
电网企业数据人工智能中台设计
2022-09-20 12:26:32佟芳林鑫王婷马文珍王忠花
电力大数据 2022年3期
佟芳,林鑫,王婷,马文珍,王忠花
(国网青海信通公司,青海 西宁 810000)
截至2020年12月,根据国家电网发布统计数据,国家电网累计接入各类智能移动电表应用终端逾7.3亿台,其中值得一提的是,随着智能电动汽车行业的快速发展,车联网的接入智能充电桩终端接入总数达到42万个。企业提供了约186万个就业岗位,彻底解决了约12亿人口的用电计量问题。现拥有的城市供电指挥中心达到336家[1]。虽然国家电网的体量已经非常庞大,但是各个部门之间的数据共享却没有真正建立起链接,继而导致国家电网在工作效率和工作质量上不能发挥其体量的优势。现阶段,国家电网的目标是需要将信息进行集中,对过量的信息进行集中处理和筛选,将有价值的信息甄别并及时共享出来,让数据的交互能力达到最大化[2]。因此,电网需要建设人工智能的数据中台,来实现数据的智能化交互。
通过建立人工智能AI,可实现人工智能的统一管理,包含人工智能业务需求、人工智能模型统一管理、人工智能应用统一执行等。在此过程中,横向打通内外网的壁垒,实现算法、样本、模型以及应用的共享,纵向实现与总部模型和样本的交互[3]。通过智慧监测大厅、应用统一视频系统接入各营业厅、变电站、公司的实时视频数据,应用AI的智能算法和模型对营业厅的营业员的着装、变电站的烟火、智慧工地的人员安全帽、人员跌倒等异常情况进行自动识别并告警。在外网应用百度的人工智能平台,通过集中视频智能识别以及边缘计算技术,支撑能源大数据中心的人工智能应用,提升光伏电站的智能运营管理水平。应用部署在电站的监控摄像头,应用智能算法,对电站人员车辆违规进入等情况进行智能识别并预警,预警信息实时传回总部集控中心,协助值班人员进行电厂的实时监测[4]。
1 电网企业数据人工智能中台设计
1.1 设计人工智能中台整体架构
设计电网企业数据人工智能中台(data middle platform)的主要目的是解决当前电商体系存在的高耗低效问题,通过将不同企业具体业务类型的汇总,以业务沉淀的方式实现各企业业务部门的共享。本文提出的数据中台架构由下至上分为5个层次。其中,数据接入层和数据治理层属于后端,数据模型层和通用分析模型层属于中端,数据服务层属于前端[5]。图1为电网企业数据人工智能中台整体结构示意图。

图1 电网企业数据人工智能中台整体结构示意图Fig.1 Overall structure diagram of data artificial intelligence platform of power grid enterprises
从图1可以看出,对于电网企业数据人工智能中台而言,后端连接的阿里云平台相当于该架构当中的服务层,其主要功能是实现对CPU的处理以及对内存、存储等基本计算资源的处理。中间层的主要作用是支撑上层结构中各项功能的充分调用。同时,中间层也是该架构当中最重要的核心结构,在其实际应用中能够为用户中心、商品中心以及交易中心提供更加优质的业务服务[6]。与传统建设方式不同之处在于,本文构建的人工智能中台整体架构前端各项业务在实际应用的过程中并不是在阿里云平台上单独设立的。
1.2 人工智能中台设计技术
(1)数据接入层。这一层主要采用人工智能的大数据采集方式,如ETL中的核心技术采用Kettle,而FTP则主要使用Git-FTP,是建立在Socket Rocket上的实时数据采集。
(2)数据治理层。使用Apache Atlas。
(3)数据模型层和通用分析模型层。在这两层,主要涉及计算存储和数据建模两个方面,在计算存储中,在线计算以Flink技术为主,而离线计算则是采用Map Reduce[7]。数据的存储主要依赖分布式数据库H base和时序数据库Timescale DB。数据建模方面,采用“敏捷数据建模平台M+”。
(4)数据服务层。数据服务的发布主要依赖于现有成熟技术Spring Cloud,但是数据服务目录是需要进行自研的[8]。
(5)应用层。在应用层,最主要就是人机交互界面和预警警报装置,人机交互界面采用Tableau,预警装置采用Bosun,可视化大屏则以较为普通的SLCD技术作为支撑[9]。
1.3 对于关键技术的验证
出于电力安全的考虑,电网人工智能中台必须保障数据建设的有序推进。因此,对于关键技术需要依次进行“设计验证”、“试点建设”、“推广建设”三个主要阶段。
首先是设计验证阶段。这一阶段需要完成人工智能中台的主数据标准的建设,开展多样化的频道报表,数字化审计的应用等,实现人工智能平台数据分析中心数据实验室建设。
其次是试点建设阶段。这一阶段是完善数据资源中心的阶段,数据地图和主数据是主要完善目标,同时需要对设备的实时状态进行检测。
最后,在基本建设成功电网企业数据人工智能中台后,是推广建设阶段。这一阶段需要保证统计报表自动编制率达到100%,实现中台数据的业务化,进而实现对企业前端业务的反馈。
1.4 基于人工智能数据中台营配优化模型
在上述人工智能中台整体架构的基础上,对电网企业售电业务区域进行划分,引入领域驱动思想,构建一个高内聚低耦合的售电业务子域[10]。由于领域驱动能够更加有效地从电网企业售电业务的角度出发,实现对业务更加系统化的拆分,因此通过这种方式划分的电网企业售电业务区域具有更高的企业密度。在具体实施时,首先,明确在售电过程中需要解决的业务问题,即电力销售与用电服务的利润最大化;其次,针对核心问题域,选择售电业务的场景,进行业务流程活动分析[11]。根据上述操作,以高压新装售电业务为例,得出如表1所示的售电业务区域。

表1 高压新装售电业务区域划分Tab.1 Regional division of high voltage newly installed power sales business
在实际操作中,针对不同售电业务的不同环节差异,可在当中实现对业务区域的增加或合并,以此确保整个售电业务流程的完整性。要点如下。
(1)设计营配贯通总体架构。电网企业营销领域、配电领域系统间存在壁垒,而数据人工智能中台可以实现人与设备、设备与设备之间的联系,实现故障自动分析、自动定位,停电信息推送以及抢修可视化的状况。
(2)完善营配数据模型。基于国家电网的SG-CIM4.0标准,实现资产完善、用户营配模型。
(3)建立移动作业核查机制。以人工智能中台为依托,实现现场维护数据的坐标、台账等实现实时的采录。
(4)支撑营配协同应用场景。这也是实现营配协同最重要的一步,这一部分需要实现多场景营配协同应用。
第一是供电服务指挥。这一部分需要根据已有的客户数据状况,通过对客户的习惯和环境等各个因素的综合分析,在结合大数据的基础上,由人工智能中台进行自主数据筛选辨析,实现对于电网故障的预判和抢修。
第二是对于同期线损分析。这一部分是需要以“站-线-变-户”的拓扑关系,以智能中台分析大数据自动计算同期线损,同时结合现场查验上传数据,进而对线损、电表故障、窃电等状况实现检测分析。
第三是对业扩报装管控。这一部分是对于电网企业各个系统的综合衔接,数据人工中台作为数据处理中心,统筹分析了营销系统、运检系统、基建系统等,实现了客户的需求和项目的实际需求直接对接转化,对电网建设的各个阶段实现监测。
第四是停电分析到户。用电户是电网建设的末端,也是组成营配一张最基础的节点。因此,客户的用电体验才是人工智能中台最重要的建设方向。人工智能中台需要完整的分析停电信息,实现停电用户信息的综合整理,再通过微信、短信息等社交方式将停电信息通知到客户,最终达到提升客户用户体验的功效。
第五则是建立用电用户客户画像。人工智能中台可以根据客户用电状况、时间、峰谷值等等用电信息,建立起一个客户评价模型,可以实现能效评估、风险评估等等功能。这些就是客户的标签,而人工智能中台就可以依据这些标签实现优质服务和精准营销。

图2 人工智能中台营配优化模型Fig.2 Platform operation and distribution optimization model in artificial intelligence
1.5 实现业务数据共享
电网企业数据人工智能中台的功能还应当包括对各类电力业务数据的共享,为保障电网企业的数据安全,本文采用非对称加密技术的数据共享传输方式。电力业务数据共享渠道与用户界面层相对应,在二者连接上引入非对称加密机制[12]。传输的内容主要包括来自Web的资源文件以及针对界面进行控制的控件,例如JSP、JS等,其主要功能是为了进一步完善对外的展示界面,将更加丰富的电力信息资源向用电用户展示。为进一步实现中台对用户发出的各项命令的有效执行,将业务应用与应用层进行对接,对需要实现的各项执行任务进行定义,并完成对相关指令的发送、调度和验证等功能[13]。除此之外,针对基础设施层中的电力业务数据共享,应当由基础设施层向其他层提供可通用的数据处理技术,包括对电力业务数据的传递技术、持久化数据传输机制等。因此,通过上述各个中台层次的连接,实现各项业务数据的共享,提高中台可用性。
在Spring Cloud框架的基础上,本次设计拟构建一个数据窗口。该数据窗口实现人工智能对外的数据服务,其中包含以下五个主要组件:“数据服务开发组件”、“数据服务发布组件”、“数据服务目录组件”、“数据服务路由组件”、“访问日志与数据服务监控组件”[14]。
1.6 数据中台应用
建设电网企业人工智能数据中台是生产力不断进步的需求,人工智能数据中台的建立可以很大提升企业内部管理,提升企业对于数据的分析能力,在建立良好的大数据分析的基础上,可以提升企业创新能力,从而最终扩大企业的市场[15]。
下面通过“电网企业客户大数据征信状况”为例,进行人工改智能数据服务的演示,该征信状况的核心评判标准是电费和电量,同时包含欠费、缴费等关键指标。在对企业用电的变化量进行数据采集和分析,进而分析出用电企业在一定时间内的经营发展状况。实施步骤如下。
(1)建立相关指标体系。构建五大一级指标、 22 个二级指标的指标体系,以缴纳费用的能力和意愿作为最核心的评判指标[16],最终构成一个完整“电网企业客户大数据征信”指标体系。
(2)根据指标体系,系统智能地筛选数据目录中的相关数据信息,将数据整合打包,上传至上层平台,予以分析处理。
(3)在M+ 平台接收到数据包之后,根据相关指标体系,对各个指标进行重要性评估,然后根据权重进行归类整理。同时,依据相关的指标制定合适的评分细则[17]。在“敏捷性数据平台M+”模型下,通过缺失值处理、异常值检测、分箱技术组件,将各个指标进行相应的分箱,将数据对应进各个分箱中,从而计算出数据密度,根据数据密度的状况,给出合理的评分规则。
(4)最后则是发布电网数据征信。依旧是利用数据平台,将信用的评级模型进行发布,利用“数据检查”“文字检查”和“详查”三种端口,提供数据模型服务[18]。
2 实验论证分析
为进一步验证本文上述提出的电网企业数据人工智能中台在实际应用中是否能够有效帮助电网企业完成更加高品质的服务。本文将上述构建的电网企业数据人工智能中台与传统基于事件驱动的同时应用到同一电网企业当中,并开展如下对比实验。
电网企业能否实现可持续发展,主要取决于其业务数据的存储、传输是否安全[19]。因此,本文将数据存储安全性作为实验的评价指标,通过对两种中台中各项业务数据的安全系数计算,实现对其量化分析。电网企业业务数据安全系数计算公式为[20]:
(1)
公式(1)中,δ表示为电网企业业务数据安全系数,M0表示为中台中存储、传输过程中产生的业务数据总量,γ表示为恶意节点数量,M表示为输出的业务数据总量。根据上述公式,分别在两个中台环境当中引入10000MB业务数据,并随机引入10个恶意节点数据[21]。对比两个中台在其充分的运行条件下,业务数据的安全系数,并绘制成表2所示。
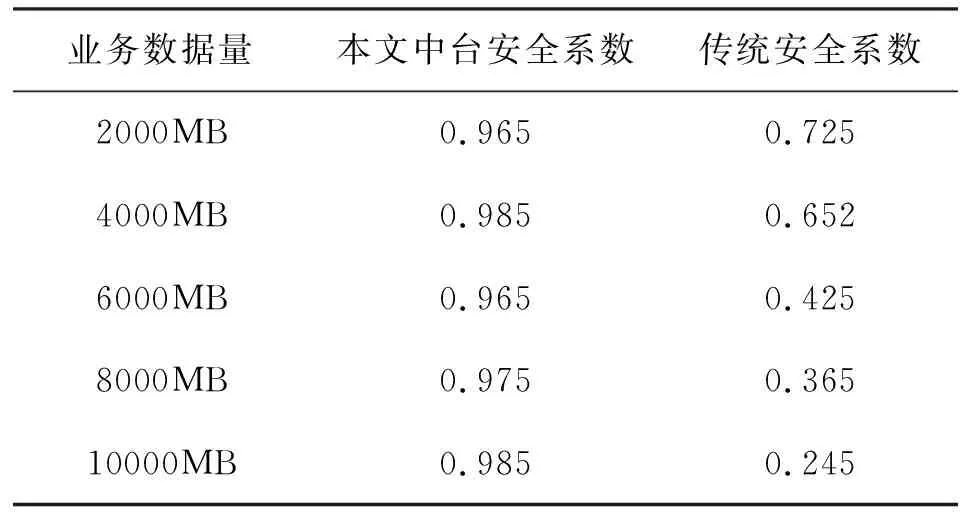
表2 两种实验结果对比表Tab.2 Comparison of two kinds of bench test results
从表2得出的实验结果可以看出,本文中台中业务数据的安全系数更高,而传统安全系数较低,并且随着业务数据量的增加,安全系数呈现出明显的降低趋势。因此,通过对比实验证明,本文提出的电网企业数据人工智能中台在实际应用中能够有效提高电网企业数据的安全性。
3 电网数据人工智能中台模型更新与升级
在实验论证分析可行之后,对人工智能中台各层的物理模型进行部署,在部署完后,对数据进行抽取、转换、整合和加载,最终实现各类数据的综合应用分析。但是数据中台处于一个不断迭代和完善的阶段,随着核心SG-CIM的不断革新,人工智能中台就必然面临着全面的更新和升级[22-23]。
人工智能中台的升级必然伴随着的物理数据表的变化,而数据表一旦处于更新状态,现有的ETL配置就需要跟随物理数据表进行重构。如此大的变更过程会导致数据处理的延迟,进而影响整个中台对各个系统的数据反馈[24]。因此,对于人工智能模型的升级的方法需要慎之又慎。
目前数据中台的升级拟采用三种方法,第一是整表删除重建法。这种方法是在更新数据之前,将旧表中需要更新的数据全部删除,然后建立同名表进行取代,在修改ETL配置后进行数据的抽取转换[25]。第二是创建中间表法。这个方法是在不破坏旧有模型表的情况下,创建一个中间表,在配置ETL时指向这个中间表[26]。而对于旧有数据的删除和处理则是中台系统数据分析的间隙进行,随后将中间表改为原数据表名称,修改完ETL配置后快速实现数据分析功能运行[27],第三是在线修改表结构,直接通过SQL语句修改表结构,然后对历史更改数据进行逐条维护。

图3 中间表模型升级过程Fig.3 Intermediate table model upgrade process
在综合试用中,整表删除法是最为简单的,并且性能也是较高的。但是,其对数据表的修改也最大,造成较长时间的数据装载,进而对人工智能中台数据处理产生影响[28]。因此这种升级方法适用于中台建立初期和电网信息处理低峰阶段,可以最为可靠地保障模型更新的准确性。而创建中间表法较为复杂,需要进行两次的ETL的配置更改,其最大的优点是对人工智能中台的数据分析能力的影响忽略不计[29-30],因此可以选择在凌晨等时间进行模型切换。在线修改表法最为复杂,也最容易出现问题,很容易对原有的数据表产生偏差修改,并且是逐条维护,效率较低,但是适用于系统高峰期紧急升级维护。
因此,数据中台模型的升级和更新会对中台的数据处理能力造成很大的影响,三种方法各有优缺点,在合理的场景使用合理的方法最为重要。
4 结束语
本文中提出数据人工智能中台利用云环境中的大数据人工智能分析工具对数据进行再加工,这些数据包括关系型对象型的模型、实时、历史和记录数据的综合业务系统源数据。电网企业人工智能中台的构建是以阿里云平台为核心基础,以服务的形式发布增量数据,实现电网企业既有业务数据的沉淀和更迭,促进数据资源的数量和价值有序增长,实现电网企业数据安全发展,为电网企业建设人工智能中台分析建模和数据的挖掘提供合理的参考。
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:04:12
数学大王·趣味逻辑(2021年11期)2021-12-03 11:04:30
——媒体中台建设的特点和误区
视听界(2021年2期)2021-11-27 00:30:14
全国流通经济(2020年20期)2020-09-17 13:39:28
科技创新与应用(2020年3期)2020-02-04 16:09:09
科技创新与应用(2019年36期)2019-12-23 07:16:37
中国商论(2016年34期)2017-01-15 14:24:18
电子科技大学学报(2016年2期)2016-08-31 02:50:00
河南电力(2016年5期)2016-02-06 02:11:32
河南电力(2015年5期)2015-06-08 06:01:46
