
基于CPET 时序聚类的中长跑耐力运动员选拔方法
2022-09-15 06:59:36李海林夏燕燕邹金串
计算机工程 2022年9期
李海林,夏燕燕,邹金串
(1.华侨大学 信息管理系,福建 泉州 362021;2.华侨大学 体育学院,福建 泉州 362021;3.华侨大学 应用统计与大数据研究中心,福建 厦门 361021)
0 概述
依据《大数据白皮书(2019 年)》的报告,全球数据量在2021 年可提升至41 ZB。数据产生大多带有时间属性,这在一定程度上推动了时间序列数据挖掘理论与应用的发展。随着运动医学领域时间序列数据的大量积累与存储,以及理论研究的日臻完善,分析这些数据以获取隐含的、具有参考价值的信息已成为多数机构和学者的需求。心肺运动试验(Cardiopulmonary Exercise Testing,CPET)能将人体的呼吸系统、心血管系统等综合为一体,其不仅能够体现受试者的有氧运动能力,评估受试者的心肺耐力(Cardiorespiratory Fitness,CRF)[1-2],而且能够以整体整合医学的视角来探究受试者对运动的应激反应[3]。对CPET 数据进行聚类分析,就受试个体而言,利于从整体整合医学视角进一步探究生理指标状况,为评估身体健康状态提供参考。对受试群体进行聚类分析,则能够发现“离群值”或是实现预分群,为运动员选拔工作提供指导,并有利于针对不同特征组群进行针对性训练。
在时间序列聚类挖掘过程中,相似性度量与聚类算法是两大关键内容。一方面,选择一种合适的相似性度量方法,将有利于聚类主题更加清晰明确。研究成果表明,合理有效的相似性度量能够提升算法性能[4]。相似性度量主要选择动态时间弯曲(Dynamic Time Warping,DTW)方法[5],其度量时序距离具有更大的灵活性,但往往时序数据维度大,计算的时间复杂度也相对较高。为此,李海林等[6]提出一种基于关键形态特征的降维方法,通过数据预处理来加速时间序列的相似性度量。针对DTW 的高时间复杂度问题,文献[7]提出一种高效优化的DTW 度量方法,文献[8]从整体上提出一种基于序列波动特征的相似性度量方法,该方法针对序列的波动特性,通过设置阈值选取关键极值点,再通过时间精准匹配、近邻匹配得出两序列间的相似性。另一方面,在多种传统聚类算法思想中,由于层次聚类事先需要给定的先验知识较少,对结果的分析往往能够得到更多启发,因而被广泛使用。文献[9]提出基于DTW 改进的层次聚类算法,并验证了该算法所得聚类结果的有效性。时间序列聚类算法已被广泛应用于金融股票[10-11]、交通客流[12-14]、环境监测[15-16]、隧道施工[17]等领域。鉴于时间因素的重要性[5,18],研究人员将时间序列聚类技术扩展应用到金融期货[19]、农场肉类数据检测[20]、电力客户群市场细分[21]等各领域中。
在运动医学领域,时间序列数据挖掘技术的应用尚未成熟。国内中长跑运动员选拔大多沿用“边训边选”的理念,选拔与训练工作是交替进行的,并采用定性与定量相结合的方法加以评定。在传统意义上,定量评定主要采用运动测试期间某一静止时点数据(如最大耗氧量VO2max、最大摄氧量速度vVO2max)或是一段时间内某类指标的差值(如vVO2max持续时间tlim)加以判别,忽略了整个运动测试期间数据的变动信息。CPET作为一种科学、整体整合理念的心肺功能测试,其数据应用价值潜力巨大。本文提出一种基于时间序列形态特征的算法,用于对CPET数据进行凝聚层次聚类分析。该算法能够将测试期间的趋势、极值、平台、周期等各项变动特征加以综合考虑,将测试期内指标变动较为相似的受试者聚为一类。通过对聚类结果的评估与分析,以实现为中长跑运动员选拔等工作提供科学化指导。
1 动态时间弯曲
时间序列数据是指通过等时间间隔获取到的序列数据,带有时间属性。数据排列可反映时间先后顺序,该数据一般具有时间维与变量维两个维度。变量维为1 的序列称为一元时间序列(Univariate Time Series,UTS),反之称之为多元时间序列(Multivariate Time Series,MTS)。
定义1(一元时间序列数据)时间维为n的一元时间序列X表示为{x1,x2,…,xn}。

DTW 度量方法可对非等长序列进行距离度量,在时间序列领域被广泛使用。另外,DTW 度量方法允许序列间出现平移、振幅、收缩等状态,能最大程度地度量序列之间的相似性。
令d(xi,yj)为原始距离矩阵元素,D(xi,yj)为DTW 累积距离矩阵元素,则最终时间序列X={(x1;t1),(x2;t2),…,(xn;tn)}与Y={(y1;t1),(y2;t2),…,(ym;tm)}的动态弯曲距离为D(xn,ym)。DTW 公式表示如下:

DTW 数据点匹配状况相比于欧式距离更加灵活,更大程度上度量了数据间的相似性。为防止序列出现过度弯曲匹配的状况,一般采用加窗改进的DTW 度量方法,在式(1)中,将i≠0且j≠0 条件转变为i≠0且j≠0;i-c≤j≤i+c,其中c为常数。
2 基于心肺时序数据的聚类方法
CPET 属力竭性测试,不同受试者运动时长不一,数据在时间维一般较短而属性维较长。递增负荷运动测试所得心肺数据序列具有一定波动特征,如通气震荡,存在明显的上升或是下降趋势。在受试者极限运动负荷下,相关指标数据可能会出现一个稳定的“平台”,这是CPET 数据的关键特征。同时,由于是纵向分析角度,不同指标阈值特征点序列长短不一较为显著,如心率(Heart Rate,HR)指标波动较小,几乎随时间逐渐递增,阈值特征点序列较短;而生理死腔与潮气量(Dead Volume/Tidal Volume,VD/VT)比值震荡波动较大,阈值特征点序列较长。若不考虑时长因素,则直接对数据进行DTW 度量不太准确。时长指序列数据之间的时间间隔跨度,n个时间间隔则计数为n。在纵向相似性度量方面,需考量时长因素以实现通过阈值特征点对原始序列进行线性拟合。横向角度由于通过对应同类指标进行度量而不需要考虑时长因素。针对以上CPET 数据特征,故需选择基于阈值特征点提取的降维策略,并结合DTW 思想进行距离度量。
2.1 形态特征表示
时间序列形态特征主要是指序列数据波动特征、变动趋势、周期规律等特点。通过提取数据的主要形态特征点,能够使聚类任务更加明确可行,并基于提取阈值极值点与阈值平稳点来实现。
2.1.1 阈值极值点
传统极值点的定义将数据点xi与其相邻两点xi-1和xi+1进行比较。在此基础上,给定误差范围ε,允许数据点之间的比较存在ε范围内的波动。
定义3(阈值极大值点)若xi-xi-1>ε且xixi+1>ε,则可判定xi为阈值极大值点。
定义4(阈值极小值点)若xi-1-xi>ε且xi+1-xi>ε,则可判定xi为阈值极小值点。
2.1.2 阈值平稳点
传统平稳点是指连续的数据值相等,在曲线形态上是一条平行于X轴的直线。阈值平稳点是指数据之间允许有ε的浮动范围。在ε范围内,将数据看成平稳波动,其值变换为该时间段内数据的均值。
定义5(阈值平稳点)若xi既不是阈值极大值点且非阈值极小值点,当|xi-xi-1|≤ε时,xi-1、xi为阈值平稳点;当连续多个数据点满足以上条件时,均可视为阈值平稳点。在寻找该点时,有可能会将以ε范围波动的递增、递减数据序列作为平稳波动序列处理。当出现以上情况时,会增加线性拟合的误差。因而依据数据特点,阈值需要谨慎选择。ε值可结合最终数据线性拟合误差、压缩率来综合确定。
对于时间序列X={x1,x2,···,xn},经过一次遍历后得到特征点序列X′={x′1,x′2,···,x′i}。依据X′对 原始序列数据进行拟合,得到等长线性拟合序列数据X″={x″1,x″2,···,x″n}。线性拟合误差表示如下:

通过比较可知,基于阈值特征点提取的序列数据比传统特征点提取的序列数据更短,并且能够提取序列数据的非极值点,即关键转折点、重要点。针对微小频繁波动的数据,阈值特征点线性拟合表现更加灵活。因此,基于阈值特征点降维能够保留数据的大体波动、周期等信息,而忽略过于频繁、细小的变动信息。
2.2 相似性度量
纵向维度相似性度量DTW_SimT 与横向维度的DTW_Sim 主要区别在于:纵向维度相似性度量需将提取的阈值特征点结合时长进行线性拟合,得到和原序列长度相等的序列;横向维度相似性度量不考虑阈值特征点的时长因素。本文主要叙述横向维度相似性度量算法。
对于多元时间序列数据集XM,需遍历每个样本个体,并求出每个数据集属性列的阈值特征点序列;若为阈值平稳点则进行标记,并以该段连续被标记为阈值平稳点集的均值代替原来的数值。两个多元时间序列样本之间的相似性距离,由使用加窗改进的DTW 方法对应计算各变量维序列距离所得的均值表示。
算法1相似性度量算法DTW_Sim

2.3 聚类方法
通过DTW_Sim(或DTW_SimT)相似性度量方法,结合基于离差平方和类间邻近性评价方法,实现对数据进行凝聚层次聚类,即聚类算法DTW_MFAC。
算法2时间序列聚类算法DTW_MFAC

3 数值实验
3.1 实验数据集
为验证所提算法的有效性,从分类数据网站上下载了6 类含有类别标签的数据,如表1 所示。数据均为一元时间序列,并选择实验数据的训练集进行聚类效果验证。由于DodgerLoopGame 训练集中除去缺失数据仅有8 个,因此选择其对应测试集数据进行实验。
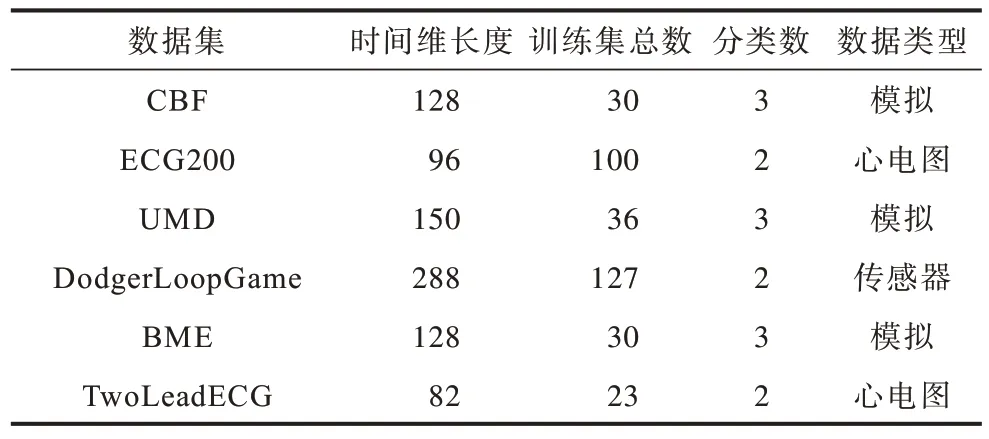
表1 实验数据集Table 1 Experimental datasets
在执行算法前,需通过平均线性拟合误差、平均压缩率为各数据寻找最佳阈值ε。初始ε变化范围为[0.001,1.0],以0.05 为步长逐渐增加。为方便综合考虑最佳阈值,将平均线性拟合误差及平均压缩率做均值方差标准化处理。
选取各数据集的最佳阈值如表2 所示,结果保留两位小数。此时,数据线性拟合误差较小,同时压缩率较低。

表2 实验数据集最佳阈值Table 2 Optimal threshold of experimental datasets
3.2 算法比较与评估
为最大限度地减少误差平方和,在凝聚层次聚类过程中,选择离差平方和类间邻近性度量方法,并与传统的欧式距离度量方法做比较,如表3 所示。

表3 实验数据集聚类准确率比较Table 3 Comparison of clustering accuracy of experimental datasets
通过不同数据集比较实验可知,相比传统基于欧式距离的层次聚类算法,DTW_MFAC 算法在对数据基本形态特征提取的过程中,一定程度上保证了聚类效果,总体而言聚类效果良好。同时,对于数据形态特征较为显著、波动幅度较大的数据集,聚类准确率更高。
4 CPET 聚类分析与运动员选拔
4.1 聚类评估
轮廓系数最早于1986 年由ROUSSEEUW 提出,是以样本类间距离与类内距离(也称为凝聚度与分离度)为出发点。当数据的类别未知时,可使用轮廓系数对聚类效果进行度量评估。对于单个样本xi,xi与同一簇内所有样本距离的平均值记为ai;样本到其他各簇Ci(1 ≤i≤k)各样本xi(xi⊂ci)之间距离平均值的最小值,记为bi,则样本xi的轮廓系数为:

单个样本的轮廓系数相加求平均值,即为样本数据集的轮廓系数S,如式(4)所示:

其中:N为样本量。轮廓系数取值在[-1,1]区间,有3 个极端分别为-1、0 和1。轮廓系数si越接近-1,表示聚类效果越差,xi应分配到其他簇中;si越接近0,表示聚类效果处于中间状态,将xi分到该簇或离其最近的簇中均可;si越接近1,表示聚类效果越好,xi属于该簇成员。
4.2 CPET 数据
选取严格按实验室要求做完CPET 试验的15 名大学体院男生(年龄为(20.8±1.42)岁;身高为(174.93±3.87)cm;体重为(64.73±5.57)kg;BMI 为(21.13±1.37))数据作为分析对象。与专业级中长跑运动员不同,15 名受试者均为业余爱好者。每位受试者进行跑台力竭测试的时间大约在10 min 不等。在实验中,每15 s 增加一个负荷并以该时间间隔获取受试者的30 项生理指标,包括最大耗氧量(VO2max)、最大心率(HRmax)等指标。通气无氧阈(Ventilatory Threshold,AT)则依据以下规则进行判别:1)VCO2、通气当量(Ventilatory Equivalents,VE)非线性升高的拐点;2)VCO2与VO2的相交点;3)VE/VO2相对升高而VE/VCO2未见降低的拐 点;4)呼吸商(Respiratory Quotient,RQ)相对升高的拐点。受试者耐力评定关键生理指标值如表4 所示。表4 中前3 列指标将数据按降序排列,可用于初步评估各ID 运动员的心肺耐量状况。可以看出,运动员耐力状况与CPET 测试时长有着直接联系。直观上也可以看出,测试时间越长,说明运动员心肺耐量越好。

表4 受试者耐力评定关键生理指标值Table 4 Value of key physiological indexes for endurance assessment of subjects
4.3 阈值和生理指标确定
纵向分析是指对某一ID 数据集进行聚类分析。纵向聚类分析为横向维度分析提供阈值参照以及聚类指标选取建议。由于VO2max是评估受试者心肺耐力、运动受限的关键指标,文中选取ID 为9 的志愿受试者数据进行纵向分析,其VO2max(单位:ml/min)为4 062,消除体重量纲之后,与该列VO2max(单位:ml/min/kg)最大值58.88 仅相差0.01。首先需预确定ID9 数据集的最佳阈值范围,如图1 所示。

图1 CPET 数据最佳阈值范围选取Fig.1 Selection of best threshold range of CPET data
ID9 数据最佳阈值范围为(0,0.15]。此时,数据的平均拟合误差以及压缩率均较小。本文中选取0.05 作为最佳阈值。此时ID9 各属性列数据的平均拟合误差为0.53,平均压缩率为0.62。同时,使用该阈值对CPET 数据集进行横向聚类。
使用DTW_MFAC 算法对ID9 数据集聚类,首先需对数据进行均值方差标准化,再使用选取的阈值对序列形态特征进行提取,并选取动脉血氧分压(Partial Pressure of Oxygen,PaO2)指标的拟合状况进行查看。从图2 可以看出,ID9 数据的PaO2拟合状态较好,保留了指标数据的大体波动特征以及平稳、趋势等状态。

图2 ID9 PaO2指标线性拟合图Fig.2 Linear fitting diagram of ID9 PaO2 index
对于同一受试者而言,CPET 测试始与末均分别对应受试者正常及力竭状态,需设置序列的首末两点对应匹配。依据轮廓系数评估结果,各簇类数目k的系数均超过0.5,如图3 所示。ID9 各项指标数据最佳分类数目为2,其值约为0.72,此时聚类效果较好。可将数据分为3 个簇群,聚类结果如图4 所示。

图3 纵向维度聚类(ID9)轮廓系数评估结果Fig.3 Profile coefficient evaluation results of vertical dimension clustering(ID9)

图4 纵向维度聚类可视化(ID9)结果Fig.4 Vertical dimension clustering visualization(ID9)results
ID9 聚类结果主要分为两大簇,可以看出:左簇群大多与耗氧、代谢以及能量转化相关,而氧气可直接影响人体能量的转化;右簇群主要与每搏输出量(Stroke Volume,SV)、二氧化碳转化指标以及呼吸时间相关。若选取k=3 作为聚类结果划分,右簇群进一步被细分为两类:一类主要与CO2气体相关;另一类则与PaO2和呼吸时间相关。由此可大致判断,心肺运动测试机理以人体呼吸过程为基础,探究O2、CO2的转换与利用状态。呼吸牵涉血液循环、肺循环等多个系统,对数据进行纵向维度解读,有利于深入探究受试者各指标间的“簇群分布”特征,对于研究不同人群例如不同专项运动员、不同等级运动员或是健康人群与患者之间呼吸生理指标的内在相似度提供参考。
4.4 选拔应用
通过纵向聚类分析,说明各指标间数据的ε误差可选择0.05。聚类指标选择左簇群耗氧量(VO2)、二氧化碳(VCO2)、心率(HR)、分钟通气当量(VE)、代谢当量(Metabolic Equivalents,METS)、生理死腔与潮气量比值(VD/VT)、呼吸商(npRQ)以及右簇群每搏输出量(SV),共8 类指标。选取的指标能够体现运动员摄取、利用氧的效率、肺循环以及心功能等综合状况。
轮廓系数评估结果如图5 所示,15 名业余中长跑受试者个体差异较大,应当单独自划分为一簇。以13 和14 作为簇类数目k划分时,轮廓系数值分别达到0.758 和0.88,相应的层次聚类结果如图6 所示。说明ID6 与ID7 以及ID14 与ID15 运动员综合耐力评估状态较为相似。

图5 CPET 数据横向聚类轮廓系数评估结果Fig.5 Evaluation results of profile coefficient of lateral clustering of CPET data

图6 CPET 数据横向聚类可视化结果Fig.6 Visualization results of CPET data horizontal clustering
通过表4 可初步判断,与其他业余中长跑运动员相比,ID6、ID7、ID14、ID15 心肺耐量较差,故针对中长跑等耐力项目选拔时以上4 位测试者可不予考虑。其余运动员可通过对应VO2max、HRmax以及AT 确立训练目标并进行专项训练。在一段时间后,可再依据CPET 各项指标结合聚类算法思想进行再选拔。阈值选取可依据平均拟合误差、平均压缩率或是领域实践经验加以确定。
5 结果分析
中长跑作为一项以体能为主的项目,已逐渐成为全民性健身运动,大众参与度高,业余参赛选手比重大。此类运动需高度重视基础耐力评定与提高[22],且已有多种可量化指标供评估参照。其中,VO2max是最为基础和综合的指标。已有研究表明,VO2max受遗传因素影响较高,达到90%以上,在青少年初步选材时期应用更加普遍。另一方面,通气无氧阈(AT)也能够用于评定有氧运动能力,在运动训练领域起到了关键性的作用,且受遗传因素影响较小[23]。针对中长跑耐力运动员的评定与选拔,国内外通常以最大耗氧量速度(vVO2max)、最大耗氧量平台(VO2maxPD)、跑步经济性(Running Economy,RE)或是vVO2max持续时间、达到VO2max后持续时间等值作为参考。此外,优选男子800 m 参赛选手时,可参考最大冲刺速度(Maximum Sprint Speed,MSS)及厌氧速度储备(Anaerobic Speed Reserve,ASR)指标,即vVO2max与MSS 的差值速度,两者值的提高被认为是具备技能竞争能力的重要条件[24];而精英级长跑运动员在增量测试中具有较高的呼气末二氧化碳浓度(Postapneic end-tidal Carbon Dioxide Pressure,PetCO2)以及更低的分钟通气量(VE)[25]。在以上评估评定过程中,通常会选择多个指标综合考虑,同时不可排除个体差异的影响。
目前,国内大多沿用“定量与定性结合”、“边训边选”的模式对运动员进行选拔。在多数情况下也需教练多年的教学经验作为辅助决策依据。但在这一过程中,往往会面临很多难题,如:需要提前了解运动员的身体素质以及各项生理指标;在训练过程中能够合理确定运动强度和运动量;能够预防运动损伤状况;能够根据运动员自身能力不足之处做科学且有针对性的训练计划[26]等。然而,心肺运动试验(CPET)作为一项整体整合式的试验,以上指标均可通过测试结果分析得到,并能有效解决上述面临的主要问题。
CPET 通常可作为跑步人士的医疗预检项目。鉴于CPET 测试的潜在价值,本文提出一种基于此类时间序列聚类的算法DTW_MFAC。该算法将以DTW 为核心的相似性度量算法DTW_Sim 与凝聚层次聚类算法思想相结合,DTW_Sim 能够识别出各指标序列的形态特征,如极值点、平稳点、趋势、周期等,在更大程度上度量了序列间的相似性。实验的结果表明,DTW_MFAC针对形态特征较为显著的MTS 数据集聚类效果较好。本文以15 名大学生业余组中长跑运动员的CPET 数据作为分析对象,选取了表征有氧能力与心肺耐量的8 类关键指标进行聚类分析,结果发现受试者个体差异较大。同时依据轮廓系数评估结果,可初步剔除心肺耐量较差的4 位测试者。此外,不同阈值以及选取不同指标用于聚类分析,结果存在一定差异,可根据实际需要灵活选择。
6 结束语
本文提出一种针对CPET 时间序列数据进行聚类分析的算法DTW_MFAC,使用该算法能够识别出CPET 序列的阈值极值点与平稳点。通过CPET 分析,选取可反映运动员心肺耐量的8 类指标进行聚类分析,发现个体差异较大,没有出现明显的簇群分布结果。依据轮廓系数评估准则,心肺耐量较差的测试者可不予考虑。为使聚类效果更佳,选取受试个体进行阈值确定或结合整体数据对象进行考虑将是进一步的研究重点。另外,本文选择凝聚层次聚类思想构建算法,未针对基于密度的聚类、基于图的聚类等目前主流聚类算法进行比较分析,后续研究可据此对算法进行优化和改进。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
中国心血管杂志(2022年2期)2022-11-25 17:29:20
中国心血管杂志(2022年4期)2022-11-25 16:59:06
数学物理学报(2022年5期)2022-10-09 08:56:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
中国心血管杂志(2021年6期)2021-01-02 08:18:16
河北画报(2020年8期)2020-10-27 02:54:20
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
中国心血管杂志(2019年3期)2019-01-04 16:25:09
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
