
基于YOLOX-L算法的安全帽佩戴检测方法
2022-09-16 06:49李骏峰杨小军张凯望
计算机技术与发展 2022年9期
李骏峰,杨小军,张凯望
(长安大学 信息工程学院,陕西 西安 710068)
0 引 言
随着现代化进程的推进,全国各地的基础建设发展越来越快,规模越来越大,对应的建筑建设需求等越来越多,然而随之而来的是基础建设过程中伤亡事故发生率的持续上升。鉴于此,近年来国家大力推广建筑业安全生产理念,多次通报建筑事故并分析事故原因,这些事故大多是由于施工现场违章违规引起的。对于建筑等生产环境来说,安全帽是一种基础生命保障设备,但由于监管和工作者意识问题,不佩戴安全帽的现象普遍存在,从而引发多次安全事故造成伤亡。为了改善这种情况,有必要检测施工人员是否佩戴,降低作业人员由于没有佩戴安全帽而造成事故的发生率。
传统的目标检测一般通过设计手工特征来实现,这种方法检测准确率低,泛化性能差。而深度网络如卷积神经网络(CNN)等,无需设计手工特征[1],直接根据网络层的特征传递并进行最终的检测等任务的输出,而且经过大量学者实验的证明,深度网络确实在目标检测方面具有更大的优势。姚群力等[2-3]将卷积神经网络和目标检测结合起来进行了相关研究。谢林江等[3-4]鉴于行人检测鲁棒性差、计算量大以及特征提取复杂等原因,将改进的卷积神经网络与行人检测相结合,提高了行人检测准确率。彭清等[3,5]针对现有车辆识别计算量大,特征提取复杂的问题,分别设置不同的卷积核、网络层数和特征图数的卷积神经网络训练模型,去检测识别车辆,正确率高达97%,明显优于传统方法。由此可见,越来越多的学者将检测的发展方向投向了深度学习的方法,并结合各种实际应用场景,是目前计算机视觉的热门研究方向之一。
目前,基于深度学习的目标检测算法大致可以分为两类,一类称为两阶段(two-stage)目标检测算法,另一类称为一阶段(one-stage)目标检测算法,两者的区别在于是否生成候选区域(region proposal)。两阶段目标检测算法首先生成可能包含目标的候选区域,进而对候选区域进一步的分类和边框回归,经过两个网络结构得到最终的检测结果,代表算法有R-CNN[6]系列,如fast R-CNN[7]、faster R-CNN[8],也可以将无锚技术应用到两阶段检测器,如RepPoints[9]。然而,这类算法由于其两阶段设计,网络复杂度高,速度方面有限,难以达到实时要求。不同于两阶段检测算法,一阶段检测算法将整张图像输入,只用经过一次CNN网络,将检测框的定位和分类看成回归问题,就可以不需要额外生成候选区域便能够识别出图片中的目标并给出其位置;因此其检测速度快,但是准确率相比于两阶段目标检测器不太理想,此外对于这些基于锚的检测器,针对具体的数据集,需要在训练之前通过k-means等聚类算法来确定最优锚点,缺乏泛化性,并且增加了检测头复杂性,代表算法有YOLO系列[10-14]、RetinaNet[15]。
针对有锚框检测器的缺点,近两年来,目标检测的新趋势主要集中在无锚检测器[16-17]、高级标签分配策略[18-19]和端到端(无NMS)检测器[20-22]。无锚检测器的出现解决了one-stage实时性好但是准确率不行的问题。无锚检测器利用特征图关键点直接回归目标信息,无需依赖设计复杂的锚框,典型网络有CenterNet[17]、FCOS[16]等。因此Ge等人[23]对YOLO系列结合当前目标检测发展趋势进行改进,将YOLO检测器切换到无锚模式,并使用解耦头和标签分配策略SimOTA等,形成了一种高性能的检测器─YOLOX。
作为最新的高性能的YOLO系列的检测算法,YOLOX系列模型具有参数量和计算量少、检测速度实时、检测准确率高、适合多种高低端应用设备、泛化能力强等优点。其基于无锚的设置很大程度解决了小目标识别等问题。因此该文使用安全帽佩戴检测数据集(SHWD)[24],考虑到速度和准确率的权衡,使用YOLOX系列中的YOLOX-L模型为主体,多处融合不同尺寸特征,针对不同大小的目标,用于位置和类别预测;在训练过程中使用冻结训练加快模型训练,并使用训练好的模型在测试集上进行验证测试;最后再与业界使用最广泛的检测器之一的YOLOv3算法[12]进行比对。实验证明,针对安全帽佩戴检测的目标任务,YOLOX-L算法能够在保证实时性的同时提高检测准确率。
1 YOLOX-L原理
YOLOX系列模型是一个以目标检测为目的设计的网络。其不同于传统的YOLO系列,YOLOX-L模型采用对预测头进行解耦,去除锚框切换为无锚模式以及使用高级标签分配SimOTA[23]等当前目标检测主流方法。而YOLOX的其他模型也基本上按照这种改进方式。这种改进使得YOLOX-L在保持YOLO系列速度优势的前提下,减少了参数量及计算量并提升了预测准确率。
1.1 预测分支解耦
目标检测中,分类和回归任务间的权衡及冲突是一个常见的问题[25-26]。因此,用于分类和定位的解耦头广泛用于大多数单级和两级检测器[12-13,15-16,26]。然而,YOLO系列的检测头仍然保持耦合。这种耦合的检测头,表达能力有所欠缺,如果放在一起反向传播的时候可能导致网络收敛速度慢,准确率降低。因此YOLOX-L将原先的耦合的检测头改为类似于RetinaNet[15]的解耦头。但是,将检测头解耦合,会增加FLOPs(计算量),因此YOLOX-L最终使用1个1×1的卷积先进行降维,并在后面两个分支里,各使用2个3×3卷积,最终调整到仅仅增加一点点的网络参数,如图1所示。

图1 YOLOX-L采用的解耦头结构
YOLO在FPN[27]自顶向下路径上的3个level(P5,P4,P3,通道数分别是1 024,512,256)上进行检测。基于锚的检测器YOLOv3~v5[12-14]中针对C类别数的检测任务,每一个anchor会对应产生H×W×(C+4+1)维度的预测结果,其中cls(区分前景背景)占用1个通道,reg(检测框坐标)占用4个通道,obj(预测C类别中的那一类)占用C个通道。而YOLOX-L首先使用1×1卷积将原本不同的通道数的特征先统一到256,然后使用两个平行分支cls(分类)分支和reg(目标框回归)分支,两个分别使用3×3卷积,同时reg分支还添加了IoU分支,并在cls分支和obj(是否是目标)采用二分类交叉熵损失,而在reg分支的训练中采用IoU损失。这种改进使得分类和回归任务互不冲突,加快了网络收敛,提高了准确率,更有利于检测任务。
1.2 无 锚
YOLOv3[12]等检测器遵循原始的基于锚的管道。但是锚的使用需要针对不同的数据集进行聚类分析,确定最优锚的尺寸超参数,缺乏泛化性,检测头复杂性和针对输入图像的无用的预测数量也增加了,对于一些嵌入式设备之间的预测移动,可能会成为总延迟的潜在瓶颈。
使用anchor-free的方式可以减少需调整的参数数量,减少所使用的技巧(例如,锚聚类[11]、网格敏感[28]等)。但是去掉了锚框,相当于去掉了针对于地面真值尺寸的先验,FPN的时候肯定会出现问题,因此YOLOX-L借鉴FCOS算法的设计,预先设定一个尺寸范围,根据地面真值的尺寸来判断应该分配到哪个尺度。为了将YOLO切换到无锚模型,YOLOX-L将原本对每个位置的预测数从3减少到1,并使它们直接预测目标框相对于网格左上角的坐标偏移量,以及框高和框宽四个值。YOLOX-L中,正样本从每个对象的中心位置中指定,并且提前设定一个比例范围,就像FCOS中所做的那样,用来指定每个地面真值对应的FPN。
但是为和YOLO系列[12-14]的分配规则一致,上述的无锚的YOLOX-L只能够为每个地面真值选择一个阳性样本,忽略其他的有价值的预测。然而,优化这些有价值的预测也会带来有益的梯度,这在一定程度上能够缓解训练期间正负样本的不平衡,因此YOLOX-L将中心3*3区域指定为正样本。
这些修改降低了检测器的参数和计算量,但是却获得了更好的mAP性能。
1.3 SimOTA
高级标签分配是近来目标检测的又一重要进展。基于OTA[29]的研究,YOLOX-L的候选标签分配策略采用OTA,OTA从全局角度分析标签分配,并采用最优传输问题的方式转化分配过程公式的方式去产生当前分配策略中的SOTA性能[18-19]。然而,OTA中为了解决OT问题而采用的sinkorn-Knopp算法对训练过程并不友好,会有25%的额外时间开销,因此YOLOX-L弃用sinkorn-Knopp算法并将OTA简化为动态top-k策略,命名为SimOTA,以获得近似解。
SimOTA[23]首先计算每个预测和地面真值对的成本[19-20,29-30]或者质量[21]。例如,在SimOTA中地面真值gi和预测pj之间的成本计算如下:
(1)
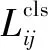
2)包括了服务器端操作数据库需要的所有方法,这些方法的实现过程比较类似。首先与数据库建立连接,然后执行查询或者修改的SQL语句,最后将得到的数据库信息组织为相应的格式返回。
SimOTA不仅减少了检测任务训练时间,而且避免了sinkorn-Knopp算法中额外求解超参数。
2 YOLOX-L的网络结构
YOLOX-L模型使用修改的CSPNet替换原本的CSPNet[31],并使用SiLU激活函数[32]替换常用的Leaky Relu激活,也保留了FPN+PAN[33]的颈部设定。上述改进使得YOLOX-L模型在保持实时的同时,提升了预测准确率。
YOLOX-L使用了新的修改过的CSPNet,并且针对骨干部分和颈部,设计了两种不同的CSP结构,如图2所示。对于骨干使用的修改过的CSPNet即CSP1_X就是将前一次的3×3、步长为2的卷积作为输入,并将该特征映射划分为两部分,其中一部分进行一次1×1、步长为1的卷积并保存结果,另一部分则进行一次1×1、步长为1的卷积和X个残差组件,将该结果与另一分支保存的结果合并,之后再进行一次1×1、步长为1的卷积。而对于网络颈部使用的CSP结构即CSP2_X,也是将输入划分为两部分,一部分进行连续两次的1×1、步长为1的卷积,另一部分进行连续X次的1×1、步长为1的卷积,并将两部分的输出合并,然后仍然是进行一次1×1、步长为1的卷积。CSPNet中的卷积操作以及使用的残差块中的卷积都是包含了普通卷积、BN层和SILU激活层三部分。CSP结构本身就可以增强卷积神经网络的学习能力,能够在轻量化整体网络、降低计算瓶颈以及减少内存成本的同时保证准确率。跟原本的CSP结构相比,如图3所示,YOLOX-L采用修改的CSP结构在减少计算量的同时可以保证准确率。

图2 YOLOX-L所采用的CSP结构

图3 原始CSP结构
由于部分YOLO系列中采用的leaky ReLU是单调非光滑的函数,在检测过程中梯度容易学习缓慢。SILU(sigmoid weighted liner unit)是一种非单调且光滑的函数,同时就像Leaky ReLU一样是上无界下有界的函数,能够产生强正则化的效果,还可以避免梯度爆炸和梯度消失的发生。此外,非单调性有助于负值的时候允许较小的负梯度流入,SILU函数不仅能够加快学习速率而且还能得到更好的准确性和泛化能力。另外,研究者们基于大量实验证明了光滑的函数曲线能够使得深度模型获得更好的信息,从而提高网络的准确和泛化能力。这里YOLOX-L模型选择SILU作为激活函数。SILU函数的公式如下:
f(x)=x*σ(x)
(2)
为了针对不同的目标尺寸都具有良好的检测性能,YOLOX-L延用YOLO系列中的FPN结构,针对骨干层不同的特征图进行特征融合。对于输入是640×640的图片,由于Focus结构会将输入的尺寸减半以及每个CSP模块前面的卷积核都是步长为2,3×3大小的,都具有下采样的功能,特征图的变化尺度依次是640->320->160->80->40,如图4所示,网络在骨干的底层,中下层以及中间层输出的特征图大小分别是40×40,80×80,160×160,这三层的输出,可以理解为是特意针对了不同尺寸的目标而输出的特征图。特征图尺寸不同,具有不同的作用,目标位置信息由浅层的大尺寸特征图提供,而深层的小尺寸特征图提供语义信息。并使用FPN层将相邻尺寸的特征图之间进行融合。除了FPN的融合特征外,YOLOX网络的颈部还在FPN层后面增加了一个与FPN相对的结构,即包含两个PAN结构的自下而上的特征金字塔。FPN自上而下,将浅层特征与上采样后的上层特征信息进行传递融合,而PAN自下而上,将下采样后的小尺寸特征图像与大尺寸特征图像进行融合,并成对组合,对不同的检测层进行两次参数融合。从而结合大小特征图的特征信息,无论是大尺寸的检测目标还是小尺寸的目标,都能够有良好的检测结果。因此YOLOX-L对于大小不同的目标均有良好的效果。

图4 YOLOX-L结构
为了更好地理解YOLOX-L的尺度变化过程,用实际输入对YOLOX-L网络的原理进行说明。如图4所示,当输入图像的尺寸大小为640*640*3像素时,首先经过一个Focus结构,图像大小变为原有的1/2,通道数为64,同样,当在经过第一个骨干层的CSP结构前,都会进行一次下采样操作,当下采样(包括之前的Focus结构产生的效果)5次、4次、3次,图像分别变小32倍、16倍和8倍,通道数从最初的64分别扩大4倍、8倍和16倍,检测层也分别得到尺寸20×20、40×40和80×80的特征图。不同尺寸的特征图在经过颈部结构之后,在预测头的输出经过concat以及reshape等操作,分别输出6 400×(4+1+C)、1 600×(4+1+C)和400×(4+1+C)的张量,其中4个通道是针对检测框的左上角坐标以及其宽高,1个通道是针对是前景还是背景,C个通道是对应的类别的预测,最终再将这三个张量进行合并操作以及转换操作,最终输出(C+4+1)×8 400的预测结果,其中C是要预测的类别数。
3 实 验
为了说明最新的高性能算法YOLOX-L在安全帽佩戴检测方面的良好应用以及其相比于应用广泛的YOLOv3算法的优势,基于安全帽佩戴检测数据集设计整个实验,并针对YOLOX-L和YOLOv3算法进行对比实验。
本实验硬件:Windows 10系统,R7 4800H的CPU,GTX 1650Ti的显卡,16G大小的内存,此外也包括python、pytorch、CUDA、OpenCV的常用开发环境。
3.1 实验数据集
该文使用2019年开源的SHWD(安全帽佩戴检测)数据集。该数据集用于安全帽检测和人体头部检测,覆盖多种安全帽佩戴场所环境,主要通过爬虫拿到,包括7 581幅图片,其中训练集包含5 457张图片,验证集包含607张图片,测试集包含1 517张图片,整个数据集包含9 044个人类安全头盔佩戴物(正类)和111 514个正常头部物体(负类),其中正类对象来自谷歌或者百度,部分负类数据来自华南理工大学,所有的图像用labelimg标注出目标区域以及类别,标注文件格式为xml,正类和负类的标签分别是“hat”和“person”,整体数据格式为Pascal VOC格式。整体数据图像的平均分辨率约为971×654。
3.2 YOLOX-L模型训练
在实验起初设置中,将SHWD数据集按照9∶1的比例划分为训练集和测试集,并随机选择10%的训练样本作为验证集,最终训练集包含5 457张图片,验证集包含607张图片,测试集包含1 517张图片,并且将图像对应的标注xml文件中的目标框和类别信息读取出来。此外,考虑到数据集的图像尺寸以及所用设备的GPU情况,最终选择640×640的尺寸进行输入。
模型训练分为两步骤,第一步骤训练为冻结训练,只训练骨干网络部分,设置学习率(learning rate)为0.001,迭代次数为200,每一次迭代训练的样本数为8。第二步骤训练整个检测网络,初始学习率设置为0.000 1,迭代次数为500,由于实验设备限制,每一次迭代训练的样本数为2。整个过程都采用Adam优化器,权重衰减设置为0.000 5,并且采用余弦学习率调度,其最大迭代次数设置为5,最小学习率设置为0.000 1。此外,在前90%个训练迭代中仅对训练集使用马赛克数据增强。YOLOX-L模型使用SHWD数据集的训练loss曲线如图5所示,可以看到迭代到500左右时,两个loss曲线已经收敛,但是将近700迭代时,验证集loss出现大的震荡,因此选择600迭代附近多个训练loss和验证loss相对最小的迭代周期的保存权重模型进行评估测试,最终选择了第633个周期迭代完成保存的权重作为最终选定的权重文件,该权重文件下的mAP值最大。

(a)整个训练过程的训练集loss曲线
3.3 对比实验
为了证明YOLOX模型在安全帽佩戴检测方面的有效性,这里将其与业界最广泛使用的目标检测算法YOLOv3进行比较,为了保证比较的公平性,在YOLOv3官方模型上采用同该文所使用的YOLOX-L模型近乎一样的训练策略,而且对于YOLOv3模型和对应的SHWD数据集生成新的先验框参数,然后基于各自生成的权重文件获取最好的结果,以准确率、查全率以及mAP等作为指标,结果如表1所示。

表1 实验结果对比
3.4 结果分析
从实验结果可以看出,虽然YOLOv3模型的输入尺寸更大,但是YOLOX-L模型的mAP足足比YOLOv3模型高5.41%,具体来看,虽然YOLOv3模型在类别的准确率方面略微高于YOLOX-L模型,这主要是由于YOLOv3的输入尺寸更大,但是由于YOLOX-L网络模型颈部额外采用了PAN结构更好地融合多特征层以及预测头解耦并采用不依赖锚框的无锚技术来增加网络泛化性,使得YOLOX-L模型的类别查全率远远高于YOLOv3模型。此外,在相同的硬件设备以及batch_size=1的条件下,YOLOX-L模型的FPS仅仅比YOLOv3模型的低2~3帧每秒。由此可见,YOLOX-L能够在更小的输入,更少的参数和计算量以及损失微小的FPS的前提下,兼顾了检测准确率,能够在安全帽佩戴检测方面取得更大的上升空间和应用实践,更好地完成安全帽佩戴检测任务。
另外,为了能够更加直观看到YOLOX算法在安全帽检测方面的优势,选择了一些检测结果,其中图6为YOLOv3算法检测效果,图7为YOLOX-L检测效果。

图6 YOLOv3检测效果

图7 YOLOX-L检测效果
在图6和图7中可以看出,相比于YOLOX-L模型,YOLOv3算法的漏检情况更加严重,尤其是在多目标且存在小目标的场景(b),漏检情况更加突出,而YOLOX-L算法基于PAN+FPN融合特征以及采用无锚加解耦头的检测方法,在保证准确率的同时,检测的目标更加全面,出现的漏检数更少。因此,提出的使用最新的YOLO系列无锚检测器YOLOX-L,针对安全帽佩戴检测问题能够在保证实时检测要求的同时,得到较高的检测准确率。
4 结束语
提出了一种基于最新YOLO检测算法YOLOX中的YOLOX-L模型的安全帽佩戴检测算法。配合2019年开源的安全帽佩戴检测数据集(SHWD)进行训练和测试并与广泛使用的YOLOv3算法进行对比,实验表明,基于YOLOX-L模型的安全帽佩戴检测不仅能够满足实时性要求,且具有更好的检测准确率和查全率。在1 517张测试集上进行评估,达到了94%~95%的准确率,平均检测速度也接近于YOLOv3算法,证明了结合多种最新检测技术的YOLOX-L算法在安全帽检测方面的可行性,为安全帽佩戴检测提供了更加具有上升空间的算法,更能够满足作业环境下的安全帽佩戴检测的各项需求。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
课外生活·趣知识(2019年4期)2019-09-10
科技风(2018年15期)2018-05-14
魅力中国(2016年52期)2017-09-01
中国新通信(2017年9期)2017-05-27
今古传奇·故事版(2017年5期)2017-04-08
安全与健康(2008年11期)2008-12-27
安全与健康(2006年2期)2006-04-21
