
结合注意力机制与LSTM 的短期风电功率预测模型
2022-09-15 06:59:40廖雪超伍杰平陈才圣
计算机工程 2022年9期
廖雪超,伍杰平,陈才圣
(1.武汉科技大学 计算机科学与技术学院,武汉 430065;2.武汉科技大学智能信息处理与实时工业系统重点实验室,武汉 430065)
0 概述
随着全球能源结构的变化,风能在未来能源中的比重逐渐提高[1]。风力发电的快速发展使得电力系统可靠性和安全性面临诸多挑战[2]。由于风速具有间歇性和随机性,因此电力系统的电压和频率波动较大,导致风力发电过程具有不确定性[3]。风电功率预测对于保障电力系统的不间断运行和风能资源的充分利用具有重要意义。风电功率的短期预测方法分为模型驱动、数据驱动、模型与数据集成驱动[4]。
模型驱动基于数值天气预报(Numerical Weather Prediction,NWP)模型,通过计算热力学和计算流体动力学(Computational Fluid Dynamics,CFD)模型的三维空间和时间信息来预测气象变量,并使用适合于给定风电场的风电功率曲线,将气象数据和风力发电机的物理特性数据转换为风电功率[5]。这种模型驱动方法的准确性在很大程度上取决于NWP 模型。NWP 模型需提供气象数据和风力发电机的物理特性数据,但这些数据并不总是可用的。因此,模型驱动方法可能不适用于实际的风电功率预测(Wind Power Forecast,WPF)应用[6]。
数据驱动是通过构建输入变量与风电功率之间的映射关系进行预测。统计模型分为持久性模型[7]、自回归移动平均(ARMA)模型[8]、高斯进程模型[9]、卡尔曼滤波模型[10]等。机器学习模型包括人工神经网络[11]、极限学习机(Extreme Learning Machine,ELM)[12]、支持向量机(Support Vector Machine,SVM)[13]等。随着大数据的发展,多变量时间序列数据呈爆炸式增长,并具有高维度性、时空相关性、动态性、非线性等特征,使得传统统计模型和机器学习模型在处理海量并且复杂的数据时面临诸多困难,而深度学习算法能挖掘更多的深层特征[14]。因此,基于深度学习的预测方法成为研究热点。深度学习模型主要有卷积神经网络(Convolutional Neural Network,CNN)[15]、层叠自编码器[16]、深度信念神经网络[17]、循环神经网络(Recurrent Neural Network,RNN)[18]等。
集成驱动是模型驱动与数据驱动的结合[19],集成了信号预处理技术(如小波变换[20]和经验模态分解(Empirical Mode Decomposition,EMD)[21]、优化算法(如粒子群优化和网格搜索[22])以及预测模型(如ELM、反向传播神经网络和SVM[23])。
本文提出一种结合变分模态分解(Variational Mode Decomposition,VMD)、双阶段注意力机制(DA)、深度学习模型和误差修正(VEC)的风电功率预测模型。利用互信息(Mutual Information,MI)计算多维特征和风电功率之间的互信息量,选择与风电功率相关性较强的特征,利用VMD 对原始特征序列和预测误差序列进行变分模态分解,同时采用基于双阶段注意力机制与编解码架构的长短时记忆(Long Short-Term Memory,LSTM)神经网络模型进行风电功率预测。在此基础上,采用误差分解预处理的误差修正模块修正原始预测结果,以得到最终的预测结果。
1 相关工作
风电功率和风速数据具有随机性强和复杂性大的特点,而信号预处理算法能有效地提取信号特征。研究人员通过结合信号预处理算法和机器学习算法进行风电预测。例如,小波包分解[24]、EMD[25]、完全集合经验模态分解(CEEMD)[26]、集合经验模态分解和自适应小波神经网络(EEMD+AWNN[27]),自适应噪声的完全集合经验模态分解等方法。研究结果表明,与无信号预处理的单一模型相比,结合信号分解与机器学习算法的模型具有更优的稳定性和预测精度,但是传统机器学习算法难以很好地把握时序依赖关系,在较长时间步长情况下性能较差。
深度学习被认为是最强大的表征学习算法,近年来,研究人员将信号预处理与深度学习算法相结合用于风电功率预测。文献[28]提出基于流形算法与径向基函数网络相结合的风速预测模型,文献[29]介绍了基于VMD-奇异谱分析-ELM-LSTM的组合模型。文献[30]使用VMD 分解预处理和LSTM 的风速预测模型,利用VMD 分解得到稳定的风电功率信号,从而提升模型性能。文献[31]结合EMD 分解,使用基于注意力机制的门控循环单元神经网络以降低模型复杂度,从而得到较高的预测精度。
LSTM 在多步预测时存在误差累积的问题,而编解码框架虽然能解决误差累积问题,但是当输入较长的时间步长时预测精度会出现显著的降低[32]。研究人员引入注意力机制提升模型对于时间相关性的选择能力,例如,文献[33]提出使用一种基于注意力机制的编解码模型进行多变量时间序列数据预测。文献[34]提出将LSTM-Attention 与CNN 相结合用于风速的预测。上述注意力机制只考虑时间维度上的相关性,并没有解决在特征维度上不同特征的重要性也不相同的问题。
因此,传统的ARMA 模型难以处理非线性和非平稳性的复杂数据,而单一的SVR、LSTM 模型存在预测滞后的问题,并且在多步预测上存在误差累积问题,编解码模型虽然能较好地解决误差累积问题,但是不能把握输入特征间的长时序相关性,一般的注意力机制只考虑时间相关性,没有考虑特性相关性。
2 相关理论与方法
2.1 互信息特征选择
互信息是用于捕捉每个特征与标签之间的线性或非线性关系的过滤方法[35]。互信息量化通过一个随机变量获得有关另一个随机变量的信息量。对于连续型变量,互信息计算如式(1)所示:
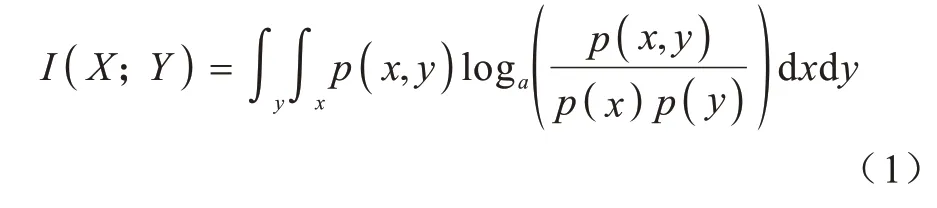
其中:p(x,y)为x与y的联合概率密度函数;p(x)和p(y)为边际密度函数。互信息量可以确定联合分布与分解的边际分布p(x,y)的相关性。文献[36]提出基于K 近邻的无参数方法,将X和Y方向上的欧氏距离最大值作为选择最近邻的标准,并进行统计计数和概率密度估计。
本文提出模型使用MI 分别计算多维特征与风电功率之间的互信息量,排序后选择相关性强的特征用于后续模型的训练和预测。
2.2 变分模态分解
DRAGOMIRETSKIY[37]提出一种VMD 方法。该方法具有计算效率高和鲁棒性优的特点,以解决模态混合问题。通过应用VMD 将信号x(t)分解为K个子序列或者模态分量uk(k=1,2,…,k),并且每个模态分量的带宽估计之和被最小化。VMD 算法分为构造和求解变分,主要有以下3 个步骤:1)通过对每个模态函数uk进行希尔伯特变换得到相应的频谱;2)通过指数混合调制算法将uk的频谱移动到各自的估计中心频率ωk;3)使用信号的高斯平滑度和梯度平方准则来解调和估计uk的带宽。
带约束的变分问题计算如式(2)所示:
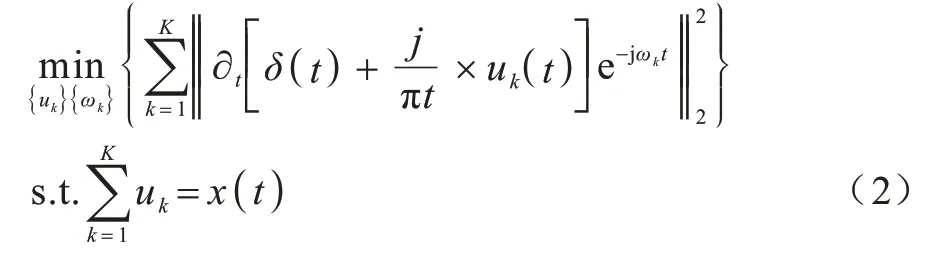
本文提出模型采用VMD 算法选择MI 特征后,并对选取的前3 维特征进行分解,得到具有一定中心频率的模态分量。
2.3 长短时记忆神经网络
RNN 在反向传播过程中存在梯度消失和梯度爆炸问题,使其难以连续优化网络参数[38]。LSTM[39]能够有效地解决这个问题。LSTM单元结构如图1所示。
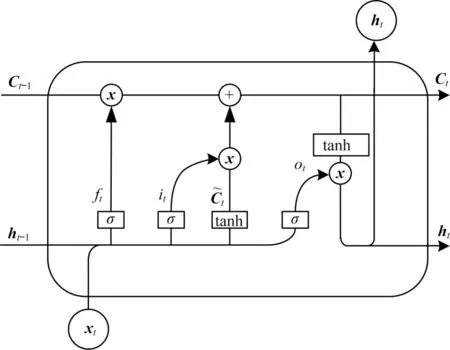
图1 LSTM 单元结构Fig.1 Unit structure of LSTM
LSTM 存储单元由遗忘门、输入门和输出门3 个激活门结构控制,以便有效地存储和更新单元信息。
1)遗忘门,在单元信息更新中控制上一单元Ct-1信息被遗忘。遗忘门的计算如式(3)所示:

2)输入门,控制信息被输入到本单元中。输入门的计算如式(4)和式(5)所示:
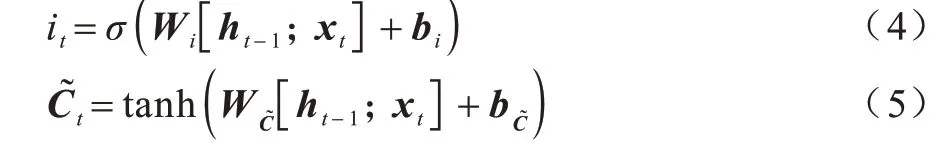
3)单元信息更新,通过遗忘门和输入门有选择地更新Ct。单元信息更新过程如式(6)所示:

4)输出门,将Ct激活,并控制Ct的过滤程度。输出门的计算如式(7)和式(8)所示:
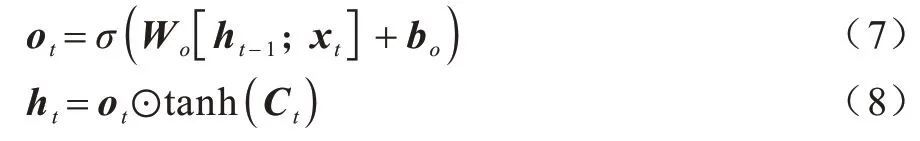
其中:W*为权重矩阵;b*为偏置项;⊙表示矩阵元素乘积;σ为sigmoid 激活函数;tanh 为双曲正切激活函数。激活函数的定义如式(9)和式(10)所示:

输出层依据式(11)得到最终预测值:

3 系统模型设计
3.1 符号描述与问题建模
对于给定的n维特征风电功率时间序列,例如X=(X1,X2,…,Xn)T=(X1,X2,…,XT) ∈Rn×T,其中,T为观测时间序列的窗口长度。本文使用Xk=表示第k维特征序列,Xt=表示第t时刻的n维特征序列。
对于风电功率预测问题,本文给定观测序列历史值(X1,X2,…,XT-1),其中Xt∈Rn,其目标是确定观测特征变量与目标预测变量yT之间的非线性映射关系,即找到一个非线性映射函数F(·),使得yT=F(X1,X2,…,XT-1)。
3.2 双阶段注意力机制
受人类注意力机制理论的启发,在第一阶段选择基本刺激特征,在第二阶段使用分类信息来解码刺激[40]。本文在模型编码层通过注意力机制输入特征,使得该编码器能够自适应地关注相关特征,同时在解码层注意力机制捕获长时间依赖关系,从而获取更加丰富的全局上下文信息。
传统的编解码模型对于编码层的所有输入特征都具有相同的权重,说明在编码阶段未利用特征之间的关系。同时,在解码层不同时刻的输入会产生相同的上下文向量。因此,传统的编解码模型不能关注时序上的重要时刻特征,当时序较长时,通常会导致模型预测性能降低。
在编解码器中使用的注意力机制仅对解码层不同时刻的输入参数产生不同的上下文向量,因此,忽略了不同特征与目标预测变量之间的相关性。
本文提出基于双阶段注意力机制编解码模型(DA-EDLSTM)的风电功率预测方法。DA-EDLSTM模型结构如图2 所示。在编码层和解码层上引入注意力机制,在空间和时间两个维度上获取上下文依赖关系,从而在把握长期时序依赖关系的同时实现对重要特征因子的选择。
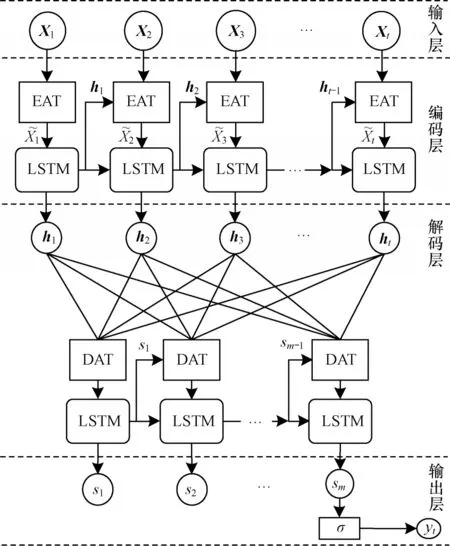
图2 DA-EDLSTM 模型结构Fig.2 Structure of DA-EDLSTM model
3.2.1 基于注意力机制的编码层
基于特征注意力机制的编码层结构如图3 所示。
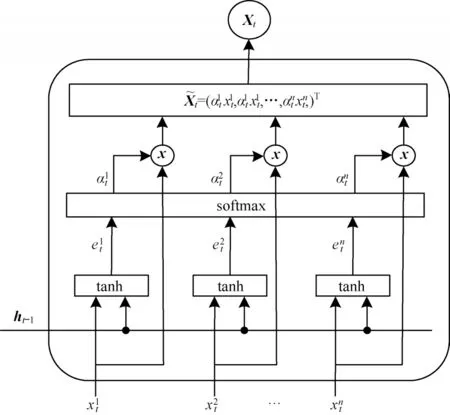
图3 基于特征注意力机制的编码层结构Fig.3 Structure of encoder layer based on feature attention mechanism
对于输入观测序列X中的第k维特征序列Xk,根据上一时刻编码器的隐藏状态ht-1和单元状态st-1构造注意力机制,如式(12)和式(13)所示:
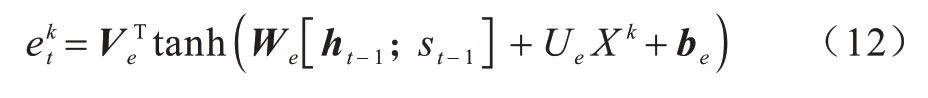

其中:Ve,be∈RT,We∈RT×2m和Ue∈RT×T为模型需要学习的参数;ht-1∈Rm和st-1∈Rm为编码层的隐藏状态和单元状态;m为隐藏层的大小。通过这种方式,当前馈神经网络训练完成后,在LSTM 获取长时序相关性的同时得到重要程度不同的特征信息,重要程度表现在每个特征训练后得到的权重Ue不同。由于在注意力机制中输入上一时刻的隐藏状态ht-1和单元状态st-1,因此特征信息具有时序依赖性。当得到之后,通过softmax 函数将其归一化,使得注意力权重之和为1。每个时刻的输入Xt为其中每个影响因子赋予一定的注意力权重可以衡量时刻t的第k维特征的重要性。由于每个时刻的每个特征都有其对应的权重,因此在第一阶段注意力加权后的输出如式(14)所示:
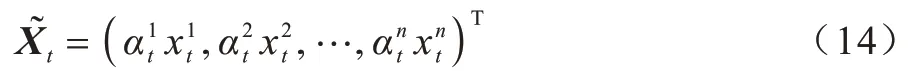
本文使用代替Xt,并将其输入到编码层中,如式(15)所示:

其中:f1为LSTM 神经网络,通过输入注意力机制,编码层可以关注重要的特征因子而不是平等对待所有特征属性。
3.2.2 基于注意力机制的解码层
在传统编解码模型的结构中,编码层输出的所有时刻都具有相同的上下文向量,然而,并不是每个时刻的输入序列Xt和编码层的隐藏状态ht对上下文向量都具有相同的贡献。因此,传统的编解码模型忽略了输入特征在时序上的重要性差别。因此,采用时间注意力机制选择性地关注相关的输入序列。基于时间注意力机制的解码层结构如图4 所示。

图4 基于时间注意力机制的解码层结构Fig.4 Structure of decoder layer based on time attention mechanism
注意力权重向量ei表示未归一化的输入重要性。注意力权重向量ei的计算如式(16)所示:

其中:Wd表示模型学习的权重参数。模型经过训练后,得到表示隐藏状态重要性的ei,通过式(17)进行归一化,得到各个时刻输入序列的关注概率βi,βi表示在不同时刻产生上下文的重要程度:

解码层在t时刻计算上下文向量中的加权求和,并对不同时刻隐藏状态分配权重大小,得到最终进入LSTM 门控单元的向量xt1,如式(18)所示:

该向量表示不同时刻的编码输入变量在预测输出时的重要性。在解码结构中基于时间注意力机制,学习不同时刻隐藏状态间的内在时间相关性,利用注意力机制对加权得到的信息进行预测。此外,注意力机制为前馈神经网络,可以与模型整体一起进行参数学习。
3.3 模型架构
本文提出MI-VMD-DA-EDLSTM-VEC 的新型组合模型来进行风电短期预测,模型整体架构如图5所示。

图5 本文模型的整体架构Fig.5 Overall architecture of the proposed model
MI-VMD-DA-EDLSTM-VEC 的新型组合模型主要包括以下4 个部分:
1)MI 特征选择:通过计算原始6 维特征与目标序列的互信息,并进行互信息量排序,以选择互信息量较大特征,从而降低相关性弱的冗余特征对预测精度的影响。
2)VMD 分解:为了得到较强的平稳性,并且在不同频域上均匀分布的特征序列,分别对风电功率、风速和空气温度序列进行VMD 分解。
3)DA-EDLSTM 模型训练:为了同时把握时序相关性与特征相关性,通过双阶段注意力机制的编解码LSTM 模型对VMD 分解得到的模态分量(IMFs)进行训练和预测,得到初始预测序列,通过得到原始预测误差e(t)。
4)误差修正:由于误差序列具有波动性较强且平稳性弱的特点,因此对e(t)进行VMD 分解预处理,使用单层LSTM 模型进行再训练预测,得到误差预测序列,并对原始预测结果进行修正,得到最终预测结果
本文提出的模型首先对原始数据进行MI 选择,以选择出与风电功率相关性强的特征;其次对相关特征进行VMD 分解,以降低各个特征序列的复杂性和非平稳性,使用新型的基于双阶段注意力机制和编解码神经网络的模型进行预测;最后对模型预测误差进行VMD 分解和误差修正,从而进一步提高模型的预测精度。
4 实验与结果分析
4.1 数据集
本文实验使用的数据集为美国国家可再生能源实验室(NREL)提供的观测站站点数据,原始数据集时间跨度为2013 年全年,包含风电功率、风向、风速、空气温度、气压和密度6 个维度特征,每5 min 采样一次。观测站点的地理位置如图6 所示。
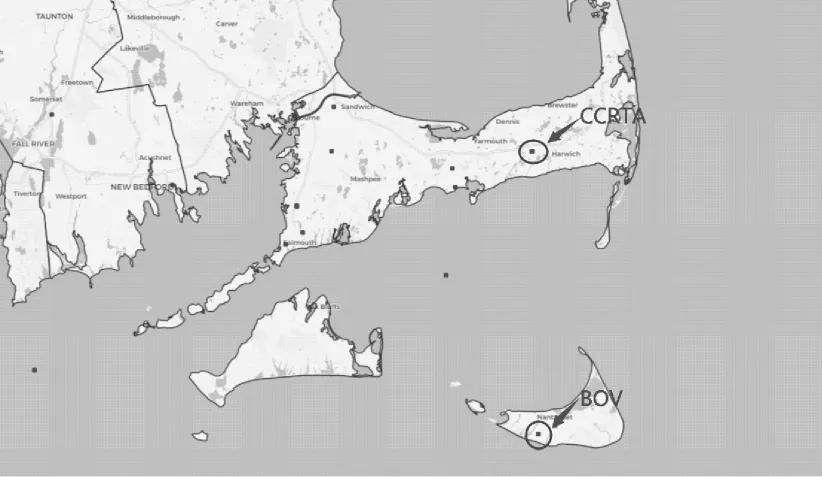
图6 观测站点位置信息Fig.6 Location information of observation station
实验数据集取自马萨诸塞州南塔基特岛西部的巴特利特的海景风电场(BOV)以及巴恩斯特布尔的丹尼斯的CCRTA 站点。
BOV 站点风电功率随时间的变化曲线如图7 所示。从图7 可以看出,风电功率变化幅度较大,风电功率中不同频率的信号相互干扰,受噪声影响较严重。由于BOV 站点风电场风电时间序列的变化幅度和波动频率的特点,因此选择该风电场数据来验证本文模型的有效性。
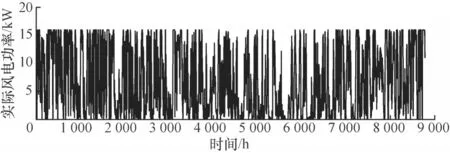
图7 在BOV 站点上风电功率随时间的变化曲线Fig.7 Change curves of wind power with time at BOV station
从2013 年1 月 到2013 年12 月,NREL 提供每5 min 采样一次的数据集,本文对1 h 内12 个采样点进行平均值重采样,以获得每小时的数据。实验评估中使用训练集、验证集和测试集3 个数据子集,根据固定比例7∶1∶2 进行划分。本文实验共有8 760 h的数据样本,其中6 132 个样本作为训练集,876 个样本作为验证集,1 752 个样本用于测试。
4.2 评价指标
本文使用3 个评价指标来评估预测模型的性能。评价指标分别为平均绝对误差(MMAE)、根均方误差(RRMSE)和对称平均绝对百分比误差(SSMAPE)。RRMSE是在预测定量数据时测量模型误差的标准指标。SSMAPE是基于百分比误差的准确性度量。3 个评价指标的计算如式(19)~式(21)所示:
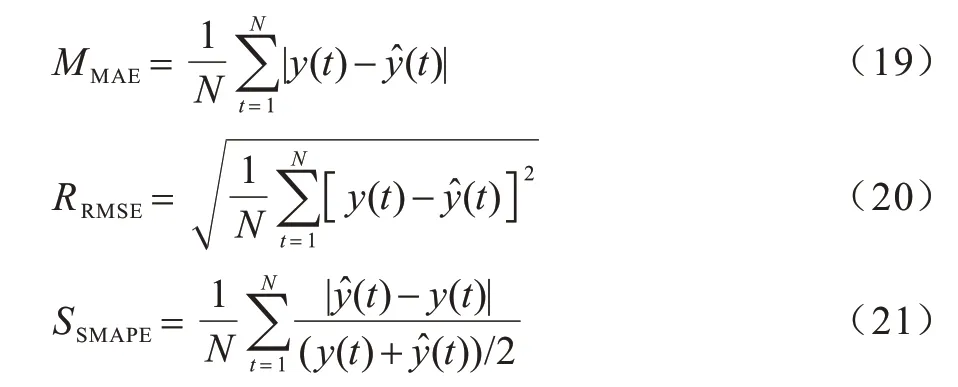
其中:y(t)为时间t的实际风电值;为时间t的预测风电值;N为测试集的数据样本数。
4.3 实验基准模型
为验证本文VMD-DA-EDLSTM-VEC 组合模型的预测效果,本文选择基准模型用于实验对比,基准模型的描述如表1 所示。单一模型的参数设置如表2 所示。

表1 基准模型描述Table 1 Description of benchmark models

表2 单一模型的主要参数设置Table 2 The main parameters setting of single model
4.4 数据预处理
为确定时间序列预测模型的最佳阶数,本文分析时间序列数据的自相关性。风电功率的自相关系数和偏自相关系数随时间的变化曲线如图8 所示,自相关系数图的特征是拖尾,而偏自相关系数图是截尾。因此,该风电功率信号满足自回归(Auto Regressive,AR)模型的特性,从图8(a)可以看出,数据在滞后30 步左右完全进入置信区间中,因此时序预测模型的最佳阶数p初步确定为30。
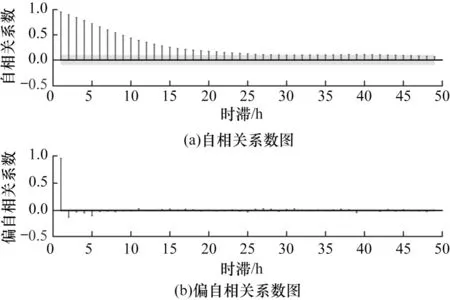
图8 风电功率的自相关系数与偏自相关系数随时间的变化曲线Fig.8 Change curves of autocorrelation coefficient and partial autocorrelation coefficient of wind power with time
由于原始数据为6 维,包含风电功率、风向、风速、空气温度、气压和密度,为了消除或者减弱冗余特性以及不相关特性带来的噪声对模型预测结果的影响,本文使用MI 作为特征选择方法进行特征选择,选择与PW 相关性较强的特征作为主要特征进行模型预测。通过互信息计算的每个特征维度的互信息量排序如图9 所示。
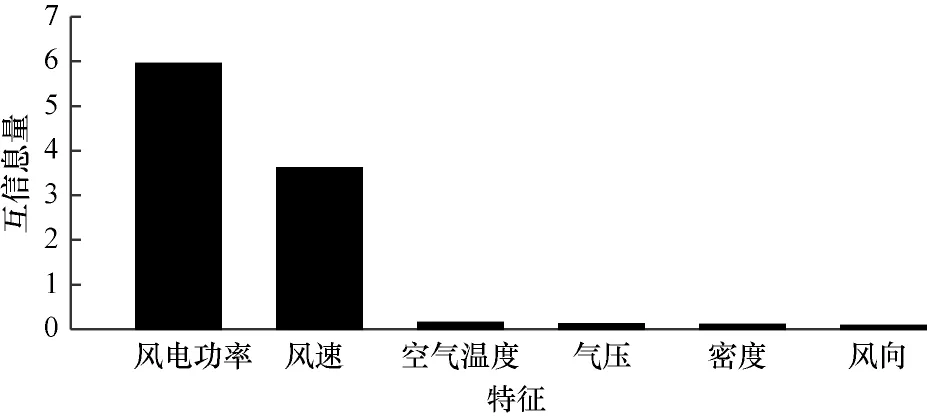
图9 不同特征的互信息量排序Fig.9 Mutual information ranking among different features
从图9 可以看出,风电功率、风速和空气温度为前3 维主要相关特征,相关性较强的是风电功率和风速,互信息量分别为5.9 和3.5,而其他4 维特征相关性较弱,互信息量小于0.3。实验选择相关性排序前3 位的特征序列:风电功率、风速和空气温度。后续模型根据这3 维特征数据进行信号分解、模型训练和预测。
为验证MI 特征选择的效果,不同维度特征使用单一LSTM 模型进行预测的结果如图10 所示。从图10 可以看出,MI 选择3 维特征序列的预测结果优于6 维特征序列的结果,但是仍然较1 维特征序列的预测结果差,这是由于加入的风速信号具有不平稳性和复杂性,导致模型的精度下降,后续采用VMD算法将信号分解为不同频率的平稳分量,从而提高模型精度。

图10 采用不同维度特征序列预测风电功率的对比分析Fig.10 Comparative analysis of prediction wind power using different dimensional features sequence
4.5 特征提取
本文分别使用VMD 算法将风电功率、风速、空气温度数据分解为20、10 和1 个IMFs,使各个特征分解为在不同频域上均匀分布的分量。风电功率、风速的VMD 分解结果如图11 所示,VMD 分解能够充分地提取信号在频域上的特征。

图11 风电功率与风速序列VMD 分解结果Fig.11 VMD decomposition results of wind power and wind speed series
风电功率和风速模态分量的分解层数通过参数寻优实验获得:p为20,s为10,t为1;风电功率IMFs[IMF1,IMF2,…,IMFp];风速IMFs[IMF1,IMF2,…,IMFs];空气温度IMFs[IFM1,IMF2,…,IMFt]。
在BOV 和CCRTA 站点上不同模型的评价指标对比如表3 所示。在BOV 站点上VMD-LSTM 模型的预测结果RMSE 和MAE 分别为1.117 kW 和0.799 kW,与3 维特征序列直接使用LSTM 模型预测的RMSE相比,VMD-LSTM 模型的RMSE指标明显降低。

表3 不同模型的评价指标对比Table 3 Evaluation indexs comparison among different models kW
VMD-EDLSTM的预测指标MAE 和RMSE 分别为0.266 和0.568,比使用单层LSTM 的VMDLSTM 提高了5.33 和5.49 个百分点。在解码层基于注意力机制的VMD-AT-EDLSTM 模型利用不同上下文向量关注重要时刻的隐藏状态,因此,相比VMD-EDLSTM 模型的RMSE 和MAE 分别提升了3.4 和4.9 个百分点,具有更优的预测精度。在VMD-AT-EDLSTM 模型的基础上,VMD-DAEDLSTM 模型在编码层的输入阶段运用注意力机制,使模型不仅能把握长期时序依赖关系和关注重要时刻,而且实现重要特征因子的选取。VMDDA-EDLSTM 模型预测指标MAE 和RMSE 分别为0.218 和0.381,具有最优的预测性能,相比VMDEDLSTM 模型降低了4.8 和18.7 个百分点,相比VMD-AT-EDLSTM 模型降低了1.4和13.8个百分点。
双阶段注意力机制的注意力权重分布如图12所示。在第一阶段的注意力机制中,注意力机制被用于选择关键的IMFs分量,风电功率、风速和空气温度的IMFs数量分别是20、10、1。从图12(a)可以看出,模型主要关注每组IMFs分量中的低频趋势分量,在图中分别为第1、21、31 号输入特征,说明模型充分提取了特征序列中的主要趋势信息。在第二阶段的注意力机制中,模型主要关注关键时间步的隐藏状态,从图12(b)可以看出,在第24 步时拥有最大的注意力权重,并且靠后的时间步拥有较大的权重,说明在第二阶段的解码层注意力机制可以选择长时间相关性中的关键信息,并且该信息在靠后时刻。以上两个结论都符合客观事实,即主要趋势分量和靠后时间步的特征对预测结果影响更大。
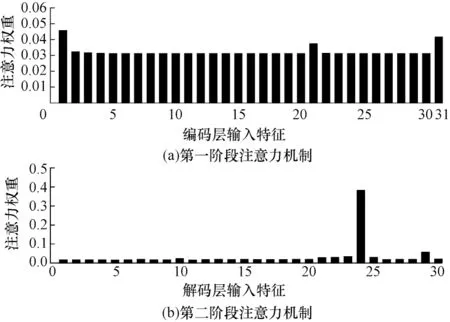
图12 注意力权重分布Fig.12 Weight distribution of attention
4.6 模型实验对比
在CCRTA 站点上不同模型的预测结果如图13所示。以CCRTA 站点的结果为例,从图13 可以看出,VMD-LSTM 的预测结果优于统计模型ARMA 和机器学习模型SVR。在图13 的散点图中VMD 分解后的预测结果比使用LSTM 直接进行预测的结果更接近基准线,说明VMD 分解后进行预测有较高的精度。
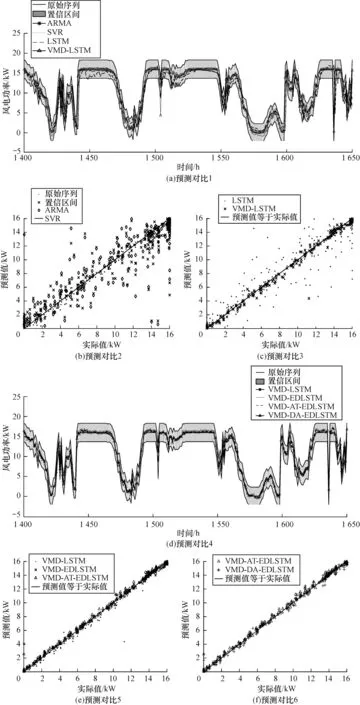
图13 在CCRTA 站点不同模型的预测结果Fig.13 Prediction results of different models at CCRTA site
在BOV 和CCRTA 站点上不同模型的误差值对比如图14 所示,本文提出的VMD-DA-EDLSTMVEC 组合模型在BOV 站点和CCRTA 站点上都具有最优的预测误差指标。
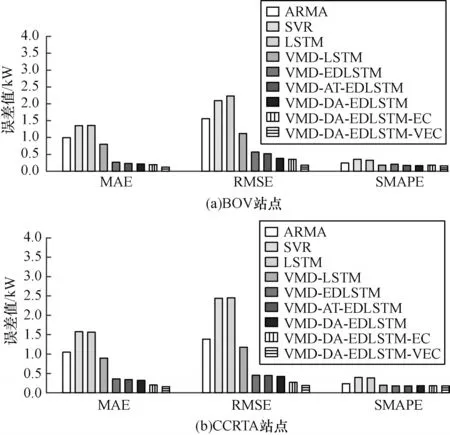
图14 不同模型的误差值对比Fig.14 Errors values comparison among different models
4.7 误差修正
为验证误差修正模块的效果,本文在双阶段注意力机制的编解码模型基础上,加入了误差修正模块,以原始预测误差作为数据样本,使用单层LSTM模型预测误差,并通过误差预测序列对原始预测误差进行修正。本文考虑到预测误差具有不平稳性和波动性较强的特点,使用VMD 分解对预测误差序列进行预处理。实验结果表明,基于VMD 分解预处理的误差修正模块能有效提高模型的预测精度。在BOV 和CCRTA 站点上引入误差修正模块的预测结果如图15 所示。
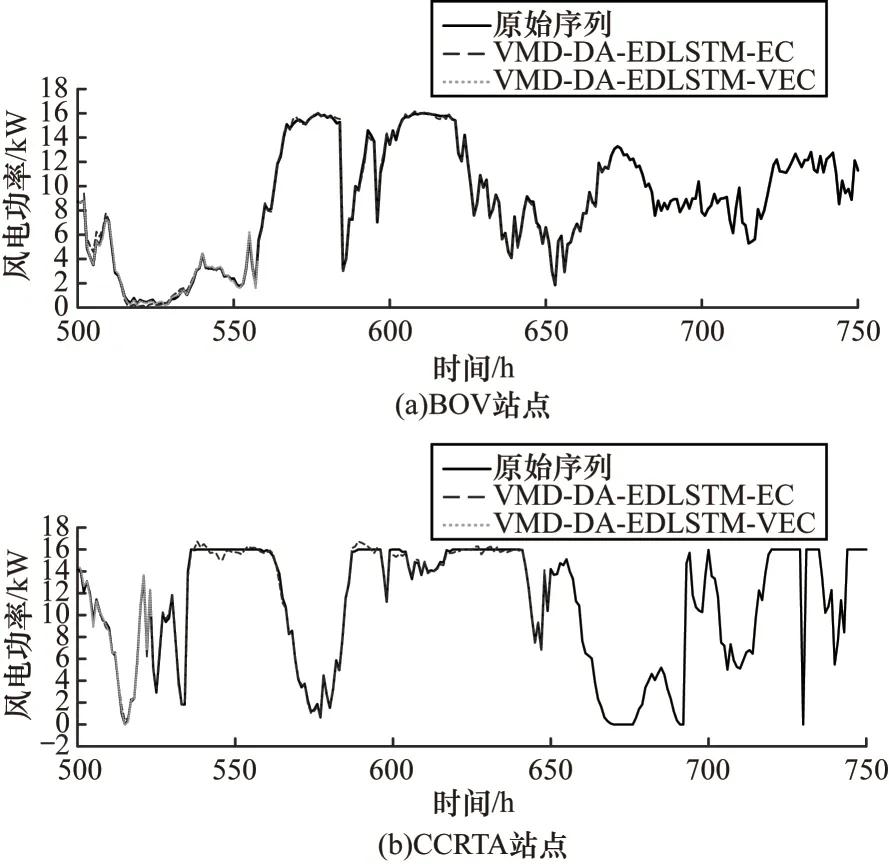
图15 不同模型引入误差修正模块的预测结果对比Fig.15 Prediction results of introducing error correction module into different models
在两个站点上,引入误差修正模块的模型得到的预测曲线更趋近于实际值。从表3 可以看出,VMD-DA-EDLSTM-VEC 模型的性能指标RMSE 和MAE 达到了0.179 和0.121,对比 未使用VMD 分解预处理的VMD-DA-EDLSTM-EC 分别提高了17.5和7.6 个百分点,在VMD-DA-EDLSTM 模型的基础上提高了20.2 和9.7 个百分点。
4.8 模型参数寻优
不同的VMD 分解层数K会影响IMFs在频域上的分布情况[37],进而影响模型的预测结果。不同的滞后时间步长同样也影响模型的预测精度。本文使用VMD-DA-EDLSTM 模型确定自相关阶数p和特征分解层数K。在不同自相关阶数和分解层数下,本文模型的预测结果对比如图16 所示。
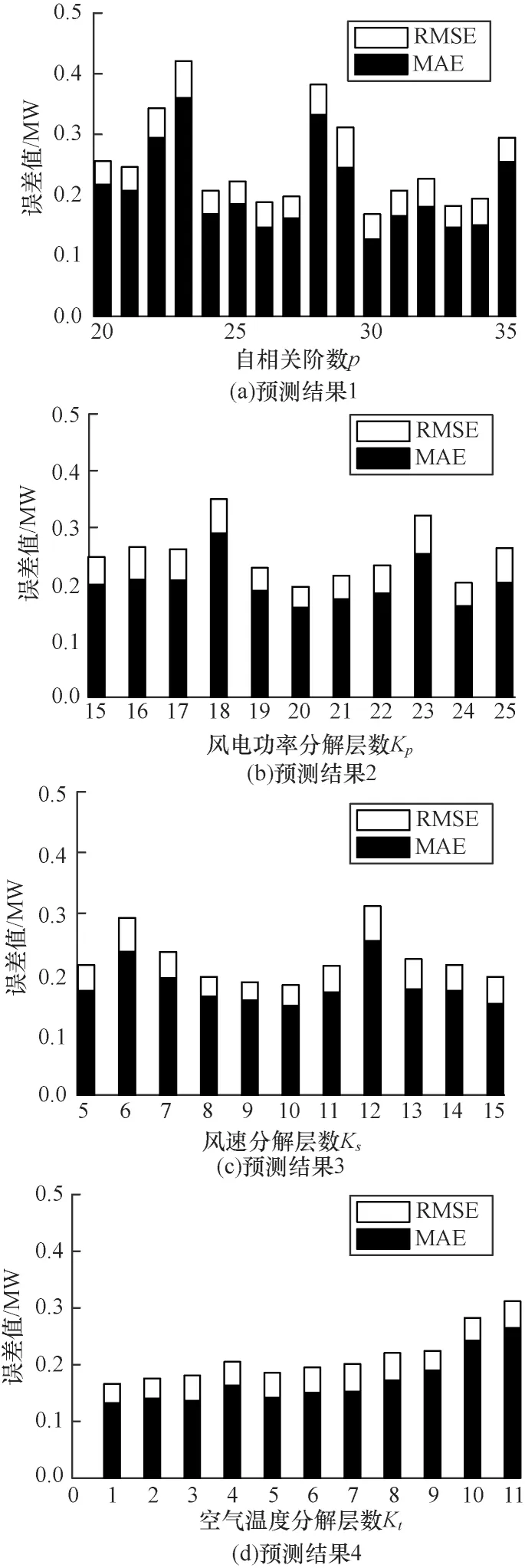
图16 在不同自相关阶数和分解层数下本文模型的预测结果对比Fig.16 Prediction results comparison of the proposed model under different autocorrelation orders and decomposition levels
自相关阶段p和特征分解层数K确定取值:
1)自相关阶数p,在确定了K值的基础上寻找p值,从图8 可以看出,自相关阶数从30 左右完全进入置信区间;从图16(a)可以看出,当自相关阶数p为30 时具有相对最小的RMSE 和MAE 误差,与偏自相关系数图得出的结果一致。
2)特征分解层数K,假设p=30,贪心算法寻找风电功率、风速和空气温度的分解层数Kp、Ks、Kt,在Kp为15~25 范围内寻找误差相对较低的Kp,在此基础上确定Ks,进一步确定Kt取值。如图16(b)、图16(c)和图16(d)所示,当Kp、Ks、Kt取值分别为20、10、1时,误差最小。
4.9 预测精度与稳定性分析
本文利用VMD-LSTM、VMD-EDLSTM、VMD-ATEDLSTM、VMD-DA-EDLSTM、VMD-DA-EDLSTMVEC 这5 种模型在BOV 站点上分别进行20 组预测实验,并对实验结果的误差指标MAE、RMSE 进行对比,结果如图17 所示。
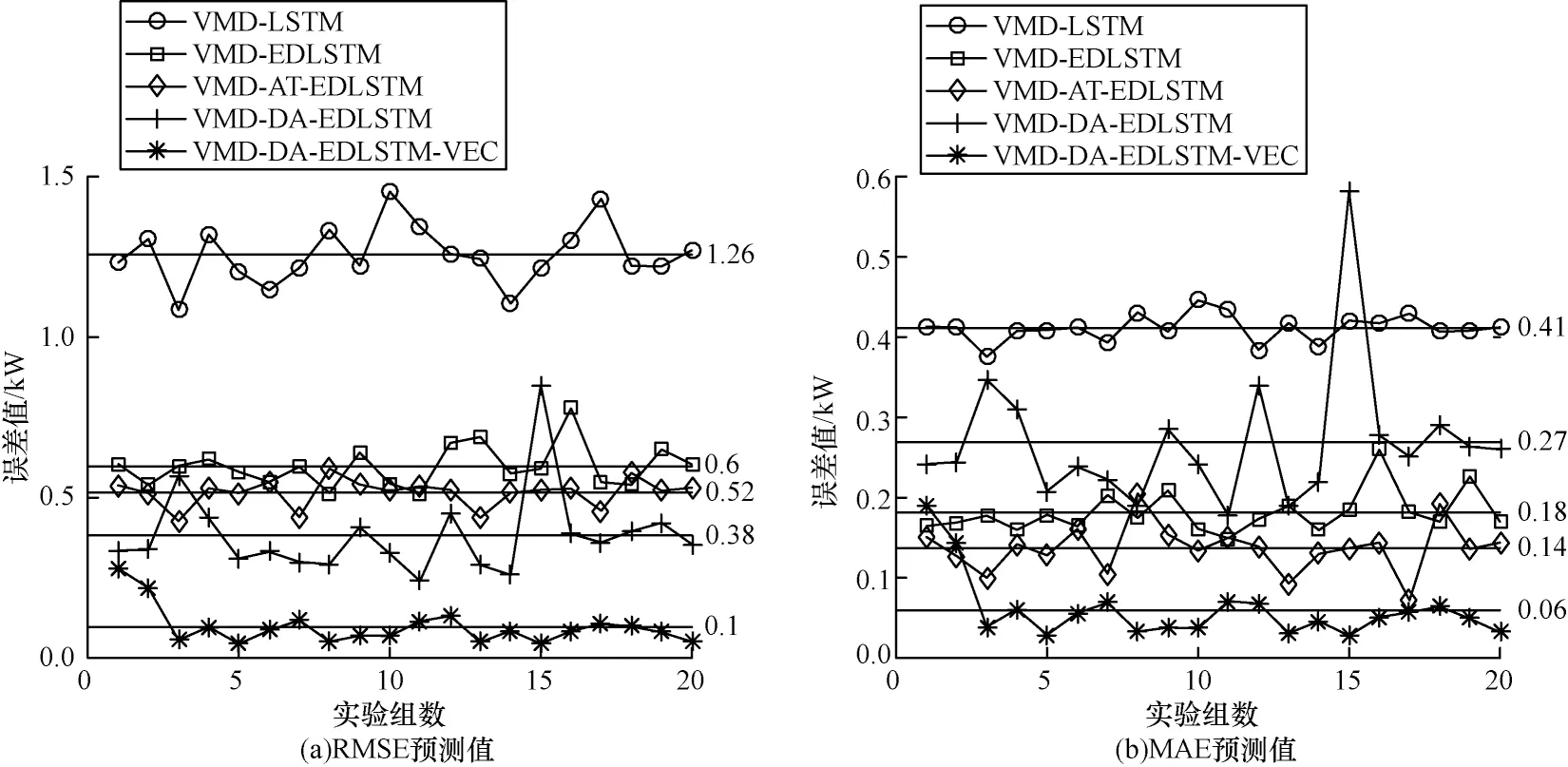
图17 不同模型的预测值对比Fig.17 Prediction values comparison among different models
从图17 可以看出,增加解码层注意力机制的VMD-AT-EDLSTM 的平均预测误差MAE 为0.14,RMSE 为0.52,普遍优于VMD-LSTM 和VMDEDLSTM,而增加编码层注意力机制的VMD-DAEDLSTM 的平均误差MAE 为0.27,RMSE 为0.38,优于单注意力机制模型,使用误差修正模块后模型的预测误差降低到MAE 为0.06,RMSE 为0.17,同时模型性能也更加稳定。
综合上述对比实验数据,本文得到如下结论:
1)常规预测模型:ARMA 模型能够预测风电功率的主要趋势,但是在出现突发峰值时准确度较低;而SVR 和LSTM 单个模型在预测风电功率时存在滞后现象,难以准确地预测下一时刻风电功率。
2)互信息特征选择的作用:对于多维特征时间序列,通过互信息选择与目标序列相关性较强的特征序列,从而减弱冗余特征和不相关特征对预测模型产生的干扰。
3)信号分解的作用:从图12 可以看出,VMD 分解可以提取复杂性强、不平稳信号的不同频域特征,解决LSTM 模型存在预测滞后的问题,提高模型的预测精度。
4)VMD-DA-EDLSTM 模型:提升模型在风电等数据急剧变化时的决策能力;能更加准确地预测风电功率出现峰值或低谷的情况;用于编码层输入和解码层隐藏状态的双阶段注意力机制,以选择关键信息,通过第一阶段注意力关注重要的特征维度,同时第二阶段注意力关注长期时序中的重要时刻,从而把握长期时序依赖关系;选取重要特征因子,解决编解码模型随着输入序列长度增加时性能变差的问题,进一步提高模型性能。
5)误差修正模块的效果:使用信号预处理的误差修正机制能够进一步提高预测精度,VMD 算法解决了误差序列存在不平稳、复杂性强等问题,实现了对误差序列很好的特征提取,从而进一步提高模型的预测性能。
5 结束语
本文提出一种由信号分解、双阶段注意力机制、误差修正策略和深度学习算法组合的新型短期风电功率预测模型。通过互信息计算多维特征序列与风电功率之间的互信息量,排序后选择相关特征用于后续模型训练与预测,利用变分模态分解对多维特征序列进行分解。在此基础上,采用基于双阶段注意力机制、编解码架构的长短时记忆神经网络模型和误差修正模块进行风电功率预测,得到最终预测结果。实验结果表明,本文提出组合模型具有较优的预测精度和较强的预测稳定性,为利用深度学习探索时间序列的预测分析提供研究思路。后续将结合编解码模型的多步预测优势进行多步风电功率的预测,进一步提高风能的利用效率。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14 03:36:50
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中学生数理化·中考版(2020年12期)2021-01-18 06:59:44
中学生数理化·中考版(2020年12期)2021-01-18 06:59:42
哈尔滨轴承(2020年2期)2020-11-06 09:22:26
今日中国·法文版(2020年7期)2020-07-04 02:53:48
中国特种设备安全(2019年1期)2019-03-13 01:06:26
中学生数理化·中考版(2018年12期)2019-01-31 06:19:00
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
