
基于岩石文本信息的命名实体识别
2022-09-16 06:50杜睿山陈思路刘文豪
计算机技术与发展 2022年9期
杜睿山,陈思路,刘文豪
(东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
自然语言处理属于人工智能与语言学的交叉学科,其中的命名实体识别是实现信息抽取的重要基础任务[1]。为智能化地对岩石薄片信息进行信息抽取以及生成研究对象相关属性等信息,进而揭示具体(比如岩石结构构造、颗粒状态、产状成因等)特征、变化及规律,这在油气勘探、开发、生产的各个阶段发挥着越来越关键的作用[2]。这可以进一步满足研究人员的快速判读需求,实现决策支持的功能。岩石相关信息多以非结构化文本形式存在于书籍和文献中,岩石相关命名实体是从非结构化文本数据中抽取出的一些含有具体特征或描述意义的相关岩石名词。
命名实体识别作为智能问答、知识图谱等自然语言处理下游任务研究的基础工作,一直受到研究者们的关注。命名实体识别的早期方法主要包括基于规则的方法[3]、基于统计的方法以及基于神经网络的方法[4-5]。通过手动创建规则、创建权重或者创建实体和规则之间的一致性可以实现早期的基于规则的方法,但存在着一些缺点,比如可移植性差、维护性差。隐马尔可夫模型[6]、支持向量机[7]、最大熵[8]和条件随机场[9]等对语料库的依赖较大的方法都可作为基于统计的方法实现命名实体识别任务。基于神经网络的方法对特征的依赖更小且更通用,并且广泛用于命名实体识别任务中,如循环神经网络(Recurrent Neural Network,RNN)[10]、长短期记忆网络(Long Short-Term Memory,LSTM)[11]、卷积神经网络(Convolutional Neural Network,CNN)[12]等。近年来,实现命名实体识别采用BiLSTM模型结合CRF模型实现,可以通过上下文信息的完美结合得到相邻标签之间的依赖关系,并且可以达到良好的效果。Huang等首次利用此模型进行命名实体识别[13]。丁泽源等在中文医学领域进行命名实体关系抽取[14]。尹学振等针对在互联网公开数据中进行军事领域命名实体识别[15]。
中文命名实体识别是基于深度学习的研究将其转化为序列标注任务,这样的解决方法通常是先进行分词再进行词的分类从而得到命名实体,但这过程中存在着错误传播问题。Zhang等提出基于lattice结构的命名实体识别[16],将单词本身的含义加入基于字向量的模型中从而解决了实体边界不清、误差传播的问题,但由于模型加入词典信息而对不相邻字符增加很多边导致模型过于复杂,所以存在计算效率低的缺点。
该文结合领域专家的意见,基于开放的非结构化文本数据构建了岩石语料集。在此基础上,提出一种岩石相关命名实体识别模型。使得每个字符的所有匹配词合并到字符级别NER模型中,进而实现非结构化岩石文本数据的命名实体识别任务。
1 岩石文本的命名实体识别模型
该文构建了基于岩石文本Lexicon-LSTM-CRF的NER模型,模型自底向上分为以下三个部分:基于Softlexicon的字向量表达层和BiLSTM层以及CRF层。首先,输入序列中的每个字映射为字向量。然后将Softlexicon特征组合并加入到字向量的表示中,同时获得每个字符的所有匹配词,这一机制缓解边界不清、分词困难的问题,然后将字向量表示输入到序列编码层,从而提取上下文特征。最终通过CRF层,相邻标签之间的依赖关系可以利用特征向量获得,从而降低错误标签的输出概率并输出相应的标签。岩石文本信息的命名实体识别模型如图1所示。

图1 岩石文本信息的命名实体识别模型
1.1 字向量表示层

由于使用ExSoftword方法将会导致无法加载预训练模型,且会缺失匹配信息,则该文使用Softlexicon方法避免以上缺点。对于一个输入句子S的一个字符,它的所有匹配词分为BMES四个类,得到4个词集合,具体见式(1)~式(4):
B(ci)={wj,∀Wj,k∈L,i (1) M(ci)={wj,∀Wj,k∈L,1≤j (2) E(ci)={wj,i,∀Wj,i∈L,1≤j (3) S(ci)={ci,∃ci∈L} (4) eS(B,M,E,S)=[VS(B),VS(M),VS(E),VS(S)] (5) XC=[XC;eS(B,M,E,S)] (6) 1997年,Hochreiter等提出一种特定形式的循环神经网络——长短时记忆网络 LSTM[17]。该模型的输入层为输入Xt,隐藏层输出为ht,输入门it、输出门οt、遗忘门ft以及记忆控制器Ct等四部分组成每个LSTM记忆单元。LSTM记忆单元如图2所示。 图2 LSTM记忆单元结构 由于LSTM局限于只能计算过去的上下文信息,未来的上下文信息对岩石文本信息的实体特征提取同样重要,故可以采用BiLSTM神经网络模型[18]。BiLSTM模型通过顺序和逆序对输入的序列进行计算并输出两个隐藏层的向量并拼接得到最终的输出向量。该文结合词典信息,对字符之间的依赖关系进行建模引入序列建模层。这一层的通用架构包括双向长短期记忆网络(BiLSTM)、卷积神经网络(CNN)和变换器(Vaswani et al.,2017)。在这项工作中,用一个单层的BiLSTM实现了这个层。这里,精确地展示了正向LSTM的定义,具体见公式(7)~公式(9): (7) Ct=Ct⊙it+Ct-1⊙ft (8) ht=ot⊙tanh(Ct) (9) 在序列建模层的顶部,通常应用序列条件随机场,它是一种用来标记和切分序列化数据的统计模型[19]。即在给定观测序列下,计算输出标记序列的条件概率分布,见公式(10)。 (10) CRF层有效地考虑了上下文依赖,在BiLSTM层之后增加了CRF层,因此实体识别模型利用上下文信息的组合来有效地考虑标签依赖。 有效降低了错误标签的输出概率并实现预测实体标注标签。利用训练好的模型,对语料进行实体标注,在CRF层,转移矩阵作为参数,更新 BiLSTM中的参数与CRF中转移概率矩阵时使用最大似然估计作为真实标记序列的概率从而标注实体类型,最终输出标注结果。从而完成岩石文本非结构化数据信息的命名实体识别任务。 通用领域的命名实体识别具有稳定的类别、规范的结构、统一的命名规则,主要包括人名、地名、组织名称等实体。相比而言,岩石相关文本信息的命名实体分类更为复杂,使用相关教材和文献制作数据集是非常好的数据来源。其中《矿物岩石学》、《简明岩石学》、《矿物学》等教材包含着有价值的岩石相关的实体信息。例如矿物实体、岩石实体、各类属性实体。为了弥补岩石相关文本的开放命名实体识别语料库的不足,该文基于教科书的非结构化数据构建了一个语料库,为基于开放数据研究岩石信息的命名实体识别奠定基础。结合领域专家的专业知识和已有的文献资料确定岩石相关文本信息的命名实体划分类别,并将实体的模糊边界与实体的简化表示相结合,将原始未标注语料的语料按照字级别进行标注。最终构建包含26 784个句,17个类别的语料集。 语料库是以原始语料文本为原材料,通过标注任务导向的操作方法从而形成带有语言学信息标注的语料文本。该文结合岩石文本语料本身特点,采用BMOES标注与自定义标注标签相结合的方式进行标注。针对其专业术语多、歧义少的特点,采用简洁、高效的BMOES标注机制,领域专家参与共同标注。BMOES标注是针对数据集中的每个实体进行字级别的位置标注,命名实体的开始用B表示,命名实体的内部用M表示,命名实体的尾部用E表示,单个命名实体用S表示,不属于命名实体中的字用O表示。将岩石信息分为17大类,标注形式具体如表1所示。 表1 命名实体标注类别 针对已获取的原始语料数据,应用命名实体标注、分类机制,实施对原始语料的实体标注,最终形成了岩石文本语料集,具体各类实体数目如表2 所示。 表2 岩石文本语料集实体统计 续表2 综上所述,由于目前没有开放的岩石语料库,该文手动构建了中文岩石文本实体语料库用于研究。实验中随机划分70%的语料作为训练集,20%的语料作为验证集,10%的语料作为测试集。命名实体识别模型的超参数设置如表3所示。 表3 实验参数设置 设置了以下5组实验,应用准确率P、召回率R与F值进行模型评估。在构建好的岩石文本数据集上,比较了上述三种命名实体识别的有效性。实验结果如表4所示。 表4 实体识别模型效果对比 从实验结果可以看出,BiLSTM-CRF相比于不引入CRF层的BiLSTM模型准确率提高1.24%,F1值提高1.4%;Lattice-LSTM-CRF相比于不引入CRF层的Lattice-LSTM模型准确率提高1.33%,F1值提高3.27%;加入CRF层可以充分考虑实体的逻辑性和顺序性,从而提升了准确率与F1值,证实了此机制可以降低错误标签的输出概率,有助于标签的预测。此外,提出的Lexicon-BiLSTM-CRF的方法F1值可以达到96.10%。在中文的数据集上,该方法比Lattice-LSTM中文实体识别模型的效果还要好,主要原因在于lexicon解决了词典无需重复多次调用的缺点,性能得以提升。 岩石实体识别中存在实体界限不清晰、实体种类丰富、数量大等问题,该文面向教材文献等非结构化数据进行岩石命名实体识别。结合领域专家的专业知识,建立了岩石相关命名实体分类规则,并构建了基于教材文献等非结构化文本数据的语料集。以岩石相关非结构化信息抽取为对象,提出了针对岩石文本信息的Lexicon-BiLSTM-CRF模型抽取方法。该模型利用字向量的优势,在基于字向量的模型中加入单词本身的含义。除此之外,该模型在训练过程中保存了所有可能匹配单词的同时利用attention机制自动给单词赋权重,进而提高了运行效率和准确率。在岩石文本数据集上通过实验对比,分析并验证了基于BiLSTM-CRF、Lattice- BiLSTM-CRF、Lexicon-BiLSTM-CRF的实体识别模型的有效性。下一步将用该方法在油气勘探、开发、生产领域的其他类型语料上进行广泛的训练和测试,提高模型的泛化能力。
1.2 BiLSTM层
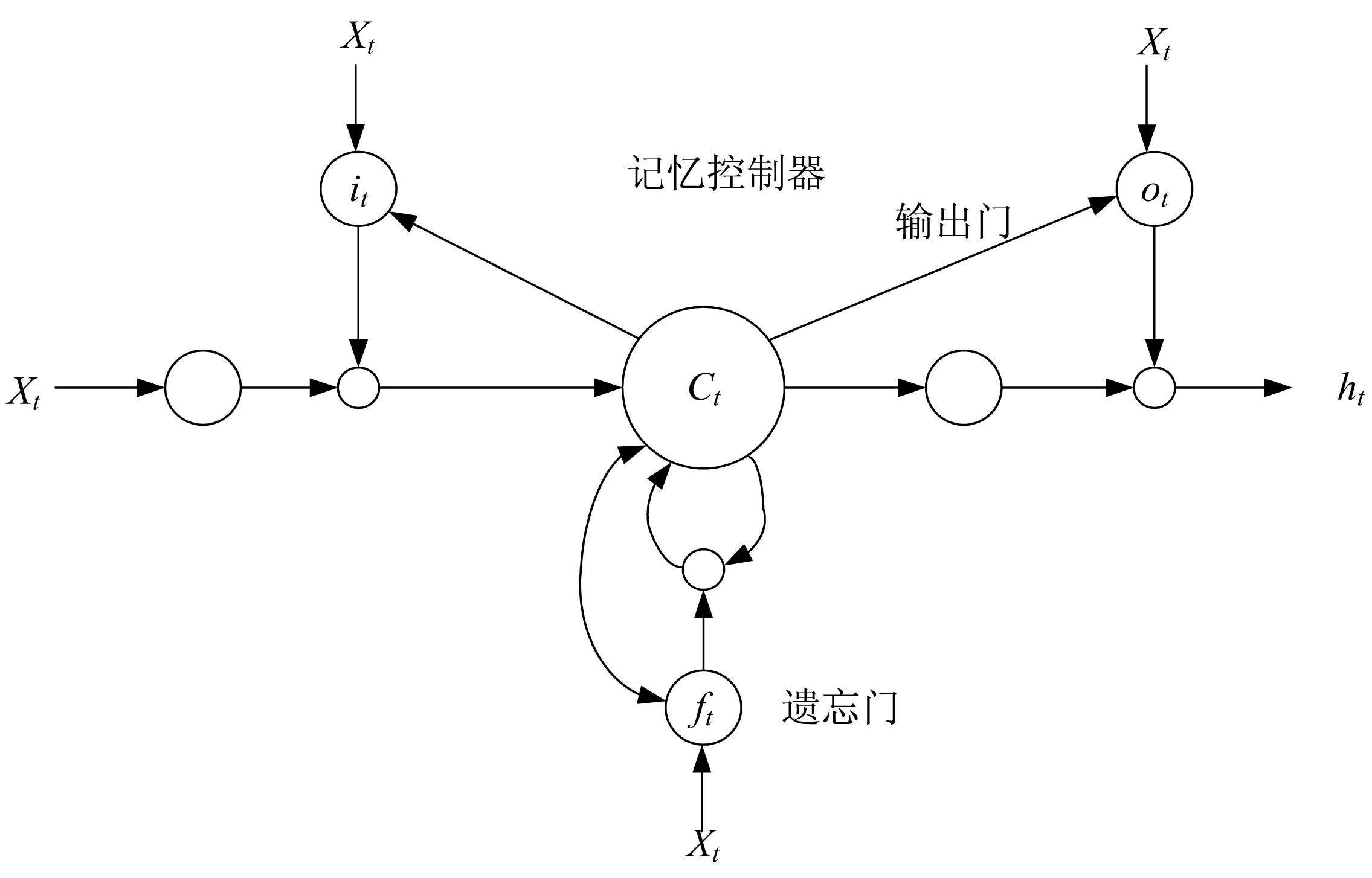
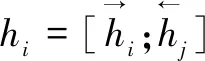
1.3 CRF层

2 模型实验及分析
2.1 实体标注与分类
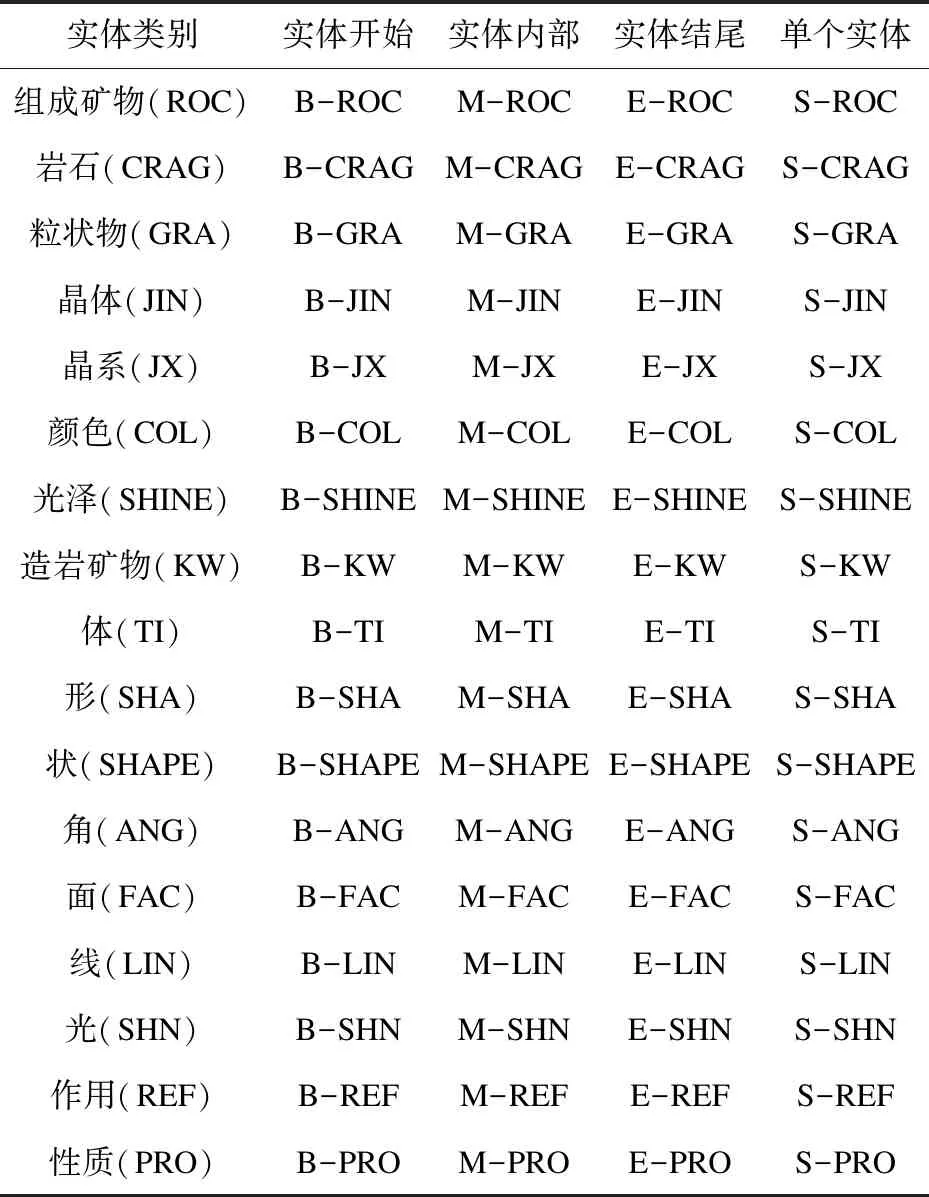
2.2 语料集统计
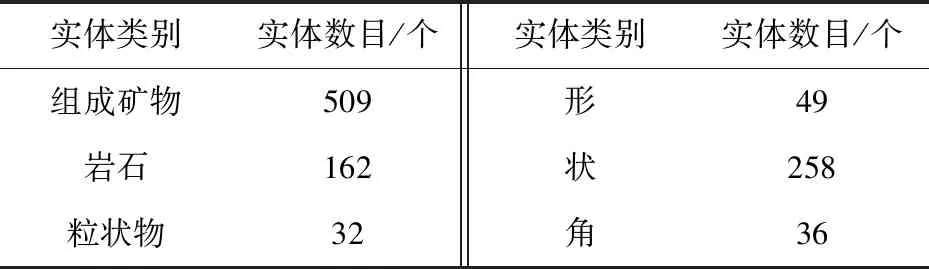

2.3 实验及结果分析


3 结束语
猜你喜欢
军事文摘(2022年18期)2022-10-14课堂内外·好老师(2022年3期)2022-04-25学习与科普(2022年17期)2022-04-23金桥(2021年5期)2021-07-28云南教育·小学教师(2021年12期)2021-03-23福建基础教育研究(2020年3期)2020-05-28长江丛刊(2019年25期)2019-11-15电脑知识与技术(2019年23期)2019-11-03东方女性(2018年3期)2018-04-16科学与财富(2016年30期)2017-03-31
