
基于堆叠GRU的伺服电机滚动轴承剩余寿命预测
2022-09-15 06:26尹柏鑫袁小芳杨育辉谢黎
机床与液压 2022年12期
尹柏鑫,袁小芳,杨育辉,谢黎
(1.湖南大学电气与信息工程学院,湖南长沙 410082;2.机器人视觉感知与控制技术国家工程实验室,湖南长沙 410082)
0 前言
轴承作为伺服电机的重要零部件之一,其工作状况直接影响着伺服电机的性能、质量和可靠性。轴承本身就是易损部件,尤其在经过长期高强度的运行之后很容易发生故障,进而影响伺服电机的性能。有研究表明,40%以上的伺服电机故障与轴承有关。因此,对伺服电机滚动轴承进行剩余寿命预测,而后制定及时的维修计划,能有效避免严重事故的发生,降低维护成本,保障伺服电机安全可靠地运行。
当前滚动轴承的剩余寿命预测方法主要分为基于故障物理的方法和基于数据驱动的方法两大类。基于故障物理的方法主要依赖于大量的先验知识来构建轴承退化指标的函数模型,然而面对实际复杂的工况,建立精确的模型是极其困难且不易标准化的。而基于数据驱动的方法则是利用大数据与人工智能挖掘轴承当前状态数据和剩余寿命之间的潜在关系,通过构建更简单的数据模型来估算复杂系统的剩余寿命。目前预测模型绝大部分都具有非线性复杂结构,因此文中采用基于数据驱动的方法进行研究。
基于数据驱动方法的两个关键步骤是特征提取和预测模型的构建。轴承振动信号特征提取方法很多,时域特征作为最常用的特征提取方法,它与轴承退化趋势有较好的一致性且参数易于提取。但是单一的时域特征并不能全面反映轴承退化信息。在实际应用中,时频域特征提取方法被广泛用于轴承振动信号的特征提取,其中经验模态分解方法对于处理非线性及非平稳信号有一定的优势。文献[5]采用经验模态分解方法提取轴承振动信号的固有模态函数能量作为特征向量。文献[6]利用经验模态分解和奇异值分解获得固有模态函数分量的奇异值作为特征向量。虽然经验模态分解取得了一定成效,但会存在模态混叠的现象,对构建最有效、敏感的特征向量存在一定的局限性。EEMD(Ensemble Empirical Mode Decomposition)作为经验模态分解的一种改进方法,它能有效抑制经验模态分解过程中的模态混叠问题。基于此,本文作者采取时域和EEMD时频域相结合的方法对轴承振动信号进行特征提取。
近年来,深度学习方法在寿命预测中取得了巨大的成功,它具有很强的非线性映射能力。循环神经网络(Recurrent Neural Network, RNN)是深度学习的基础网络,它的递归隐藏层非常适合用于时间序列的处理,GUO等提出了一种基于循环神经网络的轴承剩余寿命预测健康指标。LIU等提出一种基于递归神经网络的自编码器滚动轴承故障诊断方法。然而,RNN的结构缺陷经常导致梯度爆炸和梯度消失的产生,且难以捕获长期依赖信息。门控循环神经网络(Gated Recurrent Unit, GRU)和长短期记忆网络(Long Short-Term Memory, LSTM)作为RNN的增强变体,它们通过改变网络结构来弥补RNN的缺陷,其中GRU相比LSTM拥有更简单的网络架构和更快的收敛速度,受到越来越多学者的关注。此外考虑到轴承的退化过程具有较强的非线性和非平稳性,本文作者提出一种堆叠门控循环神经网络(Stacked Gated Recurrent Unit, SGRU)方法,通过构建深层架构使得网络的非线性表述能力和记忆能力都得到进一步提升,从而增强模型的预测能力。
综上,本文作者提出了一种基于SGRU网络的轴承寿命预测方法。该方法首先利用EEMD方法对轴承振动信号进行时频域特征提取,联合时域特征构成原始特征集,之后提出一种SGRU网络用于滚动轴承寿命预测,该网络通过堆叠多个GRU隐层来提高模型的非线性学习能力和预测精度,以解决传统基于浅层学习的轴承寿命预测模型预测能力不足的问题。
1 特征提取
1.1 基于EEMD特征提取
EEMD作为一种改进的经验模态分解方法,它通过在原始信号中添加白噪声然后进行经验模态分解并对得到的本征模函数(Intrinsic Mode Function, IMF)进行集总平均计算实现的。EEMD方法有效改善了经验模态分解方法由于信号间歇而产生的模态混叠的问题,它的具体算法如下:
(1)在原始信号()中加入一定幅值的白噪声序列(),得到信号():
()=()+()
(1)
(2)对加入噪声后的信号()进行经验模态分解,得到个IMF分量,(=1,2,…,);
(3)重复以上两个步骤直到对()加入次不同幅值的白噪声序列;
(4)将每次分解得到的IMF进行集总平均计算,计算结果就是最后得到的IMF分量。

(2)
EEMD算法流程如图1所示。
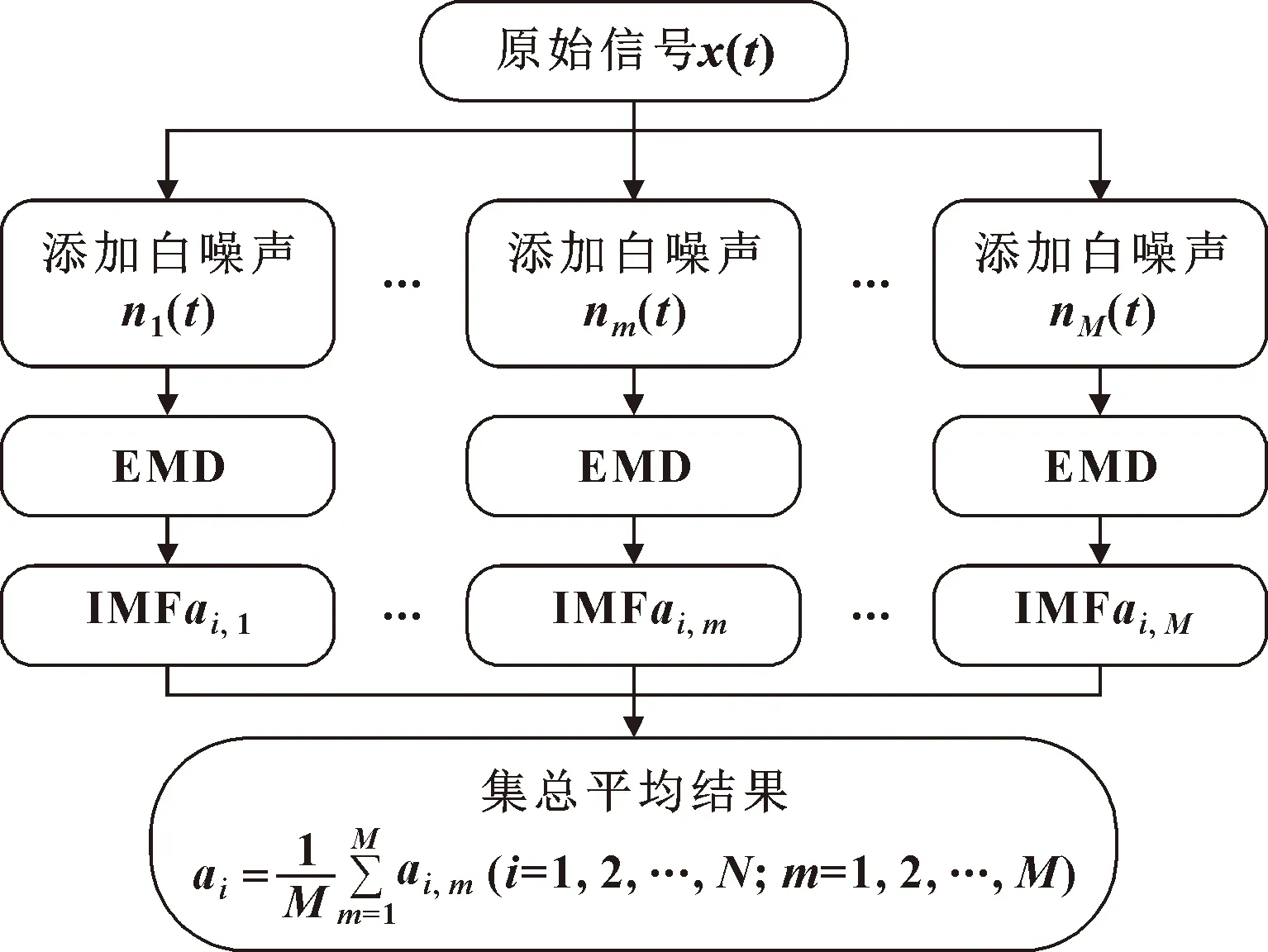
图1 EEMD算法流程
1.2 原始特征集构建
对轴承振动信号进行时域提取,得到10个常用的时域特征,包括均方根、均值、绝对均值、峰峰值、峰度、峭度、方差、偏度、最大值和最小值,然后对EEMD方法分解得到的IMF分量进行能量熵和奇异值计算,取前4个IMF的能量熵和奇异值作为时频域特征,联合时域和时频域总计18个特征构成原始特征集。
1.3 基于相似度度量特征筛选
考虑到原始特征集中存在一些不敏感特征,会影响后续预测模型的泛化能力,因此需要筛选出最能反映轴承退化过程的特征。Pearson相关系数是一种衡量特征间相似度的方法,它可以很好地检测两个特征向量之间的相关程度,因此被大量用于特征选取中来。其计算方法如公式(3)所示:

(3)
Pearson相关系数的取值范围是[-1,1],其值越接近-1说明负相关性越强,越接近1说明正相关性越强,无论是强负相关还是强正相关都说明两者具有很强的相似性。
2 基于GRU的寿命预测
2.1 GRU原理介绍
GRU的提出和LSTM一样,都是为了解决RNN因长期依赖带来的梯度消失和梯度爆炸等问题。不同的是GRU将LSTM的遗忘门和输入门融合成为单一的更新门,去除掉细胞状态并使用隐藏状态来进行信息传递,因此GRU不会随时间的改变而清除以前的有用信息,它能够保存长期序列中的信息,通过利用全部的时序信息从而避免了梯度消失问题。GRU具体结构如图2所示。
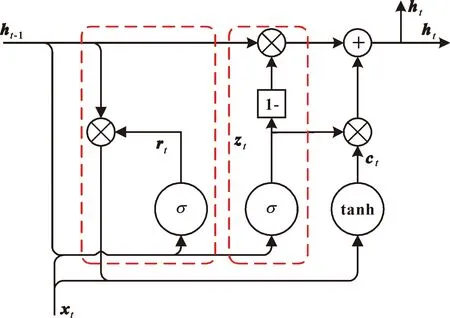
图2 GRU结构图
GRU主要由更新门和重置门两个部分组成,图2中为更新门,为重置门。其中更新门主要用于控制前一状态的信息-1对到当前状态的影响量。当更新门的数值越大,表示前一时刻的状态信息对当前状态的影响越大,即前一时刻传入的信息量越多,其表达式如式(4)所示:
=(+-1+)
(4)
重置门是用于控制前一时刻的状态信息-1对候选状态的影响量,当重置门的数值越小,表示前一时刻的状态信息对候选信息的影响越小,传入的信息量也越少。它的表达式和更新门表达式相同,只是线性变换的参数和偏置有所改变,计算方法见式(5):
=(+-1+)
(5)
最后,可得候选状态和输出为
=tanh(+(⊗-1)+)
(6)
=(1-)⊗-1+⊗
(7)
式中:为输入序列;-1为上一时刻隐藏状态;为当前隐藏状态;和是更新门的权重矩阵;和是重置门的权重矩阵;和是候选状态的权重矩阵;、、表示相应的偏置。图中的⊗符号表示点乘运算,tanh表示tanh函数作为候选状态的激活函数,表示sigmoid函数,其表达式分别如公式(8)和公式(9)所示:

(8)

(9)
通过设置sigmoid函数作为更新门和重置门的激活函数,使得输出值固定在0~1之间,以此达到保留或忘记信息的效果。
2.2 堆叠GRU网络
由于轴承的退化过程通常具有高度非线性和非平稳的特点,因此需要深层的体系结构来使网络具有更强的非线性学习能力,因此本文作者在GRU网络的基础上提出了一种SGRU网络用于构建轴承的寿命预测模型。考虑到堆叠层数过多反而会导致压缩过程中的信息丢失以及训练过程中的梯度消失现象,因此本文作者采用2个GRU隐层堆叠的方式对网络进行加深,将回归层直接构建在第二个GRU层上,回归层的激活函数使用sigmoid函数以确保输出范围在[0,1]之间。该SGRU网络的优点在于通过叠加双层GRU,网络的非线性学习能力、记忆能力都得到了增强。其网络结构示意如图3所示。

图3 SGRU网络结构
2.3 轴承剩余寿命预测流程
图4所示为轴承剩余寿命预测的流程。

图4 剩余寿命预测流程
具体分为以下几个步骤:
(1)特征提取。首先对采集到的轴承振动信号进行EEMD时频域特征提取,联合常用的时域特征一起作为初选特征,然后对提取的初选特征参数进行归一化处理以统一尺度,构成原始特征集。
(2)特征筛选。首先利用相似度度量方法对原始特征集进行特征筛选,筛选出与轴承剩余寿命相关性较强的特征构成最终的退化特征集。
(3)剩余寿命预测。以得到的退化特征参数作为输入,轴承的归一化剩余寿命作为标签对SGRU模型进行训练,然后将测试集退化参数输入到训练好的SGRU模型中得到测试集的剩余寿命预测值。
3 实验仿真与结果分析
3.1 实验数据描述
此次实验采用IEEE PHM2012挑战赛提供的FEMTO轴承数据集。数据由PRONOSTIA实验平台测得,实验台设置如图5所示。它通过增加径向负荷和加快转速的方式,使轴承在短时间内实现加速老化,当轴承的振动幅度超过20时停止实验,并把处于此状态的轴承默认为失效状态。该实验台在轴承上安装了2个加速度传感器,分别测量水平方向和垂直方向数据,传感器的采样频率设置为25.6 kHz,每隔10 s采集一次数据,每次采样0.1 s。

图5 PRONOSTIA实验平台
FEMTO数据集如表1所示,一共包含3种不同工况的轴承数据,每种工况下对应的前两个轴承全生命周期数据集是训练集,其他的则是测试集,测试集只包含轴承运行一段时间的生命周期数据。此外IEEE PHM2012挑战赛为参赛者提供了测试集轴承的全生命周期作为验证集,以验证所构建的预测模型的优劣。考虑到不同工况对模型训练有一定影响,因此本文作者仅选取工况1下的数据集进行实验,以轴承1_1和1_2为训练集来训练最佳的预测模型,以轴承1_3的全生命周期数据作为测试集来验证模型预测能力。同时,相关研究表明水平方向振动信号包含的信息比垂直方向要多,因此本文作者只对轴承水平方向振动信号进行分析。
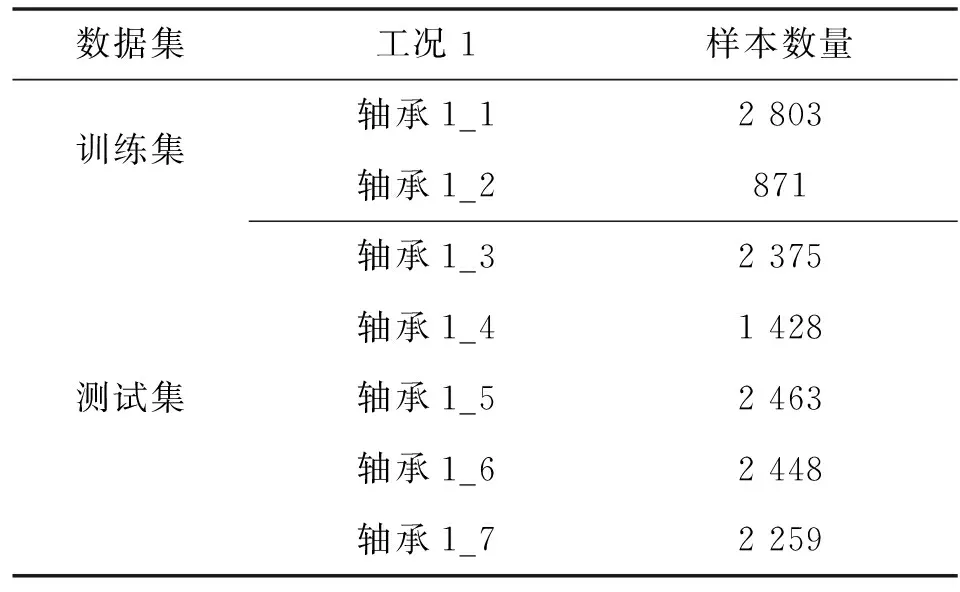
表1 FEMTO轴承数据集
3.2 实验验证
首先,对轴承振动信号采用常用的时域特征提取方法提取有量纲和无量纲的时域特征共10个,然后利用EEMD算法进行时频域分析,对得到的若干个IMF进行能量熵和奇异值计算,取前4个IMF的能量熵和矩阵奇异值作为表征轴承退化的时频域特征。因为提取到的时域和时频域特征的取值范围都各不相同,因此需要对18个特征进行归一化处理,以统一其尺度。在这里采用min-max标准化的方法对特征进行处理,计算方法如公式(10)所示:

(10)
其中:()为该特征样本时刻的特征值;和对应的是特征样本中的最小特征值和最大特征值;为归一化后的特征值。
归一化处理后得到的原始特征集中存在一些单调性不好和反映性能退化过程相对效果差的特征,因此需要对原始特征集进行特征筛选。采用第1.3小节中所提到的相似度度量方法——Pearson相关系数法对特征集进行筛选。通过计算各个特征值与轴承剩余寿命的Pearson相关系数,从而筛选出具有良好反映性能的特征。基于此方法计算得到的多维特征值的相关系数如表2所示。

表2 多维特征值的相关系数
一般来说,相关系数绝对值大于0.7的两个特征具有较强的相关性,相关性大于0.8则说明两特征间的相关性非常强。从表2可以看出:时域特征中的均方根、方差、最小值、峰度,和时频域特征中的、、、、的相关系数都超过了0.7,说明此次提取的时域和时频域特征具有较强的退化反映能力。为了获得更好的退化反映效果,选取相关系数最大的前4个特征作为最后的退化特征,基于此得到的最终退化特征有均方根、方差、、。图6为4个退化特征的归一化曲线。

图6 退化特征向量
对模型进行训练前要对轴承数据集样本进行寿命标签设置。以轴承振动信号的幅值连续超过设定阈值的点作为轴承退化起始点,将轴承从退化时刻至轴承失效的这段时间按公式(10)进行归一化映射到(0,1)区间内作为轴承完整寿命,0点代表轴承完全失效时刻,1点代表轴承退化起始点时刻。将训练集轴承中提取到的4个退化特征向量作为输入,归一化后的剩余寿命作为标签输入到SGRU网络进行训练,同时将均方误差函数作为损失函数,并采用Adam优化器对网络权值进行更新。将测试集的退化特征向量输入到训练好的SGRU模型当中,输出得到测试集轴承的剩余寿命百分比。最后采用单层LSTM算法进行对比实验,两种网络的具体训练参数设置如表3所示。

表3 网络参数设置
图7为两种方法得到的测试集轴承寿命预测结果,可以看出:本文作者提出的SGRU方法和传统LSTM方法的预测结果都不错,但是SGRU方法对测试轴承的预测寿命曲线与其实际寿命曲线更为接近。

图7 预测结果
为了更好地比较两种方法的预测结果,采用均方根误差对预测结果进行定量分析,通过计算得到两种方法的预测误差如表4所示。

表4 预测误差
可以看出:所提出的SGRU方法相比传统的LSTM方法具有更小的预测误差,即更高的预测精度。说明文中所提方法能够准确地预测轴承剩余寿命,为伺服电机安全可靠运行提供了保障。
4 结束语
传统的轴承剩余寿命预测模型都是基于浅层学习,因此非线性关系学习能力不足,相应的预测能力也会得到削弱。针对此问题,本文作者在GRU网络基础上构建了一种SGRU轴承剩余寿命预测模型。该模型以轴承退化特征向量为输入,以轴承的剩余寿命为输出,通过堆叠2层GRU隐层提高了网络的深度,增强了模型的非线性表述能力,并通过优化器对网络权值进行优化,进一步提升了模型的预测能力。最后通过实验验证了文中所提方法的可行性,并与单层LSTM方法进行对比,通过定量分析说明了文中方法具有更小的预测误差。
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22
哈尔滨轴承(2022年1期)2022-05-23
哈尔滨工程大学学报(2021年10期)2021-11-05
哈尔滨轴承(2021年2期)2021-08-12
哈尔滨轴承(2021年1期)2021-07-21
北京航空航天大学学报(2019年9期)2019-10-26
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
宇航计测技术(2019年1期)2019-03-25
