
基于自裁剪异构图的NL2SQL 模型
2022-09-15 06:59:00黄君扬王振宇梁家卿肖仰华
计算机工程 2022年9期
黄君扬,王振宇,梁家卿,肖仰华
(1.复旦大学 软件学院,上海 200433;2.信息系统工程重点实验室,南京 210007)
0 概述
随着自然语言处理技术的发展,智能问答系统在无人驾驶、语音识别、人脸识别等领域[1-3]得到广泛应用。智能问答系统通常以一问一答形式,精确定位用户所需要的提问知识,通过与用户进行交互,为用户提供个性化的信息服务。近几年,基于自然语言转换为结构化查询语言(Natural Language to Structured Query Language,NL2SQL)的问答系统成为了研究的热点[4-5],相比基于检索式、基于阅读理解的其他问答系统,NL2SQL 先生成结构化查询语句(Structured Query Language,SQL),再提供答案的推理路径,因此具有更好的可解释性。NL2SQL 任务即将自然语言问句解析为结构化查询语句,并用这条查询语句得到问题的答案。例如,给定问题“请列出图书俱乐部中1989 年之后至少有两本书的图书分类类别。”NL2SQL 需要将其解析成SQL 查询语句“SELECT category FROM book_club WHERE year>1989 GROUPBY category HAVING count(*)>=2”。由于相同的问题在不同的数据库模式上会有不同的SQL 查询语句,因此设计一种能同时学习问句表示和数据库模式表示的模型对于提高NL2SQL 模型的逻辑准确率和执行准确率十分重要。
现有研究通过在注意力机制的基础上构建一个异构图[6]来联合编码数据库模式和问句,随后再使用SQL 语法指引的树状解码器[7]来解析SQL 语句。这种方法将数据库模式和问句视为一个异构图,建立问句、列名和表名中字符之间的关系。随后学习这些关系的嵌入作为模式信息,并将其编码到模型中。然而,该方法根据整个数据库模式构建一个异构图,将导致两个主要问题:其一,当数据库模式较大时,异构图太大,模型难以捕捉并学习到正确的特征;其二,该方法会忽略数据库模式中的每一个元素的重要性。例如,当询问一个人的身高时,实际上数据库模式中人实体的所有属性中只有身高是有用的,年龄、性别等属性都是无用的,所以在构图时,年龄与性别这两个属性不应该与身高有相同的权重。一般而言,模型需要根据问句判断数据库模式中所有元素的重要程度,而不是单纯地将数据库模式中所有的元素加入到异构图中。
为了解决上述问题,本文提出基于自裁剪异构图与相对位置注意力机制的NL2SQL 模型,简称为SPRELA。SPRELA 模型采用序列到序列的框架,主要包括异构图构建、编码器和解码器三部分。异构图构建模块使用预先定义的专家知识构建一个初步的异构图。SPRELA 编码器裁剪异构图的部分边来剔除数据库模式中不重要的元素,并使用相对位置注意力机制来联合学习问句和数据库模式的向量表示,其中相对位置就是异构图中边的特征,词特征使用ELECTRA[8]预训练语言模型进行初始化。SPRELA解码器借助预先定义的SQL 语法规则,使用树型解码器分步解码出树状结构的抽象语法树,并通过槽填充将SQL 语句的信息补全。
1 相关工作
目前,NL2SQL 的相关工作可以根据模型中的模块大致分为问句与数据库模式联合编码、结构化查询语言解码和预训练词表征增强3 类。
针对问句与数据库模式联合编码的问题,SQLNet[9]通过列名注意力机制来解决问题和数据库模式的联合编码问题,然后在预定义的SQL 模板上使用指针网络补全SQL信息。IRNet[10]引入中间表示层,以解决自然语言表达的意图与SQL 中的实现细节不匹配的问题,首先将数据库模式与问句建立链接,识别出问句中提到的表名、列名和值,随后用神经网络把问句按照数据库模式分成不同的问句区间并使用BiLSTM 进行编码。RAT-SQL[11]针对数据库模式和问句通过构建一个异构图建立数据库模式与问句中词之间的联系,然后将异构图中各个节点之间的边进行向量化表示,最后使用相对位置自注意力机制将异构图信息编码到模型中。然而,上述方法都没有考虑对数据库模式信息进行过滤,无用的模式信息会放大模型编码过程中的噪声。
针对结构化查询语言解码问题,近期的工作通常使用树形结构的解码器来解码SQL 语句,即在定义目标语言的基础语法作为先验知识后,生成一棵抽象语法树来表示SQL 语言。树形结构解码策略的应用非常广泛[12-13],特别是在解决数学问题和自然语言转换为各类编程语言等任务中。RAT-SQL 使用LSTM 以深度优先的遍历顺序生成SQL 的抽象语法树,然后使用指针网络填槽补全SQL 语法树中缺失的表名和列名。SmBoP[14]使用自下而上的解码策略,在第t个步骤构建高度小于等于t的top-K 子树,由于每次解码时每个子树都是并行解码的,因此该方法提高了解码效率。
还有一些工作侧重于为NL2SQL 任务提供预训练词增强表征。GraPPa[15]首先学习Spider 数据集中的语法和SQL 规则,然后利用这些规则在其他数据库上生成与Spider 构建规则相似的高质量问句-SQL对,然后设定预训练任务让模型根据问句和数据库模式直接生成SQL,以捕捉问句和数据库模式之间的结构信息。GAP[16]通过3 个不同的预训练任务提高词表征:第1 个预训练任务判断数据库表中的列是否出现在问句中;第2 个预训练任务随机把问句中的列名替换成该列单元格的值,模型需要恢复被替换的列名;第3 个预训练任务需要模型根据问句与数据库模式直接生成SQL 语句。然而上述方法使用的预训练语料质量无法保证,且模型训练需要大量算力支持。
2 问题定义与模型框架
2.1 问题定义
NL2SQL 任务的输入是一句自然语言问句和数据库模式,输出是一个结构化查询语句Z。
具体而言,模型需要根据给定的一个长度为|Q|个字符的问句Q=[q1,q2,…,q|Q|]和数据库模式S=<T,C>生成结构化查询语句Z。数据库模式由表名T=[t1,t2,…,t|T|]和列名C={c1,c2,…,c|C|}组成,其中,表名有|T| 个,列名有|C| 个。每一个列名ci={ci,1,ci,2,…,ci,|ci|}由|ci|个字符组成,每一个表名ti={ti,1,ti,2,…,ti,|ti|}由|ti|个字符组成。生成的结构化查询语句Z以抽象语法树(Abstract Syntax Tree,AST)的形式来表示。
模式中的一些列被称为主键,主键是一个数据库表中的一行数据的唯一索引。还有一些列被称为外键,用于索引不同表中的主键列。此外,表中每一列的单元值均由数字或文本组成。
2.2 模型框架
本文提出的SPRELA 模型采用序列到序列的框架,如图1 所示,主要由3 个模块组成:1)异构图构建,使用专家知识,动态地将输入的问句和数据库模式构建为一个异构图,更好地建立了问句与数据库模式之间的联系;2)编码器,使用相对位置注意力机制,将问句、数据库模式信息和异构图联合编码为高维隐层向量表示;3)解码器,使用树型解码器将高维隐层向量解码成高质量、可执行的SQL 语句。
3 模型设计
3.1 异构图构建
本节介绍如何使用问句Q和数据库模式S构建异构图G=<V,E >。异构图的节点集合由数据库模式中的列名、表名和问句中的词语组成,以字符的形式来标记,即V=C⋃T⋃Q。针对表示列名的节点,需要在标签前加入额外特征来表示其类型是字符还是数字。加入问句中的词语作为节点能将问句中的词语与数据库模式中的信息对齐,丰富了异构图的信息表示能力,使异构图有效地建立了问句与数据库模式之间的联系。异构图的边集E 是由专家根据数据库模式来定义的,其中一部分是通过数据库特有结构(例如外键、主键等关系)而得出,另一部分是通过对验证集上错误的案例进行分析,并多次迭代归纳总结得出。专家定义的异构图边构建规则如表1 所示。

表1 专家定义的异构图边构建规则Table 1 Heterogeneous graph edge construction rules defined by experts
在表1 中,DISTANCE-D 代表Y 是X 中第D 个字符,SAME-TABLE代表X 和Y 属于同一张表,FOREIGN-F 代表X 是Y的外键,FOREIGN-R 代表Y是X 的外键,PRIMARY-KEY-F 代表X 是Y 的外键,HAS-F 代 表X 是的一个列,PRIMARY-KEY-R 代表Y 是X 的主键,HAS-R代表Y是X的一个列,FOREIGN-TAB-F 代表X 在表Y 中存在外键,FOREIGN-TAB-R 代表Y在表X中存在外键,FOREIGN-TAB-B 代表X 和Y 中互相存 在外键,NOMATCH 代表X和Y中没有重叠的字符,PARTIALMATCH代表X 是Y的子串,EXACT-MATCH 代表X和Y完全一致,HAS-VALUE 代表X 是Y 列中某个单元格的值。
3.2 编码器
SPRELA 编码器首先使用ELECTRA 预训练语言模型作为骨干网络获取向量表示cinit、tinit和qinit,其中,cinit代表异构图中列名的词向量表示,tinit代表异构图中表的词向量表示,qinit代表问句的词向量表示,然后将这3 个向量表示连接成一个向量X作为输入。

通过该方式,数据库模式中所有与问句相关的词都被连接起来,形成了最终的向量表示。为了使模型能学习边的特征,编码器将异构图构建模块构建出的初步异构图的每一个边初始化为一个向量表示。然后编码器使用相对位置编码的自注意力[17]机制对输入进行编码,使得模型能联合学习问题和知识库模式之间的关系。与传统方法不同的是,SPRELA 编码器以异构图的边向量作为相对位置编码,以此将异构图的信息融入到SPRELA 中,如式(2)~式(7)所示:


其中:边的种类一共有R种,第s条边定义为E(s)⊆X×X(1 ≤s≤R),X代表节点数量;是边的一个可学习的边向量表示;是一个自裁剪变量,根据输入的自然语言问句对异构图中每个边si进行二分类,来记录这条边是否需要保留,如果不需要保留则利用将该边的向量表示置为一个全为0 组成的同维度向量。
本文构建了一个二分类模型来实现该自裁剪子模型。首先,模型利用多头注意力机制,并使用自然语言问句的嵌入表示Xq为异构图中每条边si计算向量表示,如式(9)、式(10)所示:

然后,使用Biaffine[18]二分类器来判断经过编码的向量表示和边的嵌入表示xsi是否有关联,如式(11)、式(12)所示:

如果si出现在真实SQL 语句中,则边的标签为1。本文将该任务与语义解析任务以多任务训练的方式进行联合训练,目标函数如式(13)所示:

3.3 解码器
解码器使用IRNet 模型中基于长短期记忆(Long Short-Term Memory,LSTM)网络的树型解码器解码SQL 语句。首先以深度优先遍历的顺序将SQL 生成为一棵抽象语法树。然后通过LSTM 网络输出一连串的动作(action),动作主要分为以下2 类:1)生成的节点为非叶子节点,则将该节点扩展为一条语法规则,称为扩展规则(Extend Rule);2)生成的节点为叶子节点,从数据库模式中选择一个列名或表名,分别称为列选择(Select Column)或表选择(Select Table)。
树型解码器中的LSTM 使用如式(14)所示的方式更新状态:

其中:mt是LSTM 的核(cell)状态;ht是LSTM 在t时刻的输出;at-1是上一个动作的嵌入表示;pt是语法树中当前节点的父节点;nft是当前节点类型的嵌入表示。
扩展规则的计算方式如式(15)所示:

其中:σ(·)是Softmax 函数;g(·)是多层 感知机层并以tanh 作为激活函数。
列选择的计算方式如式(16)所示,表选择的计算方式与列选择类似。

4 实验与结果分析
4.1 数据集与评测指标设置
使用Spider[19]数据集验 证SPRELA 模型性能。Spider 是一个评估NL2SQL 系统的常见数据集,包含8 659 个训练条目和1 034 个验证条目,以及复杂的SQL 查询和1 个冷启动设置,其中测试集中的数据库模式与训练集和验证集是不同的。使用两个通用的指标评测SPRELA 模型在Spider 数据集上的效果,分别为:1)不含槽位值的逻辑准确率(EM);2)含槽位值的执行准确率(EXEC)。EM 主要评测SQL语句的语法结构,测试脚本将每个SQL 分解成多个子句并进行集合匹配,而不是简单地将预测出来的SQL 和标签SQL 进行字符串比较。EXEC 主要评测执行结果,测试脚本将直接执行预测出来的SQL 和标签SQL 进行比较判断能否查询到相同的结果。
4.2 参数设置
针对编码器,设置相对位置注意力机制的多头数 量H=8,其共包含24个自注意力层。Dropout[20]层损失的信息比例设置为0.2。针对解码器,使用集束搜索策略并设置集束大小K=30,在预测时的解码步骤最大值设置为T=9。ELECTRA 预训练语言模型和SPRELA 解码器的学习率分别设置为3e-6 和0.000 186。模型在RTX3090 显卡上训练了500 轮,批次大小设置为16,并采取梯度积累策略,其中梯度累积参数设置为4。
4.3 对比实验分析
使 用RAT-SQL[11]、GAZP[21]、COMBINE[22]、BRIDGE[23]、RaSaP[24]、RATSQL+GAP+NatSQL[25]和PICARD[26]作为基线模型进行对比,其中RATSQL+GAP+NatSQL 和PICARD 模型的规模远大于本文SPRELA 模型和其他基线模型。表2 给出了基线模型与SPRELA 模型在Spider 数据集上的实验结果。由于RAT-SQL 模型不能生成可执行的SQL 语句,因此执行准确率使用N/A 表示。由表2 中实验结果可以看出,SPRELA 模型在两个评价指标上都超越了现有的相同参数量级别的模型,特别是在执行准确率指标上超越了RaSaP模型1.1个百分点。RATSQL+GAP+NatSQL 模型的EXEC 指标效果要好于SPRELA 模型,原因是该模型集成了一个槽位预测模型,旨在提高槽位预测的准确率,而多个模型的集成也使该模型在EXEC 指标上表现优秀。PICARD模型在EM 和EXEC 指标上的效果都比SPRELA 模型好,原因是该模型骨干网络使用了T5-3B[27]预训练语言模型,T5-3B 的参数量远多于现有所有模型,所以其效果为目前最优。但是模型集成(如RATSQL+GAP+NatSQL)和大规模模型(如PICARD)意味着需要更大的算力支持、更长的训练时间,这些模型的效果理论上会更好,但是成本太高,由于实际工程应用场景对模型的并发量、成本控制都有所要求,因此无法支持超大规模的模型。

表2 NL2SQL 模型在Spider 数据集上的实验结果Table 2 Experimental results of the NL2SQL models on the Spider dataset %
图2 是SPRELA 模型与BRIDGE 模型的实验结果的案例分析,可以看出BRIDGE 模型生成了错误的SQL,SPRELA 模型生成了正确的SQL。图2 中的解释是对BRIDGE 模型生成错误SQL 的原因分析,可见SPRELA 模型可以更好地将自然语言问句与数据库模式对齐,也能更好地理解自然语言查询中的语义信息。因此,SPRELA 模型不论是在生成SQL语句的结构上,还是槽位值的选择上均具有更好的性能表现。

图2 SPRELA 与BRIDGE 模型的实验结果案例分析Fig.2 Case analysis of experimental results of SPRELA and BRIDGE models
为了更细致地分析模型在不同SQL 子句上的性能表现,本文使用精确率、召回率和F1 值3 个指标对模型子句性能做进一步实验。实验结果如表3 所示,可以看出SPRELA 模型在group 子句上的泛化能力与查询性能仍有提升的空间,在select、order 和and/or 子句上具有较好的泛化能力,在where 子句上的查询性能也仍有提升空间。
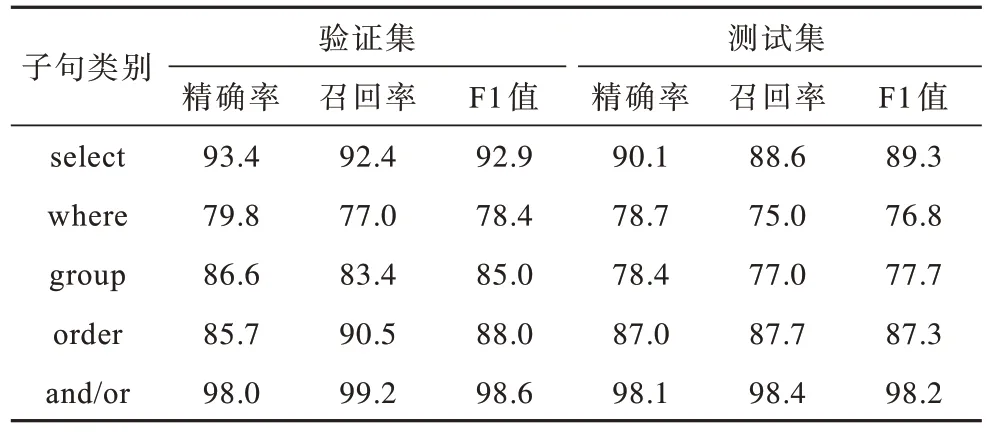
表3 SPRELA 模型子句性能Table 3 Clause performance of the SPRELA model %
4.4 消融实验分析
为了分析不同模块给SPRELA 模型带来的效果增益,本节针对SPRELA 模型进行消融实验来验证异构图构建模块中的专家知识子模块和编码器模块中的自裁剪子模块对模型性能的影响。消融实验结果如表4 所示。

表4 SPERLA 模型的消融实验结果Table 4 Ablation experiment results of the SPRELA model %
从表4 中的实验结果可以看出,完整的模型相比于不同的消融模型取得了最优的效果。对比移除专家知识模块前后,不论是EM 指标还是EXEC 指标都有所下降。在移除自裁剪模块后,模型在两个指标上效果同样有所下降。当同时移除专家知识和自裁剪模块后,模型效果则会进一步下降。为了解释消融模型效果下降的原因,本文借助图3 所示的案例进行分析,其中错误SQL 来自不包含专家知识与自裁剪模块的消融模型,正确SQL 来自完整的SPRELA 模型。此外,图3 中还列出了数据库模式信息。

图3 专家知识与自裁剪模块的有效性分析结果Fig.3 Effectiveness analysis results of expert knowledge and self-pruning modules
由图3 可以看出,错误SQL 未能识别出“amc hornet sportabout(sw)”是一个完整的槽位值的原因在于“sw”恰好是“model_list”表中“model”列的一个值而“amc hornet”恰好也是“car_names”表中“Make”列的一个值。因此,“amc hornet sportabout(sw)”就被拆分为“amc hornet”和“sw”两个槽位值并匹配到其相应的列名。
在利用专家知识构建异构图后,“amc hornet sportabout(sw)”和列名“Make”会与标记为EXACTMATCH 的边连接,而“amc hornet”和列名“Make”会与标记为PARTIAL-MATCH 的边连接。通过该方式构建的异构图可使模型能建立问句与数据库模式之间更细粒度的关系。
由于问句中的语义信息明显是查询装备“amc hornet sportabout(sw)”套件轿车的加速度,与轿车的模组(Model)无关,因此自裁剪模块会将与列名“Model”相关的边裁去。通过该方式,模型能够更好地剔除与问句无关的图信息,保留相对有关的信息,减少了噪声的引入。
在结合专家知识与自裁剪模块后,由于异构图的不同边具有较强的特征信息,使得自裁剪模块在该案例中还能学习到当存在标记为EXACT-MATCH的边时优先裁剪标记为PARTIAL-MATCH 的边的行为。因此两个模块的组合可以进一步提升模型的效果,这也与消融实验的结果一致。从上述实验结果与案例分析证明了本文设计的专家知识与自裁剪机制对于模型性能提升的有效性。
5 结束语
本文提出一种基于自裁剪异构图的自然语言转换为结构化查询语言模型SPRELA,采用ELECTRA预训练模型获取词表征作为骨干网络并利用专家知识构建异构图,通过相对位置注意力机制联合编码问句与数据库模式,使用树状解码器解码生成结构化查询语句。在Spider 数据集上的实验结果表明,相比于经典模型和同类模型,SPRELA 模型利用自裁剪机制裁剪异构图中的部分边,使得模型能够剔除与问句相对无关的信息,保留相对有关的信息,达到更细粒度的数据过滤,减少异构图中的无用信息,同时通过引入专家知识构建异构图来建模结构化数据中的模式信息,能更好地辅助模型学习结构化查询语言的相关特征。今后将尝试寻找挖掘专家知识的自动化或半自动化方法,进一步提高SPRELA 模型在级联查询、嵌套子查询等复杂SQL 解析任务下的执行准确率。
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
小学教学研究(2022年5期)2022-04-28 21:29:36
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
中国外汇(2019年19期)2019-11-26 00:57:32
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
电信科学(2016年11期)2016-11-23 05:07:56
