
基于区块特征融合的点云语义分割方法
2022-09-15 06:58高庆吉李天昊邢志伟刘佩佩
计算机工程 2022年9期
高庆吉,李天昊,邢志伟,刘佩佩
(中国民航大学机器人研究所,天津 300300)
0 概述
随着机器人场景感知实时性、精细程度、感知范围等性能的提高,点云数据可直接用于描述点的位置信息,使得目标位置估计的准确性和鲁棒性得到提高[1],因此,点云数据在环境感知中被广泛应用。其中,对大型场景点云进行语义分割是机器人理解环境并进行进一步加工处理的前提[2]。点云语义分割是指给点云中的每个点赋予特定的语义标签,以帮助机器人更好更快地定位建图或进行目标识别[3]。随着深度相机、激光雷达设备的更新迭代,点云数据的获取更加快速准确,所得点云规模更加庞大,而传统点云分割方法处理效率也逐渐降低。
2017 年,CHARLES 等[4]提 出PointNet 网 络,该网络借助深度学习提取点云特征,形成了点云语义分割网络。PointNet 可以高效地提取点云的全局特征,但在提取局部特征时效果较差。为了学习更丰富的局部结构,针对点云特征提取问题,有研究人员提出了新的神经网络模块,设计出改进的点云语义分割方法,这些方法大致可分为3 类,分别为关键点邻域点云特征聚合法[5]、基于图神经网络的点云特征提取法[6]、基于内核卷积的特征提取方法[7]。上述方法首先在原始点云中选取关键点并通过邻域采样得到关键点周围固定半径内的球形点云集,然后通过图卷积或其他内核提取点云集特征,最终通过点附近点云集特征聚合得到点云中每个点的语义特征。这些方法提升了网络对点云局部特征的提取能力,但大都只能处理数量少、尺度小的点云[8-9],在处理多目标复杂点云时精度和效率无法保证。有研究人员提出可以处理复杂点云分割任务的网络,如PCT[10]结合体素化和点级网络来处理大型点云,SPG[11]在进行神经网络学习前将大型点云投影为图像进行预处理。这两类网络分割精度较高,但预处理和网络计算耗时很大,无法在实时应用程序中进行部署。
对于点云聚合类的方法,需要非均匀采样得到点云中的关键点,并在邻域内搜索相邻点形成点云集,在处理大型点云时需要较高的计算成本;现有的局部特征学习网络大多依赖感受野大小有限的核化或图形构造,无法高效地捕获复杂结构,需要对关键点特征进行多次聚合,提高了网络计算成本。
为了提升大型场景点云的语义分割效率,本文对特征聚合方法进行优化。在点云分割时采用计算复杂度更低的方形网格分割方法,同时设计针对点云区块的特征融合和语义分割网络,将点云分割尺寸作为神经网络的优化参数,使得网络更好地提取点云特征。在此基础上,使用公开数据集从分割速度和精度2 个方面对所提方法的性能进行实验验证。
1 基于区块特征融合的点云语义分割网络
1.1 网络结构设计
基于区块特征融合的点云语义分割网络(Block Feature Fusion Net,BFF-Net)主要关注大型复杂场景,采用区块分割的预处理方法,将分割得到的点云区块输入单独设计的区块点云语义分割网络,使用区块间特征融合的方式提取大型点云特征。
如图1 所示,BFF-Net 的输入为点云数据,点云总点数为N,每个点由直角坐标系下的X-Y-Z坐标描述,形成N×3 的输入矩阵。首先对点云进行方形网格分割得到点云区块集,然后对相邻区点云块采样、坐标变换、组合后得到多个组合区块,从而完成点云预处理。在对每个区块进行语义分割时,将包含目标区块的组合区块点云数据输入到点云区块特征融合网络(Block Feature Net,BFN)中,得到目标区块的全局特征修正向量。将目标区块的点云数据和全局特征修正向量输入到点云语义分割网络并以残差[12]的方式融合得到目标区块点云每个点的语义分类结果。对每个区块重复以上操作即可完成大型场景点云语义分割任务。
1.2 基于方形网格分割的点云预处理
原始点云数据在输入网络计算前需要方形网格分割、组合、坐标变换预处理,最后得到分别用于点云特征融合和语义回归网络的两组点云集。点云预处理过程如图2 所示。
点云预处理的具体过程如下:
1)点云区块分割
在点云分割时,将原始点云P向地面投影,用方形网格分割点云P,方形网格中正方形边长为d。点云P被划分到m1个区块中,形成点云区块集。点云区块数量为:
其中:l为方形网格X方向的网格个数;w为方形网格Y方向的网格个数。
2)点云区块组合
为了提取融合不同区块点云的特征,需要组合点云区块。在组合前,对每个点云区块中的点云随机采样[5],采样点数量为n1,以3×3 的方式组合分割时相邻的点云区块,形成m2个点云组合区块:

3)点云区块坐标变换
在进行单个区块点云的语义分割前需要将坐标原点移至区块和组合区块的中心:

其中:pi为坐标变换前点云中每点的X-Y-Z坐标;p'i为坐标变换后每点的坐标;pmid为目标区块正方形中心点的坐标,其Z轴坐标为0。
点云预处理通过网格分割、采样、组合、坐标变换,原点云被处理后得到点云区块集B1和点云组合区块集B2。
1.3 基于PointNet 的点云特征提取网络
将点云特征提取网络PFN(Point Feature Net)作为基础特征提取网络,如图3(a)所示,PFN 分为位置特征提取网络LFN(Location Feature Net)和全局特征提取网络GFN(Global Feature Net)两部分。点云特征提取网络通过一维卷积模块(Multi-Layer Perceptron,MLP)完成对点云数据的特征提取,如图3(b)所示,特征数据输入到该模块先后经过一维卷积、批标准化(Batch Normalization)、ReLU 整流函数。图3(a)中的MLP(128,512,1024)表示数据先后经过一维卷积通道数分别为128、512、1 024 的MLP 模块。

图3 点云特征提取网络Fig.3 Point cloud feature extraction network
设输入点云矩阵为P,点数为n。位置特征提取网络PFN 通过MLP 模块扩展每个点[x,y,z]三维位置特征,扩展后得到64维特征向量。将每个点并行输入MLP模块进行计算,最终得到n×64 的点云位置特征:
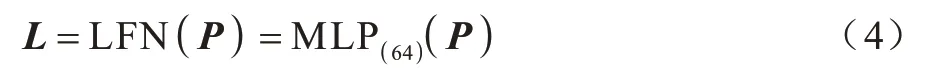
其中:L为点云位置特征。
全局特征提取网络GFN 将位置特征输入到MLP模块进行计算,扩展为n×1 024 的特征矩阵,通过最大池化得到所有点同一特征维度的最大值,得到的1 024维的特征向量即为这组点云的全局特征。由点云位置特征计算得到点云全局特征如式(5)所示:

其中:G为点云的全局特征;MaxPool 表示最大池化层。
点云位置特征矩阵先后经过位置特征提取网络LFN、全局特征提取网络GFN,最终得到全局特征,如式(6)所示:

1.4 点云区块特征融合网络
点云区块特征融合网络通过计算组合后区块点云坐标得到区块和区块间的组合特征,然后融合得到用于修正每个区块点云特征的修正向量。点云区块特征融合网络结构如图4 所示。
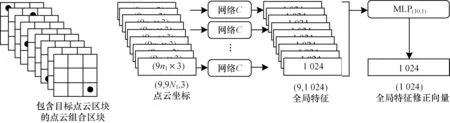
图4 点云区块特征融合网络结构Fig.4 Point cloud block feature fusion network structure
在数据输入到点云区块特征融合网络前,首先选取要进行语义分割的目标点云区块,如图4 所示,图中用带点方框表示目标点云区块,在组合点云区块集B2中,得到包含目标点云区块的9 个组合区块,由于在采样时每个区块的采样数量为n1,因此得到9 个点云组合区块的点云坐标矩阵,每个矩阵的大小为9n1×3,将这9 个矩阵并行输入到同一个点云特征提取网络,即网络C中,得到9 个点云全局特征向量,经过MLP 将其融合为1 个1 024 维的全局特征修正向量,用以修正目标区块点云的全局特征。点云区块特征融合网络可由式(7)表示:
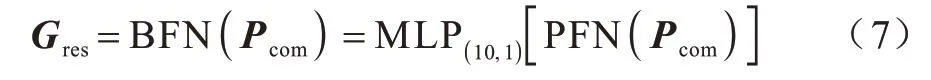
其中:Pcom为点云坐标矩阵;Gres为全局特征修正向量。
1.5 基于残差修正的区块点云语义分割网络
区块点云语义分割网络对目标区块点云的特征进行提取,利用点云区块特征融合网络得到的修正向量修正点云特征,从而得到最终的点云特征,然后通过简单分类网络实现目标区块所有点的语义分类。区块点云语义分割网络结构如图5 所示。

图5 区块点云语义分割网络结构Fig.5 Block point cloud semantic segmentation network structure
区块点云语义分割网络的输入为目标区块的点云坐标矩阵和由点云区块特征融合网络得到的全局特征修正向量,图5 中网络A为位置特征提取网络,网络B为全局特征提取网络。设目标区域的点云数量为n0,则目标区域点云矩阵Ptar可表示为n0×3 的矩阵,依次经过位置特征提取网络和全局特征提取网络,得到目标区块点云的位置特征矩阵Ltar和全局特征向量。其中,全局特征向量与加权后全局特征修正向量矩阵相加,得到修正后的全局特征向量Gtar:

其中:W为加权矩阵。
将修正后的全局特征向量复制n0份得到G′tar,与n0×64 的点云位置特征矩阵拼接形成目标区块的点云特征矩阵Ftar,如式(10)所示,其大小为n0×1 088。最后通过MLP 和Log Softmax 回归得到n0×c的语义概率矩阵,如式(11)所示,其中,c为语义种类数量。至此就完成了区块中所有点云的语义分割。

1.6 交叉熵损失函数
点云语义分割属于针对点的分类问题,本文采用交叉熵乘积[13]作为损失函数,如式(12)所示:

其中:n为神经网络训练过程中每次训练的最小样本数量;yij为第i个样本在第j类上的真实标签;pi,j为第i个样本对第j类的预测概率。
2 分割尺寸自优化验证
在前文中分割开的区块只经过简单的点云特征提取网络就得到每个点的最终特征,然后输入至最后的语义回归层,这样的网络结构降低了网络复杂度,但同时也使得网络的分割精度依赖于合适的分割尺寸。因此,一方面要将场景分割得尽量小,以保证点云特征提取网络对场景局部特征进行提取;另一方面分割又要足够大,以减少目标物体点云结构缺失,最终达到减少分割次数和网络计算时间同时保证分割精度的目的。分割尺寸由方形网格中正方形边长所决定,其作为神经网络中的一个参数,被引入神经网络反向传播优化过程。本文通过实验证明分割尺寸可以在神经网络的优化过程中自优化到最佳值附近。实验采用SemanticKITTI 数据集[14],在每个场景中随机抽取100 帧形成一组小样本实验数据,表1 所示为不同分割尺寸下的网络最终分割结果。

表1 不同分割尺寸下网络的召回率和收敛速度Table 1 The recall and convergence speed of the network under different partition sizes
从表1 可以看出,实验4 具有较少的运算次数和较高的召回率,该分割尺寸最优。
为了验证分割尺寸系数可在神经网络优化过程中自回归到最优值附近,对不同初始参数和尺度变化系数下的网络进行反向传播计算,统计得到100 组分割尺寸和网络分割精度,形成散点图如图6 所示,图中所有实验结果的等效分割尺寸最终都收敛至4.6 m 附近,并在分割尺寸为4.689 m 时点云语义分割网络得到最好的分割精度(0.816),证明分割尺寸可以自优化至最佳值附近。

图6 分割尺寸自优化结果Fig.6 Segmentation size self optimization results
3 对比实验与结果分析
3.1 计算复杂度与耗时对比
PointNet++、RandLA-Net[5]等网络使用点云特征聚合的方法对点云进行多次编码和解码,使网络更好地提取和使用点云的局部特征,但这种特征提取方法需要搜索以关键点为球心的球形邻域内的其他点以形成局部点云,一般建立点云的KD-tree(K-Dimension tree),在网络语义分割计算时使用建立好的KD-tree 进行快速的邻域搜索。
KD-tree[15]是对数据点在k维空间中进行划分的一种数据结构。网格均匀分割(即本文方法)将点云用规则网格进行均匀划分。对于数量为n的点云,构建KD-tree 的计算复杂度为,进行方形网格分割的计算复杂度为O(logan),后者复杂度更低。
在SemanticKITTI 数据集上的分割耗时对比结果如表2 所示,对数据集原始点云分别进行KD-tree建立和网格均匀分割,得到2 种方法处理不同规模点云所用时间,从表2 可以看出,本文网格均匀分割方法的耗时具有显著优势。

表2 点云分割耗时对比Table 2 Comparison of point cloud segmentation time consuming
为了对比不同方法的网络计算复杂度,参考其他论文资料统计不同方法的网络参数量和网络计算耗时,并在相同的GPU 平台下对BFF-Net 网络计算耗时进行测试,测试平台GPU 型号为RTX2080Ti,CPU 型号为Intel®CoreTMi5-7300 CPU@2.50 GHz,结果如表3 所示。从表3 可以看出,相比其他点云语义分割方法,本文方法通过对分割尺寸进行优化,提高了点云特征提取的效率,减少了卷积次数,因此,其网络计算时间最少。SPG 网络[11]虽然参数量最少,但其网络耗时巨大。通过点云预处理和网络计算时间的对比可以得出,在处理点云数为10 万~100 万的大规模点云时,本文方法的点云语义分割速度相较对比方法可提高2~4 倍。

表3 不同方法的网络参数量和网络计算时间对比Table 3 Comparison of network parameters and network calculation time of different methods
3.2 准确率计算方式
IoU(Intersection over Union)[14]是在特定数据集中检测相应物体时,对其准确率进行评估的一个度量标准。针对某一类点云分割,IoU 可由式(13)求得:

在同一数据集下,所有类别的平均IoU 为MIoU,如式(14)所示:

其中:c为类别总数。
3.3 SemanticKITTI 数据集上的准确率对比
SemanticKITTI 数据集[14]是自动驾驶场景下由激光雷达所得的点云数据构成的语义分割数据集。在测试过程中,每个场景序列取70%的场景帧作为训练集,剩余30%作为验证集,初始学习率为0.01,每轮学习率衰减系数为0.9,进行30 轮学习,参考点云分割准确率计算公式对结果进行统计,并与其他方法作对比,结果如表4 所示。从表4 可以看出,本文方法对路面、汽车、地形、卡车、路肩的语义分割结果较好,且对围栏的分割准确率比其他方法高出20%,原因在于围栏是大型物体,分割后的部分围栏容易被误识别为汽车、卡车等含有平面结构的物体,本文点云区块特征融合网络放大了网络的感受野,使得网络对于尺寸较大的物体也能很好地进行语义分割。
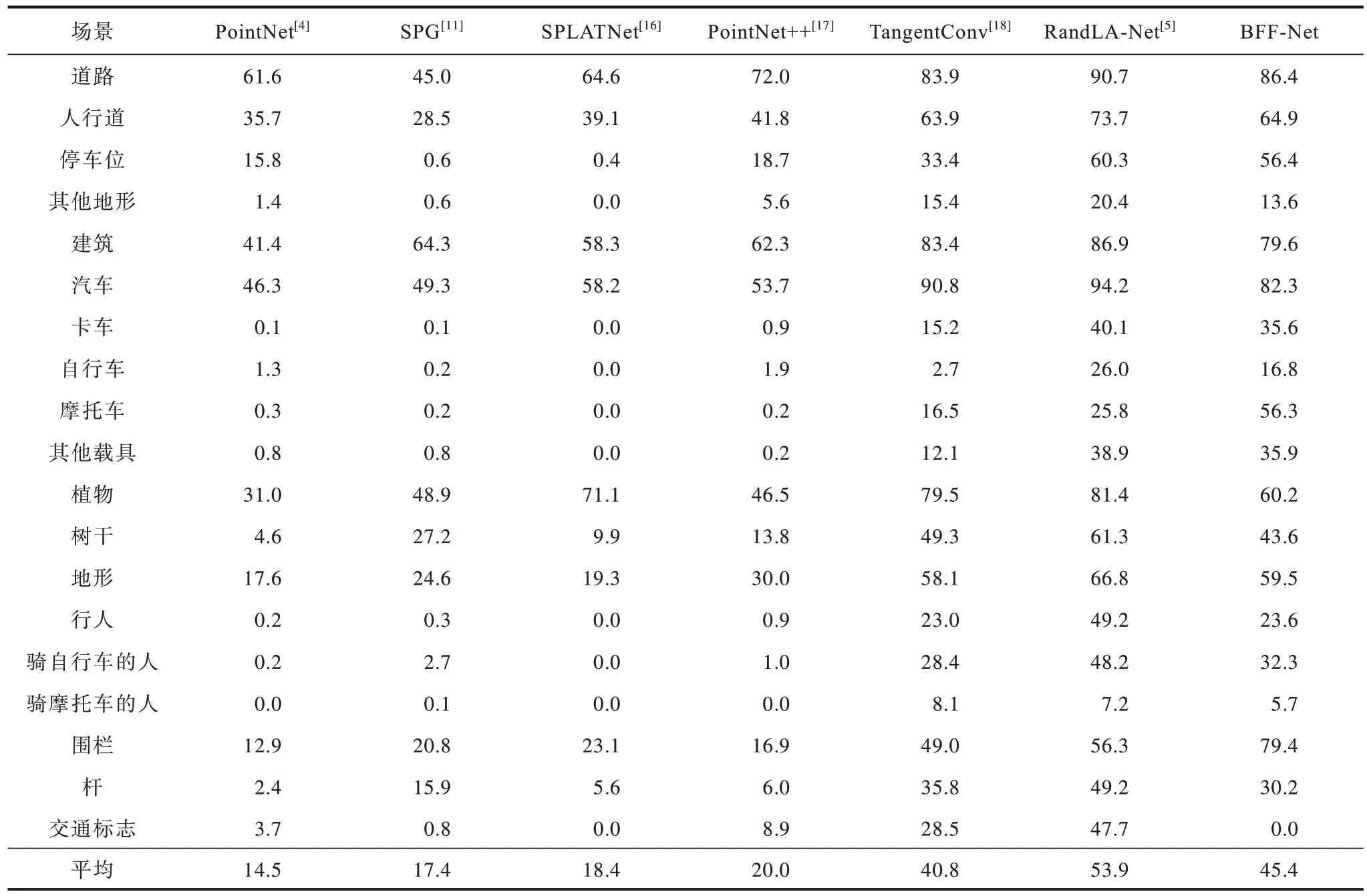
表4 7 种方法在SemanticKITTI 数据集上的测试准确率对比Table 4 Comparison of test accuracy of seven methods on SemanticKITTI dataset %
BFF-Net 与PointNet++采用的基础点云特征提取网络相似,但特征融合方式不同,图7 将这2 种方法处理SemanticKITTI 数据集的结果进行对比,图中用圆圈标出BFF-Net 分割相对正确的目标,可以看出,图中的围栏、路面等大型物体在BFF-Net 方法下分割准确率较高,如c1、c3、c4;对于一个区块中较小的车辆,BFF-Net 方法也可以准确分割,如b4、c4 之间的对比。

图7 2 种方法的点云语义分割效果对比Fig.7 Comparison of point cloud semantic segmentation effects between two methods
3.4 Semantic3D 数据集上的准确率对比
Semantic3D 数据集[19]包含8 个语义类标签,涵盖广泛的城市户外场景,包括教堂、街道、铁轨、广场、村庄、足球场和城堡。在测试过程中,由于场景过于庞大,因此对每个大场景进行分割并做50%的随机下采样,对分割后的场景进行19 轮学习,统计点云分割准确率指标IMoU 结果,如表5 所示。从表5 可以看出,在Semantic3D 数据集下,BFF-Net 方法平均准确率最高,且其对于汽车、硬景观、高植被的语义分割准确率最高。

表5 10 种方法在Semantic3D 数据集上的测试准确率对比Table 5 Comparison of test accuracy of ten methods on Semantic3D dataset %
虽然BFF-Net 方法在室外场景中取得了较好的点云语义分割效果,但在室内场景分割时效果并不理想,原因在于现阶段的BFF-Net 只在2 个维度上对点云进行区块分割和特征融合,当从Z轴方向上分割目标复杂的室内场景时,无法很好地提取点云特征。
BFF-Net 方法适用于平面环境下的点云语义分割任务,可以与SLAM 技术相结合建立环境的语义地图,加快建图和重定位的速度,同时语义分割后的点云可直接分离目标物体点云与背景点云,处理后[27]可以实现三维目标识别。BFF-Net 方法可用于自动驾驶场景,处理后的点云可更好地应用于后续的定位、检测、避障任务。
4 网络不同参数的对比实验
4.1 消融实验
为了更全面地测试BFF-Net 的性能,在由SemanticKITTI 形成的小样本数据集上测试不同网络参数的点云分割结果,如表6 所示。其中,改变的参数包括分割尺寸、组合区块采样点数量、点云语义分割是否加入全局特征修正向量以及目标区块点云密度。在表6 中:实验1~实验4 均使用最佳分割尺寸,在最高点云密度时得到的最高准确率为59.20%;实验5~实验8 加入了全局特征修正向量,点云分割准确率相比同密度下的前4 个实验提升了16.36%~32.18%,说明区块特征融合方法可以显著提高点云语义分割的准确率。

表6 不同网络参数下的运行结果对比Table 6 Comparison of operation results under different network parameters
4.2 点云密度对语义分割准确率的影响
图8 所示为点云密度与语义分割准确率的关系曲线,测试数据集是SemanticKITTI。从图8 可以看出:在平均点云密度大于25 个/m2时,点云分割准确率可以维持在0.65 以上;在平均点云密度低于20 个/m2时,点云分割准确率不足0.5 并剧烈下降。通过多次实验得出,点云密度取24 个/m2时可以在快速计算的同时保证语义分割准确率。

图8 不同点云密度下的分割准确率对比Fig.8 Comparison of segmentation accuracy under different point cloud densities
5 结束语
针对大型场景下点云语义分割计算量较大的问题,本文提出一种基于区块特征融合的点云语义分割方法,使用区块分割的点云预处理方式,针对分割所得到的点云区块设计特征提取网络,利用区块间特征融合的方法提取大型点云特征,从而加快点云预处理和网络计算的速度。公开数据集上的实验结果表明,在处理点数为10万~100万、尺寸跨度近百米的大规模点云时,该方法在保证分割精度的同时,点云语义分割速度较SPG、KPConv 等对比方法可提高2~4 倍。本文所提方法在室外大场景中能够提高点云语义分割的速度和精度,但仅限于Z轴结构简单的点云数据,下一步将利用立方体对点云进行三维区块分割,从而识别规模更大、更复杂的点云场景。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年8期)2022-08-31
开放教育研究(2020年2期)2020-03-31
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
金桥(2018年4期)2018-09-26
北京航空航天大学学报(2016年9期)2016-11-16
