
基于深度强化学习的车辆路径问题求解方法
2022-09-19 08:11黄琰,张锦,2,3
交通运输工程与信息学报 2022年3期
黄 琰,张 锦,2,3
(1.西南交通大学,交通运输与物流学院,成都 611756;2.综合交通运输智能化国家地方联合工程实验室,成都 611756;3.综合交通大数据应用技术国家工程实验室,成都 611756)
0 引 言
车辆路径问题(Vehicle Routing Problem,VRP)于1959 年由Dantzig 和Ramser[1]提出并用于解决卡车调度问题,后被Lenstra 和Kan[2]证明是一种NP-hard 问题。作为交通运输与物流领域最为经典的组合运筹优化问题,VRP 历经几十年的研究和讨论而经久不衰。
基于现实情况,学者们将相关的约束条件添加到标准的VRP 中,设计了多种对应的VRP 扩展问题。如带时间窗的车辆路径问题(Vehicle Routing Problems with Time Windows, VRPTW)、随机服务的车辆路径问题(Vehicle Routing Problem with Stochastic Travel and Service Time and Time Windows, VRPSTSTW)[3]、电动汽车车辆路径问题[4-5](Electric Vehicle Routing Problem,EVRP)、考虑增加车场数量的多车场车辆路径问题[6](Multidepot Vehicle Routing Problem, MDVRP)、带时间窗和人力分配的车辆路径问题[7](Manpower Allocation and Vehicle Routing Problem with Time Windows, MAVRPTW)、考虑一致性约束的车辆路径问 题[8](Consistent Vehicle Routing Problem, Con-VRP)等,并被广泛应用于物流配送、医疗服务[7]以及消防、潜探、巡检等特殊领域。较为常见的车辆路径问题的应用场景、特征和相关经典文献详见文献[9]。
车辆路径问题的常规求解方法主要有精确算法、经典启发式算法和元启发式算法[9-10]。目前,车辆路径问题的传统求解方法均能不同程度地适应各类型的车辆路径问题,但传统求解方法通常针对具体模型和部分静态进行建模和求解,并不具备自主学习和决策的能力。
深度强化学习是一种能够实现从原始输入到输出直接控制的人工智能方法[11],设计的方法无需人工设计或推理,使得其自主解决车辆路径问题,甚至未来自主改进至优于传统方法变得可能。在现代物流快速发展的基础上,面对复杂、数据规模较大的车辆路径规划情景,应当设计可信演化能力更强、算法柔性更大的人工智能方法,以适配实际的车辆路径问题场景,有效支撑智慧物流的发展。
常见的深度强化学习方法包括深度Q 网络方法(Deep Q-learning Networks, DQN)、演员-评论家方法(Actor-Critic,AC)、深度确定性策略梯度方法(Deep Deterministic Policy Gradient, DDPG)、近端策略梯度优化方法(Proximal Policy Optimization,PPO)等。目前,深度强化学习在VRP 中的应用是研究的热点之一[10],相关研究主要集中在采用逐一插入节点的方式构造解的“端到端”深度强化学习方法和运用深度强化学习方法设计启发式算法两个方向。相关文献运用方法及主要成果整理如表1所示。

表1 深度强化学习方法在车辆路径问题中的应用Tab.1 Application of deep reinforcement learning to vehicle routing problems
一方面,相关学者通过逐一插入节点的方式设计“端到端”输出解的车辆路径问题的深度强化学习方法。Nazari 等[12]受到TSP 旅行商问题的深度强化学习相关研究的启示,结合车辆路径问题的特性,通过改进指针网络PtrNet 的编码器,设计了适用于VRP 问题的深度强化学习方法。KOOL等[13]提出了AM 方法,引入注意力机制Attention并设定探索基线Rollout Baseline 用于修正强化学习的奖励。Vera 等[14]基于深度强化学习在多智能体协作系统中的应用,提出了解决固定车队规模的多车辆路径问题的深度强化学习方法,相比启发式方法得到了较优的实验结果。Peng 等[15]在AM方法的基础上引入动态注意力机制,相比文献[13]将算法效率提升了20~40 倍。Bdeir 等[16]针对VRP设计编码器并与DQN思想结合设计了RP-DQN方法,并证明在客户数量为20、50、100 的CVRP(Capacitated Vehicle Routing Problem)上优化效果均优于文献[12]和文献[13]。ORENJ 等[17]提出运用图神经网络表示VRP 的环境状态,并设计了一种在线-离线学习相结合的方法。韩岩峰[18]提出了基于注意力机制和AC 算法框架的深度强化学习方法,并用于解决带时间窗的无人物流车队配送问题。
另一个研究方向则是运用深度强化学习方法针对特定车辆路径问题设计启发式算法。Chen[19]等将车辆路径问题定义为序列到序列的问题,并运用指针网络结合AC 方法设计启发式算法NeuRewriter,并在实验结果上优于文献[12]和[13]。LU 等[20]通过定义改进算子和干扰算子并结合深度强化学习方法构建了启发式算法L2I,首次在实验结果上超过了专业求解器LKH3[21]。之后,Wu 等[22]运用自注意力机制结合REINFORCE 构建了启发式算法,通过对历史解决方案离线学习取得了较好的实验结果。Falkner 等[23]运用深度强化学习方法改进多个并行解决方案,设计了启发式算法JAMPR,并应用于CVRP 问题和VRPTW 问题。冯勤炳[24]设计了基于DQN的强化学习超启发算法,实验证明对比传统方法有效减少了总成本,提升了算法鲁棒性。Zhao 等[25]通过将深度强化学习方法与局部搜索算法相结合设计了启发式算法,实验结果较好,并将求解效率提升了5~40 倍。Gao 等[26]在大规模领域搜索算法框架下结合图注意力神经网络GAT 和PPO 构建了启发式算法,将问题解决规模扩大至400个客户服务点。
综上,运用深度强化学习方法设计启发式算法求解车辆路径问题可以有效地提升求解的速度和效果,但该类模型较适用于求解固定环境和类型的车辆路径问题。部分学者尝试离线学习实例数据求解车辆路径问题,该类实验效果较好,但需要大量数据和算例作为输入,一定程度上影响了算法的效率,降低了方法的实用性。许多学者致力于研究“端到端”的车辆路径问题求解方法,该类方法能够较好地针对不同约束条件的车辆路径问题,但通常需要通过波束搜索、局部搜索等方式提升直接输出解的质量。Bdeir[16]等提出的RPDQN 方法,实验结果在现有“端到端”方法中表现较优,但由于DQN 方法的动作选择方式,尚存在值函数过估计、探索局限等问题,该问题将在后文详细说明并改进。同时,并未有学者系统性地对车辆路径问题强化学习决策过程进行详细设计。
本文针对CVRP 设计了“端到端”输出解的车辆路径问题的深度强化学习方法,其主要贡献如下:
(1)提出了一种基于上置信区间算法(Upper Confidence Bound Apply to Tree,UCT)改进策略选择的DQN 方法,通过平衡智能体对策略的利用与探索,解决现行方法探索局限的问题,提升方法的效果。
(2)针对CVRP,系统性地设计了车辆路径问题场景下的强化学习决策过程,并设计了车辆路径问题场景下的状态-动作空间、奖励函数、策略选择方式等决策过程要素。
1 问题与目标
1.1 问题描述
CVRP 即对每一个服务的车辆都有装载能力约束的车辆路径问题,由一组W辆具有装载能力为cw的车辆,对一系列分布在地理上不同位置的L个顾客进行服务,每个需求点只能由一辆车服务且每个车辆的路线开始于车场,完成服务后回到车场。
1.2 优化目标
深度强化学习是通过环境与智能体的不断交互,修正不同状态下的动作选择,最终输出一系列较优动作的过程。为了达到最终期望的结果,需要通过设置一个优化目标来更好地引导智能体。
参考本文研究的CVRP 传统模型中的目标函数设定优化目标:在满足车辆装载约束的基础上,考虑车辆行驶距离总和最短,如下所示:

2 传统深度Q网络方法
深度Q 网络[27-28]是在Q-learning 的基础上,构建一个参数为Φ的深度神经网络代替Q-learning的Q值表,并通过智能体与环境不断交互更新函数参数,使得函数Qϕ(s,a)可以逼近现实的状态动作值函数Qπ(s,a),该过程为:

式中:s′为下一个状态s′的向量表示;a′为下一个动作a′的向量表示。
函数Qϕ(s,a)与Qπ(s,a)之间的误差,可表示为损失函数:
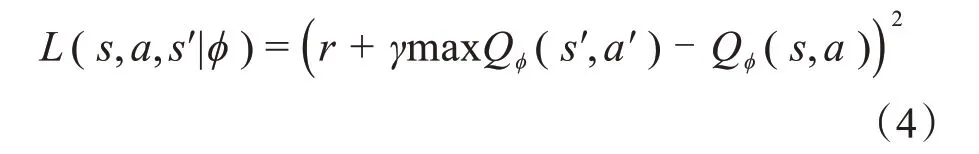
函数Qϕ(s,a)逼近Qπ(s,a)的过程就是损失函数不断梯度下降的过程。
2.1 值函数网络设计
本文参考Kool等[13]设计的基于Transformer框架的注意力模型以及Bdeir等[16]提出的RP-DQN方法,设计了值函数网络。网络结构为基于Transformer 框架的注意力网络,主要组件包括输入层、解码器、编码器和输出层。
值函数网络整体结构如图1所示,具体细节详见文献[13]和[16]。

图1 深度Q网络值函数网络结构示意图Fig.1 Structure of value function network of Deep Q-learning Networks


这些节点嵌入通过N个串联的注意力模块(Attention Blocks,AB)进行传导和更新,每个注意力模块由一个多头自注意力层(Multi-Head Self-Attention Layer, MHA)和一个全连接的前馈层(Feedforward Layer, FF)组成,激活函数为ReLU函数,每层MHA 与FF 之间通过残差连接和批量归一化处理(Batch Normalization, BN)连接而成,并允许信息传递时跳过连接。
2.1.2 解码器
解码器由1个MHA 和1个单头注意力层(Single-Head Attention,SHA)组成。
解码器每一时刻t的输入是当前时刻由编码

式中:u0为选择访问车场输出的q值;ui为选择访问节点i输出的q值;ŵi,t为t时刻节点i的剩余需求;ĉt为t时刻节点i的车辆的剩余装载量。
其中,式(8)表示车场不允许被连续访问;式(9)表示需求大于车辆剩余装载的节点和已被服务过的节点(剩余需求为0)不允许被访问。掩码M的规则设定能够很好地反映VRP 问题的约束条件。本文仅针对CVRP设计了掩码的规则,相关学者可通过增加掩码M规则将该方法拓展至各类车辆路径问题。

式中:dk为维度系数,用于平衡各节点之间的数量级,通常取64;W k和W q分别表示节点状态特征和节点嵌入权重向量。
2.2 车辆路径问题的决策过程
深度强化学习的决策过程为马尔科夫决策过程(Markov Decision Process,MDP)具有马尔科夫性,即一个随机过程其未来状态的条件概率分布仅依赖于当前状态,与之前任意时刻无关。在CVRP问题中,可将求解的过程视作车辆在某时刻与环境进行交互的过程,这个过程是一个离散动作空间。在仅考虑统一车型且不考虑时间窗的情况下,模型中w辆车可视为一辆车取货w次的过程,虽然该过程的每一个决策之间并不存在实际的时间顺序,但决策过程依旧仅依赖当前的状态,具有马尔科夫性,故这个过程可以视为半马尔科夫决策过程。
在这个虚拟的过程中,存在一个智能体即车辆,车辆从起点出发选择一个动作a1,由外部环境给予一个即时的奖励r,同时环境根据动作更改成状态s1,这个过程不断交互,直到所有顾客服务完毕,此时返回所有奖励的和。
智能体与环境交互做出动作的最终目标是达到期望累计奖励最大,可以表示为:

2.2.2 奖励函数
奖励函数的设定直接决定了强化学习方法的收敛性和优化方向,结合CVRP问题的相关约束条件以及式(1)关于本文优化目标的定义,本文定义了智能体每次做出决策,环境给予该决策对应顾客之间距离倒数的正奖励如下所示:

式中:rt表示t时刻的奖励。
3 基于UCT改进的DQN
3.1 传统DQN的问题
深度Q 网络存在对于Q 值过估计的问题。由公式(2)可知,DQN网络训练过程是通过近似估计一个函数逼近现实的状态动作值函数的过程。由于初始状态未知以及原始参数的设定,会导致这个过程的开始对于函数的估计产生偏差。而由于深度Q 网络选择执行的是Q 估计值最大的动作,因此过高估计的动作被选择的概率较大;深度Q网络目标网络冻结的机制,也会导致其不断放大值的过大估计,导致最终结果出现偏差。
同时,由于DQN 选择执行的是Q 估计值最大的动作,智能体每次进行交互的轨迹是一致的,对于未选择动作的探索程度较小,仅是对已经确定的策略进行利用,而非对环境进行探索,难以覆盖所有的状态和动作。若单纯使用深度Q 网络会导致陷入局部最优,不利于最优策略的选取,方法的收敛性和稳定性较差。
3.2 方法改进
本文通过结合UCT 算法改进DQN 中的动作选择方式以改进DQN的过估计和探索局限问题。
UCT 算法是蒙特卡洛树搜索算法(MCTS)的一个拓展,MCTS 作为一种经典启发式搜索算法,最早由Kocsis 等[29]在2006 年提出,UCT 算法是在MCTS 的基础上,将上置信区间UCB 值引入MCTS用于算法决策值的计算,被广泛应用于搜索空间较大的决策过程或象棋、围棋游戏的AI 程序中,如Alpha Go等。
强化学习的本质是通过不断探索环境并充分利用探索的经验进行控制与决策的过程[30]。传统DQN方法在解决环境的探索与利用平衡问题时是通过ε-greedy策略,通过调整贪婪和随机的概率对环境进行充分探索。
但由于ε-greedy策略是随机无向的探索,在小规模的简单问题中尚能进行。但面对较为复杂的问题,特别是VRP问题,要求每个节点顾客必须得到服务,因此对每个节点的特征进行探索是必要的。这种随机无向的探索数据利用率较低,难以保证在短时间内对所有节点特征进行探索。UCT算法则很好地解决了这个问题,UCT 算法定义了一个上置信区间值UCB为:

具体到本文的改进,是将DQN 算法中智能体做动作选择时选择输出最大q值动作的策略,改为选取k个较大q值的节点并向下遍历计算其叶节点的qUCB值,输出qUCB值最大的节点动作。值得一提的是q值的输出借鉴了Hasselt[31]等设计的DQN改进方法,为Q 估计与Q 现实中较小的数值,以此可以减少DQN 的过估计问题。动作a的qUCB值可表示为qUCB(a),表达式如下:

改进后的方法流程如图2所示,细节及具体描述如下。
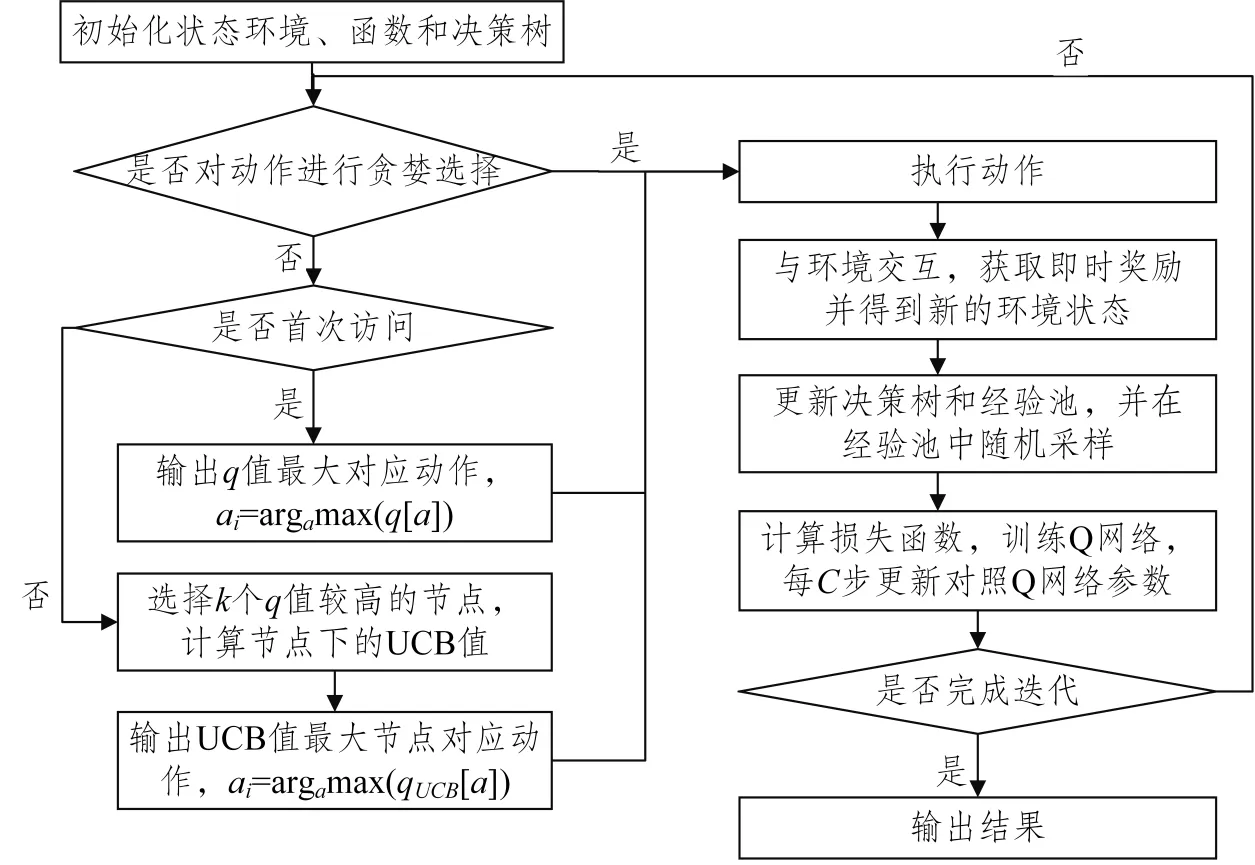
图2 基于UCT改进动作选择的DQN方法流程图Fig.2 Flow diagram of DQN method for improved policy decision-making based on UCT
步骤1 初始化虚拟状态环境。
步骤2 初始化经验池、动作价值函数Q 网络、对照动作价值函数Q 网络、决策树估计函数;设定参数:经验池容量N、最大训练迭代步数M、折扣率γ、学习率α、Adam 函数参数β1 和β2、Q 网络参数Φ、对照Q 网络参数Φ′、更新间隔C、贪婪概率ε、修剪参数k、状态访问次数ns、动作状态访问次数nsa。
步骤3 有ε概率输出随机动作;否则,判断是否首次访问节点,即ns(s)=0。若是,则输出当前q值最高动作,ai=argamax(q[a]);若不是,则输出k个节点中qUCB值最大的动作,ai=argamax(qUCB[a])。
步骤4 执行步骤3中选择的动作,环境依据动作给予式(5)和式(6)的即时奖励ri,并更新得到新的环境状态xi+1。
步骤5 更新经验池和决策树。当经验池饱和时,从经验池的最底端进行新的数据替换。
步骤6 从经验池中随机采样并代入式(9)计算损失函数梯度下降训练Q网络,每隔C步更新对照Q网络参数。
步骤7 判断是否符合训练终止条件,进入步骤8;否则,返回步骤3。
步骤8 输出结果。
改进的DQN框架示意图详见图3。

图3 基于UCT改进动作选择的DQN框架示意图Fig.3 Framework schematic diagram of DQN method for improved policy decision-making based on UCT
4 实验分析
4.1 实验参数敏感度分析和选择
本文选取的实验参数敏感度测试数据集来自Augerat[32]1995 年提出的Set A 数据测试集中的An32-k5 号数据集。该数据集共有31 个需求点、载具装载限制为100、载具数量限制为5 辆,车场坐标、服务点坐标和需求量如表2 所示,其中序号1为起终点,其余为需求点。

表2 实验参数敏感度测试环境信息Tab.2 Environmental information for sensitivity testing of experimental parameters
依据上述数据,本文在gym 中创建了一个100*100 的网格作为本文方法参数敏感性实验的虚拟环境,将数据集数据映射到虚拟环境中。
为测试本文方法在不同参数下的表现以便选择较优的参数进行最终的实例求解,本文对深度Q网络中敏感度较高、能够显著影响训练效果的参数(经验池容量N、UCT 修剪数、对照动作价值网络更新间隔C、折扣率γ和学习率α)进行敏感性分析。其中,经验池容量N、UCT 修剪数、对照动作价值网络更新间隔C并未对算法收敛和累计奖励结果变化造成显著的影响,因此本文对变化较为显著的折扣率γ和学习率α进行详细分析。
为更好地展示算法训练效果和变化情况,本文通过把每100 个训练汇合所得奖励求平均的方式将10 000 次迭代等效处理为100 个趋势点用于累计奖励变化趋势图的绘制。
4.1.1 折扣率的分析与选择
在其他参数不变的情况下,分别对折扣率γ取0.7、0.9 和0.99 的情况进行模拟,迭代10 000 次后累计奖励值变化趋势如图4所示。

图4 不同折扣率下累计奖励随迭代次数变化情况示意图Fig.4 Variation in rewards with number of iterations under different γ
由图4 可得,折扣率γ的调整显著影响了累计奖励的变化与收敛情况。γ取较大值0.99 时,由于对以往经验过于关注,导致最终累计奖励值未能更好地趋近最优值;而当γ为0.7 时,过小的折扣率导致未能很好地学习过去较好的动作选择,最终未在设定迭代步数内完成收敛。
4.1.2 学习率的分析与选择
在其他参数不变的情况下,分别对学习率α取0.005、0.05 和0.001 的情况进行模拟,迭代10 000次后累计奖励值变化趋势如图5所示。

图5 不同学习率下累计奖励随迭代次数变化情况示意图Fig.5 Variation in rewards with number of iterations under different α
由图5 看出,学习率α的调整影响了累计奖励的收敛速度和稳定性。α取0.05 和0.005 时,由于学习率过大导致较快出现收敛趋势,但未能学习到最优策略导致后续逐步出现震荡;当α取值为0.001时,累计奖励平稳上升并有较好的收敛性。
4.2 实验环境设置
为了更好地与其他深度强化学习方法进行对比,本文在文献[12]定义的车辆路径问题环境下进行实验,该环境自提出以来被用于测试国内外各类深度强化学习方法[12-20,22,23,25,26]在车辆路径问题场景下的性能。实验假设节点位置和需求是从固定分布随机生成的,具体来说,客户和车场位置是从1×1的单位方格中随机生成的,每个节点的需求在[0,10]中随机选择。此处为模拟真实需求,遵循了文献[13]的设定将需求值定义为离散的正整数。针对智能体行为设置,本文假设车辆在时间0时位于车场,在每次交互过程中,车辆从客户节点或仓库中进行选择,以便下一步访问,直至所有节点访问结束,返回车场。
本文将分别对比20、50、100 三个问题规模下的CVRP 问题,以下分别简称为CVRP-20、CVRP-50 和CVRP-100,相应规模下的额定载重分别为30、40 和50。通过在每个数据规模下随机生成1 000个实例,并且每个实例只使用一次,通过计算平均成本对比实验结果。
基于上述实验设置本文在Intel(R) Core(TM)i7-4720HQCPU@2.60 GHz、RAM 16.0 GB电脑上使用Python 语言,采用Tensorflow 框架在Jupyter Notebook中实现设计的基于UCT改进动作选择的DQN 算法。在参数敏感性分析的基础上,实验参数设置如表3所示。
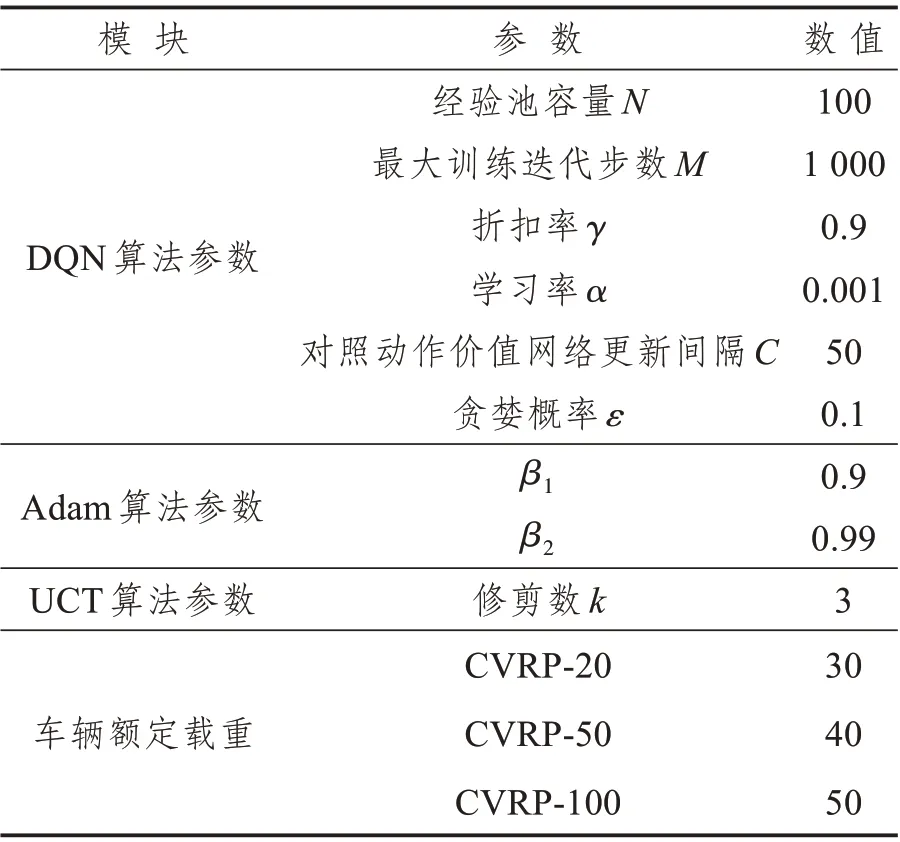
表3 实验参数设置Tab.3 Experimental parameter settings
4.3 方法有效性分析
为反映UCT-DQN 的学习过程和收敛情况并直观地与RP-DQN[16]进行对比,本文将各数据规模上两种方法的奖励及优化目标变化情况进行了绘制,如图6所示。其中,优化目标依据公式(1)为车辆行驶总距离的成本,成本越低,实验效果越优。同时,为加强实验结果的可读性,本文通过每20步取平均值的方式对奖励和优化目标值进行了平滑处理。
由图6可以看出,两者都是标准的深度强化学习曲线。智能体获取的奖励值曲线波动上升,说明智能体根据学习情况,逐步调整动作选择策略。训练初期由于Q值的估计准确性较低导致曲线波动较大,随着训练次数的增加,逐步学习到了较好的策略,波动逐步趋于稳定,说明两种深度强化学习方法均具有较好的收敛性和准确性。


图6 各规模环境奖励及优化目标随训练过程变化情况示意图Fig.6 Variation in rewards and optimization objectives with training process in various environments
对比两种方法,在CVRP-20 中,由于实验规模较小,两种方法均较快地探索到较好的解决方案,并 很 快 收 敛;在CVRP-50 和CVRP-100 中,RPDQN 方法虽较快呈现出收敛趋势,但由于探索局限和过估计问题,过分依赖已探索的动作策略,导致最终收敛的值尚有一定的提升空间。本文的UCT-DQN 方法,虽收敛趋势较为缓慢,但在三个问题规模中最终都获得了较高的奖励和较低的成本。通过统计分析,本文方法在CVRP-20、CVRP-50 和CVRP-100 三个规模中的平均成本分别为6.24、10.80 和16.23,对比RP-DQN 方法分别提升了1.89%、1.10% 和2.17%,取得了较好的实验结果。
本文所提方法对比RP-DQN 方法虽收敛时间较长,但实际应用环境下,依托GPU 服务器、高性能计算机或超算平台等,本文的方法可以快速输出较高质量的可行解或作为优秀的初始解用于启发式算法、求解器等。
将本文方法所得结果进一步与专业求解器OR Tools、Gurobi、LKH3、启发式算法节约里程法CW、扫描算法SW 以及其他“端到端”的深度强化学习方法结果进行对比,结果整理如表4所示。其中,本文以每个数据规模下的最优结果为基线,对比其他方法和求解器与其的成本偏差,偏差率值越小,方法所得结果越优。
由表4 可以看出,本文所提方法在CVRP-20中平均成本仅高于求解器Gurbi、LKH3 以及文献[17]的SOLO 的在线学习方法,与上述三种方法相比,本方法的耗时较短,能够一定程度上提升运算效率;在CVRP-50 问题中,实验结果略逊于LKH3以及文献[15]的AM-D方法;在CVRP-100问题中,实验结果相比LKH3 求解器有3.71%的成本误差,但优于其他所有“端到端”的深度强化学习和启发式算法。实验结果显示,在充分训练的基础上,随着问题规模的扩大,本文所提方法性能优势逐步显示,且相比LKH3 求解器虽有较小误差,但能较好地提升求解效率,说明该方法有较好的应用前景。
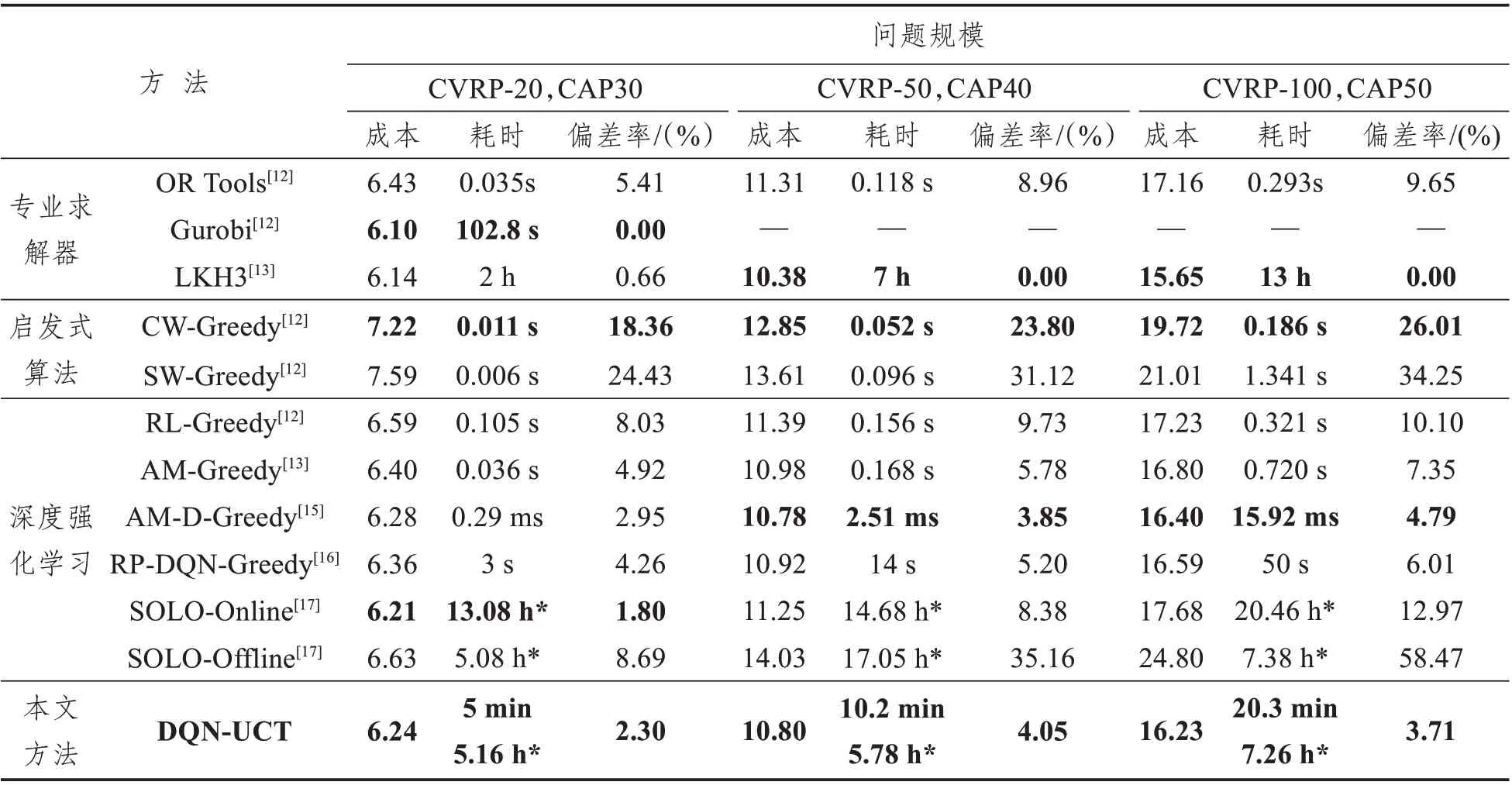
表4 实验结果对比Tab.4 Comparison of experimental results
5 结束语
本文提出一种基于UCT算法改进动作选择方式的DQN 方法。所提出的深度强化学习方法用于车辆路径规划场景,通过智能体与虚拟环境交互获得奖励寻求行驶距离最短的动作组合策略,“端到端”解决了考虑车辆装载限制约束的车辆路径问题。实验结果表明,本方法能够得出与专业求解器质量相当的解。所提算法在充分训练的基础上,能切实提高车辆路径问题的求解效率,未来在实际应用领域更具可行性。下一步工作,将考虑群智感知环境下DQN 的可信演化问题,结合企业实际进一步验证模型的场景实用性;同时,将本文方法运用在其他约束条件或更大规模的车辆路径问题也是本文的下一步工作之一。
猜你喜欢
食品科学与人类健康(英文)(2022年2期)2022-11-28
机械工业标准化与质量(2022年6期)2022-08-12
快乐学习报·教育周刊(2022年16期)2022-05-01
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
福建基础教育研究(2019年6期)2019-05-28
小太阳画报(2018年3期)2018-05-14
阅读与作文(小学低年级版)(2016年12期)2016-12-22
汽车文摘(2015年11期)2015-12-02
