
基于改进YOLOv5s 的交通信号灯识别方法
2022-09-15 06:58邓天民谭思奇蒲龙忠
计算机工程 2022年9期
邓天民,谭思奇,蒲龙忠
(重庆交通大学交通运输学院,重庆 400074)
0 概述
近年来,无人驾驶技术迎来了快速的发展,对无人驾驶场景中行人[1]、交通标志[2]等目标进行检测与识别的研究逐渐增多。交通信号灯在无人驾驶场景中扮演着极其重要的角色,因此,交通信号灯的检测与识别研究具有重要意义。目前基于深度学习的相关研究较少,主要运用两阶段检测和一阶段检测这两类方法。在两阶段检测中,具有代表性的算法有RCNN[3]、Fast-RCNN[4]、Faster R-CNN[5]等。文献[6]设计了一种基于CIFAR-10 的多任务卷积神经网络来对复杂环境下的交通信号灯进行检测,但是网络模型的泛化性和鲁棒性不足。两阶段算法需要进行多次的检测和分类流程,检测速度相对较慢,因而研究者提出了一阶段检测方法,其中具有代表性的算法有YOLO[7-9]、SSD[10-11]、SqueezeDet[12]等。一阶段检测方法的特点是候选框的产生和分类同时进行,一步到位,检测速度相对较快。文献[13]提出了Split-CS-Yolo 算法对交通信号灯进行快速检测与识别,该方法鲁棒性较好但是对黄色信号灯和数字信号灯的检测精度还有待提高。文献[14]对YOLOv3 进行改进,通过在Darknet53 的第2 个残差块中增加2 个残差单元来提高网络对小目标的检测性能,所提出的改进网络能够达到较高的检测精度,但不满足实时性的要求。可见,以上改进方法对交通信号灯的检测效果都不能满足实际需求,在检测速度和检测精度之间难以达到较好的平衡。
本文通过改进YOLOv5s 算法,提升对交通信号灯的识别精度和检测速度。设计一种基于密集连接的CSP 残差模块来替换原网络模型主干网络中的残差结构,使得主干网络能更准确地对信号灯的特征进行提取,进而提高网络的检测精度。同时,设计一种基于多层次的跨连接CSP 残差模块来替换颈部网络中的残差结构,增强网络的特征融合能力。为加快网络模型的检测速度,对检测尺度进行改进,考虑交通信号灯属于小目标的属性,只保留小目标检测尺度。在此基础上,采用巴黎交通信号灯LaRA 数据集进行实验,验证本文方法的有效性。
1 YOLOv5s 网络模型
YOLOv5 网络共有4 个版本,分别为YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。YOLOv5s 是该系列检测网络中深度和特征图宽度最小的网络,其他几个版本的网络都是在此基础上进行加深和加宽的。相比于其他系列的YOLO 检测网络,YOLOv5的权重文件相对较小,权重最小的YOLOv5s 仅27 MB,权重最大的YOLOv5x 也只有170 MB。因此,基于体积小的优势,YOLOv5 非常适合部署到嵌入式的设备中。实现对交通信号灯的检测是无人驾驶的重要环节,而YOLOv5 非常适合应用在交通场景下对交通信号灯进行检测[15]。基于对权重文件大小、识别精度和检测速度的综合考虑,本文选择检测速度较快、识别精度较高的YOLOv5s 进行研究,对其网络结构进行改进。
YOLOv5s 网络结构如图1 所示,其中的主干网络对输入的图像进行了5 次下采样来提取图像的特征,主干网络包含Focus、CBH、CSP1-x、SPP[16]4 种模块。

图1 YOLOv5s 网络结构Fig.1 YOLOv5s network structure
输入YOLOv5s 网络的图像通过Focus 模块进行自我复制,然后进行切片操作,以此来减少网络的计算量,加快对候选区域特征提取的速度。切片的图像通过CBH 模块进行卷积、归一化和激活操作,然后进行特征提取。在特征提取的过程中,CSP1-x 残差结构用于优化网络中的梯度信息,减少推理计算量,加快计算速度。最后,SPP 模块将不同尺寸的输入转换为相同大小的输出,解决输入图像尺寸不统一的问题。YOLOv5 的Neck 网络使用了ReLU 激活函数,采用FPN[17]+PAN[18]网络结构,其中FPN 层通过自顶向下对图像进行上采样,将提取到的特征与主干网络中提取到的特征进行融合。在FPN 层之后,还添加了一个自底向上的特征金字塔结构,用于对图像进行降采样,将提取到的特征和FPN 层提取到的特征进行融合。通过FPN+PAN 网络结构可以对主干网络和检测网络提取的特征进行聚合,增强网络特征融合的能力。此外,Neck 网络中还加入了CSP2-x 结构对提取的特征进行融合。输出端采用CIoU[19]作为Bounding box 的损失函数,并且提供了3 种不同的检测尺度(20×20、40×40、80×80)。
2 YOLOv5s 网络模型改进
2.1 CSPD-x 残差结构改进
YOLOv5s 网络中有3处CSP1-x 结构,该结构借鉴了CSPNet[20]的思路,把基础层的特征映射为2个部分,然后通过跨阶段层次结构进行合并,从而减少计算量和提高运行速度,同时保证精度。CSP1-x 残差结构如图2 所示。

图2 CSP1-x 残差结构Fig.2 CSP1-x residual structure
CSP1-x残差组件的设计借鉴了ResNet[21]网络的设计思想,通过在卷积层之间增加跨连接(Shortcut)方式,减少网络模型的计算量,加快运行效率。跨连接(Shortcut)和CSP1-x残差组件结构分别如图3、图4所示。
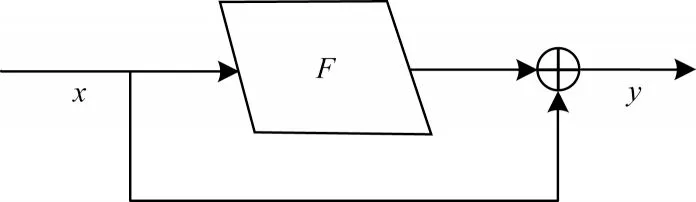
图3 Shortcut 连接Fig.3 Shortcut connection
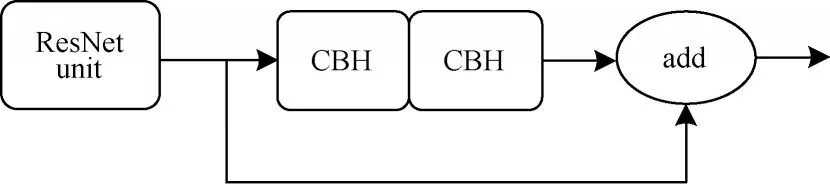
图4 CSP1-x 残差组件结构Fig.4 CSP1-x residual component structure
为了更好地解决梯度发散的问题,文献[22]提出了DenseNet 网络。在DenseNet 中,每两个卷积层之间都添加了跨连接,密集跨连接的方式使得各卷积层获取的特征都能向后进行传递并且相互融合,因此,提取到的特征也更丰富和多样化。DenseNet核心表达式如式(1)所示:

其中:xk表示第k层网络的输出;[x0,x1,…,xk-1]表示将第0 层到第k-1 层网络提取的特征进行合并;Hk表示包括卷积层、归一化层和ReLu 激活函数层的组合方式。DenseNet 结构如图5 所示。

图5 DenseNet 网络结构Fig.5 DenseNet network structure
基于DenseNet 网络结构,本文设计了新的unit组件D-unit(Dense-unit)。D-unit依旧采用1×1 和3×3两种大小的卷积核、归一化层和Hardwish 激活函数层。通过在原来的基础上对每个CBH 模块之间都添加跨连接,使得各个模块紧密连接,从而更好地解决深度网络模型退化问题。D-unit 残差组件结构如图6 所示。

图6 D-unit 残差组件结构Fig.6 D-unit residual component structure
首先,输入的特征信息经过第1 个CBH 模块,该模块含有1×1 大小的卷积核;然后,将卷积后得到的特征信息与输入的信息进行融合输出到第2 个CBH模块进行卷积,第2 个CBH 模块采用3×3 大小的卷积核,能得到与第1 个CBH 模块不同的特征信息;最后,将最开始输入到D-unit 的特征信息与第1 个CBH 模块和第2 个CBH 模块得到的特征信息进行融合,将融合后的特征信息输入到下一个特征提取结构中。
改进后CSPD-x 的残差组件以跨连接的方式将各卷积层进行密集连接,主要是为了防止模型的退化,使得模型可以更快地收敛到最优解。密集连接能够对特征进行重利用,使特征相互融合,而对融合后的特征进行提取能够获得更多的目标信息,提高识别的精度。CSPD-x 结构如图7 所示。
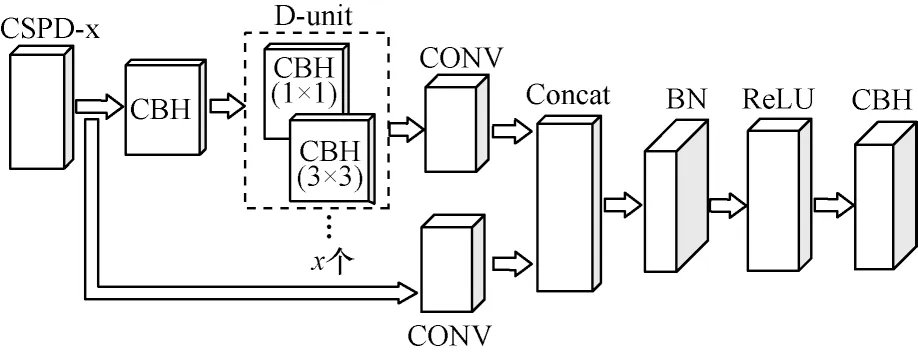
图7 CSPD-x 残差结构Fig.7 CSPD-x residual structure
2.2 CSPS-x 残差结构改进
YOLOv5s 网络中还使用了另一种残差结构——CSP2-x。与CSP1-x 结构不同,CSP2-x 结构主要是对输入的特征图进行卷积,并对所提取到的特征信息进行融合。在CSP2-x 结构中,残差组件的作用仅仅是对输入图像的特征信息进行提取。CSP2-x 残差结构如图8 所示。
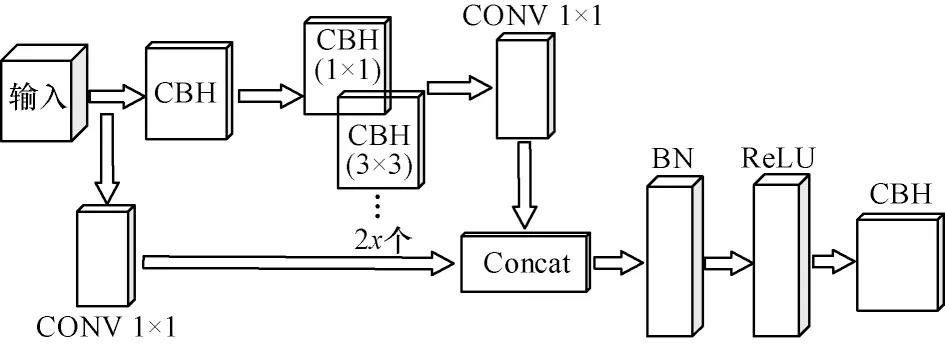
图8 CSP2-x 残差结构Fig.8 CSP2-x residual structure
通过对原残差组件的分析,本文设计了一种新的残差组件S-unit(Shortcut-unit)。该结构由4 个CBH 模块组成,卷积核的大小分别对应为1×1、3×3、1×1、3×3。各个模块之间通过多个跨连接方式相互连接。分别在第1 个和第2 个、第3 个和第4 个CBH模块间加入跨连接,然后再将第2 个和第4 个CBH模块之间进行跨连接。原始输入的特征信息通过第1 个卷积核大小为1×1 的CBH 模块,提取后的特征信息输入到第2 个卷积核大小为3×3 的CBH 模块,将原始输入的特征信息和第2 个CBH 模块所提取到的信息进行融合再输入到第3 个卷积核大小为1×1 的CBH 模块,得到的特征信息和第1 个CBH 模块所提取到的信息融合后输入到第4 个卷积核大小为3×3 的CBH 模块,第4 个CBH 模块输出的结果和第1 个CBH 模块所得到的特征信息融合后再输入到后面的卷积网络层。S-unit 残差组件与原网络残差组件对比如图9 所示。

图9 S-unit 残差组件和原网络残差组件结构Fig.9 S-unit residual component structure and the original network residual component structure
在原结构中,CSP2-x 残差组件的作用主要是对特征图的特征信息进行提取,各卷积层之间的特征信息并没有相互融合,这样会导致随着卷积层层数增加提取到的特征信息部分丢失。此外,原结构直接将各卷积层连接起来,会导致训练时网络模型的退化,且梯度容易发散,难以收敛到最优的结果。CSPS-x 残差结构通过跨连接的方式对各层提取到的特征信息进行融合,有效地解决了特征信息丢失的问题,而且还能防止模型的退化,使得对网络的训练更容易进行。CSPS-x 残差结构如图10 所示。

图10 CSPS-x 残差结构Fig.10 CSPS-x residual structure
2.3 检测尺度改进
原YOLOv5s 网络共有3 种规格的检测尺度,分别为20×20、40×40、80×80。20×20 检测尺度的感受野为32×32 大小的像素区域,主要用于检测大型物体;40×40检测尺度的感受野为16×16 大小的像素区域,主要用于检测中等大小的物体;80×80检测尺度的感受野为8×8大小的像素区域,主要用于检测小型物体。
由于交通信号灯在交通场景下属于较小的目标,因此本文对原YOLOv5s 的3 种检测尺度进行改进,保留40×40 和80×80 这两种针对中小型目标的检测尺度,去除20×20 这一针对大型目标的检测尺度,从而使网络能够更好地处理待检测目标,同时加快网络的运行速度。改进后的网络命名为TL-YOLOv5s,结构如图11所示。
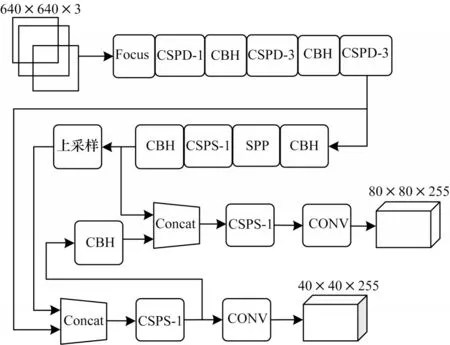
图11 TL-YOLOv5s 网络结构Fig.11 TL-YOLOv5s network structure
3 实验
法国巴黎LaRA 信号灯数据集适用于目标检测研究,且只标注了交通信号灯这一种类别,数据量大,包含的交通场景也非常丰富,因此,本文选用LaRA 信号灯数据集对所提出的方法进行评估。对于实验部分使用的硬件平台,CPU 采用Intel i7-9750H,GPU 采用NVIDAI GTX1660Ti,操作系统为Window10,训练框架采用Pytorch1.6。
3.1 实验数据集
法国巴黎LaRA 信号灯数据集包含9 168 张图片,图片尺寸为640×480像素,包含green(通行)、orange(警示)、red(停止)、ambiguous(模糊)4 种不同类别的标签,数量分别为3 381、58、5 280、449 张。其中,模糊的图片是由于在拍摄的过程中车辆出现抖动所导致。各信号灯种类及标签数量如表1 所示。

表1 LaRA 信号灯数据集中各类目标的数量Table 1 The number of various targets in LaRA signal light dataset
由于数据集中包含的模糊变形的图片会对实验的结果产生较大影响,因此本文对LaRA数据集进行处理,剔除掉449 张模糊变形的图片,使用剩余的8 719 张图片进行实验。数据集图片样本如图12 所示。

图12 LaRA 数据集图片样本Fig.12 Image samples of LaRA dataset
3.2 模型训练
对原YOLOv5s 模型和改进后的YOLOv5s 模型分别进行训练。剔除LaRA 信号灯数据集中模糊的449 张图片和标签,将剩余的图片和标签按8∶1∶1 的比例分为训练集、测试集和验证集,训练阶段初始学习率调整为0.01,训练迭代次数epoch 设定为200 次。在此基础上,通过GPU 对原YOLOv5s 和改进后的YOLOv5s 网络模型进行训练。
3.3 评价指标
本文选取精确率(Precision)、召回率(Recall)、平均精度(Average Precision,AP)、平均精度均值(mean Average Precision,mAP)、帧率(Frames Per Second,FPS)等评价指标[23]对模型性能进行评价。
1)准确率Pprecision和召回率Rrecall的计算公式如下:

其中:TP表示正确检测出的目标数量;FP表示被误检的目标数量;FN表示未被检测出的样本数量。
2)平均精度AAP和平均精度均值mmAP的计算公式如下:

其中:Nc表示类别个数;PA表示不同类别的平均精度。实验结束后利用实验数据可以绘制出网络模型的PR 曲线,该曲线所围成的面积即被定义为AP,用于评估模型在单个检测类别上的表现。计算出每一类的AP 值之后,进行平均即得到mAP。通常来说,mAP 值越高,表示网络模型性能越好。
3)检测速度一般用FPS 来衡量,表示目标检测网络每秒能处理图片的数量,FPS 值越大,表示网络模型处理图像的速度越快。
3.4 实验结果及分析
3.4.1 主干网络残差结构改进实验
原YOLOv5s 主干网络中共有3 处CSP1-x 结构,对其进行替换加入新的结构CSPD-x,然后再对改进后的网络模型和原网络模型分别进行训练,在LaRA数据集上比较2 种网络的检测结果。对改进后模型训练200 个epoch 后损失曲线变化如图13 所示,其中cls_loss、obj_loss 和box_loss 分别代表分类损失、置信度损失和边界框回归损失,由该图可以看出曲线走势基本趋于平稳。

图13 模型改进后的训练损失曲线Fig.13 Training loss curve after model improvement
原网络和改进网络(以CSPD-x 表示)识别各类别的平均精度和平均精度均值如表2 所示。
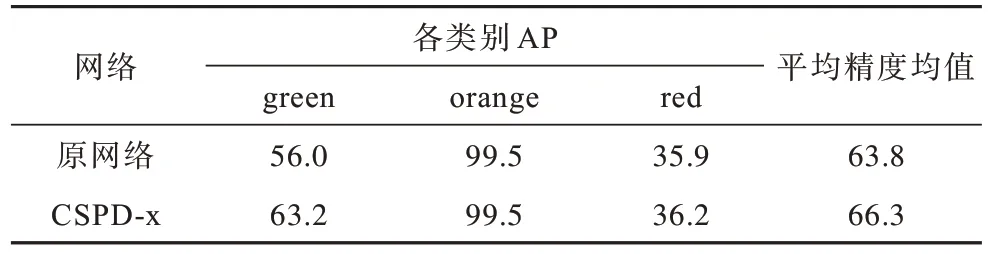
表2 主干网络残差结构改进前后实验结果对比Table 2 Comparison of experimental results before and after improvement of residual structure in backbone network %
由表2 可以看出:改进后的网络相比于原网络对各类目标的识别精度都有提升,其中绿色信号灯的识别精度相比于原网络提升了7.2 个百分点,由于数据集中黄色信号灯数量较少且图片较为清楚,因此黄色信号灯的识别精度较高,而红色信号灯的识别精度提升不是特别明显,仅提升了0.3 个百分点,但是总体上改进网络mAP 值较原网络提升了2.5 个百分点。
3.4.2 特征融合网络残差结构改进实验
为验证不同跨连接方式的效果,设计另外2 种不同的残差组件来进行对比实验(以CSPS1-x 和CSPS2-x 表示),验证CSPS-x 结构的有效性,各残差组件结构如图14 所示。最后通过比较和分析选择出最优的连接方案对原CSP2-x 结构进行替换。

图14 3 种残差组件结构对比Fig.14 Comparison of three residual component structures
根据3 种不同的改进方案,分别对原CSP2-x 结构进行替换和训练,训练完成后进行测试,实验结果如表3 所示。

表3 特征融合网络残差结构改进前后实验结果对比Table 3 Comparison of experimental results before and after improvement of residual structure in feature fusion network %
由表3 可以看出:相较于原网络,3 种改进网络识别效果都有所提升。在对绿色信号灯的识别上,CSPS-x 性能最好(AP 为66.8%),相比于原网络提升10.8 个百分点;在对黄色信号灯的识别上,由于各网络的识别效果都较好(AP 均为99.5%),因此3 种改进网络的AP 值没有提升;在对红色信号灯的识别上,各网络的效果都较差,3 种改进网络的AP 只有小幅提升,CSPR1-x 相比于原网络提升0.1 个百分点(AP 为36%),CSPR2-x 和CSPS-x 都提升0.2 个百分点(AP 为36.1%)。总体来看,3 种改进方案对交通信号灯识别的mAP 值都有较大的提升,其中第3 种方案提升最大(mAP 为67.5%),相较于原网络提升3.7 个百分点。由此可见,CSPS-x 结构所带来的优化效果优于CSPS1-x 和CSPS2-x。因此,选择CSPS-x结构对原网络进行改进,替换原网络中的CSP2-x结构。
3.4.3 检测尺度改进实验
本文对原网络进行了检测尺度的改进。原YOLOv5s 共有3 种检测尺度,分别为20×20、40×40、80×80。本实验通过增加或减少检测尺度的种类来寻找出最适合交通信号灯检测的尺度种类。
为验证本文对于检测尺度改进的合理性和有效性,在原网络的基础上去除20×20、40×40 规格的检测尺度,保留80×80 的检测尺度,得到只具有一个检测尺度的网络来增加实验的可对比性。然后再根据之前的改进思路在原网络的基础上去掉20×20 的检测尺度,保留40×40、80×80 这2 个规格检测尺度。最后对原网络和检测尺度改进后的网络模型分别进行训练,得到的检测结果如表4 所示

表4 检测尺度改进前后实验结果对比Table 4 Comparison of experimental results before and after improvement of detection scale
由表4 可以看出:只有1 个80×80 检测尺度的网络速度最快(36.5 frame/s),相比于原网络提升27.6 个百分点,但mAP 值下降1.4 个百分点;具有2 个检测尺度的改进网络检测速度为32.3 frame/s,相比于原网络提升12.9 个百分点,而mAP 值只减少0.3 个百分点;1 个检测尺度的网络相比于2 个检测尺度的网络识别精度减少较大,同时相比于原网络,改进后的2 个网络都能达到较高的检测速率。综合以上实验结果,本文选择保留40×40、80×80 这2 种规格的检测尺度来对原网络进行改进。
3.4.4 网络模型消融实验
通过以上实验分析,对原网络的网络结构分步骤依次进行改进,对改进后的网络模型进行训练并测试,消融实验结果如表5 所示。其中:●表示应用此方案;○表示不应用此方案。
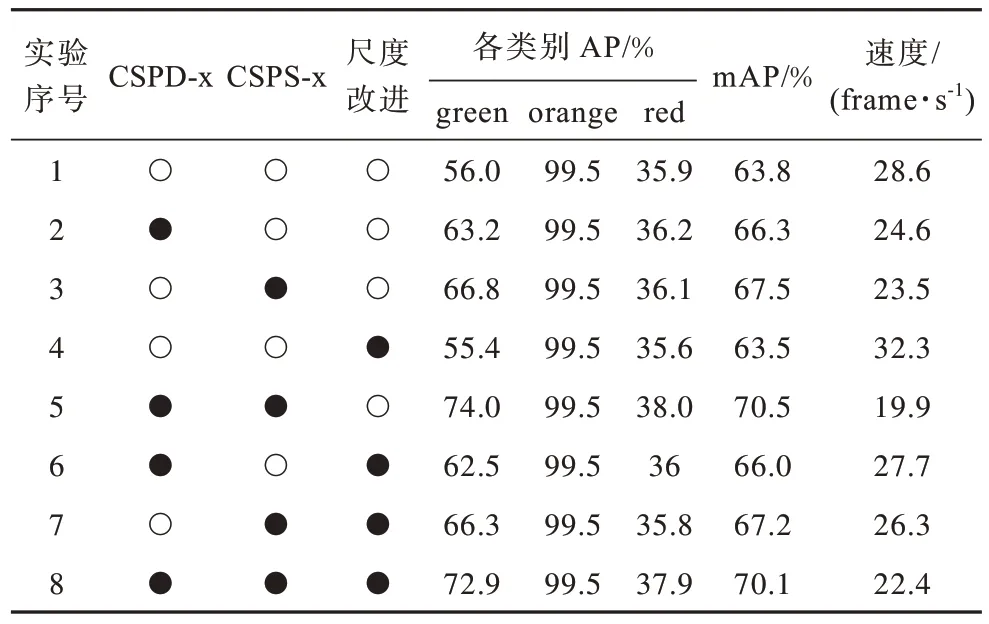
表5 消融实验结果对比Table 5 Comparison of results in ablation experiment
由表5可以看出:在采用CSPD-x结构和CSPS-x结构分别替换了CSP1-x 结构和CSP2-x 结构后,各类别识别精度都有较大的提升,mAP 值达到70.5%,但是检测速度为19.9 frame/s,相比于原网络下降8.7 frame/s;在去除20×20 检测尺度后,各类别的识别精度略微下降,mAP 值降低了0.4 个百分点,但检测速度较未去除之前提升12.6 个百分点,达到22.4 frame/s。由此可见,改进网络能够较好地实现对交通信号灯的检测与识别,并且满足实时性的要求。
实际环境下的检测效果对比如图15 所示,从中可以看出,原网络存在许多信号灯未被检测出的情况,而改进网络对交通信号灯的检测效果更好,识别精度更高。由此可见,改进网络更适用于对交通信号灯的检测与识别。
在LaRA 数据集上将本文方法与使用不同网络的识别方法进行对比,如表6 所示。

表6 LaRA 数据集上不同方法的实验结果对比Table 6 Comparison of experimental results by different methods in LaRA dataset %
由 表6 可以看出:TL-YOLOv5s 网络在LaRA 数据集上相比于其他网络具有更好的识别性能,对黄色和绿色信号灯的识别精度均为最高,对红色信号灯的识别精度略低于Faster R-CNN。总体上,TL-YOLOv5s 网络模型的mAP 值达到70.1%,相比于RefineDet、Faster R-CNN、R-FCN 等方法有较大幅度提升。
4 结束语
针对传统交通信号灯识别方法精度低且难以达到实时检测要求的问题,本文提出一种改进的YOLOv5s 网络。设计2 种新的残差模块替换YOLOv5s 网络中的残差模块,增强主干网络特征提取能力和融合网络特征融合能力,提高检测精度同时防止网络训练时模型退化。在此基础上,对网络的检测尺度进行改进,去除大目标检测尺度而保留中小目标检测尺度,以此来适应交通信号灯的检测,进一步提高网络运行的速度。实验结果表明,TL-YOLOv5s 在LaRA 数据集上取得了70.10%的平均精度均值和22.38 frame/s 的检测速度,相比YOLOv5s、R-FCN 等网络具有更高的识别精度且满足实时性的要求。下一步将通过增加数据集中交通信号灯的类别扩大模型的识别范围,提高其在实际环境下的检测性能。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
北京航空航天大学学报(2019年9期)2019-10-26
小学科学(学生版)(2019年3期)2019-03-30
小天使·一年级语数英综合(2018年6期)2018-06-22
太空探索(2016年5期)2016-07-12
华人时刊(2016年19期)2016-04-05
时代英语·高三(2014年5期)2014-08-26
