
基于完全自注意力的水电枢纽缺陷识别方法
2022-09-15 06:59:38赵国川
计算机工程 2022年9期
赵国川,王 姮,张 华,庞 杰,周 建
(1.西南科技大学信息工程学院,四川绵阳 621000;2.西南科技大学特殊环境机器人技术四川省重点实验室,四川绵阳 621000;3.清华四川能源互联网研究院,成都 610000)
0 概述
水电枢纽混凝土结构长期受到水流冲刷侵蚀,极易形成裂缝、渗漏等典型缺陷,为水电枢纽的稳定运行带来极大的安全隐患。目前,水电枢纽缺陷识别主要依靠人工巡检,该方式存在周期长、效率低、风险高等问题[1]。由于水电枢纽缺陷图像数据具有相似干扰噪声大、亮度不均衡、背景特征复杂等特点,导致基于视觉的高效、准确的水电枢纽表观缺陷识别方法的研究成为一项充满挑战性的任务。
近年来,研究人员专注于表观缺陷自动检测方法在道路、桥梁、管道、隧洞等领域的应用研究。早期,基于显式特征提取[2]的缺陷检测方法通常通过手动提取缺陷的颜色、纹理、形状等特征,并将特征送入设计的分类器,完成对缺陷图像和正常图像的分类。PRASANNA 等[3]提出一种用于桥梁裂缝识别的多特征分类器和机器学习分类器,虽然传统基于显式特征提取的缺陷检测方法在缺陷识别任务上取得了一定效果,但需要手动设计特征和参数,且计算步骤繁杂,在背景变化后其识别准确率容易大幅降低。近年来,深度卷积神经网络(Deep Convolutional Neural Network,DCNN)在图像分类[4-5]、目标检测[5]、图像增强[6]、语义分割[7]等计算机视觉任务上取得了显著成就,研究人员相继提出多种深度卷积网络来完成缺陷检测任务。LEE 等[4]提出一种基于卷积神经网络和类激活映射的钢铁缺陷分类方法,实时诊断钢铁缺陷。FENG 等[5]提出一种基于Inception V3 的水利枢纽结构损伤识别方法,利用迁移学习初始化网络,完成裂缝、渗水等5 种缺陷分类任务。文献[6]在传统U-Net 模型的基础上构建一种基于偏色图像的卷积神经网络模型,不断学习输入图像与输出图像的色彩偏差,并通过引用结构相似性的损失函数使增强后的水下图像与输入的水下图像在内容结构细节上保持高度相似。SUN 等[7]使用SSD 检测网络对路面裂纹进行定位及分类,并使用U-Net 网络对裂纹区域进行分割,最终该网络对横向、纵向和网状3 类裂纹的识别精度分别为86.6%、87.2%和85.3%。CHOI 等[8]提出SDD-Net,使用稠密空洞卷积增大卷积层感受野及降低参数量,通过特征金字塔池化模块融合多尺度特征,大幅提升裂缝分割速度。卷积架构为网络学习提供局部相关性这一重要的归纳偏置,使网络可以高效学习、迅速收敛,但该架构获取全局信息的能力较弱,在一定程度上限制了网络性能上限。
目 前,Transformer[9]作为先进的序列数据处理模型,在机器翻译[10]、语言建模[11]、语音识别[12]等自然语言处理(Natural Language Processing,NLP)领域取得了优异成绩。自注意力机制是Transformer 的核心,通过关联每个特征点与其他特征点之间的依赖关系,形成强大的全局信息捕捉能力。受Transformer 在NLP 中取得成功的启发,研究人员开始将Transformer 应用到图像处理领域。BELLO等[13]将部分卷积层替换为自注意力层,提升了图像分类效果,但大尺寸图像的自注意力计算导致时间复杂度大幅增加,计算成本太高。WANG 等[14]提出一种循环卷积网络用于场景分类,通过选择性关注关键特征区域,丢弃非关键信息,从而提升分类性能。RAMACHANDRAN 等[15]使用自注意力机制独立构建网络,以处理视觉任务。谷歌提出一种视觉变换器(Vision Transformer,VIT)[16],完全使用自注意力机制解决计算机视觉任务,在ImageNet 数据集上表现良好。
在水电枢纽缺陷识别过程中,网络通常需要全局的视野才能准确判断是否存在缺陷及缺陷类型。深度卷积网络[17]使用卷积核获取局部感受野,通过多个卷积层堆叠获得更大感受野,但捕捉长距离语义信息的能力仍然较弱,且网络过深容易导致过拟合、难训练、参数量巨大等问题。与DCNN 不同,VIT 在进行自注意力计算时,每一个特征点都会考虑其余特征点信息,具有强大的捕捉长距离依赖能力,通过训练可达到自适应调整感受野范围的效果,因此更适合水电枢纽缺陷识别。
VIT 网络首先将图像切割为尺寸相同的图像块并添加序列位置信息,然后将这些序列块送入Transformer 编码器,最后在Transformer 的输出过程直接完成分类任务。由于缺陷图像具有形态多样、尺度变化大等特点,且VIT 网络在单一尺度上对分块后的图像块进行自注意力计算,无法多尺度获取缺陷图像语义信息,因此在一定程度上限制了网络对缺陷图像的识别能力。
本文提出基于完全自注意力的水电枢纽缺陷识别网络(TSDR)。受VIT 网络启发,完全采用自注意力机制构建缺陷识别网络,通过设计2 个不同尺寸的自注意力编码器分支,以不同尺寸完成自注意力计算。此外,构建一个基于类别向量的自注意力混合融合模块,融合多尺度自注意力编码单元提取的多尺度特征,以有效应对水电枢纽缺陷尺度变化大、形态多样等问题。
1 本文网络
传统深度卷积网络使用具有局部感受野的卷积层提取图像特征,通过全连接层输出语义标签,对图像全局信息考虑非常有限。与深度卷积网络不同,本文完全使用自注意力机制构建网络,通过将图像块序列映射至语义标签,以完成分类任务,从而充分利用自注意力机制捕捉远程依赖关系的能力。本文提出基于完全自注意力的水电枢纽缺陷识别网络,其结构如图1 所示。可以看出,本文网络由线性嵌入层、多尺度自注意力编码器和多层感知机3 部分组成,其中多尺度自注意力编码器包括多尺度自注意力编码单元和自注意力混合融合模块。线性嵌入层将图像分为不重叠的图像块并添加位置编码,多尺度自注意力编码单元采用2 条分支提取不同尺度自注意力特征,通过自注意力混合融合模块融合多尺度自注意力特征,提升语义表达能力,将融合后的自注意力特征送入多层感知机获得分类结果。

图1 本文网络结构Fig.1 Structure of network in this paper
1.1 线性嵌入层
如图1(a)所示,线性嵌入层位于网络前端,对缺陷图像进行分块操作,可以得到不重叠且尺寸固定的图像块,将其映射为嵌入向量,再添加类别向量和位置编码。标准Transformer 输入是一维序列,为了使其能够处理二维图像数据,线性嵌入层首先将图片X∈RH×W×C分为二维图像序列块Xp∈RN×P2×C。其中:(H,W)是图片的分辨率;C是图像通道数;(P,P)是每个图像块的分块尺寸;主分支PL=16;副分支是图像块的数量。通过可学习嵌入矩阵e将图像序列块线性投影至一维嵌入向量,形状为1×D,其中D是嵌入向量深度,主分支为768,副分支为384,并增加一个与嵌入向量形状相同的可学习类别向量xclass与嵌入向量并列送入多尺度自注意力编码器。由于在分割图像块的过程中容易丢失图像块之间的位置关系,为保持图像块的空间排列,每一个嵌入向量和类别向量都需要加入位置编码Epos∈R(N+1)×D,最后得到具有标记的嵌入图像序列z0,其表达式如式(1)所示:

已知VIT 网络中一维和二维的位置编码分类效果几乎相同[16],因此,本文采用计算简单的一维位置编码保存图像嵌入序列的位置信息。
1.2 多尺度自注意力编码器
将线性嵌入层输出的图像嵌入序列作为多尺度自注意力编码器的输入。图像块分辨率直接影响自注意力网络的缺陷识别准确率和复杂度,低分辨率图像块可以为自注意力网络带来更高的识别准确率,但同时会带来更大的计算量和内存占用。因此,本文提出多尺度自注意力编码器,设计双分支结构对2 种不同分辨率图像块进行自注意力计算,2 个分支以类别向量为标识进行多尺度混合融合,获得分类预测结果。
图1(b)所示为多尺度自注意力编码,可以看到,该编码器由K组多尺度自注意力编码单元和自注意力混合融合模块级联组成。每个多尺度自注意力编码单元包括2 条自注意力编码分支:主分支使用16×16 大尺寸图像块、嵌入向量深度为768、4 个自注意力编码单元;副分支使用14×14 小尺寸图像块、嵌入向量深度为384、1 个自注意力编码单元。自注意力混合融合模块将一个分支的类别向量与另一个分支的嵌入向量进行自注意力计算,融合多尺度特征。
1.2.1 多尺度自注意力编码单元
图2 所示为多尺度自注意力编码单元结构,由2 个自注意力编码单元组成。如图2(a)所示,自注意力编码单元完全依靠自注意力机制实现,由L个相同层组成,每一层主要由多头自注意力层(Multi-Head Self Attention,MSA)和多层感知器(Multi-Layer Perceptron,MLP)2 个组件组成。其中,多层感知器由2 个全连接层和中间的GeLu 激活函数组成,2 个组件均采用残差结构,并在前端使用层归一化。MSA 和MLP 的表达式分别如式(2)和式(3)所示:


图2 自注意力编码单元结构Fig.2 Structure of self-attention encoder unit
图2(b)所示为多头自注意力层,是自注意力编码单元的核心组件,由线性层、自注意力头、连接层及最后的线性映射层组成。自注意力头通过计算图像嵌入序列中每个元素与其他元素的相关性,从而完成自注意力计算。计算方法如下:首先,自注意力头将嵌入图像序列z0中的每个元素与3 个可学习的自注意力权重矩阵(Wq,Wk,Wv)相乘(如式(4)所示),生成(q,k,v)3 个值,通过计算(q,k,v)的点积学习自注意力权重;然后,自注意力头计算嵌入图像序列中元素q向量与其他元素k向量之间的点积,确定该元素与其他元素的相关性,再将点积的结果缩放后送入softmax(式(5)),其中缩放因子Dk为注意力权重矩阵Wk的维度;最后,自注意力头将嵌入图像序列所有元素的v向量乘以softmax 的输出,获取注意力得分最高的序列,完成自注意力计算(式(6))。多头自注意力层采用12 个自注意力头堆叠而成,并行执行以上自注意力计算过程,并将结果拼接后通过可学习的线性映射层投影到高维空间(式(7))。

1.2.2 自注意力混合融合模块
令xi为分支i的嵌入图像序列(包括类别向量和嵌入向量),i表示分支L或者分支S,分别表示i分支的类别向量和嵌入向量。为有效获取多尺度特征,自注意力混合融合模块首先将每个分支的类别向量作为标识,与另一分支的嵌入向量进行自注意力计算,再投影回所属分支。由于类别向量已经在所属分支的所有嵌入向量中学习到充分的语义信息,因此与另一个不同尺寸分支的嵌入向量进行自注意力计算可以学习该分支不同尺度特征,实现多尺度特征融合。类别向量在与另一分支融合多尺度特征后,在下一个自注意力编码单元中可以将从另一分支学习到的语义信息传递给所属分支的嵌入向量,丰富所属分支的语义信息。主、副分支以相同方法进行自注意力融合过程,如图3 所示为主分支L的自注意混合融合模块,下面将以图3 为例详细分析融合过程。

图3 自注意力混合融合模块Fig.3 Self-attention fusion module

其中:fL(·)为线性投影函数,能够将主分支类别向量经过线性投影变换至副分支嵌入向量形状。然后,将相乘(如式(9)所示),生成(q,k,v)。最后,计算向量q和向量k的点积并将其送入softmax 函数中,再将结果与向量v相乘,获得融合后的类别向量CA(x'L),完成自注意力融合计算,该过程的计算表达式如式(10)所示:

2 实验结果与分析
本节验证本文提出的基于完全自注意力的水电枢纽缺陷识别方法的有效性。首先,设计一系列消融实验评估多尺度自注意力编码单元和自注意力混合融合模块的性能;然后,调整多尺度自注意力编码器超参数,测试本文方法不同体积模型的性能;最后,与一种机器学习方法和3 个经典深度卷积网络进行对比实验。
2.1 数据集
本实验选取的缺陷数据集由清华四川能源互联网研究院提供,通过坝面无人机[18]和隧洞机器人[19]搭载多种传感器在四川某水电站坝面、引水隧洞、泄洪洞、消力池廊道等枢纽结构处采集数据。数据集共有18 605 张分辨率为224×224 像素的RGB 图像(如表1 所示),包含无损、裂缝、渗漏、露筋和脱落5 个类别,每个类别包含3 700 余张图像样本,所有样本均由水利专家进行标注。实验过程中训练集、验证集、测试集的比例为8:1:1,其中验证集和测试集采取不放回随机抽取策略,抽取完成后剩余的数据组成训练集。

表1 数据集分布Table 1 Distribution of dataset
2.2 实验环境及方法
为了对本文方法的有效性进行合理评估,所有实验硬件、软件环境和实验方法均保持一致。
硬件环境:中央处理器(Central Processing Unit,CPU)和图像处理器(Graphics Processing Unit,GPU)分别为Intel®Xeon®CPU E5-2620 v4 @ 2.10 GHz 和2 块NVIDIA GTX TITAN Xp,24 GB;系统内存是32 GB。
软件环境:操作系统采用Ubuntu18.04;编程语言为Python 3.6;深度学习框架为Pytorch 1.8.0、CUDA 10.2。
训练参数:优化器采用学习率为0.000 1 的Adam 方法,使用预热的方法动态调整学习率,批处理大小为32。
2.3 训练图像预处理
针对水电枢纽缺陷图像亮度差异大、背景干扰噪声复杂、获取难度高、可用图像少等问题,本文采用随机亮度调整、翻转、擦除、混合和剪切混合[20]共5 种图像增强增广策略处理训练集图像,为网络提供具有挑战性的样本,提高模型泛化能力。针对训练集中每张缺陷图像,以上5 种图像增强增广策略独立发生,发生的概率为0.5,训练集中5 类原始缺陷图像共计14 889 张,经图像增强增广策略后,增加缺陷图像共计37 222 张,最终训练集缺陷图像共计52 111 张。验证集和测试集不进行图像增强增广操作。
图4 所示为各类典型样本的预处理效果,图4(b)和图4(c)分别为随机亮度调整和翻转操作,分别属于常用颜色空间变换和几何变换的图像预处理方法。
生病时,每个人都想在能力范围内找到最合适的治疗方案,尽早摆脱疾病的困扰。但因看病耗时费力等现状,让很多患者习惯在就诊前托熟人、选医院、寻良药……其实,有很多顾虑都是我们的心理作用,有时,我们大可不必“小题大做”,按常规诊治,照样可以找回健康。

图4 各类典型样本的预处理效果Fig.4 Pretreatment effect of various typical samples
图4(d)所示为擦除操作,将缺陷图像中的随机区域替换为随机大小的黑色像素。该方法鼓励模型从缺陷图像全局的上下文中学习,而不依赖于特定局部特征,可有效缓解缺陷识别过程中的遮挡问题。图4(e)所示为混合操作,将2 个同类缺陷图像进行线性组合,生成新的训练样本。该过程的表达式如式(11)所示:

设(Xi,yi)和(Xj,yj)是从训练集中随机抽取的2 个样本,将2 个样本进行线性插值,获得新样本,以增强模型应对水电枢纽缺陷识别中复杂背景干扰噪声的鲁棒性。
图4(f)所示为剪切混合操作,将缺陷图像中随机区域替换为同类别另一张缺陷图片相同大小区域。上文提到的擦除方法会出现隐藏缺陷对象重要部分的情况,在一定程度上会导致缺陷特征信息丢失,但使用剪切混合方法可以缓解该问题。
2.4 实验评价指标
为评估本文方法的性能,实验采用宏查准率Pmacro、宏召回率Rmacro和宏F1 分数Fmacro作为评价指标,其表达式如下所示:


其中:n为缺陷类别数量;NTPi是第i类中正确预测的缺陷类别个数;NFPi是第i类中错误预测i类缺陷为其他类别的个数;NFNi是第i类中错误预测其他缺陷为i类缺陷的个数;Pi是第i类的查准率;Ri是第i类的召回率;Fi是第i类的综合度量指标(F1s)。
2.5 训练过程及结果分析
交叉熵表示2 个概率分布之间的距离,本文模型采用交叉熵损失计算网络预测值与真实值之间的距离,图5 所示为本文网络在训练过程中训练损失和验证损失的变化情况。从训练过程中训练损失和验证损失的变化情况来看,本文模型在训练过程中损失迅速衰减,在60 个训练轮数后基本稳定收敛,宏查准率最高达98.87%,模型没有出现明显的过拟合现象,具有良好的泛化性能和稳定的识别能力。

图5 训练过程中损失衰减和准确率变化曲线Fig.5 Curve of loss attenuation and accuracy change during training

表2 本文方法的缺陷识别混淆矩阵Table 2 Confusion matrix of defect recognition of method in this paper
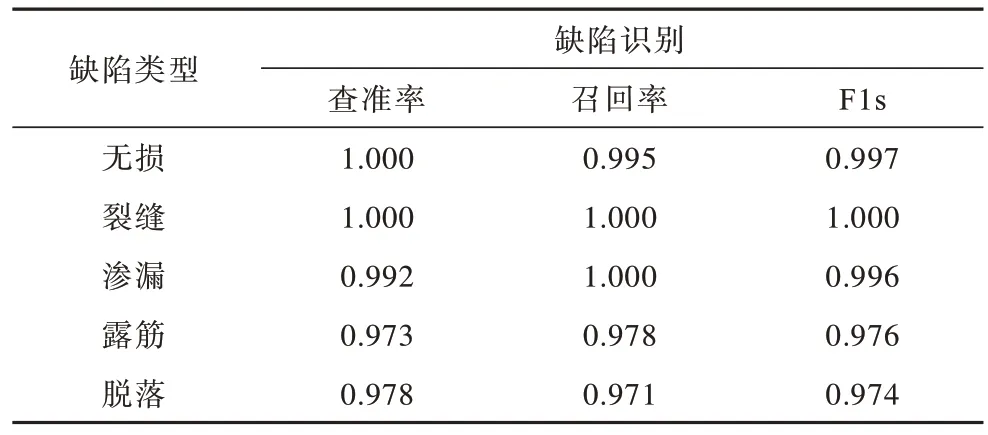
表3 本文方法的缺陷识别指标Table 3 Defect recognition index of method in this paper
2.6 消融实验
为验证本文提出的各项改进方法对模型性能的影响,在VIT-Base 的基础上逐个添加本文提出的系列改进方法,实验结果如表4 所示。其中,单独测试自注意力混合融合模块性能时,仅使用主分支通路,将当前自注意力编码单元的类别向量与上一级自注意力编码单元的嵌入向量送入自注意力混合融合模块,输出网络预测结果,以验证自注意力混合融合模块的有效性。

表4 不同改进方法对模型性能影响的评估结果Table 4 Evaluation results of the impact of different improvement methods on model performance %
从表4 可以看出,与改进前的VIT-Base 相比,多尺度自注意力编码单元的评价指标Pmacro、Rmacro和Fmacro分别提升了3.07、2.98、3.15 个百分点;自注意力混合融合模块的Pmacro、Rmacro和Fmacro指标分别提升了0.84、1.27、1.25 个百分点;在多尺度自注意力编码单元的基础上,自注意力混合融合模块的Pmacro、Rmacro和Fmacro指标分别提升了4.21、4.20、4.28 个百分点;多尺度自注意力编码单元与自注意力混合模块级联作用贡献最大,相比于VIT-Base 方法,其Pmacro、Rmacro和Fmacro指标分别提升了7.28、7.18、7.43 个百分点。此外,本文方法宏查准率达98.87%,充分说明本文方法对水电枢纽缺陷的识别效果有针对性提升。
为探究本文方法的实时性相关指标,本文从模型参数量、模型存储大小、计算量和推理时间4 个方面进行测试评估。本文方法通过调整多尺度自注意力编码器的超参数测试网络不同体积的版本。具体地,TSDR-M 是小型版本,采用1 个多尺度自注意力编码器,主分支嵌入向量深度为384,副分支嵌入向量深度为192,自注意力头的数量为6;TSDR-B 是中型版本,采用3 个多尺度自注意力编码器,主分支嵌入向量深度为768,副分支嵌入向量深度为384,自注意力头数量为12;TSDR-L 是大型版本,采用6 个多尺度自注意力编码器,主分支嵌入向量深度为768,副分支嵌入向量深度为384,自注意力头的数量为12。
从表5 可以看出,针对尺寸为224×224×3 的输入图片,本文方法的大型版本模型参数量和计算量为VIT-Base 方法的1/4,推理时间降至3.37 ms,且获得最高宏F1 分数98.87%;本文方法小型版本的模型参数量为2×106个,推理时间仅需1.51 ms,且识别效果优于VIT-Base 方法。实验结果表明,本文方法能满足水电枢纽缺陷识别工程现场较高的实时性要求,具备一定的工程应用价值。

表5 本文方法的缺陷识别指标Table 5 Defect identification index of method in this paper
2.7 对比实验
经典的机器学习分类方法需要手动选择图像特征,如支持向量机(Support Vector Machine,SVM)[21];卷积架构的深度学习方法通过堆叠卷积层自动提取特征,如ResNet-50等。为进一步验证本文方法的有效性,将本文方法与SVM、ResNet-50[22]、MobileNet v3[23]和改进的Inception v3[5]等经典缺陷识别方法进行对比实验。为保证实验的客观性,SVM 相关实验采用简易的SVM 机器学习库SVMUTIL,该数据库包括特征提取算法和用于图像分类的SVM;ResNet-50 和MobileNet v3 实验部分采用Pytorch 官方网络实现;改进的Inception v3 与本文方法使用同一个数据集,并在本文环境下进行网络复现。
由表6 可知,SVM 方法对无损和裂缝2 个类别识别较好,但对脱落、露筋、渗漏识别精度非常低,Fmacro为58.94%。

表6 SVM 方法的缺陷识别结果Table 6 Defect identification results of SVM method
由表7 可知,ResNet-50 对无损、裂缝和露筋3 个类别识别较好,但对渗漏和脱落识别精度较低,Fmacro为85.04%。

表7 ResNet-50 方法的缺陷识别结果Table 7 Defect identification results of ResNet-50 method
由表8 可知,MobileNet v3 对无损、裂缝和露筋3 个类别识别较好,但对渗漏识别精度较低,对脱落识别最差,Fmacro为92.86%。

表8 MobileNet v3 方法的缺陷识别结果Table 8 Defect identification results of MobileNet v3 method
由表9 可知,改进的Inception v3 对5 个类别识别效果均较好,识别精度超90%,但对脱落和露筋两项重大缺陷的识别精度不够高,对露筋识别最差,查准率为92.1%,Fmacro为96.88%。

表9 改进Inception v3 方法的缺陷识别结果Table 9 Defect identification results of the improved Inception v3 method
由表10 可知,SVM 方法的缺陷识别精度最低,主要原因是SVM 通过手动选择图像特征,不能有效提取图像特征,无法获得好的识别效果。ResNet-50缺陷识别精度高于SVM 方法,主要原因是水电枢纽缺陷图像具有相似干扰噪声大、背景特征复杂、尺度变化大等特点,深度卷积网络通过堆叠卷积层构建网络,并自动提取特征,能有效缓解背景噪声干扰。MobileNet v3 通过神经结构搜索构建网络,结合特征通道注意力,加强网络学习能力,从而提高深度卷积网络缺陷识别性能。改进的Inception v3 方法针对水电枢纽缺陷特点进行改进,以适应缺陷识别场景,获得了较高缺陷识别指标。以上基于卷积架构的缺陷识别方法虽然取得了一定的缺陷识别效果,但由于卷积架构不能充分获取长距离全局依赖信息,易受到局部特征干扰,无法获得更好的缺陷识别效果。本文提出基于完全自注意力的水电枢纽缺陷识别方法,充分利用自注意力机制对长距离依赖关系的强大捕捉能力,通过多尺度自注意力编码单元提取全局语义特征,在全局视野上有效识别缺陷。此外,通过自注意力混合融合模块提取多尺度语义信息,有效缓解了缺陷图像形态多样、尺寸变化大的问题。在训练过程中,使用一系列图像增强增广策略增加样本多样性,提高了模型的泛化能力。

表10 不同缺陷识别方法的macro-F1s 指标比较Table 10 Comparison of macro-F1s index of different defect identification methods %
3 结束语
本文提出一种基于完全自注意力的水电枢纽缺陷识别方法,采用双分支结构的多尺度自注意力编码单元挖掘缺陷图像长距离的全局信息,增强全局语义表达能力。通过自注意力混合融合模块融合2 条分支的多尺度特征,有效缓解缺陷尺度差异大等问题,提升缺陷识别精度。实验结果表明,本文方法的缺陷识别效果优于SVM、ResNet-50、MobileNet v3等主流缺陷识别方法,宏查准率达98.87%。但本文所采用的位置编码方法只能编码固定大小的图片,无法实现不同尺寸图片的输入,下一步将通过嵌入卷积层实现编码目的,并利用卷积操作收集图像块之间的位置信息,从而实现不同尺寸图片的输入。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
学生天地(2019年28期)2019-08-25 08:50:54
数学物理学报(2018年1期)2018-03-26 08:16:36
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
太空探索(2016年5期)2016-07-12 15:17:55
时代英语·高三(2014年5期)2014-08-26 17:01:17
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:30
疯狂英语·口语版(2013年1期)2013-01-31 09:23:26
