
多特征融合的端到端链式行人多目标跟踪网络
2022-09-15 06:59:44周海赟项学智王馨遥任文凯
计算机工程 2022年9期
周海赟,项学智,王馨遥,任文凯
(1.南京森林警察学院 治安学院,南京 210023;2.哈尔滨工程大学 信息与通信工程学院,哈尔滨 150001)
0 概述
多目标跟踪是指在视频中持续对目标进行准确定位,在场景发生变化时仍能维持目标身份信息不变,最后输出目标完整运动轨迹的技术。在复杂场景中,跟踪目标数目不定、目标之间存在频繁的遮挡以及交互、目标之间包含相似的外观特性等因素都会给多目标跟踪的实现带来挑战。由于行人是非刚体目标,且现有数据集中包含大量行人的视频,因此当前多目标跟踪中行人跟踪的算法占多数[1]。行人多目标跟踪主要分为离线跟踪与在线跟踪。在线跟踪只能使用当前帧及之前的信息来进行跟踪,而离线跟踪对每一帧的预测都可以使用整个视频帧的信息,因此离线跟踪可以看成是一个全局优化的问题,常见解决方法是基于图论的方式,将多目标跟踪建模为网络最大流问题[2]或距离最小成本问题[3]。由于离线跟踪的全局优化方式增加了对算力的要求,且离线跟踪不能应用于对跟踪实时性有要求的场景,因此本文主要研究行人多目标在线跟踪。
传统多目标跟踪网络主要通过滤波算法来预测目标在下一帧的位置进行目标跟踪,卡尔曼滤波器利用连续帧中相同目标的速度及协方差相关性最大原理进行目标状态的预测与更新[4]。使用核相关算法训练相关滤波器,并通过计算目标相关性获得置信图来预测跟踪结果[5]。当前多目标跟踪网络主要采用基于检测的跟踪方法,即先对视频中每一帧的目标进行目标检测,之后利用各种数据关联算法将检测结果与跟踪轨迹进行匹配,从而进行轨迹更新。
近年来,越来越多的研究人员致力于基于深度学习的多目标跟踪网络的研究。BEWLEY 等[6]提出Sort 网络,检测部分采用Faster R-CNN 网络,利用卡尔曼滤波预测结果与检测结果之间的交并比(Intersection over Union,IoU)进行匈牙利匹配来完成数据关联。由于Sort 仅使用IoU 进行数据关联,导致在人流较密集的场景下会产生大量的身份切换。因 此,WOJKE 等[7]提 出Deepsort,在Sort 网 络IoU 匹配的基础上增加级联匹配,并使用一个行人重识别(Person Re-identification,ReID)网络提取目标的外观特征辅助数据关联,有效解决身份切换问题。BAE 等[8]也利用预训练的ReID 网络提取可区分的行人特征,并将轨迹分为可靠轨迹与不可靠轨迹,再与检测结果进行分级关联。上述这些研究仅根据检测结果进行轨迹更新,受检测器性能的影响很大,当出现不可靠的检测时,跟踪性能也会下降。因此,CHEN 等[9]将检测框与跟踪的预测框同时作为轨迹更新的候选框,设计一种评分函数统一衡量所有的候选框,再利用空间信息和ReID 特征进行数据关联。尽管这些基于检测进行跟踪的网络取得了良好的效果,但这些网络的检测部分与跟踪部分是完全独立的,这直接增加了跟踪的复杂性,不利于满足实时性的要求。为解决该问题,BERGMANN 等[10]提出Tracktor++,利用检测器的边界框回归思想直接预测目标在下一帧中的位置,完成检测与跟踪的联合,并融入运动模型与ReID 网络,以减少帧间身份切换。ZHOU 等[11]在CenterNet 检测器的基础上输出当前帧中目标的尺寸、目标中心点的热力图及相较于上一帧的偏移量,依靠贪婪匹配实现数据关联。WANG 等[12]提出JDE 网络,将ReID 网络与检测网络整合到一个网络中,使网络同时输出检测结果和相应的外观嵌入,再根据目标的外观信息与运动信息进行数据关联。ZHAN 等[13]提出FairMOT 网络,网络中包含检测与ReID 两个同质分支,使用编解码架构提取网络的多层融合特征,提高网络对物体尺度变换的适应能力。尽管上述方法进一步改善了目标跟踪的性能,但上述方法不使用端到端的网络,文献[10-11]在一个网络中联合学习检测与跟踪,文献[12-13]将检测与ReID 网络集成到一起,这些方法中的数据关联过程仍被视为后处理部分,是一种部分端到端的网络,仍然无法做到全局优化,需要复杂的数据关联机制来处理不同模块的特征,不利于满足在线跟踪的实时性要求。
本文基于链式结构[14]提出一种多特征融合的端到端链式行人多目标跟踪网络,利用链式特性降低数据关联的复杂性。在链式结构中引入双向金字塔,在传统特征金字塔的基础上增加一条聚合路径以获得更深入的融合特征。为适应目标形状和尺度的改变,在双向金字塔中采用具有采样特征加权的改进可变形卷积。使用联合注意力提高目标框的准确性,重点突出2 帧图片中属于同一目标的区域[14]。最后,设计多任务学习损失函数,优化成对目标边界框回归的准确性,提升整体跟踪的性能。
1 多特征融合的链式跟踪网络
1.1 本文网络架构
本文基于链式网络结构提出多特征融合的跟踪网络,将目标检测、特征提取和数据关联融入到一个统一的框架中。与其他网络不同,常见的在线多目标跟踪逐帧进行检测与数据关联,网络的输入仅为单个帧,本文将相邻的两帧组成链节点作为网络的输入,完成链式跟踪,链式跟踪的整体流程如图1 所示。给定一个共有N帧的图像序列,Ft表示第t帧的图像,每一个链节点由相邻两帧图像组成,第1 个链节点为(F1,F2),第N个节点为(FN,FN+1),由于图像序列最多只有N帧,将FN+1用FN表示,即将第N个节点改写为(FN,FN)。将节点(Ft-1,Ft)输入到网络中,网络会输出2 帧中属于相同目标的成对边界框,其中nt-1表示相同目标对的数量,分别表示节点内Ft-1与Ft中相同目标的两个边界框。同理,下一个节点经过网络的输出表示相邻节点的公共帧中相同目标的边界框,本质上它们来自同一帧图像,理论上仅存在微小的差异,故不需要复杂的数据关联机制。计算之间的帧间交并比以获取亲和力矩阵,从而链接2 个相邻的节点。应用匈牙利算法完成中相同目标检测框的最优匹配任务,对于成功匹配上的边界框对应用所在的轨迹进行更新。针对目标消失的情况,若目标出现在Ft-1帧而在Ft帧消失,节点(Ft-1,Ft)与(Ft,Ft+1)均不会检测到该目标,因此可以认为该目标在Ft-1帧甚至是Ft-2帧就已消失,避免误检噪声引起的跟踪器的漂移现象。针对目标可能连续几帧消失在可视范围内导致检测失败的情况,保留消失目标的轨迹和身份σ帧,在这期间利用物体的匀速运动模型进行运动估计,持续预测目标位置并与当前检测结果不断进行匹配,尝试把丢失的目标重新链接至轨迹中,保证在强遮挡情况下目标仍可以被有效跟踪,减少身份切换的现象发生。若在σ帧之后仍没有匹配成功,则认为该目标离开了场景,此时将该目标的相关轨迹以及身份信息删除。
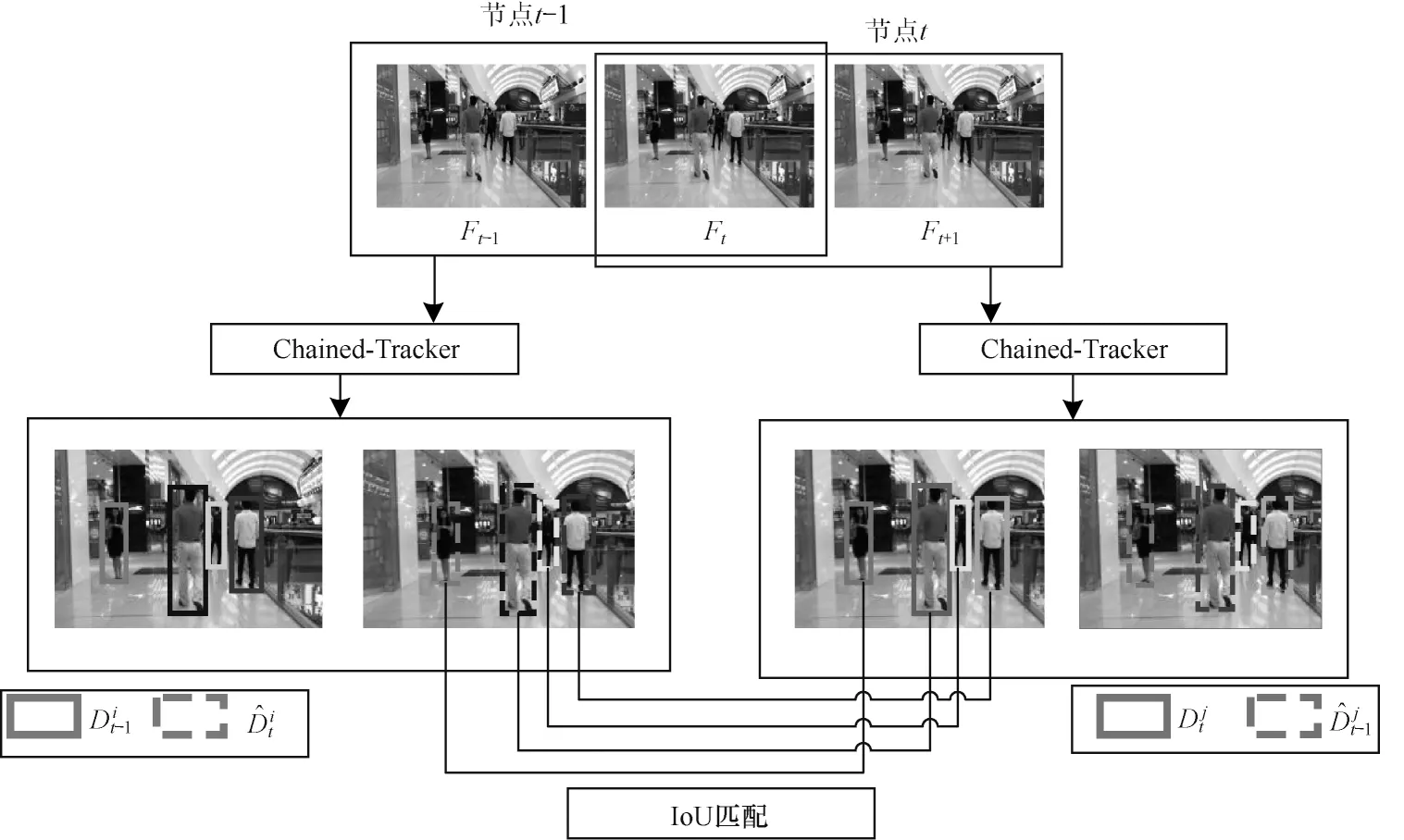
图1 链式跟踪的整体流程Fig.1 Overall process of chain tracking
针对场景中新目标出现的问题,在进行IoU 匹配时,将未匹配上的检测框认为是新出现的目标,对其分配新的身份并且初始化新的轨迹。若目标不在Ft-1帧而出现在Ft帧,节点(Ft-1,Ft)旨在输出相同目标的边界框对,因此不会识别该目标,但如果该目标稳定出现在场景中,该目标在节点(Ft,Ft+1)的输出就会被检测到,并获得初始化的新轨迹和身份标识。模型利用IoU 匹配进行数据关联,同时运动估计保证了长轨迹的生成,增加模型应对遮挡的鲁棒性。
为获得每个节点中的边界框对,网络利用了目标检测中的边界框回归思想,直接回归出两帧图像中相同目标的边界框对,网络的整体架构如图2 所示。
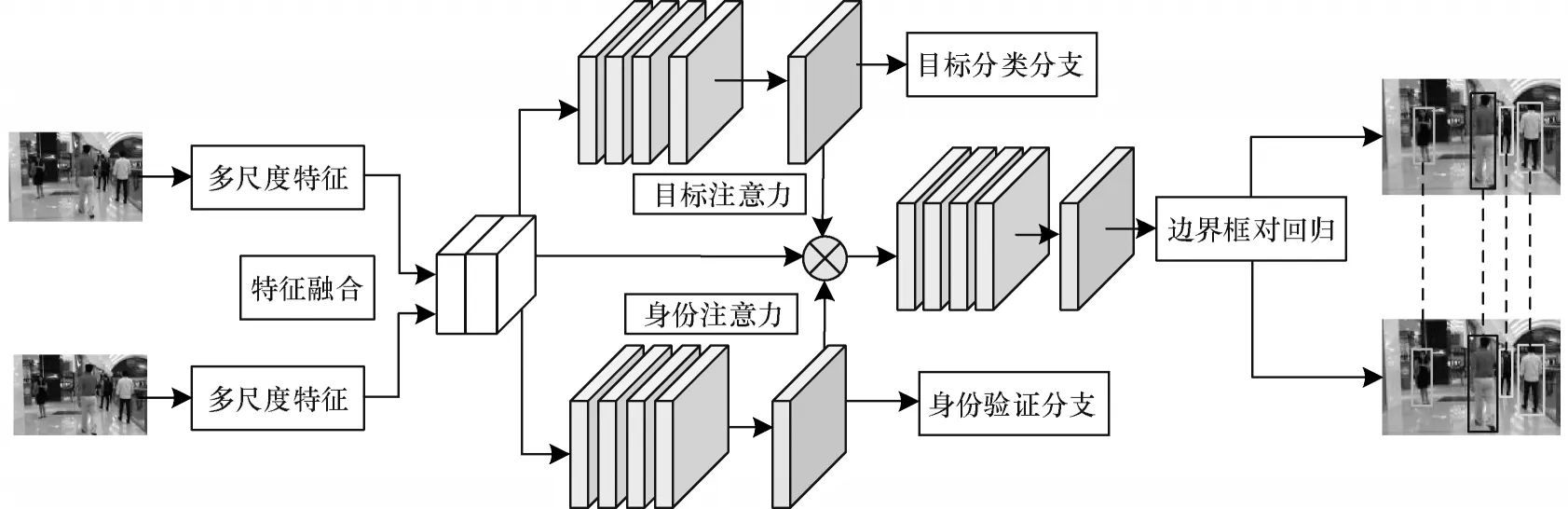
图2 网络整体架构Fig.2 Overall architecture of network
由图2 可知,网络采用孪生网络结构将连续两帧图像共同输入至网络中,分别利用Resnet50 作为骨干网提取深层语义特征,并利用多特征融合的双向金字塔结构输出多尺度的特征表示。多特征融合的特征金字塔结构如图3 所示。为获得两帧图像中相同目标的位置,首先将骨干网络生成的相邻帧多尺度特征图进行拼接,然后送入预测网络中,以直接回归出边界框对。预测网络由3 个分支组成,包括目标分类分支、身份验证分支以及边界框对回归分支。目标分类分支针对每个检测框预测前景区域置信度分数,以判断该区域中是目标还是背景。身份验证分支用于判断成对的检测框中是否包含同一个目标。若包含同一个目标,边界框回归分支同时预测两个边界框中该目标的坐标。

图3 多特征融合的金字塔网络Fig.3 Feature pyramid network with multi-feature fusion
为促进边界框回归过程可以集中于两帧图像中的相同目标,并且避免被无关信息干扰,预测网络中使用联合注意力模块,使回归过程更加关注组合特征中的有效信息区域[14],身份验证分支和目标分类分支的预测置信度图均被用作注意力图,将注意力图与组合特征相乘后再输入到边界框对回归分支,来自2 个分支的注意力起互补作用。利用预测网络结构中3 个分支的特性构造联合注意力模块,充分利用分类分支与身份验证分支的信息。相比只用于单个分支的常规注意力,联合注意力可以共同利用2 个分支的结果作用于回归过程。在执行边界框回归前,其他2 个分支的结果联合作用于回归分支,2 个分支的结果可以通过损失函数的设计来调节回归过程,其中分类分支的注意力图促进回归过程更加关注包含有效信息的前景区域,身份验证分支的注意力图使网络集中于相同目标检测框对的回归,能充分利用2 个分支的有效信息并且更好地监督回归过程,在一定程度上促进了网络中相同目标边界框回归的准确性。
网络中将相邻两帧图片组成一个节点作为输入,网络回归出两帧图片中相同目标的边界框对,不同节点之间由于存在公共帧,因此差异较小,故使用简单的IoU 匹配完成节点之间的关联,使用基础的匈牙利算法就可以完成检测框之间的最优匹配,从而完成帧间数据关联过程。数据关联的简化有利于提高跟踪的速度,满足实时性的要求。根据网络的输出特性设计轨迹管理机制,若节点间的公共帧成功匹配,则更新轨迹状态;若匹配失败则进入轨迹丢失状态,保存当前运动轨迹以及身份,同时使用运动估计尝试重新关联轨迹与目标。网络节点间的链式特性降低了误检的影响,也降低了关联机制的复杂度,实现了端到端的跟踪过程。
1.2 多特征融合的特征金字塔结构
行人目标在视频帧中处于移动状态,目标尺度变化很大,如果利用检测器的回归思想直接回归出图像对的边界框,就需要充分利用目标的语义信息保证回归的边界框坐标准确,同时增加小目标识别的准确性。常见的目标检测网络如Faster R-CNN 仅利用了骨干网提取的顶层特征来进行目标的识别与定位,图像中小目标在下采样过程中包含的有用信息会进一步减少甚至消失,这种方法不利于对小目标进行预测[15]。SSD 网络使用了多尺度特征融合的方法,从骨干网的不同层中提取不同尺度的特征进行融合,但这仍没有充分融合低层的语义信息[16]。因此,提出在骨干网后接入特征金字塔网络(Feature Pyramid Networks,FPN)[17],骨干网采用ResNet50 完成自底向上前向传播的过程,将特征图尺寸不变的层归为一个阶段。提取每个阶段最后一层的输出来完成特征融合,同时加入自顶向下的过程,来自顶层的特征图经过上采样与骨干网提取的相同尺寸的特征图横向连接并进行特征融合,以同样的方式逐层进行特征融合获得多尺度的特征图,充分融合高层与低层的语义信息,进而适应目标的尺度变化。
本文为提高网络对目标尺度的适应能力,在链式跟踪网络架构的基础上引入多特征融合的双向金字塔网络,借鉴了PANet[18]的思想,在特征金字塔FPN 自顶向下的聚合路径后增加一条自底向上的特征聚合路径,形成多特征融合的特征金字塔结构,更加充分地利用网络的浅层信息,有利于获得目标的更多位置信息。同时,为适应目标的形状变化特性,将原金字塔结构中的传统卷积替换为采样特征加权的改进可变形卷积(Deformable ConvNets v2,DCN v2),DCN v2 的具体结构见1.3 节。利用多特征融合的特征金字塔可同时适应目标的尺寸与形状变化特性。
1.3 改进可变形卷积
传统卷积方式使用尺寸固定的卷积核,对输入特征图采用规则采样,一般采样方式以矩形结构为主,提取的特征也是矩形框内的特征。然而,视频序列中行人目标在不停移动,不同帧中目标的形状以及尺度变化很大,传统卷积方式对这种几何变换的适应性较差,导致特征提取不完整,引入背景噪声也容易影响最后的结果。为适应不同目标形状和尺度的改变,在双向金字塔网络中引入DCN v2 卷积,DCN v2 卷积实现过程如图4 所示。

图4 DCN v2 卷积的实现过程Fig.4 Implementation process of DCN v2 convolution
在生成多尺度特征图的过程中将传统卷积替换为改进可变形卷积,根据当前目标的形状和尺寸自适应地调整采样点的位置,从而更加准确地提取目标特征。可变形卷积的主要思想是在标准卷积的规则网格采样位置添加2D 偏移量,偏移量的计算通过另一个标准卷积过程实现,故偏移量可以在训练过程中一起被学习,卷积核的大小和位置则可以根据学习到的偏移量进行动态调整,达到根据目标形状与尺度自适应调整的目的[19]。
可变形卷积在实现的过程中并非根据偏移量直接改变卷积核,而是通过对卷积前图片的像素值进行重新整合后再进行一般卷积操作,达到卷积核扩张的效果。可变形卷积的实现需要利用普通卷积中共N个采样点提取特征图,通过额外的卷积层从特征图中进行偏移量的学习,偏移量具有和输入特征图相同的空间分辨率,且为2D 分量,每个采样位置叠加1 个偏移量,分别包含x与y两个坐标方向的偏移,故将输出通道数设置为2N,表示N个采样点的2D 偏移,偏移量随着网络训练过程一起被学习。偏移量的变化以局部、自适应的方式取决于输入特征图中目标的形变,将获得的偏移量叠加到原来的特征图上获得加入偏移后的坐标位置,通过双线性插值的方式计算坐标位置对应的像素值。当获得所有像素值后便得到一个新的图像,将这个新图像作为输入,并进行常规的卷积操作。可变形卷积的使用对目标的形变等更具适应性,但偏移量的叠加倾向于使采样点聚集在目标对象周围,对物体的覆盖不精确,且会引入无关的背景信息造成干扰。为每一个采样点增加权重系数,通过给每一个偏移后的采样位置赋予权重来区分当前采样位置是否包含有效信息。采样权重取值在[0,1]之间,采样权重与偏移量一样,都是通过对输入特征图采用卷积运算来获得,即采样权重也是可学习参数,可以根据采样位置的变化在训练中学习得到。对输入特征图进行卷积操作,输出通道数由2N增加为3N,其中前2N个通道仍表示N个采样点的2D 偏移量,剩余的N个通道被进一步送入Sigmoid 层以获得采样权重,将偏移量与采样权重的初始值分别设置为0 和0.5,并在网络训练过程中不断被优化。如果叠加了偏移后的采样区域没有目标信息,则通过学习使权重降低,从而使网络可以更加集中于目标区域[20]。
2 损失函数



其中:参数λ可以控制简单样本的梯度变化,当λ较小时可以使简单样本产生较大的梯度,以平衡简单样本与困难样本的梯度贡献;参数η用于调整回归误差的上限;参数b保证了在x=1 时,损失函数有相同的值。3 个参数共同作用以满足约束条件,使得当偏移差接近于0 时,梯度迅速下降,接近于1 时梯度缓慢上升,解决SmoothL1 Loss 在偏移差为1 时的突变问题,使网络训练可以更平衡。
由Lb(x)可得回归分支成对检测框的回归损失Lreg的表示式如式(6)所示:

在获得目标分类分支、身份确认分支与边界框回归3 个分支的损失函数后,以一定权重对3 个分支损失函数进行加权,获得网络总的损失函数Ltotal,其表达式如式(7)所示:

其中:参数m与n分别表示分类损失与身份确认损失在Ltotal的权重。
3 实验结果与分析
本文所设计的网络在MOT17 数据集上进行训练与测试。MOT17 数据集发布于MOTChallenge上,相较于之前版本的视频序列有更高的行人密度,共包括1 342 个身份标识及292 733 个目标框,总计11 235 帧。MOT17 数据集包含14 个视频序列,既有静态摄像机场景也有动态摄像机场景,还包含不同的光照场景,例如晚间人群密集的商业街、光线昏暗的公园、明亮的商场中运动摄像机的跟拍、街道上模拟自动驾驶场景等。本文将MOT17 数据集中7 个视频序列用于训练,其余7 个用于测试。
本文使用多目标跟踪中最常用的CLEAR Metric[23]与IDF1[24]指标来评估模型的性能,其中CLEAR Metrics 主要包括多目标跟踪准确度(Multiple-Object Tracking Accuracy,MOTA)、多目标跟踪精度(Multiple-Object Tracking Precision,MOTP)、主要跟踪轨迹(Mostly Tracked Trajectories,MT)、主要丢失目标轨迹(Mostly Lost Trajectories,ML)、身份切换总数(Identity Switches,IDS)、跟踪速度等指标。
1)MOTA 是融合了误检、漏检与身份切换3 种因素的综合性指标,衡量模型在检测目标和关联轨迹时的整体性能,体现多目标跟踪的准确度;
2)MOTP 为目标检测框与真值框在所有帧之间的平均度量距离,衡量多目标跟踪的精度,主要是检测器的定位精度;
3)MT 指标衡量了目标存在期间与真值轨迹匹配高于80%的预测轨迹数目占轨迹总数目的比例;
4)ML 指标衡量目标存在期间与真值轨迹匹配低于20%的预测轨迹占总轨迹数的比例,MT 与ML两个指标均不考虑目标是否发生身份切换,仅衡量目标跟踪的完整性;
5)IDS 衡量整个跟踪过程身份切换的数目,衡量跟踪算法的稳定性;
6)跟踪速度指标用帧率(Frame Per Seconds,FPS)来衡量,FPS 数值越大,跟踪速度越快;
7)IDF1 指标衡量轨迹中身份标识的准确性。
以上指标中,MOTA 为最受关注的指标,体现了跟踪整体的性能。
在网络训练过程中为防止过拟合,一般会利用4 种方法进行数据增强:以0.5 的概率随机对图像进行亮度调整;色彩与饱和度调整;水平翻转;以[0.3,0.8]的尺度范围对图像进行随机裁剪。将模型在MOT17 训练集上训练时的批量大小设置为8,采用标准的Adam 优化器对网络训练100 轮,初始的学习率设为5×10-5,在网络训练过程中连续3 轮损失不下降则衰减学习率,学习率衰减因子为0.1。为平衡训练过程中的回归损失与分类损失,将损失函数Ltotal中的参数m与参数n均设置为1.4,目标分类损失Lcls与身份验证损失Lid中参数α与参数γ分别设置为0.25 与2.0,回归损失Lreg中参数λ与参数η分别设置为0.5 与1.5。在锚框与真值框匹配阶段将IoU 匹配阈值Tmax设置为0.5,在节点链接阶段,根据IoU 匹配的链接阈值设置为0.4,消失的目标保留其身份与轨迹σ帧,此处σ设置为10。
本文设计消融实验探究模型中各模块对整体性能的影响,实验结果如表1 所示。

表1 消融实验结果Table 1 Ablation experiment results
由表1 可以看出,由于基础链式结构中不包含多特征融合以及多任务损失模块,在加入多特征融合的特征金字塔结构之后,MOTA 指标从66.6 提升到了68.4,MOTP 指标也提升了1.3,MT 指标、IDF1指标均得到大幅提升,但ML 指标与IDS 指标均有不同程度的下降。改进后的特征金字塔网络增加了一条从下到上的特征融合路径,将其与可变形卷积融合,使其在特征提取阶段获得适应多目标形变与多尺度变化的融合特征。充分利用浅层语义信息提取更多的目标位置信息,可以根据目标的变化动态调整感受野,使网络更能适应目标的形变。由于实验所用数据集人流密度较大且处于动态变化,因此网络可以在目标发生形变时自适应地提取动态变化的特征,增强对目标形变的适应能力以及对小目标的检测能力,进而提升MOTA、MOTP、MT 和ML 等指标。此外,检测到的回归框能够进一步保证节点链接的准确性,因此相同目标的数据关联过程更准确,能够减少身份切换现象的发生,进一步优化了IDF1与IDS 指标。本文网络引入BalancedL1 Loss 替换传统的SmoothL1 Loss 损失函数,并进一步调整了损失函数的权重。虽然MT、ML 指标有一定波动,但是其他指标均有不同程度的提升,MOTA 指标获得了1.2 的增益、MOTP、IDF1 指标分别提高了1.5、2.4,这表明在网络训练过程中平衡简单样本与困难样本的梯度影响更有利于网络回归任务的均衡学习,提高了回归边界框对的准确性,进一步改善了跟踪过程的准确度与精度。
多目标跟踪网络受检测器的影响很大,为了公平地评价多目标跟踪网络的性能,将网络分为Private 与Public 两种。Public 方法使用数据集中提供的固定检测器完成整个跟踪模型的搭建,Private 方法可以使用任意检测器。由于Private 方法可以使用任何一个性能更好的检测器,因此同等条件下的Private方法比Public方法效果更好。MOT17数据集中的公共检测器为DPM、SDP 与Faster R-CNN3 种检测器,而本文网络结构中检测部分利用了RetinaNet 结构,属于Private 方法。为公平比较,本文仅将所设计网络与其他使用Private 方法的网络比较,结果如表2 所示,表中加粗数字为该组数据的最大值。

表2 不同网络在MOT17 数据集下的实验结果Table 2 Experiment results of different networks under MOT17 date set
由表2 可知,基于本文网络的方法具有较高的MOTA 值以及MOTP 值。分析原因可能是使用基于可变形卷积的多特征融合网络增强了模型特征提取能力,提高了模型对行人目标尺度以及形变的适应能力,进而提高了整体跟踪的精度与准确度。由表2还可知,本文网络的MT 指标、ML 指标与IDS 指标相较于其他网络效果略有降低,但是具有最高的帧率。这是因为本文网络在链式跟踪时节点之间仅使用IoU 进行匹配,利用节点之间公共帧的相似性进行数据关联,省去了复杂的数据关联算法,因此大幅提高了跟踪算法整体的速度。但是本文网络仅使用IoU 关联,与其他复杂的关联算法进行对比,关联的准确率与精度有所下降,影响跟踪过程的完整性,或者容易出现身份切换的现象,这表现在MT 指标、ML 指标与IDS 指标值的降低。测试结果中,本文网络的帧率最高,MOTA 指标相较于其他网络略有降低。这是因为数据关联阶段使用的IoU 匹配属于简单的基础匹配方法,在一定程度上影响了匹配的准确性,从而降低了跟踪精度。在通常情况下采用更复杂的匹配方式替换IoU 匹配可以提高跟踪精度,但数据关联需要对输入的视频帧进行逐帧匹配,数据关联算法的复杂性增加后,整个视频帧的跟踪速度就会大幅降低。从跟踪速度与精度权衡的角度考虑,本文选取了复杂性较低的基础IoU 匹配方法。为了降低简单匹配方式带来的影响,本文还采用了链式结构,利用节点之间的公共帧保证匹配双方具有强相似性,降低对复杂匹配方式的依赖性。此外,本文利用多特征融合结构与多任务损失提高边界框回归的精确性,进一步保证匹配过程的准确性。实验结果表明,所设计网络实现了速度与精度的权衡。
本文选取了测试集中2 个不同场景下连续3 帧的跟踪结果进一步展示多目标跟踪算法的实际效果。图5 所示为本文网络在MOT17-03 数据集下的可视化跟踪结果示例(彩色效果见《计算机工程》官网HTML 版本),此场景为静止的摄像机场景,地处晚间的商业街,光线较昏暗且人流密集度较大,具有一定的跟踪难度。图6 为本文网络在MOT17-12 数据集下的跟踪结果示例(彩色效果见《计算机工程》官网HTML 版本),此场景为运动摄像机视角下的场景。由图5 可知,MOT17-03 数据集下大部分的目标都可以被成功检测且在跟踪过程中保持身份不变,在人流密集处也能有效地被检测到,但是在严重遮挡环境下存在发生身份切换的可能性,例如图6 中第1 帧图像身份标识593 的目标在第2 帧中未被检测到,在第3 帧身份标识切换成了594,即在严重遮挡情况下出现了漏检、误检以及身身份切换的现象。在图6 中身份标识为140 的目标在第1 帧没有被检测到,在后2 帧才被正确地识别与跟踪。由于运动摄像机下相机与行人均处于运动状态,目标的形状与位置信息在通常情况下具有一定的模糊性,所以会发生误检以及漏检的现象,除了140 号小目标之外其余目标都被成功跟踪,这进一步说明了检测结果对整体跟踪性能的影响。实验结果表明,本文设计的网络可以较好地应对场景中的动态变化,在人流较高、光照改变、运动摄像机等复杂场景下仍具有一定的鲁棒性。

图5 本文网络在MOT17-03 数据集下的可视化跟踪结果示例Fig.5 Visual tracking results example of network in this paper under MOT17-03 date set

图6 本文网络在MOT17-12 数据集下的可视化跟踪结果示例Fig.6 Visual tracking results example of network in this paper under MOT17-12 date set
4 结束语
本文设计一种多特征融合的端到端链式多目标跟踪网络,将目标检测、外观特征提取与数据关联集成到一个框架中,并将多特征融合的双向金字塔网络引入框架中,在特征金字塔结构中融入具有采样加权的改进可变形卷积,进一步增加对目标形变的适应能力。本文网络可以根据目标的变化动态调整感受野,从而提升模型特征提取能力,从整体上改善跟踪的性能。引入focalloss 与BalancedL1 Loss 两种损失函数进行多任务学习,进一步解决回归任务中正负样本不平衡、简单样本与困难样本梯度贡献差距大的问题,实现网络的均衡学习,提升跟踪的精度与准确度。实验结果表明,本文网络实现了速度与精度的权衡,具有较高的应用价值。但本文网络在数据关联阶段仅使用了IoU 匹配,虽然简单的数据关联算法可以提高整体的跟踪速度,但是会影响关联的准确性,导致身份切换的现象发生。下一步将使用级联匹配、图卷积等方法对数据关联阶段进行优化,设计更合理的关联方法,并尝试将该网络应用于其他特定场景中。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
当代陕西(2019年15期)2019-09-02 01:52:00
电子制作(2019年11期)2019-07-04 00:34:38
现代装饰(2018年5期)2018-05-26 09:09:39
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
学苑创造·A版(2018年11期)2018-02-01 06:29:20
中国三峡(2017年2期)2017-06-09 08:15:29
读者(2017年5期)2017-02-15 18:04:18
