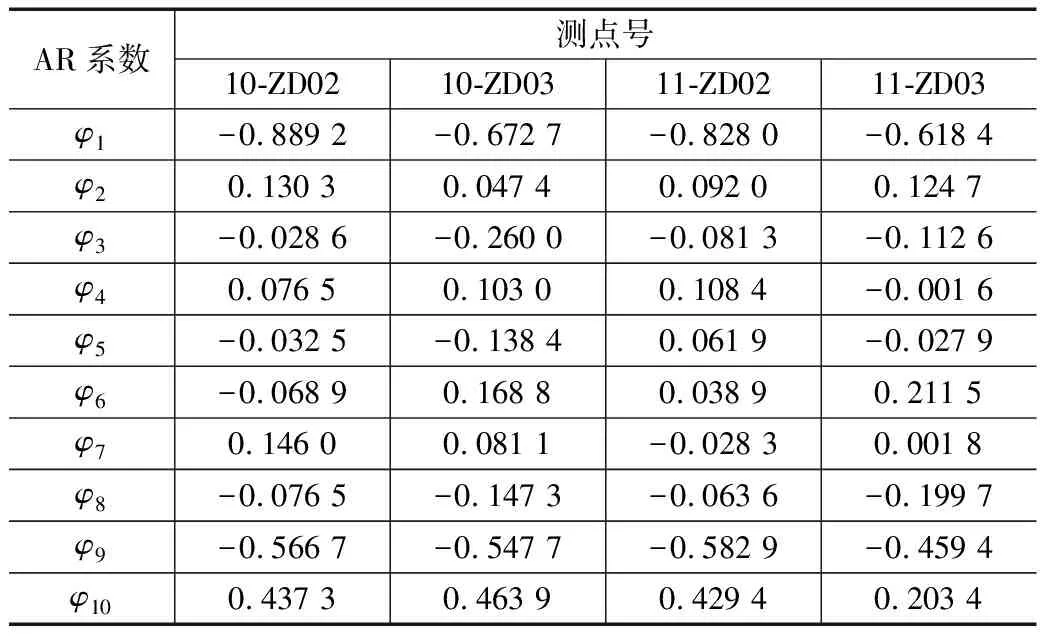
表4 工况5下各测点AR模型系数表
同理,对表2和3中列出的所有工况下的各个测点时间序列进行AR建模并求解AR系数。
3.4 AR系数聚类识别车速
选取聚类中心个数为3进行算例分析。对已知车速的17种工况下的加速度时间序列的AR系数矩阵进行FCM聚类分析,得到已知车速工况下的隶属度信息。以测点10-ZD03为对象,计算得到的聚类中心个数为3下的隶属度信息,结果如表5所示,聚类效果如图8所示。

图8 聚类中心个数为3时测点10-ZD03聚类效果图
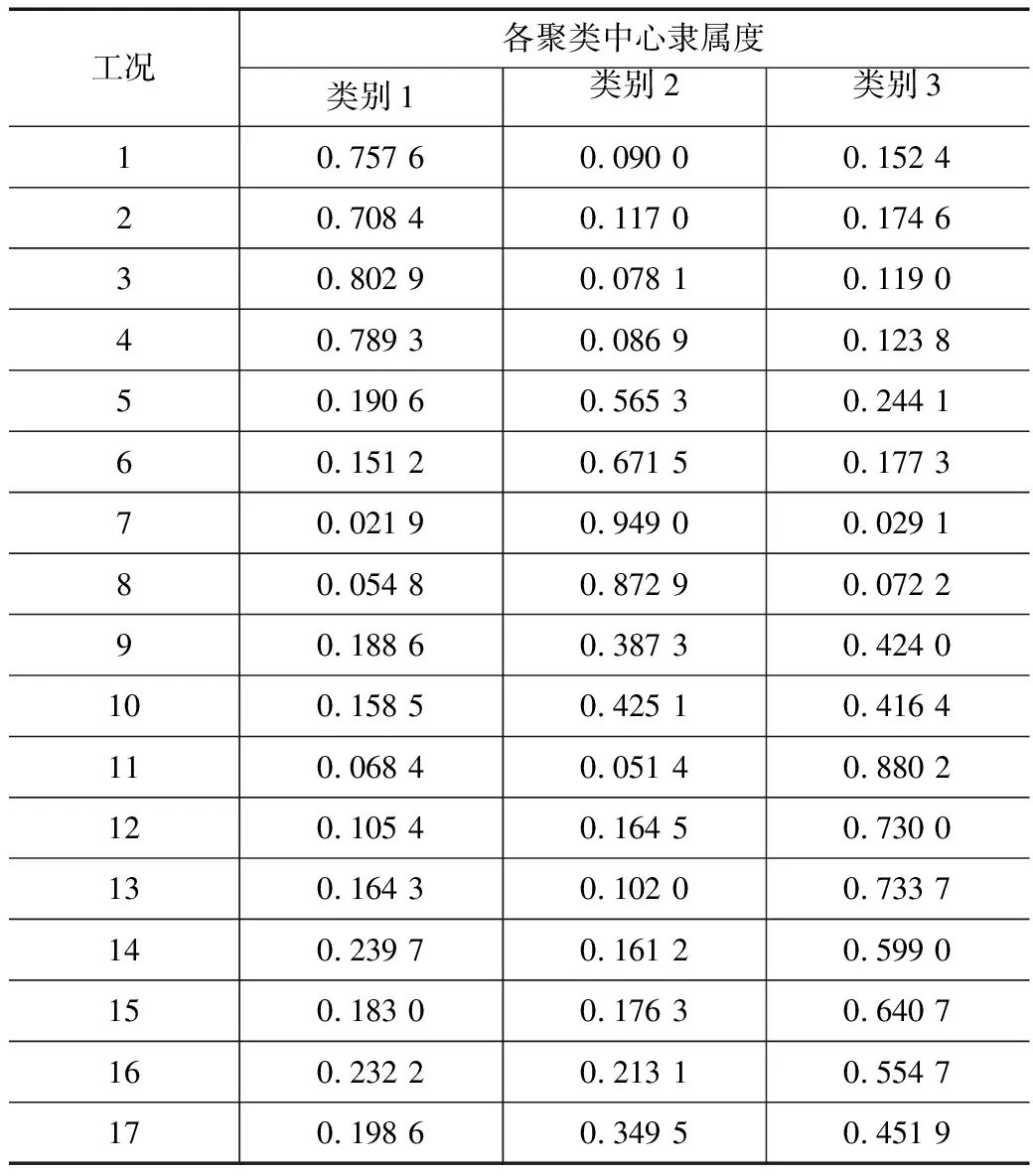
表5 测点10-ZD02各待测工况隶属度表
由表5可知,当聚类中心个数为3时,工况1~工况4对类别1的隶属度均在0.7以上,对类别2和3的隶属度均在0.18以下,隶属度的差别较大,可将工况1~工况4划分为类别1;工况5~工况8对类别2的隶属度均在0.56以上,大部分在0.67以上,对类别1和3的隶属度均在0.25以下,大部分在0.20以下,可将工况5~工况8划分为类别2;工况11~工况17对类别3的隶属度均在0.45以上,大部分在0.60以上,对类别1和3的隶属度均在0.35以下,大部分在0.20以下,可将工况11~工况17划分为类别3。此时类别1对应的车速区间为160~200 km/h,类别2对应的车速区间为318~340 km/h,类别3对应的车速区间为340~380 km/h。
将未知车速和已知车速的所有AR系数组成的AR系数矩阵再次进行FCM聚类分析,得到各未知车速工况下的隶属度信息如表6~表9所示,聚类效果图如图9所示。
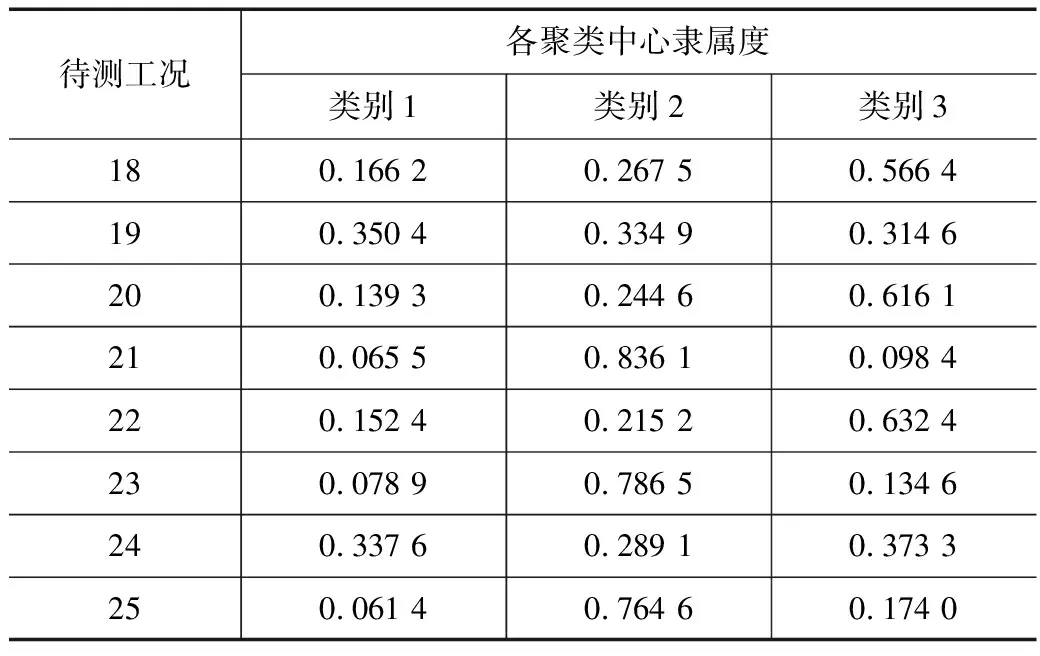
表6 测点10-ZD02各待测工况隶属度表
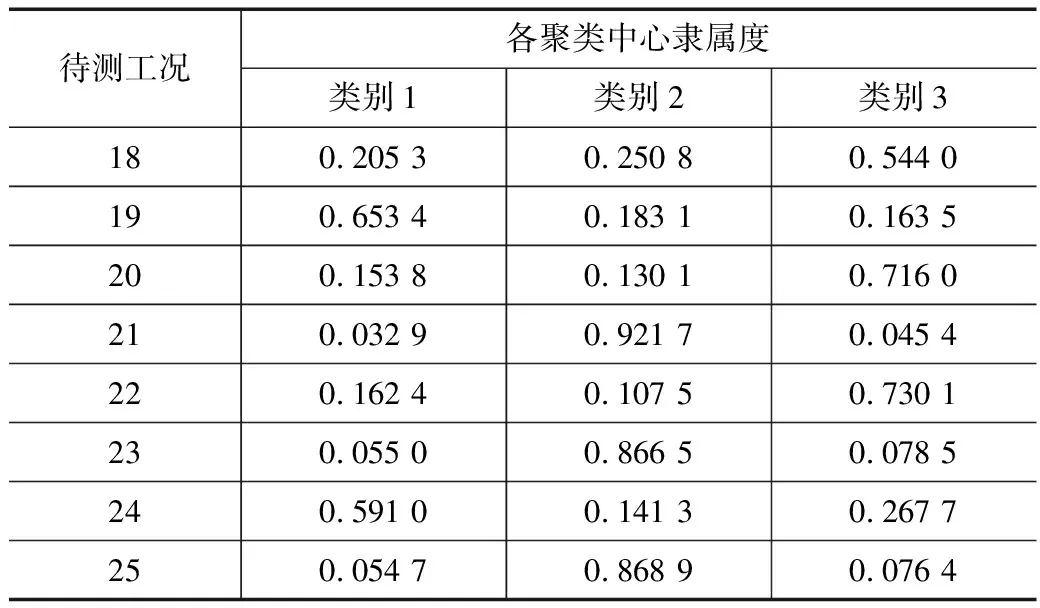
表7 测点10-ZD03各待测工况隶属度表
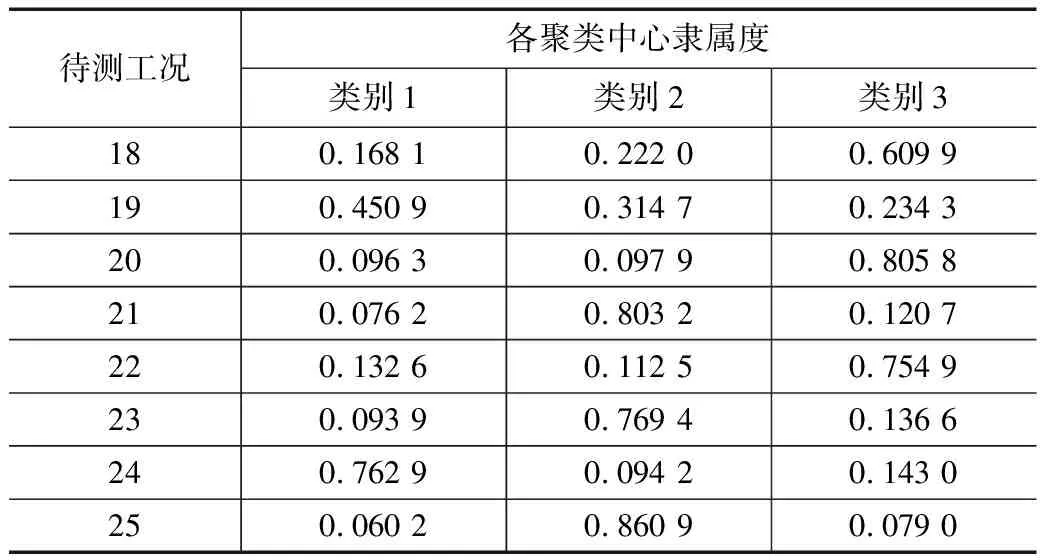
表8 测点11-ZD02各待测工况隶属度表
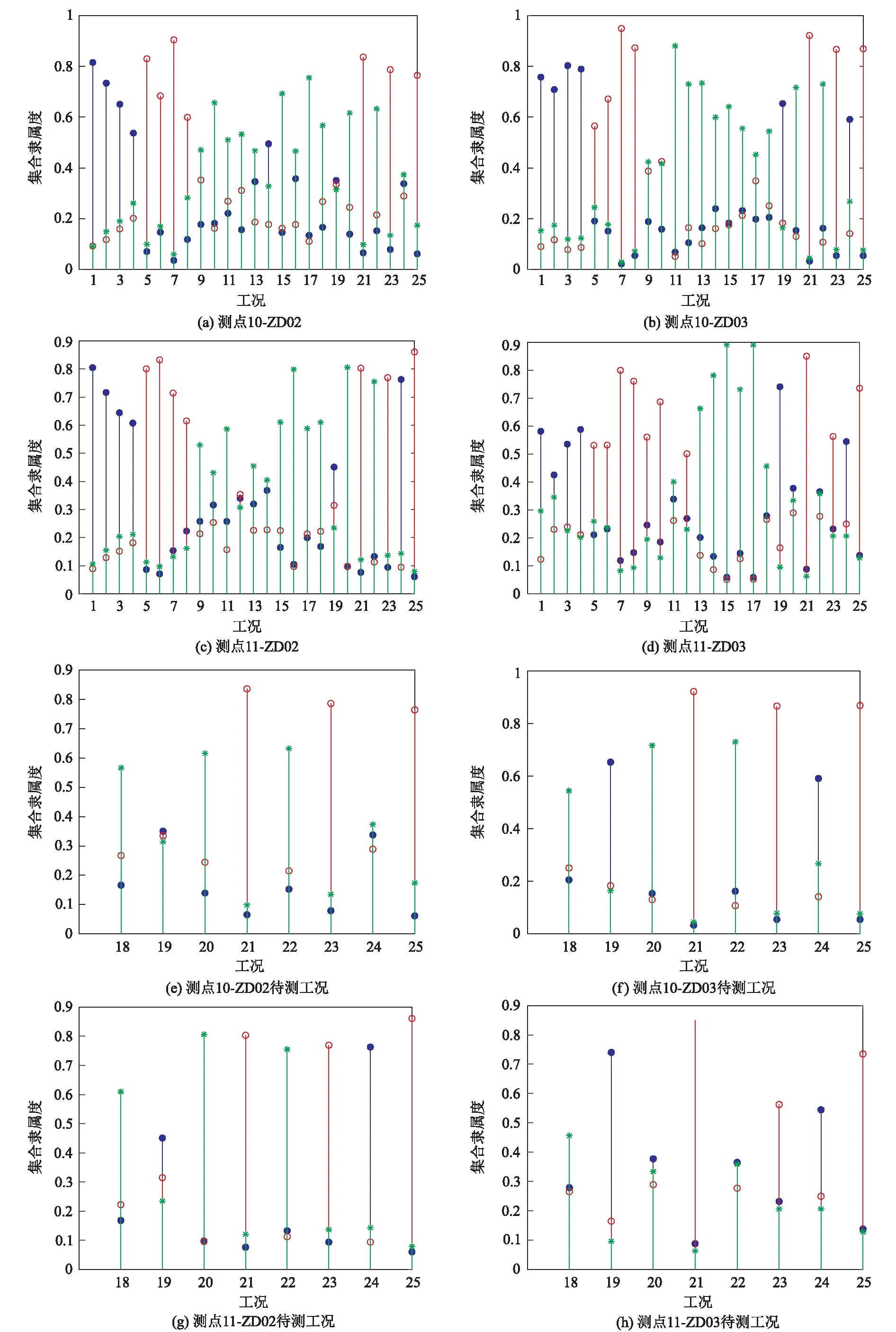
图9 聚类效果图
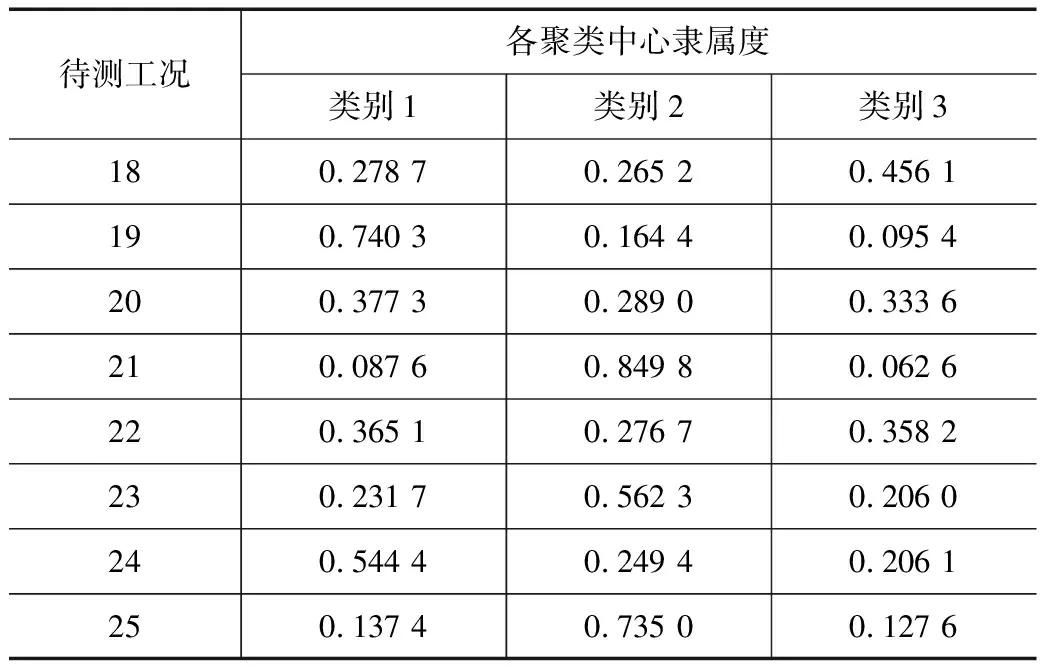
表9 测点11-ZD03各待测工况隶属度表
由表6可知得测点10-ZD02的聚类结果:待测工况19和待测工况24对3个聚类中心的隶属度皆在0.3左右,因此,待测工况19、工况24可能为3个类别中的任意一类;待测工况21、工况23、工况25对类别2的隶属度均在0.76以上,对类别1、类别3的隶属度均在0.17以下,可视为类别2;待测工况18、工况20、工况22对类别3的隶属度均在0.56以上,对类别1和类别2的隶属度均在0.27以下,可视为类别3。
由聚类分析结果可知,除了少数几个工况,其余工况类别划分基本一致。待测工况19、工况24为类别1时对应的车速区间为160~200 km/h;待测工况21、工况23、工况25为类别2时对应的车速区间为318~340 km/h;待测工况18、工况20、工况22为类别3时对应的车速区间为340~380 km/h。
4 结束语
本文采用时间序列AR系数聚类的方法,实现了对高速列车通过桥梁时车速的识别。通过计算加速度时间序列AR系数并进行模糊聚类,分析了不同车速列车导致桥梁产生的加速度响应的差异性,进而识别了列车车速。
以列车过桥时的桥梁加速度响应时间序列为研究对象,对不同车速下的加速度时间序列建立AR模型,确定了AR模型的阶数,对各个工况下的AR系数进行模糊聚类分析,将已知车速划分为3个聚类区间,并以此为参考识别了未知车速所处的区间。
猜你喜欢
机械设计与制造(2023年2期)2023-02-27 12:40:16
当代水产(2022年6期)2022-06-29 01:12:20
汽车实用技术(2021年10期)2021-06-04 07:51:00
汽车观察(2018年12期)2018-12-26 01:05:42
金桥(2018年4期)2018-09-26 02:24:46
劳动保护(2018年8期)2018-09-12 01:16:14
汽车维护与修理(2018年1期)2018-04-04 01:13:22
汽车维护与修理(2015年5期)2015-02-28 12:16:34
警察技术(2015年6期)2015-02-27 15:38:33
水利水电科技进展(2014年1期)2014-10-17 02:29:14
