
基于压缩与精化深度体素流模型的视频插值
2022-09-15 06:59茹妞妞于晋伟杨卫华
计算机工程 2022年9期
茹妞妞,于晋伟,杨卫华,卞 玮
(太原理工大学 数学学院,太原 030000)
0 概述
视频插值技术是在序列中的实际帧之间合成中间帧,使得实际拍摄的视频帧满足高时间分辨率的要求。它作为计算机视觉任务的基础工作,已被广泛应用于包括帧速率转换、慢动作生成和新视图合成的各项衍生技术中。
在实际场景中,复杂运动、遮挡和光照变化情况下的视频帧很难以固定方式估计,而光流估计是通过光流逆向扭曲输入帧来计算中间帧,能够解决视频运动估计准确率低的问题。该方法依赖于光流估计的准确性,当估计不准确时,合成的中间帧容易出现伪影。文献[1]探究光流的变化,通过计算输入图像中的路径,将像素梯度沿路径复制到插值图像中,并进行泊松重建。文献[2]采用基于欧拉-相位方法进行插值,但该方法仅限于动作幅度小的运动。文献[3]将两个输入帧引入到卷积神经网络中,以合成中间帧,但图像出现了严重的模糊现象。文献[4]构建一种基于空间和时间上的3D 深度体素流插值模型。该模型参数量较少且模糊度低。文献[5-6]提出使用空间自适应内核对输入帧进行卷积。这种模型合成的中间帧精度较高,但其按像素位的计算模式会带来较大的参数量和运算量,并且感受野受卷积核大小的限制。文献[7]扩展了自适应内核,同时估计卷积核权重和像素位置偏移量,扩大了卷积核的感受野区域。文献[8]通过双向光流估计扭曲输入帧,并使用深度网络处理遮挡效应,但对输入帧的质量要求很高。文献[9]将光流估计、视频插值方法、内容提取相结合,并检测深度信息以处理遮挡效应。这类模型依赖于卷积内核的局部特征,无法处理超出矩形内核区域中动作幅度较大的运动,且参数量较大使其不适用于在移动端的部署。
本文提出基于压缩与精化深度体素流的视频插值模型。通过对深度体素流模型进行预训练,利用稀疏压缩技术增大权重矩阵的稀疏度,同时计算卷积权重的稀疏度并得到对应卷积裁减后输入输出的通道数,构建精体素流网络,并对体素流进行精细化处理,从而提高中间帧质量。
1 网络构建
本文模型的构建流程分为4 个步骤:1)预训练深度体素流(Deep Voxel Flow,DVF)模型,使其具有较高质量的插值效果,并确定高精度参数;2)基于训练好的模型参数,利用稀疏压缩技术来增加权重矩阵的稀疏度,即为卷积权重设置ℓ1损失;3)计算卷积权重的稀疏度并求得对应卷积裁减后的输入输出通道数;4)在裁减后的体素流上增加精体素流模型,并重新训练新模型。本文模型的构建流程如图1所示。

图1 本文模型的构建流程Fig.1 Construction procedure of the proposed model
1.1 模型预训练
本文对深度体素流模型[4]进行预训练。深度体素流模型将前后输入帧(以I0和I1表示)输入到U-Net 网络中,并输出3D 体素流F=(Δx,Δy,Δt)。其中,Δx,Δy,Δt分别为空间两个维度及时间维度的偏移量。利用3D 体素流F的空间分量分别定义前后输入帧对应的位置坐标L0=(x-Δx,y-Δy),L1=(x+Δx,y+Δy),并将时间分量用于前后两帧图片的线性混合权重。在视频插值过程中,通过归一化双线性插值计算两帧图片I0,I1对应位置L0,L1上的像素值,并根据时间分量进行线性插值。该过程等价于三线性插值运算Tx,y,t合成中间帧It的估计ˉI t=Tx,y,t([I0,I1],F)。
深度体素流模型预训练的目的是更新参数。在模型预训练过程中,本文采用深度体素流模型中的参数以及对应的损失函数进行训练。当模型性能稳定时,本文终止模型参数的更新,并保存最优迭代时的参数用于压缩,记预训练好的模型为D0。
1.2 稀疏化模型参数
深度体素流模型的参数主要集中在U-Net 网络的卷积核中,因此,本文对其通道数进行压缩[10]。压缩方法是在预训练模型的损失函数中增加卷积权重的ℓ1范数稀疏与正则化损失函数,解决最小化问题[11],如式(1)所示:

其中:f(·)为深度体素流模型的损失函数;λ>0 为正则化系数;θ为模型的参数。合理选择正则化系数可以有效提高稀疏度。本文采用基于正交的随机优化算法OBPROXSG[12-13]来调节正则化系数λ,与其他求解器相比,该算法能够有效增大稀疏度,并且小幅度地降低回归性能[14]。在稀疏化过程中,如果稀疏度在4 个迭代周期后不再下降,则认为稀疏度饱和并停止训练。
1.3 模型参数裁减
本文在获得模型的稀疏参数解后,根据稀疏度裁减模型D0中的每层卷积参数[15]。对于最后一层卷积层ConvL,参数个数。由压缩后的模型计算卷积权重的稀疏度sL,即零权重参数的占比,以及密度dL=1-sL,将输入通道数裁减为。根据卷积输入输出通道数的前后一致原则,并且以此类推到第一层卷积。因此,压缩步骤根据每个卷积层的密度比来裁剪内核通道数,以重新构建一个小网络,并从后到前进行。在压缩过程中,模型中间帧的质量随着总体密度的变化情况如图2 所示,折线上方为峰值信噪比(Peak Signal-to-Noise Ratio,PSNR),下方为密度率。从图2 可以看出,随着密度率的降低,合成质量会有小幅的降低,表明稀疏度的提高不会对模型的合成质量产生显著影响。

图2 合成质量随稀疏度的变化曲线Fig.2 Variation curve of synthetic quality with sparsity
1.4 精化深度体素流模型
模型参数压缩能够有效减少模型参数量和训练成本。而深度体素流模型难以保留图像的边缘细节信息,其原因为仅通过一个U-Net[16]网络计算体素流,未充分捕获运动的边缘信息。为解决该问题,本文提出由粗到精的体素流网络,通过对体素流进行精细化处理,以提升模型对边缘信息的捕获能力,从而提高中间帧的质量。
精化深度体素流模型架构如图3 所示,包括粗体素流网络、粗信息拼接、精体素流网络3 个部分。网络以前后两帧作为输入,通过两层U-Net 网络逐步提取精体素流,最后由精体素流插值合成中间帧。

图3 精化深度体素流模型架构Fig.3 Architecture of refined deep voxel flow model
1.4.1 粗体素流网络
粗体素流网络取自裁剪卷积通道参数后深度体素流模型中的U-Net 网络,具有较少的参数量和提取体素流的能力。U-Net网络结构如图4 所示,具体参数设置如表1 所示。
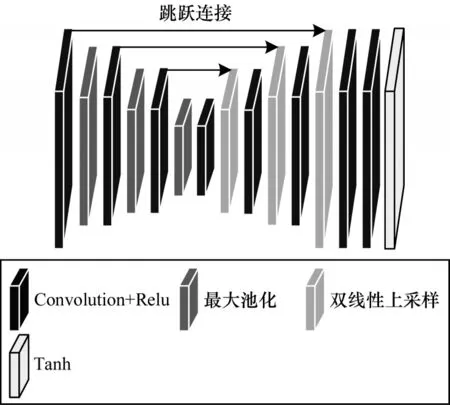
图4 U-Net 网络结构Fig.4 U-Net network structure
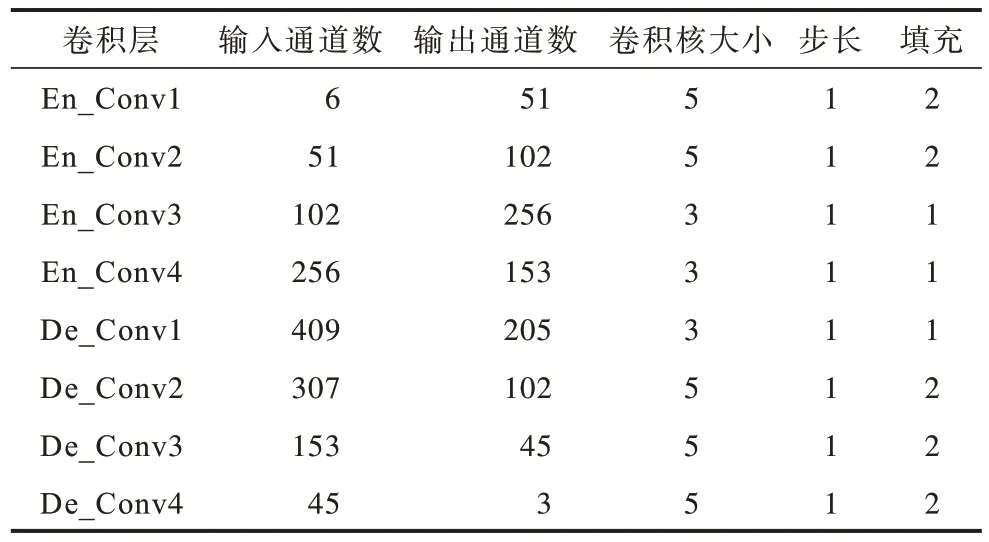
表1 U-Net 网络参数设置Table 1 Parameter settings of U-Net network
U-Net 网络是一个U 型结构的编码器-解码器卷积网络。编码器采用金字塔模型对输入图片进行下采样,解码器同样采用金字塔模型进行上采样,并在编码器和解码器的对应层中添加跳跃连接。U-Net 网络的最后一层是tanh 函数,将体素流F的三个成分规范化到-1~1,便于三线性插值处理。本文选取最大池化进行双线性上采样,以避免产生棋盘状伪影。模型的前后输入帧经过粗体素流U-Net 网络得到初步的体素流,并将其称为粗体素流F′。粗体素流F′将在之后模型中进行修正,得到精体素流。
在得到粗体素流后,本文采用深体素流模型的三线性插值方法合成粗中间帧。其目的在于为精化体素流网络提供训练的原材料。与文献[8]的方法不同,本文未选取在前后两帧上的双线性插值图像作为训练原材料,其原因为以下3 个方面:1)粗中间帧使用了空间偏移量,具有约束体素流中空间成分的可能性;2)粗中间帧可通过均方误差确保初步生成质量;3)输入精体素流网络的维度(3 维)低于采用两张插值图片的维度(6 维),能够减少后续卷积层输入的通道数和参数量。
1.4.2 粗信息拼接
粗信息拼接的作用是整合粗粒度信息,并将其作为精提取的材料。这是由于精体素流网络需要额外的输入信息修正粗体素流,以捕获边缘信息。本文在通道维度上拼接前后输入帧、粗插值帧和粗体素流,以拼接后的信息作为精体素流网络的输入。粗体素流将调整前后输入帧与粗中间帧的边缘信息差异[17-18],至此,完成了体素流的粗
提取流程。
1.4.3 精体素流网络
精体素流网络用于处理粗信息拼接后的材料,并修正获得精体素流。精体素流网络采用与粗体素流网络中卷积通道数相同的U-Net 网络,但不共享卷积权重参数。这样的选取不会大幅增加模型的参数量,使得模型具有轻量级。此外,在精体素流网络的编码器中,在第一个卷积层中使用7×7 卷积核,其余部分和解码器的超参数设置与粗体素流网络相同。
在精体素流网络中,粗体素流捕获前后输入帧与粗插值帧的差异,并调整运动的边缘细节信息[19]。精体素流网络输出粗体素流的修正ζ,即增加跳跃连接[20]使得,以提高模型精度。基于精体素流对前后输入帧进行三线性插值,以得到精中间帧。
1.5 网络训练
本文构建完成精化体素流网络后,重新开始训练模型,给定前后输入帧I0和I1,以及真实中间帧It。本文选取的损失函数l是四项的线性组合,如式(2)所示:

重构损失lr模拟合成中间帧的重建度,如式(3)所示:

这种重建损失定义在RGB 空间中,其中像素值在[0,255]范围内浮动。
粗重构损失λr'约束粗体素流的网络重构效果,确保粗体素流空间、时间成分的正确性以及初步的重构效果。粗重构损失λr'如式(4)所示:

感知损失lp保持预测帧的细节信息和锐度,缓解合成的中间帧模糊现象的发生。感知损失lp如式(5)所示:

其中:ϕ(·)为ImageNet 预训练VGG16 模型的Conv4_3的特征。
平滑损失ls均化相邻体素流的变化率,使得相邻像素具有相似的体素流值。平滑损失ls如式(6)所示:

权重依据经验设置为λr=102,λr'=51,λp=0.05,λs=0.1。其中λr/λr′=2,使得网络训练能够降低重建损失,以达到精化体素流的目的。
2 实验与结果分析
2.1 实验数据集与预处理
Vimeo 90K[21]是一个大规模、高质量的视频数据集。该数据集包含从vimeo.com 下载的89 800 个视频剪辑,其中涵盖各种场景和动作,并广泛应用于时间帧插值、视频去噪、视频解块和视频超分辨率重建领域中。
UCF101[22]数据集是由中央佛罗里达大学提供的开源数据集。数据集采集自YouTube 网站,每个视频时长不等,主要包括人与物体交互、单纯的肢体动作、人与人交互、演奏乐器、体育运动五大类动作。
本文选用Vimeo 90K 数据集进行模型预训练与训练,并在Vimeo 90K 和UCF101 数据集上进行测试。训练集与测试集划分比例为7∶3,并从UCF101数据集中随机选取1 000 组数据进行测试。所有图像的尺寸均剪切为256×256 像素。在训练前,本文对数据集中的图像随机进行数据增强,包括翻转、剪切、旋转、模糊和平移。
2.2 实验配置
本文实验操作系统环境为Ubuntu20.04.2 LTS,CPU 型号为Inter®Core ™i9-190900K,GPU 型号为NVIDIA GeForce RTX 3090,GPU 软件加速环境为CUDA11.1 和CUDNN8.05,并通过Pytorch 框架及Python3.7 编程语言实现。
本文采用SDG 优化算法训练网络,学习率初始设置为0.001。学习率调整策略采用阶梯法,共设置400 个迭代次数epoch,下降间隔设置为100,学习率调整倍数γ设置为0.1。
2.3 实验基准模型
本文选取的基准深度学习模型主要有以下4 个:1)SepConv 模型,采用2 个1D 卷积核拟合1 个2D 卷积核的方式计算每一个像素的2D 卷积核,以合成中间帧;2)DVF 模型,通过卷积神经网络计算体素流,同时进行三次线性插值得到中间帧;3)Super SloMo 模型,采用2 个U-Net 网络计算双向光流及遮挡掩码插值,以合成中间帧;4)CDFI 模型,在自适应卷积AdaCoF 基础上引入多尺度特征来改善合成的中间帧效果。
2.4 实验指标
本文通过参数量来对比模型的复杂度,并使用PSNR 和结构相似性(Structural Similarity,SSIM)评估合成帧质量。两类指标越高,合成质量越好。PSNR 的计算如式(7)所示:

其中:n为每一个像素的比特值,取值为8;MMSE为图像X和Y的均方误差。MMSE如式(8)所示:

其中:W和H分别为图像的宽和高。
SSIM 的计算如式(9)所示:

其中:μX(或μY)、σX(或σY)、σX2(或σY2)和σXY分别为图像X或Y的期望值、标准差、方差和协方差;C1、C2和C3为常数。
2.5 性能评估
2.5.1 定量评估
不同模型的评价指标如表2 所示。相比深度体素流模型(DVF),本文模型在UCF101 数据集上PSNR 和SSIM 分别提高1.04 dB 和0.004。因此,本文模型在参数量小幅增加的条件下能够有效提高合成精度。在Vimeo 90K 数据集上,本文模型的PSNR、SSIM 与DVF 模型相比分别提高2.14 dB 和0.026,表明粗体素流的修正能够有效提高合成精度。相比SepConv、Super SloMo 模型,本文模型的评价指标均最优。虽然本文模型的PSNR 略低于

表2 不同模型的评价指标对比Table 2 Evaluation indexs comparison among different models
CDFI 模型,但是本文模型具有较少的参数量。
2.5.2 定性评估
为了定性观察合成中间帧的质量,不同模型的中间帧视觉对比如图5 所示,第二行是5 种模型在方框区域内的局部放大图。从图5 可以看出,SepConv模型中间帧的右上方白点较模糊;Super SloMo、DVF、CDFI 模型的中间帧在前弓处均有不同程度的模糊现象和结构缺失;本文模型不压缩时合成的中间帧合成的中间帧会出现严重的抖动现象。

图5 不同模型的中间帧视觉效果对比Fig.5 Intermediate frame visual effect comparison among different models
3 结束语
本文提出一种压缩驱动的精化体素流视频插值模型,以解决边缘细节信息提取不充分、精度较低的问题。利用精体素流网络学习前后输入帧、粗插值帧、粗体素流的信息差异,以精化体素流,通过参数压缩技术裁减卷积层的通道数,在不增加参数量的同时以充分捕获视频的边缘信息。实验结果表明,相比DVF、SepConv、CDFI 等模型,本文模型能有效提高合成的中间帧质量。下一步将通过结构重参数化技术改进本文模型,在保证轻量级的前提下,使其适用于多帧同时合成的场景。
猜你喜欢
导航定位学报(2022年3期)2022-06-10
家庭医学(2022年3期)2022-04-07
北京航空航天大学学报(2021年9期)2021-11-02
贵州大学学报(自然科学版)(2021年5期)2021-09-26
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
浙江工业大学学报(2019年4期)2019-06-11
中国惯性技术学报(2019年1期)2019-05-21
新生代(2018年16期)2018-10-21
北京航空航天大学学报(2018年1期)2018-04-20
